多發彈氣動參數聯合辨識方法研究
2020-06-18 03:28:42劉洋常思江魏偉
兵工學報 2020年5期
關鍵詞:測量
劉洋, 常思江, 魏偉
(1.南京理工大學 能源與動力工程學院, 江蘇 南京 210094; 2.瞬態沖擊技術重點實驗室, 北京 102202;3.北京理工大學 機電學院, 北京 100081)
0 引言
氣動辨識是飛行器系統辨識中的關鍵問題,是炮彈、火箭彈、導彈、飛機等獲取自身氣動力參數的重要手段,在各類彈箭的氣動外形設計、系統參數確定、設計定型、射表編制等過程中具有不可替代的作用。氣動辨識是以一定的彈箭運動模型和辨識算法為基礎,從野外靶場或靶道實測彈箭運動數據中提取出彈箭氣動力參數的過程。理論上講,氣動辨識本質上就是利用輸入、輸出信息確定系統結構參數。從工程應用角度看,與導彈、飛機等有控飛行器相比,常規炮彈、火箭彈等無控飛行器的氣動辨識難度更大,其原因主要在于:1)描述無控飛行器的動力學模型往往具有較強的非線性結構[1],數學處理難度較大;2)常規炮彈、火箭彈發射時的瞬時狀態往往具有隨機性且難以準確測量,并且由于穩定飛行過程中不受控,無法為系統提供有效的輸入;3)某些彈丸(如槍彈)的氣動力參數非線性特性明顯,對彈道影響較大,而非線性氣動力研究本身就具有很大難度;4)常規炮彈、火箭彈等開展飛行試驗時,由于體積空間、試驗成本、發射條件、飛行環境等各方面的限制,往往造成測量數據的種類、精度及采樣頻率等,難以同導彈、飛機等相提并論,從而給氣動辨識帶來困難。
由于常規炮彈、火箭彈等無控飛行器的射程、密集度、穩定性等與氣動力參數密切相關,盡可能準確地獲取氣動力參數,對性能評估、方案改進優化等具有重要作用,故有必要深入開展氣動辨識方法與技術研究。