視覺/慣性組合導航技術發展綜述
2020-07-29 01:57:06張禮廉胡小平
導航定位與授時 2020年4期
張禮廉,屈 豪,毛 軍,胡小平
(國防科技大學智能科學學院,長沙 410073)
0 引言
隨著無人機、無人車以及移動機器人的井噴式發展,導航技術成為了制約無人平臺廣泛應用的瓶頸技術之一。在應用需求的牽引下,視覺/慣性組合導航技術,特別是視覺與微慣性傳感器的組合,逐漸發展成為當前自主導航及機器人領域的研究熱點。本文介紹的視覺/慣性組合導航技術側重于利用視覺和慣性信息估計載體的位置、速度、姿態等運動參數以及環境的幾何結構參數,而不包含場景障礙物檢測以及載體運動軌跡規劃等。
視覺/慣性組合導航具有顯著的優點:1)微慣性器件和視覺傳感器具有體積小、成本低的優點,隨著制造技術的不斷進步,器件越來越小,且成本越來越低。2)不同于衛星和無線電導航,視覺和慣性導航均不依賴外部設施支撐,可以實現自主導航。3)慣性器件和視覺器件具有很好的互補性,慣性導航誤差隨時間累積,但是在短時間內可以很好地跟蹤載體快速運動,保證短時間的導航精度;而視覺導航在低動態運動中具有很高的估計精度,且引入了視覺閉環矯正可以極大地抑制組合導航誤差,兩者的組合可以更好地估計導航參數。
視覺和慣性組合導航技術近年來取得了長足的發展。孫永全和田紅麗[1]從同步定位與構圖(Simultaneous Localization and Mapping, SLAM)的角度對視覺/慣性組合導航技術的基本原理和標志性成果進行了詳細分析。Huang[2]對基于濾波技術的視覺/慣性組合導航技術進行了全面的描述,特別是對濾波器的可觀性和濾波狀態的一致性問題進行了深入的探討。Huang和Zhao等[3]對基于激光和視覺傳感器的SLAM技術進行了全面的介紹,該文引用的文獻十分全面,但缺乏基本原理的闡述。當前隨著基于機器學習的視覺/慣性組合導航算法性能不斷提高,部分算法已達到甚至超過傳統的基于模型的組合導航算法性能。因此,非常有必要按照基于模型的算法和基于機器學習的算法對視覺/慣性組合導航技術進行詳細的分析。
1 視覺/慣性組合導航技術發展簡述
傳統的基于視覺幾何與運動學模型的視覺和慣性導航技術研究成果非常豐富。本文主要從純視覺導航以及組合導航2個層次梳理相關工作。
純視覺導航技術主要有2個分支:一個分支是視覺里程計(Visual Odometry,VO)技術;而另一個分支是視覺同步定位與構圖(Visual Simultaneous Localization and Mapping,VSLAM)技術。Scaramuzza教授[4-5]對早期的VO技術進行了詳細的介紹,并闡述了VO技術與VSLAM技術的區別與聯系:VO側重于利用連續圖像幀之間的位姿增量進行路徑積分,至多包含滑動窗口內的局部地圖;VSLAM側重于全局路徑和地圖的優化估計,支持重定位和閉環優化;通常VO可以作為VSLAM算法框架的前端。
目前,視覺里程計可以根據使用相機個數的不同分為單目、雙目和多目視覺里程計。其中最具有代表性和影響力的主要有三種算法,分別是視覺里程計庫(Library for Visual Odometry,LIBVISO)[6]、半直接單目視覺里程計(Semi-Direct Monocular Visual Odometry,SVO)[7]和直接稀疏里程計(Direct Sparse Odometry,DSO)[8]。這三種算法由于代碼公開,易于使用,運動估計效果好,成為了研究者們廣泛使用和對比的算法。
對于VSLAM算法,目前主流的方法可以分為兩類:一類是基于濾波的方法;另一類是基于Bundle Adjustment的優化算法。這兩類方法的開創性成果分別是Davison教授提出的Mono SLAM算法[9]和Klein博士提出的并行跟蹤與構圖(Parallel Tracking And Mapping,PTAM)算法[10]。在2010年國際機器人和自動化大會(IEEE International Conference on Robotics and Automation,ICRA)上,Strasdat的文章[11]指出優化算法比濾波算法的性價比更高,從此以后基于非線性優化的VSLAM算法就漸漸多起來。其中代表性的工作是ORB-SLAM[12]和LSD-SLAM[13],二者的主要區別是ORB-SLAM的前端采用稀疏特征,而LSD-SLAM的前端采用稠密特征。
當然,任何純視覺導航算法都存在無法避免的固有缺點:依賴于場景的紋理特征、易受光照條件影響以及難以處理快速旋轉運動等。因此,為了提高視覺導航系統的穩定性,引入慣性信息是很好的策略。
