A perspective on regression and Bayesian approaches for system identification of pattern formation dynamics
2020-07-01 05:13:50ZhenlinWngBoweiWuKrishnGrikiptiXunHun
Zhenlin Wng, Bowei Wu,b, Krishn Grikipti, Xun Hun,*
a Department of Mechanical Engineering, University of Michigan, Ann Arbor, MI 48109, USA
b Oden Institute for Computational Engineering and Sciences, University of Texas at Austin, Austin, TX 78712, USA
c Departments of Mechanical Engineering and Mathematics, Michigan Institute for Computational Discovery & Engineering, University of Michigan, Ann Arbor, MI 48109, USA
Keywords:Computational mechanics Materials physics Pattern formation Bayesian inference Inverse problem
ABSTRACT We present two approaches to system identification, i.e. the identification of partial differential equations (PDEs) from measurement data. The first is a regression-based variational system identification procedure that is advantageous in not requiring repeated forward model solves and has good scalability to large number of differential operators. However it has strict data type requirements needing the ability to directly represent the operators through the available data.The second is a Bayesian inference framework highly valuable for providing uncertainty quantification, and flexible for accommodating sparse and noisy data that may also be indirect quantities of interest. However, it also requires repeated forward solutions of the PDE models which is expensive and hinders scalability. We provide illustrations of results on a model problem for pattern formation dynamics, and discuss merits of the presented methods.
Pattern formation is a widely observed phenomenon in diverse fields including materials physics, developmental biology and ecology among many others. The physics underlying the patterns is specific to the mechanisms, and is encoded by partial differential equations (PDEs). Models of phase separation [1, 2]are widely employed in materials physics. Following Turing's seminal work on reaction-diffusion systems [3], a robust literature has developed on the application of nonlinear versions of this class of PDEs to model pattern formation in developmental biology [4–12]. Reaction-diffusion equations also appear in ecology, where they are more commonly referred to as activator-inhibitor systems, and are found to underlie large scale patterning[13, 14].
All these pattern forming systems fall into the class of nonlinear, parabolic PDEs. They can be written as systems of first-order dynamics driven by a number of time-independent terms of algebraic and differential form. The spatiotemporal, differentioalgebraic operators act on either a composition (normalized concentration) or an order parameter. It also is common for the algebraic and differential terms to be coupled across multiple species. Identification of participating PDE operators from spatio-temporal observations can thus uncover the underlying physical mechanisms, and lead to improved understanding, prediction, and manipulation of these systems.
Concomitant with the increasing availability of experimental data and advances in experimental techniques and diagnostics,there has been significant development in techniques for system identification. Early work in parameter identification within a given system of PDEs can be traced to nonlinear regression approaches [15–18] and Bayesian inference [19, 20]. Without knowing the PDEs, the complete underlying governing equations could be extracted from data by combining symbolic regression and genetic programming to infer algebraic expressions along with their coefficients [21, 22]. Recently, sparse regression techniques for system identification have been developed to determine the operators in PDEs from a comprehensive library of candidates [23–28]. Bayesian methods for system identification have also been proposed [29, 30] but mostly used for algebraic or ordinary differential equations and not yet deployed to PDE systems. In a different approach to solving the inverse problems,deep neural networks are trained to directly represent the solution variable [31, 32]. Using the neural network representations,the parameters within the given PDEs can be inferred through the approach of physics-informed neural network with strong forms of the target one- and two-dimensional PDEs embedded in the loss functions [33].
One may broadly categorize the various approaches for system identification to those that access different data type (full field versus sparse quantities of interest (QoI)), and whether employing a deterministic or probabilistic framework (regression versus Bayesian) (see Fig. 1). In this paper, we focus on two methods that we have recently developed, falling in the top-left and bottom-right quadrants: (a) a stepwise regression approach coupled with variational system identification (VSI) based on the weak form that is highly effective in handling large quantities of composition field measurements [28], and (b) a Bayesian inference framework that offers quantified uncertainty, and is therefore well-suited for sparse and noisy data and flexible for different types of QoIs. The key objective and novelty of this paper is then to provide a perspective and comparison on the contrasting advantages and limitations of these two approaches for performing system identification. We illustrate key highlights of these techniques and compare their results through a model problem example below.
