EWT-GG聚類的核電廠軸承故障診斷方法研究
2020-07-27 08:26:14王志超夏虹朱少民彭彬森
哈爾濱工程大學學報 2020年6期
王志超, 夏虹, 朱少民, 彭彬森
(哈爾濱工程大學 核安全與仿真技術國防重點學科實驗室,黑龍江 哈爾濱 150001)
滾動軸承作為主要旋轉元件,廣泛存在于核電廠的各類泵機、電機、壓縮機以及汽輪機等大型機械設備中,其運行狀態直接影響設備性能,當復雜的運行環境導致軸承出現故障時,可能引起整個系統設備的失效。據統計,旋轉設備的故障中30%以上源于軸承故障[1],因此軸承部件故障診斷的方法研究,對提高核電廠設備狀態監測精確度,增強核電廠運行安全性具有重要意義。
滾動軸承振動信號一般具有非平穩特性,直接對原始信號進行故障診斷是比較困難的。文獻[2]采用包絡譜分析技術對CPR1000核電廠泵組軸承故障進行了分析,但是文中軸承振動烈度閾值不具有普適性。文獻[3]基于能量解調算法,研究了一種應用于核電廠故障診斷的方法。國外也有學者將遞歸神經網絡應用于核電廠旋轉機械的狀態監測[4],但是文獻[5]指出神經網絡結構的選擇過分依賴于先驗知識或經驗。相比之下,將振動監測信號處理與機器學習算法相結合的旋轉機械故障診斷方法,已成為近年來設備故障診斷的研究熱點。其中,基于EMD、ITD、VMD的信號處理方法同樣得到了廣泛關注,眾多學者也根據其局限性作出相應的改進[6-9]。
本文基于EWT的信號分解方法,將軸承振動信號分解為各階AM-FM分量,通過K-L散度值篩選出包含原始信號故障特征的主分量,并結合樣本熵及LZ復雜度的特征提取技術,采用GG聚類算法對旋轉機械軸承進行故障診斷。實驗測試分別與基于FCM、GK聚類以及基于EMD的信號分解方法作比較,從而驗證了該方法能對旋轉設備軸承的不同故障進行精確有效識別的優勢。
1 信號預處理及主分量提取方法
1.1 經驗小波變換原理
基于EMD自適應分解思想,Gilles[10]對小波理論做出改進,提出了EWT的多分量信號分解方法。EWT信號分解的效果關鍵在于對Fourier頻譜的分割方式,一般采用基于頻譜極大值的邊界檢測方法,即若將信號頻譜劃分為N+1個連續區間,則先找到信號頻譜的前N-2個最大的極大值點,再將邊界集定義為相鄰2個極大值點的中點或者最小值點。
