基于ShuffleNet的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索
2020-07-06 03:39:35胡金水劉辰宇吳航
中國新通信 2020年3期
胡金水 劉辰宇 吳航

摘要:神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的設(shè)計在深度學(xué)習(xí)任務(wù)中至關(guān)重要,自動神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計算法的思想是在特定實際任務(wù)下,減少人工參與,直接搜索出最優(yōu)模型結(jié)構(gòu)。本文提出一個基于ShuffleNet的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索算法,該算法將計算量限制嵌入進(jìn)演化搜索過程,自適應(yīng)地調(diào)整網(wǎng)絡(luò)結(jié)構(gòu)中的通道劃分比例和通道混淆策略。在實際任務(wù)應(yīng)用所需的計算量限制下,可搜索出最優(yōu)模型結(jié)構(gòu),并具備高效前向推理效率。
關(guān)鍵詞:前向推理;結(jié)構(gòu)搜索
引言
深度學(xué)習(xí)近年成為人了智能領(lǐng)域廣泛研究的一個熱門技術(shù)。深度學(xué)習(xí)可以理解成一個數(shù)據(jù)驅(qū)動的端到端的特征表示學(xué)習(xí)框架,這個框架中重要的構(gòu)成是神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。目前研究者提出了殘差網(wǎng)絡(luò)等一系列重要的網(wǎng)絡(luò)結(jié)構(gòu),提高了圖像識別、自然語言處理領(lǐng)域等眾多任務(wù)的效果,但是面向移動端的實際應(yīng)用,在保證識別率下降可控的前提下,如何提升神經(jīng)網(wǎng)絡(luò)的前向推理效率仍然是不可回避的難題。最近一些前向推理輕量級的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)相繼提出,一定程度上緩解了推理效率低的問題。通過端到端的方式來可以進(jìn)行特征表示學(xué)習(xí),是否可以設(shè)計一個算法,針對特定任務(wù),通過端到端的方式直接給出模型的結(jié)構(gòu)呢?
本文先簡單介紹神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索的最新進(jìn)展,接著提出一個輕量級的自動神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計算法,能根據(jù)實際任務(wù)的硬件算力,自適應(yīng)地調(diào)整網(wǎng)絡(luò)結(jié)構(gòu)中通道劃分比例和通道混淆策略。
一、神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索概述
神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索通過構(gòu)建一個RNN作為神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)采桿器,利用強化學(xué)習(xí)算法將采桿所得的神經(jīng)網(wǎng)絡(luò)的性能表現(xiàn)作為反饋去優(yōu)化該采桿器,使采樣器采桿所得的網(wǎng)絡(luò)性能達(dá)到最優(yōu)。但由于搜索空間龐大,每次采桿的子網(wǎng)絡(luò)都需要從頭進(jìn)行訓(xùn)練,需用450塊GPU訓(xùn)練長達(dá)數(shù)月,難以實用。為減少搜索耗時,有論文中改為搜索子結(jié)構(gòu),而完整網(wǎng)絡(luò)結(jié)構(gòu)則由這兩種網(wǎng)絡(luò)子結(jié)構(gòu)雄疊而成。由于這種模塊結(jié)構(gòu)搜索空間相對較小,搜索耗時降低了7倍。更有研究組通過構(gòu)建超網(wǎng)絡(luò)并引入權(quán)車共享的思想,在搜索效果略有下降的情況下僅用單塊GPU在一天內(nèi)即可實現(xiàn)。
