一種基于語義軌跡的相似性連接查詢算法
2020-07-13 12:55:46高祎晴
計(jì)算機(jī)應(yīng)用與軟件 2020年7期
關(guān)鍵詞:文本
高祎晴 潘 曉* 吳 雷,2
1(石家莊鐵道大學(xué)經(jīng)濟(jì)管理學(xué)院 河北 石家莊 050043)2(燕山大學(xué)信息科學(xué)與工程學(xué)院 河北 秦皇島 066004)
0 引 言
隨著全球定位系統(tǒng)和無線通信系統(tǒng)的發(fā)展,配備GPS的移動(dòng)設(shè)備不斷涌現(xiàn)(例如車輛導(dǎo)航系統(tǒng)和智能手機(jī)),基于地圖的在線服務(wù)不斷擴(kuò)散(例如Google Maps2和MapQuest3),軌跡數(shù)據(jù)在當(dāng)下的大數(shù)據(jù)時(shí)代扮演著越來越重要的角色。常見的軌跡數(shù)據(jù)[5],除了GPS設(shè)備采集到的人或車輛等運(yùn)動(dòng)物體的移動(dòng)路線以外,還包括傳感器采集到的數(shù)值隨時(shí)間的變化情況,比如某個(gè)監(jiān)控對象的溫度和濕度變化曲線也可以認(rèn)為是溫度和濕度所構(gòu)成的二維空間中的一條軌跡。因此可以說軌跡無處不在,這些豐富的軌跡數(shù)據(jù)資源也帶來了對于軌跡數(shù)據(jù)研究的巨大需求。目前對于軌跡數(shù)據(jù)的研究,大部分集中于對于軌跡數(shù)據(jù)的查詢和清洗[14],受現(xiàn)有存儲能力和計(jì)算能力的限制,非常有必要對軌跡規(guī)模進(jìn)行縮減。那么當(dāng)軌跡集合中的部分軌跡表現(xiàn)相似,那么便可以刪掉其他相似軌跡只留其一條。因此對于軌跡相似性查詢的研究成為了一個(gè)熱點(diǎn)問題。即用戶給定一個(gè)相似值,就可以在一個(gè)軌跡數(shù)據(jù)集中查找出滿足用戶要求相似性的軌跡對,并返回給用戶[9]。
空間相似性查詢是軌跡相似性查詢中較為普遍的一種操作方式,基于空間角度對軌跡進(jìn)行相似性的衡量,根據(jù)用戶給定的相似性閾值,對于查詢軌跡集中的軌跡進(jìn)行相似性度量,找出滿足用戶要求的空間相似性閾值的軌跡對,并且返回給用戶。目前越來越多的應(yīng)用中出現(xiàn)了地理位置與文本信息交融的現(xiàn)象[8]。一方面,越來越多的場所,例如商店、飯店、游樂場等,都附加了與其地理位置相關(guān)的文本描述信息;另一方面,文本信息也通過地名、街道、地址等特征與地理信息相關(guān)聯(lián)。所以如果僅考慮空間這一方面的相似性,可能對于軌跡相似性衡量較為片面。因此,本文在相似性的度量方面融入了文本信息的考慮,綜合了空間和文本兩方面對于軌跡的相似性進(jìn)行衡量[12]。例如,當(dāng)A用戶在A省找到與其相似性滿足要求的軌跡t時(shí),如果軌跡t的用戶出現(xiàn)在B省,恰好A用戶也想去B省,那么當(dāng)給其推薦軌跡時(shí),就可以參考軌跡t的用戶在B省的軌跡推薦給用戶A。在衡量相似性時(shí),如果只考慮空間方面也就是距離問題,就顯得不夠嚴(yán)謹(jǐn)[4]。針對根據(jù)相似性向用戶推薦可行路線,除了考慮距離問題即空間方面外,也應(yīng)該考慮關(guān)鍵字的問題,由此推薦的軌跡能夠更加符合用戶的要求[7]。
以圖1為例,在所調(diào)查的空間中有三條軌跡t1{p11,p12,p13}、t2{p21,p22,p23}、t3{p31,p32,p33},假設(shè)t1為查詢軌跡,t2、t3為被查詢軌跡。當(dāng)只考慮空間因素時(shí),可以輕易地得到t2相較t3與t1更為相似。但是當(dāng)考慮空間和文本兩個(gè)方面時(shí),根據(jù)表1中軌跡的詳細(xì)信息,軌跡t3和t1的相似性要大于軌跡t2與t1的相似性,所以會更容易滿足用戶的要求。因此,對于兩條軌跡相似性的度量,除了考慮軌跡間的距離外,還要看關(guān)鍵字的匹配程度。

圖1 軌跡相似性示例
