基于強化學習DQN的智能體信任增強
2020-06-24 06:30:22亓法欣童向榮
計算機研究與發展 2020年6期
亓法欣 童向榮 于 雷,2
1(煙臺大學計算機與控制工程學院 山東煙臺 264005)2(紐約州立大學賓漢姆頓分校計算機科學系 紐約州賓漢姆頓市 13902)
多智能體(agent)系統是一種分布式計算技術,是多個自主個體組成的群體系統,目標是通過個體間相互信息的通信,進行交互作用.利用多智能體系統對現實問題進行研究已經相當普遍,在社交網絡背景下的信任研究是其中的典型研究內容.隨著網絡的發展,利用社交網絡進行推薦已經非常普遍.許多研究都將社交關系網絡中的用戶信任值作為基礎,通過用戶的過往交互記錄以及用戶間的互動來推測用戶的偏好和評級,并向用戶進行相關項目的推薦.近年來,許多學者都給出了社交網絡中信任計算及推薦的方法,這些方法建立在不同研究基礎上,也有不同的研究目的.總體來說,大多數方法都聚焦于信任的傳遞及信任推薦系統,將信任視為靜態不變的參數.而實際上,信任作為一種主觀狀態,可隨用戶交互經驗、時間等因素的動態變化而發生變化.利用靜態信任進行計算會使推薦結果漸漸偏離現實狀態.
現有的動態信任研究大多針對信任相關因素的變化以及信任變化后的狀態,未充分考慮影響信任動態變化的因素及動態變化過程.實際上,信任動態性將在較大程度上影響推薦結果,動態變化過程會實時地反映到推薦系統中,影響推薦系統的系數,進而實時影響推薦結果,使之得到完全不同的推薦結果.因此,將信任來源的動態性和動態變化一起考慮來改進推薦系統的性能可以得到更加準確、及時的推薦結果,使得推薦系統的實時性得到更大的提高,從而改善推薦系統的性能.
現實生活中,當A出于某種目的希望提升B對自己的信任時會主動增加與B的交流次數,這種交流往往是從B的興趣愛好開始的.如果B喜愛看電影,A會經常向B推薦他可能喜歡的電影.當B對A的推薦電影做出正向評價時,說明A的推薦符合B在電影方面的偏好,同時B將更加相信A在電影方面的欣賞水平,此時B對A的信任將增加;反之,則說明B懷疑A的欣賞水平,B對A的信任值將降低.隨著A向B推薦電影的次數增加,A將越來越了解B在電影方面的偏好,并可以更精準地推薦B喜愛的電影,同時,B將十分信任A.該過程實質上是一種學習其偏好并“投其所好”的過程.
本文的方法模擬了上述過程:推薦者為增強用戶信任,向用戶進行項目推薦,用戶接受推薦后,將對項目做出實際評價.實際評價與用戶接受項目時的心理預期存在一定差異,該差異決定了用戶對項目的滿意程度:若實際評價高于心理預期,則用戶向推薦者返回正向反饋;反之,用戶返回負向反饋.正向反饋表明用戶對推薦者的認可,用戶對推薦者的信任將增加;負向反饋表明用戶懷疑推薦者的推薦水平,導致用戶對推薦者信任下降.本文利用強化學習方法實現用戶的信任增強,并將其應用到推薦系統中,提高推薦結果的實時性和準確性.實驗結果驗證了所提出的基于強化學習的深度q-學習(deepq-learning, DQN)的信任增強算法可以更為準確、及時地展現信任的動態變化,并得到更為可信的推薦結果.由于DQN方法有穩定性強、可處理大量數據的特點,所提出的方法可以很好地擴展到推薦系統使用.
本文主要貢獻有2個方面:
1) 提出的方法結合了強化學習方法深度q-學習(DQN),對信任變化過程進行學習以增強用戶信任.以體驗評價和預期評價之間的差值為依據,對用戶偏好進行學習,可以得到更為完全的信息,進而提高推薦的個性化水平和準確性.
2) 提出的方法綜合考慮了用戶的興趣度、直接信任、間接信任,并對這些因素進行了選擇性的篩選,使計算結果更加符合實際.
1 相關工作
在信任的相關研究中,一些學者已經取得了一些成果.如Jiang等人[1]提出的鄰域感知的信任網絡提取方法,目的為解決信任網絡中的信任傳播失敗問題.該方法考慮到用戶在在線社交網絡中的領域感知影響力,采用有向多重圖對異構信任網絡中用戶間的多重信任關系進行建模,隨后設計了一個領域感知信任度量來度量用戶之間的信任程度.Yan等人[2]提出了一種改進后的基于鄰域和矩陣分解的社會推薦算法,旨在解決關系網絡中的大規模、噪聲和稀疏性問題.該方法開發了一種新的關系網絡擬合算法來控制關系的傳播和收縮,為每個用戶和項目生成一個單獨的關系網絡.然后將矩陣因子分解與社會正則化和鄰域模型相結合,利用關系網絡生成建議.一些學者在研究過程中對信任的動態性有所考慮,提出了一些關于動態信任的方法,如Ghavipour等人[3]考慮了信任傳遞過程中用戶信任值的改變,提出了基于學習自動機的啟發式算法DLATrust,并使用改進后的協同過濾聚合策略來推斷信任的價值.在此基礎上,Ghavipour等人[4]又提出了利用分布式學習自動機的隨機信任傳播的動態算法DyTrust,兩者目的均為學習發現社交網絡中用戶之間的可靠路徑.游靜等人[5]提出了一種考慮信任可靠度的分布式動態管理模型,使用可靠度對信任進行評估來降低不可靠數據的影響,并在交互結束后修正可靠度.此外,許多學者針對自適應聲譽和信任相關性質等方面進行了相應的研究[5-11].本節將對前人所做的工作和DQN方法進行簡要介紹.
1.1 DyTrust
DyTrust算法是利用學習算法進行動態信任計算的方法之一.DyTrust考慮了信任傳播過程中節點信任值的動態變化,利用分布式學習自動機獲取信任傳播過程中信任的動態變化,對信任變化做出反應并根據信任的變化來動態更新可靠的信任路徑.
該方法作為一種動態信任傳播算法,可以更準確地推斷出信任路徑.但是該方法僅利用了信任的動態性特征,并未對其動態變化過程進行研究.本文的方法對信任動態變化過程進行研究,并詳細闡述了該過程.
1.2 q學習與DQN
DQN[12]是q學習算法[13]的發展,也是將深度學習與強化學習結合起來而實現學習的一種新興算法.
q學習算法通過單一神經網絡進行值函數估計與現實累積經驗計算,與q學習相比,DQN使用2個相同結構的神經網絡分別計算值函數估計(Q網絡)與現實(target-Q網絡).Q網絡估計每個動作的值(Q_eval),并根據策略選擇最終動作,環境根據動作返回獎勵值;target-Q網絡利用獎勵值進行現實估計(Q_target).
