我國食品安全與數據科學交叉研究的科學計量學分析
2020-07-23 04:23:34宋英華李墨瀟雷生姣庫任俊夏亞瓊
食品科學 2020年13期
邵 航,宋英華,*,李墨瀟,*,邵 偉,雷生姣,庫任俊,夏亞瓊
(1.武漢理工大學中國應急管理研究中心,湖北 武漢 430070;2.安全預警與應急聯動技術湖北省協同創新中心,湖北 武漢 430070;3.武漢理工大學安全科學與應急管理學院,湖北 武漢 430070;4.三峽大學生物與制藥學院,湖北 宜昌 443001)
食品安全關系人民群眾身體健康和生命安全,關系中華民族未來[1]。以食品安全突發事件為研究對象,深入開展演化機理、檢測技術和預警方法等方面的研究,能夠幫助政府及時采取有利的措施,預防食品安全問題的再次發生,已經得到黨和國家的高度重視[2]。
數據科學是基于傳統的數學、統計學的理論和方法,運用計算機技術進行大規模數據計算、分析和應用的一門學科[3]。它是一門既古老又年輕的科學,其淵源可以追溯至1749年起源于瑞典的統計學[4];隨著計算機技術的發展與大數據概念的興起,數據科學又逐漸成為大數據技術的代名詞。大數據時代的到來使得數據科學逐步演變成了一門“立足現代、面向未來”的顯學;而公共安全領域對大數據挖掘與利用的迫切需求加劇了全社會對數據科學人才的需要;同時,這種社會需求導向又反向顯著地提升了數據科學在公共安全各個子領域中的學科地位。
隨著社會信息化程度的提升與信息儲存方式的變革,食品生產與消費的各個環節已經積累了海量異構的食品安全歷史數據,且仍在源源不斷地產生著新的食品安全大數據。在大數據時代的背景下,大數據技術方法相比起傳統的研究方法,在處理海量的食品安全數據時顯得更加對口和有效。
已發表的科技論文是經過同行評議,且其主題被認為是隸屬于該領域的論文[5]。因此,從已發表的學術論文中識別并探測某一特定研究主題是被實踐證明的可靠方法[5]。基于此種假設,本文選取中國知網(China National Knowledge Infrastructure,CNKI)數據庫中食品安全研究與數據科學存在交集的科技文獻作為我國食品安全與數據科學交叉研究的樣本數據集,運用科學計量學理論,主要使用科技文本挖掘軟件Citespace對文獻數據進行深度挖掘。
本文將從所收集的文獻數據的特征出發,開展本交叉研究的研究主體分析與研究主題分析,以期從文獻數據空間中發現本領域重要的研究機構、期刊和作者,并進一步地發現本領域當前的研究熱點與未來的發展趨勢。
1 數據與方法
1.1 數據采集與預處理
本文所收集的數據全部來源于CNKI。考慮到文獻題錄數據的更新會有遲滯,本研究以2019年5月20日0時為截止時間,以“主題 = 食品安全 AND 數據”為檢索條件,收集了1996年1月至2019年5月跨度約23 年的3 375 條文獻數據,文獻類型包括期刊論文、學位論文、會議論文和報紙圖書等。文獻數據以Refworks格式(包含文獻類型、作者、作者單位、標題等主要科學計量字段)存儲為UTF-8編碼的.txt文件到本地路徑備用。同時,使用Python爬取檢索頁面分年數據的完整信息,并寫入Excel文件。
1.2 科學計量學方法與科技文本挖掘軟件
科學計量學是運用數學等定量方法對科學的整體及其各個方面進行定量化研究,以解釋科學發展規律的一門新興學科[6]。傳統的科學計量學研究方法主要有出版物統計、著者統計、引文分析、詞頻分析等[7]。
Citespace是由美國德雷塞爾大學信息科學與技術學院的Chen Chaomei教授應用Java語言開發的一款信息可視化軟件[8],本研究使用的是該軟件的5.1.R8.SE.版本。它主要基于共引分析理論和尋徑網絡算法等,對特定領域文獻(集合)進行計量,以探尋出科學領域演化的關鍵路徑及知識轉折點,并通過一系列可視化圖譜的繪制,來形成對科學演化潛在動力機制的分析和學科發展前沿的探測[9]。
2 結果與分析
2.1 交叉研究的研究主體分析
2.1.1 文獻年代分布
對數據集進行分類檢索可知:其中期刊論文記錄1 604 條,博、碩士學位論文記錄1 599 條,會議論文記錄71 條,這3 類文獻體例占總體文獻的97.01%。進一步地對期刊和博、碩士學位論文的年累計量進行多項式回歸預測,發現當多項式階數由2階增加到4階時,預測精度不再隨著方程階數的增加而增加,故采用4階多項式預測。
