基于集成學習的城市軌道交通乘客路徑選擇建模
2020-07-13 08:53:12王璐瑤
鐵道學報 2020年6期
關鍵詞:模型
王璐瑤,蔣 熙
(北京交通大學 軌道交通控制與安全國家重點實驗室,北京 100044)
在城市軌道交通網絡化運營中,準確掌握乘客的路徑選擇行為規律是合理制定運輸組織計劃、協調各線路運營狀態的重要基礎。如何構建符合實際的路徑選擇模型一直是理論與應用研究中的一個熱點與難點,相應的建模方法可分成基于行為機理的建模和基于數據的建模兩大類。很多學者進行了基于隨機效用及相關理論的離散選擇建模研究,文獻[1-5]屬于第一類中的代表方法。然而,準確反映乘客行為的機理建模及參數設置一直是一個難題,尤其是在復雜運營條件下,基于行為機理的路徑選擇建模方法開始體現出其固有的局限性。基于數據的建模方法則可以運用機器學習方法從數據中挖掘乘客路徑選擇規律,從而脫離行為機理的束縛,建立起更準確、更符合實際的路徑選擇模型。道路交通領域的學者開展了相關研究,文獻[6-8]研究了車輛的路徑選擇神經網絡模型和支持向量機模型;對于城市軌道交通的路徑選擇問題,文獻[9]構建了基于決策樹的乘客個體出行路徑隨機生成模型,但僅適用于某特定日期及既有OD對;文獻[10]構建了基于支持向量機的路徑選擇模型,但未能考慮不同乘客構成的影響,模型適應性和靈活性還有待提高;文獻[11]針對乘客的選擇傾向研究了路徑推薦算法,但并未面向運營決策給出路徑選擇概率。因此,在既有研究的基礎上,本文面向網絡化運營特點研究城市軌道交通乘客路徑選擇機器學習問題,圍繞路徑選擇的核心影響要素,研究更加準確并符合實際的路徑選擇機器學習建模方法,以適應實際運營決策對乘客路徑選擇建模的需求。
1 方法的提出
1.1 路徑選擇建模的機器學習問題分析
城市軌道交通系統中,具有不同屬性的乘客在出行時,往往會依據各自的出行經驗、出行需求、所獲取的信息,在某OD對的多條路徑中進行各個方案的比較和選優,選出最符合其自身需求的“最優”路徑方案。本文將影響OD對間各路徑選擇概率的主要因素歸納為客流成分構成、各路徑的屬性、OD特性等方面。
(1)客流成分構成。主要指OD對之間由多種不同屬性乘客構成的客流及其類別。乘客屬性中,除了性別、年齡、教育、職業、收入等基本屬性外,與出行目的相關的特性對路徑選擇的影響也需要格外重視。
