基于時序數據庫的工業大數據應用研究
2020-06-29 03:02:52王紅濤王志超馮連強孫思豪
重型機械 2020年4期
關鍵詞:數據庫
王紅濤,王志超,陳 峰,馮連強,孫思豪
(中國重型機械研究院股份公司,陜西 西安 710032)
0 前言
復雜重型裝備定制生產的設計、制造、運作管理、營銷服務等過程中會產生海量的時序數據[1],這些來自產品全生命周期的時序數據是提高生產水平和管理水平的數據基礎[2]。獲取生產現場的時序數據,能夠為各種設備監控系統、工藝分析系統、管理系統提供實時的數據服務,從而打破流程工業生產過程中的“數據壁壘”,為提高產品質量和優化設備調度計劃提供依據[3]。但海量數據的處理同時也面臨著日益嚴峻的問題:存儲容量問題,單一設備的各類傳感器每天的采樣數據數以百萬計,每年的采樣數據所需的存儲容量從GB到TB[4];處理速度問題,不斷增加的數據量給數據的存儲方法和檢索查詢方式帶來了難度;實時數據的展示問題,傳統的關系型數據庫的采樣周期和采樣方式難以完成對時序數據的連續存儲[5],且無法通過折線圖、散點圖等實時顯示數據的變化趨勢。
面對傳統的關系型數據庫在工業互聯網環境下的不足,本文提出基于時序數據庫的工業大數據存儲管理系統,首先設計以開源的時序數據庫influxDB為參考的工業時序數據庫引擎,實現應用于邊緣計算的時序數據庫,再通過構建數據圖譜的方式探尋數據之間的關聯關系,然后選擇合適的圖表形式將時序數據可視化,為后續的設備監控、遠程運維等系統提供數據支撐,最后提出了基于時序數據庫的工業大數據存儲管理系統的性能測試方法。
1 應用于邊緣計算的時序數據庫
工業互聯網的快速發展帶來了各種傳感器的廣泛使用和海量工業數據的采集[6]。海量實時數據的分析需求無法用傳統的集中處理方式滿足,因此數據計算逐漸走向邊緣端[7]。
1.1 邊緣計算
1.1.1 邊緣計算的發展
邊緣計算(Edge Computing, EG)指的是接近物理實體或數據源的一側,匯集了網絡、計算、存儲、應用核心能力等的開放平臺[8]。當前業界對邊緣計算概念的描述并不統一,但有基本的共性認識:邊緣計算是在接近終端的網絡邊緣上提供服務[9]。
邊緣計算并不是新興概念,早在2003年,作為全球最大的分布式計算服務商之一的AKAMAI就與IBM合作“邊緣計算”。近年來,邊緣計算因其滿足萬物互聯需求的突出優點,逐漸受到國內外的廣泛關注。 2017年,全球性產業組織工業聯盟ICC成立Edge Computing TG,為邊緣計算指出了參考架構;同年11月,中國聯通推出了“邊緣云&智能安防”的技術方案[10]。在標準化方面,國際電工委員會(IEC )于2017年發布了《垂直領域邊緣智能(VEI)白皮書》,指明了邊緣計算對于制造業等垂直行業領域的重大意義。
1.1.2 裝備制造業邊緣計算體系架構
裝備制造業作為向國民經濟和國防建設提供生產技術裝備的先進制造業,是制造業的核心組成部分,是我國工業發展的基礎[11]。但經過對企業進行走訪調查、閱讀文獻資料等過程,進一步了解了邊緣計算應用于裝備制造業的現狀和需要,得知裝備制造業總體的工程建設程度不一致,普遍面臨數據開放性差且工業協議標準不統一、數據采集種類較少、數據采集實時性水平較低、數據安全存在隱患等問題[12]。
