2020年洞庭湖特大洪水分析
2022-11-23 05:49:24劉海
水利水電快報 2022年8期
劉 海
(湖南省岳陽水文水資源勘測中心,湖南 岳陽 414000)
0 引 言
洞庭湖古稱云夢,為中國第二大淡水湖,湖盆周長為803.2 km,總容積220億m3,包括178億m3的天然湖泊容積和42億m3河道容積。洞庭湖北邊通過藕池、松滋、太平、調弦(1958年堵口建閘)四口與長江相連,南邊承接著湘水、資水、沅水、澧水(簡稱“四水”)等湖南省內主要水系,從岳陽市城陵磯口匯入長江。洞庭湖是長江流域具有強大蓄洪能力的重要調蓄湖泊,在長江流域防洪體系中有著不可替代的作用。
2020年6月下旬以來,受長江5次編號洪水及湖南省內沅水、澧水來水共同影響,洞庭湖區防汛形勢嚴峻,洞庭湖區城陵磯站、營田站、湘陰站等重要控制站點長時間超警戒水位、超保證水位。2020年7月4日洞庭湖控制站城陵磯開始出現超警戒水位,直至9月2日退出警戒水位,歷時長達60 d,超警戒水位天數僅次于1998年的91 d,排在有實測歷史記錄以來第2位[1]。洞庭湖控制站城陵磯7月28日13:00達到洪峰水位34.74 m,超保證水位0.19 m,排在有實測歷史記錄以來第5位,為2000年以來第2位。汛情最嚴重時,湖區共有130個堤垸2 930 km堤段超警戒水位,256 km堤段超保證水位。為更好地應對特大洪水災害,降低洪澇損失,本文以洞庭湖2020年特大洪水為研究對象,分析其降雨情況、洪水過程、水利工程調度、防御體系等方面情況,旨在為洞庭湖區防汛抗洪提供參考。
1 雨洪過程
2020年降雨頻繁、總量偏多,時空分布不均,屬降水偏多年份,8月中旬主雨帶北抬后,長江上游的岷江、沱江、嘉陵江流域發生持續強降雨過程。在湖南省境內大范圍、高強度暴雨影響下,受沅水、澧水來水及長江干流的5次編號洪水的來水疊加影響,使得7月份洞庭湖湖區整體水位偏高,湖區城陵磯(七里山)站、湘陰站、鹿角站等重要控制站點長時間出現超警戒水位、超保證水位。雨洪過程主要具有以下幾個方面的特點。