之前的研究者針對相似性研究方面提出了許多索引技術(shù)和查詢算法[6]。本文通過對空間相似性和文本相似性賦予不同的權(quán)重,找到空間方面的邊界值,或者是文本方面的邊界值。根據(jù)這個(gè)邊界值在空間和文本方面進(jìn)行范圍查詢,通過計(jì)算出來的范圍去除一些不必要的軌跡,進(jìn)而縮小查詢范圍;同時(shí)也可以提前提取一些確定的結(jié)果集軌跡對,提升算法的效率。同時(shí)將查詢空間網(wǎng)格化,在網(wǎng)格上進(jìn)行范圍查詢,可以有效提高查詢效率。對于范圍查詢到的軌跡點(diǎn)進(jìn)行一系列操作,就可以得到滿足用戶要求的結(jié)果[11]。本文貢獻(xiàn)如下:
(1) 在研究軌跡空間相似性的基礎(chǔ)上,增加了對于文本相似性的考慮。
(2) 通過空間、文本兩方面因素對于最終軌跡相似性貢獻(xiàn)權(quán)重的調(diào)整,得出空間和文本相似性的閾值范圍,便于進(jìn)行剪枝。
(3) 對于空間進(jìn)行網(wǎng)格化處理,在空間網(wǎng)格上根據(jù)滿足要求的范圍進(jìn)行范圍查找,提高效率。
1 相關(guān)工作
文獻(xiàn)[1]研究了道路網(wǎng)絡(luò)中行駛車輛的軌跡相似性查詢(TS-Join)。該文為了實(shí)現(xiàn)在大量的軌跡上高效的軌跡相似性查詢,提出了空間修剪技術(shù)并考慮并行處理能力。文獻(xiàn)[3]解決了用于大量移動(dòng)軌跡的有效相似性查詢問題。與以前方法不同的是,該文認(rèn)為在許多基于位置的服務(wù)應(yīng)用中,軌跡已按原樣在其原生空間中編入了索引。在這個(gè)前提下,在變換的空間中使用專用索引,便于處理常見的時(shí)間和空間方面軌跡相似性查詢。同時(shí)該文介紹一種從經(jīng)典的弗雷歇距離中改編新穎的距離,可以自然地延伸來支持利用上下限對于在原生空間中的移動(dòng)對象數(shù)據(jù)庫進(jìn)行索引。文獻(xiàn)[2]研究空間關(guān)鍵詞范圍搜索問題,這對于理解大量數(shù)據(jù)軌跡至關(guān)重要。為了進(jìn)行有效的條件搜索,提出了一個(gè)被稱為IOC-Tree的基于倒排樹和八叉樹技術(shù)的空間網(wǎng)格索引結(jié)構(gòu)對空間、時(shí)間和文本進(jìn)行有效的剪枝。
本文在空間距離方面使用DTW進(jìn)行計(jì)算,在文本方面用Jaccard系數(shù)進(jìn)行計(jì)算[16],運(yùn)用范圍查詢相關(guān)技術(shù)并通過一系列定理來進(jìn)行軌跡相似性計(jì)算,將空間網(wǎng)格化劃分進(jìn)而進(jìn)行范圍查詢剪枝,提高算法的效率。
2 問題的形式化定義
2.1 基本定義
空間軌跡上任意軌跡點(diǎn)對象均包含地理位置和文本關(guān)鍵字集合,對于任意一個(gè)軌跡點(diǎn)對象pi都是包含地理位置和文本關(guān)鍵字集合的軌跡點(diǎn)對象。每一個(gè)軌跡點(diǎn)對象的存儲形式pi(x,y,K,Rid),空間文本信息記為K,K={a1,a2,…,an},ai是文本關(guān)鍵字[10]。x、y分別為軌跡點(diǎn)對象的經(jīng)緯度,Rid為軌跡點(diǎn)對象所在的軌跡編號。對于軌跡集合中的任意一條軌跡都由n個(gè)軌跡點(diǎn)對象組成,記為R(p1,p2,…,pn)[13]。
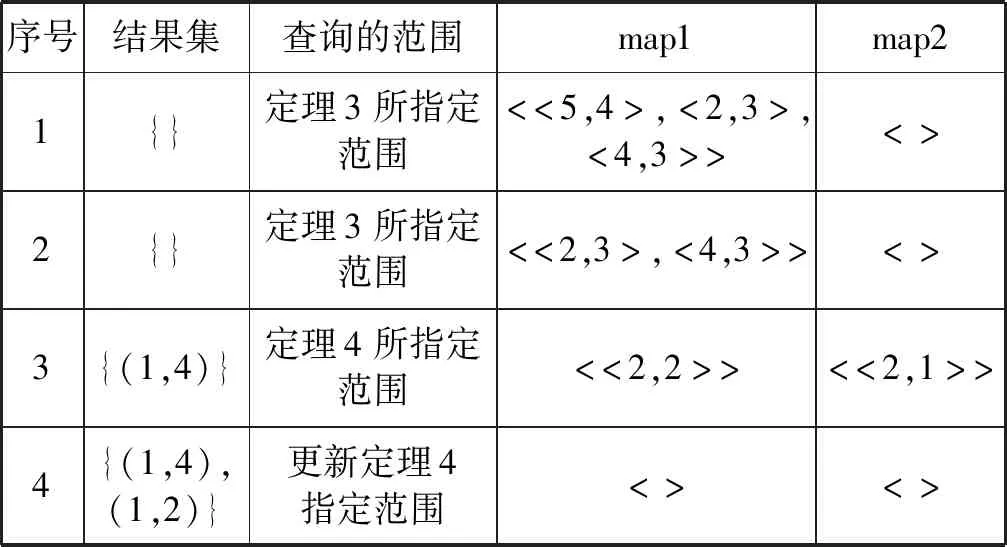