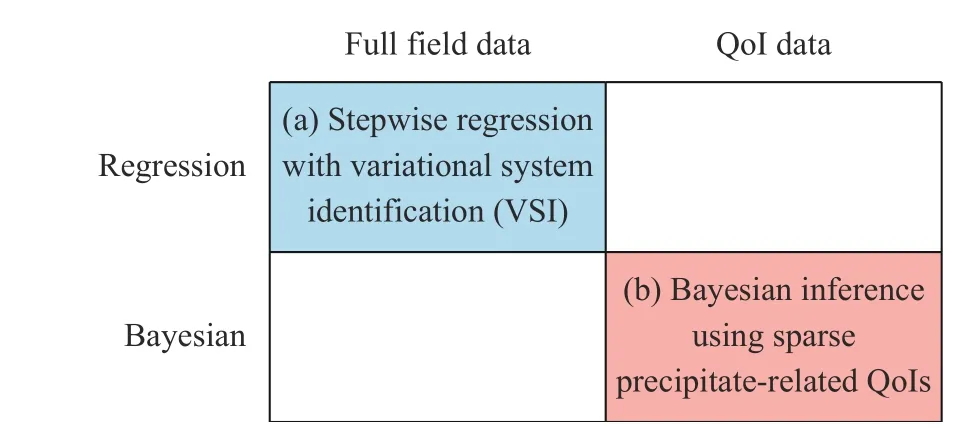
Fig. 1. Broad categorization of system identification approaches,with our paper focusing on two methods falling in the top-left and bottom-right quadrants.
Model problem. For demonstration, consider the following model form in [0, T] × ?:
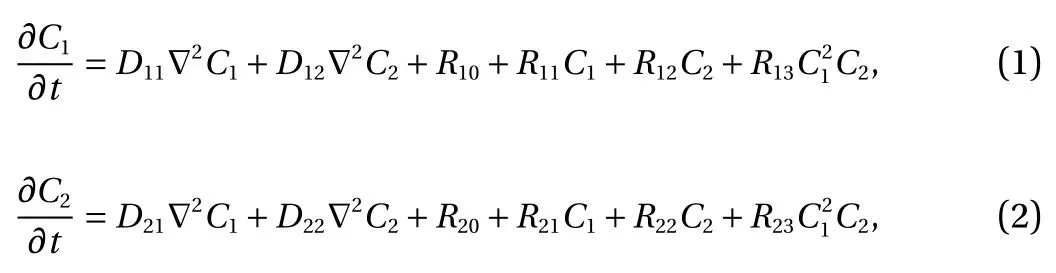
with
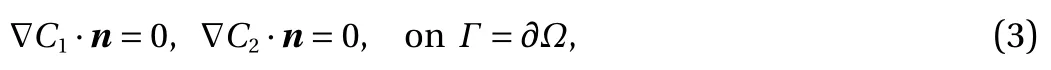
and
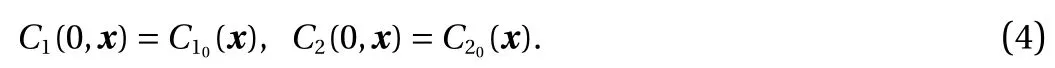
Here, C1(t, x) and C2(t, x) are the compositions, with diffusivities D11,D12,...,D22and reaction rates R10,R11,...,R23assumed constant in space and time. This model represents the coupled diffusion-reaction equations for two species following Schnakenberg kinetics [34]. For an activator-inhibitor species pair having autoinhibition with cross-activation of a short range species, and auto-activation with cross-inhibition of a long range species, these equations form so-called Turing patterns [3]. For simplicity, we pose the above initial and boundary value problem to be one-dimensional in space for x ∈(?40,40). A relatively fine uniform grid of 401 points is used to numerically discretize x; we note that data corresponding to too coarse of a resolution may lead to incorrect VSI results, and refer readers to Ref. [28] for a discussion on the data discretization fidelity. The initial conditions for all simulations are set to C10(x)=0.5 and C20(x)=0.5, and the value at each grid point is further corrupted with an independent perturbation drawn uniformly from [?0.01,0.01] in order to represent measurement error and experimental variability. Three sets of different diffusivities are considered to illustrate scenarios inducing different particle sizes (see Fig. 2 for examples of the composition fields under these three different parameter sets at time snapshot t = 15, which is long enough for the precipitates to have formed). The true prefactors of the PDE operators are summarized in Table 1. Our goal for the system identification problem is to estimate these PDE operator prefactors from available measurement data.