依據邊緣計算的發展現狀,結合裝備制造業的行業需求,參考工業互聯網平臺體系中的邊緣層架構,提出裝備制造業邊緣計算體系架構如圖1所示。

圖1 裝備制造業邊緣計算體系架構
(1)設備接入。為工業現場設備、智能產品/裝備設置數據采集端口[13],實時獲得生產現場的數據并進行安全傳輸,實現不同制造商設備的互聯互通。
(2)協議轉換。基于OPC UA 設計支持多種總線協議、網絡接口和網絡拓撲的工業網關。將各提供數據的設備使用的協議標準化為OPC UA協議[14]。
(3)邊緣數據處理。通過設備部署實現邊緣端和云端的協同。基于流式計算處理邊緣設備產生的數據,實時響應業務需求,并行聚合非實時數據并傳到云端,實現邊緣計算和云計算的協同。
1.2 時序數據庫
1.2.1 時序數據
時序數據就是時間序列數據,即某個指標根據時間順序記載的數據序列[15]。在以時間為橫軸的坐標系中將時序數據值連成線,可將歷史時序數據做成多維度表,發現其規律和異常,也可將時序數據用于大數據分析,實現趨勢預測和異常預警。
工業互聯網環境下需采集的工業時序數據量巨大,且具有如下典型特征:數據都是結構化的;一個采集點的數據源是唯一的;數據較少有更新或刪除操作,一般按到期日期來刪除;數據以寫操作為主,讀操作為輔;數據流量平穩,可較為準確地計算;數據都有統計、聚合等實時計算操作;數據根據指定的時間段和區域進行查找。
1.2.2 時序數據庫特性
時序數據庫即存儲時序數據的數據庫。它允許快速寫入、持久化、多維度地聚合查詢時序數據等操作[16]。該類數據庫不但存儲了此刻的數據值,而且保存了全部歷史數據,在查詢時也總會將時間作為過濾條件。
以存儲風速傳感器數據的時序數據庫為例(圖2),時序數據庫的相關定義如表1所示。
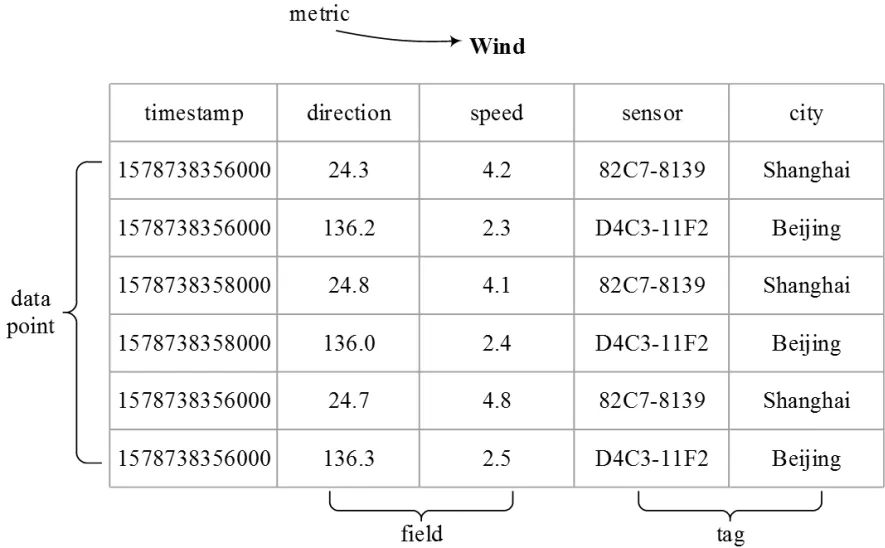
圖2 時序數據庫基本概念圖

表1 時序數據庫相關定義
時序數據庫適用于一切有時序數據形成,對數據的歷史規律、異常變化等有分析需求,或者需判斷時序數據后續發展趨勢的場景。根據工業大數據特點和實際需要,將本文使用的時序數據庫的內部架構設計為圖3所示的架構。
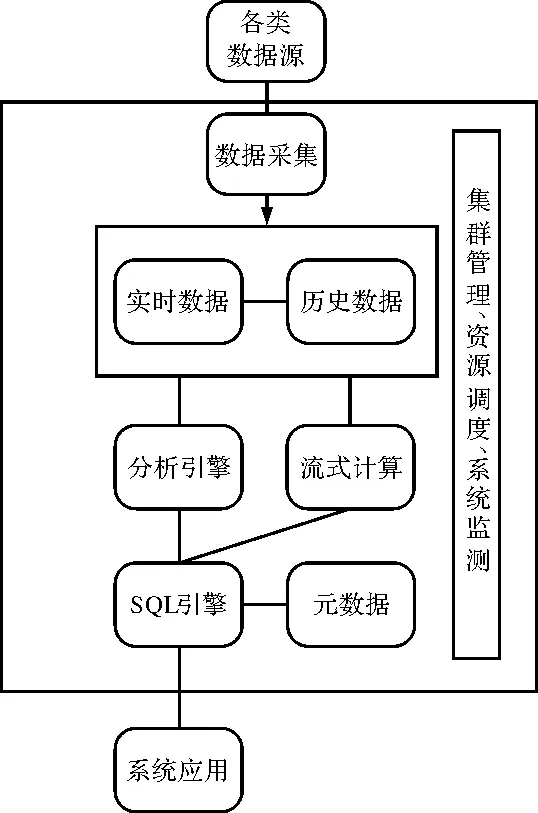
圖3 時序數據庫內部架構
2 基于influxDB的數據庫存儲引擎
隨著企業生產規模的擴大和生產工藝的提高,需要采集的現場生產數據愈加龐大[17],常規采用單計算機體系結構的實時數據庫產品遇到了單臺計算機體系結構處理能力的限制,無法有效滿足現場生產數據共享的需要。為了便于計算機處理,需要將來自工業生產現場中連續變化的工藝參數等數據進行離散數字化取樣,生成持續的、間斷變化的離散數字數據流。
2.1 influxDB時序數據庫
InfluxDB時序數據庫起源于服務器運行情況的監控領域,較為復雜的元數據模型使除測點、時間、取值以外的附加屬性信息得以保存[18]。該數據庫基于日志結構合并樹(Log Structured Merge Tree, LSM)提出了時間結構合并樹(Time Structured Merge Tree, TSM),分別優化了時序數據的讀和寫。寫入過程中,數據增加到日志文件中,并在內存中緩存,當緩存至一定容量時新建日志文件,并運行壓縮線程,把數據壓縮成TSM數據文件。