(1) 四水上游降雨量明顯偏多,雨強較大。2020年6~7月沅水、澧水來水量異常偏多,洪水過程頻繁,沅水干流下游9月發生同期最大洪水,桃源站2020年9月17日洪峰水位44.04 m,較歷史同期最高水位偏高1.25 m。2020年6~7月,沅水、澧水流域平均累計降雨量分別達668,848 mm,較歷年同期均值分別偏多約70%,90%。據統計,沅水干流控制站桃源站2020年6~7月來水量322億m3,較多年同期均值偏多近50%;澧水干流控制站石門站6~7月來水量102億m3,較多年同期均值偏多1倍。2020年汛期(4~9月)湖南省各流域雨量與歷年同期均值統計見表1。
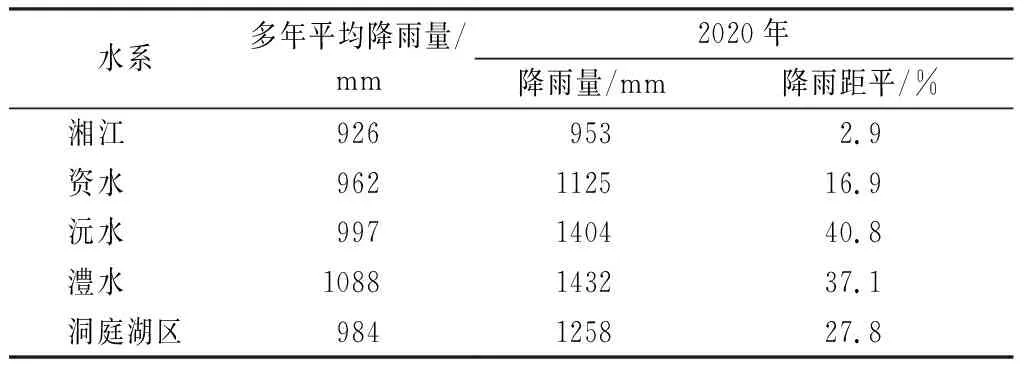
表1 2020年汛期(4~9月)湖南省各流域雨量與歷年同期均值統計
(2) 洞庭湖入湖水量總體偏多,來水量集中。2020年4月1日至10月1日,藕池口、松滋口、太平口(簡稱“三口”)與四水合計來水總量1 972.7億m3,較歷年同期均值1 600.4億m3偏多23.3%。藕池口、松滋口、太平口來水總量大幅增加,達到709.2億m3[2],較歷年同期均值433.9億m3偏多63.4%;四水合計來水總量1 263.5億m3,較歷年同期均值1 166.5億m3偏多8.3%,澧水、沅水、資水來水量分別偏多37.5%,32.0%,10.8%,湘江來水量偏少23.9%。6~8月份洞庭湖總入流1 534億m3,占汛期總入流的64.5%。2020年藕池口、松滋口、太平口與四水流量過程見圖1。
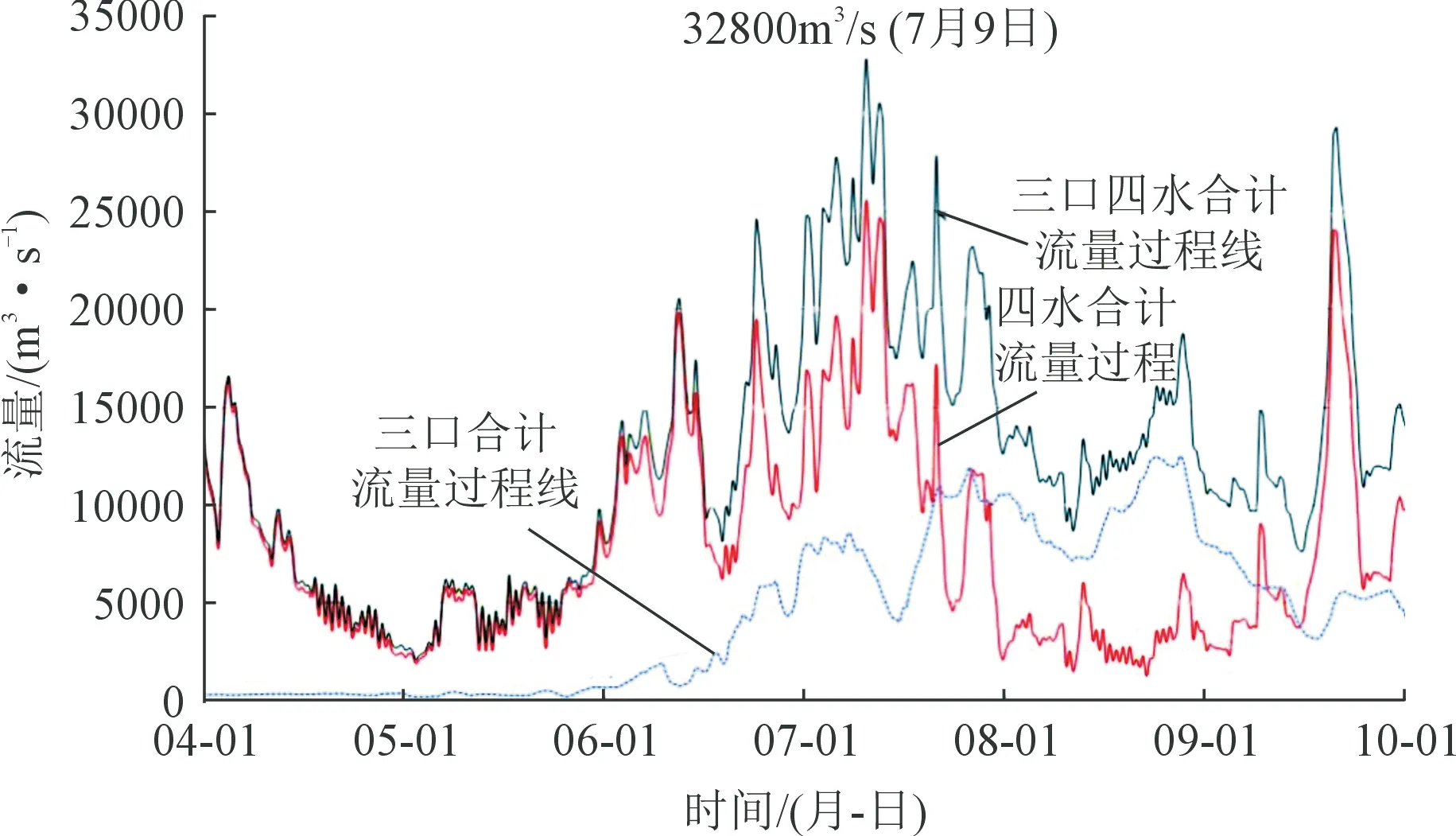
圖1 2020年藕池口、松滋口、太平口與四水流量過程Fig.1 Processes of Ouchi,Songzi,Taiping outlets and Lishui,Yuanshui,Zishui and Xiangjiang River in 2020
