深度學習可解釋性研究進展
2020-06-23 09:21:34成科揚師文喜詹永照
計算機研究與發展 2020年6期
成科揚 王 寧 師文喜 詹永照
1(江蘇大學計算機科學與通信工程學院 江蘇鎮江 212013)2(社會安全風險感知與防控大數據應用國家工程實驗室(中國電子科學研究院) 北京 100041)3(新疆聯海創智信息科技有限公司 烏魯木齊 830001)
隨著大型數據庫的可用性和深度學習方法的不斷改進,人工智能系統在越來越多復雜任務上的性能已經達到甚至超過了人類的水平.目前,基于深度學習算法的系統已經廣泛應用于圖像分類[1]、情緒分析[2]、語音理解[3]等領域,實現了代替人工作出決策的過程.然而,盡管這些算法在大部分的任務中發揮著卓越的表現,但由于產生的結果難以解釋,有些情況下甚至不可控[4].與此同時,如果一個模型完全不可解釋,那么其在眾多領域的應用就會因為無法展現更多可靠的信息而受到限制.
從用戶的角度而言,深度學習系統不僅需要向用戶展現推薦的結果,還需要向用戶解釋推薦的原因.如在新聞推送的應用[5]方面,針對不同的用戶群體,需要推薦不同類型的新聞,滿足他們的需求.此時不僅要向用戶提供推薦的新聞,還要讓用戶知道推薦這些新聞的意義.因為一旦用戶認為推薦的內容不夠精準,那么他們就會認為深度學習系統在某些方面存在偏差.在經濟學方面,對于股價的預測以及樓市的預測深度學習有可能會表現得更好.但是由于深度學習的不可解釋以及不安全性,應用中可能會更偏向于使用傳統可被解釋的機器學習.
從系統開發人員的角度來說,深度學習一直以來是作為一個黑盒在實驗室的研究過程中被直接使用的,大多數情況下其確實可以取得一些良好的結果.而且,通常情況下,深度學習網絡的結果比傳統機器學習的結果更精準.但是,關于如何獲得這些結果的原因以及如何確定使結果更好的參數問題并未給出解釋.同時,當結果出現誤差的時候,也無法解釋為什么會產生誤差、怎么去解決這個誤差.如耶魯大學科研人員曾嘗試使用基于深度學習的AI進行程序Debug,導致AI直接將數據庫刪除的結果.
從監管機構立場來看,監管機構更迫切希望作為技術革命推動力的深度學習具有可解釋性.2017年監督全球金融穩定委員會(Financial Stability Board)稱,金融部門對不透明模型(如深度學習技術)的廣泛應用可能導致的缺乏解釋和可審計性表示擔憂,因為這可能導致宏觀層級的風險[6].該委員會于2017年底發布了一份報告,強調AI的進展必須伴隨對算法輸出和決策的解釋.這不僅是風險管理的重要要求,也是建立公眾及金融服務監管機構更大信任的重要條件.
現今,隨著深度學習廣泛而深入的應用,其可解釋的重要性越發突顯,如基于深度學習的醫療診斷由于不可解釋性無法獲知其判斷依據從而無法可信使用、司法量刑風險得分因為其不可解釋而發生偏差造成判斷錯誤、無人駕駛造成車禍卻因為系統不可解釋而難以分析其原因等.
由此可見,深度學習的可解釋性研究意義重大,其可以為人們提供額外的信息和信心,使其可以明智而果斷地行動,提供一種控制感;同時使得智能系統的所有者能夠清楚地知道系統的行為和邊界,人們可以清晰看到每一個決策背后的邏輯推理,提供一種安全感;此外,也可監控由于訓練數據偏差導致的道德問題和違規行為,能夠提供更好的機制來遵循組織內的問責要求,以進行審計和其他目的.
當前,學術界和工業界普遍認識到深度學習可解釋性的重要性,《Nature》《Science》《MIT Tech-nology Review》近來都有專題文章討論這一問題,AAAI 2019設置了可解釋性人工智能討論專題,David Gunning則領導了美國軍方DAPRA可解釋AI項目,試圖建設一套全新且具有可解釋性的深度學習模型.
