基于Mask-RCNN的服裝識別與分割
2020-06-24 12:59:46張澤堃張海波
紡織科技進展 2020年6期
張澤堃,張海波
(1.北京服裝學院 信息中心,北京100029;2.北京服裝學院 服裝材料研究開發與評價北京市重點實驗室 北京市紡織納米纖維工程技術研究中心,北京100029;3.北京服裝學院 圖書館,北京100029)
根據中國服裝協會發布的《2018-2019年度中國服裝行業發展報告》[1]顯示,2018年全年限額以上服裝品類零售額實現7 742.8億,累計增長9.1%,增速較2017年提高了1.1%,網上銷售增長了22%,大型零售增長0.99%。2018年全年服裝行業規模以上企業主營業務收入17 106.57億。服裝行業發展迅速,計算機行業進軍服裝領域,如何理解、區分和識別不同的服裝圖像,以及如何處理海量的服裝圖像,并從中提取出有用的信息成為當前的研究熱點。除了電商的以圖搜物外,服裝的智能搭配和服裝定制都用到了服裝的圖像識別與分割。目前網購服裝的檢索主要以文字檢索為主,但隨著服裝數量劇增,服裝款式變化多樣,傳統的圖像處理已無法滿足當前快速、智能準確的要求,而這也使得計算機在服裝圖像的處理上遇到了瓶頸。
從最初的人工標注到使用卷積神經網絡來訓練模型,期間出現了很多圖像識別和分割的算法。早期的識別方法有靜態圖像中的分割、邊緣提取、運動檢測等,如局部模板方法、光流檢測法等,這些方法速度較慢,識別率較低,誤報率也高。隨著深度學習[2]的不斷發展,深層卷積神經網絡在圖像的處理上更加針對服裝圖像的特征,具有獨特的優勢。Kim[3]等為了識別攝像機拍攝的灰度圖像中的任務,使用邊緣提取的方法提取服裝圖像的紋理特征,計算歐幾里得距離來判定特征向量之間的相似性。只使用服裝邊緣的直方圖特征向量,并不適用于圖像縮放、旋轉、扭曲等形變。Hidayati[4]等提出了一種基于視覺差異化風格元素的服裝風格自動分類方法,而不用低層次特征或模糊關鍵詞來識別服裝風格,基于服裝設計理論,確定了一組對識別服裝風格的特定視覺風格至關重要的風格元素,將服裝風格元素歸一化為上身的特征向量和下身的特征向量,通過一個判別函數來判斷輸入特征向量到類別標簽的映射關系,利用判別函數來確定服裝的類型。Liu[5]等設計了用于服裝圖像分類檢測的Fashion Net,提出了Deep Fashion數據集,這是一個具有全面注釋的大型服裝數據集。Luo[6]等研究了頻場景中識別服裝的相關技術,在Image Net數據集上預訓練GoogleNet模型,并根據服裝本身的特點對網絡進行微調,以完成服裝的檢索任務。
