基于Greenplum的城軌信號(hào)系統(tǒng)車(chē)載日志大數(shù)據(jù)分析平臺(tái)
2020-06-30 06:56:44魏盛昕張奕男
鐵路計(jì)算機(jī)應(yīng)用 2020年6期
謝 飛,魏盛昕,張奕男
(1.卡斯柯信號(hào)(成都)有限公司,成都 610083;2.卡斯柯信號(hào)有限公司,上海 200071)
隨著我國(guó)城市軌道交通迅猛發(fā)展,信號(hào)系統(tǒng)的運(yùn)營(yíng)維護(hù)也朝著自動(dòng)化、可視化和智能化方面發(fā)展,其獲取的數(shù)據(jù)量呈現(xiàn)指數(shù)級(jí)增長(zhǎng)且規(guī)模日益龐大,如何處理這些海量數(shù)據(jù)并挖掘其價(jià)值已成為業(yè)內(nèi)的一個(gè)難題[1]。國(guó)內(nèi)各地鐵公司都在探索如何應(yīng)用大數(shù)據(jù)技術(shù)解決在實(shí)際運(yùn)維過(guò)程中的問(wèn)題,例如:杜時(shí)勇[2]提出了利用大數(shù)據(jù)搭建信號(hào)系統(tǒng)線網(wǎng)智能運(yùn)維平臺(tái),楊文軒[3]提出了基于Hadoop 平臺(tái)構(gòu)建城軌信號(hào)系統(tǒng)健康維護(hù)平臺(tái),但是,目前主要依賴信號(hào)系統(tǒng)定制化的監(jiān)測(cè)系統(tǒng)實(shí)現(xiàn)數(shù)據(jù)存儲(chǔ)與分析,很少直接去分析車(chē)載日志,因此,無(wú)法對(duì)關(guān)鍵信息進(jìn)行深度挖掘,不利于系統(tǒng)安全保障能力的提升。本文旨在構(gòu)建一種能夠?qū)A康男盘?hào)系統(tǒng)車(chē)載日志T+1 離線分析的大數(shù)據(jù)平臺(tái),實(shí)現(xiàn)對(duì)車(chē)載日志的統(tǒng)計(jì)分析和高效管理,以便為地鐵公司的日常運(yùn)維與保障工作提供更好的決策支撐。
1 車(chē)載日志大數(shù)據(jù)分析平臺(tái)需求
1.1 城軌信號(hào)系統(tǒng)車(chē)載日志特點(diǎn)
(1)缺乏日志數(shù)據(jù)的集中管理
在城市軌道交通建設(shè)過(guò)程中,不同線路采用不同廠家的信號(hào)系統(tǒng),存在標(biāo)準(zhǔn)不統(tǒng)一,各線路之間多為隔離狀態(tài),日志數(shù)據(jù)分散在各個(gè)數(shù)據(jù)孤島中,不同線路之間無(wú)法進(jìn)行數(shù)據(jù)的交互和統(tǒng)一管理。
(2)日志分析手段落后
當(dāng)信號(hào)系統(tǒng)車(chē)載設(shè)備或模塊發(fā)生故障時(shí),地鐵公司需要上車(chē)拷貝日志,然后通過(guò)日志工具對(duì)車(chē)載日志文件逐個(gè)分析,存在效率低下、過(guò)程繁瑣等問(wèn)題。
(3)傳統(tǒng)數(shù)據(jù)庫(kù)架構(gòu)無(wú)法滿足需求
據(jù)估算,1 條擁有40 列車(chē)的線路每天將會(huì)產(chǎn)生近1 億條原始數(shù)據(jù),1 年下來(lái)將累積達(dá)到近300 億條的數(shù)據(jù)規(guī)模。在傳統(tǒng)數(shù)據(jù)庫(kù)架構(gòu)下,受單機(jī)性能的限制,要處理如此大的數(shù)據(jù)量,已經(jīng)無(wú)法滿足用戶快速、及時(shí)的查詢需求。
