基于隨機森林的溢漏實時判斷方法研究
2020-07-21 01:56:50史肖燕周英操趙莉萍蔣宏偉
鉆采工藝 2020年1期
關鍵詞:特征
史肖燕, 周英操, 趙莉萍, 蔣宏偉
(中國石油集團工程技術研究院有限公司)
井漏和溢流是影響鉆井施工安全最為常見的兩種井下復雜事故。井漏和溢流不僅會帶來嚴重的儲層損害,增加勘探開發投入成本,造成油氣開發效率低下,一旦控制不力,還會誘發卡鉆、井塌、井噴等重大惡性事故,造成損失及負面社會影響。因此,鉆井過程中溢流、漏失的實時識別判斷具有重要意義。
目前,國內外在溢流、漏失監測方面展開了較多研究,形成的技術主要有:井口監測技術、井下隨鉆監測技術和人工智能監測技術。井口監測技術成熟,能比較準確地監測出溢流和漏失,但這種方法的監測結果存在滯后性,不能很好地解決高壓氣井、深水鉆井等特殊環境下的井下溢流、漏失監測問題。井下隨鉆監測方法能夠快速、早期監測到溢流和漏失,但成本較高,并且隨鉆測量儀器存在失效的風險。隨著信息技術和人工智能技術快速發展,國內外研究人員把人工智能技術應用到溢流、漏失的監測中,監測結果更為準確,但這些人工智能的方法普遍存在著建模較為復雜,推廣較難的問題。
近年來,以數據為驅動的機器學習算法在社會各領域得到了廣泛的應用,其中最重要的算法之一隨機森林具有建模較為簡單、調節參數少、預測準確率高和強魯棒性的特點。本文采用隨機森林的方法對鉆井實時測量數據進行建模,來對溢流、漏失進行實時識別判斷。
一、隨機森林方法
隨機森林由Breiman L在2001年提出,是一個可處理高維度與非線性樣本的分類器組合模型。大量的理論和實證研究都證明了隨機森林具有很高的預測準確率,對異常值和噪聲具有很好的容忍度,并且不容易出現過擬合。因此,自其被提出以來,在醫學、生物信息、管理學等領域得到了廣泛應用。隨機森林分類的基本思想[1-2]:首先,利用自助法(Bootstrap)抽樣技術從原始訓練集抽取k個樣本集;然后,對k個樣本集分別建立k個決策樹模型,得到k種分類結果;最后,對每個新記錄根據k種分類結果進行投票表決決定其最終分類。
二、基于隨機森林的溢漏實時判斷方法
