基于LRC-SNN的圖像高效重建與識別
2020-07-21 14:19:40宋林林
計算機工程 2020年7期
關(guān)鍵詞:分類
索 靜,宋林林,李 強
(1.太原工業(yè)學(xué)院 電子工程系,太原 030000; 2.太原理工大學(xué) 信息與計算機學(xué)院,山西 晉中 030600)
0 概述
圖像集分類[1]是指從多個圖像中進行目標(biāo)識別的過程,對于圖像集分類問題而言,訓(xùn)練集由各個類別中的一個或多個圖像集構(gòu)成,測試集包含具有相同主題的多個圖像,分類算法通過某些相似度指標(biāo)可對這些測試圖像集與訓(xùn)練圖像集進行匹配,進而確定測試圖像的主題。與傳統(tǒng)的基于目標(biāo)識別的單圖像分類算法相比,圖像集分類算法具有多種優(yōu)勢,其可有效應(yīng)對圖像內(nèi)的多種外觀變化,如視角變化、遮擋、非剛性形變、光照變化及背景變化等。上述特性使得圖像集分類技術(shù)在偵察、基于視頻的臉部識別、攝像頭網(wǎng)絡(luò)人臉檢測等領(lǐng)域得到廣泛應(yīng)用,引起了計算機視覺和模式識別領(lǐng)域相關(guān)學(xué)者的關(guān)注[2]。本文利用線性回歸分類(Linear Regression Classification,LRC)和共享最近鄰(Share Nearest Neighbor,SNN)子空間分類理論進行圖像重建和識別,并提出一種改進的基于LRC-SNN的圖像集高效分類算法。
1 相關(guān)工作
近年來,圖像分類算法成為圖像處理領(lǐng)域的研究熱點之一。文獻[3]提出了一種圓周特征描述方法,該方法利用圓心在輪廓線上的圓、輪廓線、葉片形狀區(qū)域兩兩相交所得到的3類葉片圖像的圓周特征,通過改變圓的半徑來產(chǎn)生由粗到細的圓周特征描述。文獻[4]提出了一種基于深度卷積神經(jīng)網(wǎng)絡(luò)、可應(yīng)用于大規(guī)模圖像分類的深度學(xué)習(xí)框架,其在經(jīng)典AlexNet的基礎(chǔ)上分別從框架和內(nèi)部結(jié)構(gòu)2個方面對網(wǎng)絡(luò)進行優(yōu)化和改進。文獻[5]通過在卷積結(jié)構(gòu)單元中添加通道關(guān)注模塊和空間關(guān)注模塊,實現(xiàn)網(wǎng)絡(luò)的混合關(guān)注,并提出一種遞歸深度混合關(guān)注網(wǎng)絡(luò)方法。文獻[6]提出一種融合Zernike矩全局特征和加速魯棒性特征包BoF-SURF局部斑點特征的花粉圖像分類識別算法。文獻[7]研究深度卷積神經(jīng)網(wǎng)絡(luò)的發(fā)展及其在計算機視覺領(lǐng)域的應(yīng)用。
圖像集分類算法可分為有參數(shù)算法和無參數(shù)算法兩大類。其中,有參數(shù)算法[8-9]首先根據(jù)某種統(tǒng)計分布對圖像集進行建模,然后計算這些分布間的相似度。然而,如果同一對象的測試圖像集和訓(xùn)練圖像集間的統(tǒng)計關(guān)聯(lián)較弱,則參數(shù)估計值可能不夠準(zhǔn)確,導(dǎo)致算法的性能較差。
無參數(shù)算法利用多種指標(biāo)來衡量圖像集間的相似性,該類算法是目前圖像集分類問題中的研究熱點。其中,較為典型的算法有基于時域圖像序列的臉部識別算法(TIS)[10]、判別規(guī)范關(guān)聯(lián)分析識別算法(DCC)[11]、流形-流形距離識別算法(MMD)[12]、流形判別分析算法(MDA)[13]、仿射殼體圖像集線性距離算法(AHISD)[14]、凸殼體圖像集距離算法(CHISD)[15]、圖形嵌入判別分析算法(GEDA)[16]、稀疏近似最近鄰點算法(SANP)[17]、協(xié)方差判別學(xué)習(xí)算法(CDL)[18]、正規(guī)化最近鄰點算法(RNP)[19]、平均序列稀疏表示分類算法(MSSRC)[20]、集合-集合距離度量學(xué)習(xí)算法(SSDML)[21]等。另外,圖像集還可表示為線性子空間或復(fù)雜非線性流形的組合。對于線性子空間,往往利用某個子空間中的向量與另一子空間中向量間的最小角度余弦值來衡量2個圖像集的相似度。文獻[22]將訓(xùn)練和測試圖像集看作高維空間的子空間,提出一種對偶線性回歸分類算法(DLRC)以進行圖像集分類,該算法綜合利用了各個圖像集的最后一幅圖像、其他被比較圖像集的變化以及線性回歸分類算法,從而確定2個子空間的距離。文獻[23]對文獻[22]的研究進行拓展,提出一種成對線性回歸模型(PLRC)以進行圖像集分類,該模型利用圖像集的平均圖像而非最后一幅圖像來確定子空間的距離。然而,上述算法要求特征向量的維度遠大于畫廊圖像集和測試圖像集中圖像的總體數(shù)量,此外,進行圖像集合表示時往往做出部分先驗假設(shè)。在許多實際應(yīng)用中,這些假設(shè)可能無法成立,尤其是當(dāng)集合內(nèi)部存在大量復(fù)雜的數(shù)據(jù)變化時。因此,上述算法只適用于小規(guī)模的測試圖像集。
文獻[24]利用深度學(xué)習(xí)理論提出一種自適應(yīng)深度網(wǎng)絡(luò)模板(ADNT)算法。該算法利用一種深度自動編碼器來定義訓(xùn)練集中各個類別的模型,并通過高斯受限玻爾茲曼器(GRBM)對自動編碼器的權(quán)重進行初始化。在分類時,ADNT利用學(xué)習(xí)過的類別模型重建測試集中的各幅圖像,將重建誤差作為指標(biāo)來確定測試圖像集。仿真結(jié)果表明,ADNT算法的性能優(yōu)于多種經(jīng)典算法,但其依賴于人工LBP特征,并且需要對多個參數(shù)進行微調(diào)才能保證算法性能。另外,ADNT算法的訓(xùn)練需要大量圖像,計算成本很高。
本文提出一種改進的圖像重建與識別算法。對各個畫廊圖像集進行下采樣后,每個類別的畫廊圖像集形成高維空間中的一個子空間。在測試階段,測試圖像集中的每個測試圖像表示為每個畫廊圖像集中圖像的線性組合。利用最小二乘算法估計各個測試圖像的回歸模型參數(shù),然后利用估計后的回歸模型并結(jié)合畫廊子空間對測試圖像進行重建,真實測試圖像和重建圖像間的歐氏距離作為距離度量。在此基礎(chǔ)上,每個測試圖像對畫廊中的各個類別進行投票,最后累積權(quán)重最高的類別作為圖像類別。
2 問題描述

