基于Spark的大數據訪存行為跨層分析工具
2020-06-23 09:21:42許丹亞張偉功2
計算機研究與發展 2020年6期
許丹亞 王 晶,2 王 利 張偉功2,
1(首都師范大學信息工程學院 北京 100048)2(高可靠嵌入式技術北京市工程研究中心(首都師范大學) 北京 100048)3(北京成像理論與技術高精尖創新中心(首都師范大學) 北京 100048)
大數據時代的到來,為信息處理技術帶來了新的挑戰.大數據時代的信息具有數據量大、數據類型多、增長速度快、價值密度低等特點[1].MapReduce有效地解決了海量數據處理的擴展性問題[2],然而MapReduce在處理過程中,將數據和中間結果以文件的形式存放到磁盤上,例如Map階段的計算結果,頻繁地訪問磁盤,導致磁盤的壓力成為計算中的性能瓶頸[3].對此,Spark以內存計算的方式進行了改進,即數據的存儲和處理都位于內存之中.目前Spark已經得到了工業界的廣泛應用,騰訊、百度、淘寶、亞馬遜、網易等企業都在使用Spark構建自己的大數據業務[4].內存計算顯著地提高了程序的運行速度,但同時也對內存系統造成了巨大的壓力,使得內存系統的性能成為影響數據處理速度的瓶頸[5-6].
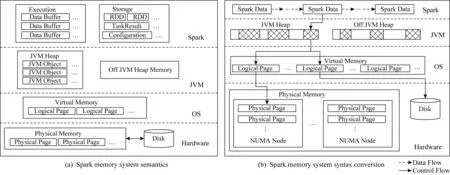
Fig.1 Spark memory system semantics and syntax conversion圖1 Spark系統中各層內存對象的語義及各層語義轉換流程
傳統的計算機體系結構和存儲系統設計已經無法適應處理大數據的要求.內存計算方式的Spark采用了“統一內存管理”模型,將存儲系統化分為Spark層、JVM層、操作系統(OS)層和硬件層,完成數據的傳輸、元數據的管理,以及內存和磁盤等硬件的數據管理.層次化的存儲系統給設計和維護帶來了便利.然而,上層應用程序對系統內存、磁盤、CPU、網絡等資源敏感,需要底層優化以達到性能最優.因此理解底層系統行為與上層應用特征之間的關系,對于優化系統性能十分有意義,而此時層次化設計中底層對上層透明的工作方式給系統優化帶來了困難.例如,位于硬件和軟件交界面的操作系統從應用層角度常被作為黑盒對待,豐富靈活的系統配置參數對普通用戶難以準確理解和使用,進而導致其對上層應用程序的影響不得而知,陷入“不知道”與“不使用”的循環.因此,跨層的理解Spark系統的行為是十分重要且必要的.然而,計算機體系結構中“高內聚、低耦合”的分層設計,使得Spark系統中跨層的分析存在4個挑戰:
1) 在Spark系統中,Spark應用層、JVM層和OS層每一層都有自己的內存管理機制和本層特有的語義.從圖1 Spark系統中各層內存對象的語義及各層語義轉換流程可以看出,每層的語義對外暴露較少,因此如何在不破壞其原有工作方式的同時獲取其內存對象是Spark分析的挑戰之一.
2) 現有的性能分析工具大多只工作在某一層,盡管我們可以在每一層利用各種工具來獲取程序行為、抓取性能指標,但無法將每一層的結果相互對應起來進行分析,Spark語義與底層動作脫離,在OS層分析Spark性能時如何感知Spark語義是Spark分析的挑戰之二.
3) OS層性能表現與上層應用程序特征并不是清晰可見的,我們在OS層觀測到的性能指標,除了體現Spark應用程序特征之外,還包含其他因素的影響,如Spark框架、JVM自身運行引發的開銷,如何排除邏輯上不相關的參數通過其他機制產生的間接影響是Spark分析和實驗的挑戰之三.
4) 物理存儲對上層應用的性能存在影響.當前數據中心里的商用服務器內存通常較大,很多已達到128 GB以上.在這類場景下,為了提高服務器內存訪問的吞吐率,通常采用多內存條結構,即多個內存條均勻地分布在多個CPU內存控制器上,盡可能地利用所有CPU的內存控制器.但在對上層類似Spark自己管理內存的應用,通常僅利用虛擬地址進行內存管理,無法感知底層的內存分布,容易造成NUMA架構下的內存訪問不均衡(CPU訪問非本地內存會有較大的時延;多CPU同時訪問同一個內存通道也有性能瓶頸),從而影響性能.并且上層應用對虛擬地址以外的內存地址無法感知,也沒有現有的工具建立Spark存儲對象的關聯關系,因此如何對Spark物理頁進行追蹤是性能分析工具需要解決的挑戰之四.
為了解決上述問題,本文設計了跨層的Spark內存追蹤工具SMTT(Spark memory tracing toolkit).SMTT垂直打通了Spark層、JVM層和OS層,將上層應用程序的語義與底層物理內存信息建立了聯系,從而有助于對應用程序的訪存行為進行跟蹤和分析.
在Spark運行期間,SMTT會在Spark應用層抓取到Spark應用程序對數據的訪問序列,并記錄每層的使用信息.SMTT針對Spark系統中特有的執行內存和存儲內存分別設計了不同的追蹤方案.對于執行內存,我們將RDD(resilient distributed datasets)與其對應的虛擬內存地址聯系起來.對于存儲內存,我們逐層剝去封裝數據的外層數據結構,獲取存放數據的真正虛擬地址,并將虛擬地址與數據在Spark應用層的語義對應起來,從而有效地分析Spark的分布式執行和RDD的存儲訪問等重要信息.
Spark一直處于快速發展之中,伴隨著頻繁的版本迭代,很多重要的特性也發生了變化.然而,目前為止,本文所關注的“統一內存管理”和“迭代計算”并未發生根本性的改變,因此,本文的研究方法對于較新版本的Spark仍有借鑒意義.SMTT能夠提供內存對象的各個層次對應關系,為系統優化提供支持,例如通過SMTT得到的物理頁存儲關系,能夠為基于NUMA感知的內存調度等優化策略提供指導,實現對分布式內存結構的高效利用,為Spark的性能分析和優化奠定了基礎.
1 相關工作
針對Spark和Hadoop的對比分析無論是從日志文件角度[7]、從頁排序和分類算法的角度,還是詞頻統計算法方面[8-9],結果都表明面向云負載,內存計算方式的Spark優于Hadoop.隨著Spark的廣泛應用,其性能優化問題成為研究人員普遍關注的熱點.Spark性能可以通過配置Spark參數、重構Spark應用代碼、優化JVM等手段,從調度與分區、內存存儲、網絡傳輸、序列化與壓縮等方面優化[4,10].然而,無論哪種優化方案,都需要首先對Spark行為特征進行分析.如基于Spark的彈性分布式數據集設計首先分析了Spark屏幕終端日志在迭代算法和迭代數據挖掘應用場景下的效率問題,觀察到內存數據管理和存放策略對性能的影響,從而提出了基于共享內存和粗粒度交易的容錯系統設計[11].將Spark應用程序運行的歷史數據建立成數據庫,根據對歷史數據的分析來自動化配置Spark參數,能夠大大降低調優的門檻,同時也使調優的效果變得更為可信[12].Spark SQL分析了應用層的API接口、基本操作行為和數據模型,并基于分析提出了新的Apach Spark集成模型[13].江濤等人分析了典型算法Spark實現的執行時間、每秒鐘磁盤讀寫次數、內存帶寬、內存頁訪問頻率等[6].現有性能分析工作對于我們認識Spark負載的性能特征具有很大的參考價值,但這些研究大多在系統單一層面開展,缺乏全面、有效和系統的分析方案以及分析工具.