定義1(空間文本軌跡) 空間文本軌跡R由點(diǎn)p1,p2,…,pi,…,pn組成,其中每個(gè)點(diǎn)pi=(xi,yi,tmi),表示對象在時(shí)刻tmi位于(xi,yi)位置,其中tm1 如圖1所示,軌跡t1由三個(gè)軌跡點(diǎn)p11、p12、p13組成,因此軌跡t1的長度是3;在軌跡t1的p11軌跡點(diǎn)那一時(shí)刻,軌跡t2、t3分別位于p21、p31軌跡點(diǎn)處;對于軌跡t1的關(guān)鍵字集合就是組成軌跡t1的各個(gè)軌跡點(diǎn)所帶的關(guān)鍵字集合,即{coffee,cinema,shop,library,swim}。 給定一條軌跡t,軌跡集合中任意一條軌跡t′與軌跡t的空間相似度、文本相似度和空間文本相似度的定義如下: 定義2(軌跡空間相似度) 任意兩個(gè)軌跡在空間中的相似程度記為SIMs(t,t′)用兩條軌跡間的空間距離表示。設(shè)dmax表示空間中任意兩條軌跡之間的最遠(yuǎn)距離,則空間中任意兩條軌跡t和t′的相似度定義為: (1) 由式(1)知兩個(gè)軌跡間距離越近,軌跡的空間相似性就越大。由于DTW算法不要求軌跡等長也可完成軌跡點(diǎn)的動(dòng)態(tài)匹配,因此本文采用DTW計(jì)算任意兩條軌跡之間的空間距離。 定義3(軌跡文本相似度) 任意兩個(gè)軌跡的文本相似性,記為SIMT(t,t′)。即文本集合的相似度,用Jaccard系數(shù)計(jì)算獲得。 (2) 由式(2)可知,兩個(gè)軌跡之間文本集的交集的元素個(gè)數(shù)越多,SIMT(t,t′)的值越大,文本相似性就越大。 定義4(軌跡空間文本相似度) 結(jié)合定義2和定義3,任意兩個(gè)軌跡之間的相似性定義為: SIM(t,t′)=αSIMS(t,t′)+(1-α)SIMT(t,t′) (3) 式中:α(α∈[0,1])是一個(gè)可調(diào)節(jié)參數(shù),用以調(diào)節(jié)計(jì)算空間文本相似性時(shí)空間因素與文本因素之間的相對重要程度。SIM(t,t′)的值越大,兩條軌跡之間的空間文本相似度就越大。 表2給出圖1中軌跡t1與軌跡t2的空間距離。 表2 軌跡t1和t2之間的DTW距離 由表2可知軌跡t1和軌跡t2之間的距離為1.33,根據(jù)同樣的方法計(jì)算其他軌跡對之間的距離,可得dmax=5.66,根據(jù)定義1可得軌跡t1和t2的空間相似度為0.77;根據(jù)表1可知t1與t2的文本并集個(gè)數(shù)為7,文本交集個(gè)數(shù)為1,根據(jù)定義3可得t1與t2的軌跡文本相似度為0.143。若給定的α值為0.5,根據(jù)定義4可得最終t1與t2的空間文本相似度為0.46。 本文的問題描述如下:給定一個(gè)軌跡的集合P和一個(gè)閾值ψ,軌跡相似性查詢是從一個(gè)軌跡集合中找出任意兩條軌跡的相似性大于給定閾值ψ的軌跡對集合。 由于軌跡數(shù)量十分龐大,為提高查詢效率,需要先將一部分完全不可能存在在結(jié)果集中的軌跡剪枝掉。通過觀察式(3)發(fā)現(xiàn),在軌跡相似度閾值確定的情況下,如果兩條軌跡文本相似度(空間相似度)取最大值(即1),則空間相似度(文本相似度)將取最小值。對于任意一條軌跡t,如果其他軌跡到該軌跡的空間相似性(文本相似性)小于這個(gè)最小值,則這些軌跡一定不在查詢軌跡t的相似性結(jié)果集中。因此,相似度下限如定理1。 定理1(相似度下限) 給定軌跡空間文本相似度ψ和參數(shù)α,對于任意一條軌跡t的空間相似度下限和文本相似度下限分別為: (1) 空間相似度下限LB_SS:對于軌跡集合中另外任意一條軌跡t′,若兩者的文本相似度取最大值1,則根據(jù)式(4)可以計(jì)算出空間相似度下限,表示為: LB_SS=(φ+α-1)/α (4) 由于空間相似度與空間距離成反比。根據(jù)空間相似度下限,可以得到空間兩條軌跡之間最大距離下限,即SD_LBmax。根據(jù)定義2可以計(jì)算出空間兩條軌跡之間最大距離的下限: SD_LBmax=dmax[(1-φ)/α] (5) (2) 文本相似度下限LB_ST:對于軌跡集合中另外任意一條軌跡t′,若兩者的空間相似度取最大值1,則根據(jù)式(3)可得文本相似度下限,如下: LB_ST=(φ-α)/(1-α) (6) 根據(jù)文本相似度下限,設(shè)MINks是軌跡上包含的最小文本數(shù),可得兩條軌跡之間的最小相同文本數(shù)Wmin: Wmin=MINks×LB_TT (7) 由于在軌跡集合中任意兩條軌跡的并集集合數(shù)都大于MINks,因此MINks是兩條軌跡并集集合數(shù)的下限,根據(jù)定義3,在文本相似度取最小值時(shí),由此下限乘以文本相似度下限,得到相同文本數(shù)是最小值。 