相較于Q網絡,target-Q網絡的權重更新較慢,即往往每經過多輪更新一次target-Q網絡.該方法保證DQN可避免時間連續性的影響,從而得到更優結果.
同時,DQN方法利用經驗回放對Q網絡進行訓練.DQN進行神經網絡參數訓練時,利用貝爾曼方程思想計算LossFunction并更新Q網絡權重參數:
LossFunction=Q_target-Q_eval,
target-Q網絡的計算方式由Markov決策得到.
本文中的信任增強算法結合DQN算法進行計算,實際上針對單個用戶的信任增強過程使用q學習算法也可以取得相近的結果.現實中使用q學習方法時,狀態量過多且需人工設計特征,且結果質量與特征設計質量關系緊密,導致q學習方法無法應用于推薦系統對大量用戶進行項目推薦;同時,q學習方法需使用矩陣存儲Q值,當針對用戶過多時,會造成數據量過大,導致存儲空間需求急劇增加.推薦系統中用戶群體數目龐大,推薦項目類別復雜,對q學習方法的數據存儲來說是一場災難.
因此,考慮到本文提出的方法應用于推薦系統時的相關問題以及DQN相較于q學習算法的先進性,本文使用DQN算法進行信任增強,并推廣至推薦系統.
2 問題描述與基本定義
本節詳細介紹了問題的基本描述、用戶信息集、推薦者信息集和DQN信息集等.
2.1 問題描述
如圖1所示,用戶A為提升用戶B對自己的信任,向B推薦與他感興趣的內容相關的項目.當B接受A的推薦后,如果B對A推薦的項目的評價高于其心理預期值,B對A的信任值將增加;反之,B對A的信任值將降低.
2.2 基本定義

定義1.用戶信息集{T,S,sp}.
本文對社交網絡中每個用戶建立用戶信息集.其中,T為用戶信任矩陣,S表示用戶評價矩陣,包括用戶過往評價及用戶對推薦項的預期評價,sp表示用戶對推薦項的實際評價.
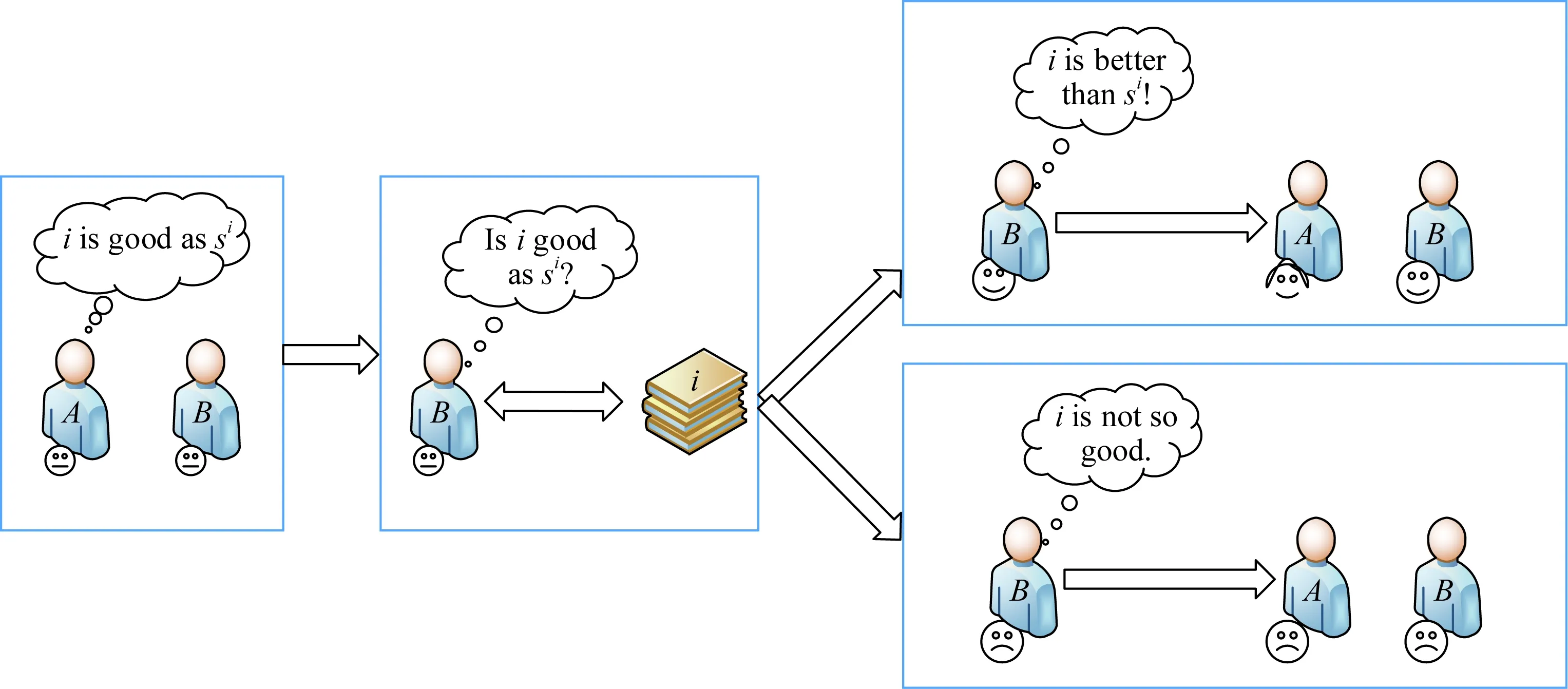
Fig.1 Relationship between recommendation and trust圖1 建議-信任影響關系示意圖
推薦過程中,推薦者從項目集中選擇項目進行推薦,用戶對符合偏好的項目有高滿意度,滿意度將動態影響用戶間信任.
定義3.DQN信息集{n,a,π,r}.
1) 推薦者狀態n.用戶于時刻τ發出廣播,推薦者根據選擇策略做出動作,與該動作對應的推薦者狀態為nτ.推薦者動作選擇結束后,狀態更新為nτ+1并等待用戶下一次廣播.
2) 推薦者動作a.推薦者從項目集選擇最終向用戶推薦的項目,推薦該項目即為推薦者動作a.
3) 動作選擇策略π.選擇策略決定推薦者最終選擇的推薦項目.本文選擇策略與DQN中策略相同,為ε-greedy policy.
4) 動作獎勵r.用戶對推薦者提供的推薦項將有相應的滿意度.滿意度對信任的影響幅度記為獎勵r,該值影響推薦者在下一時刻的動作選擇.
本文通過用戶預期評價與實際評價差值來表征用戶滿意度,利用最小均方誤差方法(least mean square, LMS)方法計算評價差值與信任變化的動態映射關系.本過程將信任的動態變化視為DQN過程中給予推薦者的獎勵,信任的變化將影響推薦者對推薦項目的選擇行為.