從現有文獻看,相關氣動辨識研究的重點主要是辨識算法,例如Chapman-Kirk方法(C-K法)[2]、Levenberg-Marquardt方法(L-M法)[3-5]、極大似然法[6-9]以及某些全局優化算法[3,10-11]等。實際工程中,為了確定彈箭氣動力參數,一般都是在不同初速、射角等條件下,成組發射彈箭并進行測量。對于1組射彈,由于氣象變化、起始擾動、彈箭結構參數等具有不同程度的隨機性,即便測量設備具有相同誤差,同一組試驗的每發彈也不可能測得完全相同的彈道數據。已有實踐表明,同一組試驗中每發彈的氣動力參數辨識結果往往有一定差異,對于某些動態氣動力參數,如俯仰阻尼力矩系數、馬格努斯力矩系數等,發與發之間的差異甚至很大。目前,絕大多數相關研究關注的都是單發彈丸的氣動辨識過程,主要涉及模型和辨識算法,并未考慮如何優化處理多發彈丸辨識結果的差異。例如,在對氣動力參數精度要求甚高的射表試驗數據處理中[12-13],就是對多發彈測量數據辨識出的氣動力參數取平均值,作為該彈的氣動力參數以供后續使用。然而實際科研中發現,采用平均值氣動力參數去重構彈道,經常出現計算值與單發測量值差異較大的現象。這表明,盡管基于單發測量數據的獨立辨識結果具有最優性,但平均值氣動參數對于多發測量數據來說并不是全局最優的。目前常用的C-K法、L-M法、極大似然法等都屬于局部優化方法,在用于單發測量數據獨立辨識時具有精度較高、收斂性好等優點,但用于多發彈氣動參數聯合辨識卻具有較大局限性,辨識過程極不穩定。近年來全局優化算法在氣動辨識中的應用研究逐漸增多,但大多還是解決單發數據氣動辨識的狀態初值問題、收斂性問題等[3,10]。在考慮多發彈氣動參數聯合辨識方面,國外有一些初步研究。如文獻[3]針對仿真數據,利用L-M法和遺傳算法分別對多發彈的氣動參數進行了聯合辨識,然而,L-M法收斂于局部極值,而遺傳算法的結果殘差比L-M法更大,這說明兩種算法都未能在多發彈氣動參數聯合辨識中取得較好的全局最優解。