基于暗通道先驗與YOLO的水下河蟹識別研究
2020-06-22 13:15:56賀帆趙德安
軟件導刊 2020年5期
賀帆 趙德安


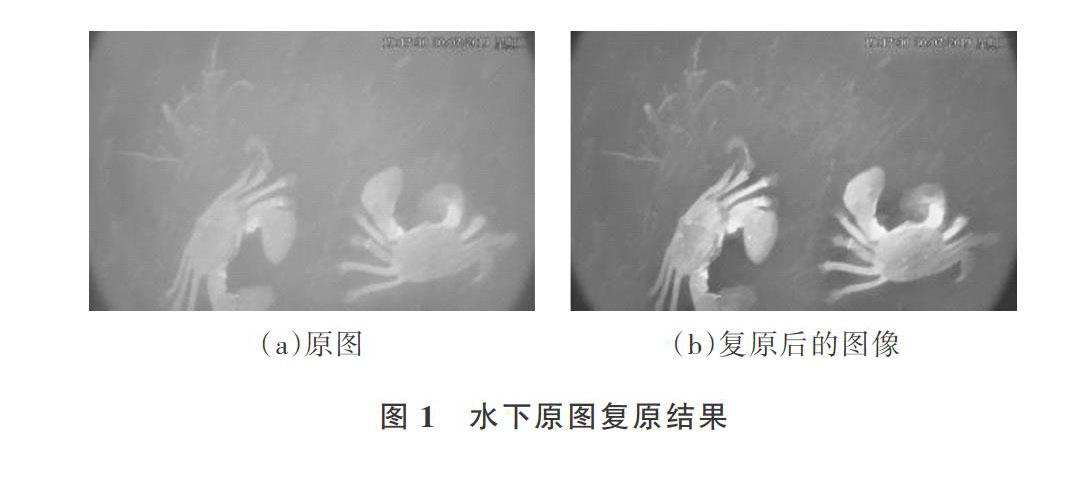
摘 要:為解決全自動均勻投餌作業船在河蟹養殖過程中投餌不精準問題,引入水下攝像設備采集圖像,但采集的圖像存在對比度低、模糊和圖像退化等問題。為此,采用暗通道先驗提高圖像對比度。利用YOLO卷積神經網絡技術快速準確地識別出低照度環境下的河蟹,識別準確率達到98%,平均耗時50ms。獲得河蟹生長、分布信息后測算出河蟹養殖密度,為全自動均勻投餌作業船精準投飼提供數據支持。
關鍵詞:圖像退化;暗通道先驗;河蟹識別;卷積神經網絡;YOLO
DOI:10. 11907/rjdk. 191919 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP301文獻標識碼:A 文章編號:1672-7800(2020)005-0029-04
0 引言
水下圖像通常表現為能見度有限、低對比度、光線不均勻以及噪聲模糊等。河蟹養殖以蟹塘養殖為主,受限于蟹塘客觀環境以及采集設備硬件限制,難以獲得清晰的水下圖像。
水下圖像在成像時,由于光線在水中傳播,不同光譜波長的光呈現不同的指數衰減,波長最長的可見光最先被吸收。紅光水下傳輸1m,其光強值就會減少2/3并在4~5m后基本消失。與其它波長光相比,藍紫光最后被吸收。
傳統的目標檢測算法通常分為區域選擇、提取候選區域特征、輸入分類器訓練分類幾個步驟。Dalai等[1]提出梯度方向直方圖(Histograms of Oriented Gradient,HOG)特征,經線性支持向量機(support vector machine,SVM)訓練分類進行行人檢測;FELZENSZWALB等[2-3]提出一種多尺度可變部件模型(deformable parts model,DPM)進行目標識別。傳統目標檢測算法中,手工設計的特征匹配主要是顏色、形狀輪廓特征,由于水下河蟹圖像對比度低、圖像模糊以及紋理特征不明顯等,導致河蟹識別效果不理想。
水下成像和戶外大氣霧霾相似,He等[4]提出基于大量戶外清晰圖像統計得出的暗通道先驗(DCP)廣泛應用于水下圖像復原研究。針對水下河蟹圖像低對比度、噪聲嚴重、模糊難以識別的問題,本文提出基于暗通道先驗和深度學習相結合的方法進行水下河蟹圖像復原和識別。該方法考慮了水下環境不同光譜波長吸收存在差異的情況,有效提高圖像對比度,減少噪聲影響;將深度學習應用于河蟹養殖,在蟹塘復雜的水下快速準確識別河蟹,獲得河蟹生長、分布信息,為全自動作業船精準投飼提供數據支持。
1 水下圖像成像模型
水下圖像復原方法主要考慮水下圖像的成像機制,并建立有效的水下圖像退化模型,通過物理模型和先驗知識推導復原參數,最終反演出復原后的圖像。根據Jaffe-McGlamery[5-6]提出的成像模型,圖像由3部分分量線性疊加:①直接照明部分:不受介質散射光到達成像設備部分;②前向散射分量:代表散射的直接分量;③后向散射分量:表示從所有觀察到的外部場景散射的光信息。見式(1)。
[J(x)]分量表示未經傳輸介質退化的原始圖像,圖像受傳輸介質影響按距離指數衰減。[B∞(1-e-cz(x))]表示隨著目標與成像平面距離增大而增大的附加退化分量,常量[B∞]是促使后向散射效果的水色表示。
此模型與描述大氣霧霾退化模型相似,但是在其它方面仍有很多區別。從水下環境成分的生物化學特性可知,水下各個光譜波長的光吸收差異顯著。
2 水下圖像復原
2.1 暗通道先驗
He得出的暗通道先驗(DCP)結論為:在絕大多數非天空的局部區域存在著一些像素,其中至少有一個顏色通道的數值很小,即其光照值是一個很小的數,趨近于0。但是,DCP不能直接應用于水下環境。隨著水下目標深度的加大,大部分波長的光會被吸收。
由于水介質對光的選擇性吸收,所獲得的水下模糊圖像主要由波長較小的B、G通道表示,缺少衰減嚴重的R通道信息。依靠圖像中的RGB表示,具有較大R、G、B值并不一定代表具有大的波長值,但是可以補償在水下衰減的光信息量。因此,本文采用式(3)的方式估計暗通道。
其中,[Ω(x)]表示局部以x為中心的局部區域,本文引入R通道的補集(invR),由1-R計算得到。基于DCP及其變形應用方法很多。Chiang等[7]直接使用DCP結論,在水下環境增加了深度信息;Bianco等[8]考慮水下圖像中紅色分量與藍綠分量水下吸收的顯著差異,提出最大像素先驗(Maximum Intensity Prior,MIP)。
2.2 傳輸介質透射率