(2)各路徑方案的屬性。本文稱為路徑屬性,主要指各路徑的乘車時間、換乘時間、換乘次數、擁擠程度等方面。
(3)OD基本特性。主要包括OD的換乘可達性及OD旅行時間等。經分析可見,乘客在進行路徑選擇時,路徑屬性在乘客路徑選擇中發揮的作用還可能因OD而異[10]。例如,相對于較長耗時的OD,旅行時間較短的OD內不同路徑間的出行時間差對選擇概率的影響更大;乘客對增加一次換乘的敏感度也因OD的時間距離和OD內各路徑的最少換乘次數有關。
構建基于機器學習的乘客路徑選擇模型,需要從數據中挖掘上述影響因素對乘客路徑選擇概率的作用關系與規律。其中,乘客出行路徑選擇數據主要通過調研、手機定位等方式進行采集,目前國內多個城市已經在實際運營中不斷積累并形成了一定規模的數據可供使用。此外,通過AFC刷卡數據、列車時刻表數據,可以直接抽取或者經處理后形成路網內各個OD的基本特性以及各路徑方案屬性。然而,各OD之間的客流成分構成信息卻無法從既有運營數據中獲取,另外,在全網范圍內進行各OD客流調查又存在較大難度。因此,在缺乏客流構成一手數據情況下,如何在建模和預測時納入這一要素,從而體現客流構成的不同對路徑選擇結果的影響,是本文在確立建模方法時需要考慮的關鍵問題。
1.2 基于集成學習的路徑選擇建模方法
在相同條件下,不同客流成分構成的路徑選擇結果存在一定差異,而一個OD對間的客流并非完全確定,其構成往往呈現出一定的隨機分布規律。這就增加了路徑選擇建模的復雜度,如果僅僅依靠單一的機器學習模型和算法的優化則難以建立高效而準確的模型。因此,本文引入集成學習方法,構建若干子學習器并按一定方式集成為考慮了異質性的路徑選擇機器學習模型。
基于集成學習的建模,首先需要依據某種策略劃分子學習器,結合本文的出發點,基于客流成分構成的異質性進行子學習器的劃分就成為自然的選擇。針對無法直接獲取客流成分信息所帶來的難題,分析發現,路網中不同OD對之間的客流構成與起、終點站所在的區域特性有關。例如,北京地鐵中,早高峰時段由天通苑、回龍觀等大型居住區附近站點進站的通勤客流占比遠大于由北京站、北京南站進站的客流,而在天安門、王府井等站點出站客流中,以旅游商業為主要出行目的的客流占比遠大于從國貿、西二旗等大型工作區站點出站的客流占比。因此,本文將聚類算法與集成學習相結合,基于軌道交通站點特性與客流構成間的內在關聯性進行軌道站點聚類,將客流成分構成這一隱性要素轉化為站點特性這一顯性因素,并將其用于子學習器劃分與模型構建,形成了基于客流異質性的路徑選擇集成學習方法,見圖1。