本文將對深度學習可解釋性研究的源起、發展歷史進行分析,并從深度學習的可解釋性分析和構建可解釋性深度模型2個方面對現有研究方向進行歸納總結,同時對可解釋深度學習未來的發展作出展望.
1 深度學習可解釋性研究歷史
1.1 深度學習可解釋性研究起源
近年來,隨著深度學習應用領域的不斷拓展,作為制約深度學習應用的瓶頸,可解釋性問題越來越受到研究者的重視.
早在1982年Fukushima等人開發了一種名為Neocognitron的人工神經網絡[7],該網絡采用分層的多層設計允許計算機“學習”識別視覺模式.經過多層重復激活的強化策略訓練使其性能逐漸增強,由于層數較少,學習內容固定,具有最初步的可解釋性能,并且可以看作是深度學習可視化的開端之作.1991年Garson[8]提出了基于統計結果的敏感性分析方法,從機器學習模型的結果對模型進行分析,試圖得到模型的可解釋性.早期的研究,啟迪了后來研究者的思路.自此,越來越多的研究者加入到了深度學習可解釋性研究,研究進入了蓬勃的發展期.
1.2 深度學習可解釋性研究探索期
在這一階段,研究者們從實驗和理論2方面都進行了探索研究,研究取得了顯著進展.
在實驗研究方面,主要包括深度學習模型內部隱層可視化和敏感性分析等實驗.
1) 在內部隱層可視化實驗方面.2012年Google研究人員在基于TensorFlow的深度模型可視分析工作中,將人的視覺感知能力和深度學習算法的計算能力相結合,對深度學習的可解釋性進行探索和分析[9];2014年Zeiler等人[10]介紹了一種新穎的CNN隱層可視化技術,通過特征可視化查看精度變化,從而知道CNN學習到的特征是怎樣的,深入了解中間特征層的功能和分類器的操作.
2) 在敏感性分析實驗方面的代表性工作則包括:
① 基于連接權的敏感性分析實驗.如1991年Garson[8]提出通過度量輸入變量對輸出變量的影響程度的方法.
② 基于統計方法的敏感性分析法.如2002年Olden等人[11]通過大量的重復采樣、隨機打亂輸出值,得到基于給定初始值隨機訓練網絡的權重和重要性分布,通過統計檢驗的方法來進行敏感性分析.
③ 基于樣本影響力的敏感性分析實驗.如2017年Koh等人[12]通過影響力函數來理解深度學習黑盒模型的預測效果,即將樣本做微小的改變,并將參數改變對樣本微小改變的導數作為該樣本的影響力函數[13].
除了實驗方面,研究者們也對深度學習可解釋性理論進行了探索性研究:
2018年Lipton[14]首次從可信任性、因果關聯性、遷移學習性、信息提供性這4個方面分析了深度學習模型中可解釋性的內涵,指出“可解釋的深度學習模型作出的決策往往會獲得更高的信任,甚至當訓練的模型與實際情況發生分歧時,人們仍可對其保持信任;可解釋性可以幫助人類理解深度學習系統的特性,推斷系統內部的變量關系;可解釋性可以幫助深度學習模型輕松應對樣本分布不一致性問題,實現模型的遷移學習;可解釋性可為人們提供輔助信息,即使沒有闡明模型的內部運作過程,可解釋模型也可以為決策者提供判斷依據.”同時,作者指出構建的可解釋深度學習模型至少應包含“透明性”和“因果關聯性”的特點.
早期對深度學習可解釋性的探索研究取得了豐富的成果,然而,基于黑盒模型進行解釋始終存在解釋結果精度不高、計算機語言難以理解等局限.所以,構建可解釋性模型開始成為新的研究方向.
1.3 深度學習模型可解釋性模型構建期
與對深度學習黑盒模型進行解釋相比,直接構建的可解釋性模型往往具有更強的可解釋性.
2012年起,人們開始嘗試引入知識信息以構建可解釋的深度模型.主要的嘗試方案有2種:1)將表示為知識圖譜的離散化知識轉換為連續化向量,從而使得知識信息的先驗知識能夠成為深度模型的輸入;2)將知識信息中的邏輯規則作為深度學習優化目標的約束,指導模型的學習過程[15].2017年Hu等人[16]提出的teacher-network網絡中,通過將深度神經網絡與一階邏輯規則相結合,顯著提高了分類的效果,表現出良好的可解釋性.