視覺/慣性組合導航技術與VSLAM算法類似,主要采用兩種方案:一種是采用濾波技術融合慣性和視覺信息;另一種是采用非線性迭代優化技術融合慣性和視覺信息。
基于濾波技術的視覺/慣性組合導航算法,可以進一步分為松組合和緊組合兩種框架。文獻[14-15]使用了卡爾曼濾波器來融合雙目相機和慣性器件輸出。作為一種松組合方式,組合中沒有充分使用慣性器件的輸出來輔助圖像特征點的匹配、跟蹤與野值剔除。2007年,Veth提出了一種視覺輔助低精度慣性導航的方法[16]。該算法使用了多維隨機特征跟蹤方法,其最大的缺點是跟蹤的特征點個數必須保持不變。同年,Mourikis提出了基于多狀態約束的卡爾曼濾波器 (Multi-State Constraint Kalman Filter,MSCKF)算法[17],其優點是在觀測模型中不需要包含特征點的空間位置;但是MSCKF算法中存在濾波估計不一致問題:不可觀的狀態產生錯誤的可觀性,如航向角是不可觀的,但MSCKF通過擴展卡爾曼濾波(Extended Kalman Filter,EKF)線性化后會使航向角產生錯誤的可觀性。為了解決濾波估計不一致問題,李明陽等[18]提出了首次估計雅可比EKF(the First Estimate Jacobian EKF,FEJ-EKF)算法;Huang等[19]提出了基于可觀性約束的無跡卡爾曼濾波(Unscented Kalman Filte,UKF)算法;Castellanos等[20]提出了Robocentric Mapping 濾波算法。這些算法均在一定程度上解決了濾波估計不一致問題。
2015年,Bloesch等提出了魯棒視覺慣性里程計(Robust Visual Inertial Odometry,ROVIO)[21],該算法利用EKF將視覺信息和慣性測量單元(Inertial Measurement Unit,IMU)信息進行緊耦合,在保持精度的同時降低了計算量。Indelman等基于EKF,綜合利用了2幅圖像間的對極約束和3幅圖像之間的三視圖約束融合單目相機和慣性器件[22]。基于相同的觀測模型,Hu等給出了基于UKF的實現方法[23]。
近年來,基于優化的算法得到了快速發展。Lupton和Sukkarieh于2012年首次提出了利用無初值條件下的慣性積分增量方法來解決高動態條件下的慣性視覺組合導航問題[24]。文中采用了Sliding Window Forced Independence Smoothing技術優化求解狀態變量。預積分理論的建立,使得基于優化的視覺/慣性組合導航算法得以實現。受此思想啟發,Stefan等采用Partial Marginalization技術,通過優化非線性目標函數來估計滑動窗口內關鍵幀的位姿參數[25]。其中,目標函數分為視覺約束和慣性約束2個部分:視覺約束由空間特征點的重投影誤差表示,而慣性約束由IMU運動學中的誤差傳播特性表示。該方法不適用于長航時高精度導航,因為沒有閉環檢測功能,無法修正組合導航系統的累積誤差。2017年,Forster等完善了計算關鍵幀之間慣性積分增量的理論,將該理論擴展到Rotation Group,并分析了其誤差傳播規律[26]。該算法也未考慮閉環檢測問題。同樣基于預積分理論,沈劭劼課題組提出了視覺慣性導航(Visual-Inertial Navigation System, VINS)算法[27]。該算法具備自動初始化、在線外參標定、重定位、閉環檢測等功能。ORB-SLAM的設計者Mur-Artal等利用預積分理論,將慣性信息引入ORB-SLAM框架,設計了具有重定位和閉環檢測等功能的視覺/慣性組合導航算法[28]。關于預積分理論,目前還缺乏積分增量合并以及相應的協方差矩陣合并方法。因此,文獻[28]去掉了ORB-SLAM中的關鍵幀刪除功能。表1匯總了基于視覺幾何與運動學模型的視覺和慣性導航技術的主要研究成果。
基于模型的視覺/慣性組合導航技術需要信噪比較高的輸入數據,算法的整體性能不僅受制于算法的基本原理,還取決于參數的合理性與精確度。相對而言,深度學習神經網絡能夠通過大數據訓練的方式自適應地調節參數,對輸入數據具有一定的容錯性,因此已有研究人員開發了一系列基于深度學習的視覺/慣性組合導航技術,并已取得一定成果。
