基于用戶數據實現天線方位角糾偏的方法
2020-07-10 00:53:16朱格苗王計斌閆興秀
江蘇通信 2020年3期
關鍵詞:用戶
朱格苗 徐 慧 王計斌 閆興秀 余 健
南京華蘇科技有限公司
0 引言
近年來,隨著通信網絡的不斷發展,其復雜性也越來越高,網絡優化成為運營商面臨的主要問題之一,而準確的工參尤其是方位角是網絡優化的基石,如何獲取正確的方位角是目前研究的重點問題之一。
目前,小區方位角核查主要采用人工定期巡檢的方法,分批逐步核查全網所有小區的方位角,該方式不僅耗時、耗人、耗力,而且運維成本較高。另一種自動核查天線方位角的方法是分析小區覆蓋范圍,目前通常是對路測數據進行分析。
目前很多學者的研究都是從某一方面對天線方位角進行計算,而沒有全面考慮到數據的差異。本文利用OTT數據、MDT數據、MR數據和工參數據,從各個方面考慮數據的差異性,相應地提出五個算法,分別對用戶數據進行分析,從而預測天線的方位角,并將五種算法通過賦予不同的權重形成一種聯合算法。本文方法的主要創新點是將五種預測算法聯合在一起,規避了單獨算法的一些缺點,以達到更高的精度和更好的穩定性。
1 數據收集
我們的方法收集了三種不同的數據:用戶數據(OTT、MDT)、小區工參信息表、小區真實勘站數據。
用戶數據收集的是特定時間及空間上用戶手機上報的實時信息。最終保留的指標有:小區唯一標識(ECI)、用戶經度、用戶緯度、參考信號接收功率(Reference Signal Received Power,RSRP)(以下簡稱RSRP)。
小區工參信息表收集的是一定區域內大量小區的基本信息,每行代表一個ECI。最終保留下列指標:小區唯一標識(ECI)、小區經度、小區緯度、工參方位角、小區覆蓋類型。
小區真實勘站數據收集的是小區真實的信息,包括小區唯一標識(ECI)、勘站方位角。
對用戶數據進行分析,利用我們的聯合算法對小區方位角進行預測,并且將預測的方位角和真實勘站的數據進行對比,得出算法預測的準確性。當算法的準確性較高時,該算法則投入生產應用,這樣則可以節省大量的人力、物力,不需要對每個小區進行實際勘站就能獲得準確的工參。
2 方法論
在實際生活中,當收集到的樣本數據量較小時,預測值與真實值之間常常會有較大的誤差,為了避免誤差過大,本文將五種基本預測算法和權重算法結合,形成聯合算法,從而對用戶數據進行預測,這樣可以在一定程度上保證預測結果的準確性。基于用戶數據實現天線方位角糾偏的方法主要分為以下5個步驟:
步驟1:收集數據。收集用戶數據和工參數據樣本以及勘站數據。
步驟2:數據處理。首先將工參表中小區經度和緯度為空的小區刪除,只選取小區覆蓋類型為室外的小區,在柵格級多天時間粒度上對用戶數據和工參數據通過小區唯一標識碼進行匹配,然后對匹配后的數據組進行去重處理,統計每個小區下的用戶數據數量,僅保留用戶數據數量大于閾值區,根據小區經緯度和用戶數據經緯度,計算用戶數據到小區的距離,并且進行異常值檢測,刪除距離較遠的用戶數據,再通過小區經緯度和用戶經緯度計算用戶相對小區的角度,以正北方位為0度。