根據式(2),將透射率定義為目標到成像平面距離的指數函數,用以描述某一點的模糊程度。透射率由式(4)表示。
2.3 透射率細化
引導濾波[9]與軟摳圖相比,最大的優點在于時間復雜度低、運算速度快。根據輸出圖像[qi]和引導圖像[I]之間的局部線性關系式(9)可得:
當透射率[t(x)]很小時[J(x)會]偏大,將導致恢復圖像整體向白場過渡,因此需要引入一個合理的閾值[t0]。當[t(x) 3 基于YOLO的河蟹檢測 3.1 YOLOv3網絡 與使用滑動分類器CNN[10]網絡結構相比,YOLOv3[11-13]是可以同時預測目標位置、大小以及類別的統一網絡。YOLOv3由53個卷積層組成,每個卷積層后都會增加BN層和Leaky ReLU層約束輸出參數。該網絡采用類似Inception Net[14]的機構,使用大量3×3卷積層并在卷積層之間插入1×1卷積層壓縮特征。本文采用以Darknet-53 為基礎改進的輕量級網絡模型,13層網絡結構如圖2所示。 經過訓練的網絡模型在河蟹檢測過程中會選取合適的候選區域,并對這些候選區域進行預測,最后對預測結果進行篩選,得到置信度較高的預測框。置信度公式(12)如下: 3.2 模型訓練與評估 本文選擇13層卷積網絡訓練模型,采用自制的水下河蟹數據集進行訓練。訓練參數為:動量系數0.9,權重衰減系數為0.000 5;訓練迭代20 000次,迭代0~15 000時,學習率取0.001;迭代15 000~18 000時,學習率取0.000 1;迭代18 000~20 000時,學習率取0.000 01。 訓練過程中,網絡每迭代500次輸出一個網絡模型。根據制作的驗證集評估每個網絡模型的mAP。隨著網絡迭代的增加,網絡模型趨于穩定,選擇最高的mAP模型作為最終測試模型。mAP評估結果如圖3所示。 圖3中橫坐標為每迭代500次輸出的模型序數,縱坐標為相應的mAP值。從圖中可以看出,網絡迭代12 000(24×500)次之后,其mAP值已基本穩定。網絡輸出模型中最大的mAP值為90.53%,因此選擇該模型作為本文所用預測模型。 對于所選的最終河蟹識別預測模型,還需調節網絡測試模型的閾值參數。不同的閾值參數在識別過程中得到不同的精確率、召回率和F1值。不同參數指標如圖4所示。 4 實驗結果與分析 4.1 河蟹識別結果 采用從蟹塘采集的80幅水下河蟹圖像進行識別,用時4s,平均每幅圖像用時50ms。圖5顯示河蟹識別效果,沒有出現漏檢、誤檢錯誤,較好滿足了實時性和識別準確率要求。 4.2 與傳統方法對比 本文對相同數據集采用基于滑動窗口HOG+SVM的方法訓練,并對水下攝像頭采集的河蟹圖像進行對比實驗,對比測試結果如表2所示。 通過對比可知,基于13層卷積網絡的檢測方法與基于滑動窗口HOG+SVM檢測方法相比較,不論在檢測精度上還是在檢測速度上都有顯著提升,滿足全自動均勻投餌作業船技術要求。 5 結語 水下河蟹圖像紋理特征不明顯,河蟹形狀姿態各異,基于紋理、顏色和形狀特征的目標檢測算法在識別精度方面并不理想。 本文提出了基于暗通道先驗和深度學習的水下河蟹識別方法。針對不同光譜波長色光在水下吸收的差異,以及水下河蟹圖像存在對比度低、退化嚴重和模糊的現象,結合暗通道先驗原理,增強圖像對比度。引入卷積神經網絡模型,能夠快速準確識別水下河蟹,獲得河蟹大小、數量及分布信息。 卷積神經網絡識別精度及泛化能力取決于龐大的數據集。為提升網絡泛化能力,后續研究需采集更多訓練樣本,完善網絡模型,實現全自動均勻投餌作業船更精準投餌。 參考文獻: [1] DALAI N,TRIGGS B. Histograms of oriented gradients for human detection[C]. IEEE Computer Society Conferenceon Computer Vision and Pattern Recognition,2005(1):886-893. [2] FELZENSZWALB P, MCALLESTER D, RAMANAND. A discriminatively trained, multiscale,deformable part model[C]. Boston:Computer Vision and Pattern Recognition,2008:1-8. [3] FELZENSZWALB P,GIRSHICK R B,MCALLESTERD,et al. Object detection with discriminatively trained part-based models[J]. IEEE Transactionson Pattern Analysis and Machine