1.2 車(chē)載日志大數(shù)據(jù)分析平臺(tái)需求
(1)平臺(tái)架構(gòu)需考慮支持多線路車(chē)載日志數(shù)據(jù)的分析,打破不同線路信號(hào)系統(tǒng)之間的數(shù)據(jù)壁壘。
(2)平臺(tái)架構(gòu)需考慮支持通過(guò)無(wú)線網(wǎng)絡(luò)下載車(chē)載日志,并自動(dòng)完成車(chē)載日志數(shù)據(jù)的解析與存儲(chǔ)。
(3)平臺(tái)架構(gòu)需考慮滿足數(shù)據(jù)大容量、高可用和高擴(kuò)展性的需求[4]。
(4)平臺(tái)架構(gòu)需考慮地鐵公司實(shí)際運(yùn)維的特點(diǎn),保證數(shù)據(jù)的處理能夠在規(guī)定時(shí)間范圍內(nèi)完成。
(5)平臺(tái)規(guī)模與造價(jià)需要控制在合理范圍內(nèi)[5]。
2 基于Greenplum的車(chē)載日志大數(shù)據(jù)分析平臺(tái)設(shè)計(jì)
2.1 Greenplum介紹
Greenplum 是基于PostgreSQL 開(kāi)發(fā)的數(shù)據(jù)庫(kù)集群,每個(gè)單獨(dú)的節(jié)點(diǎn)都是一個(gè)PostgreSQL 數(shù)據(jù)庫(kù),其采用的是Shared-Nothing 架構(gòu)[6],每一個(gè)節(jié)點(diǎn)的CPU、內(nèi)存等資源都是獨(dú)立的,每個(gè)節(jié)點(diǎn)都有全部數(shù)據(jù)的其中一部分。在用戶體驗(yàn)方面,Greenplum 與傳統(tǒng)數(shù)據(jù)庫(kù)類似,但在任務(wù)處理上卻有本質(zhì)的區(qū)別[7],它能將任務(wù)分配給多個(gè)節(jié)點(diǎn)服務(wù)器主機(jī),實(shí)現(xiàn)對(duì)分布式事務(wù)的高效管理,在金融、保險(xiǎn)、證券、通信、航空等領(lǐng)域都有著廣泛的運(yùn)用。
本文選擇Greenplum 搭建車(chē)載日志大數(shù)據(jù)分析平臺(tái),主要還考慮到其擁有的一些獨(dú)特優(yōu)勢(shì):
(1)開(kāi)源項(xiàng)目,其造價(jià)低,部署靈活且不受限于硬件環(huán)境和平臺(tái),允許客戶能根據(jù)自身需求選擇最適合的方案,從而降低未來(lái)的遷移代價(jià)。
(2)關(guān)系型數(shù)據(jù)庫(kù),雖然每天產(chǎn)生的車(chē)載日志數(shù)據(jù)量大,但數(shù)據(jù)本身是結(jié)構(gòu)化數(shù)據(jù),開(kāi)發(fā)與運(yùn)維人員不需要學(xué)習(xí)很多新的數(shù)據(jù)庫(kù)處理技術(shù),能夠降低人力成本。
(3)支持處理和分析多種數(shù)據(jù)源,包括 Kafka、Hadoop、HIVE、HBase、S3、Gemfire 及各種關(guān)系型數(shù)據(jù)庫(kù)和文件等,便于后續(xù)平臺(tái)的擴(kuò)展改造。
2.2 平臺(tái)架構(gòu)設(shè)計(jì)
為了滿足地鐵信號(hào)系統(tǒng)中海量車(chē)載日志的分析需求,基于Greenplum 的車(chē)載日志大數(shù)據(jù)分析平臺(tái)主要由數(shù)據(jù)源層、數(shù)據(jù)采集層、數(shù)據(jù)存儲(chǔ)層、數(shù)據(jù)分析層、應(yīng)用展示層構(gòu)成,其平臺(tái)架構(gòu),如圖1 所示。