步驟3:分別采用基于采樣點強度預測算法、基于采樣點密度分扇區預測算法、基于采樣點強度和密度結合的預測算法、基于采樣點強度的分層統計預測算法、基于采樣點強度分扇區的預測算法,計算每個小區的預測方位角。
步驟4:使用用戶數據和實測的勘站數據作為訓練集,用步驟3的五種預測方法對訓練集進行預測,再根據預測結果使用蒙特卡羅方法訓練出五種預測方法的權重。
步驟5:根據步驟4的權重在訓練集上得到的預測效果,選出最優權重,確定最優權重的預測模型,根據最優權重的預測模型對用戶數據進行預測,得出小區的預測方位角。

圖1 基于五種預測模型算法的天線方位角工參清洗的說明示意圖
2.1 基于采樣點強度的預測算法
該算法從采樣點的強度出發,將信號強度作為主要指標進行考慮。主要是計算每個小區唯一標識碼下RSRP值最大的前n個采樣點角度的均值作為方位角預測值,n為自然數。
2.2 基于采樣點密度分扇區的預測算法
該算法從采樣點密度分扇區進行考慮,將采樣點有規律地劃分為多個區域。每個小區唯一標識碼下,以基站經緯度為圓心,以基站的正北方向為0度,順時針方向角度增加,每N度劃分一個扇區,將基站的區域劃分為360/N(取整數)個扇區。根據采樣點的經緯度和基站的經緯度,計算得到采樣點與基站之間相對正北方向的夾角,根據該角度將采樣點按照到小區的角度,每N度劃分一個扇區,分成360/N份,將每個采樣點都劃分到其所屬扇區,統計每個扇區中點的個數,取點的個數最多的扇區角度作為方位角預測值。
2.3 基于采樣點強度和密度結合的預測算法
該算法將采樣點的密度和強度結合考慮,首先同2.2中的扇區的劃分方法一致,進行扇區劃分,同樣是將采樣點有規律地劃分成多個區域。每個小區唯一標識碼下,將采樣點按照到小區的角度每N度劃分一個扇區,分成360/N份,N∈[1,360],360/N取整數;然后統計每個小區唯一標識碼下的采樣點總數扇區中采樣點數占比,取出360/N個扇形區域中采樣點個數大于總采樣點d%的扇區,d∈[1,99],計算這些扇區中RSRP值最大的前n個采樣點RSRP均值,n為自然數,取出RSRP均值最大的扇形區域t個,t的范圍為[1,360/N]之間的整數,計算這t個扇區角度的均值作為方位角預測值。
2.4 基于采樣點強度的分層統計預測算法
該算法是在第一個基于采樣點強度的預測算法的基礎上進行的改進,這個算法考慮距離變量的作用。每個小區唯一標識碼下,先將距離去重,再計算n-1個不同的百分位數,按照從小到大排列,根據用戶數據到小區的距離劃分m環,m≥3。第一環:距離≦第一個百分位數;第二環:第一個百分位數<距離≦第二個百分位數;第三環:第二個百分位數<距離≦第三個百分位數;第四環:第三個百分位數<距離≦第四個百分位數;第n環:第n-1個百分位數<距離,刪除最小環和最大環的數據,保留中間環數據;確定位于中間環中每環RSRP值最大的前n個采樣點角度均值,最后求前n個采樣點角度均值的均值作為方位角預測值,n為自然數。
2.5 基于采樣點強度分扇區的預測算法
