基于語(yǔ)譜圖和神經(jīng)網(wǎng)絡(luò)的聲紋識(shí)別研究
2020-06-23 10:31:18李蜜
高師理科學(xué)刊 2020年4期
關(guān)鍵詞:模型
李蜜
基于語(yǔ)譜圖和神經(jīng)網(wǎng)絡(luò)的聲紋識(shí)別研究
李蜜
(華中師范大學(xué) 物理科學(xué)與技術(shù)學(xué)院,湖北 武漢 430079)
隨著科技的不斷發(fā)展,人們對(duì)信息安全的要求越來(lái)越高,如何更簡(jiǎn)單、更方便、更加安全地進(jìn)行身份驗(yàn)證變得異常重要.在卷積神經(jīng)網(wǎng)絡(luò)(CNN)的基礎(chǔ)上,結(jié)合語(yǔ)譜圖和直方均衡增強(qiáng)算法對(duì)聲紋識(shí)別特征進(jìn)行學(xué)習(xí)和訓(xùn)練.模型使用非固定長(zhǎng)度語(yǔ)音段,首先將語(yǔ)音段進(jìn)行濾波、分幀、加窗和離散余弦變換得到語(yǔ)譜圖,再使用直方均衡算法將像素點(diǎn)不均勻分布語(yǔ)譜圖轉(zhuǎn)化成像素點(diǎn)能在整個(gè)灰度區(qū)間均勻分布的語(yǔ)譜圖,最后使用CNN對(duì)語(yǔ)譜圖進(jìn)行特征訓(xùn)練和身份認(rèn)證.
聲紋識(shí)別;語(yǔ)譜圖;卷積神經(jīng)網(wǎng)絡(luò);圖像增強(qiáng)
隨著現(xiàn)代科技的不斷發(fā)展以及移動(dòng)互聯(lián)網(wǎng)、物聯(lián)網(wǎng)等技術(shù)的普及,人們?cè)絹?lái)越致力于尋求高效安全的身份認(rèn)證方法.聲紋識(shí)別是生物特征識(shí)別的一部分,它是通過(guò)提取說(shuō)話人語(yǔ)音中的特征來(lái)驗(yàn)證說(shuō)話人身份的一種技術(shù),與人臉識(shí)別和指紋識(shí)別相比,聲紋識(shí)別具有實(shí)現(xiàn)簡(jiǎn)單、不易模仿、不會(huì)遺失等特點(diǎn).
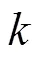
通過(guò)分析并深入研究了文獻(xiàn)[7-11]的具體模型,包括前期的預(yù)處理過(guò)程、說(shuō)話人特征提取結(jié)構(gòu)模型、分類方法,結(jié)合文獻(xiàn)模型的特點(diǎn),本文使用CNN神經(jīng)網(wǎng)絡(luò)算法,將說(shuō)話人語(yǔ)音使用MFCC算法提取個(gè)性特征形成語(yǔ)譜圖,并將語(yǔ)譜圖進(jìn)行統(tǒng)一規(guī)范.之后使用直方均衡化算法對(duì)語(yǔ)譜圖進(jìn)行增強(qiáng),使語(yǔ)譜圖像素點(diǎn)均勻分配,再使用CNN神經(jīng)網(wǎng)絡(luò)進(jìn)行特征訓(xùn)練學(xué)習(xí)和自動(dòng)識(shí)別,達(dá)到身份認(rèn)證效果.本文使用的開發(fā)平臺(tái)為PyCharm,使用的神經(jīng)網(wǎng)絡(luò)框架為Keras.
1 聲紋識(shí)別算法
1.1 語(yǔ)譜圖提取
特征參數(shù)提取在語(yǔ)音識(shí)別等方面廣泛應(yīng)用,其算法線性預(yù)測(cè)編碼系數(shù)(LPC)算法、線性預(yù)測(cè)倒譜系數(shù)(LPCC)算法和梅爾倒譜系數(shù)(MFCC)算法[12]等.其中,MFCC算法在梅爾倒譜頻帶上是等距劃分的,頻率尺度值與實(shí)際頻率的對(duì)數(shù)分布更符合人耳的聽覺(jué)特性,但是MFCC算法會(huì)進(jìn)行三角濾波,造成說(shuō)話人信息丟失.因此,本文直接將語(yǔ)音信號(hào)進(jìn)行分幀之后,進(jìn)行傅里葉變換,取其對(duì)數(shù)形成語(yǔ)譜圖.