然而旋轉設備的軸承振動信號頻譜較為雜亂,往往前幾個最大的極大值集中在一個頻率峰群,導致根據頻譜極大值的方法分解效果較差。因此本文應用一種基于給定初始邊界的自適應邊界檢測方法,該方法首先根據信號頻譜給出N個初始邊界集,然后檢測出每個邊界各鄰域內的最小值作為新的邊界集。其中檢測的鄰域范圍是初始相鄰邊界距離的一半,從而避免了新邊界出現混疊現象。該方法不僅能根據信號頻譜特性進行分解,而且克服了檢測邊界過于集中的問題。因此針對旋轉設備的振動信號,EWT具體實現步驟如下:
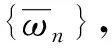
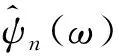
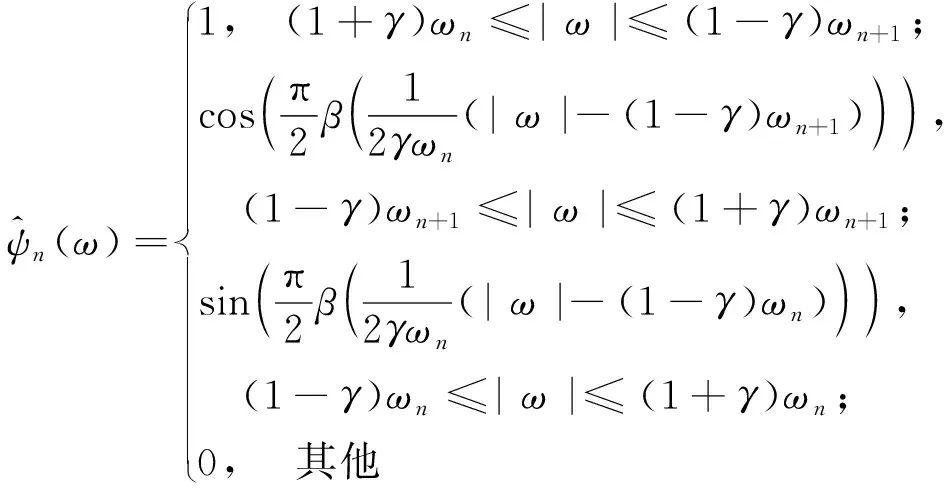
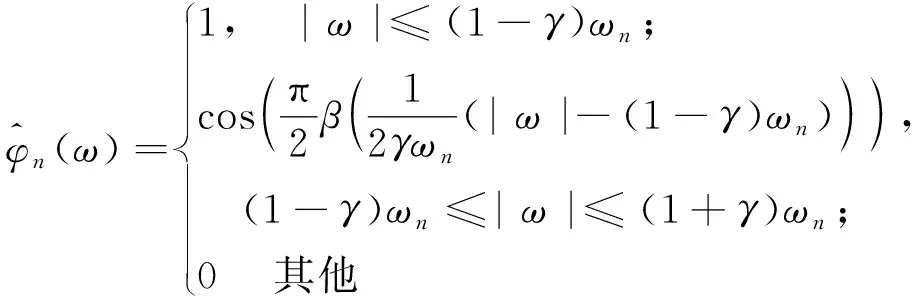
式中β(x)和γ表達式為:
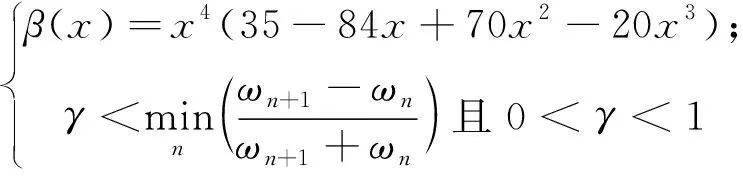
3) 根據傳統小波變換定義方法,將信號與經驗小波函數內積產生細節系數,同時信號與經驗尺度函數內積產生近似系數;
4) 再由細節系數、近似系數與經驗小波函數、經驗尺度函數的卷積即可得到各AM-FM分量。
自適應邊界檢測方法的EWT能夠較好分解出多個分辨率的信號分量,但是需要指出,初始邊界集可以根據信號各頻率峰群給定,同時也可以類似文獻[11]將相鄰極大值間的極小值作為初始邊界集。
1.2 基于K-L散度的主AM-FM分量提取
信號經過EWT分解處理后,得到包含不同頻段的AM-FM分量,有些分量包含信號的固有信息,能夠較大程度上代表原始信號,但是其余分量則不能反映原始信號特征或者直接是噪聲干擾,因此有必要從各AM-FM分量中選出原始信號較多特征的主AM-FM分量,從而提高旋轉設備的故障診斷精度。本文應用K-L散度來篩選EWT分解的主AM-FM分量,K-L散度也被稱為相對熵,是信息論中較為重要的概念,用來度量2個概率分布間的差異程度[12]。在本文的主AM-FM分量篩選中,與原信號K-L散度越小,則分量對原信號的近似度越強,反之,則與原信號相似度越小。K-L散度理論計算步驟如下:
1) 首先采取非參數估計法計算各分量概率分布:

得到信號x=(x1,x2,…,xn)的概率分布p(x),以及信號y=(y1,y2,…,yn)的概率分布q(x),其中平滑參數h是給定的正數,k(u)為高斯核函數。
2) 根據2個信號的概率分布分別計算其K-L散度值,其中p(x)與q(x)的K-L距離為:
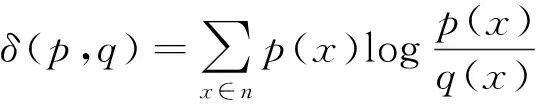
由于δ(p,q)≠δ(q,p),無法滿足距離的概念,故應用定義的p(x)及q(x)的K-L散度值來定量衡量其差異:
D(p,q)=δ(p,q)+δ(q,p) (6)
2 基于EWT-GG聚類的故障診斷方法
2.1 特征提取方法
對于由K-L散度篩選得到的主AM-FM分量,為較完備地獲取其特征,選用基于樣本熵及LZ復雜度的特征提取方法,組成二維矩陣進行聚類分析,從而提高聚類性能。
2.1.1 樣本熵
樣本熵是由Richman提出的一種度量時間序列復雜性的方法[13]。對于n個數據點組成時間序列x={x(1),x(2),…,x(n)},其樣本熵計算步驟如下:
1) 構造一個m維向量Xm={Xm(1),Xm(2),…,Xm(n-m+1)},其中Xm(i)={x(i),x(i+1),…,x(i+m-1)}。
2) 定義Xm(i)與Xm(j)的距離D[Xm(i),Xm(j)]為2個向量中元素最大差值的絕對值,即:
D[Xm(i),Xm(j)]=max[|x(i+k)-x(j+k)|] (7)
3) 給定閾值r,統計每個向量距離值小于r的數目,計作Bi,并計算Bm(r),其表達式為:
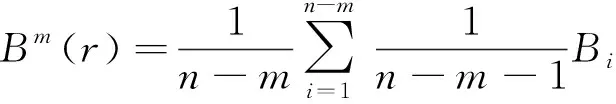
4) 將維數增加至m+1,統計每個向量距離值小于r的數目,計作Ai,并計算相應的Am(r)。從而得到了2個序列在相似容限r下匹配m個點的概率Bm(r),以及匹配m+1個點的概率Am(r)。則樣本熵的定義為:
SampEn(m,r)=-ln[Am(r)/Bm(r)] (9)
可以看出,樣本熵與m、r取值有關,本文依據Pincus研究結果[14],取m=2,r=0.2EStd,其中EStd為原始數據x(i)的標準差。
2.1.2 Lempel-Ziv復雜度
Lempel-Ziv復雜度算法由Lempel及Ziv給出,是一種時間序列復雜度分析方法[15]。在計算LZ復雜度之前,首先將信號轉化為二值符號序列,將序列中大于平均值的點賦值為1,而小于平均值的點賦值為0。