該算法是在第一個基于采樣點強度的預測算法的基礎上進行的改進。它將采樣點有規律地劃分為多個區域,然后基于采樣點強度進行計算。每個小區唯一標識碼下,將采樣點按照到小區的角度每N度劃分一個扇區分成360/N份,求每個扇區下RSRP值最大的前n個采樣點的RSRP均值,最后取RSRP均值最大的扇區角度為方位角預測值。
2.6 蒙特卡羅方法
為了將前面的五種算法進行聯合,通過蒙特卡羅方法隨機從訓練集中抽取一部分數據作為訓練樣本,共隨機選取P次得到P份訓練樣本;針對每份訓練樣本隨機生成Q個權重組合,Q為自然數;針對每個權重組合,統計訓練模型輸出的預測方位角與勘站方位角的偏差在R°以內的個數占比作為該權重組合的置信度,R的取值范圍為[0,360];針對每份訓練樣本,確定置信度最大的權重組合。
在具體實現時,按照如下公式(1)和(2),針對每份訓練樣本確定置信度最大的權重組合。

其中,公式(1)中的Z為實際預測誤差,angelpredict為預測方位角,angeltrue為勘站方位角;公式(2)中cost表示權重組合對應的誤差系數,M為訓練樣本中總勘站小區數量,K為設定的角度誤差閾值。
從上面的公式可知,權重組合的置信度為1-cost,例如,cost為20%,則權重組合的置信度就為1-20%,即為80%。
2.7 檢驗結果
對于上述的聯合算法模型,我們通過最終損失函數值來衡量改進,損失函數越小則越好,通過訓練出的最好模型可以對新的用戶數據進行預測方位角,并根據最終輸出的結果更新小區工參信息。最終選取一部分小區進行勘站,將預測結果和勘站數據進行對比,判斷算法的準確性。
3 實驗及結果
3.1 實驗
本文收集了國內某省30天691個小區的OTT(Over The Top)數據,并且對這691個小區進行勘站,獲取小區真實信息數據,從而計算聯合算法預測結果的準確性、穩定性。
為了確保數據的完整性,需要對數據進行異常值處理,對缺少小區唯一標識碼和經緯度信息的數據予以剔除,刪除采樣點中距離異常的數據和重復的采樣點數據。首先將訓練數據放到模型中訓練、預測,將每個算法得到的預測數據和誤差數據保存,接著將訓練數據放到聯合算法中訓練、預測,將得到的預測數據和誤差數據保存,最后是對比聯合算法和五種算法的預測效果,分別計算聯合算法和五種算法在訓練集、驗證集上的誤差,計算誤差小于20度(包含20度)的個數占比。
3.2 實驗結果
在實驗中發現,聯合算法的預測準確性更高,使用聯合算法進行預測,得到如下所示的一些相關圖。
圖2是實驗例中某個小區10米柵格級OTT采樣點RSRP熱力圖,從圖中可以看出該小區的識別碼、名稱、30天的采樣點數以及工參方位角和預測方位角,以及每個柵格中平均RSRP值的強弱。

圖2 10米柵格級OTT采樣點rsrp熱力圖
圖3是實驗例中某市預測方位角與勘站結果對比分析圖,分別計算了預測誤差小于等于20度、35度、45度的小區個數占比,從圖中可以看出預測偏差小于45度的小區占比達到96.88%,預測偏差小于35度的小區占比達到87.53%,預測偏差小于20度的小區占比達到80.39%,占比都較大,說明預測模型有較好的準確性。
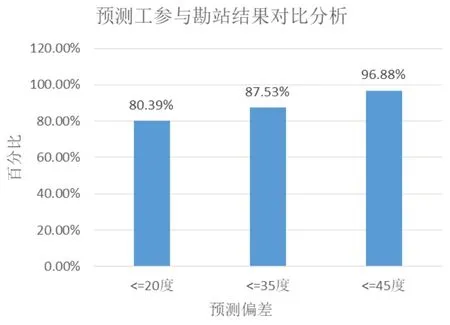