圖1 基于Greenplum的車(chē)載日志大數(shù)據(jù)分析平臺(tái)架構(gòu)
2.2.1 數(shù)據(jù)源層
數(shù)據(jù)源層主要由車(chē)載數(shù)據(jù)日志單元(DLU)板卡、線路服務(wù)器、線網(wǎng)服務(wù)器及綜合監(jiān)測(cè)系統(tǒng)構(gòu)成。DLU 板卡完成對(duì)列車(chē)所有行車(chē)日志的存儲(chǔ),經(jīng)由車(chē)- 地?zé)o線通道把日志文件傳送到線路服務(wù)器,線路服務(wù)器將本地的車(chē)載日志文件經(jīng)由FTP 軟件再同步至線網(wǎng)服務(wù)器上。另外,地鐵綜合監(jiān)測(cè)系統(tǒng)存儲(chǔ)著列車(chē)在線路上運(yùn)行過(guò)程中的綜合告警記錄。
2.2.2 數(shù)據(jù)采集層
數(shù)據(jù)采集層主要負(fù)責(zé)對(duì)車(chē)載日志數(shù)據(jù)的采集、解析以及入庫(kù),其中,車(chē)載日志分為ATP 和ATO2種日志。數(shù)據(jù)采集主要分為2 部分:(1)通過(guò)FTP方式下載車(chē)載日志文件;(2)從Oracle 數(shù)據(jù)庫(kù)同步綜合監(jiān)測(cè)系統(tǒng)的告警記錄。大數(shù)據(jù)平臺(tái)通過(guò)FTP 方式從線網(wǎng)服務(wù)器中下載車(chē)載日志文件,并對(duì)完整的日志文件按照數(shù)據(jù)協(xié)議進(jìn)行解析。解析后的日志數(shù)據(jù)將推送給基于kafka+Zookeeper 的消息中間件,最終這些消息流數(shù)據(jù)將被Greenplum Stream Server(GPSS)消費(fèi),完成到大數(shù)據(jù)平臺(tái)的入庫(kù)操作,具體處理流程,如圖2 所示。
2.2.3 數(shù)據(jù)存儲(chǔ)層
數(shù)據(jù)存儲(chǔ)層負(fù)責(zé)對(duì)采集處理后的日志數(shù)據(jù)和告警記錄進(jìn)行存儲(chǔ)。大數(shù)據(jù)平臺(tái)采用Greenplum 對(duì)日志數(shù)據(jù)進(jìn)行存儲(chǔ)管理,采用MySQL 對(duì)車(chē)載日志文件進(jìn)行FTP 下載記錄管理,采用Oracle 對(duì)綜合監(jiān)測(cè)系統(tǒng)的告警記錄進(jìn)行管理。
2.2.4 數(shù)據(jù)分析層
數(shù)據(jù)分析層負(fù)責(zé)對(duì)大數(shù)據(jù)平臺(tái)存儲(chǔ)的日志數(shù)據(jù)和告警數(shù)據(jù)進(jìn)行統(tǒng)計(jì)和分析,同時(shí)結(jié)合各業(yè)務(wù)主體需求整理出用于運(yùn)維決策和應(yīng)用端展示所需要的統(tǒng)計(jì)數(shù)據(jù)。大數(shù)據(jù)平臺(tái)在數(shù)據(jù)積累的基礎(chǔ)上,可以應(yīng)用目前機(jī)械學(xué)習(xí)領(lǐng)域中相對(duì)成熟的算法挖掘出車(chē)載日志中關(guān)鍵設(shè)備或系統(tǒng)模塊的失效原因和故障趨勢(shì)。
2.2.5 應(yīng)用展示層