(1)


圖1 本文算法結(jié)構(gòu)
3 圖像識別算法
3.1 圖像的子空間表示

(2)
如果Xμ屬于第c個類別,則有可能將Xμ的圖像向量表示為同一類別畫廊圖像的線性組合:
(3)
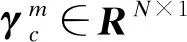
3.2 回歸模型參數(shù)估計

(4)

(5)
(6)

Xμ=QcΓc,c=1,2,…,C
(7)
其中,Γc∈RN×M表示參數(shù)矩陣。利用最小二乘法估計即可計算得到Γc:
Γc=(Q′cQc)-1Q′cXμ,c=1,2,…,C
(8)
(9)
(10)

3.3 加權(quán)投票策略
(11)

(12)
其中,α為常數(shù)。根據(jù)各個測試圖像確定的類別c的累積權(quán)重可計算為:
(13)

(14)
本文提出的圖像集分類算法具體描述如算法1所示。
算法1圖像集分類算法
輸入畫廊圖像集Kc,c=1,2,…,C,測試圖像集Yμ
輸出測試圖像集Yμ的類別μ
形成畫廊:
For c in 1 to C do
For n in 1 to N do

向量化,T=ab
End
End
測試:
For m in 1 to M do

向量化,T=ab
End
For c in 1 to C do
For m in 1 to M do
End
End
算法1流程如圖2所示。
3.4 奇異性問題

3.4.1 擾動
通過添加微小擾動項對回歸量Qc進行正規(guī)化,便可解決Qc的奇異問題。通過經(jīng)驗發(fā)現(xiàn),添加矩陣ε并保證矩陣元素服從-0.5≤ε≤0.5隨機均勻分布,可克服Qc的奇異性。修正后的Qc表示為:
(15)
式(15)需要在所有處理步驟之前實現(xiàn),且矩陣Qc的數(shù)值在0~255之間,因此,任何像素值的最大變化為0.5,經(jīng)過分析可知上述過程不會對分類精度產(chǎn)生影響。
3.4.2 基于QR分解的基本解
解向量的非0元素數(shù)量滿足γc≤r,因此,通過回歸量Qc的QR分解計算式(3)或式(7)的基本解便可解決奇異性問題,其中,r表示回歸量Qc的秩。該方法所得的結(jié)果精度可滿足本文圖像重建的需要。
3.5 快速線性圖像重建
與式(3)~式(6)相比,使用式(7)~式(10)可顯著縮短算法處理時間。在形成畫廊期間利用Moore-Penrose偽逆矩陣[26]計算回歸量Qc的逆矩陣,可進一步縮短算法的處理時間。因此,本文將測試期間的計算過程分解為2次矩陣操作,如算法2所示。
算法2圖像快速重建和分類算法
輸入畫廊圖像集Kc,c=1,2,…,C,測試圖像集Yμ
輸出測試圖像集Yμ的類別μ
形成畫廊:
For c in 1 to C do
For n in 1 to N do
向量化,T=ab;
End
End
測試:
For m in 1 to M do
向量化,T=ab;
End
For c in 1 to C do
End