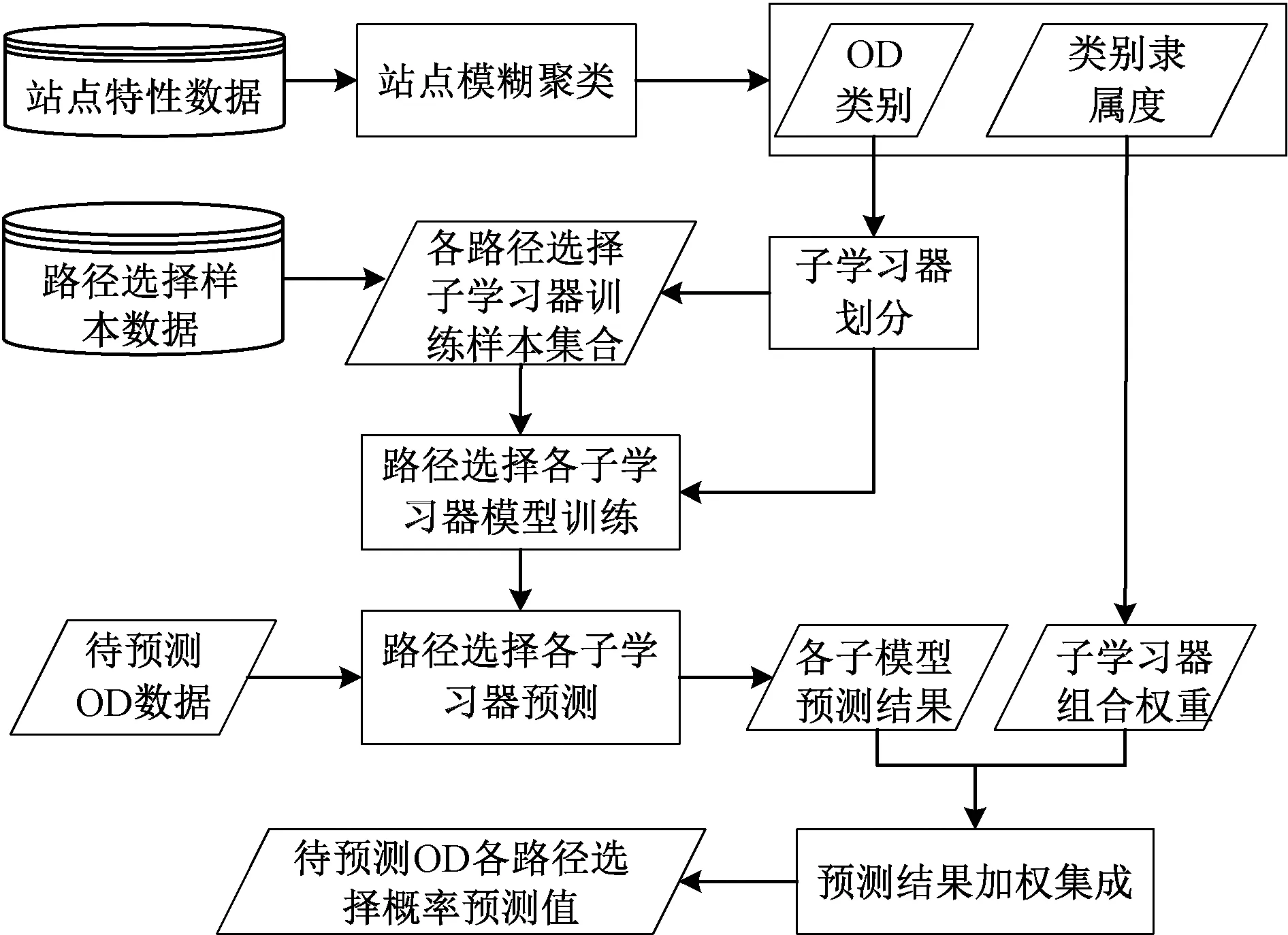
圖1 基于客流異質性的路徑選擇集成學習方法
首先,進行地鐵站點聚類,將路徑選擇模型劃分為不同OD類別下的路徑選擇子學習器模型。然后,按照聚類結果抽取各個類別的訓練樣本數據,選擇適當的機器學習算法構建路徑選擇子學習器。最后,對任一給定的OD及路徑集,當需要預測各路徑選擇概率時,將該OD對應的類別隸屬度進行變換后形成權重系數,將各子學習器分別預測后形成的結果進行加權集成,輸出最終預測結果。
2 模型建立
2.1 軌道交通車站聚類
運用聚類方法將軌道交通車站劃分為若干類別并給出隸屬度,可反映不同OD對之間客流構成的異質性。為了反映客流構成與站點特性之間的內在關聯,從車站周邊土地利用、進出站客流量特性、客流票卡類型等方面選擇并確定聚類要素,同時考慮數據獲取的可行性,選取了如下16個維度的聚類變量:
(1)F1、F2分別為該站點周圍居住類POI及辦公類POI在總POI中的百分比,可根據電子地圖中POI數量進行計算。
(2)F3表示該站點周圍是否有大型景點,0表示無、1表示有。
(3)F4為該站點距離市中心的直線距離,m。
(4)F5為軌道路網中該站點的可達性度量,用20 min內從該站可到達的其他站點總數表征。
(5)F6、F7、F8、F9分別為該車站工作日早晚高峰的客流量占比,分別用早高峰進站量/全天進站量、晚高峰進站量/全天進站量、早高峰出站量/全天出站量、晚高峰出站量/全天出站量進行計算;F10為工作日與周末的進站客流量百分比。這些變量表征該站客流的時間分布特征,可利用AFC數據統計得到。
(6)F11、F12分別為該車站工作日、周末一票通乘客所占的百分比,利用AFC數據統計得到。
(7)F13、F14、F15、F16分別為該車站在工作日、周末、進站、出站的客流高峰所在時段,利用AFC數據統計得到。