對于二值符號序列S(s1,s2,sn),在循環之前初始化字符變量P0、Q0為空字符,復雜度C(i)=0;隨后,分別將Pt-1、Qt-1與si連接成為新的字符串Pi、Qi;判斷若Qi為Pi-1的子字符串,則表示暫時未出現新模式,復雜度C(i)保持不變,反之復雜度值加1;最后循環遍歷n次后,將C(n)歸一化得到C,即為該時間序列的LZ復雜度,其歸一化表達式為[16]:
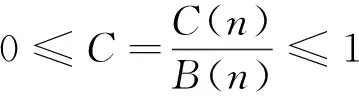
其中,B(n)為C(n)的上限,其表達式為:
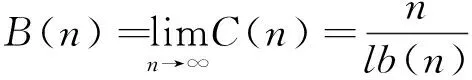
2.2 GG模糊聚類
選用GG模糊分類算法對旋轉機械振動信號的特征向量進行分析,該聚類算法引入基于模糊最大似然估計的距離測度,適用于非規則分布的數據分析,從而提高聚類性能[17],算法具體步驟如下:
1) 假定聚類樣本為X={x1,x2,…,xn},其中每個樣本xj(1≤j≤n)包含d個特征屬性,即xi=(xi1,xi2,…,xid),對樣本X初始劃分為c類。設每個聚類中心的向量為V={v1,v2,…,vc},且隸屬度矩陣為U=[μij]c×n,其中μij∈[0,1]表示第j個樣本對第i類的隸屬度;
2) 設定迭代的終止容限ε,有ε>0,并隨機初始化隸屬度矩陣U;
3) 計算聚類中心:
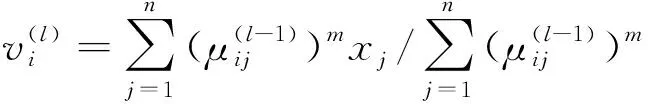
4) 計算各樣本與類的模糊最大似然估計距離:
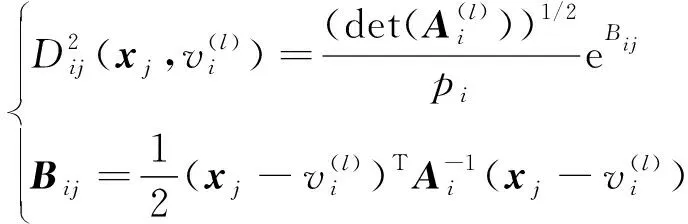
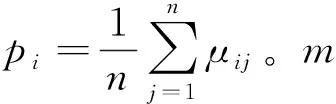
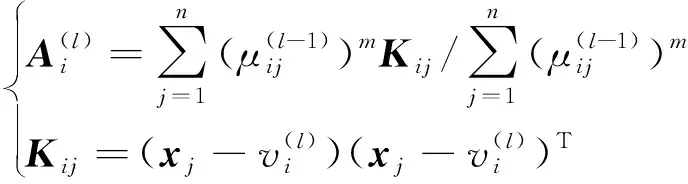
5) 更新隸屬度矩陣U:

判斷條件‖U(l)-U(l-1)‖<ε是否滿足,如果滿足,則終止迭代計算,否則令l=l+1。重復執行迭代V及U,直到滿足條件,使目標函數J取得最小值:
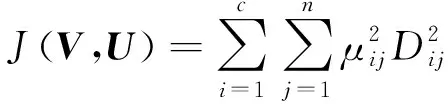
2.3 基于EWT-GG聚類的多分量故障診斷方法
采用Gath-Geva聚類的方法建立基于信息論及復雜度特征的軸承故障診斷模型,以便更加準確高效地識別故障類型,其故障診斷流程圖如圖1所示。