使用深度學習神經網絡替換傳統算法中的個別模塊是較為直接的算法設計思路,如利用深度學習神經網絡實現里程計前端中的特征點識別與匹配。Detone等[29]提出了SuperPoint算法,該算法首先使用虛擬三維物體的角點作為初始訓練集,并將特征點提取網絡在此數據集上進行訓練;對經過訓練的網絡在真實場景訓練集中進行檢測得到自標注點,并將標注有自標注點的真實場景圖像進行仿射變化得到匹配的自標注點對,從而得到了最終的訓練集;隨后使用對稱設計的特征點識別網絡,將特征提取器讀入的原始圖像經過多層反卷積層轉換為特征點響應圖像,響應區域為相鄰幀圖像匹配特征點的位置。幾何對應網絡(Geometric Correspondence Network, GCN)[30]則是利用相對位姿標簽值構建的幾何誤差作為匹配特征點空間位置估計值的約束;隨后使用多視覺幾何模型結合低層特征提取前端網絡得到的匹配特征點,求解載體的運動信息。此類低層特征提取前端易于與傳統實時定位與建圖系統相結合,并且較為輕量,可植入嵌入式平臺進行實時解算。
另一種思路是使用深度學習神經網絡實現從原始數據到導航參數的整個轉化過程。Kendall團隊基于圖像識別網絡GoogleNet[31]開發了一種基于單張圖像信息的絕對位姿估計網絡PoseNet[32]。首先,搭建絕對位姿回歸數據集,配合高精度姿態捕捉設備,為單目相機拍攝的每一幀圖像標注絕對位姿標簽值;然后使用多層全連接層替換GoogleNet的多個softmax層,并構成位姿回歸器,回歸器的輸出維度與使用歐拉角表示的位姿維數相同;通過長時間的訓練,PoseNet能較為準確地將訓練數據集圖像投影為對應位姿標簽,然而沒有額外的幾何約束,網絡收斂較為困難。Wang等在位姿估計網絡中引入相鄰幀圖像信息,構建基于深度學習的單目視覺里程計DeepVO[33],為了能夠同時處理相鄰兩幀圖像的信息,將FlowNet[34]網絡的主體作為視覺特征提取器,并使用輸入窗口大于1的長短時記憶(Long Short Term Memory, LSTM)網絡聯合時間軸上相鄰多幀圖像的高層信息,以此來優化里程計短時間內的估計精度;最后使用全連接層綜合圖像高層信息,并轉化為相鄰幀圖像的相對位姿估計值。實驗結果表明,DeepVO相對于早期基于模型的視覺里程計LIBVISO[6]性能具有一定提升,同時與同類型算法[35]相比,也有明顯的性能提升。
與基于模型的視覺/慣性組合導航技術類似,為了提高導航算法的自主性與抗干擾能力,研究人員在基于深度學習的視覺導航技術中引入慣導數據,并為其設計單獨的網絡來提取有用的數據特征。牛津大學的Clark團隊設計了一種端對端的視覺/慣性組合里程計網絡VINet[36],使用雙向光流提取網絡FlowNet-Corr[34]提取相鄰幀圖像的高層特征,使用單層全連接層對圖像高層特征進行壓縮,并使用多節點LSTM網絡處理兩幀圖像間的慣性信息;隨后將兩種數據的高層特征在單維度上進行結合,構成視覺/慣性信息融合特征;最后使用全連接層將融合特征投影至SE(3)空間中,得到相對位姿估計值。VINet在道路與無人機數據中都顯示出較為優秀的性能,同時為基于深度學習的組合導航技術提供了基礎模板。
陳昶昊于2019年提出了基于注意力模型的視覺/慣性組合里程計網絡Attention-based VIO[37],網絡的基本框架與VINet類似,但視覺特征提取器使用更為輕量的FlowNetsimple[34]卷積層,以此來提高網絡運行效率。借鑒自然語言處理領域的注意力機制,使用soft attention和hard attention兩種注意力網絡剔除融合特征中的噪聲高層特征,從而加快訓練收斂,提高網絡性能。表2匯總了基于機器學習的視覺/慣性組合導航技術的主要研究成果。

表2 基于機器學習的視覺/慣性組合導航技術Tab.2 Learning based visual-inertial integrated navigation
在國內,清華大學、上海交通大學、浙江大學、哈爾濱工程大學、國防科技大學、北京航空航天大學、北京理工大學、南京航空航天大學、西北工業大學、電子科技大學、中國科學院自動化研究所等高校和科研機構的多個研究團隊近年來在慣性/視覺組合導航領域開展了系統性的研究工作,取得了諸多研究成果[38-44]。
2 基于模型的視覺/慣性組合導航技術
基于模型的視覺/慣性組合導航技術的通用結構示意圖如圖1所示。
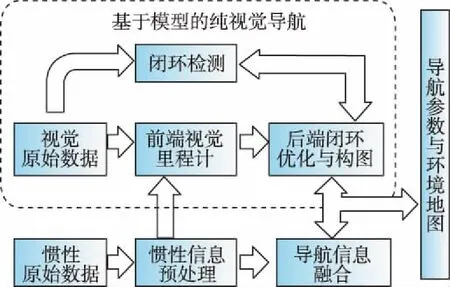
圖1 基于模型的視覺/慣性組合導航技術通用結構示意圖Fig.1 Scheme of model based visual-inertial navigation technology
2.1 基于模型的純視覺導航算法
基于模型的視覺導航算法是指以多視圖幾何等數學模型構建的VO和VSLAM算法。
(1)視覺里程計原理