文獻累計量的分年統計及回歸預測見圖1,期刊論文、學位論文累計數量預測曲線的R2均達到99%以上,證明回歸模型的擬合優度很高。曲線數值的增長具備某種指數型趨勢,而此處依據泰勒公式原理,以多項式函數來近似計算指數函數值,通過設置預測點,可以推測:本領域期刊論文總量有望在2019年達到1 940 篇左右,在2020年達到2 340 篇左右;本領域學位論文總量有望在2019年達到1 810 篇左右,在2020年達到1 950 篇左右。在2007年以前,期刊論文的累計量高于學位論文的累計量,這表明1996—2007年交叉研究還處于討論與積累的萌芽階段,尚未形成較完備的學科形態;2007—2019年學位論文的累計量高于期刊論文的累計量,這表明從事交叉研究的人越來越多,交叉研究的熱度在不斷提高,社會的重視程度也在不斷提高;預計2019年會成為期刊論文數量第二次超過學位論文數量的轉折點,這將標志著交叉研究會逐步形成新的學科增長點,推動新一階段的交叉研究發展。
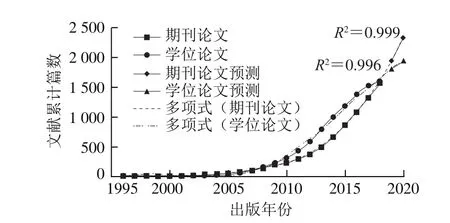
圖1 我國食品安全與數據科學交叉研究的文獻累計量分年統計與預測Fig. 1 Accumulated annual statistics and prediction of literature on cross-disciplinary studies on food safety and data science in China
2.1.2 重要機構分布
使用CNKI數據庫的“分組瀏覽-機構”功能,可以查詢到當前學科領域中重要機構的信息(以發文量統計,列表機構最低發文量為14 篇)。由表1可知,發表論文30 篇及以上的機構有18 家,所發表的論文占全部3 375篇文獻的26.93%,屬于引領本領域研究的核心機構群體。
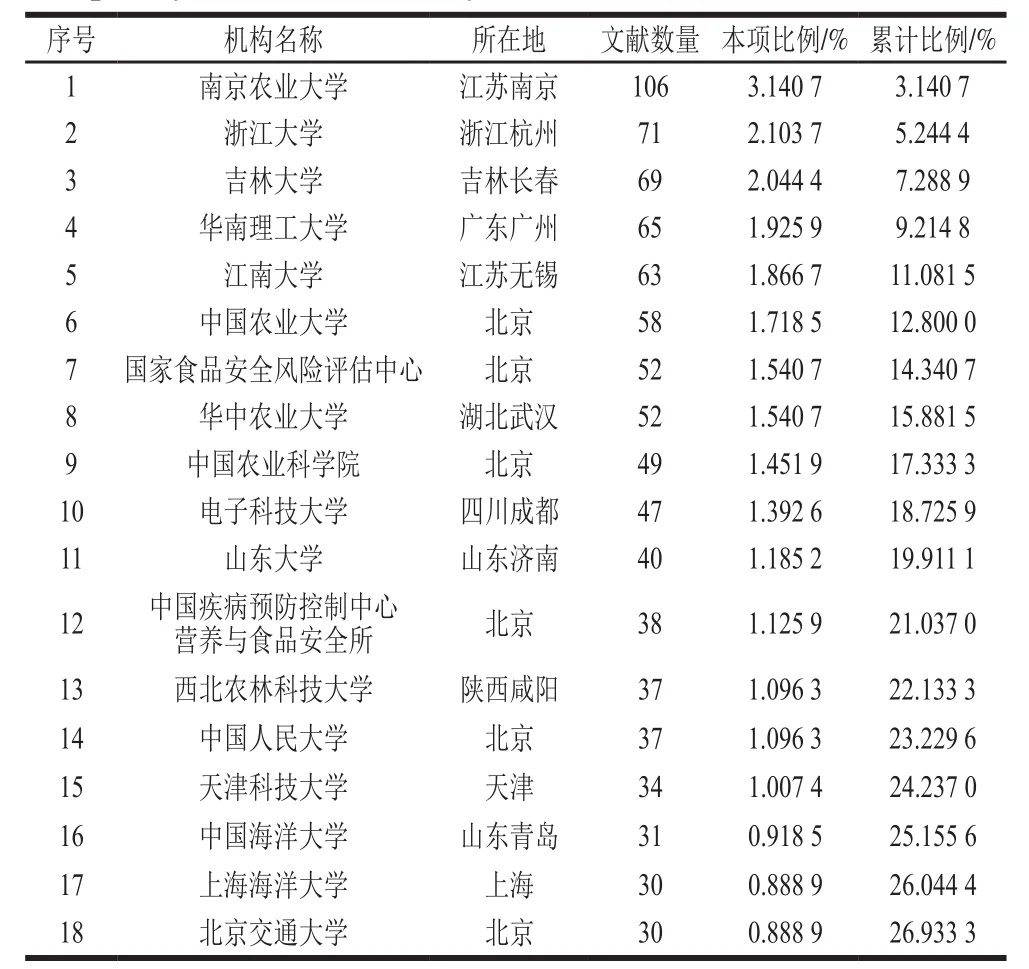
表1 1996—2019年我國食品安全與數據科學交叉研究領域文獻產出量前18的機構Table 1 Top 18 most prolific research institutions in terms of crossdisciplinary studies on food safety and data science in China (1996-2019)
在本領域發表論文的數量與該機構研究人員的數量、獲得相關科研項目的數量密切相關。例如:在南京農業大學所發表的論文中,李太平教授團隊的研究成果最多,共有6 篇論文,主要受到國家自然科學基金面上項目“生鮮農產品質量安全的監管機制研究”(71173114)的資助;在浙江大學所發表的論文中,杜樹新副研究員及其團隊的論文數量最多,共有5 篇,主要受到國家科技攻關計劃資助項目(2001BA804A34)的資金支持。
2.1.3 重要期刊與學位授予單位分布
使用Excel 2016軟件的數據透視表功能,對所收集的3 375 條題錄數據的“期刊名稱”或“學位授予單位”字段進行數據透視,可以得到期刊論文文獻的來源期刊或學位論文的學位授予單位的統計信息。共有1 611 篇與本主題相關的期刊論文被刊載在684 種學術期刊上,平均載文量為2.36 篇/刊。由表2可知,集中刊載本領域論文10 篇及以上的期刊有18 種,載文數量達438 篇,占全部期刊論文的27.19%,在期刊分類[10]上分屬于4大類,其中“食品科學技術”和“農業綜合”分類占大多數。
共有1 598 篇與本主題相關的學位論文來自248 個不同的學位授予單位,平均載文量為6.44 篇/機構。由表3可知,學位論文數量在20 篇及以上的機構有17 家,論文數量達到650 篇,占本領域學位論文總量的40.68%。其中,農林類與綜合類高校涉足食品安全與數據科學交叉研究領域的數量相較于其他類別更多。

表2 交叉研究期刊論文的來源期刊分布Table 2 Journal distribution of published papers on cross-disciplinary studies on food safety and data science