為了獲得站點類型以及各站屬于某一類別的概率,選擇模糊c-均值算法(FCM)進行地鐵站點聚類,主要流程如下:
(1)聚類數據提取與標準化
主要以電子地圖數據與AFC數據為數據源,對路網內各車站的上述聚類變量進行數據提取,并采用Z-score[12]方法處理后形成標準化的各站點聚類數據。
(2)變量相關性檢驗
采用KMO檢驗和Bartlett檢驗方法檢驗聚類變量之間的相關性,若檢驗通過則可對原始聚類變量進行下一步聚類因子提取。
(3)運用FCM算法進行聚類
FCM是一種基于目標優化的聚類方法,將各樣本點進行模糊劃分,用模糊隸屬度來表征各個樣本點屬于各個組的程度,并通過不斷迭代,使各個樣本點距模糊聚類中心的加權距離之和達到最小。
運用FCM算法對路網各車站進行聚類,優化目標為
(1)
式中:n為路網中聚類樣本車站的總數;i為車站,i=1,2,…,n;c為聚類數目;j為站點類別編號,j=1,2,…,c;uij為樣本車站i屬于第j類的模糊隸屬度;m為加權指數,在此取2;dij為車站i距離第j類聚類中心的距離,用歐式距離計算。最佳聚類數目c通過最小化類內距離DBI[13]與最大化中心間距CHI[14]的值來確定。具體優化算法在此不贅述。
2.2 基于支持向量回歸機(SVR)的路徑選擇子學習器構建
站點聚類后,對任一O點站類型與D點站類型均可形成一類OD類別。本文利用軌道交通系統中的路徑選擇結果數據,運用SVR進行學習,挖掘路徑選擇影響因素與路徑選擇概率間的作用關系與規律,形成每一種類別OD的路徑選擇子學習器。此機器學習算法通過引入核函數把原有的線性學習器拓展為非線性學習器,該算法不在此贅述。
每個乘客在進行路徑選擇時,總是面對單個OD進行決策,在一個OD對內部的有限路徑集范圍內進行分析、比較和選擇。由此,進行基于SVR的機器學習時,各個樣本的數據集也是以OD對為單位來構建。模型輸入包括該類OD下各個OD的基本特性與各路徑方案特性,模型輸出則為每一OD內各條路徑的選擇概率。
對某一OD類型下的任一OD對p,如前分析,OD內所有路徑的最小換乘次數和平均旅行時間對乘客選擇路徑有重要影響,因此,以這兩項表示該OD對p的OD基本特性S為
S=(cp,tp)
(2)
式中:cp為OD對p所有路徑集的最小換乘次數;tp為OD對p的平均旅行時間。