載體在運動過程中,可以通過與其固聯的攝像機獲取圖像流。由于載體運動,同一個靜止的物體在不同幀圖像中的成像位置將發生變化。根據攝像機的成像幾何模型,可以利用同一物體在不同幀圖像中成像位置的關系,恢復出相機在拍攝圖像時的位置和姿態變化量。然后,將相鄰幀圖像的位置和姿態變化量進行積分,可以推算出攝像機運行的軌跡,如圖2所示。
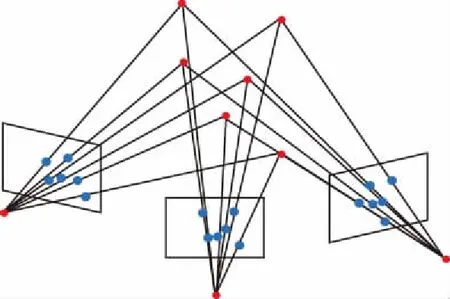
圖2 多視圖幾何示意圖Fig.2 Scheme of multi-view geometry
攝像機的成像模型是從多視圖中恢復出載體運動參數的基礎。常用的相機模型包括透視模型(perspective model)、全景模型(omnidirectional model)和球形模型(spherical model)等。攝像機模型可以通過觀察棋盤格或二維碼等特征固定且尺度大小已知的物體進行離線標定。
視覺里程計根據特征利用的方式可以分為間接法和直接法兩類。間接法通過最小化同一特征在不同圖像中的位置投影誤差來解算攝像機的運動參數;而直接法則基于光度(灰度)不變假設,通過最小化同一特征在不同圖像中的光度誤差來估計攝像機的運動參數。
間接法視覺里程計首先需要建立特征匹配關系,然后根據特征匹配對之間的坐標關系,解算出相機的運動參數。設載體在運動過程中,攝像機拍攝了n幅圖像,表示為I1∶n={I1,…,In};同時,在導航環境中有m個特征,特征的空間坐標為p1∶m={p1,…,pm} ;第j個特征在k時刻拍攝圖像中的坐標為zk,j=πk(pj),其中πk表示相機在k時刻的投影模型,其與相機的成像模型和相機的位姿相關。
首先,通過特征匹配算法建立特征之間的對應關系{zk,j?zk+1,j},間接法視覺里程的運動估計可以表示為最小化如下誤差函數的過程
(1)
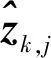
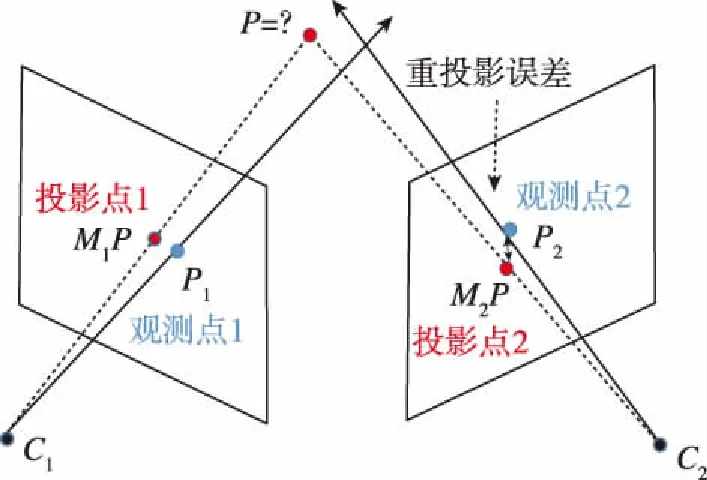
圖3 重投影誤差示意圖Fig.3 Scheme of reprojection error
與間接法不同,直接法視覺里程計則通過最小化光度誤差估計攝像機的運動參數。通常,同一特征在短時間內拍攝的多幅圖像中,其光度基本不變,并且攝像機在短時間內的位姿變化較小,同一特征在相鄰幀圖像中的成像位置變化不大。據此,直接法視覺里程計通過迭代優化算法在狀態空間中進行搜索,使得同一特征在不同圖像中的像點光度誤差最小,從而解算得到攝像機運動參數,具體優化目標函數為
(2)
其中,Ik(pj)和Ik+1(pj)分別表示同一特征在相鄰幀圖像中的光度。若直接法里程計在運動估計過程中使用了整幅圖像的像點光度,則為稠密視覺里程計算法;若僅使用部分像點光度,則為稀疏視覺里程計算法。由慕尼黑工業大學開發的DSO算法[8]就是一種稀疏直接法視覺里程計。
除直接法與間接法里程計外,Forster等還提出了一種半直接法視覺里程計[7]。在SVO中使用了直接法進行運動解算,同時采用了間接法來估計特征的三維坐標,建立局部地圖。
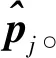
(2)閉環優化與構圖
視覺里程計是一種路徑積分方法,因此具有累積誤差。閉環優化是廣泛使用的一種用于修正視覺里程計累積誤差的方法。閉環修正依賴于構建的環境地圖,其基本原理是:載體在移動過程中,將觀測的視覺特征與地圖中的視覺特征進行匹配,并通過匹配關系解算出載體在地圖中所處的位置和姿態。由于建圖誤差和視覺里程計累積誤差的影響,通過里程計估計的攝像機位姿與通過閉環檢測估計的攝像機位姿之間具有差異,通過建立數學模型可以同時對里程計累積誤差和建圖誤差進行修正。閉環優化與構圖可以描述為一個最大后驗概率(Maximum A Posteriori, MAP)問題,具體表達式為
(3)
其中,X表示攝像機在整個運動過程中的位置和姿態構成的狀態向量;L表示所有特征在參考系下的位置向量的集合;Z表示特征在攝像機圖像中的成像點位置的集合;U表示里程計測量的運動參數。在大范圍的導航應用中,式(3)中包含的狀態量較多,因此需要對優化算法進行合理設計才能滿足算法的實時性需求。目前,廣泛使用的建圖與閉環優化工具有G2O[45]、GTSAM[46]和Ceres[47]等。
2.2 基于模型的視覺/慣性組合導航算法
基于濾波技術和基于非線性迭代優化技術是視覺/慣性信息融合的兩種典型方式。
(1)基于濾波技術的信息融合算法
基于濾波技術的信息融合算法主要考慮以下3個方面的問題:濾波器狀態變量的選取、狀態方程和觀測方程的建立以及濾波算法的選取。