本研究以生態(tài)語(yǔ)言學(xué)理論、建構(gòu)主義理論、ESP理論等為理論依據(jù),采用調(diào)查、文獻(xiàn)、比較等研究方法,并遵循以下思路開(kāi)展研究。先調(diào)研分析高職公共英語(yǔ)教學(xué)現(xiàn)狀及其所存弊端,提出其改革需融入EOP的必要性;再分析融入EOP后原高職公共英語(yǔ)教學(xué)生態(tài)失衡產(chǎn)生的失調(diào)現(xiàn)象及不良影響,論證重構(gòu)融入EOP的教學(xué)生態(tài)的可行性;然后明晰改革思路,開(kāi)發(fā)EOP教學(xué)資源,開(kāi)展考核學(xué)生英語(yǔ)應(yīng)用能力的多元評(píng)價(jià),加強(qiáng)EOP師資建設(shè),實(shí)現(xiàn)高職公共英語(yǔ)教學(xué)生態(tài)再平衡;最后總結(jié)研究成果,并在其他高職推廣。具體研究如下三大內(nèi)容。
應(yīng)用展示層負(fù)責(zé)把數(shù)據(jù)分析層整理出的結(jié)果數(shù)據(jù),通過(guò)PC 端和大屏端向地鐵用戶進(jìn)行展示和應(yīng)用,主要包括列車(chē)停站時(shí)間、停車(chē)精度、緊急制動(dòng)(EB)、信標(biāo)丟失事件以及無(wú)線通信故障事件的統(tǒng)計(jì)與分析結(jié)果的展示。
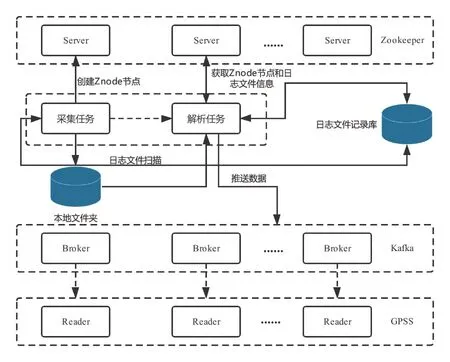
圖2 數(shù)據(jù)采集層處理流程
2.3 系統(tǒng)功能設(shè)計(jì)
基于Greenplum 的車(chē)載日志大數(shù)據(jù)分析平臺(tái)以車(chē)載日志和綜合告警記錄中的特定事件(主要涉及停站、EB、信標(biāo)丟失以及無(wú)線通信中斷等)進(jìn)行統(tǒng)計(jì)分析,其主要功能包括列車(chē)停站時(shí)間分析、列車(chē)停車(chē)精度分析、EB 事件統(tǒng)計(jì)、信標(biāo)丟失統(tǒng)計(jì)和無(wú)線通信交叉故障統(tǒng)計(jì)。
2.3.1 列車(chē)停站時(shí)間統(tǒng)計(jì)分析
通過(guò)ATO 日志對(duì)列車(chē)停站事件的關(guān)鍵參數(shù)進(jìn)行分析,計(jì)算出列車(chē)停站過(guò)程中的關(guān)鍵指標(biāo),主要包括列車(chē)停站總時(shí)長(zhǎng)、乘客有效上下客時(shí)間、司機(jī)開(kāi)門(mén)響應(yīng)時(shí)間、司機(jī)關(guān)門(mén)響應(yīng)時(shí)間、司機(jī)按發(fā)車(chē)按鈕響應(yīng)時(shí)間和乘客上下客效率等。根據(jù)列車(chē)停站記錄,按照列車(chē)、車(chē)站等維度按日分別統(tǒng)計(jì)出列車(chē)和車(chē)站的停站超標(biāo)結(jié)果,包括超標(biāo)次數(shù)和超標(biāo)時(shí)長(zhǎng)。
2.3.2 列車(chē)停車(chē)精度統(tǒng)計(jì)
通過(guò)ATO 日志計(jì)算出列車(chē)每次停車(chē)事件發(fā)生時(shí)的駕駛模式、停站狀態(tài)(包括正常停、欠停、過(guò)停)及停站位置偏差,同時(shí)按照列車(chē)、車(chē)站等維度按日生成列車(chē)欠停、過(guò)停次數(shù)的統(tǒng)計(jì)報(bào)表,并提供信息查詢。