在鉆井過程中,當有溢流、漏失發生時,在鉆井測量參數上會有所體現;例如溢流發生時,進出口流量之差會增加,立壓降低,大鉤負載緩增;漏失發生時,進出口流量之差減少,立管壓力降低,井底環壓降低;由此可見,鉆井測量參數與溢流、漏失存在著相關關系。可把溢流、漏失的識別問題建模成以鉆井測量參數為自變量,是否發生溢流、漏失為結果變量的分類模型。本文選用隨機森林方法對溢流、漏失的實時識別進行分類建模,通過大量歷史數據對隨機森林進行訓練,并對新的實時輸入數據作出是否發生溢流、漏失的分類。
基于隨機森林的溢流、漏失實時判斷方法的流程如圖1所示。
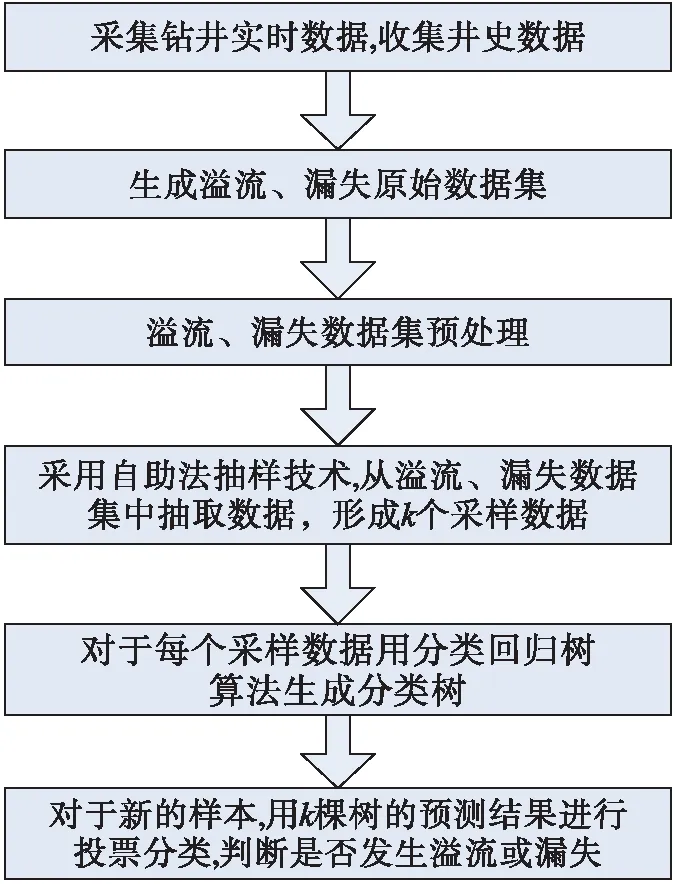
圖1 基于隨機森林的溢流、漏失實時判斷方法的流程圖
1. 生成原始數據集
隨機森林是有監督的機器學習算法,用于訓練算法的樣本數據需要有輸入變量和結果變量。在本文的模型中,輸入變量即以時間為索引的鉆井測量參數,結果變量為是否發生溢流或漏失。因為溢流、漏失的信息一般以文本的方式記錄在井史數據中,因此需要對文本數據進行自動識別,并根據文本中溢流、漏失事故的發生和持續時間,生成以時間為索引的溢流、漏失數據;合并以時間為索引的鉆井測量參數和溢流、漏失數據,即可生成用于隨機森林算法的原始數據集。生成的原始數據集是以時間為索引的多維特征數據和分類結果,特征包括:入口流量、出口流量、PWD環空壓力、PWD環空溫度、大鉤載荷、井深、鉆頭深度、總池體積、立管壓力、轉速、鉆壓、鉆井液出口密度和鉆井液出口溫度;數據的分類結果為離散值:0代表無事故發生,1代表有溢流發生,2代表有漏失發生。
2. 數據預處理
本文的原始數據集是以時間先后為順序排列的數據集,很難直接用于溢流、漏失實時識別的建模,為了讓數據適合于隨機森林的建模,需要對數據進行預處理。
首先,溢流、漏失的發生導致原始數據集中各特征數據發生變化,因此各特征數據的相對變化量能更好的應用于隨機森林中決策樹的創建,而且使用特征數據的相對變化量,可綜合多口井的數據,形成更大數據量的歷史數據集。對于某一特征數據,相對變化量的計算公式為:
(1)
式中:A(Ti)—特征數據列A在Ti時間點的值;A(Ti-1)—特征數據列A在Ti-1時間點的值。
其次,在不同的工況下,當溢流和漏失發生時,各特征數據的變化情況不同,因此根據原始數據集中的數據,對工況進行自動識別,有助于下一步決策樹的生成。本文自動識別的工況包括:鉆進、起鉆、下鉆和其它(包括接單跟,卸單根和鉆井液循環等)。鉆井工況計算方法為:
在時間Ti,若HDEP(Ti)=BDEP(Ti),HDEP(Ti)> HDEP(Ti-1),則鉆井狀態DS(Ti)為鉆進。
在時間Ti,若HDEP(Ti)>BDEP(Ti),BDEP(Ti)>BDEP(Ti-1),則鉆井狀態DS(Ti)為下鉆。
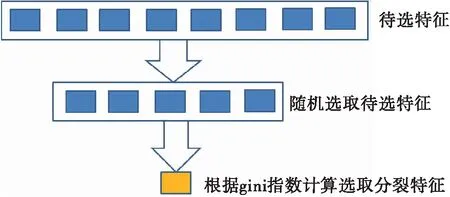
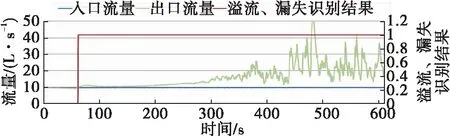
在時間Ti,若HDEP(Ti)>BDEP(Ti),BDEP(Ti) 否則, 鉆井狀態為其它。 其中,HDEP(Ti)為Ti時刻的井深,HDEP(Ti-1)為Ti-1時刻的井深,BDEP(Ti)為Ti時刻的鉆頭深度,BDEP(Ti-1)為Ti-1時刻的鉆頭深度。 再次,把相關特征數據進行簡單的計算,能與溢流、漏失的發生建立更直接的關系,例如出口流量和入口流量之差,可更直接反應是否有溢流、漏失發生。因此把出入口流量差加入到輸入特征集中。 對于預處理之后的溢流、漏失數據集,隨機森林采用Bootstrap重采樣方法,生成k個用于決策樹生成的樣本集,k由所需建立的決策樹的數量確定。隨機森林中決策樹的數量對預測結果有重要影響,本文將在現場實例中進行討論。Bootstrap方法的基本思想為[3]:從容量為N的原始樣本集中進行有放回的重復采樣,采樣樣本的容量也為N,每個觀測對象被抽到的概率為1/N,每次采樣構成的子樣本集稱為Bootstrap樣本集。 對于上述步驟生成的每一個樣本集,隨機森林采用CART決策樹來對訓練數據進行分類。CART算法采用一種二分遞歸分割的技術,總是將當前樣本集分割為兩個子樣本集,使得生成的決策樹的每個非葉節點都只有兩個分支,因此CART算法生成的決策樹是結構簡潔的二叉樹,可用于分類和回歸任務。在創建分類樹遞歸過程中,CART每次都選擇當前數據集中具有最小gini信息增益的特征作為節點劃分決策樹。gini指數是一種不等性度量,可用來度量任何不均勻分布,是介于0~1之間的數,0代表完全相等,1代表完全不想等。分類度量時,總體內包含的類別越雜亂,gini指數就越大。gini指數的計算公式為: (2) 式中:pj—類別j在樣本T中出現的頻率; nj—樣本T中類別j的個數。 在每個節點分裂時,計算不同特征和不同閾值相對應的gini信息增益,選擇最小的gini指數對應的特征和閾值,對特征空間進行二元分裂。