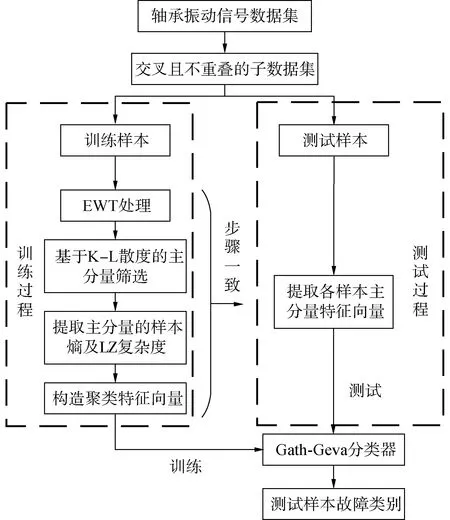
圖1 基于EWT-GG聚類的軸承故障診斷方法Fig.1 Bearing fault diagnosis method based on EWT-GG clustering
本文故障診斷方法主要有以下幾個步驟:
1) 首先采集軸承正常及一些常見故障下的振動信號,將其分為訓練及測試樣本集。對各樣本集序列分別應用EWT進行分解,得到各頻段的AM-FM分量;
2) 對每個分量進行基于K-L散度的主AM-FM分量篩選,得到的主分量與原始信號相似度最高。對主分量采用基于信息論及復雜度的特征提取方法,得到二維特征向量空間,從而完備地提取主分量的特征;
3) 采用GG聚類算法對訓練樣本的特征向量進行聚類,以此識別不同的軸承運行工況。同時,采用分類系數PC以及平均模糊熵CE對GG聚類的分類性能進行對比評價:
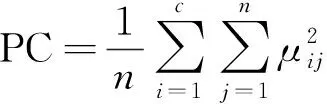
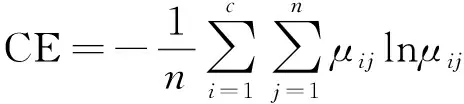
4) 計算測試樣本特征向量與步驟3)GG聚類中心的歐式貼近度E(Ck,T):
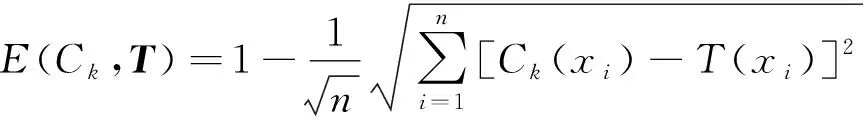
其中Ck為第k個狀態,T為測試樣本特征向量,元素x={x1,x2,…,xn}。
5) 依據擇近原則進行判斷,貼近度最大則表明為同一類運行狀態,從而實現了對旋轉設備軸承振動信號的故障診斷。
3 軸承故障診斷實例分析
本文針對核電廠旋轉機械軸承進行常見故障診斷方法研究,提高核電廠設備監測及診斷精確度。采用美國Case Western Reserve University電氣工程實驗室的滾動軸承實驗數據,該軸承為SKF軸承,實驗采用電火花技術加工軸承內圈、外圈以及滾動體單點故障,實驗裝置如圖2所示。采用的軸承數據樣本集分為軸承正常、內圈故障、外圈故障以及滾動體故障4種類型,如圖3所示,損傷直徑為0.177 8 mm,損傷深度為0.279 4 mm,軸承轉速為1 797 r/min,采樣頻率為12 kHz。
3.1 主分量的選取