文獻[4]中給出了L-M法和有限差分法的氣動辨識結果,比文獻[3]有較大改進,但也未能解決局部極值問題。文獻[14]提出采用多組試驗數據聯合辨識某無控空間探測器的氣動參數,但其重點在于將氣動參數表示成攻角和馬赫數的非線性函數,未考慮可能存在的局部解問題,并未給出具體的全局策略和算法。
本文針對槍彈、常規炮彈、火箭彈等無控彈箭的氣動參數聯合辨識問題開展研究,提出一個可同時處理多發彈測量數據并給出唯一具體氣動力參數值的全局優化策略。以單發彈獨立辨識為基礎、以目前國際優化領域新興的差分進化算法為工具,建立了利用多發彈測量數據聯合辨識氣動力參數的全局優化流程,并通過對某大口徑炮彈攻角紙靶試驗數據的處理,驗證了本文所提策略的正確性和有效性。
1 多發彈測量數據聯合辨識策略
1.1 辨識流程設計
彈丸氣動辨識流程主要由以下5個部分組成[5]:測量數據預處理、數學模型、辨識算法、準則函數和辨識結果后處理。測量數據預處理和辨識結果后處理主要為剔除野值與曲線的平滑濾波,數學模型則根據辨識問題的不同可采用4自由度、5自由度、6自由度外彈道方程或攻角運動方程等,準則函數的選取與辨識算法有關。因此,多發彈測量數據聯合辨識的流程設計重點是辨識算法。
辨識算法按尋優點個數可分為局部優化算法和全局優化算法,按搜索方向可分為梯度法和非梯度法,在氣動辨識中,一般選用基于梯度的局部優化算法或非梯度的全局優化算法。
文獻[4]中選取L-M法作為多發彈測量數據聯合辨識的算法,該算法是局部優化算法中的一種,具有計算時間較短、計算效率較高的優點,在對單發彈的辨識中得到了廣泛應用。但是,利用局部優化算法對多發彈測量數據進行辨識,存在以下2個缺點:1)多發彈聯合辨識中求得的矩陣可能達到幾十甚至上百階[3],若矩陣接近奇異矩陣,計算可能發散;2)局部優化算法尋得全局最優的概率較低[3-4,15],當預先給出的待辨識參數與實際值相差較大時,容易陷入局部最優解。