對節點進行二元分裂時,gini信息增益的計算公式為: (3) 式中:s1—T1中樣本的個數;s2—T2中樣本的個數。 不同于傳統的CART樹,隨機森林在CART樹的創建過程中,采用了隨機特征的選擇,即在每一個結點隨機選擇一小組輸入變量(m個特征,m<總待選特征個數)進行分割,如圖2所示。 圖2 決策樹創建過程中的特征選擇 對于新的輸入樣本,隨機森林根據CART算法所生成的k棵決策樹的投票結果,判斷是否有溢流、漏失發生。 本文以塔里木油田的某復雜井為例,用基于隨機森林的智能方法對溢流、漏失進行實時識別。用于隨機森林算法訓練的歷史數據從該井的鄰井數據中獲取,訓練數據集包括正常鉆井樣本,溢流樣本和漏失樣本。 對該井的鉆井測量參數進行實時監測的開始時間為2018年2月11日21∶08,如圖3所示。從21∶09開始,該井停止鉆進,并打開泵進行循環。由圖3可見從21∶09開始,出口流量大于入口流量;總池體積從21∶19分開始明顯增加,到21∶25達到峰值,為147.9 m3,增量為0.9 m3,可判斷有溢流發生。 圖3 鉆井實時測量參數 圖4為用隨機森林的方法對溢流進行實時識別的結果,0代表正常工況,1代表溢流工況,2代表漏失工況。由圖4可見,系統自動在溢流發生初期(21∶09)即對溢流進行了自動識別,這比用傳統的總池體積增加法來判斷溢流提早了16 min,實現了溢流監測的及時性;在21∶24,出口流量等于入口流量,溢流結束,系統亦進行了自動識別,識別的結果為正常工況。 圖4 基于隨機森林的溢流實時識別 從2018年2月16日00∶16開始,對該井的鉆井測量參數進行實時監測,如圖5所示。從00∶16開始,該井邊鉆邊漏,出口流量小于入口流量。從00∶35開始,總池體積明顯減少,到00∶39,總池體積從原來的129.3 m3降低到128.1 m3,減少了1.2 m3,可判斷漏失發生。 圖6為用隨機森林的方法對漏失進行實時識別的結果。由圖6可見,系統自動在溢流發生初期(00∶16)即對漏失進行了自動識別,這比用傳統的總池體積減少法來判斷漏失提早了23 min,實現了漏失監測的及時性。 圖5 鉆井實時測量參數 圖6 基于隨機森林的漏失實時識別 用隨機森林的方法建模時,一個重要參數為決策樹的數量,此參數的選擇對于隨機森林的預測準確性有重要影響。