VSI and stepwise regression using composition field data.When composition field data are available, the PDEs themselves can be represented directly. This can be achieved by constructing the operators either in strong form, such as with finite differencing in the sparse identification of nonlinear dynamics(SINDy) approach [23], or in weak form built upon basis functions in the VSI framework [28]. The weak form transfers derivatives to the weighting function, thus requiring less smoothness of the actual solution fields C1and C2that are constructed from data and allowing the robust construction of higher-order derivatives. Another advantage of using the weak form is that Neumann boundary conditions are explicitly included as surface integrals, making their identification feasible. We briefly present VSI in conjunction with stepwise regression below, while referring readers to Ref. [28] for further details and discussions.
For infinite-dimensional problems with Dirichlet boundary conditions on Γc, the weak form corresponding to the strong form in Eq. (1) or (2) is, ? w ∈V={w|w=0, on Γc}, find C such that

where ? is the domain, χ is the vector containing all possible independent operators in weak form:
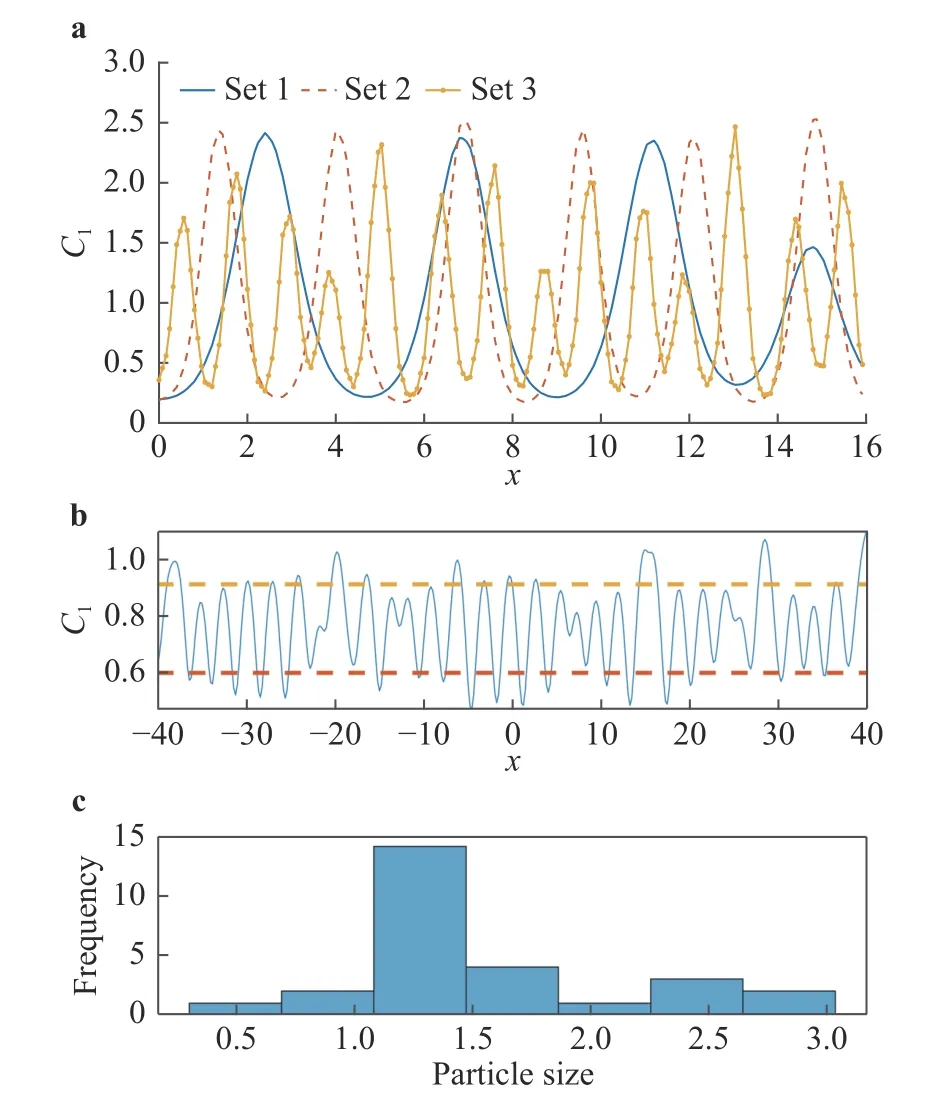
are the average of local maxima and average of local minima . c Histogram of the particle sizes corresponding to the top fig-Fig. 2. a C1 fields over a zoomed-in range of x at time snapshot t =15 generated using the three parameter cases. We see that the different diffusivity values in the three cases indeed lead to particles (the“crests”) of different sizes. b Example field C where the dashed lines ure, whose sample mean μ and standard deviation σ are chosen by us to be two of our QoIs in this problem. Together are our QoIs.