2013年,influxDB時序數據庫被Errplane公司開源,經不斷優化后目前排至開源時序數據庫的首位。
2.2 數據庫存儲引擎結構
基于influxDB思想設計工業時序數據庫的引擎,如圖4所示。從上到下包括數據庫實例、存儲策略、存儲分片幾個層次[19]。每個存儲分片里包含一個內存緩存區、一或多個日志文件、多個數據文件,以及用于處理寫入、壓縮、讀取的線程。
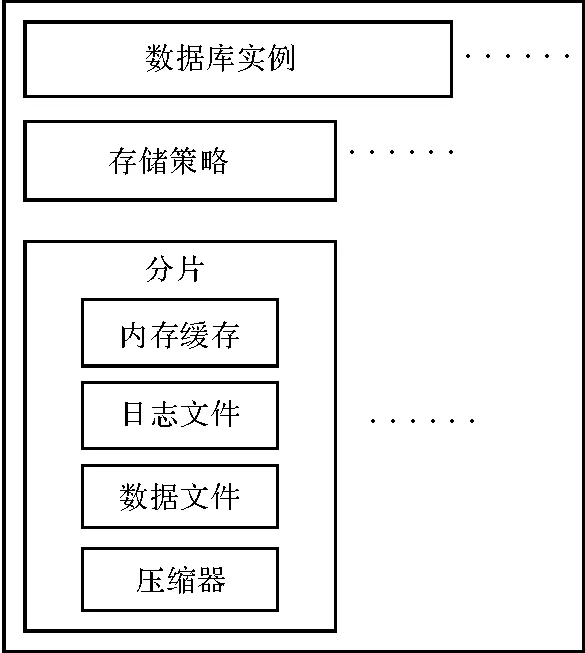
圖4 時序數據庫引擎結構示意圖
3 時序數據應用
3.1 面向全生命周期的數據圖譜
結合工業場景中各數據和對象的全生命周期,統一地將當前系統和設備中的數據進行采集、儲存、處理,探尋數據之間的相關性,加入模型分析、算法預測,提高企業的生產工藝水平,完善企業的供應鏈,提高產品質量,從而改善企業效益。
可將企業數據圖譜看作是有機融合企業數據的知識圖譜的延伸[20]。它包含計算機視覺、圖形學、數學等在內的多學科知識。企業構建數據圖譜的主要內容如圖5所示。所謂“全生命周期”,指的是按照時間流分析圖中包括的主體。

圖5 企業構建數據圖譜的主要內容
3.2 時序數據可視化
數據本身是一個抽象的概念,隨著數據量的不斷增大,傳統的數據統計方法很難滿足用戶去理解數據本身含義的任務,而數據可視化作為一項新興且蓬勃發展的技術,其依賴于本身可視的優越性,已經在自然科學、工程技術、經濟、通信及商業等領域得到了廣泛的應用并取得了很多卓有成效的進展[21]。對數據的理解,人們普遍傾向于具體、形象的展示,數據可視化方法通過圖像、表格等視覺載體“看到”數據,因此在用戶對數據進行可視分析的過程中起到了至關重要的作用。
假設時序數據的主要信息是數據的變化趨勢,則可從散點圖、折線圖二者中選取能夠最大程度揭示時序數據變化趨勢的圖表類型,實現時序數據的可視化。
4 系統性能測試方法
基于時序數據庫的工業大數據存儲管理系統的性能測試主要是檢驗其對常見工業數據的存儲能力[22]。
4.1 存儲性能
存儲海量工業時序數據時,通常由若干個終端一起產生多條存儲指令,該過程存在較多的風險因素。以在連續存儲請求下的數據存儲速度作為評估系統存儲性能的指標,如
Zmax=Qs/T
(1)
式中,Qs為成功存入數據庫的數據量;T為消耗的總時間。
4.2 壓縮性能
壓縮是時序數據庫非常重要的能力之一。將存儲完成后數據庫文件的大小和原始數據大小之比作為評估數據壓縮性能的指標,即
R=Sdb/Sr
(2)
式中,Sdb為數據庫文件大小;Sr為原始數據大小;R為為壓縮比。
5 結語
在工業互聯網快速發展的大背景下,工業生產現場投放了大量的設備傳感器和監控系統[23],二者提供的實時數據能夠反映設備的狀態和生產的進度,其中的大多數據都是按照時間順序形成的實時數據。這些海量實時數據有著多樣化的分析需求和重要的參考價值,此現狀下能夠融入大數據生態并具有良好擴展性的時序數據庫應運而生。對企業而言,設計并實現基于時序數據庫的工業大數據存儲管理系統,能夠為產品的可視化運維、預測性維護、遠程智能管理等方面提供依據,降低人員、時間等成本,同時加速工業化與信息化的深度融合,促進復雜重型裝備制造業的轉型升級,產生社會經濟效益。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