將正常、內圈、外圈以及滾動體故障樣本數據分別分割為40組子樣本集,樣本長度為3 000,即0.25 s內軸承振動信號,并且交叉選取20組作為訓練樣本、剩余20組作為測試樣本。首先對各訓練樣本進行EWT處理,得到各階AM-FM分量,并計算其與原始信號K-L散度值以進行主分量篩選。為了對比篩選標準,本文計算分量與原始信號的相關系數。以內圈故障信號為例,將第1組訓練樣本經EWT分解,得到5個分量時頻域結果如圖4所示。
由圖4可以看出,內圈故障的第1組訓練數據經EWT分解后,得到的5個分量在時域上出現規律的周期成分,頻域沒有出現模式混疊現象,從而極大提高了后續故障診斷的精確度。接著把得到的5個分量選取K-L散度及相關性系數評價每種分量代替原始信號的程度,其歸一化計算結果如表1。
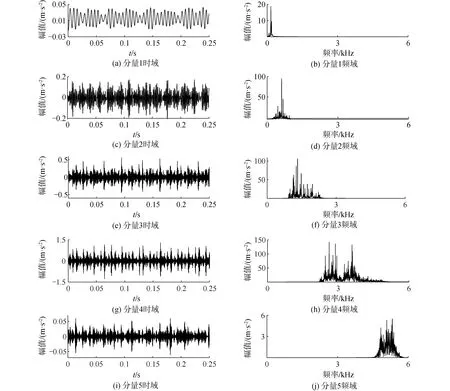
圖4 內圈信號EWT分解Fig.4 EWT decomposition of inner ring signal
由表1可以看出,分量4與原始信號的K-L散度較小,說明其與原始信號的關聯性較大,能較大程度上代表原始信號,從而將分量1、分量2、分量3、分量5視為虛假分量濾除。同時,雖然分量4的相關性系數最大,但與分量2、分量3同屬一個數量級,在后續篩選中易與虛假分量混淆。因此,本文采用基于K-L散度的主AM-FM分量篩選標準,可以更加準確識別虛假分量,提高后續GG聚類識別率。

表1 內圈故障信號分量篩選標準Table 1 Selecting criteria of inner ring fault signal components
3.2 模糊聚類算法對比測試
對于由K-L散度篩選的80組主分量訓練樣本數據,分別選用樣本熵以及LZ復雜度進行特征提取,以便于完備地提取分量特征,同時將組成的二維特征向量作為輸入,進行聚類分析。在GG聚類中,設定聚類中心數目為4,加權指數m為2,迭代終止容限設定為,得到的GG聚類結果如圖5(a)所示。
由圖5可以看出,GG聚類算法將特征向量分為4類,其中黑色的“O”代表聚類中心,其具體坐標如表2所示。各聚類簇較集中于聚類中心,簇之間沒有重疊部分,且等高線邊界劃分具有較大分類間隔。因此應用K-L散度提取信號主分量,并利用樣本熵以及LZ復雜度作為特征向量進行GG聚類分析,極大地提高了聚類效果以及故障診斷精確度。
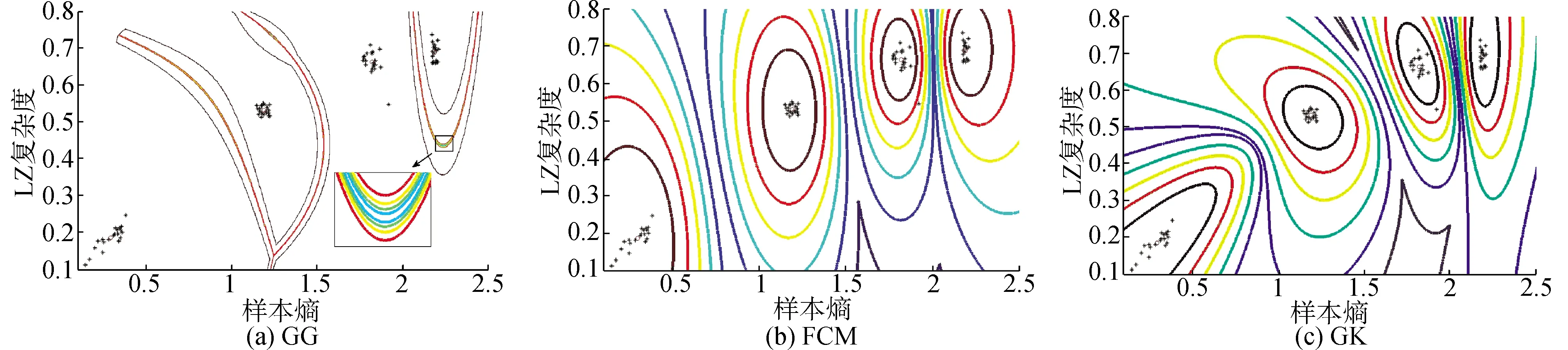