2.3.3 EB事件統(tǒng)計(jì)
2.3.4 信標(biāo)丟失統(tǒng)計(jì)
根據(jù)列車(chē)信標(biāo)丟失的標(biāo)記位的變化規(guī)律,從ATO 日志中獲取發(fā)生信標(biāo)丟失事件的信標(biāo)ID、開(kāi)始時(shí)間、結(jié)束時(shí)間以及丟失位置。按照列車(chē)、車(chē)站、區(qū)段等維度,按日生成信標(biāo)丟失發(fā)生次數(shù)的統(tǒng)計(jì)報(bào)表,同時(shí)繪制線路信標(biāo)丟失趨勢(shì)圖。當(dāng)某個(gè)信標(biāo)丟失事件次數(shù)異常時(shí),能及時(shí)提醒用戶進(jìn)行維護(hù)。
2.3.5 無(wú)線通信故障統(tǒng)計(jì)
結(jié)合車(chē)載日志和監(jiān)測(cè)系統(tǒng)的告警數(shù)據(jù),計(jì)算出列車(chē)每次車(chē)載發(fā)生無(wú)線通信故障時(shí)的中斷時(shí)間、恢復(fù)時(shí)間、發(fā)生位置及車(chē)載故障Modem名稱。按照列車(chē)、車(chē)站等維度按日統(tǒng)計(jì)出無(wú)線通信中斷的故障統(tǒng)計(jì)次數(shù)并生成報(bào)表,繪制出無(wú)線通信故障趨勢(shì)圖,能夠及時(shí)向用戶發(fā)出告警,并提示用戶及時(shí)處理故障。
3 基于Greenplum的大數(shù)據(jù)平臺(tái)實(shí)現(xiàn)
3.1 大數(shù)據(jù)平臺(tái)構(gòu)建
為了滿足車(chē)載日志的數(shù)據(jù)存儲(chǔ)、數(shù)據(jù)分析以及數(shù)據(jù)查詢的性能要求,并充分考慮到大數(shù)據(jù)平臺(tái)的建設(shè)成本,平臺(tái)建設(shè)時(shí)主要采用了Greenplum、Kafka、Zookeeper 及MySQL 等開(kāi)源組件,形成一套可按需部署、開(kāi)源軟件為主的大數(shù)據(jù)平臺(tái)。
基于Greenplum 的大數(shù)據(jù)平臺(tái)主要由1 個(gè)管理節(jié)點(diǎn)和3 個(gè)數(shù)據(jù)節(jié)點(diǎn)組成,每個(gè)節(jié)點(diǎn)配置為2顆8 核 的Intel 64 bit 處理 器、32 GB 內(nèi) 存及3 塊600 GB SAS 硬盤(pán),每個(gè)節(jié)點(diǎn)間使用千兆網(wǎng)絡(luò)連接,Greenplum 版本為5.19,其拓?fù)浣Y(jié)構(gòu),如圖3 所示。每個(gè)數(shù)據(jù)節(jié)點(diǎn)上部署2 個(gè)主實(shí)例和2 個(gè)鏡像實(shí)例,各數(shù)據(jù)節(jié)點(diǎn)之間進(jìn)行交叉鏡像配置,提高了集群的可用性[6]。在部署實(shí)際的生產(chǎn)環(huán)境時(shí),根據(jù)實(shí)際需求可以增加兩臺(tái)服務(wù)器,一臺(tái)作為大數(shù)據(jù)應(yīng)用展示的Web 應(yīng)用服務(wù)器,另一臺(tái)作為存儲(chǔ)車(chē)載日志文件的數(shù)據(jù)日志服務(wù)器。
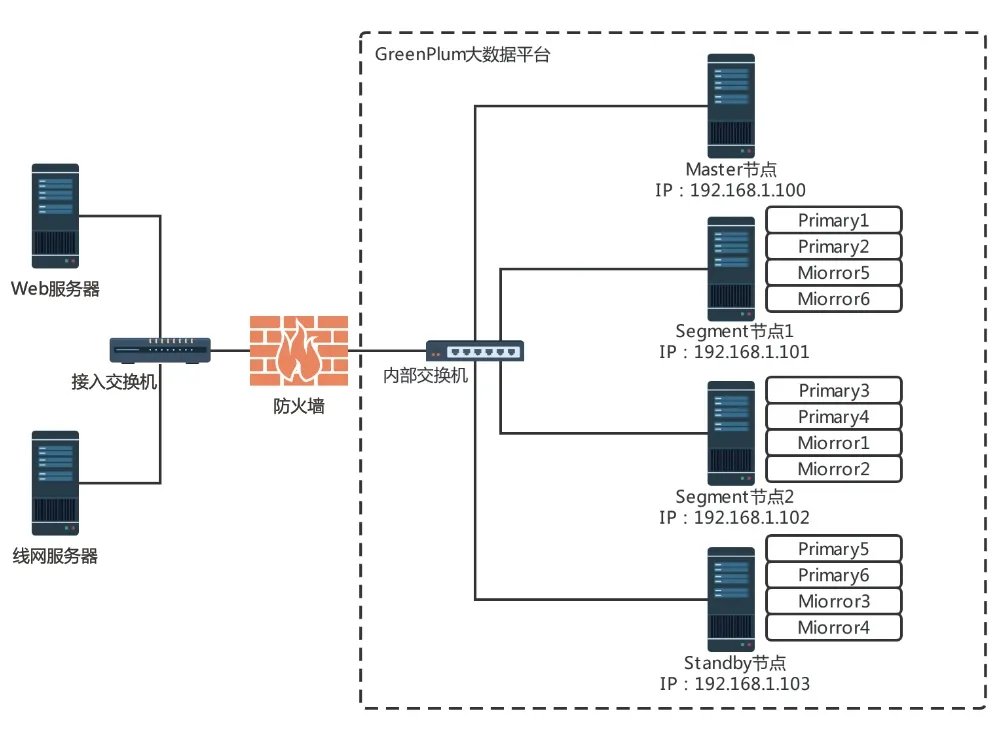
圖3 基于Greenplum的大數(shù)據(jù)平臺(tái)拓?fù)浣Y(jié)構(gòu)