此外,由于實測數據的誤差種類較多,且有些誤差難以定量甚至難以定性(如紙靶試驗中彈丸穿靶瞬間對其自身的干擾),可能使局部最優解個數增多,從而導致局部優化算法搜索到全局最優解的概率更低。
因此,局部優化算法不適用于多發彈測量數據聯合辨識。故考慮使用全局優化算法作為多發彈測量數據聯合辨識的算法,該類算法計算穩定性更好,搜索到全局最優解的概率更高,但搜索維度較多,計算效率較低。
為改善全局優化算法的性能,本文提出一種新的辨識流程:先利用局部優化算法分別對各發彈進行快速辨識(以下簡稱獨立辨識),利用辨識結果生成全局優化算法中的搜索空間;再使用全局優化算法對多發彈進行聯合辨識(以下簡稱聯合辨識)。具體辨識流程如圖1所示。圖1中n表示試驗彈丸的發數,1發彈對應1套試驗數據、氣象數據和結構參數,n發彈共有n套數據。待辨識參數為狀態初值和氣動參數。狀態初值為彈道方程中的積分初值或攻角方程的初始幅值、初始相位等,由于每發彈的發射條件、起始擾動等都有可能不同,導致每發彈的狀態初值差異較大,而某些狀態初值,如彈丸角運動的初始幅值與初始相位等難以直接測量,故狀態初值應作為待辨識參數與氣動參數同時進行辨識。每組狀態初值中包含N1個待辨識參數,每組氣動參數中包含N2種待辨識氣動參數,如阻力系數、升力系數導數等。
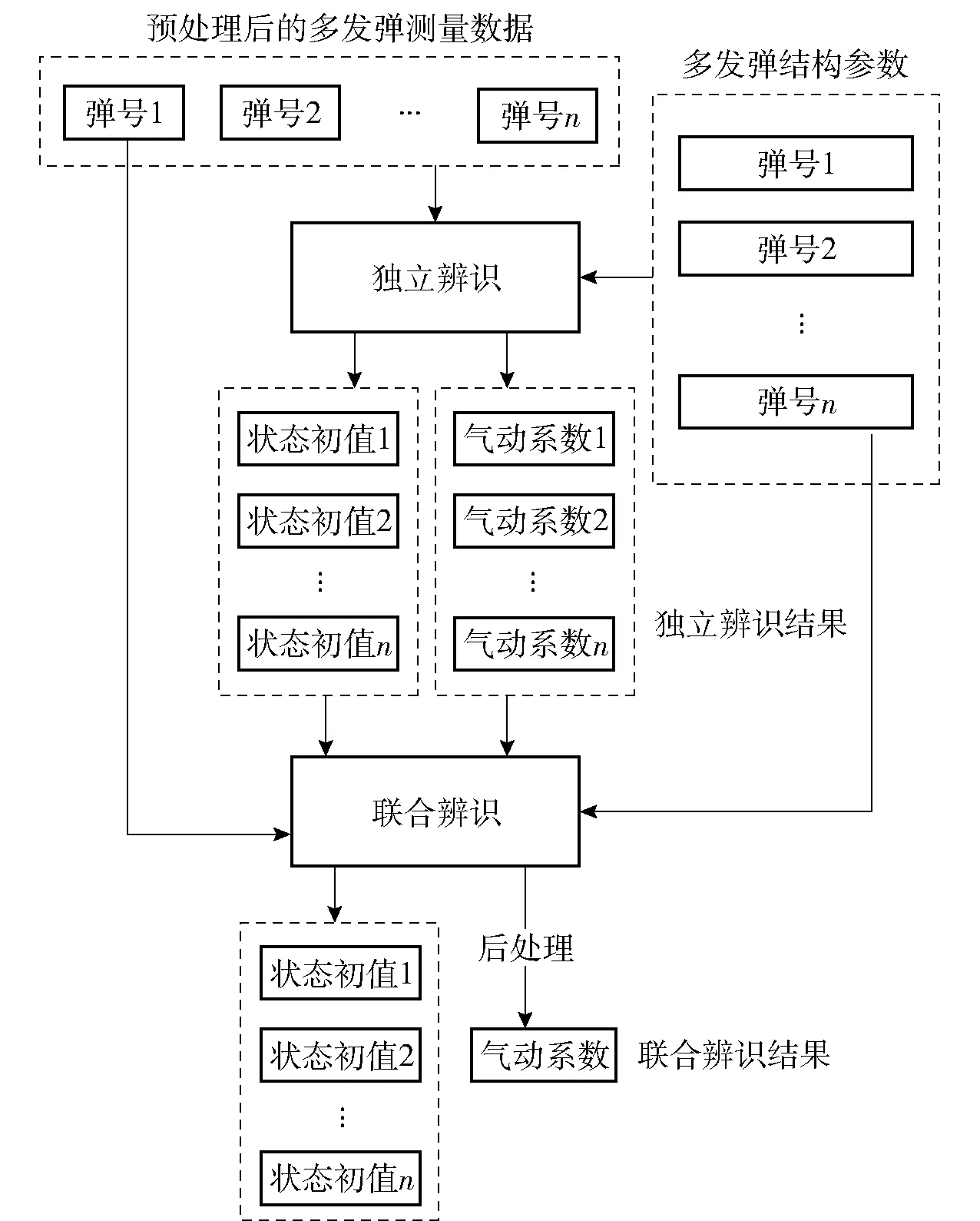
圖1 辨識流程Fig.1 Identification procedure
圖1中的獨立辨識中僅對單發彈測量數據辨識,可根據實際情況選用C-K法、極大似然法等辨識算法,辨識結果為聯合辨識提供搜索空間,該搜索空間用于聯合辨識中待辨識參數的初始化,使其位于較小的約束范圍內,進而減少迭代次數,提升計算效率與穩定性;聯合辨識中對多發彈測量數據同時辨識,辨識算法選用全局優化算法。