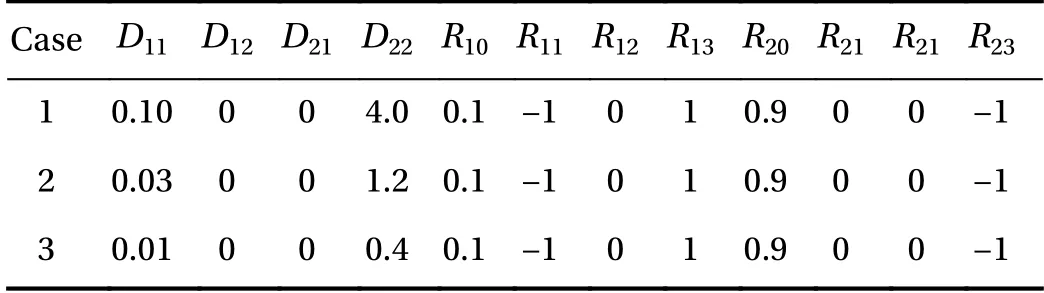
Table 1 True PDE operator prefactors for the three different cases.
and ω is the vector of operator prefactors. Using this notation,ω=[D11,D12,R10,...,R13] for Eq. (1) and ω=[D21,D22,R20,...,R23]for Eq. (2). Upon integration by parts, application of appropriate boundary conditions, and accounting for the arbitrariness of w,the finite-dimensionality leads to a vector system of residual equations: R =y ?χω, where y is the time derivative term and may be represented via a backward difference approximation

with Nidenoting the basis function corresponding to degree of freedom (DOF) i, and ? t=t1?tn?1the time step. While other time-marching schemes are certainly also possible, we use backward differencing here for its simplicity, stability, and as a representative choice for illustration purposes when the focus of our problem is not on time-marching specifically. The other operators in χ are constructed similarly and grouped together into the matrix χ. Minimizing the residual norm towards ∥R∥=0 then yields the linear regression problem

The construction of this linear system is quite inexpensive,equivalent to the finite element assembly process where the computational cost is a very small fraction of the overall solution process (even when considering a large set of candidate operators). Furthermore, this system only needs to be constructed once in the entire VSI procedure, and the subsequent regression steps do not ever need them to be reconstructed; this is because y and χ are constructed from data which are given and fixed.Solving Eq. (8) via standard regression, especially with noisy data, will lead to a non-sparse ω. Such a result will not sharply delineate the relevant bases for parsimonious identification of the governing system. Sparse regression (compressive sensing)techniques such as L1-based regularization are useful to promote sparse solutions of retained operators, but we found their performance for system identification to be highly sensitive to the selection of regularization parameters. We therefore use backward model selection by stepwise regression coupled with a statistical F-test, thus taking an approach to iteratively and gradually remove inactive operators instead of attempting to find a solution in one shot. Starting from a dictionary containing all relevant operators (such as in Eqs. (1) and (2)) and while the residual remains small, we eliminate the inactive operators iteratively until the model become underfit as indicated by a drastic increase of residual norm. Extensive algorithmic details are available in Ref. [28].
With clean (noiseless) composition field data, VSI can pinpoint the complete governing equations of our model problem using data from as few as two time instants. Figure 3 shows the inferred operator prefactors for Eqs. (1) and (2) on the left, which is achieved when the residual norm increases dramatically upon further elimination of operators as shown in Fig. 4. All prefactors are correctly identified with high accuracy with reference to Table 1. Investigations of the effects from varying fidelity and data noise are further discussed in Ref. [28]. The main advantages of this approach are: (a) repeated forward PDE solves are not necessary and it is therefore computationally very fast, and (b) its efficiency can accommodate a large dictionary of candidate PDE operators, such as illustrated in Ref. [28] with more than 30 operators. However, this approach requires the availability of composition field data (full or partial [Ref. 35]) at instants separated by sufficiently small time steps, Δt.