若其他任何軌跡t′與t的空間相似度小于LB_SS,則軌跡t′不會存在于軌跡t的相似軌跡集合中。 證明:對于空間相似度下限來講,已知軌跡集合R,用戶要求的空間文本相似度為ψ,給定一條軌跡t,其他任何軌跡t′與t的文本相似度取最大值1;對于R中任意軌跡對象Ri,SIMT(Ri,t)≤1,SIMS(Ri,t) 同理可證,對于給定的一條軌跡t,其他任何軌跡t′與t文本相似性小于LB_TT,則軌跡t′不會存在于軌跡t的相似軌跡集合中,被剪枝。 同樣,對于空間相似度下限和文本相似度下限來說,也可以用另一種方式說明,即空間最大距離下限和最小相同文本數(shù),因此同理可以證明,當(dāng)軌跡t′與t的相同文本數(shù)小于最小相同文本數(shù)或者軌跡t′與t的空間距離大于空間軌跡最大距離的下限時(shí),就將軌跡t′剪枝掉。 證畢。 與之相反,在軌跡相似度閾值確定的情況下,式(4)中如果兩條軌跡文本相似度取最小值(即0),則空間相似度將取最大值。對于任意一條軌跡t,如果其他軌跡t′到t的空間相似性大于這個(gè)最大值,則t′一定在t的相似性結(jié)果中。由此,空間相似度上限形式化如定理2。 定理2(空間相似度上限) 給定軌跡相似度閾值ψ,一條軌跡t,如果其他任何軌跡t′與t的空間相似度大于UB_SS,則軌跡t′一定存在于軌跡t的相似軌跡集合中。表示為: UB_SS=φ/α (8) 由于空間相似度與空間距離成反比,則根據(jù)定義2,可得空間軌跡最小距離的上限為: SD_UBmin=dmax(1-φ/α) (9) 證明:對于空間相似度上限而言,已知軌跡集合R,用戶要求的空間文本相似度為ψ,給定一條軌跡t,其他任何軌跡t′與t的文本相似度取最大值0;對于用戶給定軌跡集合R中的任意軌跡對象Ri,都有SIMT(Ri,t)≥0;因?yàn)閁B_SS是在SIMT(Ri,t)=0情況下計(jì)算出的結(jié)果,所以如果要滿足用戶的相似度φ,不管Ri和t之間的文本相似度值取何值,若SIMS(Ri,t)≥UB_SS,則SIM(Ri,t)=αSIMS(Ri,t)+(1-α)SIMT(Ri,t)≥φ,一定滿足用戶要求。 證畢。 在定理1和定理2中,分別獲得了任意兩條軌跡的空間距離的最大距離下限SD_LBmax和最小距離上限SD_UBmin。根據(jù)最小距離上限SD_UBmin,得到緊湊的最小距離上限。軌跡t′中若有任意點(diǎn)的位置在最大距離下限之外,則軌跡t′被剪枝;軌跡t′上的所有點(diǎn)都在緊湊的最小距離上限內(nèi),則軌跡t′一定是查詢結(jié)果之一;否則我們通過逐步上調(diào)SD_UBmin,進(jìn)而調(diào)整緊湊的最小距離上限,對軌跡t′做進(jìn)一步的驗(yàn)證。同樣算法根據(jù)最大距離下限SD_LBmax,也可得到緊湊的最大距離上限。通過這個(gè)距離,可對算法進(jìn)行一些改變,得到另外一種解決問題的方式,算法部分會給出具體介紹。 根據(jù)最大距離下限做范圍查詢,可以對軌跡進(jìn)行一些剪枝。 定理3給定軌跡t和任意一條軌跡t′,若以t中的每一個(gè)位置點(diǎn)為圓心,以SD_LBmax為半徑做范圍查詢,若軌跡t′中存在任意一個(gè)點(diǎn)在范圍查詢之外,則軌跡t′被剪枝。 證明:假設(shè)給定一條查詢軌跡t,有n個(gè)軌跡點(diǎn);軌跡集合中的任意一條軌跡t′,有m個(gè)軌跡點(diǎn);此時(shí)定理3所指定的范圍的半徑是SD_LBmax,當(dāng)把兩個(gè)軌跡之間的最大距離上限用在單點(diǎn)上時(shí),對于每一個(gè)單點(diǎn)來說,如果在這個(gè)范圍之外,根據(jù)DTW計(jì)算兩條軌跡之間的規(guī)律,經(jīng)過層層迭代,我們可以知道最終距離總是會加上一個(gè)SD_LBmax。