1.2 直方圖均衡圖像增強(qiáng)算法
直方圖均衡化是通過(guò)一個(gè)映射函數(shù),將輸入的像素點(diǎn)不均勻的灰度圖像轉(zhuǎn)化為像素點(diǎn)能夠在整個(gè)灰度區(qū)間呈現(xiàn)均勻分布,拉伸圖像的灰度動(dòng)態(tài)范圍[13].通過(guò)這種映射關(guān)系的處理,重新計(jì)算每一個(gè)像素點(diǎn)上的新像素從而實(shí)現(xiàn)圖像增強(qiáng).
直方圖均衡化算法:
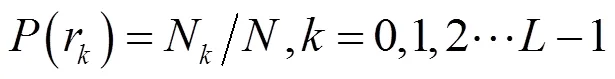
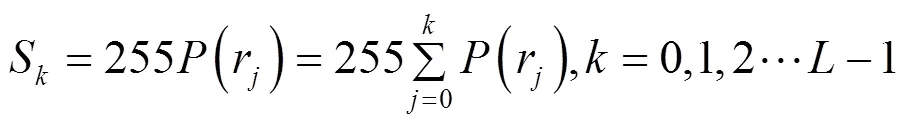
沒(méi)有經(jīng)過(guò)直方圖均衡化增強(qiáng)算法處理的語(yǔ)譜圖見圖1,經(jīng)過(guò)直方圖均衡化增強(qiáng)算法處理之后的語(yǔ)譜圖見圖2.圖1、圖2為同一個(gè)說(shuō)話人同一段語(yǔ)音,這2幅語(yǔ)譜圖呈肉眼可見區(qū)別.實(shí)驗(yàn)結(jié)果表明,經(jīng)過(guò)圖像增強(qiáng)處理后的圖片更能凸顯說(shuō)話人信息.
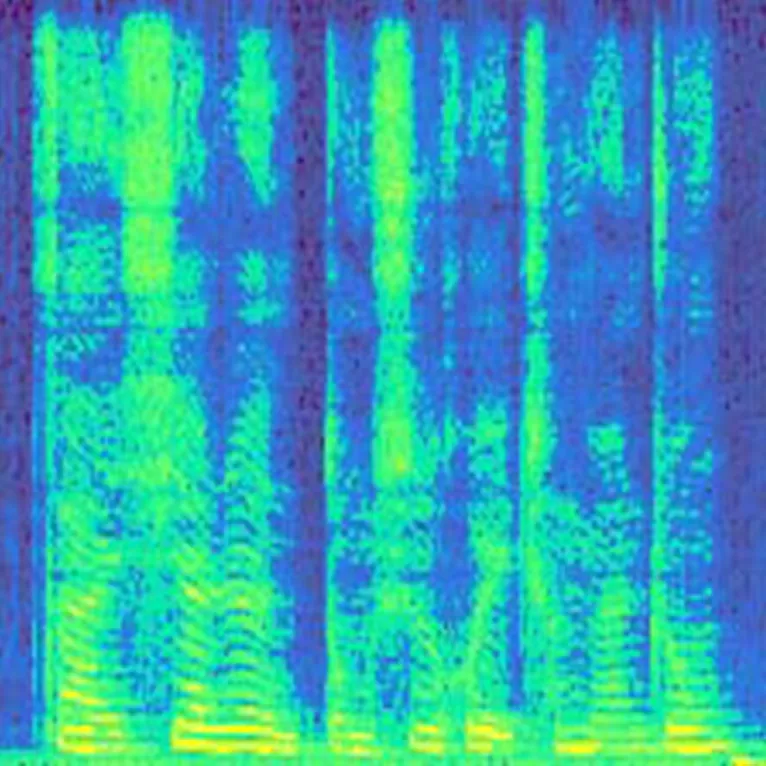
圖2 圖像增強(qiáng)語(yǔ)譜圖
1.3 卷積神經(jīng)網(wǎng)絡(luò)
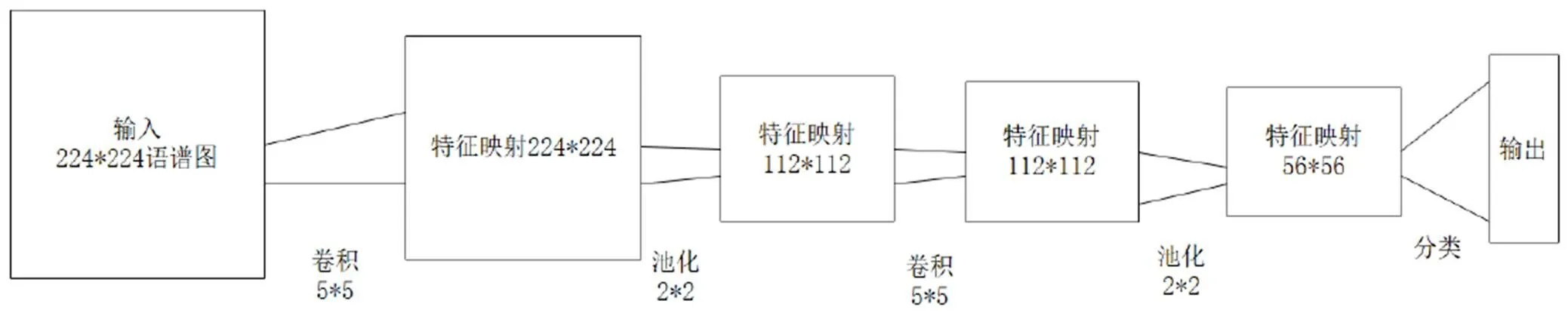
圖3 CNN 模型
2 實(shí)驗(yàn)部分
2.1 語(yǔ)音數(shù)據(jù)集