(3) 長江干流來水突出,出湖頂托嚴重。2020年6月28日至9月1日最強雨洪過程期間,長江上游先后形成5次編號洪水,三峽水庫發生建庫以來最大入庫洪峰75 000 m3/s[3]和出現最高調洪水位167.65 m。6月28日至7月8日(7月5日白天除外),7月16日至9月2日三峽水庫出庫流量均維持在30 000 m3/s以上;7月21~25日,7月28~30日,8月13~26日三峽水庫出庫流量均維持在40 000 m3/s以上,持續時間長達22 d。
長江來水通過藕池、松滋、太平口三口匯入洞庭湖,增加洞庭湖入湖水量。據統計,2020年6月28日08:00至9月2日08:00,藕池、松滋、太平口入湖總水量503.2億m3,較歷年同期均值261.7億m3偏多92.3%。同時,長江干流中下游也發生了大洪水。漢口站洪峰水位達28.77 m(7月12日),超過了2016年的28.37 m,低于1998年的29.43 m,列歷史第4位。鄱陽湖、修河發生超1998年洪水[4],長江干流監利、蓮花塘、螺山、漢口4站超警戒水位。長江干流城陵磯以下河段發生的大洪水對洞庭湖湖口形成頂托,減緩了洞庭湖洪水出湖速度,使洞庭湖形成上壓、下頂之勢,洪不宣泄不暢,造成洞庭湖水位持續上漲、居高不下。2020年長江洪水特征值見圖2。
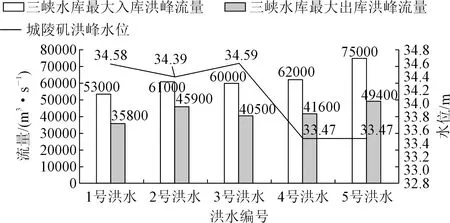
圖2 2020年長江洪水特征值Fig.2 Characteristic values of the Yangtze River flood in 2020