3 興趣度、信任計算與建議處理
本節介紹了用戶間信任的基本定義及用戶建議定義,信任計算結合了用戶興趣度及推薦用戶信任,使得計算結果更加符合實際.本節給出了用戶建議處理過程,并說明了預期評價的計算方法.
3.1 用戶興趣度
1) 網頁保存、收藏.sf(pk)表示保存、收藏參數.用戶進行保存、收藏行為時,sf(pk)=1,否則sf(pk)=0.
2) 網頁瀏覽.用戶對網頁內容感興趣時,相應的網頁瀏覽時間與訪問次數均會增加.設置用戶瀏覽時間比率表示單位頁面大小的用戶瀏覽時間,即瀏覽時間time(pk)與頁面大小e(pk)之比,時間比率越大,表示用戶對該網頁內容越感興趣.頁面pk被訪問次數f(pk)與頁面瀏覽時間time(pk)構成頁面瀏覽參數b(pk),即:
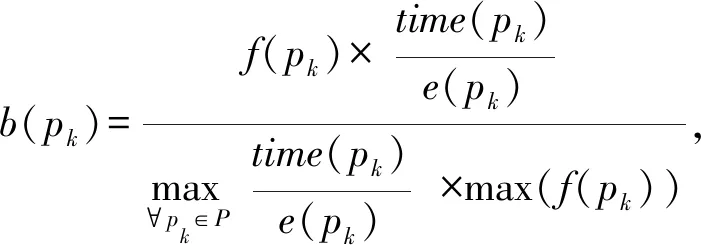
(1)
其中,P是所有用戶瀏覽頁面的集合.
3) 點擊網頁提供的超鏈接.超鏈接點擊參數c(pk)通過點擊的超鏈接數nc(pk)和頁面pk提供的超鏈接總數ls(pk)計算為
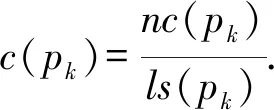
(2)
4) 分享、轉發網頁內容.分享參數trans(pk)衡量用戶的分享行為,若用戶對網頁pk進行分享、轉發操作,trans(pk)=1,否則trans(pk)=0.
用戶對項目內容相關網頁pk的興趣度Im(pk)可計算為
(3)
(4)
3.2 信任計算及數據結構
用戶間的信任可通過直接信任和推薦信任得到.有交互經驗的用戶為直接用戶,無交互經驗但存在信任路徑的用戶為間接用戶.
有交互經驗的直接用戶之間產生直接信任,無交互經驗但存在信任路徑的間接用戶之間產生推薦信任.
tj,b表示用戶j對用戶b的直接信任:
tj,b存儲在矩陣T中,tj,b∈[0,1].

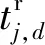
其中,信任值的范圍為[0,1],信任值為0表示完全不信任,信任值為1表示完全信任.
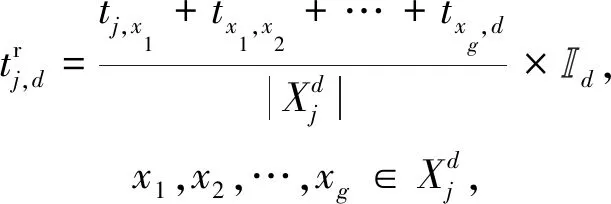
(5)
3.3 用戶評價建議處理

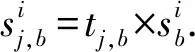
(6)
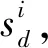
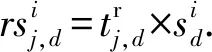
(7)
其中,rsi與si均存儲在矩陣Si中,Si為初始用戶j通過不同用戶得到的對項目i的預期評價存儲矩陣,用戶評價分值范圍為[0,10].
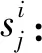
(8)
用戶j接收到多項推薦時,將計算得到每個項目的預期評價,接受預期評價最高的項.
4 DQN信任增強過程
本節詳細介紹了DQN信任增強過程(trust boost via deepq-learning, DQN-TB),說明了該過程的方法和流程,并給出了相應的偽代碼.圖2給出了DQN-TB過程的流程圖框架.

Fig.2 Flow chart of DQN-TB圖2 DQN-TB過程流程圖
需要說明,DQN-TB過程中可以存在1對1關系,即只有用戶u1期望提高u2對自己的信任值tu1,u2;也可以存在多對1的關系,即用戶u1,u2,…均期望提高用戶u3對自己的信任值.
4.1 模型框架
如圖3所示,項目集中每個項目分別對應不同動作,DQN-TB方法將用戶視為環境主體,在每個狀態通過記憶池中的數據進行訓練,并從項目集中選擇項目作為最終動作向用戶推薦項目,同時獲得用戶返回的獎勵并將其與狀態、動作存入記憶池中進行下一次網絡訓練更新.
本過程使用Q網絡預期回報,并根據圖2的過程流程及圖3的框架圖,更新網絡:
Step1.推薦項目
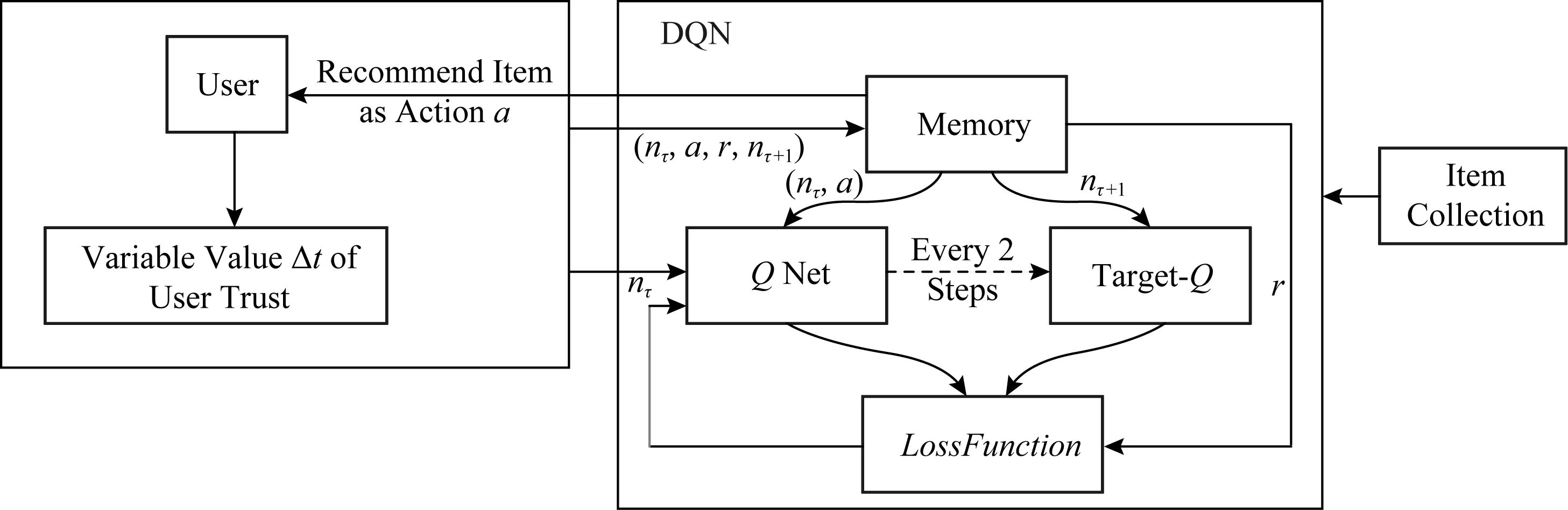
Fig.4 Data transmission process of DQN-TB圖4 DQN-TB過程數據傳輸流程圖
用戶在時間τ發出廣播,推薦者根據用戶廣播中的項目要求,從對應項目集中選擇項目進行推薦,所選項對應動作aτ,推薦者狀態記為nτ.