因此,只要有一個(gè)軌跡點(diǎn)在定理3所指定的范圍之外,那么軌跡t′和軌跡t的距離就會大于SD_LBmax。在定理1中我們已經(jīng)證明了如果兩條軌跡之間的距離大于SD_LBmax,那么就可以直接被剪枝。 因此只要有一個(gè)軌跡點(diǎn)在定理3所指定的范圍之外,一定不是備選軌跡,將其剪枝掉。 證畢。 (1) 緊湊的最小距離上限:可以將最小距離下限SD_UBmin通過式(10)變得更緊湊些。 r1=SD_UBmin/n′ (10) 式中:n′是軌跡t和軌跡t′中軌跡長度較大的軌跡長度。 定理4給定軌跡t和任意一條軌跡t′,若以t中的每一個(gè)位置點(diǎn)為圓心,以r1為半徑做范圍查詢,若軌跡t′中所有點(diǎn)在范圍查詢之內(nèi),則軌跡t′一定在軌跡t的結(jié)果集合中。 證明:假設(shè)給定一條查詢軌跡t,有n個(gè)軌跡點(diǎn);對于軌跡集合中的任意一條軌跡t′,假設(shè)有m個(gè)軌跡點(diǎn);當(dāng)n=m時(shí),定理4所指定的范圍大小為SD_UBmin/n,若軌跡t′上的所有軌跡點(diǎn)都在定理4指定的范圍之內(nèi),根據(jù)DTW計(jì)算兩條軌跡距離的規(guī)律,對于最終兩條軌跡之間起決定作用的各個(gè)對應(yīng)軌跡點(diǎn)之間的距離,由于軌跡t′的所有軌跡點(diǎn)都在軌跡t的定理4所指定的范圍中,所以各個(gè)對應(yīng)軌跡點(diǎn)之間的距離都是小于SD_UBmin/n,當(dāng)有一個(gè)對應(yīng)的軌跡點(diǎn)之間的距離小于SD_UBmin/n,再往下推算兩條軌跡之間距離時(shí),就可以知道在這個(gè)對應(yīng)下一層是由一個(gè)小于SD_UBmin/n的數(shù)加上下一層的對應(yīng)軌跡點(diǎn)之間的距離,同樣因?yàn)橄乱粚訉?yīng)軌跡點(diǎn)依然是小于SD_UBmin/n,因此經(jīng)過一層層的推算,可以得到最終軌跡t′到軌跡t的距離小于SD_UBmin/n;當(dāng)m>n時(shí),此時(shí)定理4指定的范圍大小是SD_UBmin/m,同樣根據(jù)DTW計(jì)算兩條軌跡距離的規(guī)律,兩條軌跡點(diǎn)相同的部分參照兩條軌跡點(diǎn)相同的情況給出,即兩條軌跡點(diǎn)相同的部分計(jì)算出一個(gè)最終值小于SD_UBmin×n/m,考慮較長軌跡的剩余部分,容易知道最終兩條軌跡之間的距離小于SD_UBmin;當(dāng)m 因此軌跡上軌跡點(diǎn)完全在定理4指定范圍之內(nèi)的軌跡一定屬于結(jié)果集。 證畢。 (2) 緊湊的最大距離下限:根據(jù)最小距離下限SD_LBmax,可以通過下式變得更緊湊些。 r2=SD_LBmax/n′ (11) 式中:n′是軌跡t和軌跡t′中軌跡長度較大的軌跡長度數(shù)。 定理5給定軌跡t和任意一條軌跡t′,若以t中的每一個(gè)位置點(diǎn)為圓心,以r2為半徑做范圍查詢,若軌跡t′中所有點(diǎn)在范圍查詢之內(nèi),則軌跡t′一定是軌跡t的備選結(jié)果集合。 證明:參照緊湊的最小距離上限證明方法,同時(shí)根據(jù)DTW計(jì)算規(guī)律可以得到完全在緊湊的最大距離下限所給定的范圍之內(nèi)的,一定是軌跡t的候選結(jié)果軌跡。 證畢。 算法分為三個(gè)步驟:第一步,剪枝。給定軌跡t,先在軌跡t上每一個(gè)位置點(diǎn)上執(zhí)行定理3所指定的范圍查詢。如果對于軌跡集合中任意一條軌跡t′,有任意軌跡點(diǎn)位于范圍查詢之外,則軌跡t′被剪枝并形成初步相似軌跡候選集candk。candk中任意的軌跡t′,如果與軌跡t的相同文本數(shù)小于Wmin,則從candk中去除t′。如此,完全在最大范圍下限范圍查詢內(nèi)且滿足最小相同文本數(shù)要求的軌跡組成了相似軌跡候選集cand。第二步,確定結(jié)果集。