(16)
(17)
對于ETH-8數(shù)據(jù)集,快速線性圖像重建算法的計算效率相對其他算法幾乎提升了2倍。數(shù)據(jù)集規(guī)模越大,計算效率的提升幅度越明顯。
4 仿真驗證
本文在如下4個常見數(shù)據(jù)集上對算法的性能進行驗證:CMU人體識別數(shù)據(jù)集(CMU MoBo),YouTube名人數(shù)據(jù)集(YTC),UCSD/Honda人臉識別數(shù)據(jù)集,ETH-8目標(biāo)識別數(shù)據(jù)集。將本文算法與如下典型的圖像集分類算法進行比較:基于時域圖像序列的臉部識別算法(TIS)[11],判別規(guī)范關(guān)聯(lián)分析識別算法(DCC)[12],流形-流形距離識別算法(MMD)[13],流形判別分析算法(MDA)[14],仿射殼體圖像集線性距離算法(AHISD)[15],凸殼體圖像集距離算法(CHISD)[15],圖形嵌入判別分析算法(GEDA)[16],稀疏近似最近鄰點算法(SANP)[17],協(xié)方差判別學(xué)習(xí)算法(CDL)[18],正規(guī)化最近鄰點算法(RNP)[19],平均序列稀疏表示分類算法(MSSRC)[20],集合-集合距離度量學(xué)習(xí)算法(SSDML)[21],DLRC算法[22],PLRC算法[23],自適應(yīng)深度網(wǎng)絡(luò)模板算法(ADNT)[24]。其中,ADNT算法的分類精度最高,本文采用文獻[24]中的實驗設(shè)置。為了便于比較,本文給出已有文獻提供的所有算法的平均識別結(jié)果。
4.1 CMU人體識別數(shù)據(jù)集上的分類結(jié)果
CMU人體識別數(shù)據(jù)集包含從6個不同視角拍攝的25個人體在跑步機上的運動視頻,除了最后一個人體外的其他所有人體均有不同運動模式拍攝的4個視頻,即緩慢走動、快速走動、彎腰走動及手中持球走動的視頻。本文采用前24個人體的視頻序列,每個視頻的多個幀組成一個圖像集合。與文獻[13,15,17,24]類似,隨機選擇各個人體的一種步態(tài)視頻作為畫廊圖像集,其余3種步態(tài)作為測試集。從每個畫廊視頻中隨機選擇50個幀,利用文獻[27]中的Viola-Jones臉部檢測算法自動檢測各個圖像幀中的人臉區(qū)域。與文獻[18]類似,本文按40×40分辨率對圖像再次采樣,并轉(zhuǎn)換為灰度圖像。利用直方圖均衡化方法增加圖像對比度。