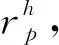
(3)
若OD對p包含w條有效路徑,該OD對的路徑方案屬性矩陣R為
(4)
然而現實系統中不同OD對有效路徑數目可能不相等,這將增加建模的復雜度。本文采用了設置“虛擬路徑”進行路徑集增補的方法來解決這一問題。“虛擬路徑”在實際中并不存在,對任一OD對,可將其定義為換乘次數、乘車時間與路徑長度均為極大值,且其選擇概率為0的“路徑”。假設路網所有OD中最大有效路徑數目為N,對任一擁有w條有效路徑的 OD, 若w 經過路徑增補后,對于路網中某一OD類型,基于SVR的路徑選擇子模型的輸入為該類OD下各個OD樣本數據X的集合,對于其中的任一OD對p,其輸入可表示為 (5) 子模型輸出為該類別OD下各個OD樣本數據Y的集合,對于其中的OD對p,其輸出可表示為 (6) 對任一OD類別的路徑選擇SVR子模型,按下述步驟進行模型訓練: Step0從路徑選擇實際數據中抽取該類別下的所有OD對及各個OD的樣本數據。 Step1采取隨機原則對給定類型OD下的樣本數據進行劃分,形成訓練集與測試集。 Step2選用ε-SVR作為機器學習模型,經訓練形成該類別下的路徑選擇子學習器。 Step3運用測試數據集對訓練好的SVR模型進行評價,將預測值與實際值進行對比并計算誤差。 在某軌道交通路網內(既有的或接入新線后擴展形成的),對設置或更新了相應屬性的任一OD對od(其起點站為o,終點站為d),可運用集成學習方法對各路徑選擇概率進行預測。基于路徑選擇子學習器的集成預測方法的主要流程如下: Step1子學習器樣本劃分與訓練 Step2計算待預測OD對od的類別隸屬度 Step3各子學習器預測 Step4子學習器預測集成 對各個子學習器的輸出概率進行加權結合,獲得集成后的路徑選擇概率向量P為 (8) 基于本研究的可用數據,以2015年北京市軌道交通為背景進行案例分析,當時北京地鐵路網共包含16條線路,231個運營車站,路網拓撲圖見圖2。 圖2 2015年北京軌道交通路網拓撲圖 本文以電子地圖數據與AFC數據為數據源進行數據提取,獲得各站點16維聚類變量的數據集并進行標準化處理及檢驗。進而,運用FCM算法進行模糊聚類,計算得到在聚類數目為5時DBI值最小,CHI值最大,因而最優聚類數目為5。