當前,云服務器面臨著嚴峻的存儲墻問題,對訪存行為的分析和追蹤是優化存儲系統的重要基礎.現有的內存追蹤工具分別從操作系統層、應用層和硬件層展開分析.
1) 操作系統層分析工具.perf[14]是廣泛使用的系統性能分析工具,通過它應用程序可以利用PMU,tracepoint和內核中的特殊計數器來進行性能統計,但perf只能看到操作系統層面的行為,無法感知上層邏輯.Simics[15]和QEMU[16]等軟件模擬器能夠生成訪存蹤跡并評測存儲系統性能,但現有模擬器大多只能支持桌面應用,難以模擬Spark和Hadoop這類復雜系統的行為.HMTT可以跟蹤到物理內存的訪問軌跡和對應的程序語義[17-18].然而這里的“程序”僅限于OS層面的程序,無法感知Spark層的語義,如RDD、分區等,因此不適用于Spark的應用場景.
2) 應用層分析工具.Pin[19]和Valgrind[20]等二進制插樁工具能夠分析應用程序的虛擬地址,但難以對內核插樁,無法分析內核層面的信息.Spark UI[21]是針對Spark的應用層分析工具,可以跟蹤Spark的執行情況,同樣無法看到其引起的底層動作.由于Spark語義與底層動作的關聯缺失,無法完整地看到一個Spark程序執行的來龍去脈,更無法解釋什么樣的程序會引起什么樣的系統性能變化.應用層的分析工具都把操作系統看成了黑盒、忽略了它的可配置性,導致數以千計的內核參數并沒有發揮其該有的作用.
3) 硬件層分析工具.Awan等人通過雙端口服務器的硬件計數器分析了批處理和流處理負載的體系結構特征,發現了同時多線程、Cache預取和NUMA結構對于性能的影響[22].這類基于硬件計數器的方法只能看到系統中的一部分硬件事件,無法對所有訪存行為進行追蹤.
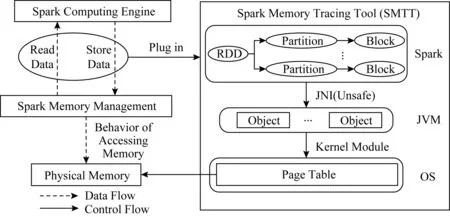
Fig.2 Framework of SMTT圖2 SMTT整體架構
針對上述單一層面分析工具的問題,本文設計了打通Spark,JVM,OS三層的內存跟蹤工具SMTT,以滿足跨層內存跟蹤的需要.SMTT從OS層對Spark應用程序進行性能分析,在不丟失Spark語義的情況下,分析Spark負載的行為特征與底層系統性能之間的關系,為Spark應用的調優提供依據.此外,SMTT在執行節點層對訪存進行追蹤,能夠為Spark Streaming[23]和Spark SQL[12]等上層框架提供細粒度的內存追蹤結果.
2 SMTT整體設計
內存計算是Spark的重要特征,即數據的存儲和處理都在內存之中.與JVM層一樣,Spark層也有著自己的內存管理機制.Spark層采用統一內存管理模型,將所管理的內存分為保留內存、用戶內存和Spark內存這3部分[24].保留內存由系統保留,對Spark應用程序是透明的,其中存放了許多Spark內部對象.用戶內存由Spark應用程序使用,比如:應用程序如果在內存中保留了大量用戶數據,那么將從這一部分中分配空間用于存儲.Spark在集群層次的主要工作是進行任務調度,其具體的對象級內存管理過程屬于節點級,主要體現在executor節點上的內存管理.因此,本文針對目標為Spark任務執行節點內存狀態進行追蹤,對應Spark整體集群的內存管理狀態,可以通過對單節點采集信息的聚合得到.Spark內存由Spark層進行管理,按照Spark的工作方式來存儲應用程序數據.Spark內存又分為存儲內存和執行內存2部分.其中,存儲內存用于存儲持久化的RDD數據、廣播變量等;執行內存用于存儲運行期間的中間數據,如洗牌過程中在映射端的緩存.
Spark所管理的內存可以來自JVM堆,也可以直接從操作系統獲得.對Spark應用進行性能分析時,Spark層、JVM層和OS層都有追蹤工具可以利用,但無法將各層追蹤到的結果建立聯系.例如,Spark層的評測系統可以看到被存儲的RDD以及它們的大小,但無法知道它們位于內存何處;JVM工具可以看到當前堆的狀態,卻無法知道堆內具體存儲什么數據對象,導致我們無法討論上層應用程序行為與系統性能的關系;OS層無法跨越JVM層將性能指標與Spark應用程序行為建立聯系,導致底層觀測丟失了Spark語義.盡管JVM層也有對象的創建、回收和復用機制,但Spark的數據有很大一部分不來源于JVM堆,對于這類數據JVM分析工具無能為力.SMTT將Spark語義延伸至硬件,整體架構如圖2所示.邏輯上Spark分為計算引擎和存儲系統2部分.計算引擎負責對數據的處理;存儲系統負責從底層(JVM或OS)獲取內存,對計算過程中的內存進行動態地分配和回收.代碼層面上,Spark存儲系統相對獨立,統一封裝對外的接口.計算引擎在執行過程中調用存儲系統的接口來分配和釋放內存.
SMTT首先在不破壞原有執行邏輯的情況下對這些接口進行了代碼插樁,獲取當前操作的數據信息、數據所在的數據結構和數據訪問序列.其中,代碼插樁只監聽Spark的數據結構,不改變其固有的接口與邏輯,因此在修改源碼和重新編譯后不影響Spark與其他組件,如Yarn和Flink等的集成.然后,SMTT分別對JVM堆內和堆外的數據進行處理,獲得虛擬地址:對于從JVM堆內獲取的內存,找到數據所對應的JVM對象,并將對象轉換為OS層的虛擬地址.對于從JVM堆外獲取的內存,SMTT找到起始地址,此時這個起始地址直接就是OS層的虛擬地址.最后,SMTT將虛擬地址轉換成物理地址,并獲得物理頁號、是否被交換到外存、所在NUMA節點等數據在物理硬件上的分布信息.經過這樣的流程,Spark數據在物理硬件上的分布一目了然,便于從性能的根源分析Spark應用程序的數據訪問特性與系統性能的關系.
SMTT按照數據被訪問的順序給出訪問序列,記錄Spark語義與底層地址信息的對應關系,其結果格式如圖3所示,包括:
1) 訪問時間.何時發起的本次訪問.
2) 訪問類型.對數據的訪問是讀還是寫.
3) Spark語義.被訪問數據在Spark應用層的意義,如所屬RDD和分區.
4) 虛擬地址.被訪問數據在OS中分配的虛擬地址.
5) 虛擬頁信息.被訪問數據屬于哪些虛擬頁、數據是否跨頁了、頁是在內存中還是被交換到了外存等影響性能的重要因素.
6) 物理地址.被訪問數據在物理內存中的地址.
7) 物理頁信息.被訪問數據所屬物理頁、物理頁的熱度,以及在NUMA系統中該物理頁是否跨節點等.
由于執行內存和存儲內存的用途不同、工作原理不同,它們在Spark源碼中的存取接口也完全不一樣.因此,SMTT針對這2種內存分別設計了追蹤方案.