Intelligence,2010,32(9):1627-1645. [4] HE K M,SUN J,TANG X. Single image haze removal using dark channel prior[J]. ?IEEE Transactions on Pattern Analysis and Machine ntelligence,2011,33(12):2341-2353. [5] JAFFE J S. Computer modeling and the design of optimal underwater imaging systems[J]. Oceanic Engineering,IEEE Journal,1990,15(2):101-111. [6] MCGLAMERY B. A computer model for underwater camera systems[C]. ?Proceedings of SPIE 0208, Ocean Optics VI,1980:221-231. [7] CHIANG J Y,CHEN Y C. Underwater image enhancement by wavelength compensation and dehazing[J]. Image Processing, IEEE Transactionson,2012,21(4): 1756-1769. [8] HE K.Guided image filtering (matlab code)[EB/OL]. ?http://research.microsoft.com/en-us/um/people/kahe/. [9] KRIZHEVSKY A,SUTSKEVER L,HINTON G E.ImageNet classification with deep eonvolutional neural networks[C]. Advances inneural information processing systems,2012:1097-1105. [10] REDMON J,DIVVALA S,GIRSHICK R,et al. You only look once:unified,real time object detection[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:779-788. [11] REDMON J,FARHADI A. YOL09000:better,faster,stronger[C]. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,2017:6517-6525. [12] REDMON J, FARHADI A. YOLOv3:an incremental im.provement[DB/OL]. https://arxiv.org/abs/1804.02767. [13] SZEGEDY C,IOFFE S,VANHOUCKE V,et al. Inception-v4,inception-resnet and the impact of residual connections on learning[EB/OL]. https://blog.csdn.net/kangroger/article/details/69488642. [14] HE K M,ZHANG X Y,REN S Q,et al. Deep residual learning for image recognition[C]. Proceedings o f the ?IEEE Conference on Com puter V ision and Pattern Recognition ,Las Vegas,NV,USA:IEEE,2016:770-778. [15] 魏湧明,全吉成,侯宇青陽. 基于YOLO_v2 的無人機航拍圖像定位研究[J]. ?激光與光電子學進展,2017,54(11): 95-104. [16] 王宇寧,龐智恒,袁德明. 基于YOLO 算法的車輛實時檢測[J]. ?武漢理工大學學報,2016,38(10):41-46. [17] 楊愛萍,鄭 佳,王 建,等. 基于顏色失真去除與暗通道先驗的水下圖像復原[J]. 電子與信息學報,2015,37(11):2541-2547. [18] 劉海波,楊杰,吳正平. 等. 基于暗通道先驗和Retinex理論的快速單幅圖像去霧方法[J]. 自動化學報,2015 (7):1264-1273. (責任編輯:杜能鋼)