路網各站點聚類結果如下: (1)類4 該類別以工作區站點為主,客流通勤特性明顯。 (2)類3 該類別以居住區類站點為主,客流通勤特征明顯。 (3)類2 該類別屬于職住混合但偏居住類,客流特性較類3復雜。 (4)類1 主要為旅游景區及交通樞紐類站點,客流特性與通勤類有明顯區別。 (5)類0 該類別屬于職住混合但偏工作區類,客流特性較類4復雜。 各類站點在路網上的分布見圖3。圖中,除了少數產業園外,工作類與偏工作的混合類站點基本位于三、四環之間,而城市外圍區域的居住類及偏居住的混合內站點數量多于中心城區,類1中的站點集中于各大景點附近。這一結果與城市實際情況吻合度較高。 可見聚類結果較好地反映了路網各站點在客流成分構成上的相似性與差異性,客流構成的異質性與站點的類別能夠很好地關聯起來,在此基礎上,可進行路徑選擇子學習器的構建。 本文利用北京市軌道交通的乘客路徑選擇數據,經計算得到各個OD基本特性及各路徑屬性信息,以及每條路徑所對應的乘客選擇概率。統計路網中各個OD的最大有效路徑數量,最終將最大有效路徑數目N設為5,對路徑數量小于5的OD設置虛擬路徑進行增補后形成機器學習數據總體樣本集。依據聚類結果,路徑選擇數據樣本被劃分為25個類別,每一類OD中的路徑選擇數據即為一個子樣本,再將其分成測試樣本和訓練樣本,計算樣本對于每個OD類別的隸屬度。 進一步,利用25個子樣本集分別構建相應的路徑選擇SVR模型,訓練出25個子學習器。以居住區類—工作區類(類別3—類別4)的子學習器為例,訓練集中包括1 698個OD的樣本數據,經訓練獲得最優的SVR回歸模型。然后,利用訓練好的SVR回歸模型對測試集中的425個OD進行測試,與實際數據比較,計算得到均方誤差為0.005 996,平均絕對誤差為0.062 121。 對于每一個需要預測的OD對,分別運行訓練好的25個子學習器,以OD類別隸屬度為權重對所有子學習器的預測結果進行加權平均后形成最終預測結果,與實際數據的對比見圖4。 圖4 集成學習的路徑選擇SVR模型預測與實際值的對比結果 經計算得到均方誤差為0.004 911,平均絕對誤差為0.053 835。與子學習器在測試集上的預測結果相比,集成學習的預測結果誤差滿意。 