表3 交叉研究學位論文的學位授予單位分布Table 3 Degree conferring institution distribution of dissertations on cross-disciplinary studies on food safety and data science
本文通過文獻[11]的方法,統計載文數量、載文數量的出現頻數、出現概率和累計概率,得到了期刊論文和學位論文的頻數與概率分布表。使用Origin Pro 9.1軟件對上述數據進行概率分布模型的擬合檢驗,得到圖2。
圖2A、B分別表示本領域期刊論文載文數量和學位論文載文數量的概率分布擬合曲線,決定系數分別為0.999 9、0.999 6,具有很高的擬合優度。所以兩種文獻的載文數量的概率分布都服從異速生長指數(Allometric)分布。這表明我國食品安全與數據科學交叉研究領域經過萌芽與積累,研究規模正在高速增長。根據異速生長尺度規律[12]的特點,我國食品安全與數據科學交叉研究所形成的這個特定的食品安全子領域,可以看作是一種廣義的生態系統,而本主題新科技論文的產生則是這個生態系統中最重要的信息流之一。自身的主題與偏好適合這個子領域的優質文獻被刊載的期刊,或者重視這個新興子領域發展的研究機構,會在這個新興子領域里快速生長,顯得愈發重要。

圖2 期刊論文(A)和學位論文(B)載文數量的概率分布擬合Fig. 2 Fitted probability distribution of the number of papers published in journals (A) and degree papers (B)
2.1.4 重要作者分布
關于論文合著情況,共有3 619 人次的作者參與撰寫了這1 611 篇期刊論文,平均作者為2.24 位/篇,即作者合作度[6]為2.24。使用CNKI數據庫的“分組瀏覽-作者”功能,可以查詢到當前學科領域中高產作者的信息,本文將所述高產作者中發文數量大于5 篇的作者信息進行整理。同時,為了客觀地評價各位高產作者在論文合著中對其論文的貢獻度,本文引入了Du Yongping等2015年提出的基于作者順序的影響力計算方法,該方法適用于大數據環境下具備統計意義的計算[13]。該方法的算理實質是:先計算除第一作者以外其他作者的分配得分(以百分數計),再反向用總貢獻值倒減出第一作者的得分,其計算見下式。

式中:paij表示論文署名次序為i(即Order(i))的作者對其論文j的規范化貢獻值;M表示該論文的作者總數。
本文使用pa鏈來記錄作者的署名和排位情況,如:5(2)表示該作者的某一篇論文共有5 位作者,其為第2作者(若為通信作者,則視為第一作者;若存在并列一作,也視為第一作者;特殊情形(比如通信作者)將以“*”標記,如:5(2*),計分為5(1))。根據公式(1)進一步計算累計pa和平均pa,并將以上字段信息合并為表4。
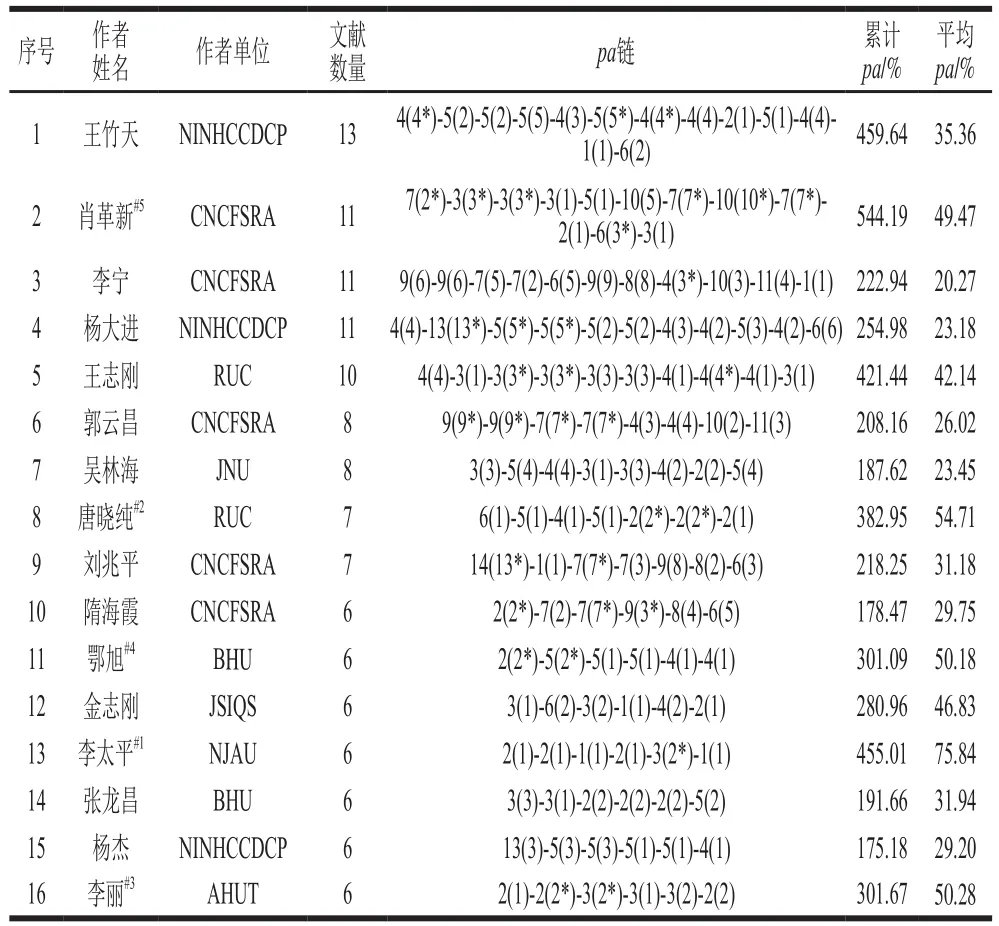
表4 本領域發文數量大于5 篇的高產作者和pa鏈Table 4 Productive authors publishing more than 5 papers and their pa chain in this field
由表4可知,這些高產作者中,平均pa前5 名分別是:李太平、唐曉純、李麗、鄂旭、肖革新,他們應該是本領域研究合作的優秀候選人。從累計pa來看,王竹天、王志剛也是本領域具備合作潛質的優秀候選人。
2.2 交叉研究的研究主題分析
2.2.1 關鍵詞共現分析
本文使用對數似然率(log-likelihood rate,LLR)算法對關鍵詞共現網絡進行聚類分析,得到了具有11 個主要聚類的關鍵詞共現網絡圖譜(圖3),這些聚類的輪廓值(Silhouette)均大于0.5,且部分大于0.7,說明這些聚類合理且令人信服[14]。這11 個聚類可以進一步歸納為3大類(表5),即:食品安全領域的新型數據采集技術(類I)、食品安全領域的新型數據分析技術(類II)、食品安全領域的新型數據科學應用(類III)。