首先是濾波器狀態變量的選取,常見的方式是將當前時刻的慣性導航參數、鄰近n幀圖像對應時刻的載體位姿參數以及這些圖像所觀測到的特征的空間位置參數加入到狀態變量中。當前時刻慣性導航參數通常包含IMU的位置、姿態、速度和陀螺、加速度計的零偏等,其定義如下
(4)
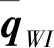
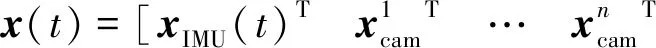
(5)
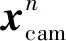
其次是狀態方程和觀測方程的建立。由于通常假設場景是固定的,即特征點的空間位置變化率為0,因此系統的狀態方程只與載體的運動參數有關。
典型的系統狀態微分方程如式(6)所示
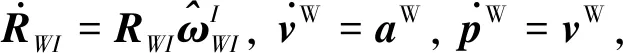
(6)
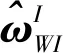
關于濾波器的選取,最常見的有EKF[17-18,20-22]和UKF[19,23,40-41,43],二者都是在卡爾曼濾波器(Kalman Filter, KF)的基礎上發展起來的。EKF通過偏導數得到雅可比矩陣,將狀態方程和觀測方程線性化,從而解決視覺/慣性融合中的非線性問題。為了克服EKF中高階導數省略問題和雅克比矩陣計算難的問題,UKF按一定間隔和概率在狀態空間中選取采樣點(sigma points) 的方式,代入狀態方程和觀測方程,預測和更新狀態值及其對應的協方差矩陣。
由于計算量的限制,一般不會將全局地圖中的特征空間位置參數加入濾波器狀態變量中,因此基于濾波技術的視覺/慣性組合導航算法通常無法構建全局地圖,不支持閉環檢測與優化。
(2)基于優化技術的信息融合算法
為了實現迭代優化算法框架下的視覺/慣性導航信息融合,必須解決慣性約束和視覺約束的統一表示問題。對于視覺信息,關鍵幀之間的位置和姿態約束可以通過它們共同觀測的圖像特征之間的匹配關系來確立。而對于慣性信息,2個時刻間的位置和姿態約束可以通過2個時刻間的陀螺和加速計測量信息來建立。在視覺/慣性組合導航系統中,當前時刻的關鍵幀位姿參數是在前一時刻關鍵幀的位姿參數基礎上,利用陀螺和加速度計測量值遞推得到。由于關鍵幀的位姿參數屬于迭代優化的狀態變量,在優化過程中,每一次迭代都會改變,所以由前一時刻關鍵幀的位姿參數遞推得到的當前幀的位姿參數,需要重新利用兩幀之間的陀螺和加速度計測量值推算,處理效率非常低。為了避免該問題,需要設計一種不依賴于積分初值的慣性積分增量計算方法,使得在迭代優化過程中,前一時刻關鍵幀位姿參數變化之后,可以根據積分增量快速更新當前時刻的關鍵幀位姿參數。
圖4 基于迭代優化技術的視覺/慣性組合導航示意圖Fig.4 Scheme of visual-inertial integrated navigation based on iterative optimization
慣性預積分技術應運而生[24],其核心思想是定義位置、姿態和速度積分增量,使得積分增量與積分初值無關。從系統的運動學模型式(6)出發,可以得到關鍵幀[ti,tj]時刻間的位姿參數與慣性測量值之間的關系為
(7)
其中,g是重力矢量,η是加速計測量噪聲,n是積分時段內慣性傳感器的采樣個數。從式(7)可以看出,tj時刻關鍵幀的位姿參數與ti時刻關鍵幀的位姿參數以及[ti,tj]時刻間的慣性測量值有關。為了消除ti時刻關鍵幀的位姿參數的影響,定義ti和tj時刻關鍵幀之間的狀態變量增量計算公式如下
(8)
式中,Δtij=tj-ti。從式(8)可以看出,慣性積分增量ΔRij、Δvij、Δpij僅與[ti,tj]時刻間的陀螺測量值ω和加速度計測量值a有關,與積分的初值Ri、vi和pi無關。
通過預積分對慣性信息進行預處理之后,就可以建立統一視覺約束和慣性約束的優化目標函數。以VINS為例,其目標函數具有如下形式[27]
(9)
其中,3個殘差項依次是邊緣化的先驗信息、IMU測量殘差以及視覺的觀測殘差,X是待優化的狀態向量,包含關鍵幀的相機位姿、特征的空間位置、慣性器件的零偏等。
當然,一個完整的視覺/慣性組合導航系統還包含系統初始化、閉環修正與優化等。此處不再贅述,感興趣的讀者可以查閱文獻[25-28]。
3 基于機器學習的視覺/慣性組合導航技術
深度學習神經網絡是機器學習概念的重要分支,具有參數學習與非線性模型擬合的能力,利用深度學習解決組合導航問題,實質上是使用神經網絡對原始數據與導航參數之間的關系進行建模,并通過長時間訓練來優化模型的參數。為了增強深度學習網絡的可解釋性,需對網絡不同功能模塊使用不同種類的網絡進行建模。圖5所示為基于深度學習的視覺/慣性組合導航技術的通用結構示意圖。