值得一提的是,Hinton等人提出的膠囊網絡模型(CapsNet)[17],其在2017年發表的“Dynamic Routing Between Capsules”[18]一文中,詳細介紹了CapsNet架構.由于該模型采用動態路由來確定神經網絡的邊權,這就從一定程度上提供了邊權確定的解釋性,更重要的是,與傳統卷積神經網絡(convolutional neural networks, CNN)相比,CapsNet具有用少量訓練數據就能實現泛化的特點.同時,樣本對象的細節特征,如對象的位置、旋轉、厚度、傾斜度、尺寸等信息會在網絡中被學習保存下來,不會被丟失.這些CapsNet所獨具的優點展現了其作為成功的可解釋深度學習模型的特點.
深度學習的可解釋性研究從提出到展開,也就短短數年,但已取得了令人矚目的諸多成果.為此我們有必要對相關研究現狀及其成果做一個系統的梳理.
2 深度學習可解釋性研究現狀
可解釋性研究目前主要存在2方面研究方法:1)從深度學習模型本身進行入手,調整模型內部參數,對系統得到的結果進行分析,判斷參數對于結果的影響.或是通過對輸入變量添加擾動,探測表征向量來評估系統中不同變量的重要性,推測系統作出決策的依據.2)直接構建本身就具有可解釋性的模型,旨在學習更結構化和可解釋的模型.
2.1 深度學習模型可解釋性分析研究
深度學習作為黑盒模型,對于輸出結果往往無法指出系統得到決策的依據.因此,通過對黑盒模型內部結構進行剖析,可以清晰地看到決策背后的邏輯推理,得到具有可解釋性的結果.
2.1.1 基于可視化的可解釋性研究
2012年Krizhevsky等人[19]利用大型卷積網絡模型在ImageNet基準數據集上的測試展示了令人印象深刻的分類性能.然而,并沒有較為合理的方法說明模型表現出色的原因或者展示作出判斷的依據.因此,Zeiler等人[10]提出了一種新穎的CNN隱層可視化技術,從信息提供性方面入手,通過特征可視化,查看精度變化,從而知道CNN學習到怎樣的特征.這些隱層可視化可應用于中間每一層結構,通過對隱層運用一些可視化方法來將其轉化成人類可以理解的有實際含義的圖像.方法利用反卷積的相關思想實現了隱層特征可視化來幫助理解CNN的每一層究竟學到了什么東西,從而能夠找到優于Donahue等人[20]的模型架構,具體過程如圖1所示:
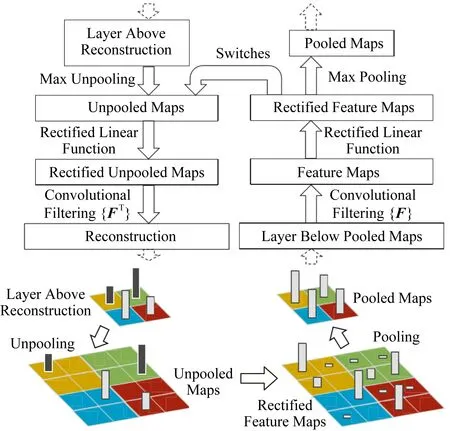
Fig.1 Visualization of the hidden layer process圖1 可視化隱層過程
2.1.2 基于魯棒性擾動測試的可解釋性研究
基于魯棒性擾動的方法主要是通過對輸入數據添加擾動元素[21].有些模型不能直接解釋實現過程,但是可以對其他屬性作出評估.例如通過對輸入數據添加擾動元素,測試添加的特征是否為主要特征,是否會影響最后得出的結果.所以,解釋這些黑盒模型的工作普遍集中在理解固定模型如何導致特定預測.例如通過在測試點周圍局部擬合更簡單的模型[22]或通過擾亂測試點來了解模型預測的變化[23-25].其中比較有代表性的工作是Koh等人[12]在2017年提出的通過影響力函數來理解深度學習黑盒模型的預測效果.通過學習算法跟蹤模型[26]的預測并返回其訓練數據,從而識別對給定預測負責的訓練點[27].即使在理論失效的非凸和非可微模型上,影響函數的近似仍然可以提供有價值的信息.在線性模型和卷積神經網絡上,由于計算出了對訓練樣本施加輕微擾動之后對特定測試樣本損失函數的影響,所以這個方法也可以應用到對抗樣本的生成中[28],只需要在一部分影響力函數較大的樣本中添加一些微小的擾動,就足以干擾其他樣本的判定結果.文章證明影響函數可用于理解模型行為[29]、調試模型、檢測數據集錯誤,甚至創建視覺上可區分的訓練集攻擊等多個任務.