由圖3可知,1996—2019年我國食品安全與數據科學交叉研究領域形成了內部邊界聚合且外部邊界分明的復雜關鍵詞共現網絡圖譜。該圖譜有405 個節點和1 543 條連線,是一個由大量高頻關鍵詞形成的廣闊知識空間。以下將根據引文空間聚類成員的歸屬和食品安全意義上的類別界定,以大類(I、II、III)劃分為展開順序,對所得到的關鍵詞共現網絡圖譜進行深入的分析。

表5 關鍵詞共現網絡的聚類信息Table 5 Clustering information of keyword co-occurrence network
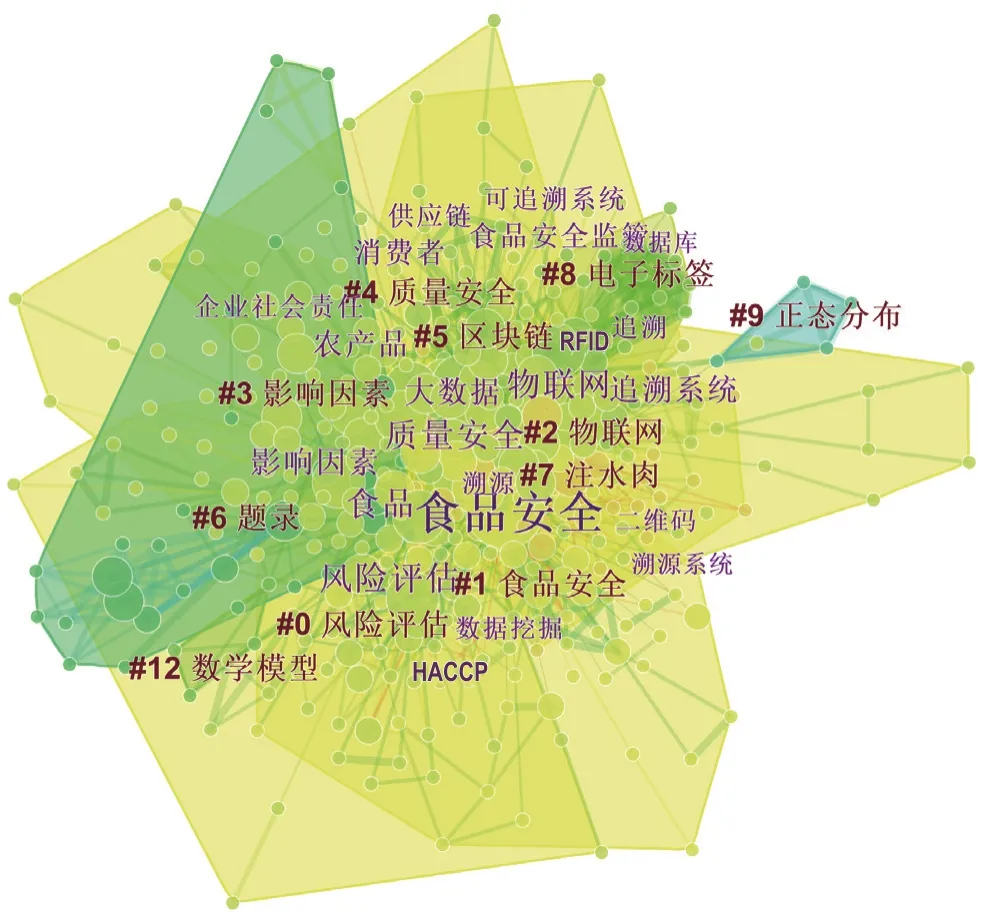
圖3 我國食品安全與數據科學交叉研究的關鍵詞共現網絡圖譜Fig. 3 Keyword co-occurrence network map of cross-disciplinary studies on food safety and data science in China
2.2.1.1 食品安全領域的新型數據采集技術
在大數據時代的背景下,物聯網、區塊鏈和電子標簽等技術成為了采集新型食品安全數據的重要支撐技術。將網絡嵌入食品生產流通各環節的物理設備,有利于提升食品供應鏈的智能化,完善食品溯源體系。尚培培等[15]研究了具備感知層、網絡層和應用層3 層架構的產品電子代碼(elctronic product code,EPC)物聯網在牛肉供應鏈安全中的應用,實現了牛肉產品標準化唯一標識、不合格牛肉溯源追蹤、全程信息共享3 個層面的食品安全保障。區塊鏈技術的數據分布式儲存與數據不可刪改的特性將對食品從生產到零售的整個商業過程起到某種監督與凈化作用。顏波等[16]設計并開發了基于RFID和EPC技術的具有企業、政府部門和消費者3 個追溯主體的羅非魚供應鏈可追溯平臺,在羅非魚上架銷售前一直使用可循環RFID標簽,實現了銷售前的全程追溯;而零售端顧客則可以通過獨立包裝外的條形碼標簽溯源,提升了生鮮食品安全監管的效率,滿足了顧客的食品安全需求。
2.2.1.2 食品安全領域的新型數據分析技術
數學模型方法結合新興的人工智能技術應用于食品安全領域,提升了食品安全數據及其分析挖掘技術在食品安全治理中的功能與地位。晁鳳英等[17]對某出入境檢驗檢疫局提供的食品安全檢測數據,使用廣度優先的Apriori算法進行了關聯規則數據挖掘,并對挖掘出的幾條有代表性的關聯規則進行了解讀,由此提煉出食品安全抽檢的優化策略。質量控制圖是一種簡單、有效的統計技術[18]。帶有上中下控制界限的、以檢測食品生產過程安全和判斷食品質量穩定狀態為目標的控制圖,已經逐步演化和固定為食品質量安全過程控制的專門化數據分析方法。秦燕等[19]使用控制圖工具進行危險檢出物指標預警,對廣州食檢中心某時段內的出口茶葉中的六氯環己烷和白蘭地酒中的甲醇的檢測數據進行統計分析,提出了Y-Pn控制圖、C-Pn控制圖、J-Pn控制圖和-δ控制圖4種預警方法。
2.2.1.3 食品安全領域的新型數據科學應用
以數據密集型科學發現的研究范式,研究前沿且恰當的食品安全問題,是數據科學應用在食品安全領域的一種使命。因為面向主體對象不同,故其應用場景和應用需求也不相同[20]。所研究的對象是當前層出不窮的各類食品安全事件及危險源,如:使用主成分分析-最小二乘支持向量機預測模型鑒別地溝油[21]、使用層次分析法(analytic hierarchy process,AHP)評價水產品孔雀石綠的殘留風險[22]、使用SGompertz-SLogistic生長動力學模型預測清蛋糕中金黃色葡萄球菌的生長速率[23]等;所研究的內容是在宏觀層面上食品安全水平提升所亟待解決的各種問題,如:使用關聯規則算法探尋食品質量安全保障的關鍵因素[24]、使用循環神經網絡算法對食品安全描述文本的情感傾向進行分類[25]、通過構建貝葉斯網絡對白酒質量安全進行預測[26]等;交叉研究所受益的主體及研究方向包括:政府的智慧監管與風險預警[27-29]、食品企業的生產控制與事后應對[30-32]、消費者的食品安全風險認知與支付意愿[33-35]等。
2.2.2 時間線聚類分析