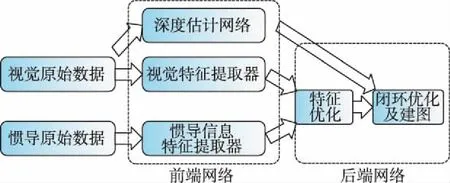
圖5 基于機器學習的視覺/慣性組合導航技術通用結構示意圖Fig.5 Scheme of learning based visual-inertial navigation technology
3.1 前端網絡
(1)視覺特征提取器
與基于模型的組合導航技術類似,基于深度學習的導航技術也存在前端,即處理原始數據的模塊。針對圖像這種高維度的信息,需從中捕獲高層特征來解析相機運動信息。
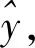
(10)
文獻[33,37]使用單輸入的光流估計網絡 (FlowNetSimple)[34]的卷積層部分搭建視覺特征提取器,并將網絡的輸入層通道數設置為6,接收時間軸上相鄰兩幀的RGB圖像。為了能對相鄰圖像的高層信息進行更充分的解析,文獻[36]使用雙輸入的光流估計網絡(FlowNetCorr)[34]的卷積層部分搭建視覺特征提取器,為前后兩幀圖像分別構建卷積神經網絡,解析2張圖像中的高層特征,并使用correlate操作融合兩幀圖像的高層特征。FlowNetCorr的層數較多,訓練成本較大,因此在基于深度學習的視覺里程計中一般選用FlowNetSimple的卷積層部分搭建視覺特征提取器。上述兩種視覺特征提取器依據成熟的卷積神經網絡進行設計,同時Dosovitskiy 等[34]已公開這兩種卷積神經網絡的預訓練參數,有利于開發基于視覺信息的深度學習導航技術。然而FlowNetCorr與FlowNetSimple都屬于層數較多的卷積神經網絡,參數量較大,其中FlowNetCorr參數占磁盤空間149M,FlowNetSimple占148M,因此這兩種卷積神經網絡不適用于包含深度信息的全導航參數估計算法。針對此問題,文獻[49-50]設計了僅由6層卷積核構成的視覺特征提取器,并且使用均值池化操作將視覺高層特征直接壓縮為6維度的相鄰圖像幀位姿;但較少的層數也導致提取器的解析能力較弱,在深度以及位姿估計任務中的性能也有一定局限性,訓練收斂速度較慢。
(2)慣性信息特征提取器
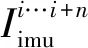
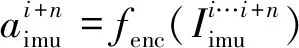
(11)
文獻[36-37]使用慣性信息與圖像的融合特征進行姿態解算,實驗結果表明,添加慣性信息的里程計網絡收斂較快并且測試精度較高。為了進一步提高里程計的解算精度,文獻[37]設計了兩種注意力網絡,注意力網絡輸出與原始數據高層特征同尺寸的權重掩膜,并通過改變特征元素的相對大小,從而調整網絡的訓練方向,規避噪聲特征對網絡性能的影響。文獻[37]的實驗結果表明,基于深度學習的慣導信息特征提取器在多種慣導信息噪聲的環境下也具有較為穩定的性能。然而由于深度學習神經網絡參數對于訓練數據具有一定的依賴性,對于不同場景數據的泛化能力較差,這限制了基于深度學習的特征提取器的應用范圍。文獻[52]使用遷移學習的方法,找到不同場景中慣導數據的共有特征并結合其物理模型,在沒有標簽數據的情況下,利用低精度的手持設備數據也能得到精度較高的位姿解算結果。
原始數據的高層特征,需使用位姿回歸器將高層特征投影至標簽空間中。常見的位姿回歸器由多層全連接層組成,全連接層的輸出通道數與位姿估計值的形式有關。現階段基于深度學習的視覺里程計都采用歐拉角來表示姿態,因此一般將位姿回歸器中最后一層的全連接層設置為6[33,37],也可以將位姿回歸的過程解耦,分別設置3維度的位置回歸器與姿態回歸器。
(3)深度估計網絡
除了提取原始數據的特征以外,前端還需給出當前視角內特征點的深度信息。基于模型的視覺/慣性組合導航技術使用多視覺幾何模型聯合相鄰幀圖像的匹配特征點,求得相對位姿以及無尺度的特征點深度值。然而,在紋理缺失以及光線較暗的部分,特征點識別算法失效導致無法得到較為準確的深度值。深度學習神經網絡通過前向傳播直接得到原始圖像像素點對應的深度值,同時設計具有幾何約束的誤差項來校正神經網絡參數,從而提高深度估計的精度。文獻[50,55-56]構建了類U-NET的深度估計網絡,使用多層卷積神經網絡構建特征提取器,其中文獻[54-55]使用主流的PackNet和ResNet網絡作為特征提取器,在訓練前使用預訓練參數進行初始化,便于訓練的收斂;隨后使用深度解碼器將特征提取器解析的圖像高層特征變為與原圖尺寸一致的深度估計值,深度解碼器由多層反卷積層構成,同時將特征提取器輸出圖像的不同層次的特征輸入到深度解碼器對應的反卷積層中,強化深度估計圖像的多尺度細節。為了提高深度估計網絡的性能,現有兩種思路:1)改進網絡的結構,例如將網絡的高低特征聯結[50,55-56],增強輸出的深度圖像質量;2)在設計誤差函數時添加約束條件,例如文獻[55]引入時空最小誤差,剔除在連續兩幀圖像中因相機旋轉而移出視場范圍的像素點,避免了在計算重投影誤差時出現局部異常極大值的現象;文獻[56]則在總誤差中引入極線誤差,使得網絡能夠充分利用相鄰幀的點線特征,從而增強網絡性能。