Fig.3 Output formation of SMTT圖3 SMTT結果格式
2.1 執行內存追蹤方案
執行內存在Spark任務執行期間按需分配,例如,當數據需要排序、合并等整理操作時,系統會在執行內存中分配空間進行處理,使用之后立即釋放.
對于RDD中的每一個分區,Spark會啟動一個Task線程處理其中的數據.但是,Task只包含RDD信息,卻無法獲得該RDD內數據對應的虛擬內存地址;Sorter中包括虛擬內存地址,但無法獲得該地址中存放的數據所對應的RDD信息.為了打通各部分的語義,我們設計了如圖4所示的針對執行內存的追蹤方案,其中箭頭表示追蹤流程:
1) 在Task中,將所用Writer的Hash碼(Hashcode)和RDD信息傳給SMTT,SMTT將其寫入一張以Writer的Hash碼為鍵(key)、RDD信息為值(value)的Hash表;
2) 在Writer中,將所用Sorter的Hash碼和當前Writer的Hash碼傳給SMTT,SMTT將其寫入一張以Sorter的Hash碼為鍵、Writer的Hash碼為值的Hash表;
3) 在Sorter中,將當前Sorter的Hash碼,以及數據申請到的虛擬內存地址傳給SMTT;
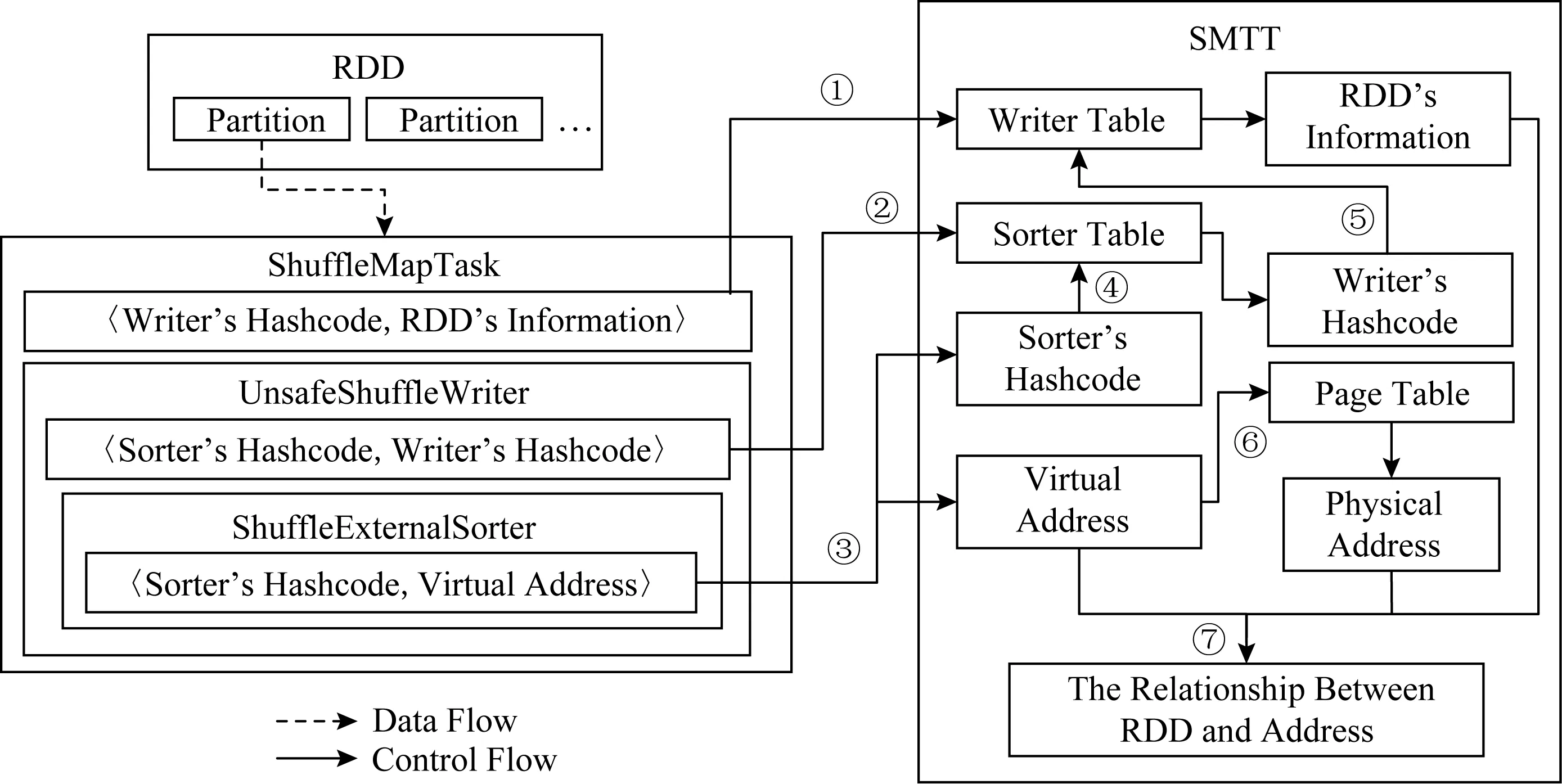
Fig.4 Tracing scheme of execution memory圖4 執行內存的追蹤方案
4) 根據Sorter的Hash碼找到Writer的Hash碼,根據Writer的Hash碼找到RDD信息;
5) 通過訪問OS頁表,根據傳進來的虛擬內存地址得到對應的物理內存信息;
6) 將RDD信息、虛擬地址、物理地址信息對應起來,作為一條記錄保存至文件.
7) 緩存中的數據和溢出文件中的數據會被合并到一個文件中.
通過上述步驟,我們將Spark應用層RDD的信息,同JVM層的信息,與底層物理內存信息聯系起來,獲得了一一對應的關系,實現了任意層觀測到的信息與其他層特征和行為之間的因果關系分析.