與文獻[22-24]不同,本文沒有使用任何LBP特征,而是對原始圖像進行實驗,在式(12)中設(shè)置α=0.2。重復(fù)10次實驗,每輪實驗隨機選擇不同的畫廊和測試圖像集,以增加本文測試環(huán)境的多樣性。表1所示為不同算法對CMU人體識別數(shù)據(jù)集的平均分類精度和標(biāo)準(zhǔn)差。可以看出,本文算法的精度遠高于其他參數(shù)化算法和非參數(shù)化算法。
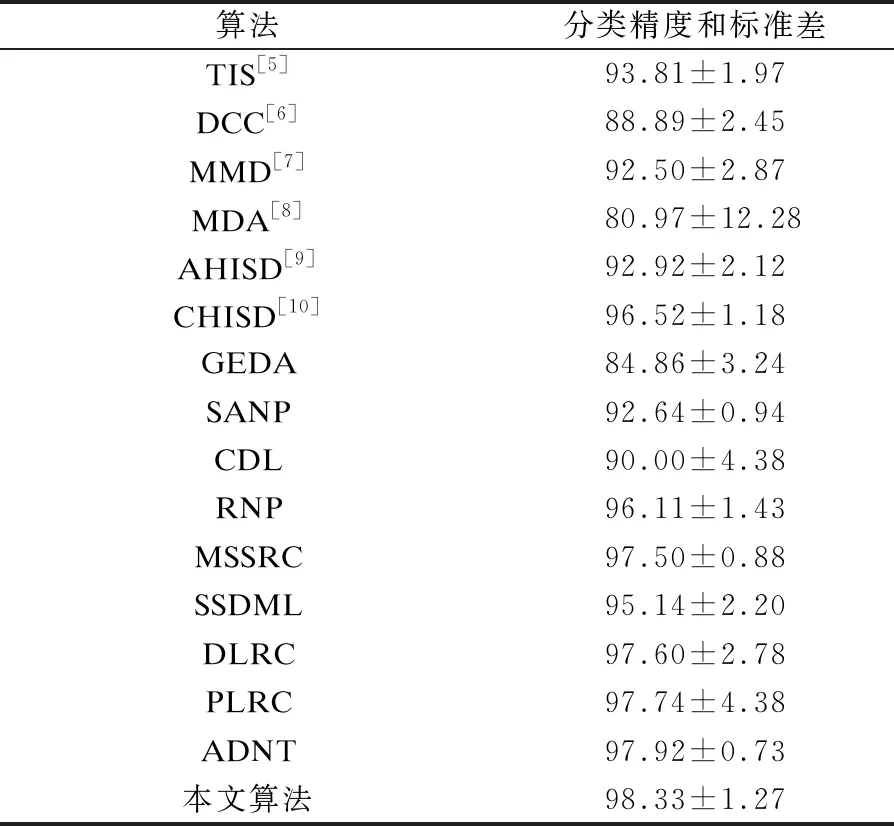
表1 各種算法對CMU-MoBo人體識別數(shù)據(jù)集的平均分類精度和標(biāo)準(zhǔn)差
4.2 YouTube名人數(shù)據(jù)集上的分類結(jié)果
YouTube名人數(shù)據(jù)集包含由47位名流和政客構(gòu)成的1 910個視頻片斷,如圖3所示,其為目前規(guī)模較大的圖像集分類數(shù)據(jù)集。從YouTube下載的這些真實視頻噪聲較大、分辨率較低、錄制視頻時壓縮率較高。與文獻[13-15,17,26]類似,本文實驗采用5折交叉驗證策略:將數(shù)據(jù)集劃分為5個部分,保證不同部分的重疊交叉最小化。每部分包含423個視頻片斷,每個人體為9個視頻片斷,其中,隨機選擇3個片斷作為畫廊視頻集,其他6個作為單獨的測試集。采用文獻[24]中的方法對所有被跟蹤的人臉圖像按分辨率30×30進行重采樣,并將其轉(zhuǎn)換為灰度圖像,通過直方圖均衡化方法提高圖像的對比度。從每部分數(shù)據(jù)集中每個人體的3個畫廊視頻中隨機選擇20個圖像作為畫廊數(shù)據(jù)集,如果某個畫廊視頻片斷的視頻幀數(shù)量少于20個,則該視頻的所有圖像均作為畫廊數(shù)據(jù)集,則每個畫廊數(shù)據(jù)集最多有60個圖像,在式(12)中設(shè)置α=10.5。重復(fù)10實驗,每次實驗的畫廊圖像、畫廊圖像集和測試圖像集均隨機選擇且各不相同。表2所示為不同算法對YouTube數(shù)據(jù)集的平均分類精度和標(biāo)準(zhǔn)差。可以看出,本文算法的精度高于其他所有參數(shù)化算法和非參數(shù)化算法,ADNT算法分類精度也比較理想,但本文算法使用的訓(xùn)練數(shù)據(jù)量遠低于ADNT算法,運行速度更快。此外,本文算法無需對任何參數(shù)進行微調(diào),也不需要參數(shù)訓(xùn)練,因此,其更適用于真實應(yīng)用場景。