此后,出于效率和資源消耗的考慮,基超網(wǎng)絡(luò)的搜索方案逐漸成為主流。由于強化學(xué)習(xí)算法搜索過程收斂較慢,性能不穩(wěn)定,業(yè)界又提出了One-shot NAS算法和DARTS算法。One-shot NAS算法將訓(xùn)練與搜索分開進(jìn)行,通過在超網(wǎng)絡(luò)里隨機采桿子網(wǎng)絡(luò)進(jìn)行超網(wǎng)絡(luò)訓(xùn)練,并對訓(xùn)好的超網(wǎng)絡(luò)通過EA算法進(jìn)行子網(wǎng)絡(luò)搜索,從而獲得最優(yōu)網(wǎng)絡(luò)結(jié)構(gòu)。而DARTS方案最早由CMU團(tuán)隊提出,通過松弛超網(wǎng)絡(luò)的所有子網(wǎng)絡(luò),利用超參進(jìn)行加權(quán)組合,通過梯度下降算法對該超參進(jìn)行優(yōu)化。最后,根據(jù)優(yōu)化結(jié)果即可獲得最優(yōu)子網(wǎng)絡(luò)。相比于另兩種方案,這種基于梯度優(yōu)化的方案效率極高,極大地減小了搜索耗時。
另一方面,采用網(wǎng)絡(luò)模塊結(jié)構(gòu)搜索空間,這桿搜索出來的網(wǎng)絡(luò)結(jié)構(gòu)效果較好,但由于網(wǎng)絡(luò)模塊內(nèi)部較為碎片化,難以實現(xiàn)并行計算,實際部署難度大,效率低。如果采用的是全局結(jié)構(gòu)搜索空間,搜索網(wǎng)絡(luò)空間包含深度寬度等模型結(jié)構(gòu)的大部分超參,這樣保證了獲得的網(wǎng)絡(luò)模塊結(jié)構(gòu)相對規(guī)整,使得網(wǎng)絡(luò)結(jié)構(gòu)部署相對簡單。
二、基于ShuffleNet的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索
(一)ShumeNet簡介
與殘差網(wǎng)絡(luò)等不同,ShuffleNet系列的模型通過引入有規(guī)則的通道打亂來增強輕量級Depthwise(DW)卷積后特征通道上的信息混疊,同時ShuKleNetV2又額外通過通道均分和拼接的操作移除了網(wǎng)絡(luò)中的碎片元組操作,使模型的效率和效果得到了進(jìn)一步提升。一個基本的ShuKleNetV2塊結(jié)構(gòu)如下圖1(a)所示。
通過分析,我們發(fā)現(xiàn)ShuKleNetV2的通道切分與拼接實際上是在不斷地進(jìn)行特征的整合與復(fù)用,且隨著通道上的不斷拆分與組合,通道上特征的實際深度是現(xiàn)出一種固定分布的特性。進(jìn)一步,當(dāng)我們不是考慮通道均分,而是考慮通用性更強的比例切分時,特征通道的實際深度仍然具有固定分布的特性。
考慮每次切分出比例為p的通道數(shù),當(dāng)圖1(a)中的ConvOP為DW卷積時,網(wǎng)絡(luò)第K層實際深度為j的通道數(shù)目占比為:
實際深度為i的通道數(shù)目占比為:
(二)搜索算法描述
根據(jù)式(3-1)、式(3-2)可知,在每層網(wǎng)絡(luò)切分比例固定的時候,最終特征的復(fù)用和組合是滿是與通道切分比例相關(guān)的固定分布的。如果我們對每層通道切分的比例進(jìn)行針對性建模優(yōu)化,就可以對不同任務(wù)、不同數(shù)據(jù)、不同計算量需求去靈活自動搜索出該場景可用的最優(yōu)模型,同時滿是所得模型的高效推理特性。
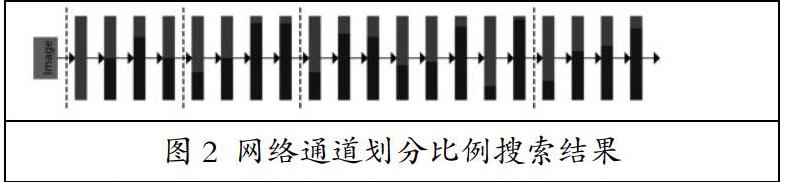
本文使用遺傳算法對自動通道切分結(jié)構(gòu)進(jìn)行了演化搜索,且將計算量限制嵌入進(jìn)演化過程,保證了計算資源限制下的最優(yōu)搜索。一個搜索空間和搜索結(jié)果的例子如圖1(b)、圖2所示,紅色代表著當(dāng)前層所使用的通道,藍(lán)色代表復(fù)用的通道,通過特征的不斷組合,算法可搜索㈩最優(yōu)模型結(jié)構(gòu),同時具備高效前向推理效率。
三、結(jié)論
本文提出了一個基于輕量級的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索算法。該算法基于遺傳算法對通道劃分比例和通道混淆策略進(jìn)行了演化搜索,將計算量限制嵌入進(jìn)演化過程,解決了受限計算資源下的神經(jīng)網(wǎng)絡(luò)大規(guī)模靈活應(yīng)用問題。
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
甘肅教育(2020年14期)2020-09-11 07:57:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛(wèi)生(2014年11期)2014-11-12 13:11:32