在完成大數(shù)據(jù)平臺(tái)部署后,通過(guò)數(shù)據(jù)采集/解析服務(wù)將線網(wǎng)服務(wù)器中的車(chē)載日志數(shù)據(jù)加載到平臺(tái)中去。Greenplum 作為一個(gè)分布式數(shù)據(jù)庫(kù),數(shù)據(jù)分散在每一個(gè)節(jié)點(diǎn)上[8],而采用列車(chē)號(hào)作為源數(shù)據(jù)表的主鍵會(huì)造成數(shù)據(jù)傾斜問(wèn)題。因此,該平臺(tái)在數(shù)據(jù)分布策略上采用隨機(jī)分布方式。
3.2 大數(shù)據(jù)平臺(tái)關(guān)鍵性能指標(biāo)評(píng)估
基于Greenplum 的大數(shù)據(jù)平臺(tái)的建設(shè)目標(biāo)是必須滿足車(chē)載日志T+1 離線分析的要求,主要包括數(shù)據(jù)質(zhì)量和分析速度兩方面,數(shù)據(jù)質(zhì)量必須滿足報(bào)表展示的要求;分析速度要求必須滿足地鐵車(chē)輛運(yùn)營(yíng)的時(shí)間特點(diǎn)。車(chē)載日志離線分析的工作時(shí)間可以分為兩個(gè)階段,第1 階段列車(chē)正常運(yùn)營(yíng)回庫(kù)后到第2 天出車(chē)前,即每日晚上23:30—次日5:30,這個(gè)階段內(nèi)要完成從列車(chē)DLU 板卡到線網(wǎng)服務(wù)器的日志收集工作;第2 階段是列車(chē)出庫(kù)后到白班上班前,即次日5:30—次日9:00,這個(gè)階段為大數(shù)據(jù)平臺(tái)的工作時(shí)間,共計(jì)3.5 h,主要完成從線網(wǎng)服務(wù)器下載日志文件到統(tǒng)計(jì)報(bào)表生成。
大數(shù)據(jù)平臺(tái)對(duì)6 列車(chē)1 天的車(chē)載日志數(shù)據(jù)(約540 個(gè)日志文件,共239 MB)從數(shù)據(jù)下載→解析→入庫(kù)→清洗→查詢的整個(gè)數(shù)據(jù)鏈路的關(guān)鍵性能進(jìn)行了測(cè)試,具體測(cè)試結(jié)果分析如下。
(1)數(shù)據(jù)下載性能:由于大數(shù)據(jù)平臺(tái)與線網(wǎng)服務(wù)器之間采用千兆局域網(wǎng)連接,平均網(wǎng)速約為30 MB/s,通過(guò)FTP 傳輸工具完成車(chē)載日志測(cè)試數(shù)據(jù)下載,實(shí)際耗時(shí)約20 s,因此日志下載環(huán)節(jié)的耗時(shí)可以忽略不計(jì)。
(2)數(shù)據(jù)解析性能:大數(shù)據(jù)平臺(tái)跑單任務(wù)解析單個(gè)日志文件耗時(shí)大約35 s,即解析速度為170 條/s。為了縮短解析時(shí)間并充分利用平臺(tái)的計(jì)算資源,可在平臺(tái)上同時(shí)運(yùn)行40 個(gè)解析任務(wù)去解析日志文件,最終完成車(chē)載日志測(cè)試數(shù)據(jù)的解析實(shí)際耗時(shí)約為0.8 h。