在判斷擾動對模型結果產生的影響方面,Fisher等人[30]提出了模型分類依賴性(model class reliance, MCR)方法,通過提取模型的重要特征來對模型進行解釋.變量重要性(variable importance, VI)工具用于描述協變量在多大程度上會影響預測模型的準確率[31].通常情況下,在一個模型中重要的變量在另一個模型中卻不是那么重要,或者說,一個分析人員使用的模型依賴的協變量信息可能與另一個分析人員使用的協變量完全不同.通過設定模型VI的上下限,根據變量的擾動對模型判定結果的影響來判斷模型對于變量的依賴程度[32-33].方法通過對COMPAS犯罪模型中性別和種族等變量的變化進行度量,解釋模型對于不同變量的依賴程度.
2.1.3 基于敏感性分析的可解釋性研究
敏感性分析(sensitivity analysis, SA)是一類非常重要的,用于定量描述模型輸入變量對輸出變量的重要性程度的方法,在經濟、生態、化學、控制等領域都已經有了非常成熟的應用.其基本思想就是令每個屬性在可能的范圍內變動,研究和預測這些屬性的變化對模型輸出值的影響程度.典型的敏感性分析方法有基于連接權、基于統計和基于擾動分析3類.
在基于連接權的方法中比較有代表性的工作是Garson[8]提出的通過設置權重來估測輸入變量對輸出變量的影響程度.然而這種方法放到深度網絡中由于忽略了非線性激活函數誤差會一步一步積累[34],所以逐漸不再被使用.
在基于統計方法的敏感性分析方法中有代表性的是Olden等人[11]提出的使用隨機初始的權重構建一組神經網絡并記錄其中預測性能最好的神經網絡的初始權重[35],通過大量重復采樣得到基于給定初始值隨機訓練網絡的權重和重要性分布,從而判斷不同變量對于模型的影響程度,可以被看作是在基于統計方法的敏感性分析方法中的代表作.
在評估輸入樣本擾動敏感性方面,Hunter等人[36]開發一種新的擾動流形模型及其對應的影響程度測量方法,以評估各種擾動對輸入樣本或者網絡可訓練參數的敏感性影響.這種方法是對使用信息幾何解決分類問題的局部影響測量方法的全新擴展.它的貢獻在于其度量方法是由信息幾何驅動的,可以直接進行計算而不需要優化任何目標函數.并且該方法提出的敏感性影響測量適用于各種形式的外部和內部擾動,可用于4個重要的模型構建任務:檢測潛在的“異常值”、分析模型架構的敏感性、比較訓練集合測試集之間的網絡敏感性以及定位脆弱區域.
2.2 可解釋性深度學習模型構建研究
深度學習模型可解釋性分析的研究只是嘗試通過一定的技術手段去分析和解釋深度學習模型,猶如管中窺豹、盲人摸象,所以另一些研究者試圖直接創建具有可解釋性的深度學習模型,使其對數據處理的過程、表示或其他方面更易于人們理解.
2.2.1 基于模型代理的可解釋性建模
常用的深度網絡通常使用大量的基本操作來推導它們的決策.因此,解釋這種處理所面臨的基本問題是找到降低所有這些操作的復雜性的方法,或是將已有的深度學習系統學習另外的可解釋的系統,以此提高可解釋性,代理模型法就是這樣一類方法.