使用Citespace軟件進一步繪制關鍵詞共現網絡的時間線圖譜,由圖4可知,我國食品安全與數據科學交叉研究的各研究主題存續時間不同。例如:聚類C0、C1和C2存續時間都接近20 年,而且從聚類產生到現在一直是活躍的聚類;而另一些聚類的存續時間則相對較短,例如:聚類C6、C7和C8,存續時間只有大約7~10 年,且目前已經不再是該主題研究熱度最高的時段,這些主題都具有從存續時間長的主題中分化產生的特點。圖中的這些顏色與流向表征著我國食品安全與數據科學交叉研究的不同發展階段。
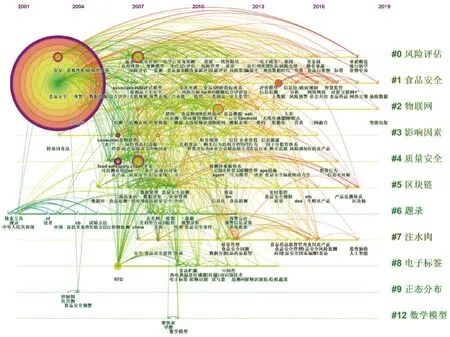
圖4 我國食品安全與數據科學交叉研究的關鍵詞聚類的時間線圖譜Fig. 4 Keyword clustering time-line atlas of cross-disciplinary studies on food safety and data science in China
1996—2006年為重視食品標準數據與傳統數理統計方法的階段。此階段的科技文獻主要側重引進國外先進的食品安全標準并與我國的食品安全標準進行比較[37-39];在數據分析上多基于HACCP系[40-42]、調查問卷方法和數理統計工具[43-45]。
2007—2014年為新型食品安全數字技術和數學模型方法開始涌現的階段。此階段層次分析法[46-47]、貝葉斯網絡[48]、關聯規則[49]、決策樹[50]、可拓決策[51]等數學模型方法被廣泛地應用于食品安全風險評估和風險預警等方面;RFID[52-54]、QR二維碼[55-56]、同位素指紋[57-58]等技術被廣泛地應用于食品質量安全追溯領域。
2015—2019年為大數據與人工智能開始廣泛地應用于食品安全各子領域的階段。此階段計算機視覺[59]、電子鼻與電子舌[60]、模式識別[61]等基于人工智能的食品安全無損檢測技術得到應用;基于區塊鏈技術的可追溯平臺[62]、基于大數據的社會共治模式[63]、食品安全大數據的可視化分析方法[64]、基于大數據的食品安全風險分析[65]等由大數據技術驅動的食品安全智慧監管技術與模式正在探究與實踐中。
2.2.3 關鍵詞突現分析
本文采用Kleinberg突發事件檢測算法[66]來探測文獻空間中的突現詞,Citespace軟件會從論文題目、關鍵詞和摘要等字段中提取候選專業術語,通過跟蹤分析它們在不同時間區間內出現頻率的突然變化(激增),識別出代表研究前沿的若干名詞術語[67]。運行程序后,Citespace找到了47 個突現關鍵詞,將突現度前50%的突現詞按照其突現起止時間的升序排列得到表6。

表6 突現度最高的前50%的關鍵詞Table 6 Top 50% keywords with the strongest citation burstness
從表6可以看出,不同年份本領域的研究者所關注的研究熱點不同。根據表6可以進一步把我國食品安全與數據科學交叉研究的熱點演進劃分為3 個階段,與時間線聚類分析的年代劃分相吻合。1)1996—2006年為重視國外食品安全標準的引進及與我國食品安全標準開展比較研究的階段,“檢索工具”、“GB(國家標準)”是這一階段的突現詞。2)2007—2014年,突現詞“RFID”和“電子標簽”代表了新型食品數字溯源技術的研究方向;突現詞“利益相關者”與“食品行業”代表了與食品企業有關的研究方向;突現詞“供應鏈”與“預警”等代表了與食品安全風險控制有關的研究方向。3)2015—2019年,突現詞“大數據”代表了數據密集型科學發現的研究范式;突現詞“風險感知”、“購買意愿”和“社會共治”等代表了這一階段涌現出的研究熱點。
3 討 論
3.1 交叉研究當前的研究熱點
3.1.1 新型數據采集技術與食品溯源及網絡輿情的研究在食品從農田到餐桌的流通過程中,食品及其有關主體的多重屬性被計量和記錄,產生了食品關聯屬性的數據化基礎[68]。以保障食品質量或數量安全為目的,提取這些數據,則產生了海量的食品安全數據。數據采集技術的發展使得文本資料、社會關系、地理方位等不易被提取的數據變得可被利用;使得政府、企業、檢測機構、行業協會、媒體和消費者這6 類食品安全社會主體[20]所產生和需要的結構化、半結構化和非結構化數據[69]被各種技術手段收集和儲存,以備挖掘與利用。