(4) 洞庭湖區洪水峰高、量大,超警戒水位時間長。2020年,洞庭湖環湖區全線超警戒水位,多個重要控制站超保證水位。洞庭湖城陵磯(七里山)站2020年最高水位34.74 m(7月28日),超警戒水位水位2.24 m,超保證水位0.19 m;水位排歷史實測流量第5位;最大流量33 200 m3/s(7月12日),排在1949年以來第15位。洞庭湖最大入湖流量51 500 m3/s,排歷史實測流量第10位。城陵磯(七里山)站超警戒水位時長排歷史第3位。2020年洞庭湖區主要洪水過程見表2。城陵磯(七里山)站排名前10位的年最高水位排序見圖3。
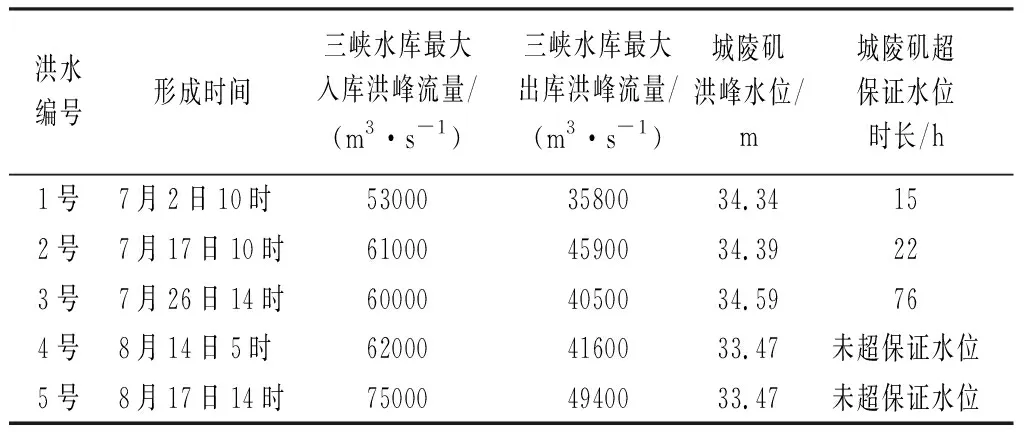
表2 2020年洞庭湖區主要洪水過程

圖3 城陵磯(七里山)站前10位年最高水位排序Fig.3 Top 10 annual highest water level of Chenglingji(Qilishan)hydrological station
2 水利工程調度分析
2020年汛期,長江流域先后出現5次編號洪水過程,面對洞庭湖洪水上壓下頂的不利局面,三峽水庫及上游水庫充分發揮了水庫群攔洪削峰作用,科學有序實施了水庫群、排澇泵站等水工程聯合調度[5]。通過長江流域水工程調度體系的防洪調度,避免了宜昌至石首河段水位超保證水位,縮短中下游干流各站超警戒水位時間8~22 d。據統計,在防御長江第4,5號洪水期間,長江上游水庫群的累計攔洪量約190億m3,其中三峽水庫的攔洪量約108億m3。通過三峽水庫以上水庫群的攔蓄,分別降低了岷江、嘉陵江下游洪峰水位約1.4 m和2.3 m,降低長江干流川渝河段洪峰水位2.9~3.3 m,減少洪水淹沒面積約112.7 km2。
2020年汛期,湖南省境內水庫采取了精準預報和提前預泄等諸多措施,統籌“一江一湖四水”聯合調度[6]。據統計,沅水流域的8座梯級水庫聯合防洪,沅水各水庫共攔蓄洪量58.7億m3;澧水江埡水庫、皂市水庫分別攔蓄洪量8.8億,5.4億m3;柘溪水庫、鳳灘水庫分別攔蓄洪量7.84億,4.20億m3。6月28日至7月12日,沅水和澧水流域同時普降暴雨,遭遇長江1號洪水。