根據現有研究,目前使用較多的檢測算法有RCNN、Fast R-CNN、Faster R-CNN 和 Mask-RCNN,檢測結果的準確性和速度不斷提高,但是缺點是需要大量的訓練數據。Mask-RCNN[7]是目前最新的實例分割架構,引入了RoI Align,增加了一個分支用于分割任務,在時間上有一定的優化。而且Deep Fashion2數據集在Deep Fashion數據集的基礎上進行了優化。
本文基于Mask-RCNN和Deep Fashion2的服裝識別與分割,對傳統深度學習目標檢測算法的訓練數據和特征提取器做了調整,使得模型更加適用于服裝識別和服裝分割,得到的結果更加準確。
1 DeepFashion2數據集
1.1 Deep Fashion2數據集概況
近年來,時尚產業愈發火爆,時尚服裝圖像分析成為了熱點。現有最大的時尚數據集Deep Fashion存在標記較為稀疏,沒有定義服裝姿態,沒有對每個像素進行掩膜標注的缺點。為了解決上述缺陷,提出了Deep Fashion2[8],它是一個大規模的基準集,能全面的進行服裝分類和服裝圖像的標注,包含49.1萬張時裝圖像,圖片可分為13種流行的服飾類別。Deep-Fashion2定義了相對全面的任務,包括服裝的檢測和識別,關鍵點的標記和服裝姿態估計,服裝分割,服裝的驗證和檢索。所有的服裝圖像都有豐富的標注。它有81萬個服裝項目,每個項目都有豐富的注釋,其中每件都標有不同的比例、不同大小的遮擋、不同的縮放大小、不一樣的視角、精準的邊界框、密集的標注和每個像素的掩膜。表1為Deep Fashion2與其他數據集的比較。
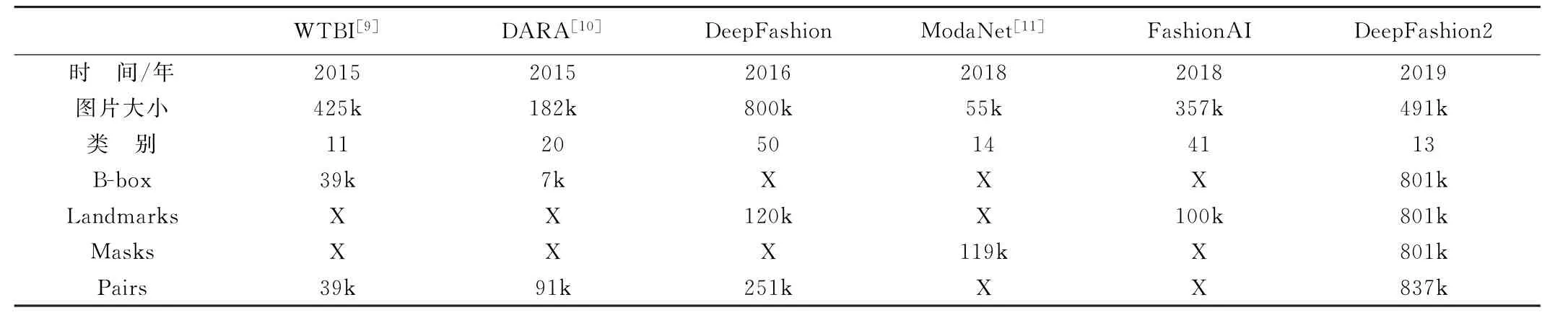
表1 Deep Fashion2與其他數據集的比較
Deep Fashion2的貢獻主要有三個:(1)構建了擁有豐富標注的大規模數據集,推動了時尚圖像分析的發展。擁有豐富的任務定義和最大數量的服裝標簽。它的標注至少是Deep Fashion的3.5倍,是Moda Net的6.7倍,是Fashion AI的8倍。(2)在數據集上定義了全部任務,包括服裝檢測、服裝姿態、服裝分割與檢索。(3)使用Mask-RCNN對數據集進行識別和分割。
1.2 Deep Fashion2數據集和基準
1.2.1 數據標簽
(1)類別和邊界框。對服裝圖片進行人工標注,并為每個服裝項目指定一個類別標簽。通過重新對Deep Fashion的類別進行分組,得到了13個沒有歧義的服裝類別。
(2)服裝標簽、輪廓和骨架。由于不同類別的衣服(如上下半身服裝)有不同的形變和外觀變化,通過捕捉服裝的形狀和結構將特征點連接。將每類服裝進行人工標注,每個特征點都被將指定為“可見”或“遮擋”。然后,將特征點通過一定順序連接后生成輪廓和骨架,還將標注區分為兩種類型,即輪廓點和連接點。以上過程控制了標簽的質量,生成的骨架有助于人工重新檢查這些標記是否具有較高的識別效率。只有當輪廓覆蓋整個項目時,標記的結果才合格,否則將重新確定關鍵點。