一方面,RFID和傳感器、物聯網等面向現實世界中食品理化數據的數據采集技術,推動了食品安全溯源技術的發展。圣光磊[70]通過改進滑動窗口射頻識別數據分析-目標自適應射頻識別數據分析(statistics moothing for unreliabler fid data-dynamic tags-based SMURF,SMURF-DSMURF)算法中數據完整性和標簽動態性條件,設計了新的更高效的多層級射頻識別數據分析(multi label DSMURF,MDSMURF)算法,并應用于白芍飲片溯源系統中,提高了數據噪聲的清洗效率和多標簽動態的閱讀效率。鐘聰兒等[71]將ALOHA算法應用于基于RFID技術的茶葉物流溯源系統中,并設計了仿真實驗,結果表明:通過解決硬件不兼容、信息冗余等問題,能夠顯著地提高追溯系統的響應效率。
另一方面,網絡爬蟲及數據接口等面向虛擬世界中的食品資訊數據的數據采集技術,推動了食品安全輿情研究的發展。程鐵軍等[72]使用網絡爬蟲技術在線獲取了2011—2014年總貼數達50萬以上的超熱度食品安全新聞事件15 例,并構建了4大類11小類的食品安全風險預警指標,通過粗糙集理論進行屬性簡約計算,從高熱度輿情事件中提煉出易引發食品安全事件的關鍵食品流通環節,為源頭管理和社會共治提供了針對性建議。洪小娟等[73]以所收集的包含588 個媒體微博節點的2014年食品安全微博輿情事件為數據集,使用Pajek軟件進行了社會網絡分析特有的網絡結構、度、K-核以及派系分析,發現了食品安全新聞傳播的核心節點、媒體派系以及傳播模式,為食品安全輿情的利用與引導提供了可參考的建議。
3.1.2 新型數據存儲技術與食品數據倉庫及預警系統研究
大數據及其應用技術的爆炸式發展所產生的數據存儲需求推動了數據存儲技術的發展。大規模并行處理機(massively parallel processor,MPP)存儲架構、Hadoop技術和分布式計算等新興技術,讓已經長期存在的食品安全大數據有了被規范化存儲和多元化挖掘利用的可能性,尤其是基于數據庫的食品安全預警系統,是當前研究的重要熱點形態。郭曙超等[74]以山東地區進出口食品檢測實驗室的檢測數據為數據集,根據食品安全工作需要,設計數據字典和體系架構,建立了“進出口食品與農產品實驗室檢測數據倉庫系統”,該系統可進行數理統計、可視化分析與數據挖掘,能夠實時掌握食品安全狀況的動態,可以為食品安全管理人員提供高質量的決策依據。劉翠玲等[75]使用Eclipse開發環境和Java語言,設計并開發了一種基于多源大數據的食品安全監測預控系統,該系統后臺采用My SQL關系數據庫,實現了拉曼光譜儀數據的導入、分析與預警。黎建輝等[76]以云計算、云存儲、分布式計算框架為系統主體,結合信息爬取、模式識別以及深度學習技術等,設計并開發了全球食品安全信息監控與分析云平臺,通過對近5 000 個信息源的固定周期爬取與監控,成功地預警出了礦泉水水源污染事件、病死豬肉流入市場事件以及保鮮膜中塑化劑超標事件等具有重大社會影響的食品安全事件。
3.1.3 新型數據分析技術與食品安全智能解決方案研究
應用數據科學模型方法體系中的有監督學習、半監督學習和無監督學習[77]的各類算法對海量的食品安全數據進行計算分析,可以為食品安全的信息探測、數據預測和風險評估等各方面帶來更加智能化的解決方案。劉金碩等[78]提出一種基于隱狄利克雷分配模型(latent Dirichlet allocation,LDA)的K平均值(K-means)聚類的網絡食品安全問題話題發現算法,并以網絡爬取的2017年包含43 個食品安全分類的1 920 條新聞報道為數據集,通過LDA-K-means算法進行聚類,以此發現新的食品安全話題,并與傳統的向量空間模型(vector space model,VSM)算法進行了比對,實驗結果表明,LDA-K-means算法相對于傳統的VSM算法聚類效率更高,更加利于快速探測網絡中新的食品安全問題話題。陳國慶等[79]使用基于熒光光譜和徑向基函數神經網絡,對光譜儀發射波長的網絡特征參數進行訓練,并對胭脂紅溶液樣本的濃度進行預測,結果表明,該方法對食品色素溶液種類識別的準確度接近100%,可應用于合成食品色素檢測及食品安全監管。趙靜嫻[80]以2005—2009年華北地區20 個蔬菜種植基地的調查數據和國家農業科學數據中心的共享數據為數據集,抽取82 個樣本作為訓練集,抽取10 個樣本作為驗證集,應用決策樹算法進行食品安全評估,提取了5 條規則,與驗證集對比的準確率達到了90%,說明該方法能夠有效指導農產品質量安全的提高方向。