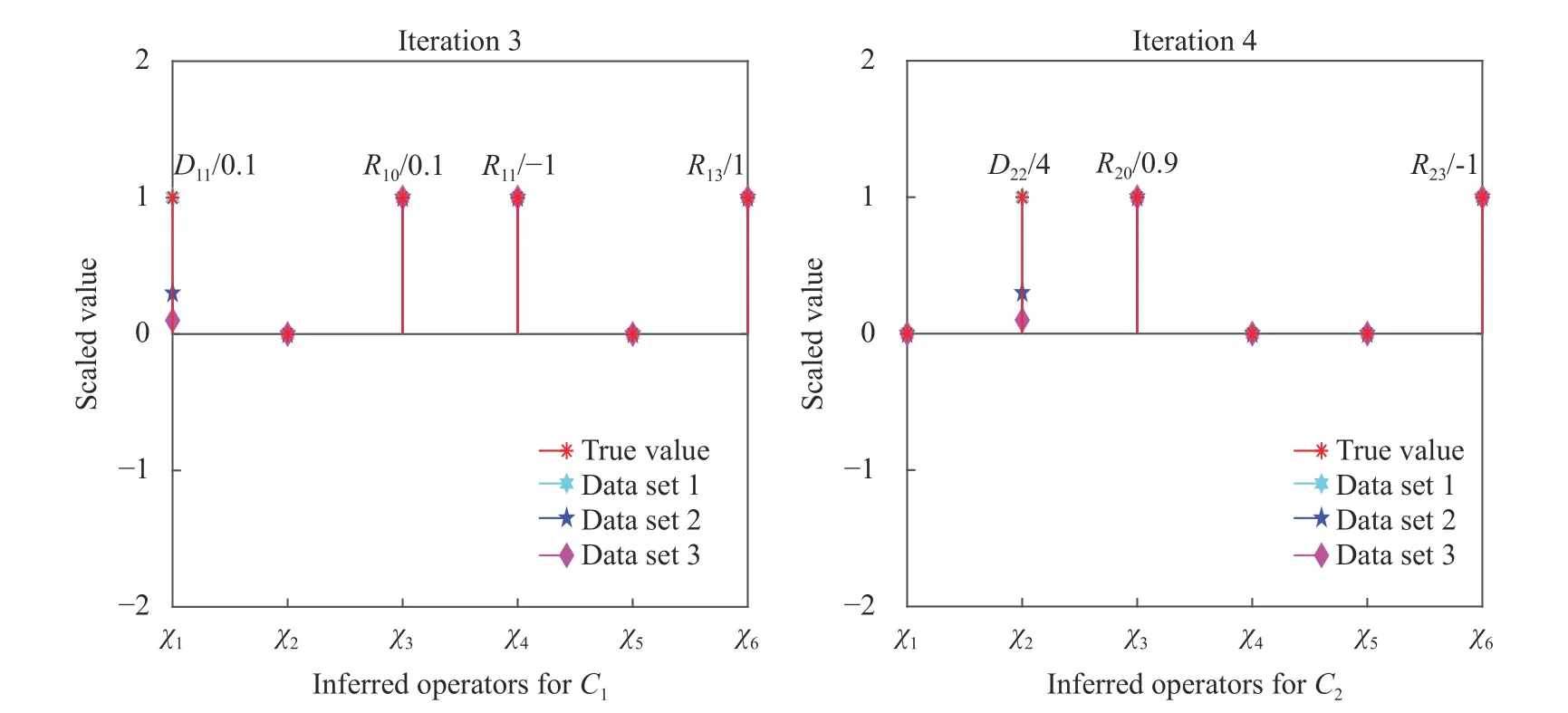
Fig. 3. Inferred operator prefactors at final iteration of the stepwise regression using composition field data generated from the three parameter sets. The identified coefficients of active operators on the y-axis are scaled by the true values of the first parameter set (for better visual presentation). Labels for the corresponding operators, χ 1,χ2,...,χ6, are shown on the x-axis and their definitions can be found previously in Eq.(6). All final VSI results achieve machine zero error here.
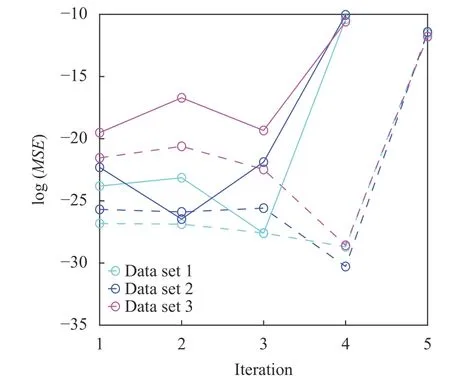
Fig. 4. Residual norm at each iteration using composition field data generated from the three parameter sets. The algorithm for identifying governing equations of C1 (shown by solid curves) and C2(shown by dashed curves), respectively, converged at iterations number 3 or 4, beyond which the residual increases dramatically if any more operators are eliminated.