圖3 YouTube名人數(shù)據(jù)集

表2 各種算法對YouTube數(shù)據(jù)集的平均分類精度和標(biāo)準(zhǔn)差
4.3 UCSD/Honda數(shù)據(jù)集上的分類結(jié)果
UCSD/Honda數(shù)據(jù)集包含20個人體的59個視頻,每個人體有1個~5個視頻。該數(shù)據(jù)集的主要作用是作為標(biāo)準(zhǔn)的視頻數(shù)據(jù)集,對各種人臉跟蹤和識別算法進行性能評估,其所有視頻均有嚴重的搖頭和姿態(tài)變化,另外,部分視頻序列存在局部遮擋現(xiàn)象。本次實驗設(shè)置與文獻[13-15,17,24]相同,利用文獻[27]中的Viola-Jones人臉檢測算法自動檢測各個視頻幀的人臉。與文獻[24]類似,本文對檢測出的人臉圖像按分辨率20×20進行重采樣并轉(zhuǎn)換為灰度圖像,通過直方圖均衡化方法提高圖像的對比度。將圖像與均值圖像相減然后與標(biāo)準(zhǔn)差相除,實現(xiàn)圖像的標(biāo)準(zhǔn)化。從各個人體中隨機選擇一個視頻作為畫廊圖像集,將其余視頻作為測試圖像集。為了保證畫廊圖像數(shù)量遠低于像素點數(shù),從各個畫廊視頻中隨機選擇少量視頻幀,比如50個。在式(12)中設(shè)置α=0.2。為了保證實驗得分的穩(wěn)定性,重復(fù)進行10實驗,每次實驗的畫廊圖像、畫廊圖像集和測試圖像集均隨機選擇且各不相同。表3所示為不同算法對UCSD/Honda數(shù)據(jù)集的平均分類精度和標(biāo)準(zhǔn)差。從中可以看出,即使采用極少量的畫廊圖像,本文算法的分類精度也較高。