3.1.4 新型數據可視化技術與食品安全決策輔助研究
食品安全數據可視化分析作為一個新興的交叉研究領域,通過先進的交互式可視化工具幫助食品安全領域人員快速分析數據的分布態勢、探尋數據間隱含關聯、提升認知和分析能力、提高食品安全監管的科學性和有效性[81]。陳誼等[81]在分析食品安全大數據特征的基礎上,使用了數據地圖、ThemeRiver、雙曲樹、TimeWheel和SolarMap等新型圖表,展示了時空數據、層次數據、多維數據和關聯關系的數據可視化形式,為提升數據可視化的易用性和輔助食品安全決策的可靠性提供了技術路徑。陳紅倩等[82]提出了一種基于Open GL圖形庫與統計數據的農殘檢測數據的融合對比可視化方法,該方法可將一定規模的農殘數據根據其所屬的地區和類別進行分類統計,并將多個統計結果融合到一個可視化界面中,可對農殘檢測數據進行快速展示,并以此進行分析和預判,為有關專家進行農產品安全快速決策提供研判依據。楊璐等[83]提出了一種挖掘數據關系的可視分析圖ExploreView,以國家食品藥品監督管理總局抽檢數據為數據集,使用立方體隱喻組織數據,進而完成數據編碼,綜合使用層次圖、細節描述圖和關系挖掘圖等新式可視化圖像,實現對數據的展示和交互,為食品質量安全的監測和預警提供決策幫助。江美輝等[84]以“上海福喜過期肉”事件新聞文本為研究對象,基于復雜網絡理論,使用Gephi軟件對非結構化的文本信息進行了拓撲特征分析和關聯網絡挖掘,結果表明,食品安全事件新聞報道的關注點具有集聚性,且關注點會隨著時間推移而變化,該研究挖掘出了新聞實體間的隱含關系,為有關部門對食品安全突發事件的應急管理提供了決策依據。
3.1.5 面向對象的食品安全大數據技術應用研究
面向食品安全治理的不同社會主體的數據特征和數據需求的應用研究,是目前交叉研究的重要橫向層面。總體來看,政府需要食品安全智慧監管類的研究。張亮等[85]提出了面向智慧型城市的食品安全監管體系,該體系基于感知網絡發現與采集數據,基于云儲存規劃與分析數據,基于大數據技術挖掘與預測數據,為智慧城市食品質量的安全預警和應急管理提供了參考路徑;食品企業需要產品質量與輿情安全類的研究,席磊等[86]提出了一種分布式無公害農產品數字認證系統,該系統具有中心化分布式拓撲結構,使用元數據、工作流和Web Service技術,可實現跨部門、跨地域的協同工作和高效認證的系統功能;檢測機構需要共享分析和能力評價類的研究,沐曉馥[87]提出了一種基于AHP算法的檢驗檢測機構檢測能力管理信息系統績效評價方法,該方法基于AHP算法設計了具有4 個一級指標和10 個二級指標的評價指標體系,用于量化評價不同檢測機構的檢測能力管理信息系統的績效,為有關單位進行系統選型提供了實際的決策依據;行業協會需要行業自律和治理參與方式類的研究,劉根華等[88]以浙江省金華市為例,應用數據統計分析方法分析了行業協會參與食品安全社會共治的現實困難,提出了“政府職能前移”和“五方聯動機制”等有益對策;媒體需要治理策略和信息查詢類的研究,謝康等[89]基于Kahneman-Tversky前景理論和博弈論方法,定量化分析了媒體參與食品安全社會共治的條件,借助MATLAB軟件進行系統仿真,得出媒體可采取的“提高違規者聲譽損失度”、“持續跟蹤調查或深度報道”、“動態監督”和“媒體群監督與共治代表制度”4 種有效策略;消費者需要風險感知和購買意愿類的研究,張宇東等[90]使用數理統計方法分析了所設計、發放與回收的550 份有效調查問卷,定量化地揭示了食品安全風險感知下,消費者的量化信息偏好、購買意愿和決策邏輯,結果表明,對食品安全風險嚴重性的主觀判斷會顯著提升消費者對食品安全量化信息的偏好,而這種偏好會反向刺激消費者量化消費,以應對所認知的食品安全風險。
3.2 交叉研究未來的發展趨勢