對于在軌跡t上每一個(gè)位置點(diǎn)上執(zhí)行定理4指定的范圍查詢,如果對于cand中的任意軌跡t′的所有位置點(diǎn)都在此范圍內(nèi),則從cand中去掉t′并返回結(jié)果(t,t′)。第三步,候選結(jié)果集求精。對于cand中剩余軌跡,調(diào)整定理4所指定的范圍,重新進(jìn)行范圍查詢,如果對于軌跡t′所有軌跡點(diǎn)在調(diào)整范圍過程中被訪問到,則從cand中去掉t′并返回(t,t′);重復(fù)上述操作直至調(diào)整范圍的半徑大于SD_UBmin。若cand中依然存在沒有被完全訪問到的軌跡,取出該軌跡的具體信息,驗(yàn)證其是否為結(jié)果。 下面對于候選結(jié)構(gòu)求精步驟進(jìn)行詳細(xì)介紹: r′=(SD_UBmin-sd)/(n-1) (12) 再次進(jìn)行定理4所指定的范圍查詢,對于范圍查詢中訪問到的軌跡點(diǎn),判斷是否為t′上的軌跡點(diǎn),如果t′上的軌跡點(diǎn)被訪問完全,那么返回(t,t′);否則計(jì)算訪問到的各個(gè)點(diǎn)與在查詢軌跡t上對應(yīng)的軌跡點(diǎn)之間的距離,在這些距離中取最大值更新sd,進(jìn)而更新r′,重復(fù)進(jìn)行上述步驟,直至r′大于或者等于SD_UBmin。 如果在上述停止條件出現(xiàn)之后,cand中依然存在軌跡點(diǎn),那么取出軌跡點(diǎn)所在軌跡的具體信息,計(jì)算其與查詢軌跡t的空間文本相似度判斷是否符合用戶要求,如果符合就納入結(jié)果集,否則就剪枝掉。接下來用圖2來解釋我們的驗(yàn)證算法。 圖2 驗(yàn)證例圖 對于圖2來說,此時(shí)查詢軌跡是由p11、p12、p13組成的軌跡1,驗(yàn)證軌跡是由p21、p22、p23所組成的軌跡2,圖中較小的圈就是我們定理4所指定的范圍;由于p21在定理4所指定的范圍中,所以我們計(jì)算p21到p11之間的距離,根據(jù)這個(gè)距離我們就可以更新查詢軌跡上p12、p13點(diǎn)所對應(yīng)的范圍,即如圖2所示外面較大的圈。緊接著判斷是否在新一次的范圍查詢中查詢到所有驗(yàn)證軌跡2的軌跡點(diǎn),可以得到軌跡對(1,2)在最終的結(jié)果集中。 本文通過對于空間(文本)相似度取最大或最小值,從而得到文本(空間)的最小或最大值,在計(jì)算的過程中,對于φ和α的取值,會有大小的沖突。因此在算法中,對于最小距離上限的計(jì)算,將本文相似性從0的取值更新至當(dāng)前備選軌跡集合中文本相似度的最小值,證明可參考定理2中的證明過程,結(jié)論依然成立。那么此時(shí)SD_UBmin的計(jì)算公式如下: (13) 具體算法如下: Input:用戶要求的相似性φ,參數(shù)值α,軌跡集合R Output:滿足用戶相似性要求的軌跡集集合A 1. for軌跡集合R中的每一條軌跡Ri 2. 計(jì)算SD_LBmax=dmax[(1-φ)/α]; 3. for在定理3所指定的范圍的每一個(gè)軌跡點(diǎn)對象Xi 4. 將 5. for在map1中的每一個(gè)軌跡點(diǎn)對象Xi 6. if(map1中t′的軌跡點(diǎn)個(gè)數(shù)<軌跡t′的個(gè)數(shù)) 7. 剪枝掉軌跡t′,形成candk; 8. 計(jì)算LB_ST=(φ-α)/(1-α)Wmin=W*LB_ST 9. for candk中每一個(gè)軌跡點(diǎn)對象Xi 10. if(Xi所在軌跡t′與Ri的相同文本數(shù) 11. 剪枝掉t′,形成cand; 12. for cand中每一個(gè)軌跡點(diǎn)對象Xi 13. if(Xi所在軌跡t′的軌跡點(diǎn)數(shù)==查詢軌跡t軌跡點(diǎn)數(shù)) 14. 計(jì)算cand中軌跡的文本最小值記為SIMTmin; 15. 計(jì)算SD_UBmin=dTminmax; 16. 計(jì)算r1=SD_UBmin/n′; 17. if(Xi在定理4所指定范圍內(nèi)) 18. 