圖5 GG、FCM、GK聚類等高線Fig.5 Contour map of GG, FCM, GK clustering
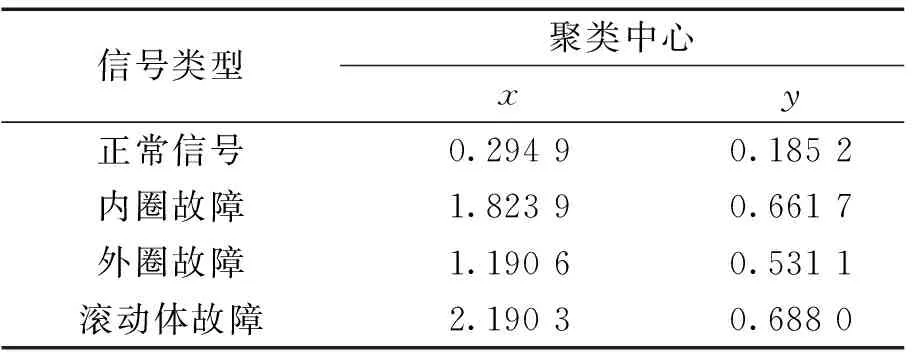
表2 4類信號的GG聚類中心Table 2 GG clustering centers of the four types signals
同時為了驗證GG聚類算法中,采用基于模糊最大似然估計距離的優越性,本文應用FCM聚類以及GK聚類算法對同樣的特征向量進行分析,得到的聚類效果如圖5(b)、(c)所示。
由圖5(b)、(c)可以看出,各聚類算法的聚類中心相較于GG聚類差別不大,但是GG聚類算法具有最大化分類間隔,其聚類等高線為任意形狀,但是FCM聚類以及GK聚類等高線形狀分別近似圓形以及橢圓形,表明GG聚類對數據分別最為自適應,能夠區分任意分布的特征向量,而FCM聚類以及GK聚類算法僅對于圓形及橢圓形分布的特征向量具有較好的分析效果。
同時計算3種聚類算法的分類系數PC以及平均模糊熵CE以對其分類性能進行定量評價,其中分類系數越接近1,聚類效果越好,平均模糊熵越接近0,聚類效果越好。計算結果如表3所示,可以看出,作為FCM算法的改進,GK聚類算法的分類性能優于FCM聚類,但是GG聚類算法的分類系數最高,達到了最好的分類效果,并且其平均模糊熵最低,說明該算法對4類故障信號的聚類效果最優。
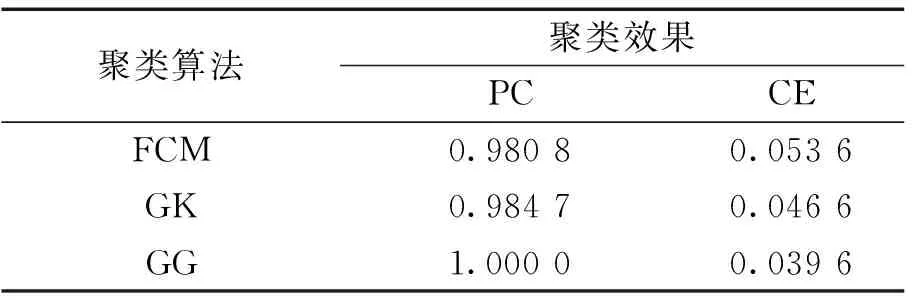
表3 3種聚類算法效果定量分析Table 3 Quantitative analysis of three clusterings
3.3 信號分解方法對比測試
為進一步分析基于EWT信號分解方法的優越性,本文將信號分解方法替換為經驗模態分析(EMD)進行對比測試。同樣以內圈故障信號為例,將第1組訓練樣本經EMD分解,得到10個分量,其中前5階分量時頻域結果如圖6所示。
由圖6可以看出,EMD處理得到的前5階內圈信號分量頻率由高到低依次排列,其中第1階分量頻率最高。相比于圖4的EWT內圈信號分解圖,第1階分量所包含的頻域較廣,出現了較嚴重的模態混疊現象,不利于故障特征提取。后續故障診斷的其他流程不變,將訓練樣本應用GG聚類進行分析,得到的EMD-GG聚類結果如圖7所示。