因此,多發彈測量數據聯合辨識的具體步驟為:
1)對多發彈測量數據進行預處理,剔除野值、平滑測量曲線等,并根據測量數據種類及待辨識氣動參數構建數學模型;
2)使用局部優化算法進行獨立辨識,得到n組狀態初值與n組氣動參數;
3)利用獨立辨識結果生成聯合辨識的搜索空間,使用全局優化算法對多發彈相關氣動參數進行聯合辨識,得到n組狀態初值與1組氣動參數;
4)對辨識結果進行平滑、插值等后處理。
1.2 準則函數與最優解定義
在整個辨識過程中,獨立辨識與聯合辨識的準則函數應在形式上保持一致,如:不能同時使用最小二乘準則和極大似然準則。本文使用最小二乘準則作為辨識準則。
最小二乘準則可用(1)式表示:
(1)
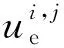
在辨識、優化等問題中,J值越小,表明全局優化性越好[16]。在約束域內:若J是最小值,則對應的解是全局最優解;若J是極小值且非最小值,則對應的解是局部最優解。將此概念擴展到多發彈測量數據聯合辨識的問題中,利用辨識出的1套氣動參數和n套狀態初值重構出n條彈道,若對應的J值是約束域內的最小值,則該氣動參數與狀態初值共同構成全局最優解,反之則為局部最優解。以上概念也作為后續評價全局性與最優解的依據。
2 差分進化算法的應用
2.1 基本算法
差分進化算法是近年來國際優化領域新興的一種全局優化算法,相比于遺傳算法、粒子群算法等,差分進化算法具有更好的收斂速度、魯棒性和全局尋優能力[16],適合計算量較大的聯合辨識。
差分進化算法主要是由“變異”、“交叉”和“選擇”3個部分構成。但是在聯合辨識中,種群的搜索空間與初始化也較為重要。
差分進化算法的“變異”遵循(2)式:
(2)
式中:k為迭代次數;θ是待變異的個體,θr1和θr2是隨機的2個個體;a是[0,1]之間的1個隨機數。與粒子群算法等具有一定方向性算法不同,差分進化算法的變異方向是完全隨機的,這意味著算法具有更好的全局搜索能力。
“交叉”是指2個個體間隨機交換若干參數生成新的個體,也可以進行算數重組或者連續重組。“選擇”可以選用模擬退火的選擇方式,防止算法因為早熟而產生局部最優解[17]。
2.2 算法應用
在全局尋優過程中,較大的搜索空間不僅增加迭代次數、降低辨識效率,對于某些彈道方程,如果氣動參數與狀態初值的迭代初值不在合理區間內,可能導致計算發散。對于帶約束的優化問題,若能將搜索空間預先確定在約束范圍內,可大幅減少無效迭代。因此,在聯合辨識中,獲得合理搜索空間是非常重要的環節。
差分進化算法應用于圖1中的聯合辨識部分,具體流程如圖2所示。
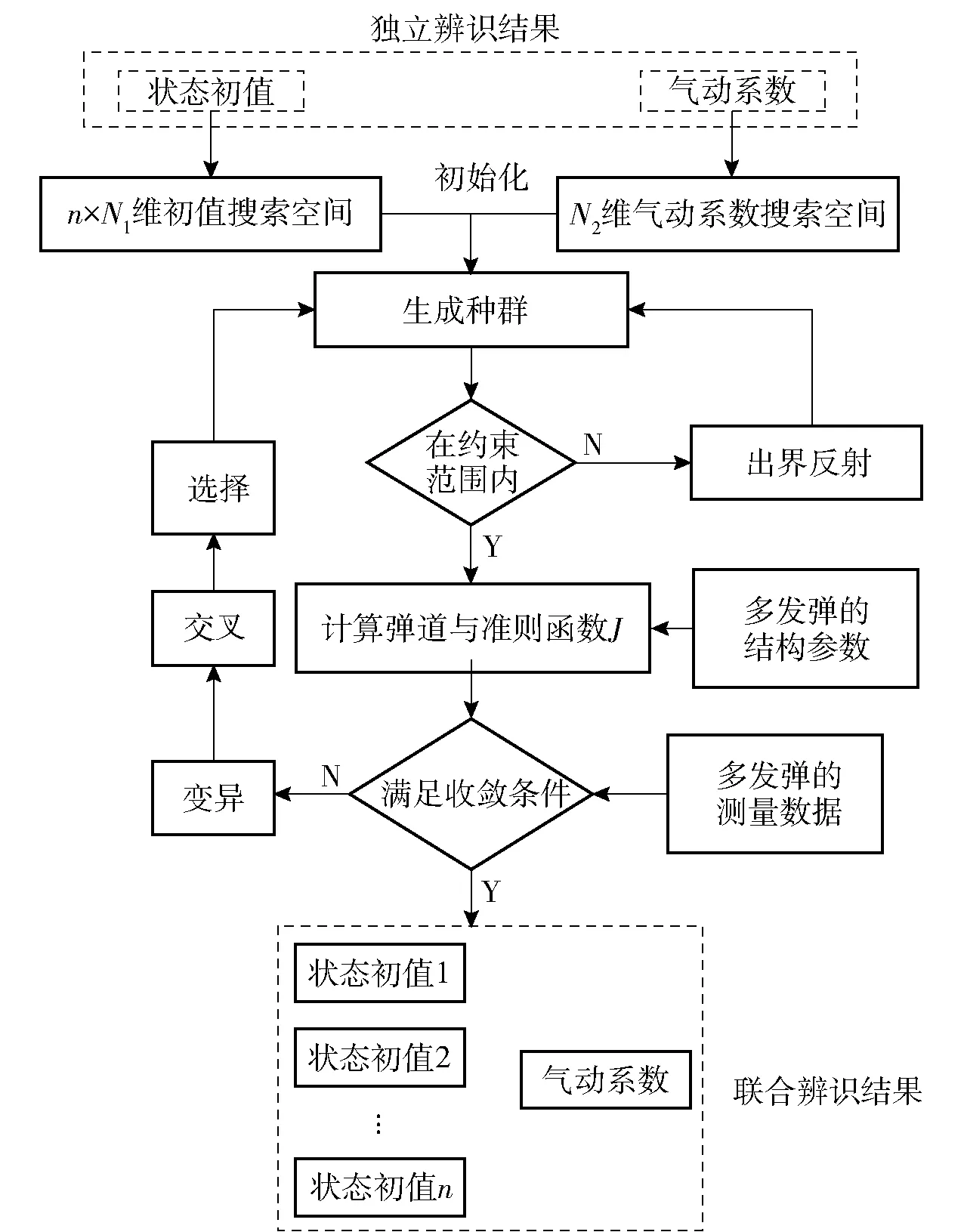
圖2 差分進化算法的應用流程Fig.2 Flowchart of differential evolution algorithm
如圖2所示,聯合辨識的搜索空間由獨立辨識結果確定。由于每發彈狀態初值不同,故以狀態初值的辨識結果為中心按一定比例擴展生成新的搜索空間。經反復調試發現擴展比例與狀態初值類型有關,當狀態初值為可測量(如速度、位置等),擴展比例可取±2%~±5%;當狀態初值為不可測量(如角運動初始幅值和初始相位),擴展比例可取±20%~±30%. 需說明的是,在調試過程中當采用±50%、±30%和±20%這3組不同擴展比例進行辨識,得到了相同的辨識結果,但迭代次數分別為 26 541次、9 538次和4 076次。這表明,對于本文所提策略,擴展比例大小對計算速度影響較大,但對計算精度影響較小。