將 19. if(map2中Xi對應(yīng)軌跡編號t′的軌跡點(diǎn)數(shù)==此時(shí)map1中t′的軌跡點(diǎn)個(gè)數(shù)) 20. 將(t,t′)加入結(jié)果集A中; 21. else 22. 進(jìn)一步驗(yàn)證map1,map2中剩余軌跡否為結(jié)果集; 23. else if(Xi所在軌跡的軌跡點(diǎn)對象個(gè)數(shù)>Ri的軌跡點(diǎn)對象個(gè)數(shù)) 24. 更新SD_UBmin,r1,重復(fù)執(zhí)行11-21行; 25. ReturnA; 對于用戶給定軌跡集合中的每一條軌跡Ri,首先計(jì)算SD_LBmax,(1-2行)。對于查詢軌跡t構(gòu)造定理3所指定的范圍,進(jìn)行范圍查詢,對于訪問到的軌跡點(diǎn)Xi,將 對于cand中的每一個(gè)軌跡點(diǎn)Xi,判斷Xi所在的軌跡t′的軌跡點(diǎn)個(gè)數(shù)是否等于查詢軌跡的軌跡點(diǎn)個(gè)數(shù)。如果相等,計(jì)算cand中軌跡的文本相似性的最小值SIMTmin和SD_UBmin,之后計(jì)算緊湊的最小距離上限r(nóng)1;對于查詢軌跡Ri構(gòu)造定理4所指定的范圍,進(jìn)行范圍查詢(13-16行)。判斷Xi軌跡點(diǎn)是否被訪問到。如果被訪問到了,將 在算法中可以將定理3指定的范圍改變?yōu)槎ɡ?指定的范圍,同樣執(zhí)行范圍查詢。但是在進(jìn)行最小文本數(shù)剪枝之前,需要增加一個(gè)驗(yàn)證算法,驗(yàn)證部分在定理5指定范圍內(nèi)的軌跡是否為備選結(jié)果集。該驗(yàn)證算法與上述驗(yàn)證算法相同。 因此,還有另外一種算法去解決這一問題,即把上述算法的2-4行改變?yōu)椋?/p> 2. 計(jì)算SD_LBmax=dmax[(1-φ)/α] r2=SD_LBmax/n′; 3. for在定理5所指定的范圍的每一個(gè)軌跡點(diǎn)對象Xi 4. if(Xi所在軌跡的軌跡點(diǎn)對象個(gè)數(shù)==Ri的軌跡點(diǎn)對象個(gè)數(shù)) 5. 將 6. if(map1中Xi對應(yīng)軌跡編號t′的軌跡點(diǎn)數(shù)=0) 7. 將軌跡t′從map1中剪枝掉; 8. else 9. 驗(yàn)證該軌跡是否備選軌跡; 對于算法部分,本文提出了兩種解決問題的算法。由于不同的數(shù)據(jù)集會有不同的數(shù)據(jù)分布,這兩種算法也會有不同的運(yùn)行效率。同時(shí)對于相同的數(shù)據(jù)集可能也有運(yùn)行時(shí)間上面的不同。 給定一條查詢軌跡t,有n個(gè)軌跡點(diǎn)。 2. 取map2中的軌跡對應(yīng)的任一軌跡點(diǎn)對象Yi 5. 根據(jù)d,對棧nbs進(jìn)行從大到小排序,取棧頂d記為sd; 8. for(更新范圍內(nèi)的每個(gè)軌跡點(diǎn)) 9. 重復(fù)執(zhí)行3-7行; 10. 記錄棧內(nèi)軌跡出現(xiàn)的次數(shù)N,和棧頂軌跡出現(xiàn)的次數(shù)N′; 11. if(棧頂對應(yīng)的軌跡的軌跡點(diǎn)個(gè)數(shù)==N′) 12. 將棧頂對應(yīng)的軌跡和查詢軌跡組成軌跡對加入結(jié)果集中 13. else 14. 從磁盤中取出相應(yīng)的軌跡信息,進(jìn)行計(jì)算驗(yàn)證 15. if(nbs中其他軌跡的軌跡點(diǎn)==N) 16. 將該軌跡和查詢軌跡組成軌跡對加入結(jié)果集中; 18. else 19. 重復(fù)執(zhí)行4-14行。 給定一個(gè)例子來詳細(xì)介紹算法的流程。如圖3所示,整個(gè)的矩形空間是本文算法的查詢范圍,其中每個(gè)點(diǎn)都是軌跡點(diǎn)。 圖3 軌跡相似性示例 由圖3可知,在整個(gè)進(jìn)行空間中,有5條軌跡,軌跡的詳細(xì)信息如表3所示。 