(3)掩膜。使用兩個階段的半自動方式為每個項目標記像素掩膜。第一階段自動從輪廓生成掩膜。在第二階段,要求人工重新定義掩膜,因為當呈現復雜的人體姿勢時,生成的掩膜可能不準確。例如,當從人腿交叉側視圖拍攝圖像時,標記會不準確,這時掩膜需要人工調整,如圖1所示。

圖1 掩膜出現識別錯誤時進行人工調整
1.2.2基準
使用Deep Fashion2的圖像和標簽構建了四個基準。對于每個基準測試,訓練集圖像39.1萬,驗證集圖像3.4萬,測試集圖像6.7萬。
(1)服裝檢測。通過識別邊界框和類別標簽來檢測圖像中的衣服。根據COCO數據集,評價標準為。
(2)特征點估計。預測每個圖像中檢測到的每個服裝項目的標志。采用COCO用于人體姿態估計的評估指標,通過計算關鍵點AP pt、AP OKS=0.50pt和AP OKS=0.75pt的平均精度,其中OKS表示目標特征點相似性。
(3)圖像分割。將類別標簽(包括背景標簽)分配給項目中的每個像素。評估指標是平均精度,包括在掩膜上計算的AP mask、AP IoU=0.50mask和AP IoU=0.75mask。
2 Mask-RCNN服裝識別
2.1 檢測框架設計思路
在檢測模型訓練階段,對具有初始參數的卷積神經網絡進行迭代訓練,并通過Tensorboard來查看訓練過程,從而不斷修改和優化訓練模型的參數,最終得到目標檢測模型。在模型測試階段,將待檢測樣本輸入之前得到的目標檢測模型并得到檢測結果。主要有檢測模型的訓練和模型測試兩個階段,如圖2所示。

圖2 服裝識別檢測模型框架
目標檢測方法的訓練包括6個步驟:(1)獲取Deep Fashion2數據集源文件;(2)對訓練樣本進行預處理,將Deep Fashion2中的json文件轉換成dataset備用;(3)將dataset輸入到Res Net中,得到對應訓練服圖像的特征圖,對特征圖中的每一點設定預定的RoI,得到多個候選RoI;(4)將候選的RoI送入RPN進行二分類(輸出為前景或背景)和BB(bounding box)回歸,過濾掉一部分候選的RoI,對剩下的RoI進行RoIAlign操作;(5)將得到的RoI進行N類別分類、BB回歸和MASK生成;(6)重復步驟4和步驟5,訓練完所有的服裝樣本后得到最終的檢測模型。
服裝檢測的方法包括兩個步驟:(1)利用測試的服裝樣本對檢測模型進行測試,最終得到新樣本的檢測結果。(2)測試結果不符合要求時重新進行模型的調整與參數訓練,并且重新訓練模型,若測試結果符合要求,則得到最終的目標檢測模型。
2.2 Mask-RCNN簡介與原理
Mask-RCNN是何凱明等人在Faster R-CNN[12]基礎上提出的目標實例分割模型。該模型能夠有效地檢測圖像中的目標并為每個實例生成高質量的分割掩碼。如圖3所示,該模型通過在Faster R-CNN已存在的B-box識別分支旁并行地添加了一個用于預測目標掩碼的分支。掩碼分支是一個應用到每個RoI上的小型FCN(全卷積網絡),能夠預測RoI中每個像素所屬的類別,從而實現準確的實例分割。