Ribeiro[37]的局部可理解的與模型無關的解釋技術(local interpretable model-agnostic explanation, LIME)即為一種代理模型方法.該方法首先通過探測輸入擾動獲得深度模型的響應反饋數據,然后憑此數據構建局部線性模型[38],并將該模型用作特定輸入值深度模型的簡化代理.Ribeiro表示,該方法可作用于識別對各種類型的模型和問題域的決策影響最大的輸入區域.LIME這樣的代理模型可以根據其對原始系統的吻合程度來運行和評估.代理模型也可以根據其模型復雜度來測量,例如LIME模型中的非零維度的數量.因為代理模型在復雜性和可靠性之間提供了可量化的關系,所以方法可以相互對照,使得這種方法很具有吸引力.
另一種代理方法是Carnegie Mellon大學Hu等人[39]提出的反復蒸餾方法,該方法體現了可解釋方法中的遷移學習性,通過將邏輯規則的結構化信息轉移到神經網絡的權值[40]中.網絡包括教師網絡(teacher network)和學生網絡(student network)兩個部分,教師網絡負責將邏輯規則所代表的知識建模,學生網絡利用反向傳播方法加上教師網絡的約束,迫使網絡模擬一個規則化教師的預測,并且在訓練過程中迭代地演進[41]這2個模型.教師網絡在每次訓練迭代中都要構建,也就是說訓練過程中教師網絡和學生網絡是一個聯合訓練[42]的過程.它將深度神經網絡與一階邏輯規則[43]相結合,將邏輯規則整合到神經模型中,將邏輯規則的結構化信息轉換為神經網絡的權重.通過使用后驗正則化原理[44]構建的教師網絡完成這種規則信息的轉移,具體過程如圖2所示.方法能夠在具有高精度分類效果的同時,又能體現邏輯規則的解釋性,該方法可用于CNN和循環神經網絡(recurrent neural network, RNN)等不同網絡上,用于情感分析、命名實體識別,在深度神經網絡模型的基礎上實現效果提升.
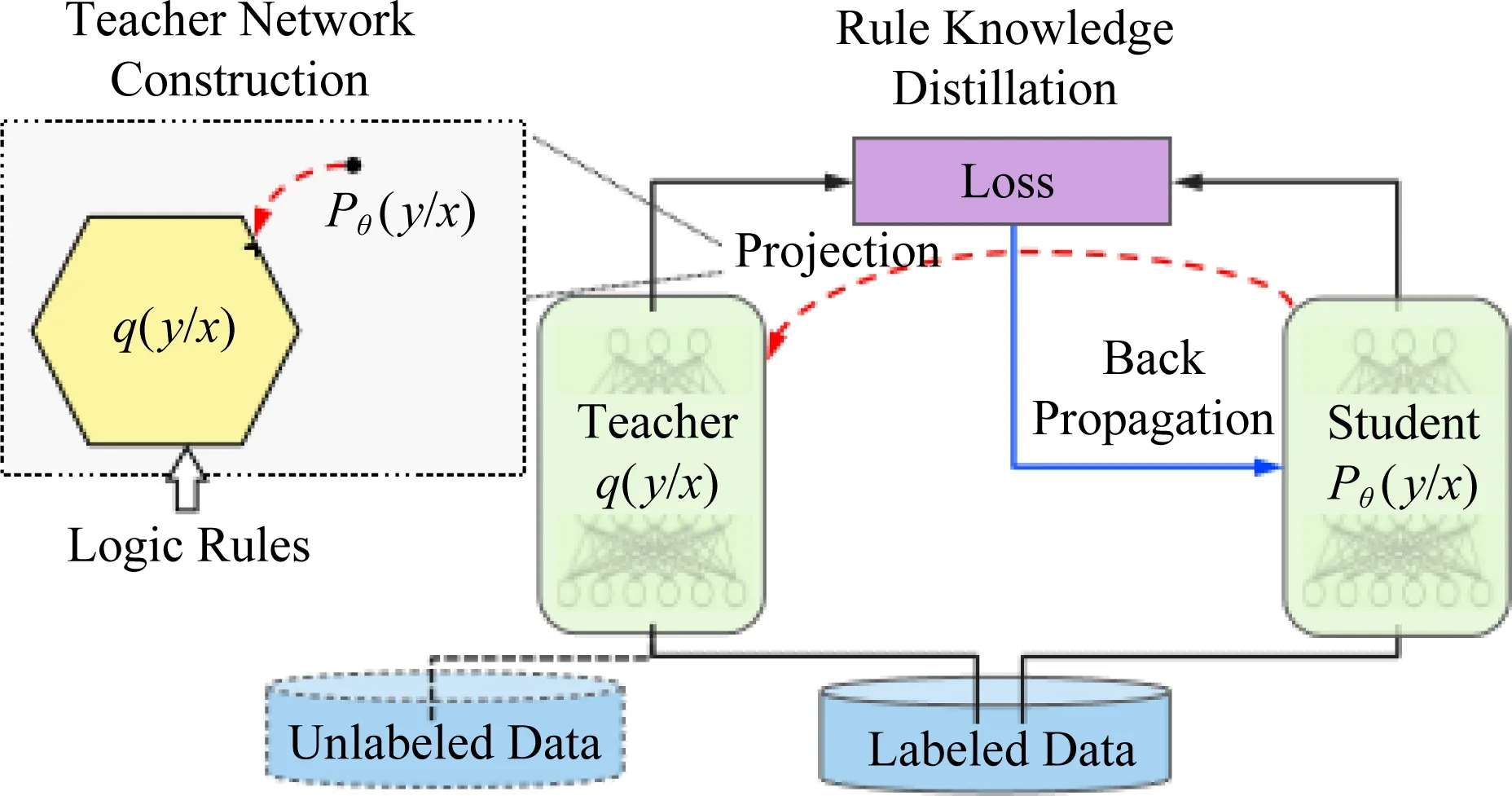
Fig.2 Teacher-Student network圖2 教師-學生網絡