Bayesian inference using QoIs. When only sparse and noisy data are available, the quantification of uncertainty in the prefactor estimates becomes highly important. Bayesian statistics[36, 37] provides a mathematically rigorous framework for solving the system identification problem while capturing uncertainty, and is particularly flexible in accommodating different QoIs simultaneously, that may also be arbitrary functionals of the solution fields. Letdenote the set of available QoI measurement data. Bayes' theorem states

where p (ω|D) is the posterior probability density function (PDF),p(D|ω) is the likelihood function, and p(ω) is the prior. For example, in this work we choose priors for the prefactors to be log-normal and normal distributions, and model the likelihood to exhibit an additive Gaussian data noise: D =G(ω)+? where G (ω) is the forward model (i.e., PDE solve) andis a zero-mean independent (Σ diagonal) Gaussian random variable depicting measurement noise. The likelihood PDF can then be evaluated via p (D|ω)=p?(D ?G(ω)) where p?is the PDF of the multivariate Gaussian ?, hence each likelihood evaluation entails a forward PDE solve and together make up the most expensive portion of a Bayesian inference procedure. Solving the Bayesian inference problem then entails characterizing the posterior—that is, the distribution of the prefactors conditioned on the available data—from evaluations of the prior and likelihood PDFs.
While different Bayesian inference algorithm exist, the primary method is Markov chain Monte Carlo (MCMC) [38] that involves constructing a Markov chain exploring the parameter space in proportion to the true posterior measure. Variants of MCMC, especially when equipped with effective proposal mechanisms, are particularly powerful as they only require evaluations of p (ω|D) up to a normalization constant, which enables us to use only the prior and likelihood without needing to estimate the constant of proportionality on the righthand-side of Eq.(9), an otherwise extremely difficult task. In this work, we demonstrate the Bayesian framework using the delayed rejection adaptive Metropolis (DRAM) algorithm [39], which is a simple yet effective method that offers secondary proposal distributions and adapts proposal covariance based on chain history to better match the true target distribution. A brief summary of DRAM steps is provided below (please see Ref. [39] for full details), where we see that each of these MCMC iterations requires a new likelihood evaluation in Step 2 (and possibly also Step 4 if 1st-stage encountered a rejection) and thus a forward PDE model solve, and this requirement for repeated PDE solves can become computationally intensive or even prohibitive for some problems.
1. From current chain location ωt, propose ωt+1from 1ststage proposal distribution;
3. Draw u1~U(0,1), accept ωt+1if u1< α1and go to Step 5, else reject;
4. (Delayed rejection) If rejected in Step 3, re-propose ωt+1from 2nd-stage proposal (usually smaller in scale compared to 1st-stage proposal) and evaluate α2and u2to decide acceptance/rejection (detailed formulas in Ref. [39]);
5. (Adaptive Metropolis) At regular intervals (e.g., every 10 iterations) update proposal distributions using the sample covariance computed from the Markov chain history.
In practice, surrogate models (e.g., polynomial chaos expansions, Gaussian processes, neural networks) are often employed to accelerate the Bayesian inference.
Our Bayesian example targets the same system in Eqs. (1)and (2). We generate synthetic data D by first solving the PDEs using the true prefactors from Table 1 to obtain C1and C2at at only two (sparse) time snapshots (t = 7.5 and 15), then for each field we calculate four QoIswhich are respectively the mean and standard deviation of particle size distribution, and the composition field average local maxima and minima (see Fig. 2b). Hence D contains(2 species)×(2 snapshots)=16 scalars. Leveraging and illustrating the Bayesian prior as a mechanism to introduce physical constraints and domain expert knowledge, we set D12and D21to zero from prior knowledge and endow normal prior distributions for the remaining 10-dimensional ω prefactor vector, except furthermore targeting log D12and log D21to ensure positivity of diffusion coefficients.