2.2 存儲內存追蹤方案
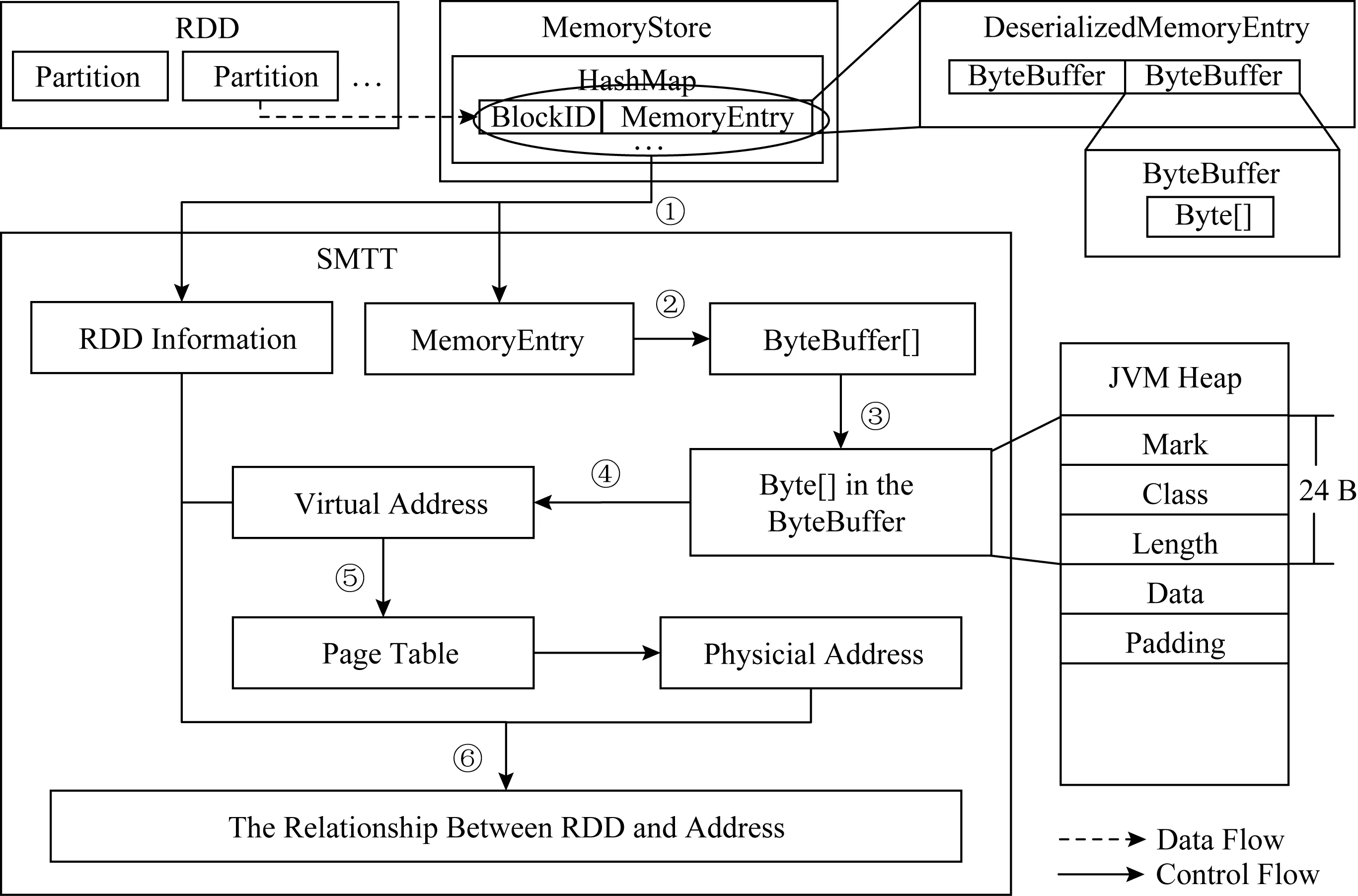
Fig.5 Tracing scheme of storage memory圖5 存儲內存的追蹤方案
Spark迭代計算節約了內存,但犧牲了時間.為了改善性能,Spark提供了緩存機制:被緩存在內存中的RDD數據,后續被訪問時可直接從內存中獲取,而無需從頭計算,緩存RDD的內存來自于存儲內存.對于持久化到內存中的RDD,Spark的Memory-Store對象提供了統一的存/取接口.其內部維護了一個以Spark的BlockID對象為鍵、以MemoryEntry對象為值的Hash表.其中BlockID對象的值就是RDD的ID與分區的ID按照特定格式的組合.MemoryEntry對象用于描述被存儲的數據,其內部有一個Java對象ByteBuffer數組,而每一個Byte-Buffer對象內部有一個存放數據的字節數組.
對于存儲內存的追蹤,我們主要解決的問題是如何逐層剝去封裝數據的外層數據結構,獲得虛擬地址,并將其與數據在Spark層的語義對應起來.對此,我們的設計方案如圖5所示,箭頭表示追蹤流程:
1) 在MemoryStore對象內部,當對Hash表進行存/取時,將此時的BlockID對象和MemoryEntry對象傳給SMTT;
2) SMTT獲取MemoryEntry對象的成員變量ByteBuffer數組;
3) 對于每一個ByteBuffer實例,通過Unsafe對象提供的接口獲取其中的成員變量字節數組在JVM堆中的起始地址;
4) 獲得字節數組內數據的起始地址,在不使用指針壓縮的情況下,數組在JVM堆中前24 B為頭信息,其后緊跟著數據,所以根據頭信息的長度獲得數據的虛擬地址,然后使用JNI技術直接訪問內存地址;
5) 通過訪問操作系統頁表,將虛擬地址轉換成物理地址;
6) 將傳入SMTT的RDD信息、數據虛擬地址信息、物理地址信息對應起來,保存至文件.
通過上述步驟,完成了存儲內存中不同層語義之間的關聯,為訪存行為分析建立了通路.
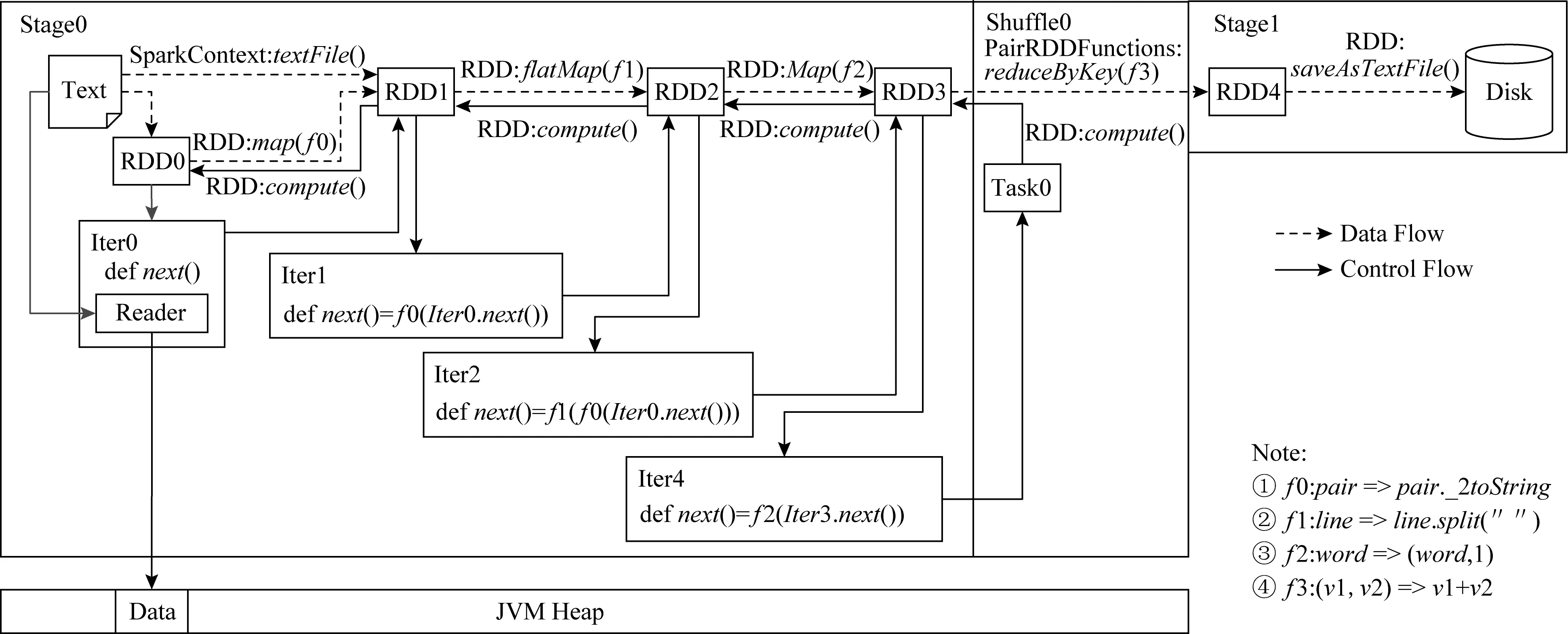
Fig.6 Distributed computing process of Spark for word count algorithm圖6 詞頻統計算法中Spark分布式計算的過程
3 基于SMTT的訪存行為分析
SMTT給出了跨層的追蹤方式,建立了不同層的語義.本節借助于SMTT工具對Spark的迭代計算過程中內存的訪問過程,以及執行內存和存儲內存的使用過程進行詳細的跟蹤,解釋了Spark中RDD的數據對象從應用層開始,經JVM層和OS層對應到物理內存的流程.