Step2.信任更新
用戶收到并接受推薦項目后,預期評價與實際評價的差值將影響用戶對推薦者的信任.將用戶視為DQN-TB過程的環境,信任值t隨著用戶對推薦項目的滿意度進行更新,用戶的信任變化幅度Δt將作為DQN-TB過程的獎勵值.
Δt與動作aτ、推薦者狀態nτ和未來狀態nτ+1存儲在記憶池中,并作為網絡輸入.
Step3.網絡訓練學習
DQN-TB過程使用記憶池中的數據與Q網絡進行動作預期選擇,通過target-Q網絡模擬用戶現實,并根據Q網絡與target-Q網絡的差值更新Q網絡.
Step4.重復Step1~Step3.
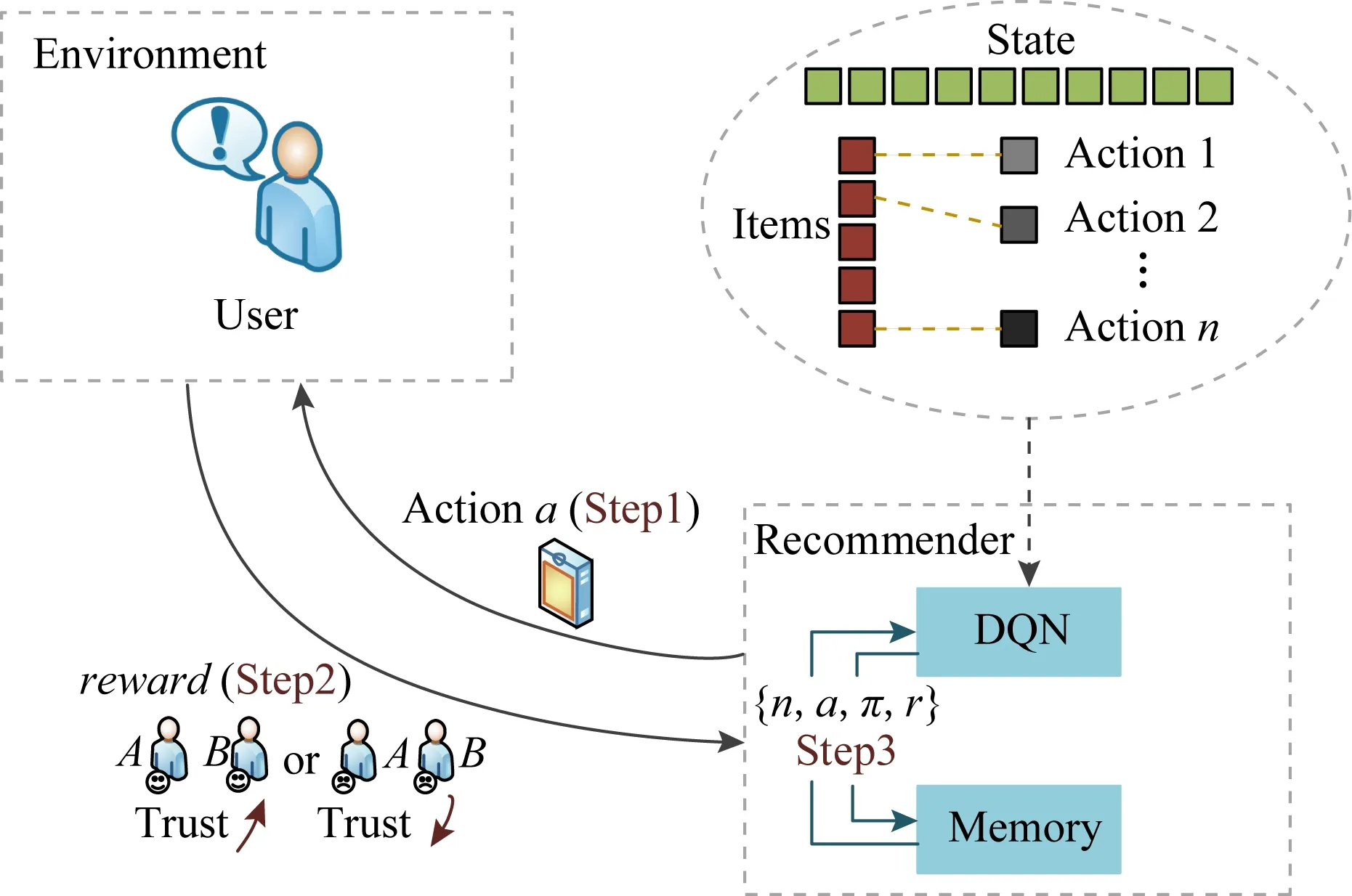
Fig.3 Framework steps of DQN-TB圖3 DQN-TB過程步驟框架
考慮到現實情況,用戶間的推薦過程一旦建立,將不會無條件停止.用戶對推薦者信任值過低時,推薦者提供的意見不會被用戶采納.因此,若推薦者始終得到負向獎勵或推薦失敗次數過多,將會終止循環.為使推薦者可擁有更多機會進行推薦學習,同時考慮到實際情況,信任值過低時進行推薦不合現實,通過實驗驗證,發現當設定t<0.2時終止推薦,會得到較好的結果.并且,為防止信任值溢出,規定當t更新結束后,t>1時,取t=1.
4.2 DQN-TB設計
考慮信任的動態性以及推薦項目的具體過程,本方法使用Q網絡來估計推薦者選擇某項目進行推薦(即動作aτ)的回報.將信任變化程度作為獎勵值后,項目選擇回報可模型化為
Q(nτ,aτ;ω)≈Qπ(nτ,aτ),
(9)
其中,ω為Q網絡權重參數,π為所選策略.考慮到推薦者與用戶可能無交互經驗,規定推薦策略:
1) 初次推薦.所有備選項目選擇概率相等,隨機選擇推薦項.