表3 各種算法對UCSD/Honda數(shù)據(jù)集的平均分類精度和標(biāo)準(zhǔn)差
4.4 ETH-8數(shù)據(jù)集上的分類結(jié)果
ETH-8數(shù)據(jù)集由蘋果、梨子、西紅柿、奶牛、狗、馬、轎車和茶杯8種對象組成,每種類別有8個不同的圖像集,每個圖像集包含從不同角度拍攝的41幅圖像,如圖4所示。本文實驗只采用經(jīng)過修剪后只包含對象且沒有邊緣區(qū)域的圖像,采用文獻[24]的實驗設(shè)置,按照分辨率32×32對圖像進行重采樣,并將其轉(zhuǎn)換為灰度圖像,通過與均值圖像相減以及與標(biāo)準(zhǔn)差相除進行圖像的標(biāo)準(zhǔn)化。與文獻[13-15,17,26]類似,隨機選擇各個圖像類別的5個圖像集作為畫廊圖像集,其余5個圖像集作為獨立的測試圖像集,在式(12)中設(shè)置α=0.2。實驗重復(fù)10次,每次實驗均隨機選擇不同的畫廊和測試圖像集。表4所示為不同算法對ETH-8數(shù)據(jù)集的平均分類精度和標(biāo)準(zhǔn)差。從中可以看出,本文算法的性能與ADNT算法接近。

圖4 ETH-8數(shù)據(jù)集

表4 各種算法對ETH-8數(shù)據(jù)集的平均分類精度和標(biāo)準(zhǔn)差
4.5 低分辨率條件下的實驗結(jié)果
利用分辨率更低的圖像進行實驗,進一步評估本文算法與ADNT算法的性能。實驗設(shè)置與4.4節(jié)相同,對于ADNT算法,采用文獻[24]中相同的參數(shù)設(shè)置。實驗重復(fù)10次,每次均隨機選擇不同的畫廊和測試圖像集。表5給出了2種算法的平均分類精度和標(biāo)準(zhǔn)差。從表5可以看出,對于CMU數(shù)據(jù)集,當(dāng)圖像分辨率降低時,本文算法的分類精度仍然有所提升。對于UCSD/Honda數(shù)據(jù)集,當(dāng)圖像分辨率降低時,本文算法的分類精度也非常理想。對于ETH-8數(shù)據(jù)集,圖像分辨率為20×20時,本文算法的分類精度最優(yōu)。綜上,雖然圖像分辨率發(fā)生變化,但本文算法的分類精度沒有受到顯著影響。另外,對于分辨率較低的目標(biāo)圖像,本文算法的性能總是優(yōu)于ADNT算法,這表明本文算法更適用于低分辨率應(yīng)用場景。

表5 2種算法對低分辨率圖像的平均分類精度和標(biāo)準(zhǔn)差
5 計算時間分析
以ETH-8數(shù)據(jù)集為實驗對象,對所有算法在該數(shù)據(jù)集上的計算時間進行測試,表6所示為CPU RAM條件下各算法所需的訓(xùn)練時間和每個圖像進行分類所需的測試時間的比較結(jié)果,其中,NR表示不需要訓(xùn)練。從中可以看出,與其他算法相比,本文算法的運行效率最高,這主要是因為:
1)本文算法不需要任何訓(xùn)練。
2)雖然本文算法根據(jù)所有畫廊圖像集合對測試圖像集中的各個圖像進行重建,但是采用了高效的矩陣表示法,使得本文算法的效率優(yōu)于其他算法。