2015年底,北京地鐵14號線中段和昌平線二期2條軌道新線開通運營。新線開通后的路網拓撲與出行路徑均發生了改變,需要在新的條件下進行乘客路徑選擇預測。首先,對新線開通后增加的9個車站進行了重新聚類,并獲得新站點類別及隸屬度,見表1。 然后運用本文方法進行全網OD路徑選擇預測。以方莊至安定門這一新OD為例,將這一OD的基本特性和路徑特性輸入訓練好的每個子學習器,按隸屬度進行加權集成后得到各條路徑的選擇結果,該OD的路徑信息及選擇概率結果見表2。 表1 新站點的類別隸屬度 表2 方莊至安定門間路徑信息及路徑選擇預測結果 由表2可見,新增的方莊至安定門OD有5條路徑,最小換乘次數為2次,最小旅行時間為41.28 min。依據OD基本特征和各路徑特征預測得到各路徑選擇概率,絕大多數乘客選擇前2條路徑,其中,換乘次數最少、乘車時間和路徑長度最短的第1條路徑被選擇概率最高,達到79.89%。 圍繞不同客流構成特性、OD基本特性、路徑集特性等要素對乘客路徑選擇的作用與規律挖掘,采用機器學習方法構建了路網乘客路徑選擇模型。運用模糊聚類方法對軌道交通車站進行聚類,將客流構成特性與站點類型關聯起來,將客流特性作為隱性要素映射到OD類型這一顯性要素上,提出了基于客流異質性的乘客路徑選擇集成學習方法,解決了乘客特性數據不便直接獲取這一難題。在OD類別基礎上進行路徑選擇學習器及學習樣本的劃分,構建了路徑選擇SVR子學習器模型,并利用OD類別隸屬度對子學習器的預測結果進行集成預測,經集成學習前后的預測數據對比分析,證明用本文提出的方法所構建模型的預測結果更符合實際。基于路網乘客路徑選擇結果,可準確把握客流在路網上的分布,更好支撐網絡化運營決策的需要。
2.3 基于路徑選擇子學習器的集成預測
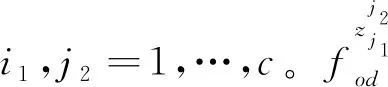
3 案例
3.1 北京地鐵站點聚類
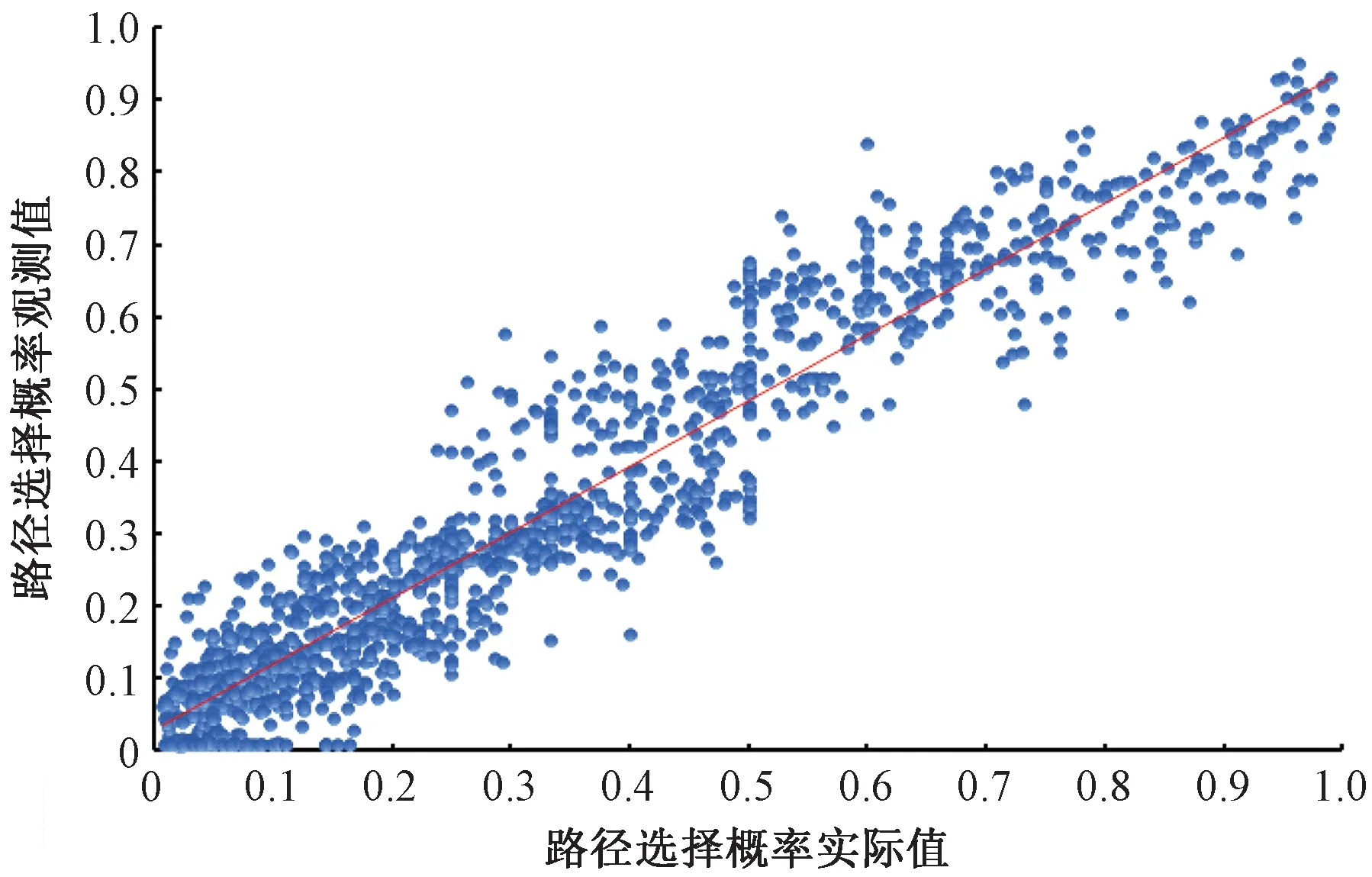
3.2 路徑選擇子學習器的訓練與集成預測
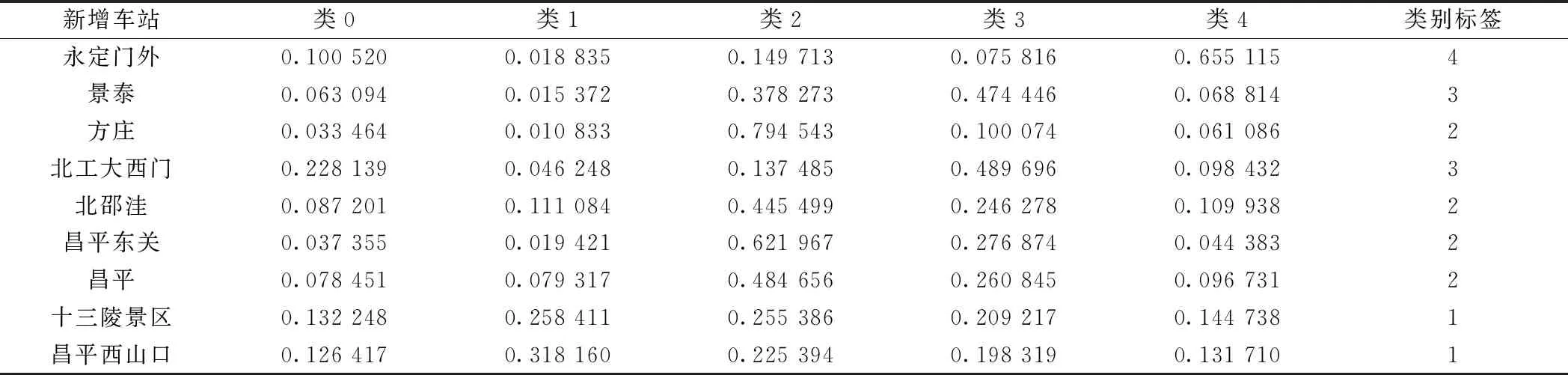
3.3 應用

4 結論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