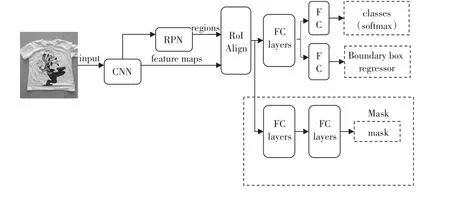
圖3 Mask-RCNN結構圖
Mask-RCNN的技術要點主要有三個:(1)使用Res Net+FPN來提取圖像特征。(2)使用RoIAlign替代RoIPooling,引入了一個插值過程,先通過雙線性插值到14×14,再pooling到7×7,解決了僅通過Pooling直接采樣帶來的Misalignment對齊問題。(3)每個RoIAlign對應k×m2維度的輸出。k對應類別個數,即輸出k個掩膜,m對應池化分辨率7×7。
2.3 RoI Align操作
RoI Align是取消量化操作和整數化操作,并保留小數,使用雙線性內插的方法獲得坐標為浮點數的圖像數值,將整個特征聚集過程轉化為一個具有連續性的操作。RoI Align不是簡單的補充出候選區域邊界上的坐標點,然后進行池化,而是重新設計。圖4中虛線框表示的是5×5的特征圖。虛線部分表示的是feature map,實線表示RoI,如圖4所示將RoI切分成4個2×2的單元格,之后在每個實線的方形區域中選擇4個采樣點,除了這4個點還選取離該采樣點最近的4個特征點,如圖4中黑色小方格的4個頂點,并且通過雙線性插值的方法得到每個采樣點的像素值;最后計算每個小區域的像素值,并生成2×2的特征圖。

圖4 RoI Align原理
2.4 FPN(特征金字塔網絡)
FPN的提出是為了實現更好的feature maps融合,FPN采用了自上而下的側向連接來融合不同尺度的特征,使用3×3的卷積來消除混疊現象,來預測不同尺度的特征,不斷重復以上的過程,最終得到最佳分辨率。FPN的優點在于,它可以在不增加計算量的情況下提高多個尺度上小物體的準確性和快速檢測能力。圖5為特征融合原理圖。左邊的底層特征層通過1×1的卷積得到與上一層特征層相同的通道數;上層的特征層通過上采樣得到與下一層特征層一樣的長和寬再進行相加,從而得到了一個融合好的新的特征層。
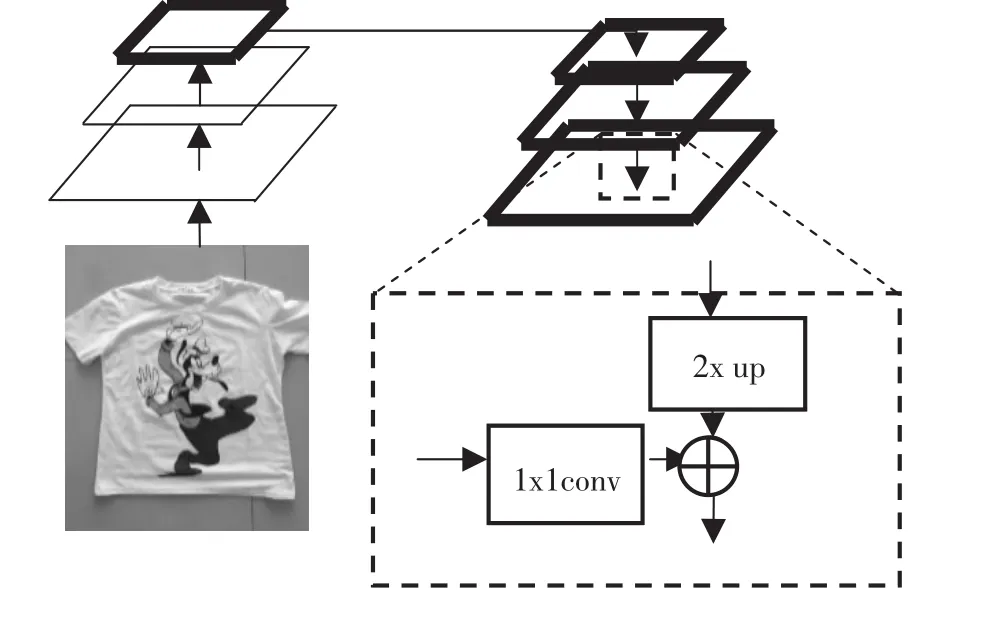
圖5 特征融合原理圖
2.5 Loss Function
Mask-RCNN的損失函數為:
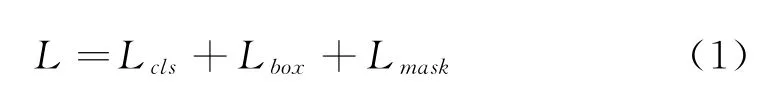
式中L cls和L box與Fast RCNN中定義的分類和回歸損失相一致,mask分支對于每一個RoI都有k×m2維度的輸出,k個分辨率為m×m的二值mask。L mask為平均二值交叉熵損失。對于一個屬于第k個類別的RoI,L mask僅僅考慮第k個mask。
3 試驗部分