隨著大數據時代的到來以及數據挖掘技術在食品安全領域的應用,數據科學在食品安全各領域的地位將會越來越重要,食品安全監管也將向著更加智能化的方向發展,社會食品安全水平必然會得到更加顯著的提升。數據科學的發展是推動交叉研究進步的重要推動力,食品安全研究的發展過程中對數據科學產生的新需求是引領交叉研究進步的重要牽引力。從數據科學的發展趨勢來看:數據可視化、文本挖掘與自然語言處理、社交網絡分析、計算機視覺和高性能計算等會成為未來的大數據技術前沿[91]。若將這些前沿技術投射到食品安全領域,則會帶來如下的未來研究熱點:1)計算機視覺技術的發展將推動食品無損檢測技術的研究;2)自然語言處理能力的提升將推動食品安全網絡輿情處理的研究;3)各種機器學習算法的進步將推動食品安全歷史數據的知識發現以及決策支持的研究;4)食品安全大數據的云儲存與人工智能服務的需求將持續擴大,其產業化的研究將得到蓬勃發展。
4 結 語
在近23 年的發展歷程中,我國食品安全與數據科學的交叉研究從零星的學科交集萌芽,逐漸發展出一個新興交叉學科的雛形,目前正處于新的快速增長期。文獻數量呈指數式增長,目前已存在3 375 篇各類文獻的研究體量,期刊論文和學位論文的年平均增速分別達到51.49%和52.45%,作者合作度為2.24。涌現出的高產和高貢獻度作者越來越多,例如南京農業大學的李太平教授、中國人民大學的唐曉純副教授和安徽工業大學的李麗副教授等。通過CNKI的“分組瀏覽-研究層次”檢索功能獲知,我國食品安全與數據科學交叉研究目前涉及到國內工程技術(自科)、行業指導(社科)和基礎研究(社科)等16 個學科領域。結合科學計量學的分析,得出以下3 個方面的結論。
第一,通過關鍵詞共現圖譜分析,找出了本領域3大類11小類熱點研究主題。通過時間線聚類圖譜分析與關鍵詞突現度圖譜分析,劃分出了本領域發展史上的3 個典型歷史階段,即:1996—2006年的食品安全標準引入與比較和食品安全數據的數理統計階段;2007—2014年的食品安全數字技術與數學模型階段;2015—2019年的食品安全大數據與人工智能階段;預計在未來計算機視覺、自然語言處理技術、機器學習算法和大數據服務產業會在我國食品安全與數據科學交叉領域發揮更加重要的作用。
第二,通過文獻分析,在食品安全與數據科學交叉融合的方向層次來看,數據科學的數據采集、數據存儲、數據分析和數據可視化等技術,在23 年間不同程度地與食品安全的食品溯源、網絡輿情、風險預警、智慧監管和可視化決策等重要方面相融合,誕生出新的食品安全前沿研究形態,是推動交叉研究不斷發展的重要縱向動力。數據科學的各種技術與食品安全社會共治的各個主體的實際需求相結合,誕生出各種面向對象的食品安全大數據技術,是推動食品安全與數據科學交叉融合、促進食品安全大數據技術發展的重要橫向動力。
第三,值得注意的是,雖然在僅僅23 年的時間里,我國食品安全與數據科學的交叉研究得到了迅猛發展;但是高被引論文[92]卻只是總體文獻中的極少數,國內研究與世界先進水平相比仍有差距;相比起食品安全領域的其他成熟學科板塊,本領域的學科影響力仍然較為有限。結合未來的科技發展趨勢和國家科技政策導向,我國食品安全與數據科學交叉研究應該得到社會各界更多的重視;本領域經過探索且被證明是成熟可行的研究范式,應該以課程化的形式進入到與食品安全有關的專業學科的課程體系之中;各級科學基金也應該加強對本領域的支持力度,推動本領域新的科研成果的不斷產生以及科技成果的高效轉化,以此推動我國食品安全監管防控的智能化進程。
本文也存在一定的局限性,因為數據下載階段可檢索到并可供下載的數據與所在高校(或研究機構)所購買的數據庫的時間跨度及文獻種類的權限有關[93]。故可能存在少量未被CNKI收錄的文獻,或作者單位未購買下載權限的數據庫所包含的文獻,未被納入本研究的數據集會造成少量的樣本缺失,并會一定程度地影響科學計量與主題分析的精準度。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
中國科技教育(2019年11期)2019-09-26 10:49:15
中國科技教育(2019年12期)2019-09-23 08:02:08
小小藝術家(2019年6期)2019-06-24 17:39:44
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
今古傳奇·故事版(2016年15期)2016-09-07 06:57:32