經過48次調度,五強溪、江埡、皂市、鳳灘、托口等5座主要大型水庫共攔蓄洪量23.6億m3,避免了下游桃源、常德堤防超過保證水位。7月17~23日,在防御長江2號洪水過程中,湖南省澧水、沅水和資水流域上的大型水庫超常規調度,大力削弱洪峰強度,總計減少入湖洪水達28億m3。通過此次水庫的攔洪錯峰,下游沿岸人民生命和財產安全得到了保障,洞庭湖連續6 d入湖流量小于藕池、松滋、太平口流量,為三峽水庫科學調度降低水位、騰出庫容贏得了時間,最終實現洞庭湖洪峰與長江干流高洪水位錯峰通過。在長江發生3次編號洪水的關鍵時期,通過聯合三峽水庫的攔洪削峰調度,城陵磯洪峰水位分別降低約0.8,1.7,0.6 m[7],避免了洞庭湖與長江高洪水位的不利組合遭遇,保障了洞庭湖區的安瀾。洞庭湖城陵磯主要洪水過程控制站還原特征值見圖4。
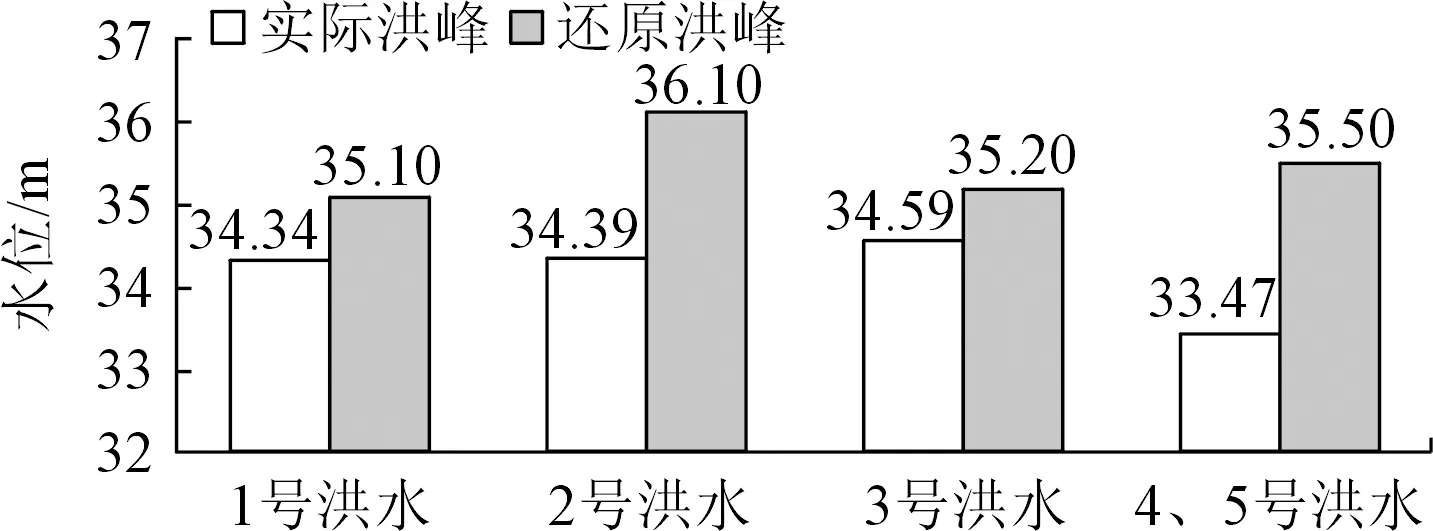
圖4 洞庭湖城陵磯主要洪水過程控制站還原特征值與實際值Fig.4 Reduced characteristic value and actual values of the main flood process control station in Chenglingji,Dongting Lake
3 結 語
2020年進入主汛期以來,長江上游發生持續性強降雨,降雨強度大、時間長,加之在湖南省境內大范圍、高強度暴雨共同作用下,沅水、澧水來水及長江干流的5次編號洪水的來水產生疊加影響,洞庭湖入湖水量總體偏多,長江來水突出,洞庭湖洪水峰高、量大出湖頂托嚴重,使得洞庭湖湖區7月份整體水位偏高,城陵磯站超警戒水位歷時長達60 d,排有實測歷史記錄以來第2位。為應對嚴峻的防洪形勢,以長江上游三峽水庫為首的水庫群和湖南省內水利工程配合聯合調度,成功防御了此次洞庭湖區特大洪水。但是也暴露出了防洪工程體系不盡完善、監測預報預警精準度仍有提升空間、基層防汛專業力量薄弱、群眾防災避災意識不強等方面的問題,需在今后加以改進和提升。