因此本文對此參數的選擇進行討論。 圖7~圖10展示了用不同的決策樹數量,對發生在2月11日20∶17開始的溢流進行識別的結果。由圖7可見,當決策樹數量為10時,溢流的識別結果里有較多的錯誤,隨著決策樹數量的增加,溢流識別結果越來越準確,到決策樹數量為100時,識別結果趨于穩定。因此選用100為決策樹數量可得到較為準確的預測結果。 圖7 決策樹數量為10時的溢流識別圖 圖8 決策樹數量為20時的溢流識別圖 本文還用隨機森林的方法對用于溢流漏失識別的14個輸入特征的重要性進行分析,其中,流入流出差對于溢流漏失識別的重要性最高,這符合當前主要的溢流、漏失識別的判斷依據;重要程度接近于0的鉆壓變化量、轉速變化量、泵沖變化量和出口溫度變化量可從用于隨機森林建模的輸入特征中剔除,以提高計算速度。 圖9 決策樹數量為50時的溢流識別圖 圖10 決策樹數量為100時的溢流識別圖 (1)隨機森林作為新興起的集成學習算法,具有預測準確度高、對噪聲的容忍度大,計算速度快等優點,這些優點使其適用于溢流、漏失的實時識別判斷。 (2)現場實例顯示,通過對鉆井實時測量數據的合理預處理,結合隨機森林的方法,溢流、漏失可在早期被準確識別。 (3)由于隨機森林可以處理大量的特征數據(輸入數據),并可在決定類別時,評估特征的重要性;本文利用隨機森林對初選的特征進行重要性分析,結果表明鉆井液流入流出差對于溢流、漏失的判斷具有重要影響。3. 生成子數據集
4. 用CART樹進行分類
5. 溢流、漏失識別
三、現場實例
1. 實驗數據
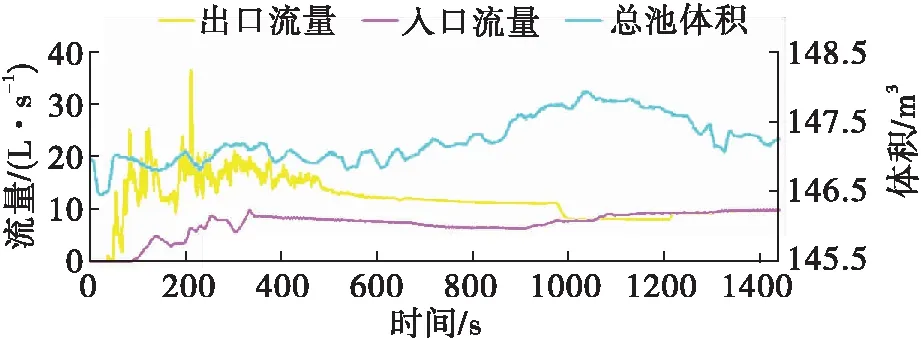
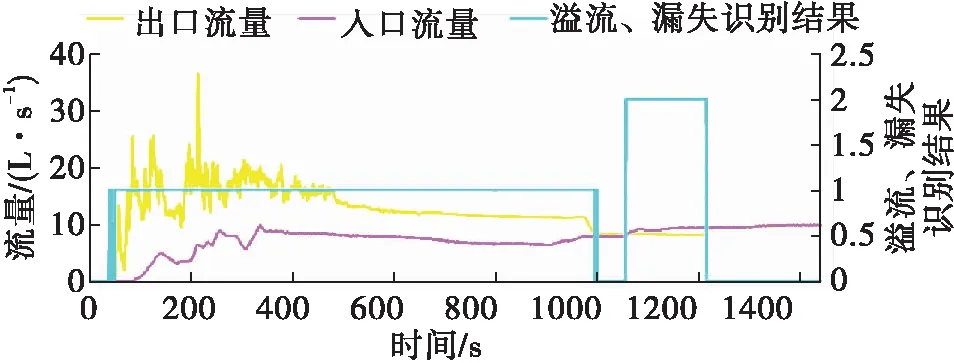
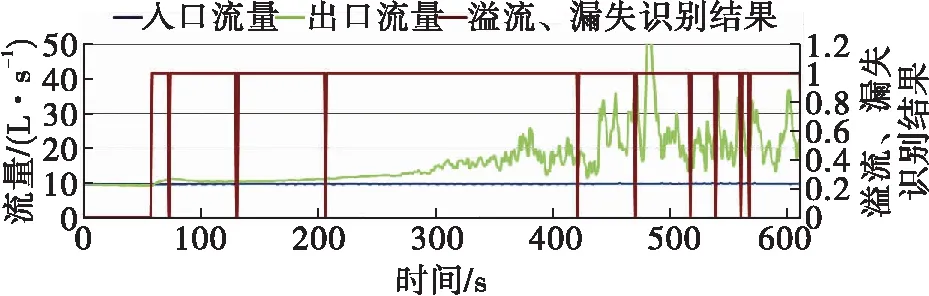
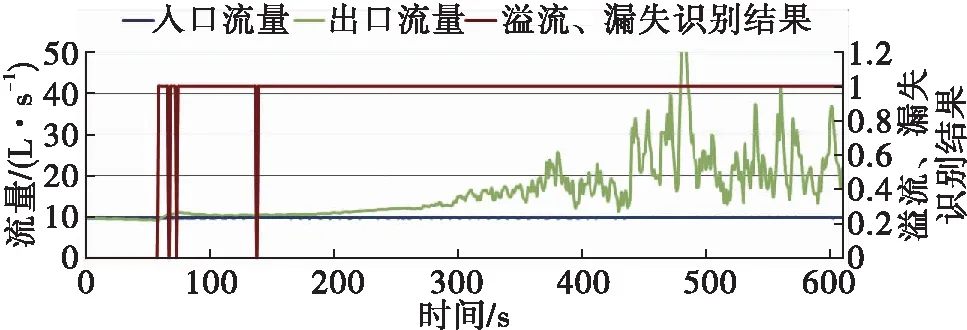
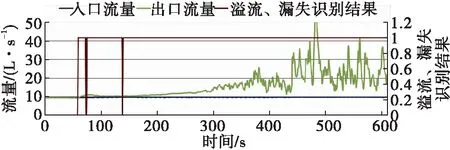
2. 溢流識別
3. 漏失識別

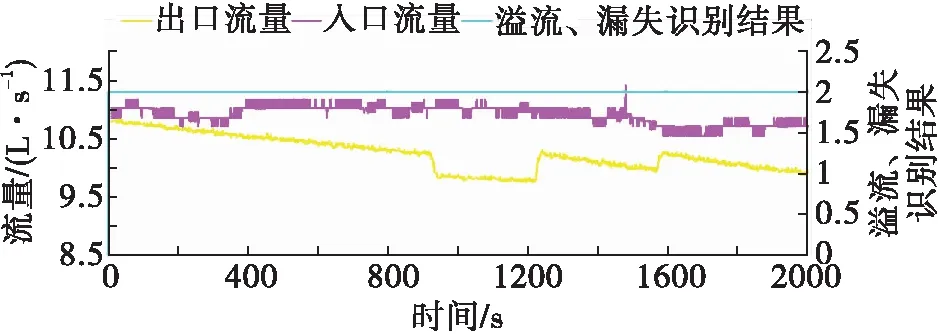
4. 建模參數的選擇
5. 變量的重要性分析
四、結論
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