(3)數(shù)據(jù)入庫(kù)性能:日志數(shù)據(jù)入庫(kù)采用的是GPSS,其原理是通過(guò)外部表的方式實(shí)現(xiàn)數(shù)據(jù)高并發(fā)加載到Greenplum 數(shù)據(jù)庫(kù)的ETL 工具。在大數(shù)據(jù)平臺(tái)上通過(guò)GPSS 方式入庫(kù)的實(shí)測(cè)速度約為2 500 條/s,完成車(chē)載日志測(cè)試數(shù)據(jù)解析入庫(kù)實(shí)際耗時(shí)約為1.8 h。由于數(shù)據(jù)解析的同時(shí)會(huì)進(jìn)行入庫(kù),因此數(shù)據(jù)入庫(kù)總耗時(shí)包含了數(shù)據(jù)解析耗時(shí)。
(4)數(shù)據(jù)清洗性能:車(chē)載日志測(cè)試數(shù)據(jù)由原始日志表到中間日志表清洗耗時(shí)約為18 min,從中間日志表到統(tǒng)計(jì)結(jié)果表清洗耗時(shí)約為16 min。從原始日志表到統(tǒng)計(jì)結(jié)果表的清洗過(guò)程共耗時(shí)約為0.57 h。
(5)數(shù)據(jù)查詢性能:對(duì)原始日志表、中間日志表和統(tǒng)計(jì)結(jié)果表中數(shù)據(jù)量最大的表分別執(zhí)行相同操作的SQL 語(yǔ)句,記錄執(zhí)行時(shí)間,其測(cè)試結(jié)果,如表1 所示。從數(shù)據(jù)查詢耗時(shí)的結(jié)果來(lái)看,數(shù)據(jù)查詢階段的耗時(shí)可以忽略不計(jì)。

表1 大數(shù)據(jù)平臺(tái)數(shù)據(jù)查詢結(jié)果
綜上所述,車(chē)載日志從下載到報(bào)表生成的整個(gè)數(shù)據(jù)鏈路耗時(shí)等于數(shù)據(jù)入庫(kù)時(shí)間加上數(shù)據(jù)清洗時(shí)間,總共耗時(shí)約為2.37 h,小于大數(shù)據(jù)平臺(tái)實(shí)際要求的最大工作時(shí)長(zhǎng)3.5 h。因此,本文所搭建的基于Greenplum 的大數(shù)據(jù)平臺(tái)完全符合車(chē)載日志T+1 離線分析的要求。
4 結(jié)束語(yǔ)
基于Greenplum 的車(chē)載日志大數(shù)據(jù)分析平臺(tái)具有良好的擴(kuò)展性和實(shí)用性,在實(shí)際生產(chǎn)部署時(shí),可以根據(jù)日志分析需求增加Segment 節(jié)點(diǎn)數(shù)和硬盤(pán)容量,并考慮采用萬(wàn)兆交換機(jī)和性能更高的處理器。該平臺(tái)為解決城市軌道交通信號(hào)系統(tǒng)的車(chē)載日志分析提供了一種解決方案,彌補(bǔ)了目前城軌信號(hào)系統(tǒng)在運(yùn)維管理方面的不足之處,是對(duì)今后城軌信號(hào)系統(tǒng)向智能化運(yùn)維發(fā)展的一次應(yīng)用探索。

- 鐵路計(jì)算機(jī)應(yīng)用的其它文章
- 地鐵列車(chē)制動(dòng)系統(tǒng)速度信號(hào)模擬的研究
- 高鐵車(chē)站設(shè)備智能化運(yùn)維管理系統(tǒng)設(shè)計(jì)及關(guān)鍵技術(shù)研究
- RSSP-I鐵路信號(hào)安全協(xié)議的設(shè)計(jì)及實(shí)現(xiàn)
- 基于改進(jìn)卷積神經(jīng)網(wǎng)絡(luò)的無(wú)絕緣軌道電路調(diào)諧區(qū)故障診斷
- 虛擬化在鐵路旅客服務(wù)信息系統(tǒng)集成管理平臺(tái)的應(yīng)用研究
- 鐵路行包票據(jù)電子化移動(dòng)終端系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)