2.2.2 基于邏輯推理的可解釋性建模
由于邏輯推理[45]能夠很好地展現系統的可解釋性[46],并且邏輯推理體現了可解釋方法中的因果關聯性.Garcez等人[47]提出了一種面向連接性論證的網絡框架,它允許推理和學習論證推理.方法使用神經符號學習系統將論證網絡轉換成標準的神經網絡,實現了基于權重的論證框架,具有學習能力[48].文中將算法分為正面論點和反面論點,2種論點都被設置在了論證網絡中,通過學習進行累積論證,隨著時間的推移,某些論證將會加強,某些論證將會削弱,論證結果可能會發生變化,其展現出該網絡的學習過程.
此外,Yao等人[49]提出了另一種新穎的推理模型,該模型通過深度強化學習來激活邏輯規則.模型采用記憶網絡的形式,存儲關系元組,模仿人類認知活動中的“圖像模式”.方法將推理定義為修改或從內存中恢復的順序決策,其中邏輯規則用作狀態轉換函數.模型在使用不到1000的訓練樣本且沒有支持事實的情況下,實現了在文本數據集bAbI-20上僅0.7%的平均錯誤率.
2.2.3 基于網絡節點關聯分析的可解釋性建模
2017年Hinton等人[18]提出了一種被稱為“膠囊”的新型神經單元.膠囊網絡極大地體現了可解釋方法中的因果關聯性特點,它改進了傳統的CNNs網絡,膠囊網絡中神經元節點間的權重路由關系可以解釋檢測到的特征之間的空間關系.每一組神經元組成一個膠囊,通過每一個膠囊中的神經元的活動向量(activity vector)來表示實體類型的實例化參數.活動向量的長度表示實體出現的概率,方向表示實例化的參數.活躍的低層膠囊預測結果通過轉移矩陣發送到相鄰活躍度相對較高的膠囊之中.當多個預測信息一致時,膠囊將被激活.該方法使用協議路由機制,該機制會為那些能更好擬合高層膠囊的實例化參數的低層膠囊分配更高權重.其中,協議路由機制使得每個膠囊能夠編碼一個特定語義的概念,可以清晰地知道每一個“膠囊”所做的工作.在一定程度上,膠囊網絡可以看作是一種特定語義化的網絡結構,從而使得構建的膠囊網絡成為了一種具有能夠解釋并識別對象空間結構信息的可解釋模型[50].在MNIST上的實驗表明,使用膠囊網絡,能夠有效甄別重疊的不同數字.