3.1 Spark計算過程追蹤
本節以統計詞頻的Spark應用程序為例,分析其分布式計算的完整過程.如圖6所示,一個RDD訪問完整過程可視為一個有向無環圖,分成2個階段:第1個階段Stage0完成Shuffle寫,即Map映射;第2個階段Stage1完成Shuffle讀,即Reduce化簡.每個階段的執行起點是當前階段的最后一個RDD,這個RDD的每一個分區會交給一個Spark創建的獨立Task線程進行處理.Task會調用最后一個RDD(即RDD3)的iterator()方法獲得其負責處理的分區數據的迭代器,在RDD沒有被持久化的情況下,這個iterator()方法會調用當前RDD的compute()方法.這樣一直遞歸調用到第1個RDD(即RDD0)的compute()方法,這時的compute()會返回一個文本數據的迭代器給它的下一個RDD(即RDD1),下一個RDD會新創建一個迭代器對象Iter1,并重寫其中的next()方法,用自身生成時的轉換函數f0包裝前一個RDD傳過來的迭代器Iter0的next()方法,然后將這個新創建的迭代器返回給它的下一個RDD;它的下一個RDD還會采取相同的操作,一直到最后一個RDD(即RDD3)的compute()返回給Task.此時Task拿到迭代器之后,每調用一次next()方法,就會從文件系統讀取一條記錄并經過逐層轉換函數的加工返回給它.
值得注意的是,第1個RDD從文件系統中讀取數據的時候使用了一塊緩存,即圖6中JVM堆中的Data部分,這塊緩存在迭代器后續的數據讀取過程中是被重復使用的.從上述的迭代過程可以看出,如果不做持久化,RDD的數據是不會全部存在內存中.這就解釋了,盡管一個Task需要處理大量的數據,但其實際內存占用量并不大的原因.有效的復用提高了存儲空間的利用率.
3.2 執行內存使用過程追蹤
在Spark中執行內存通常在洗牌過程以Unsafe方式、Sort方式或Bypass方式使用.圖7描述了使用SMTT工具對Unsafe方式和Sort方式的工作過程進行追蹤的過程,其中①~⑦表示當前任務通過迭代計算獲取它所負責分區的數據迭代器,然后將數據逐條寫到執行內存分配的緩存空間中,然后進行排序、合并等操作.每向緩存中插入一條記錄,當前任務都需要判斷緩存是否夠大,如果不夠則通過acquirExecutionMemory()方法向Spark申請新的執行內存空間,如圖7中的步驟⑧⑨所示.寫緩存期間,如果所占內存超過一定閾值,當前任務便將數據寫回到硬盤文件,這個過程稱為溢出(Spill).最后,步驟⑩緩存中的數據和溢出文件中的數據會被合并到一個文件中以供Stage2讀取.對于Bypass方式,與Unsafe方式和Sort方式不同之處在于,不將數據寫到緩存,而是直接寫到硬盤文件.
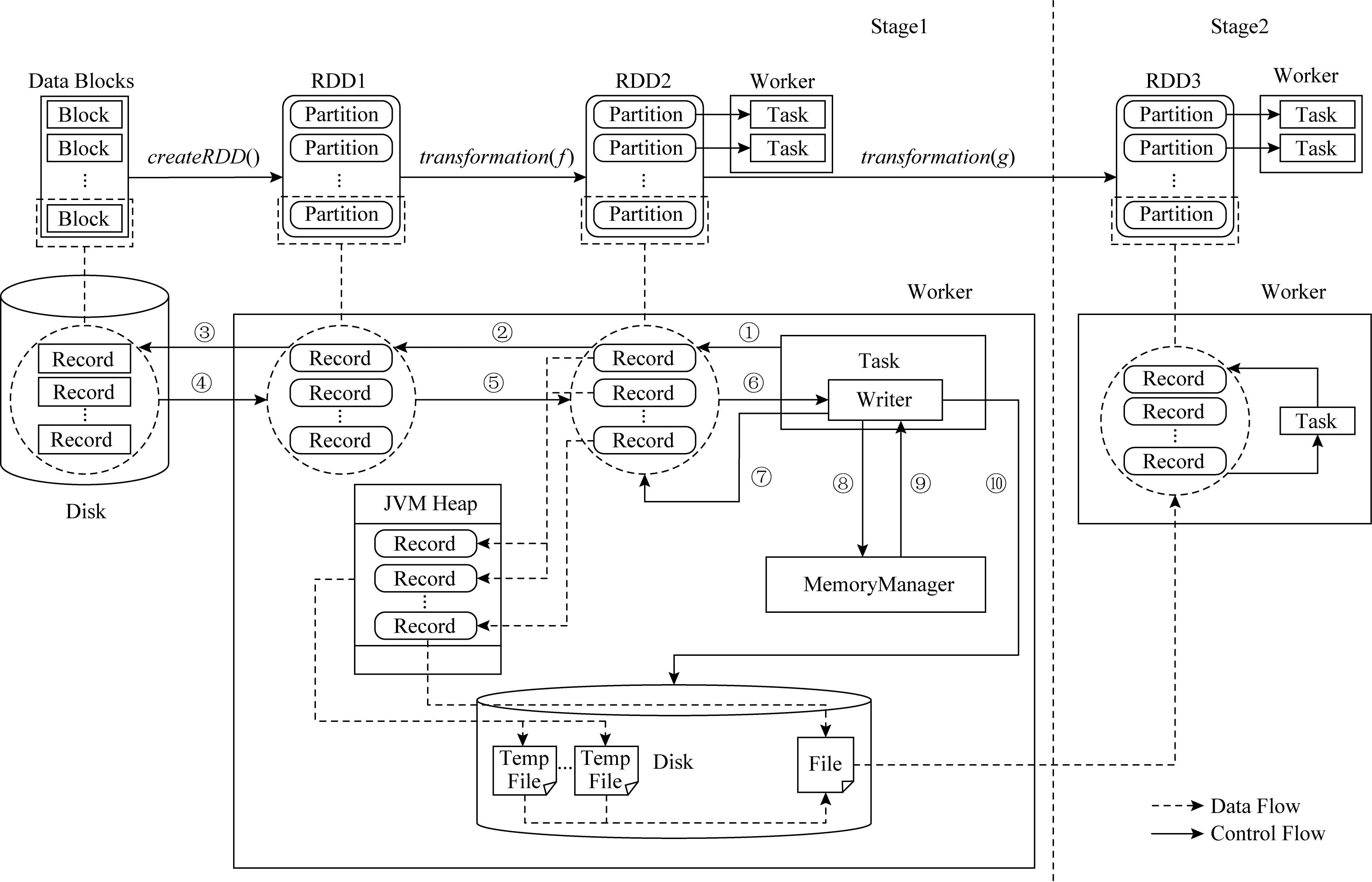
Fig.7 Memory access process of execution memory in Unsafe mode and Sort mode圖7 Unsafe和Sort方式中執行內存使用過程
3.3 存儲內存使用過程追蹤
我們使用SMTT對Spark中存儲內存的使用方式進行了追蹤和分析,如圖8的步驟①~表示Task遞歸獲取迭代器的過程.存儲內存的使用過程跟執行內存相似,區別是從步驟⑦開始,被存儲的RDD(RDD2)的迭代器不返回給它的下一個RDD,而是交給BlockManager對象.隨后,BlockManager對象使用獲得的迭代器將數據逐條存入到內存.每向內存中寫入一條記錄,Task都會檢查內存是否夠用,如果不夠則通過acquirStorageMemory()方法向Spark申請新的存儲內存空間.在全部數據寫入內存之后,被持久化的RDD會創建一個遍歷這塊內存的迭代器并返回給下一個RDD,從而完成Task遞歸地獲取迭代器的過程.由此可見,訪問持久化的RDD數據實際上訪問的是內存的某一段空間.