實(shí)驗(yàn)采用AISHELL中文語(yǔ)音數(shù)據(jù)庫(kù),其中包含400個(gè)說(shuō)話人,共178 h的語(yǔ)音數(shù)據(jù),語(yǔ)音采樣頻率為16 k.語(yǔ)料庫(kù)中的語(yǔ)音數(shù)據(jù)按8∶2的比例分為訓(xùn)練集和測(cè)試集.在訓(xùn)練集上隨機(jī)選取100個(gè)語(yǔ)音進(jìn)行訓(xùn)練,采用不同的迭代次數(shù)和抓取的訓(xùn)練個(gè)數(shù)測(cè)試模型準(zhǔn)確率.模型使用SoftMax回歸函數(shù)將神經(jīng)網(wǎng)絡(luò)輸出轉(zhuǎn)換成概率分布,再使用交叉熵來(lái)計(jì)算預(yù)測(cè)的概率和實(shí)際的概率之差距離來(lái)訓(xùn)練模型.
2.2 實(shí)驗(yàn)分析
訓(xùn)練集和測(cè)試集在不同迭代次數(shù)下的準(zhǔn)確率和損失函數(shù)變化見圖4.由圖4可以看到,訓(xùn)練集和測(cè)試集在迭代次數(shù)不同的條件下精確度(ACC)上升和損失函數(shù)(LOSS)下降.在設(shè)置的迭代次數(shù)為30次時(shí),精度上升和損失降低速率均較為快速,且能趨于穩(wěn)定;在設(shè)置的迭代次數(shù)為40次時(shí),精度上升和損失降低速度與30次時(shí)基本一致,而在迭代后期出現(xiàn)過(guò)擬合情況.因此,本文選擇使用神經(jīng)網(wǎng)絡(luò)對(duì)聲紋迭代30次來(lái)判斷其精確度.