2.2.4 基于傳統機器學習的可解釋性建模
已有的深度學習系統具有強大的預測能力,結果精準但缺乏可解釋性;傳統的機器學習系統結構較為簡單,預測精度不如深度學習系統,但往往具備可解釋性.所以利用傳統可解釋機器學習方法構建可解釋深度學習模型,成為了一種新的嘗試方向.
以決策樹為例,眾所周知決策樹具有較好的可解釋性.自20世紀90年代起,便有研究者將決策樹與多層神經網絡相聯系進行研究.該工作主要利用決策樹的可解釋性的優點對神經網絡決策進行過程簡化,使深度學習網絡具有信息提供性的特征.方法之一是基于決策樹的深度神經網絡規則提取器(DeepRED)[51],它將為淺層網絡設計的基于決策樹的連續規則提取器(CRED)[52]算法擴展到任意多個隱層,并使用神經網絡逆向提取規則方式(RxREN)[53]來修剪不必要的輸入.然而,盡管DeepRED能夠構建完全忠實于原始網絡的樹,但生成的樹可能非常大,并且該方法的實現需要大量的時間和內存,因此在可伸縮性方面受到限制.為解決此問題,2018年南京大學周志華等人[54]提出了一種全新的深度學習方法“gcForest”(multi-grained cascade forest).該方法采用一種深度樹集成方法(deep forest ensemble method),使用級聯結構讓gcForest做表征學習.需要指出,由于模型的構建是基于可解釋的決策樹,gcForest的超參數比一般深度神經網絡少得多并且其可解釋性強、魯棒性高.因此,在大多數情況下,即使遇到不同領域的不同數據,也能取得很好的結果.同時,gcForest所需的訓練數據集較小,這不僅使gcForest訓練起來很容易,也使其可解釋性理論分析更為簡單.
總體而言,目前可解釋性深度學習模型的構建可以從可信任性、因果關聯性、遷移學習性、信息提供性4個方面對其進行分析.可信任性是具有可解釋性深度學習模型的基礎,其可以為人們提供額外的信息和信心,使人們可以明智而果斷地行動.使得智能系統的所有者清楚地知道系統的行為和邊界,人們可以清晰地看到每一個決策背后的邏輯推理,提供一種安全感,使得深度學習模型更好地服務于大眾.因果關聯性主要從邏輯推理和特征關聯2方面體現,例如面向連接性的網絡框架與Hinton提出的膠囊網絡.遷移學習性主要通過將結構化信息轉移到神經網絡的權值中,使神經網絡具有可解釋性.信息提供性主要是使模型向人們提供可以被理解的知識,主要包括與傳統機器學習相結合的深度學習模型或是深度學習模型的可視化等方法.
3 可解釋性深度學習的應用
當前,深度學習應用廣泛,但在某些特定領域,由于深度學習模型的不可解釋性限制了深度學習模型的應用.隨著深度學習可解釋性研究的深入,特別是具有可解釋性深度學習模型的建立,越來越多的關系到重大生產活動、人類生命安全的關鍵領域也開始能夠放心接受深度學習所帶來的紅利.
在推薦系統方面,新加坡國立大學Catherine等人[55]提出知識感知路徑遞歸網絡(KPRN),對用戶和物品之間的交互特征在知識圖譜中存在的關聯路徑進行建模,為用戶提供可解釋性推薦.在基于外部知識的基礎上,Wang等人[56]又提出基于翻譯的推薦模型,利用共同學習推薦系統和知識圖譜補全模型,提高推薦的解釋性.加州大學圣地亞哥分校Wang等人[57]借鑒混合專家模型(mixtures-of-experts)的思想提出了一種全新的深度學習推薦系統框架,利用用戶序列行為中相鄰物品間的關系來解釋用戶在特定時間點的行為原因,進而基于用戶的近期行為對其下一次行為進行預測,實現對用戶群體的精準推送.