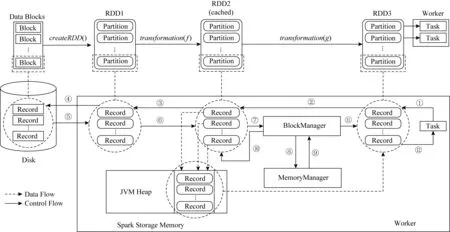
Fig.8 Memory access process of storage memory圖8 存儲內存使用過程
存儲內存除了存放持久化的RDD數據之外,還存放反序列化過程中“unroll”過程的數據,以及用于全局的廣播變量等.無論何種數據,存儲內存同執行內存一樣,既可以從堆上分配,也可以從堆外分配,返回的都是連續的地址空間,從而保證了當前線程訪存的局部性.
4 實驗評測
4.1 實驗環境
本文采用如圖9所示的Spark運行模式,主要組件包括:1個驅動器節點、1個主節點、多個從節點.其中,1個主節點和多個從節點組成集群,主節點用于管理計算資源,而從節點用于執行具體的計算;驅動器節點位于應用程序端,負責向集群提交任務.
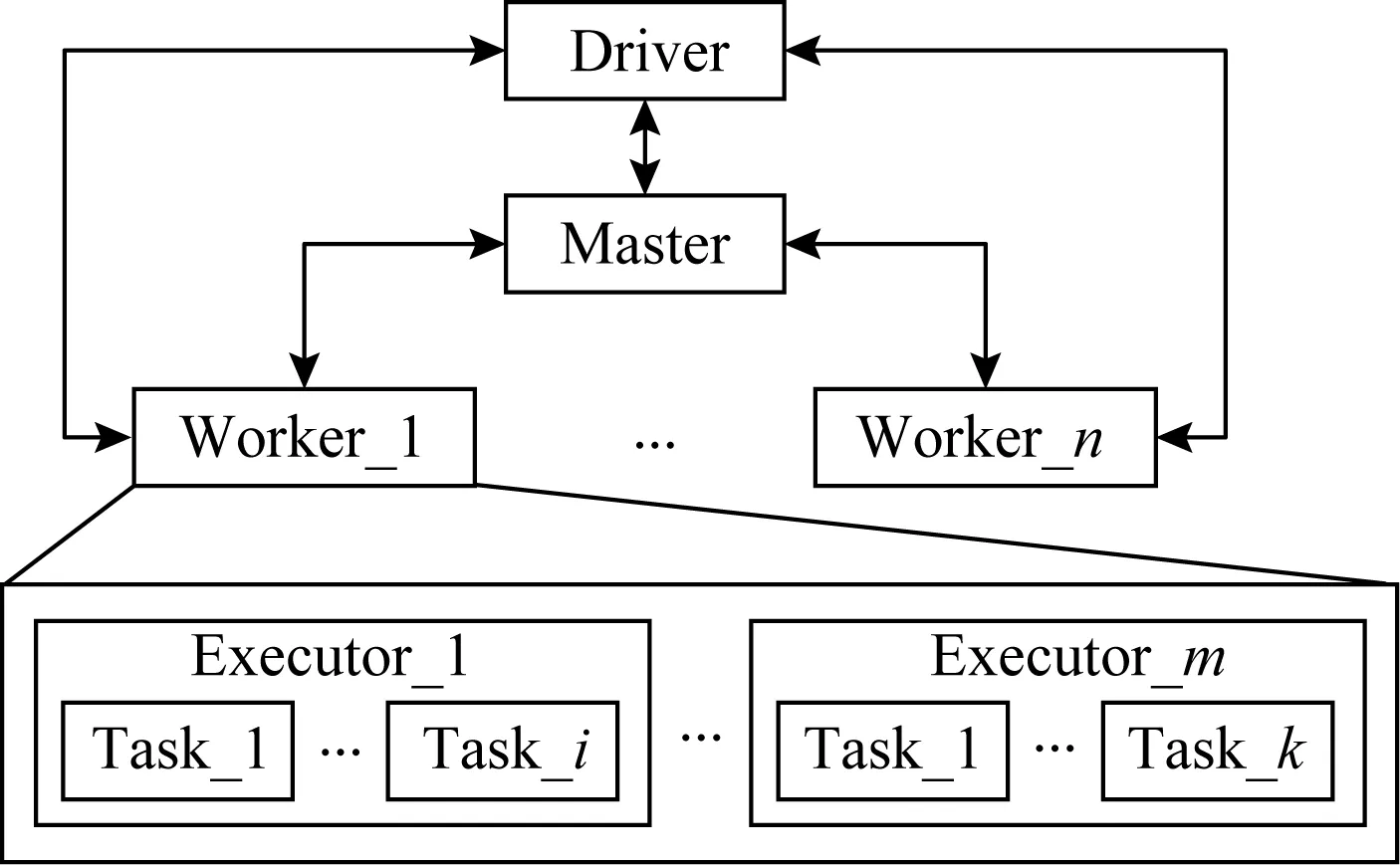
Fig.9 The development model of Spark圖9 Spark部署模型
在實際的生產環境中,集群的情況往往比較復雜.首先,同一個物理集群上運行的除了Spark,可能還有HDFS,Yarn,Presto等其他分布式程序;其次,針對不同的需求,集群的規模可能從幾臺到幾千臺不等;此外,對于不同的業務,運行在集群上的應用程序也多種多樣.然而,優化Spark的前提是對Spark自身原理和特性的分析和理解,為了避免復雜環境的影響,本文的實驗將焦點聚集在Spark本身.考慮到計算節點的訪存行為是由Spark本身決定的,不受集群規模影響,因此本文選擇了代表Spark的Standalone部署模式的實驗環境,采用3臺物理機組成HDFS集群和Spark集群,為避免相互干擾進而使觀測和分析變得復雜,本文將HDFS集群和Spark集群的工作節點盡量分開,物理機的角色如表1所示:

Table 1 The role of Physical Machines表1 實驗所用物理機角色
每臺物理機有2個Intel?Xeon?E5620CPU和32 GB物理內存;每個CPU主頻為2.4 GHz,包含4個Core,每個Core支持雙線程.CPU采用IA32e模式,支持4 KB,2 MB和1 GB大小的頁.
為了更好地評測大數據處理程序的性能,很多基準測試程序應運而生,常用的有BigDataBench[25],CloudSuite[26],SparkBench[27]等.Spark擁有活躍的社區,貢獻著各種類型的計算模型,目前提供4種類型的應用:機器學習、SQL查詢、圖計算、流計算[28-29].表2列出了本文中所用的SparkBench的負載程序及輸入大小.本文基于這4種類型的應用,以讀寫RDD的評測結果為例,評測借助SMTT追蹤分析不同程序的不同特征的效果.