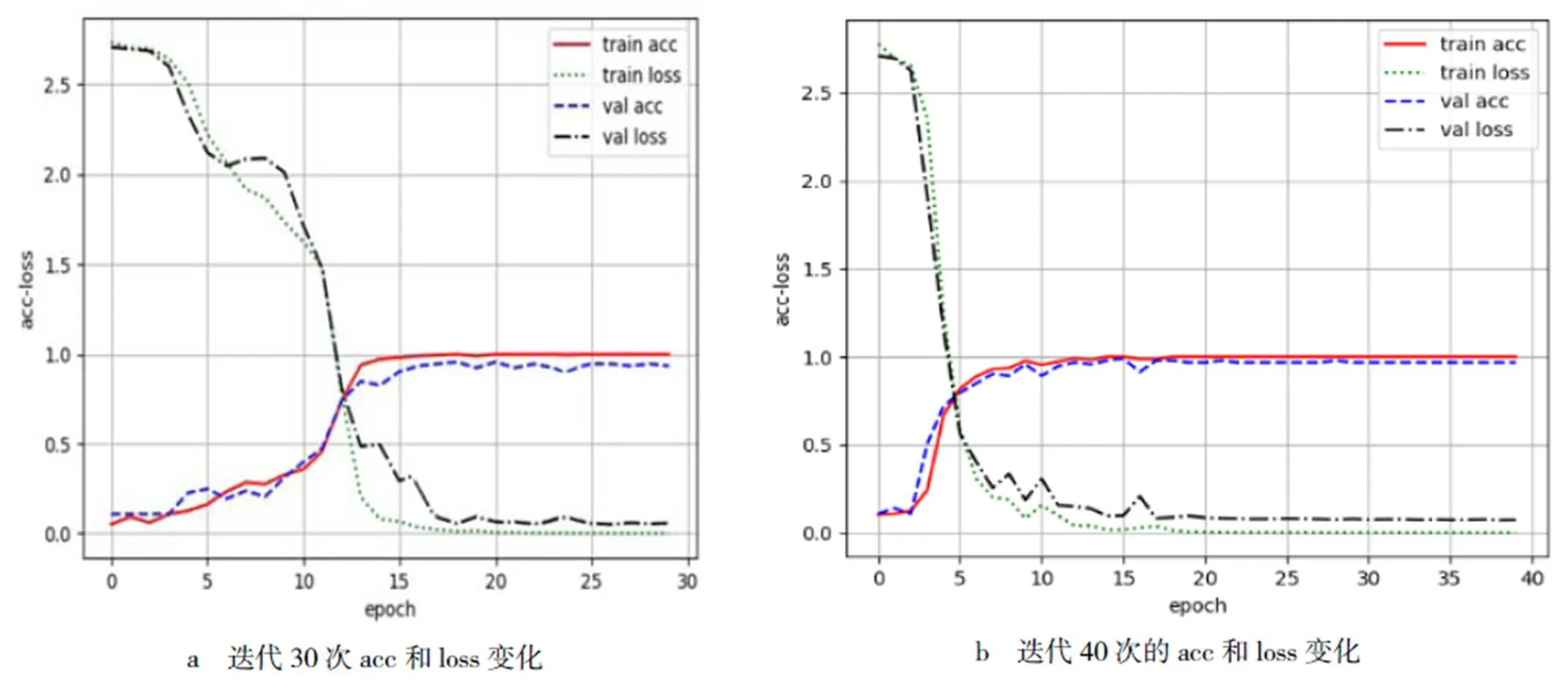
圖4 不同迭代次數(shù)下的訓(xùn)練集和測(cè)試集準(zhǔn)確率和損失函數(shù)變化曲線
將本文方法與常用的聲紋識(shí)別模型CNN,GMM-UBM,GMM-SVM模型進(jìn)行對(duì)比,在這些模型下的識(shí)別率見表1.

表1 不同模型下的識(shí)別率比較
從實(shí)驗(yàn)結(jié)果可以看出,在CNN結(jié)合圖像增強(qiáng)算法之后識(shí)別率高于傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)CNN,LSTM模型以及傳統(tǒng)的聲紋識(shí)別模型.現(xiàn)階段基于神經(jīng)網(wǎng)絡(luò)的聲紋識(shí)別模型都是以大數(shù)據(jù)為基礎(chǔ),在大數(shù)據(jù)的基礎(chǔ)上進(jìn)行說(shuō)話人個(gè)性特征提取,再用神經(jīng)網(wǎng)絡(luò)進(jìn)行訓(xùn)練和學(xué)習(xí).同樣與傳統(tǒng)聲紋識(shí)別模型對(duì)比,傳統(tǒng)模型學(xué)習(xí)形式過(guò)于單一,不能完全保證將說(shuō)話人特征全部學(xué)習(xí),影響識(shí)別率.本文借鑒使用語(yǔ)譜圖和CNN網(wǎng)絡(luò)聲紋學(xué)習(xí)模型的方法,在語(yǔ)譜圖的基礎(chǔ)上進(jìn)行圖像增強(qiáng).該方法的優(yōu)點(diǎn)在于將語(yǔ)譜圖上的說(shuō)話人信息凹陷,便于網(wǎng)絡(luò)模型從語(yǔ)譜圖提取個(gè)性特征進(jìn)行學(xué)習(xí)和訓(xùn)練,提高識(shí)別率.
3 結(jié)語(yǔ)
本文采用語(yǔ)譜圖來(lái)表示聲紋特征,并利用卷積神經(jīng)網(wǎng)絡(luò)對(duì)特征加以訓(xùn)練的方法,實(shí)現(xiàn)了對(duì)聲紋信息的識(shí)別.在經(jīng)過(guò)圖像增強(qiáng)之后聲紋識(shí)別有著較高的識(shí)別率,更好地反應(yīng)了說(shuō)話人的特征,提高了神經(jīng)網(wǎng)絡(luò)對(duì)聲紋的學(xué)習(xí)和識(shí)別水平.