Figure 5 presents for Case 2 (Cases 1 and 3 yielded similar results and are omitted for brevity) the posterior PDF contours and selected chain traces that visually appear to be well-mixed.The posterior contours are plotted using a kernel density estimator, and the diagonal panels represent marginal distributions while off-diagonals are the pairwise joint distributions illustrating first-order correlation effects. Overall, strong correlations and non-Gaussian structures are present. The summarizing statistics (mean ± 1-standard-deviation) for the posterior marginals are presented in Table 2, all agreeing well with the true values for Case 2 although residual uncertainty remains. For system identification, sparse solutions may be sought by employing sparsityinducing priors (e.g., Laplace priors), coupled with eliminating prefactors that concentrate around zero with a sufficiently small uncertainty based on a thresholding policy analogous to that in the stepwise regression procedure. As an example, from Table 2,we may choose to eliminate prefactors based on criteria satisfying (a) the marginal posterior standard deviation falls below 10%of the largest marginal posterior mean magnitude (i.e., achieving a relative precision requirement), and (b) the interval of mean ± 1-standard-deviation covers zero (i.e., supporting operator to be inactive). This would lead to the elimination of R12in this case, while R21and R22(which are also zero in the true solution) cannot be eliminated yet since the available (sparse and noisy) data are not enough in reducing the uncertainty sufficiently to arrive at a conclusion. We note that the criteria above only serve as an example, and better thresholding strategies should be explored. The main advantages of this approach are:(a) the ability to quantify uncertainty in prefactor estimates, thus making it valuable for sparse and noisy data, and (b) its flexibility in accommodating various types of indirect QoIs that do not explicitly participate in the governing PDE. The drawback of this approach is its high computational cost, and weaker scalability compared to the regression VSI method introduced previously.
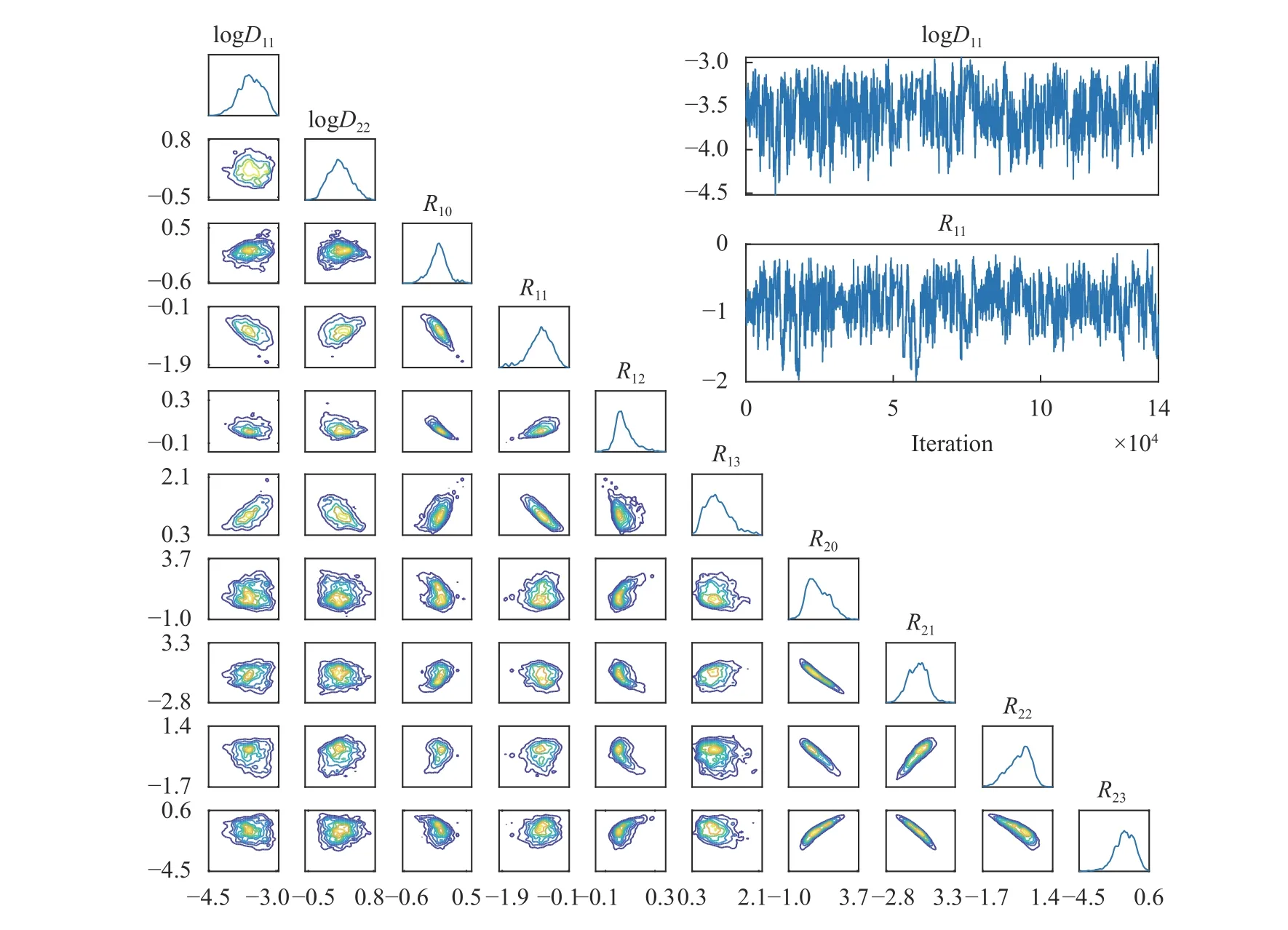
Fig. 5. Lower left: marginal and pairwise joint posterior distributions of the ω for Case 2. Upper right: select chain traces of MCMC.