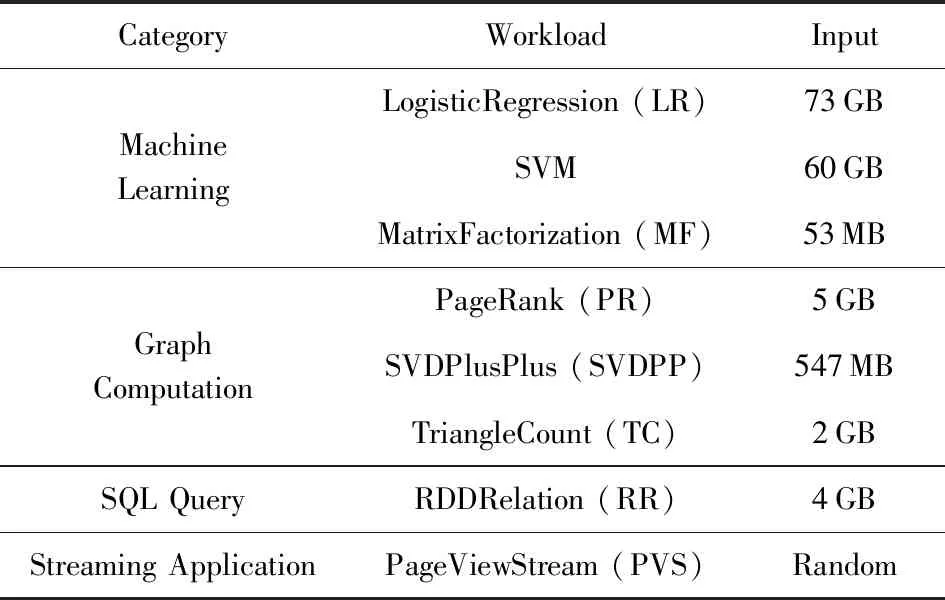
Table 2 Description and Input of Workloads表2 實驗負載及輸入
4.2 實驗結果
我們追蹤了每一個Spark負載中RDD的讀寫開銷情況,由于不同負載業務類型不同,因此在RDD訪問方面也呈現出不同的特性,這個特性與負載的具體程序實現方式緊密相關.
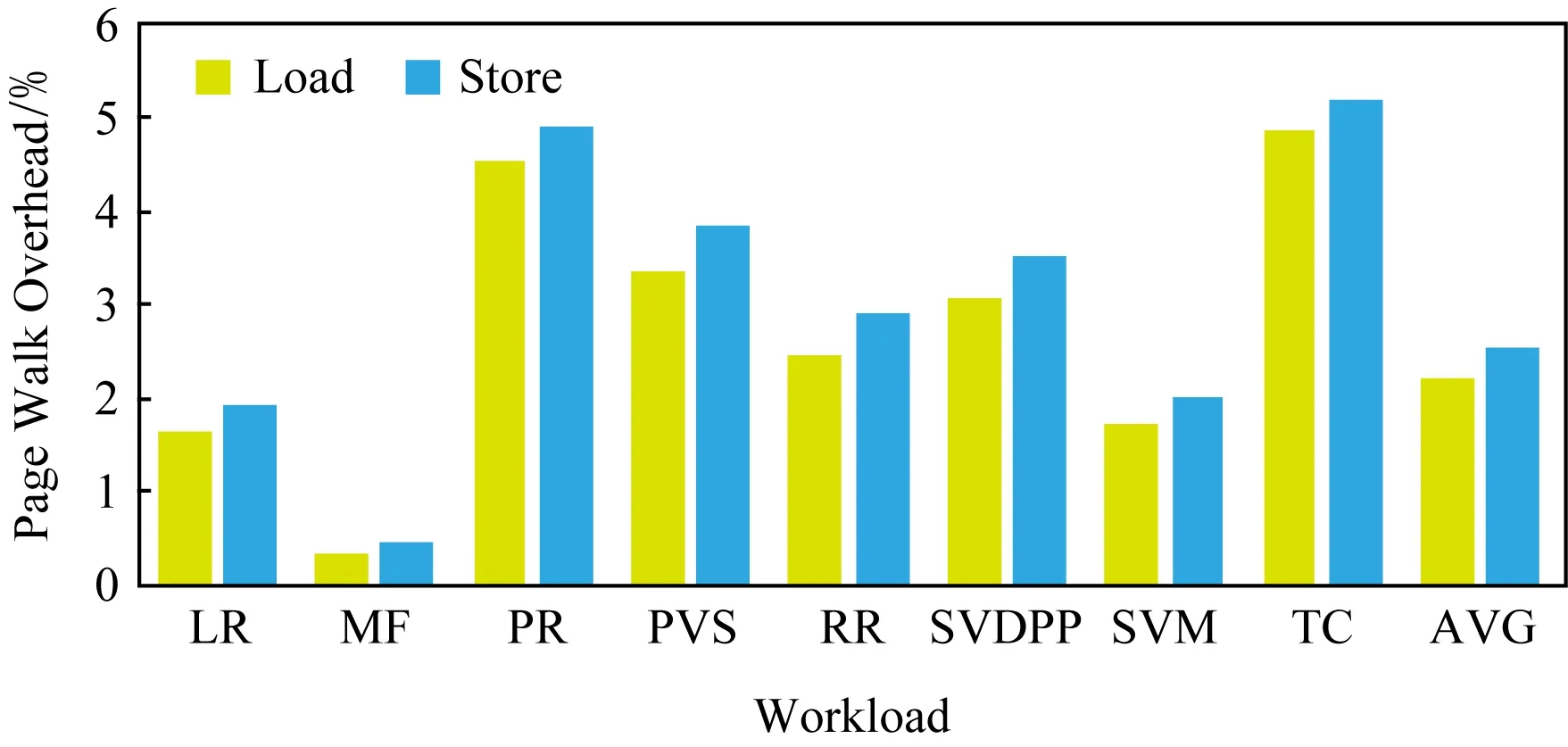
Fig.10 Page walk overhead of RDD of single node mode圖10 單節點RDD訪問引發的頁遍歷開銷
圖10顯示在只有一個主節點和一個從節點的單節點集群上RDD引發的頁遍歷讀寫操作占比.RDD的讀操作比例平均為2.20%,寫操作比例平均為2.55%,平均有4.75%的周期用于RDD訪問.其中,應用程序TC的比例最大:讀操作比例為4.87%、寫操作為5.21%,累計占到總執行周期的10.08%.PR和TC相似,讀操作占4.55%、寫操作占4.91%,總共有9.46%的周期在進行RDD讀寫.此外,PVS讀寫占比7.22%、RR讀寫占比6.59%、RR讀寫占比5.38%,也都高于平均開銷.比例最低的負載為MF,讀操作比例為0.34%、寫操作比例為0.46%,總共花費的執行周期為0.80%.而LR讀操作為1.63%、寫操作為1.91%,SVM讀操作為1.72%、寫操作為2.03%,這2個負載雖然讀寫比例也低于平均值,但其所占總執行周期的比例分別為3.54%和3.75%,相對居中.
由圖10可得結論:寫操作開銷略高于讀操作開銷,這是因為RDD被設計為只讀的,常用的RDD會被持久化到內存中,此后可以多次重復讀取,但是“寫”只有一次,即它被創建的時候.