3.2 特征優化
特征優化環節對應基于模型的視覺/慣性組合導航技術中的非線性優化模塊,該模塊利用前端提取的低層特征以及里程計估計的位姿參數構建幾何誤差函數,使用特定的非線性優化算法降低誤差函數值,以此得到優化的導航參數。同樣地,特征優化環節也設計了特定的網絡來優化前端網絡得到的數據特征或者導航參數估計值。
借鑒傳統SLAM窗口優化的思想,文獻[33,36-37]在視覺特征提取器的最后一層卷積層中添加LSTM網絡,以綜合前后多幀原始數據的高層特征,優化當前時刻的高層特征。上述過程如式(12)所示,其中flstm的每一時刻都引出隱藏變量,使得經優化的特征與未優化特征的尺寸保持一致。
(12)
同時LSTM網絡采用多層次級聯設計,并添加多個節點以增加網絡的解析能力。然而,此類算法屬于端對端優化算法,不具有可解釋性。為了能在優化原始數據高層特征的過程中考慮到幾何模型的因素,文獻[49-50,53-55]在總誤差中設計了重投影誤差,耦合了深度估計網絡與位姿估計網絡參數的優化過程。然而,以上工作都僅將重投影模型體現在總誤差函數中,沒有構建顯示的網絡結構對重投影模型進行求解,網絡設計依舊欠缺一定的可解釋性,因此很難確定網絡是否擬合出了圖像像素值、深度與相對位姿之間存在的重投影模型;同時從以上文獻的算法性能驗證實驗可以看出,以上算法相對于端對端的里程計或者深度估計網絡的性能并沒有顯著的提升,這從另一個側面說明了以上算法在構建網絡時并沒有充分利用重投影模型原理。鑒于此,Tang 等[57]構建了可微重投影約束層(BA-Layer),對重投影模型的每個參數進行顯示建模,從而對輸出的導航參數進行優化。分別設計了基礎深度生成網絡以及多尺度特征提取網絡,將時間上相鄰的一組圖像代入基礎深度生成網絡得到每一幀圖像的深度圖像族,并使用與深度圖像族對應的可微系數,將深度圖像族加權組合為深度估計值圖像;同時使用多尺度特征提取網絡得到圖像幀的高層特征,隨后構建特征級的重投影誤差,并代入BA-Layer層中進行優化。BA-Layer層根據前一時刻的狀態優化量計算雅克比矩陣、正規方程、阻尼系數以及海森矩陣,進而得到狀態量的變化量,從而得到當前時刻的狀態優化量。為了確保BA-Layer層的可微性,固定了特征級重投影誤差的優化步數,同時使用多層全連接層將特征級重投影誤差轉化為阻尼系數。從實驗結果來看,相比于使用光度重投影誤差與幾何重投影誤差的位姿估計方法,該文設計的相對位姿估計網絡的旋轉角與平移矢量測試精度更高。首先,這說明BA-Layer能對重投影誤差進行有效建模。其次,文獻提到使用幾何重投影誤差的位姿估計方法在室內環境中可能無法進行有效的特征匹配,光度重投影誤差則會增加優化函數的非凸性,導致優化算法對初值設置較為敏感。相比較而言,BA-Layer使用經卷積神經網絡解析的高層特征進行導航參數的求解,相比于特征點、光流等底層特征,高層特征具有較高的穩定性,因此算法的魯棒性較好。此外,卷積神經網絡具有較強的非線性擬合能力,可以在訓練過程中對狀態初值進行隱式估計,不需要人為指定。
Chen等[58]則提出了一種基于深度學習的卡爾曼濾波算法DynaNet。該算法首先假設視覺/慣性組合里程計是一個馬爾科夫過程,即當前時刻的狀態量與前一時刻的狀態量有關,并且能用線性模型來描述狀態傳遞過程。DynaNet算法使用LSTM網絡估計狀態傳遞矩陣以及協方差傳遞誤差,并使用卷積神經網絡得到視覺/慣性原始數據的高層特征以及測量誤差;隨后構建卡爾曼濾波方程,經過迭代得到當前時刻的狀態量估計值;最后結合狀態量的標簽值構建訓練誤差,經過多輪訓練得到精度更高的狀態量估計值。相比于Tang 等的工作,DynaNet使用深度學習神經網絡重構線性卡爾曼濾波方程,但鑒于深度學習具有強大的非線性擬合能力,DynaNet的狀態傳遞矩陣估計網絡也能對位姿求解過程進行建模。從實驗結果來看,DynaNet的位姿解算精度高于基于模型的ORB-SLAM[12]以及基于深度學習的VO-Feat[50],這證明了經過精心設計的深度學習網絡具有超越基于模型的導航算法的能力;同時也說明了使用深度學習重構傳統卡爾曼濾波模型能有效提升深度學習框架求解位姿問題的能力。