在社區安全方面,可解釋深度學習應用于犯罪風險評估,可根據罪犯的受教育程度、前科、年齡、種族等一系列參數判斷再次犯罪的概率,對社會管理起到協助作用.Bogomolov等人[58]采用圖形卷積神經網絡來對毒品進行檢測,對輸入向量與網絡中的神經元關系進行解釋,通過訓練完成的圖形卷積神經網絡的測試結果給出結論,并根據藥效團特征來證明他們的結論.
在醫療方面,Luo等人[59]從重癥監護中的多參數智能監測(MIMICII)數據集中提取了特征,使用局部可解釋的模型不可知解釋(LIME)技術,實現了對難以解釋的復雜RF模型決策過程中重要特征的簡單解釋.這些解釋符合當前的醫學理解,并且推動了基于深度學習醫學診斷的發展進程.Zhang等人[60]提出了AuDNNsynergy深度學習模型來進行藥物組合克服耐藥性,通過整合多組樣本學習數據和化學結構數據來預測藥物組合產生新藥物,并對其中的深度模型的學習過程進行解釋分析.
綜上,深度學習已廣泛應用于推薦系統、醫療、安全等各個領域,而深度學習良好的表現也使其成為這些領域不可或缺的工具.可解釋性深度學習的出現,將顯著提高系統的可靠性,使其可知、可控、可被人們信任,在更多的領域發揮更大的作用.
4 總結與展望
以深度學習為代表的各種機器學習技術方興未艾,取得了舉世矚目的成功.機器和人類在很多復雜認知任務上的表現已經不分伯仲.然而,在解釋模型為什么奏效及如何運作方面,目前學界的研究還處于非常初級的階段.從當前研究現狀看,研究者們普遍意識到深度學習可解釋性的重要性,并已展開了諸多十分有意義的研究.但目前對深度學習可解釋性的研究尚處于起步階段,對于可解釋性的本質、研究手段認識都還未能形成統一認識和找到最佳方案,未來可解釋性深度學習領域的研究將會持續火熱下去.基于對當前研究實踐的分析和理解,我們認為未來深度學習的可解釋性研究將可從4個方面著手深入:
1) 嵌入外部人類知識.目前,大多數深度學習模型使用數據驅動的方法,而較少關注知識驅動的觀點.因此,將人類知識,如以知識圖譜形式與深度學習技術相結合構建具有解釋性的深度學習模型,可以作為一個研究方向.此外,可以利用可視化分析直觀地驗證模型是否正確遵循人類嵌入的知識和規則,以確保深度學習按照人類的意愿進行工作.
2) 深度學習的漸進式視覺分析.大多數現有可解釋的深度學習方法主要側重于在模型訓練完成后進行理解和分析模型預測,但由于許多深度學習模型的訓練非常耗時,因此迫切需要使用漸進的可視化分析技術,在保證模型準確率的情況下,同步進行可視化分析,保證模型的可解釋性.這樣不僅可以在模型訓練過程中漸進式進行同步分析.專家可以利用交互式可視化來探檢查新傳入的結果并執行新一輪的探索性分析,而無需等待整個培訓過程完成,并且保證了模型每一層的可解釋性.
3) 提高深度學習的擾動可解釋性.深度學習模型通常容易受到對抗性擾動的影響導致輸出錯誤的預測.有時對抗性示例的修改非常輕微,以至于根本無法注意到修改,但模型仍然會出錯.這些對抗性示例通常用于攻擊深度學習模型.在這方面,保持深度學習模型的魯棒性在實際應用中至關重要,當模型具有可解釋性時,即使輕微的擾動人們也可以知道擾動變量對于模型的影響以及影響程度,并且可以在基于人類知識的情況下向人們進行解釋.因此,關于可解釋深度學習的一個研究機會是結合人類知識來提高深度學習模型的魯棒性.
4) 以人為中心進行模型解釋性升級.理想的深度學習可解釋模型,應該能夠根據受眾背景知識的不同作出不同的解釋,即以人為中心進行解釋.同時,這種解釋應是機器一邊解決問題,一邊給出答案背后的邏輯推理過程.面對這樣的需求,未來深度學習可解釋模型,其輸出的整體可解釋性將由各個多元的子可解釋性組合而成,這對目前的機器學習從理論到算法都將是一個極大的挑戰.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