2) 后續推薦.使用ε-greedy policy,選擇概率根據推薦結果動態變化,最終收斂.
根據馬爾可夫性,隨機狀態中下一時刻的狀態只與當前狀態有關.因此DQN-TB過程通過Q網絡計算動作概率并作出動作選擇后,會得到獎勵值Δt及下一步的狀態nτ+1.同時,實際回報由target-Q網絡模擬計算:
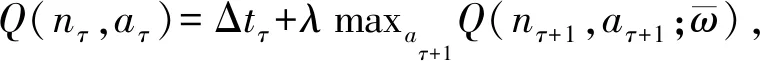
(10)
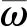

(11)
同時,對目標函數L(ω)使用隨機梯度下降,即可更新Q網絡參數ω.DQN-TB過程中,Q網絡與target-Q網絡結構相同,target-Q網絡的權重參數與Q網絡權重參數相同,每2次迭代同步1次.
圖4給出了DQN-TB過程的數據傳輸流程過程.Q網絡與target-Q網絡提取記憶池中數據進行計算,根據計算出的Q_eval值從項目集中選取項目作為動作進行推薦.用戶接受項目后,實際體驗會使用戶信任發生改變.用戶信任更新后,信任變化值返回DQN-TB,Q網絡的權重根據LossFunction進行更新,并進行下一輪迭代.DQN-TB過程中,Q網絡每2步將網絡權重傳輸至target-Q網絡.
4.3 獎勵參數Δt設置及信任更新
靜態信任由于數值固定,無法準確表示用戶在未來的信任關系,這一問題導致許多推薦算法不能響應用戶關系及用戶偏好的改變,使推薦結果的準確性降低.而隨著經驗累積,動態信任中的推薦者可及時響應用戶的偏好改變,從而使推薦結果愈加精準.
已有部分學者將DQN方法應用于推薦系統,這使推薦過程保持長久的動態性.Zheng等人[14]提出了一種應用于新聞推薦的深度強化學習框架.該方法根據用戶特征及行為反饋計算動態獎勵值,使推薦系統能夠捕捉用戶偏好的改變,從而獲得長久的獎勵,并保持用戶對推薦系統的興趣.
本文提出的方法受到文獻[14]的啟發,考慮到信任的動態變化特性及長期推薦過程的經驗學習,將信任動態變化幅度Δt作為獎勵值,采用DQN進行過程建模.
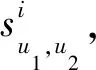
以u1,u2分別為用戶和推薦者為例,使用LMS算法對信任變化及更新過程進行模擬:
由于實際信任更新過程中評價誤差及信任均基于單個用戶(即u1和u2),誤差成本函數定義為
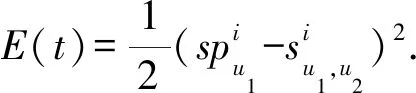
(12)
更新梯度g定義為
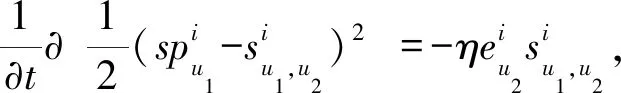
(13)
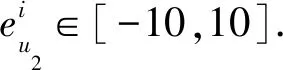
為保證數值計算合理性,防止信任更新值溢出,更新梯度g被約束為
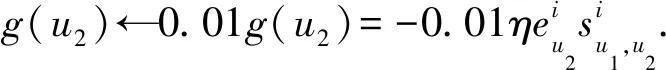
(14)
通過計算用戶u1的實際評分與預期評分的差值,可對用戶u1與推薦者u2的信任進行更新.若u1與u2的信任關系為直接信任,兩者信任更新表示為
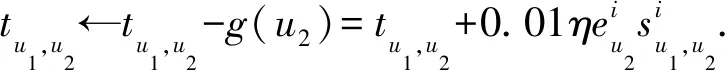
(15)
同樣地,若u1與u2的信任關系為間接信任,更新表示為
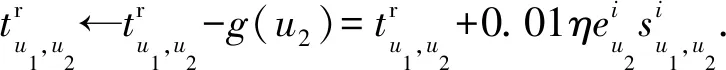
(16)
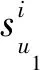
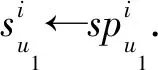
(17)
推薦者u2獲得的獎勵值為0.01g(u2)=Δt.
DQN-TB過程中,用戶u1接受用戶u2的推薦并做出實際評價后,該獎勵值將作為參數輸入網絡中進行下一步計算.
4.4 Markov決策過程參數
表1給出了DQN-TB過程的Markov決策過程相關定義.

Table 1 Parameters of Markov Decision Process表1 Markov決策過程參數
用戶推薦過程不會無條件停止,因此,用戶狀態數將隨著推薦過程不斷增加.推薦過程中的動作為推薦項目,因此可選動作與項目集中的項目數量相關.通過查閱相關文獻和參考資料,本文設定γ=0.9.
4.5 算法偽代碼
算法1.DQN-TB算法.
① 初始化記憶池D的容量N;
② 初始化Q網絡的權重ω;
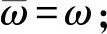
④ for (episode=1) do
⑤ 初始化序列n1={x1},序列預處理φ1=
φ(n1);
⑥ for (τ=1) do
⑦ 初次推薦使用隨機概率ε選擇動作aτ;
⑨ if (accept) do
⑩ 得到動作aτ的獎勵值Δt,載入xτ+1;
4.6 計算復雜度分析
DQN-TB使用了隨機梯度下降方法進行參數更新,因此,可知DQN-TB算法的計算復雜度為T(n)=(C+n)×n×n×n≈T(n4)=O(n4).可知算法復雜度為多項式級別.
5 實 驗
本節將對DQN-TB過程中推薦信任與直接信任的轉化比例、獎勵參數計算中的信任更新學習率進行說明,同時說明DQN-TB過程的信任增強效果,并對DQN-TB應用于推薦系統后的性能給出了相應的對比驗證,包括推薦成功率與感知用戶偏好的動態變化.
5.1 基本介紹
本文使用仿真實驗驗證模型性能,來模擬推薦方向單個用戶進行推薦,用戶對推薦方的信任隨推薦而變化的過程.實驗環境基于OpenAI Gym,其中,獎勵參數值reward隨著DQN-TB的每一輪推薦,根據LMS方法動態更新,并傳輸至DQN-TB.實驗數據使用從豆瓣采集的用戶影評數據及電影項目類別,包括10個用戶對11個電影項目類別中不同電影的評價數據,所有用戶的觀影總數為300部,影評數據規模為510條.實驗從所有用戶中隨機選擇用戶作為目標用戶,并進行推薦.
DQN-TB過程目的為提高單個用戶信任值,本實驗中Q網絡結構示意如圖5所示,Q網絡從記憶池中提取數據輸入到網絡中,通過隱藏層計算Q值,并根據相應動作選擇策略來選擇最終動作.DQN-TB過程中的狀態為用戶當前信任值,動作為DQN-TB可向用戶推薦的項目.