圖11給出了基于SMTT獲得的1個主節點、2個從節點的多節點集群上各Spark負載由RDD訪問所花費的周期占總執行周期的比例.平均情況,讀操作所占周期比例為2.15%、寫操作所占周期比例為2.52%,所以總的RDD讀寫周期比例為4.67%.首先,開銷較大的負載為:TC操作為5.29%、寫操作為5.61%,PR讀操作為4.18%、寫操作為4.55%,SVDPP讀操作為3.49%、寫操作為3.96%,總的周期比例分別為10.90%,8.73%,7.45%.其次,開銷居中的是PVS讀操作為2.49%、寫操作為2.93%,RR讀操作為2.27%、寫操作為2.67%,SVM讀操作為1.74%、寫操作為2.08%,LR讀操作為1.57%、讀操作為1.90%,所耗周期比例分別為5.42%,4.94%,3.82%,3.47%.最后,MF的開銷最小,讀操作為0.38%、寫操作為0.53%,總比例僅為0.91%.
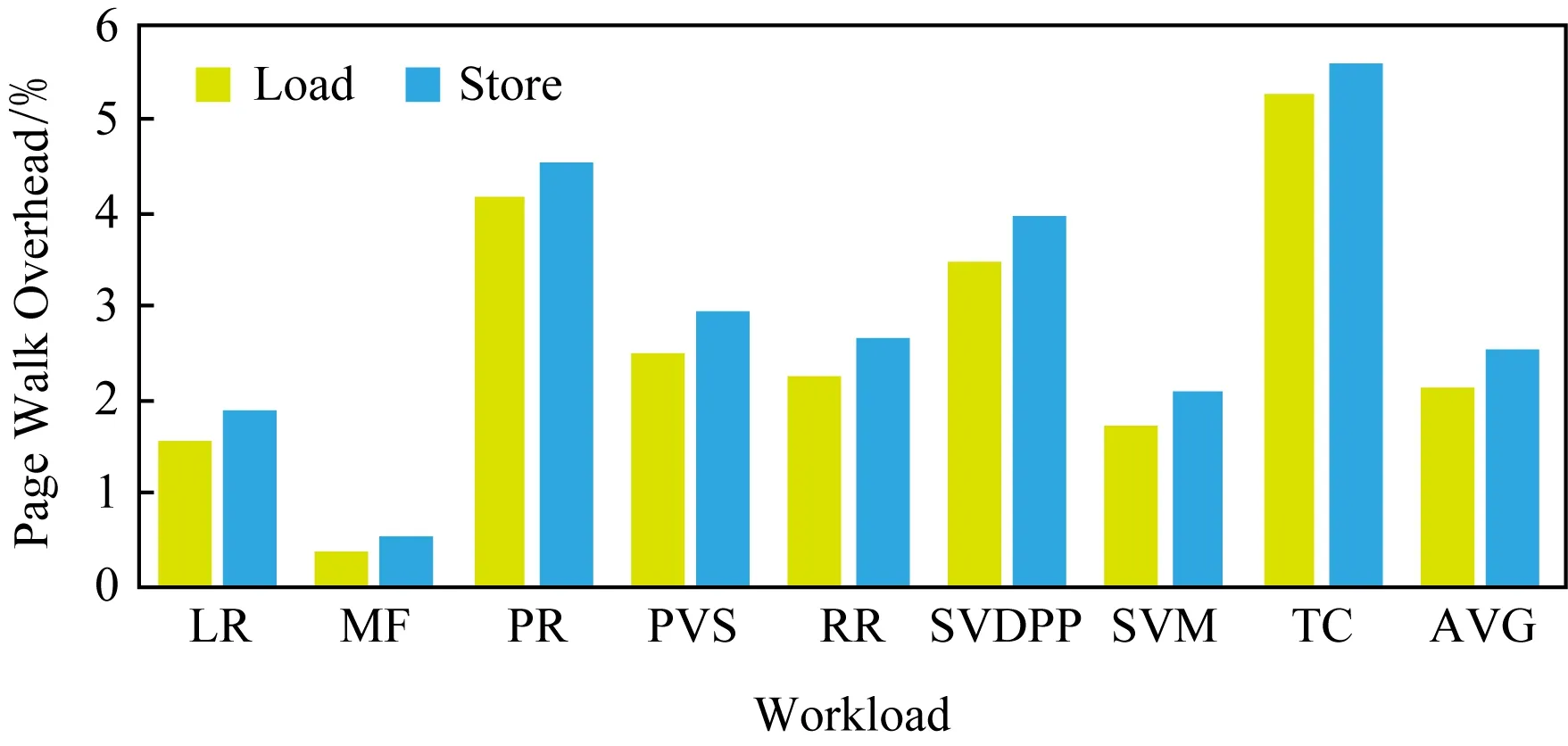
Fig.11 Page walk overhead of RDD of multiple node mode圖11 多節點RDD訪問引發的頁遍歷開銷
由圖11可得結論:無論是單節點還是多節點,Spark訪存引發的頁遍歷開銷普遍較低,這主要是因為Spark迭代計算、連續分配執行內存和存儲內存的設計.迭代計算使程序讀取初始數據時盡可能復用內存,從而減少內存占用.并且Spark每次從執行內存和存儲內存中都分配連續的空間,保證了程序訪存的局部性,保持了較高的TLB命中率和較低的頁表遍歷開銷.
單節點和多節點情況下不同負載RDD所占內存比例如圖12所示,不同負載的內存占用率差別較大.單節點時,內存使用率的平均值為40.74%.其中,LR使用率為80.10%,SVM使用率為76.55%,SVDPP使用率為71.32%,TC使用率為71.17%,相對較高.PR使用率為56.52%,RR使用率為35.52%,接近平均值.而PVS使用率為13.91%,MF使用率為8.73%,遠遠低于平均值.
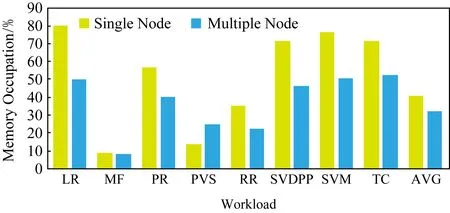
Fig.12 Memory occupation of RDD圖12 單節點和多節點下RDD內存占用率
多節點時,內存占用率普遍不高,平均值為32.01%.其中,TC使用率為52.51%,SVM使用率為50.80%,LR使用率為49.73%,SVDPP使用率為46.17%,PR使用率為40.47%,相對較高.PVS使用率為24.58%,RR使用率為22.12%,MF使用率為8.17%,內存利用率最低.
結論1.各負載的RDD內存占用率差別較大,其中,LR,SVM,SVDPP,TC內存占用率較高,PR,RR,PVS內存占用率較低,MF內存占用率最低.
結論2.相比單節點集群,多節點內存利用率較低.
結論3.PVS負載在單節點和多節點情況下的行為差異最大.
5 結論與展望
本文針對大數據計算環境下Spark底層行為與上層應用程序特征之間的關聯缺失問題,設計了SMTT工具,打通了Spark層、JVM層和OS層,實現了上層應用程序的語義與底層物理內存信息的對應.針對Spark內存計算的特點,分別針對執行內存和存儲內存設計了不同的追蹤方案.本文使用SMTT分析了內存使用方式,并分析不同負載用于RDD讀/寫的開銷和內存占用情況,結果顯示本文所設計的工具能夠有效支持Spark的存儲系統分析,為Spark的性能優化奠定了基礎.
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
開放教育研究(2020年2期)2020-03-31 01:54:14
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