3.1 深度學習框架與預訓練模型的選取
目前深度學習的學習框架有很多,深度學習的模型需要大量時間和海量訓練樣本進行訓練,在考慮到硬件水平的前提下,試驗使用COCO 2014數據集作為預訓練模型。COCO 2014數據集擁有9 000多張圖片,包含了自然圖片和生活中常見的物品圖片,也有較多的服裝圖像,因此試驗采用遷移學習方法將COCO 2014數據集訓練得到的權重模型作為服裝檢測算法模型的預訓練模型,在此預訓練模型的基礎上使用Deep Fashion2作為訓練集再進行樣本訓練,通過遷移學習的方式不但可提升訓練效率,而且能有效地提升檢測模型的整體檢測精度和模型性能。
3.2 數據集的處理
由于Deep Fashion2已經得到了各圖片的json文件,故不需要再使用Lebel Me進行手動標注,只需將json文件轉換為dataset即可。試驗在Ubuntu18.04、CUDA9.0環境下進行。試驗參數設置如下:初始學習率0.000 01,每迭代2 000次縮小10倍。為了使訓練效果和模型性能更好,選取服裝圖片有不同遮擋、不同縮放和不同姿態。
3.3 試驗結果與分析
得到訓練模型后,使用測試代碼進行測試,得到的測試效果如圖6所示。

圖6 測試效果
試驗選取了不同服裝姿態的圖片,其中矩形框表示檢測服裝的位置,矩形框上的數字表示的是屬于不同服裝類別的概率大小。為了提高檢測的準確率,將模型中的矩形框概率的閾值設置為0.7。一方面減少了網絡中確定服裝圖像邊框的計算量,提升計算速度。另一方面防止發生過擬合。經過測試,把NMS(non maximum suppression)在RPN網絡的預測階段在proposal layer的閾值設定為0.7時,試驗結果較好,被標注的服裝識別概率均高于0.764。
試驗中也存在識別失敗的例子,如圖7所示。原因可能是服裝占比較大或較小、形變較明顯、放大不正規和有較大的遮擋等。
由于服裝本身的易形變和拍照的角度問題,總體上Mask-RCNN識別率較高,達到了預期的效果。為了提高識別準確率,可以將訓練集的數據進行篩選。也可以增加訓練集數量來提高訓練模型的性能。

圖7 服裝識別失敗例子
4 結語
基于Mask-RCNN和Deep Fashion2的服裝檢測模型可以更好的識別和分割服裝,更好地促進服裝識別算法的發展,更好地理解時尚圖像。通過使用Mask-RCNN對Deep Fashion2數據集進行測試,得到較為精確的結果,可以通過分割得到的服裝進行智能搭配等。這為探索服裝形象的多領域學習提供了基礎,也為以后進一步優化服裝提取算法提供了借鑒。同時,在Deep Fashion2中引入更多的評估指標,例如深度模型的大小、運行時間和內存消耗,可解釋現實場景中的時尚圖像。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