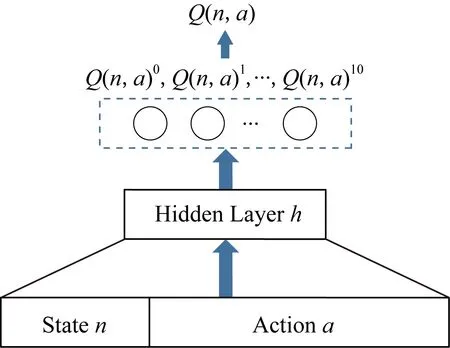
Fig.5 Q network structure圖5 Q網絡結構圖
5.2 推薦信任與直接信任轉化
用戶項目推薦過程中,當通過推薦信任進行推薦后,用戶間交互更新為直接信任,此時,為更符合現實情境,通過推薦信任計算出的信任值需進行一定折扣才可轉化為直接信任值,并進行后續計算.推薦信任折扣因子由μ表示.
為確定μ的具體數值,本節使用4組小數據對選擇不同折扣因子導致的結果變化進行分析.4組數據分別對應高推薦信任與高推薦評價、高推薦信任與低推薦評價、低推薦信任與高推薦評價、低推薦信任與低推薦評價,同時,4組數據中其他項均相同.分析使用的數據集由表2給出.推薦信任折扣因子μ采用不同數值時對結果影響如圖6中整體評分項表示,對比評分項為僅使用Direct Trust1至Direct Trust4計算得出的預期評價.
由圖6可知,當μ較低時,整體預期評價值低于對比評分;當μ較高時,推薦信任用戶的評價結果對總結果起正向激勵作用.該對比實驗使用數據雖不能代表全部現實情況,但依舊可以反映推薦信任折扣因子μ對結果的影響.考慮到現實因素,當用戶第一次進行直接信任推薦時,依舊會對評價主體用戶有相應評分影響.為使用戶評分由信任值影響,并盡量少的受到μ的干擾,本文設定μ=0.8.

Table 2 Trust Value and Score Value表2 信任及評分值表
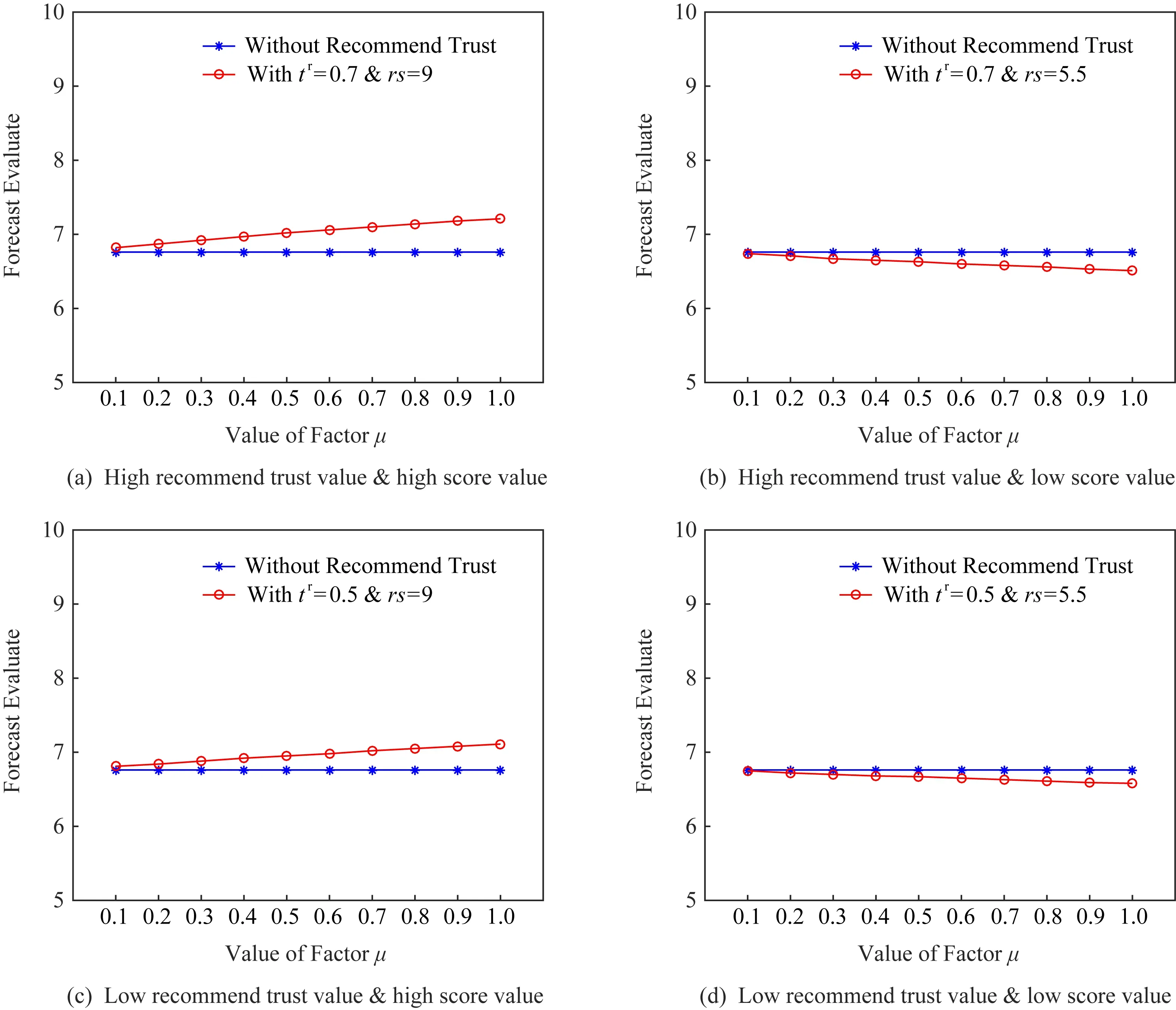
Fig.6 Performance comparison on different μ圖6 不同μ下預期評價比較
5.3 信任更新學習率
由4.3節可知,獎勵參數reward需要通過信任更新得到.信任更新的學習率η對更新結果有直接的影響.η過小會使更新步長過小,收斂速度過慢;η過大時收斂速度會提高,但可能因為步長過大而導致無法收斂.因此,本節將針對不同學習率對信任更新幅度的影響進行討論.
信任更新時,根據建議用戶與用戶主體社會關系的遠近,用戶主體信任的更新幅度也會有所區別.本文將推薦用戶分為直接用戶和推薦用戶.