3.3 閉環優化與建圖
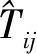
(13)
在得到經過優化的絕對位姿之后,需結合關鍵幀的深度信息構建全局的三維立體模型,然而基于重投影誤差估計的關鍵幀深度值不具有全局一致的尺度,因此還需設計更多的幾何約束使得網絡在長時間的訓練過程中逐漸恢復關鍵幀的尺度。Guizilini 等[54]提出了在訓練誤差函數中添加訓練數據集中的速度標簽,使得相對位姿估計網絡輸出的相對平移量具有與標簽值一致的尺度。Bian 等[61]則使用深度估計網絡同時估計參考幀與目標幀的深度,隨后使用匹配特征點對應的空間點坐標構建投影誤差。
4 視覺/慣性組合導航技術的典型應用及發展趨勢
視覺/慣性組合導航技術是機器人、計算機視覺、導航等領域的研究熱點,在國民經濟和國防建設中取得了廣泛的應用,但也面臨著諸多挑戰。
4.1 視覺/慣性組合導航技術的典型應用
國民經濟領域,在無人機、無人車、機器人、現實增強、高精度地圖等應用的推動下,視覺/慣性組合導航技術取得了快速發展。例如Google的Tango項目和無人車項目、微軟的Hololens項目、蘋果的ARKit項目、百度無人車項目、大疆無人機項目、高德高精度地圖項目等大型應用項目都成立了視覺/慣性組合導航技術相關的研究小組,極大地促進了視覺/慣性組合導航技術在國民經濟中的應用。以Google的Tango項目為例,其導航定位核心算法是基于濾波框架的MSCKF算法;微軟的Hololens項目則是以KinectFusion為基礎的SLAM算法。
國防建設領域,由于視覺/慣性組合導航技術不依賴外部人造實施,在衛星拒止環境中有著重要的應用價值。例如美國陸軍研發的一種新型聯合精確空投系統采用慣性/視覺組合導航技術解決高精度定位問題。嫦娥三號巡視器也采用視覺與慣性組合實現定姿定位。李豐陽等[62]總結了視覺/慣性組合導航技術在地面、空中、水下和深空等多種場景中的應用。
4.2 視覺/慣性組合導航技術的未來發展趨勢
視覺/慣性組合導航技術取得了廣泛的應用,但在復雜條件下的可靠性還有待加強,其未來的發展主要體現在以下4個方向:
1)提升信息源的質量。首先是提升慣性器件(特別是基于微機電系統(Micro-Electro-Mecha-nical System,MEMS)工藝的微慣性器件)的零偏穩定性和環境適應性等性能指標;其次是提升視覺傳感器的光照動態適應性、快速運動適應性等性能指標;此外,還可以引入更多的傳感器,如磁傳感器、超聲波傳感器、激光雷達等,提升復雜條件下組合導航系統的綜合性能。
2)提升信息融合算法的水平。視覺和慣性信息各有特點,不同條件下信息的質量也不盡相同,需要設計智能的信息融合機制。目前的算法大多是基于靜態場景假設,但在實際應用中,場景都有一定的動態性,動態環境下的視覺/慣性組合導航是提升復雜條件下導航可靠性的重要研究方向。此外,目前基于濾波的信息融合算法仍然存在濾波狀態發散或者狀態收斂到錯誤值的情況,需要對系統的可觀性進行分析,提升狀態估計的一致性。對于優化框架的信息融合算法,目前的預積分理論還有待完善,特別是在SLAM的地圖管理中刪除關鍵幀時,與關鍵幀相關的積分增量及對應的協方差需要合并,目前還缺乏協方差合并方法;而且基于BA的優化算法計算量較大,對于大尺度的閉環優化,計算耗時太久,存在錯失閉環優化的情況,急需提升BA算法的效率。
3)發展新的導航理論。大自然中許多動物具有驚人的導航本領,例如:北極燕鷗每年往返于相距數萬km遠的南北兩極地區;信鴿能夠在距離飼養巢穴數百km遠的地方順利返回巢穴。模仿和借鑒動物導航本領的仿生導航技術逐漸成為了導航領域研究的熱點。胡小平等[63]對仿生導航技術進行了全面的總結。此外,隨著多平臺集群應用的普及,利用組網編隊中平臺間導航信息交互來提升位置、速度、姿態等參數估計精度的協同導航技術方興未艾。謝啟龍等[64]從無人機、機器人、無人水下潛航器、導彈4個應用層面梳理了協同導航技術的國內外發展現狀。
4)擴充導航系統的功能。目前的視覺/慣性組合導航側重于導航參數的估計,對于引導和控制等關注較少。隨著機器學習技術在視覺/慣性組合導航領域的應用,可以將機器學習在環境理解、避障檢測、引導控制等方面的成果融入到導航系統中。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