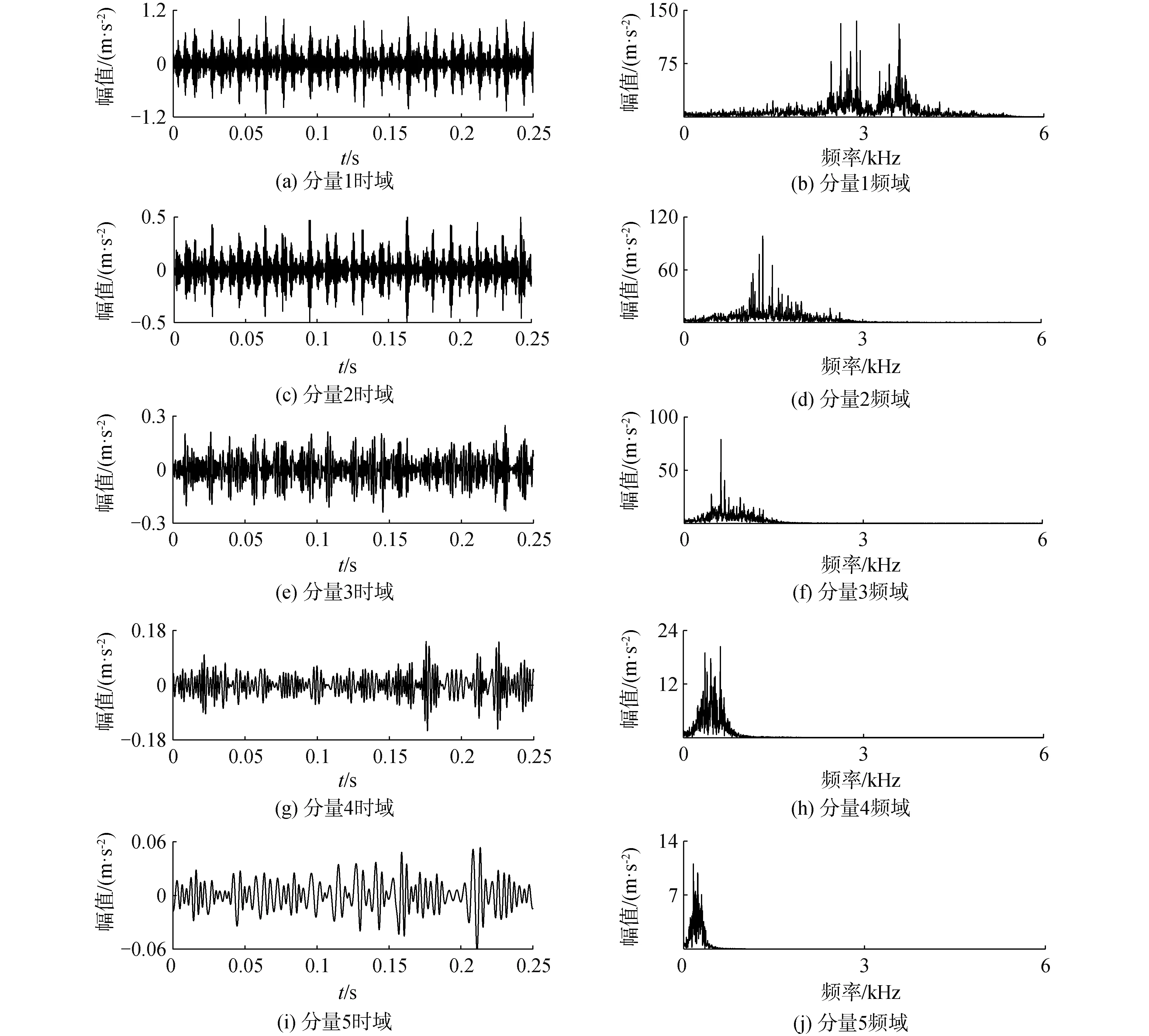
圖6 內圈信號EMD分解Fig.6 EMD decomposition of inner ring signal
由圖7可以看出,采用GG聚類方法具有較大的分類邊界距離,但是EMD方法容易產生模態混疊現象,且受到虛假成分干擾較大,不能很好地分解出原始信號的主分量,導致聚類簇較為分散,不便于聚類邊界的劃分。再利用訓練完畢的2種聚類器,計算EWT-GG聚類以及EMD-GG聚類的測試樣本歐式貼近度,分別得到4類各20組測試樣本的歐式貼近度,如圖8,每類樣本4種圖柱代表相對于4個聚類中心的平均歐式貼近度。
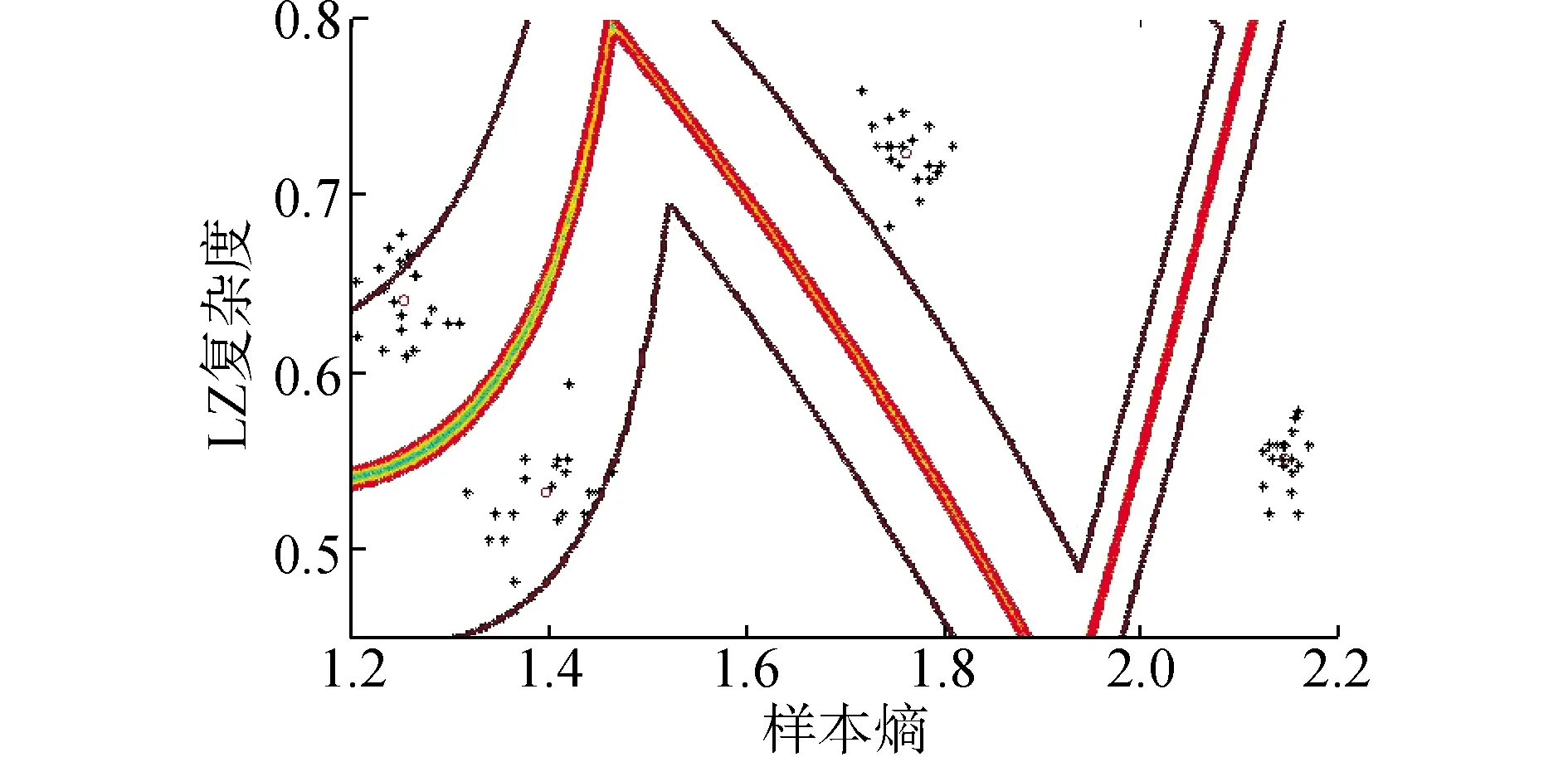
圖7 EMD-GG聚類等高線Fig.7 Contour map of EMD-GG clustering
由圖8(a)可知,基于EWT-GG方法的測試樣本與聚類中心的最大歐式貼近度更接近于1,且相對于其他聚類中心具有明顯的區分度,便于測試樣本的故障診斷;而在圖8(b)中,基于EMD-GG方法的最大歐式貼近度較小一些,同時正常與外圈故障樣本的貼近度較為接近,不利于故障的識別。因此,本文方法在更加準確地提取出信號特征的同時,還能提高故障診斷精度。
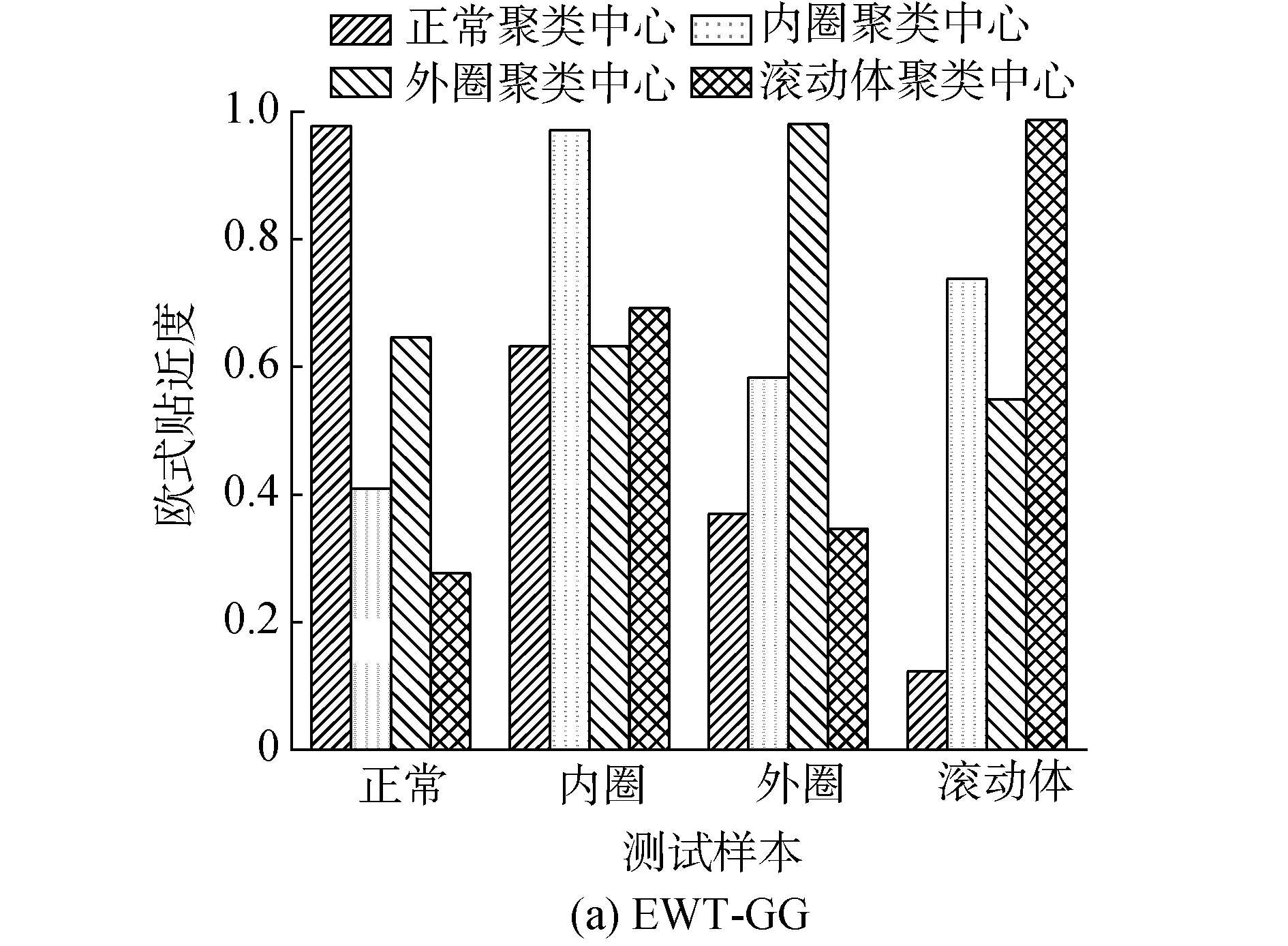
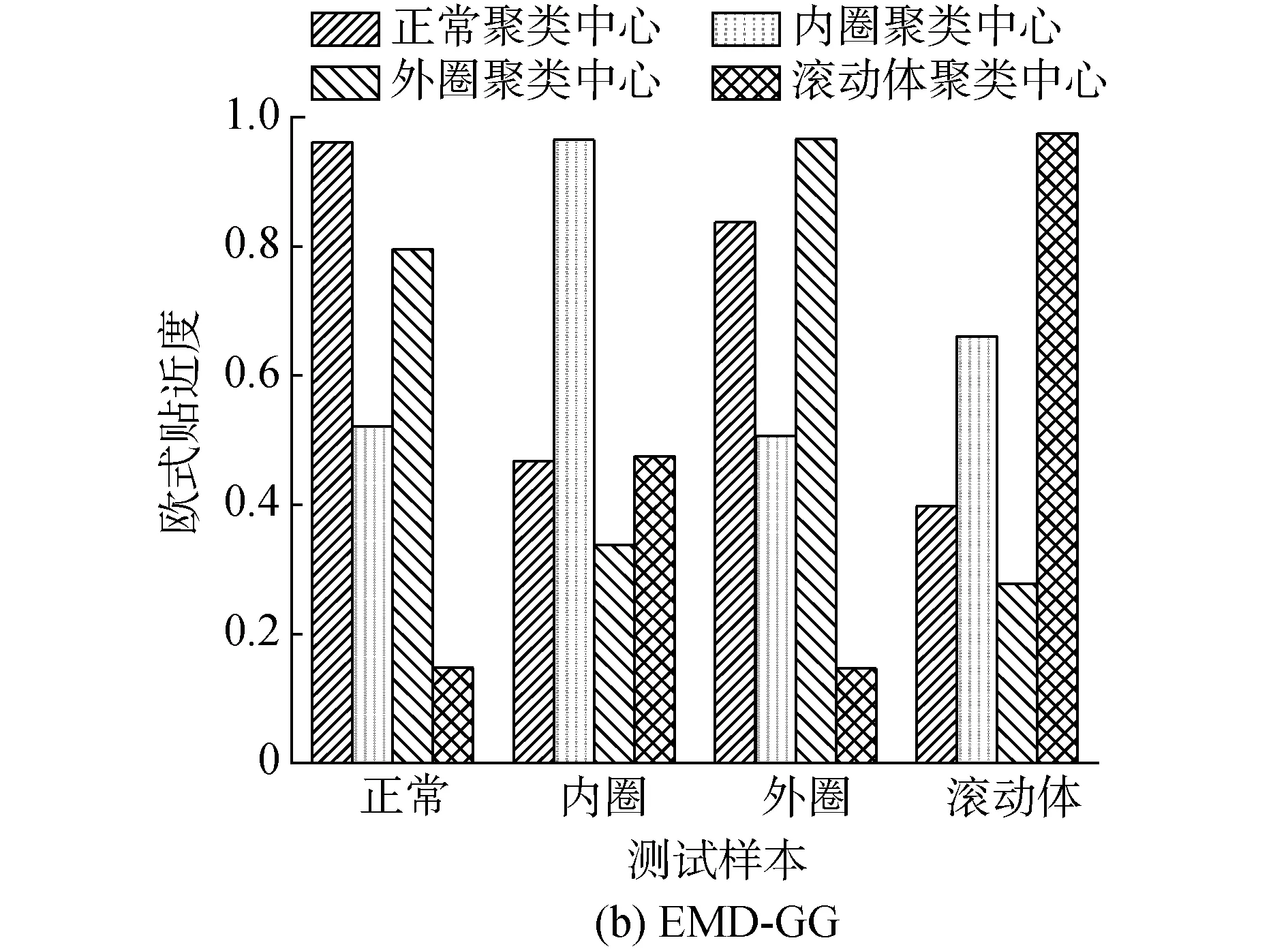
圖8 EWT-GG及EMD-GG聚類方法Fig.8 EWT-GG and EMD-GG clustering
4 結論
1)應用EWT的信號分解方法能極大抑制模態混疊現象,相比于EMD更適合非平穩信號分析。
2)采用K-L散度篩選出信號的主AM-FM分量,能較好地獲取信號主要特征,便于提高后續故障診斷效率。
3)GG聚類對軸承常見故障診斷的分類性能優于其他模糊聚類算法,最后應用歐式貼近度進行故障識別,診斷過程簡單且高效。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
電子制作(2018年11期)2018-08-04 03:25:42
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