表6 不同算法進行圖像集分類時的計算時間比較
6 性能分析
從表1可以看出,DLRC算法、PLRC算法、ADNT算法和本文算法的圖像集分類性能遠優(yōu)于其他算法。其中,本文算法和ADNT算法的平均分類精度接近,高于DLRC算法和PLRC算法,這主要是因為:
1)本文算法與DLRC算法和PLRC算法具有顯著差異。DLRC算法將訓(xùn)練和測試圖像集看作高維空間的子空間,利用測試圖像集和訓(xùn)練圖像集間的距離來確定測試圖像集的類別。為了確定子空間之間的距離,DLRC算法利用各個圖像集的最后一幅圖像以及訓(xùn)練圖像集和測試圖像集間的變化來求解線性回歸問題。PLRC算法是DLRC算法的拓展,其不采用每個圖像集的最后一幅圖像,而是利用均值圖像以及相關(guān)子空間和非相關(guān)子空間概念進行圖像分類。DLRC和PLRC算法均需要測試圖像集和訓(xùn)練圖像集中的圖像總量遠低于特征向量中的特征數(shù)量,而這一要求有時無法滿足。除了畫廊圖像集,這2種算法還將測試圖像集作為回歸量,導(dǎo)致在測試期間容易發(fā)生矩陣缺秩問題。另外,這2種算法對部分數(shù)據(jù)集還采用了LBP特征。因此,DLRC算法和PLRC算法采用原始圖像時表現(xiàn)出的性能不具有普遍性。
2)與DLRC和PLRC算法不同,本文算法對測試圖像集中的各個圖像獨立對待,并將其看作高維空間中的點。本文算法根據(jù)畫廊子空間對各個測試圖像進行重建,并采用加權(quán)投票以及原始測試圖像和重建測試圖像間的歐氏距離進行目標(biāo)分類,加權(quán)投票策略增加了本文算法面對噪聲以及測試圖像集中部分異常數(shù)據(jù)時的魯棒性。本文算法對測試圖像集中的圖像數(shù)量不做任何要求。利用原始圖像進行仿真,結(jié)果驗證了本文算法的普遍性。與DLRC和PLRC算法相反,只要在構(gòu)建畫廊圖像集時解決回歸量Qc的奇異性問題,本文算法在測試階段便不會發(fā)生矩陣缺秩問題,原因是算法沒有利用測試圖像集作為回歸量。另外,本文算法既可同時處理所有圖像集,也可每次處理一幅圖像然后對分類決策進行實時更新,因此,其適用于現(xiàn)場視頻監(jiān)控任務(wù)。本文算法的精度優(yōu)于多數(shù)參數(shù)化算法和非參數(shù)化算法。
3)ADNT算法對YouTube和ETH-8數(shù)據(jù)集的精度更高,但是其需要大量的訓(xùn)練數(shù)據(jù)和人工LBP特征。另外,ADNT算法利用受限Boltzman機器方法進行參數(shù)初始化,參數(shù)微調(diào)的時間較長。相比而言,本文算法只需少量訓(xùn)練數(shù)據(jù),即使采用原始圖像,算法性能也與ADNT相當(dāng)。如果圖像分辨率較低,本文算法的性能優(yōu)于ADNT算法,測試階段本文算法效率比ADNT算法快10倍。當(dāng)有新的數(shù)據(jù)需要處理時,本文算法也具有良好的可拓展性。
綜上,本文算法對訓(xùn)練數(shù)據(jù)的要求較少,對低分辨率數(shù)據(jù)具有較好的處理效果,因此,其更適用于可用訓(xùn)據(jù)數(shù)據(jù)量有限、對決策效率要求高的應(yīng)用場景。
7 結(jié)束語
本文提出一種改進的圖像集分類算法。通過線性回歸分類技術(shù)結(jié)合畫廊圖像集對測試圖像集中的圖像進行重建,利用累積加權(quán)重建誤差確定測試圖像集的類別。該算法對訓(xùn)練數(shù)據(jù)的需求量較少,面對不同的數(shù)據(jù)集時具有良好的普適性,在分辨率較低、訓(xùn)練數(shù)據(jù)較少的條件下仍然能夠取得較好的分類性能。在常見的圖像分類數(shù)據(jù)集上進行仿真,結(jié)果表明,本文算法測試階段的效率比ADNT算法高10倍,且其精度與ADNT算法相差不大。下一步將研究并設(shè)計一種基于最優(yōu)路徑搜索的圖像分類方法,以提高分類精度和時間效率。
猜你喜歡
西北民族大學(xué)學(xué)報(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