表3 圖3中軌跡信息 表4為上述運(yùn)行過程的運(yùn)行示例表。通過對于每次訪問區(qū)域的更新,得到備選軌跡集和結(jié)果集的更新,最終得到滿足用戶要求的軌跡對結(jié)果集合。 表4 運(yùn)行示例表 第一步,給定用戶要求的相似性φ=0.9,α=0.5;給定一條查詢軌跡t1(p11,p12,p13);計(jì)算出SD_LBmax=3.39;進(jìn)而根據(jù)查詢軌跡的軌跡點(diǎn)得到定理3所指定的區(qū)域,即圖3中大圈所含區(qū)域。根據(jù)訪問空間中軌跡點(diǎn)的位置信息,對每一個(gè)軌跡點(diǎn)判斷是否在定理3所指定的范圍內(nèi),經(jīng)過判斷,此時(shí)map1中有<<5,4>,<2,3>,<4,3>>,構(gòu)成初步的備選軌跡集合candk。 第二步,計(jì)算出Wmin=5,candk中的軌跡5與軌跡1的相同文本數(shù)為2,小于5,剪枝掉軌跡5。此時(shí)map1中有<<2,3>,<4,3>>,構(gòu)成最終的軌跡備選集合。進(jìn)而得到目前軌跡集合中最小的文本相似度為0.83。 第三步,計(jì)算出SD_UBmin=0.54,r1=0.18,進(jìn)而得到定理4所指定的范圍。對于cand中的每一個(gè)軌跡點(diǎn),判斷該軌跡點(diǎn)是否在定理4所指定的范圍內(nèi)。以p21為例,根據(jù)p21軌跡點(diǎn)的位置,易知p21不在定理4所在指定的范圍之內(nèi),不可將該點(diǎn)加入map2,所以map2中存入<<4,1>>。重復(fù)上述的判斷,可得最終map2中為<<4,3>,<2,1>>,map1中為<<2,2>>。根據(jù)map2中的軌跡信息可知,軌跡4在map2中的軌跡點(diǎn)數(shù)等于自身的軌跡點(diǎn)個(gè)數(shù),即軌跡4完全在定理4所指定的范圍之內(nèi),因此將(1,4)納入結(jié)果集A。 因此最終滿足用戶要求的結(jié)果集中有{(1,4),(1,2)}。 隨著移動(dòng)互聯(lián)網(wǎng)的高速發(fā)展和移動(dòng)定位設(shè)備的廣泛普及,基于位置的地理信息服務(wù)逐漸滲透進(jìn)人們生活的方方面面。隨之而來的對于基數(shù)龐大的軌跡數(shù)據(jù)研究成為熱點(diǎn)。本文研究軌跡相似性,在一般的空間相似性研究的基礎(chǔ)上,加入了對于軌跡文本相似性的考慮,使得對于軌跡相似性的研究更為全面,未來這一算法可以推廣到旅游路線推薦的應(yīng)用開發(fā)中。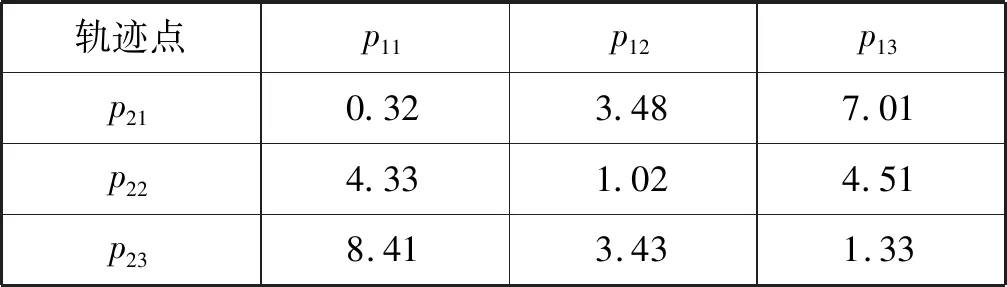
2.2 相關(guān)定理
3 算法設(shè)計(jì)
3.1 距離介紹
3.2 基本步驟
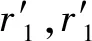
3.3 具體流程

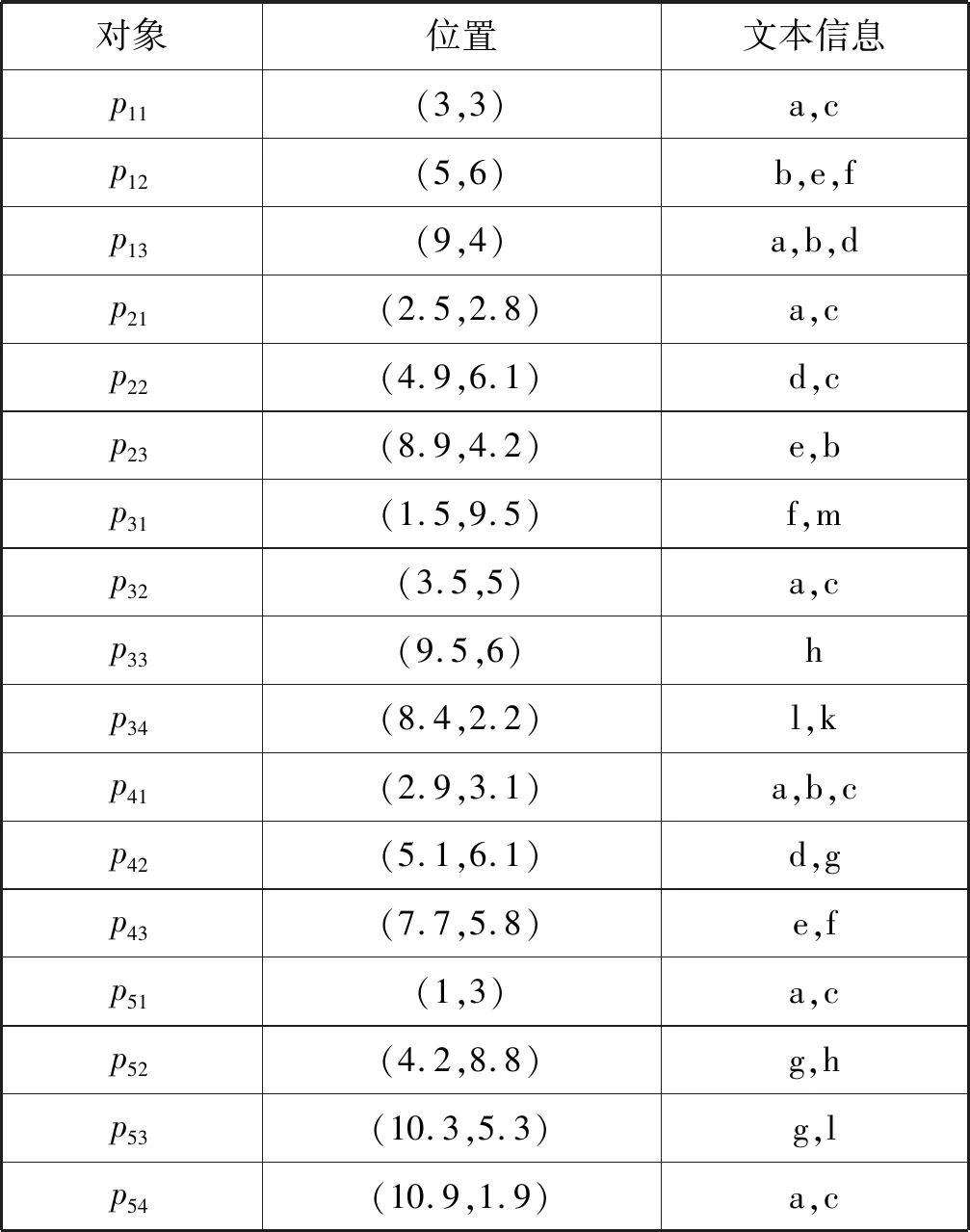
4 運(yùn)行示例


5 結(jié) 語
猜你喜歡
云南教育·小學(xué)教師(2022年4期)2022-05-17 14:46:24新世紀(jì)智能(語文備考)(2020年4期)2020-07-25 02:28:52新世紀(jì)智能(語文備考)(2020年4期)2020-07-25 02:28:52甘肅教育(2020年8期)2020-06-11 06:10:02藝術(shù)評論(2020年3期)2020-02-06 06:29:22制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08新世紀(jì)智能(語文備考)(2018年11期)2018-12-29 12:30:58電子制作(2018年18期)2018-11-14 01:48:06小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38語文知識(2015年11期)2015-02-28 22:01:59