[1] Rabiner L R,Levinson S E,Sondhi M M.On the Application of Vector Quatiz-Ation and Hidden Markov Models to Speaker-Independent,Isolated Word Recognition[J].Bell System Technical Journal,1983,62(4):1075-1105
[2] Lawrence R,Rabiner.A tutorial on Hidden Markov Models and selected applications in speech recognition[J].Processings of the IEEE,1989,77(2):257-286
[3] Reynolds D A,Rose R C.Robust text-independent speaker identification using Gaussian mixture speaker models[J].IEEE Transactions on Speech & Audio Processing,1995,3(1):72-83
[4] 方曉.基于CPSO優(yōu)化的BP神經(jīng)網(wǎng)絡(luò)在說(shuō)話人識(shí)別中的應(yīng)用[C]//中國(guó)通信學(xué)會(huì)青年工作委員會(huì).Proceedings of International Conference of China Communication and Information Technology(ICCCIT2010).2010:299-303
[5] 余玲飛,劉強(qiáng).基于深度循環(huán)網(wǎng)絡(luò)的聲紋識(shí)別方法研究及應(yīng)用[J].計(jì)算機(jī)應(yīng)用研究,2019,36(1):153-158
[6] 李靚,孫存威,謝凱,等.基于深度學(xué)習(xí)的小樣本聲紋識(shí)別方法[J].計(jì)算機(jī)工程,2019,45(3):262-267,272
[7] 張旺俏.基于VQ的聲紋識(shí)別研究[J].中國(guó)科技信息,2007(7):124-125,127
[8] 魯曉倩,關(guān)勝曉.基于VQ和GMM的實(shí)時(shí)聲紋識(shí)別研究[J].計(jì)算機(jī)系統(tǒng)應(yīng)用,2014,23(9):6-12
[9] 陳仁林,郭中華,朱兆偉.基于BP神經(jīng)網(wǎng)絡(luò)的說(shuō)話人識(shí)別技術(shù)的實(shí)現(xiàn)[J].智能計(jì)算機(jī)與應(yīng)用,2012,2(2):47-49
[10] 吳震東,潘樹誠(chéng),章堅(jiān)武.基于CNN的連續(xù)語(yǔ)音說(shuō)話人聲紋識(shí)別[J].電信科學(xué),2017,33(3):59-66
[11] 余玲飛,劉強(qiáng).基于深度循環(huán)網(wǎng)絡(luò)的聲紋識(shí)別方法研究及應(yīng)用[J].計(jì)算機(jī)應(yīng)用研究,2019,36(1):153-158
[12] 高銘,孫仁誠(chéng).基于改進(jìn)MFCC的說(shuō)話人特征參數(shù)提取算法[J].青島大學(xué)學(xué)報(bào):自然科學(xué)版,2019,32(1):61-65,73
[13] 錢小燕.引導(dǎo)濾波的紅外圖像預(yù)處理算法[J].科學(xué)技術(shù)與工程,2015,15(21):32-33
Research on voiceprint recognition based on spectrogram and neural network
LI Mi
(School of Physical Science and Technology,Central China Normal University,Wuhan 430079,China)
With the continuous development of science and technology,people′ s requirements for information security are getting higher and higher,how to conduct authentication more easily,more conveniently and more securely becomes extremelyimportant.On the basis of convolutional neural network(CNN),the feature of voiceprint recognition is learned and trained by combining spectrogram and square equalization algorithm.The model uses a non-fixed-length speech segment.First,the speech segment is filtered,framed,windowed,and discrete cosine transformed to obtain a spectrogram.Then,a histogram equalization algorithm is used to convert the pixel uneven distribution profile into pixel points.A spectrogram that is uniformly distributed in the grayscale interval.Finally, the CNN is used to perform feature training and identity authentication on the spectrogram.
voiceprint recognition;language spectrum;convolutional neural network(CNN);image enhancement
TP312
A
10.3969/j.issn.1007-9831.2020.04.008
1007-9831(2020)04-0039-04
2019-11-06
李蜜(1993-),女,湖北天門人,在讀碩士研究生,從事聲紋識(shí)別研究.E-mail:limi_1993@outlook.com
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