圖3 預測方位角與勘站結果對比分析圖
圖4、5、6分別是居民小區、道路小區、城中村小區預測工參與勘站結果對比分析圖,分別計算了預測誤差小于等于20度、35度、45度的小區個數占比,從圖中可以看出預測偏差小于45度的小區占比分別達到95.96%、95.96%、93.96%,預測偏差小于35度的小區占比分別達到81.25%、86.25%、87.25%,預測偏差小于20度的小區占比分別達到75.36%、82.35%、79.36%,占比都較大且表現一致,可以說明預測模型在道路、城中村等場景中都有較好的準確性。
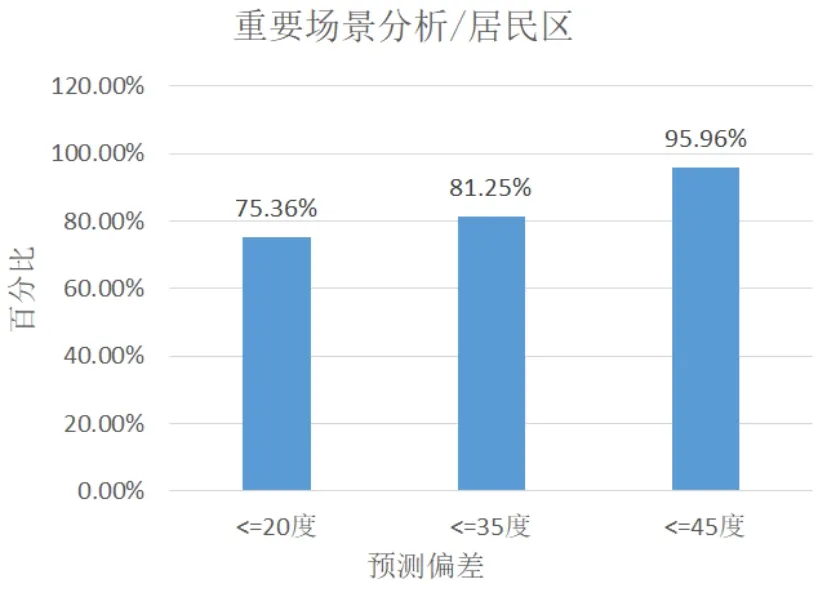
圖4 居民區小區預測方位角與勘站結果對比分析圖
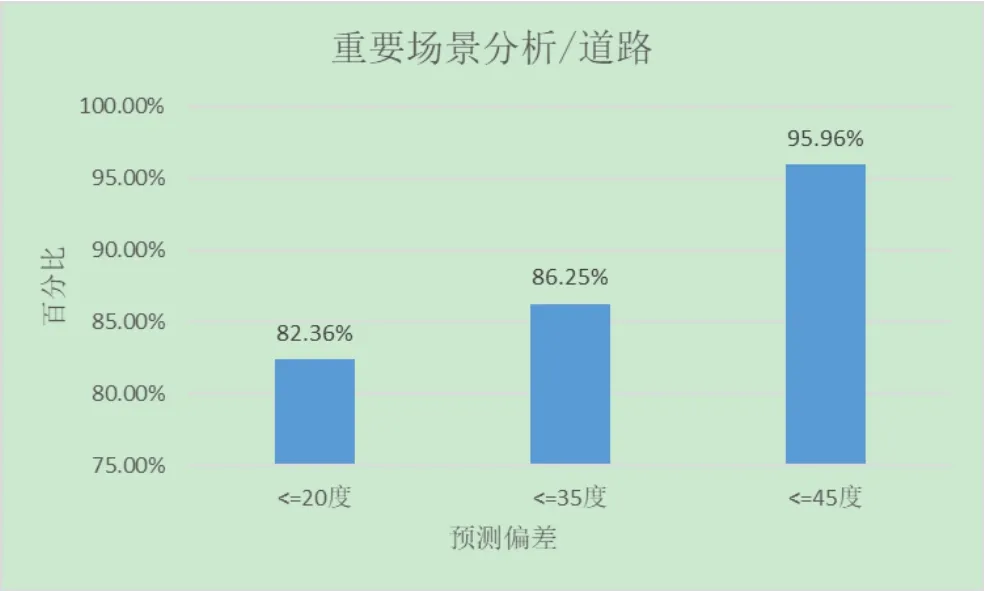
圖5 道路小區預測方位角與勘站結果對比分析圖
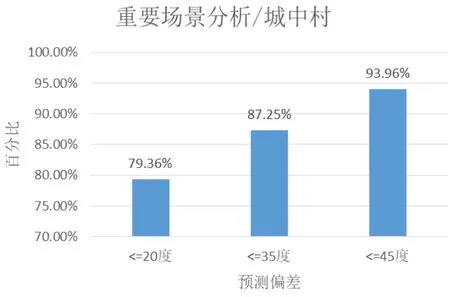
圖6 城中村小區預測方位角與勘站結果對比分析
圖7是實施例中方位角錯誤實際效果圖,該小區中根據OTT采樣點預測的方位角為75度,而實際勘測的方位角為60度,但是工參表中的方位角為20度,預測的方位角與實際勘測的方位角誤差較小,經驗證發現,該小區工參方位角為人為錄入錯誤,此算法為平臺軟件快速甄別小區方位角異常提供了理論及技術支撐。

圖7 小區方位角錯誤實際效果圖
圖8是實施例中接反小區實際效果圖,圖8中(a)和(b)的藍色加粗線條標注的扇形區域和紅色加粗線條標注的扇形區域表示兩個相鄰小區,小區周邊的各小圓圈表示采樣點。參見圖8中的(a)圖可知,利用本方法提供的上述預測模型,基于采樣點的數據,預測出第一個小區(紅色加粗線條標注的扇形區域)的方位角預測值為300度,而實際勘測第一個小區的方位角為187度;參見圖8中的(b)圖可知,基于采樣點的數據,預測出第二個小區(紅色加粗線條標注的扇形區域)的預測方位角為120度,而實際勘測第二個小區的方位角為293度,可見,這兩個相鄰小區的預測誤差很大,這提供給維護人員作為參考數據,維護人員現場核查發現這兩個小區的天線被人為接反,此算法為平臺軟件快速甄別接反小區提供了理論及技術支撐。

圖8 接反小區實際效果圖
4 結束語
本文提出了一種基于用戶數據實現天線方位角糾偏的方法,將五種預測算法聯合在一起,規避了單獨算法的一些缺點,提高了方法的準確性和穩定性。經實際勘站證明模型的準確性如下:預測偏差小于45度的小區占比達到96.88%,預測偏差小于35度的小區占比達到87.53%,預測偏差小于20度的小區占比達到80.39%,并且在各個場景表現一致。本文通過對分析的數據畫柵格級用戶數據RSRP熱力圖,獲得小區周圍的采樣點信息以及預測的方位角,通過更深層次的分析,可以找出工參中方位角錯誤、接反小區等問題,以對運營商的工參數據進行修正,對其網絡優化工作具有指導意義。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