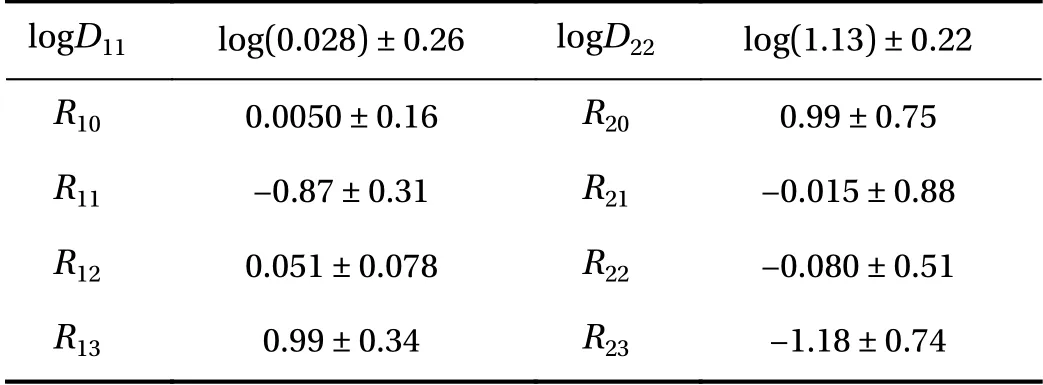
Table 2 Bayesian inference marginal posterior mean ± 1-standarddeviation for the PDE operator prefactors. We emphasize that these are summarizing statistics for the Bayesian posterior that reflect the remaining uncertainty conditioned on the particular available data,and should not be compared to the true parameter values and then interpreted as an accuracy assessment.
Summarizing remarks. In this paper we presented a perspective and comparison on the contrasting advantages and limitations of two approaches of system identification from a broader categorization of methods in Fig. 1, with illustration on a model problem for pattern formation dynamics. The first approach is a regression-based VSI procedure, which has the advantage of not requiring repeated forward PDE solutions and scales well to handle large numbers of candidate PDE operators. However this approach requires specific types of data where the PDE operators themselves can be directly represented through these data.More recently, we also have extended the VSI approach to uncorrelated, sparse and multi-source data for pattern forming physics [35]. However, as may be expected, data at high spatial and temporal resolution deliver more accurate identification outcomes. The second approach uses Bayesian statistics, and has advantages in its ability to provide uncertainty quantification. It also offers significant flexibility in accommodating sparse and noisy data that may also be different types of indirect QoIs.However, this approach requires repeated forward solutions of the PDE models, which is computationally expensive and may quickly become impractical when the number of PDE terms (i.e.,dimension of the identification problem) becomes high. It is thus best used in conjunction with surrogate models and other dimension reduction techniques.
Acknowledgements
We acknowledge the support of Defense Advanced Research Projects Agency (Grant HR00111990S2), as well as of Toyota Research Institute (Award #849910).
 Theoretical & Applied Mechanics Letters2020年3期
Theoretical & Applied Mechanics Letters2020年3期
- Theoretical & Applied Mechanics Letters的其它文章
- Physics-informed deep learning for incompressible laminar flows
- Learning material law from displacement fields by artificial neural network
- Multi-fidelity Gaussian process based empirical potential development for Si:H nanowires
- Nonnegativity-enforced Gaussian process regression
- Reducing parameter space for neural network training
- Physics-constrained bayesian neural network for fluid flow reconstruction with sparse and noisy data