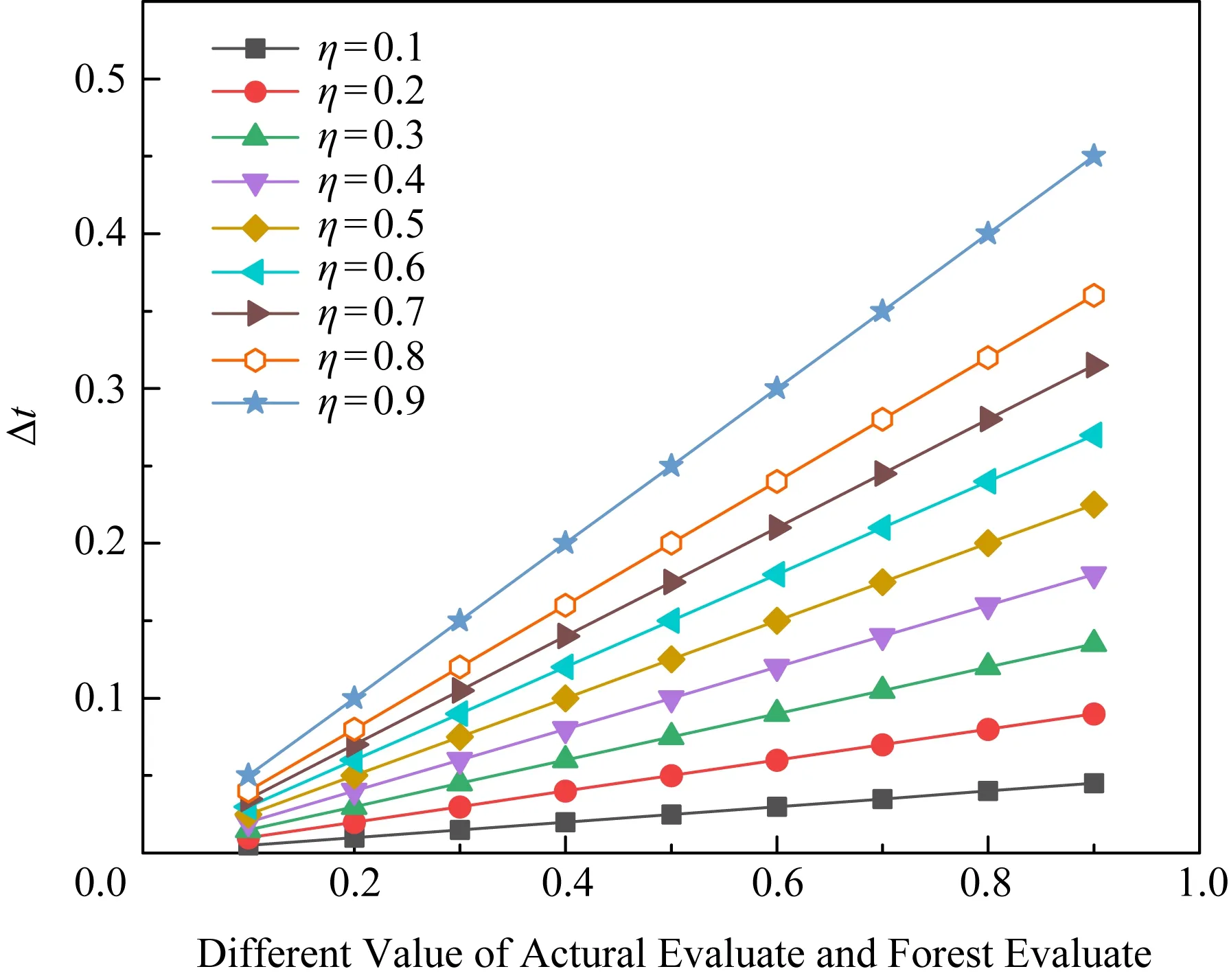
Fig.7 Performance comparison on different η圖7 不同η下信任更新幅度比較
推薦用戶由于社會關系較遠,不會被用戶主體給予高度包容性,同時由于心理預期較低,推薦成功后用戶主體的信任值將變化較大,因此推薦信任的更新步長相對較大.并且,由于信任值范圍為[0,1],η數值過高會導致信任變化過大,因此設定推薦用戶信任更新學習率η=0.2.
對于直接用戶,由于社會關系近,用戶主體會抱有更多包容性,直接用戶比推薦用戶單次信任更新步長相對小,因此本文設定直接信任用戶的信任更新學習率η=0.1.但直接信任用戶信任更新存在累計作用,因此直接用戶學習率設定為

其中,p為直接用戶推薦得到正面反饋的次數,q為得到負面反饋次數.
5.4 信任動態變化
根據DQN-TB過程,用戶通過推薦結果學習到相關經驗后,推薦選擇將會進一步調整,以符合被推薦用戶的相關興趣偏好.圖8給出了DQN-TB過程中隨輪次增加的信任變化折線圖,用戶初始推薦信任值為0.67.
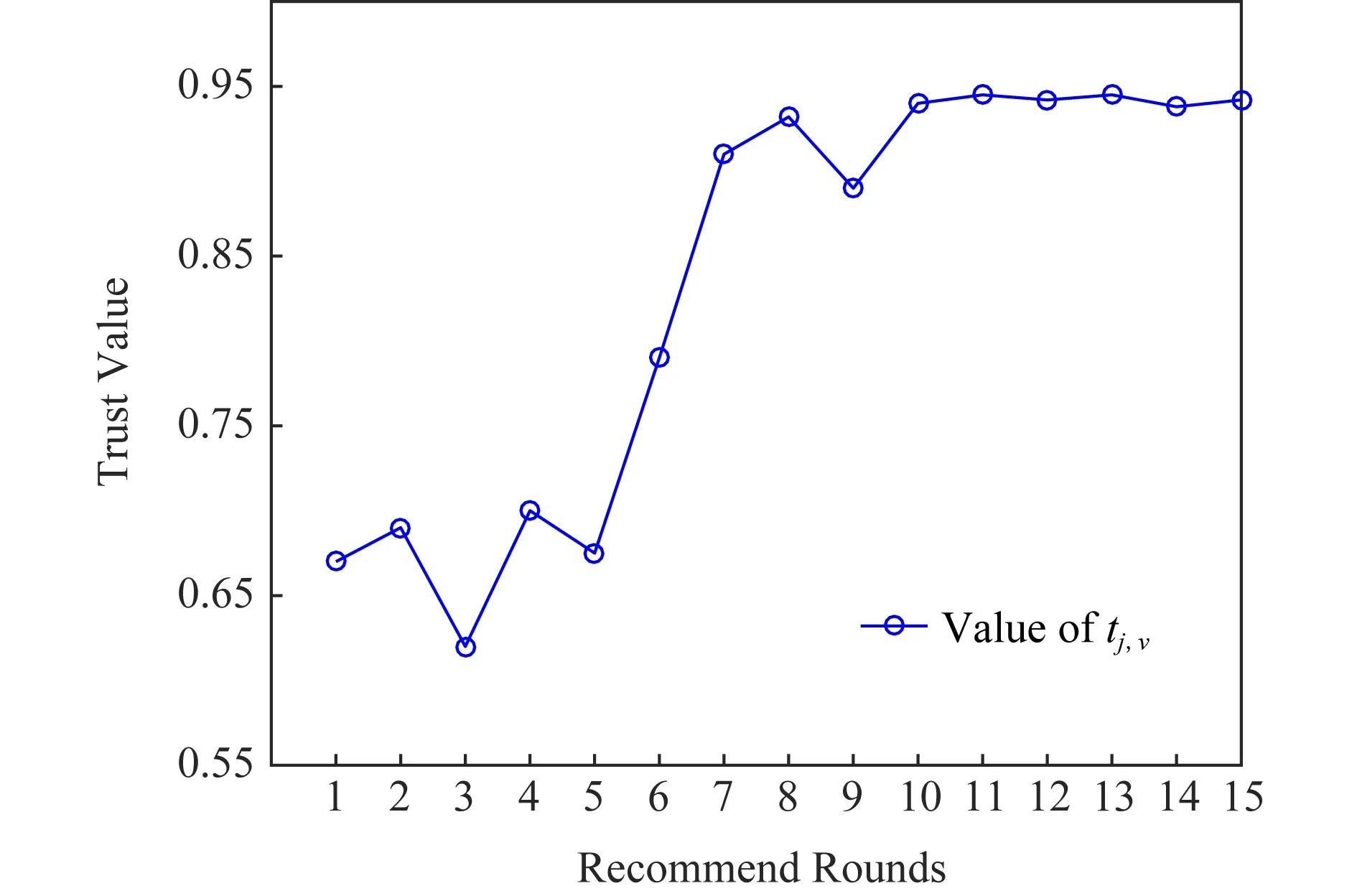
Fig.8 The line chart of dynamic change of trust value圖8 信任動態變化折線圖
當用戶間第1輪推薦結束后、第2輪推薦開始前,用戶間信任將根據5.2節中轉化率進行推薦信任-直接信任轉換,使得信任值有一定程度的下降.由圖8可知,當輪次較少時,DQN-TB過程處在探索階段,此時記憶池中的經驗不夠豐富,因此信任變化折線較為波折,由于最初用戶間為推薦信任,因此當推薦者經驗增加時,對被推薦用戶的偏好的了解加深,此時用戶間的信任值持續上升.并且由于成功經驗的增多,后續推薦輪次中用戶間信任值始終處于較高水平,且波動幅度很小.
DQN-TB過程可較準確地刻畫用戶的信任變化狀態,并取得較好的效果.用戶信任的動態變化可以實時地反映用戶偏好的變化以及社交關系的改變,因此DQN-TB的動態性研究是很有意義的,這一特性也為DQN-TB應用于推薦系統帶來更多靈活性.
5.5 DQN-TB應用于推薦系統
5.4節中的實驗驗證了DQN-TB對于信任的動態變化及增強都有準確的刻畫,因此該方法亦可應用于推薦系統中,為系統中的用戶提供精準的推薦.本節將DQN-TB與Li等人[15]的CSIT方法和Gohari等人[16]提出的CBR方法進行了對比,并比較了三者向用戶進行推薦的成功率及三者對用戶偏好改變的響應靈敏度.
CSIT方法是一種性能優越的矩陣因子分解和上下文感知推薦者法,作者同時提供了GMM方法進行增強并同時處理分類上下文和連續上下文.CBR方法使用對用戶意見的信任和意見的確定性來描述用戶信心,并將用戶信心引入信任建模,通過隱式信任模型向用戶提供一系列的推薦.由于目前的推薦系統僅利用用戶的社交關系以及關系網絡中其他用戶的偏好來進行相關推薦,無法反映用戶的信任變化,且用戶的偏好變化捕捉只能來源于關系網絡中的其他用戶,造成系統對用戶偏好的變化反饋不及時、不準確.
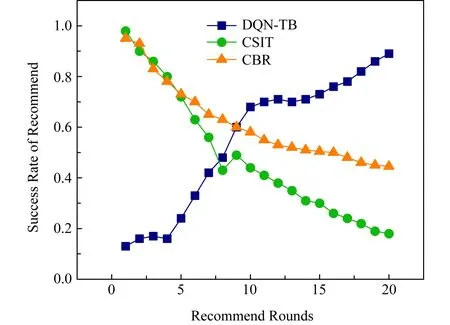
Fig.9 Change of success rate in recommend system圖9 推薦系統成功率變化
圖9給出了用戶信任與偏好動態變化下,20輪內不同輪次對應的DQN-TB方法、CSIT方法和CBR方法的平均成功率對比.隨著推薦輪次的增加,DQN-TB擁有越來越高的準確率,這是由于DQN-TB對于動態變化響應的靈活性.同時,由于CSIT方法和CBR方法的對用戶偏好感知的計算方法影響,兩者的準確性隨條件的動態變化而逐漸下降.實際情況中,普通推薦者法準確率下降的速度隨用戶偏好的變化幅度而有所偏差,但亦足以說明DQN-TB的優越性.
5.6 響應靈敏度
定義MANR表示用戶偏好變化后推薦系統響應變化所需要的輪次(answer rounds, ANR),MSUMR表示推薦總輪次(sum rounds, SUMR),MSEN表示推薦系統相應用戶偏好變化的靈敏度(sensitivity, SEN),則MSEN可計算為
表3給出了450輪推薦中用戶偏好變化60次后各推薦系統的響應靈敏度.隱式信任模型與上下文矩陣分解過多的依賴用戶的鄰居及相似用戶,當偏好改變多次時,相關信息的分析將失去其準確性,將無法及時反饋用戶的偏好.CBR方法同時為用戶推薦多個項,因此具有一定的覆蓋性,響應靈敏度優于CSIT模型.表3的數據驗證了DQN-TB過程對用戶偏好具有較好的靈敏度,這一特性與DQN-TB過程中的動態獎勵及經驗學習有關.因此,將DQN-TB過程應用到推薦系統可及時感知用戶偏好的改變,并相應地調整推薦項目的選擇.

Table 3 Response Sensitivity of Each Recommendation System表3 各推薦系統響應靈敏度
6 總結及未來展望
本文結合強化學習方法提出了一種基于動態信任的信任增強方法,該方法通過用戶信任的動態變化感知用戶偏好的變化,并根據推薦經驗進行學習,以提供更加準確的推薦,從而使用戶信任增加并保持在較高水平.實驗表明:所提出的方法是高效、準確的.同時,本方法也可應用于推薦系統,并達到感知用戶偏好變化、進行精準推薦的目的.
本文的方法重點考慮用戶信任的動態變化,未來,將針對信任及建議計算方法進行改進以使推薦的結果更加精準、有效.
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
創業家(2015年5期)2015-02-27 07:53:25
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