擴展比例根據具體問題調試選取,調試的一般原則是在保證多次測試均能成功獲得最優解的前提下,盡可能地減小其數值[16]。氣動參數的搜索空間可由獨立辨識結果的最大值和最小值確定,為增大全局最優解位于搜索空間的概率,該搜索空間可進行適當放大。因此,狀態初值的搜索空間共有n×N1維,氣動系數的搜索空間共有N2維。
由于差分進化算法具有一定的隨機性,為確保搜索到全局最優解,當搜索空間維度較多時,應增大個體數量N,使種群在初始化搜索空間內的密度更大、分布更均勻,增大搜索到全局最優解的概率[16]。此外,由于獨立辨識采用的是局部優化算法,其給出的初始搜索空間有可能未包含全局最優解,為解決這一問題,本文的策略是利用同一程序進行多次辨識,前幾次辨識不對搜索空間施加邊界約束,可使迭代向初始化搜索空間外進行。若前幾次辨識結果差異很小且位于搜索空間內,該結果大概率為全局最優解,則后續幾次辨識中可對搜索空間施加“出界反射”的邊界約束,即當“變異”后的個體在某個維度上超出搜索空間時,則在該維度上將其“反射”回搜索空間內,以提高計算效率[16];若前幾次辨識結果差異較大或不在搜索空間內,后續若干次辨識仍然不對搜索空間施加邊界約束,以增加搜索到全局最優解的概率。當多次辨識完成后,若辨識結果差異很小(如小于0.01%),可認為辨識結果是全局最優解;若辨識結果差異較大,應選取物理意義正確且準則函數更小的解作為辨識結果,但該解是否為真正意義上的全局最優解,還需結合氣動工程計算、計算流體力學數值計算等進行驗證。
辨識過程中,局部優化算法和全局優化算法的收斂條件均為
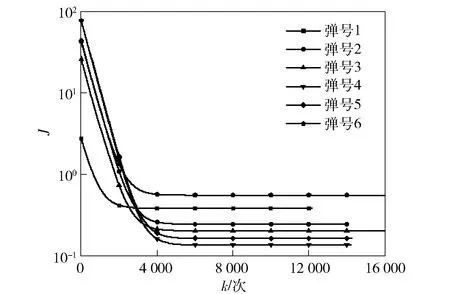
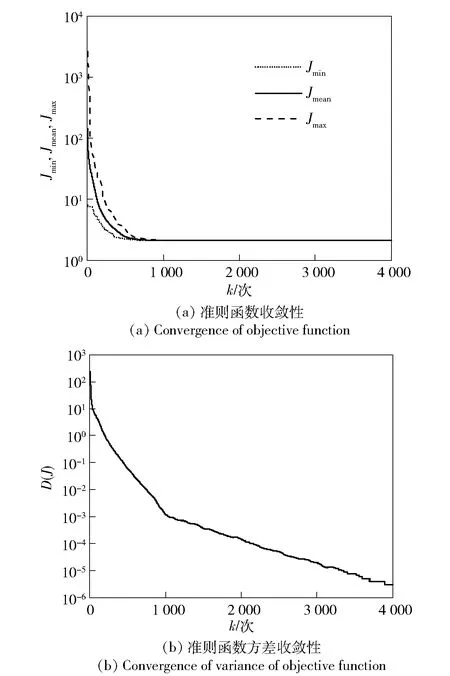
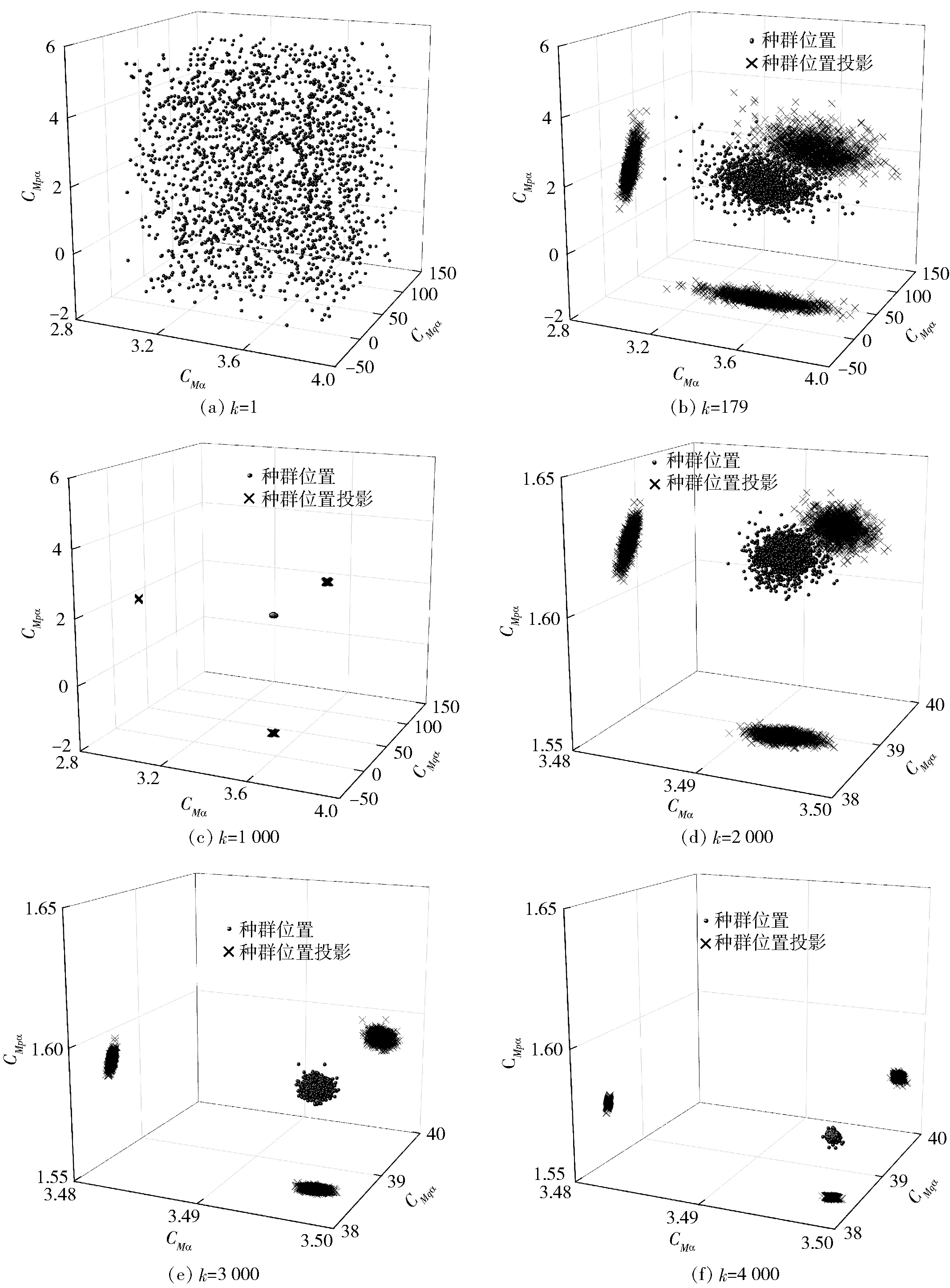
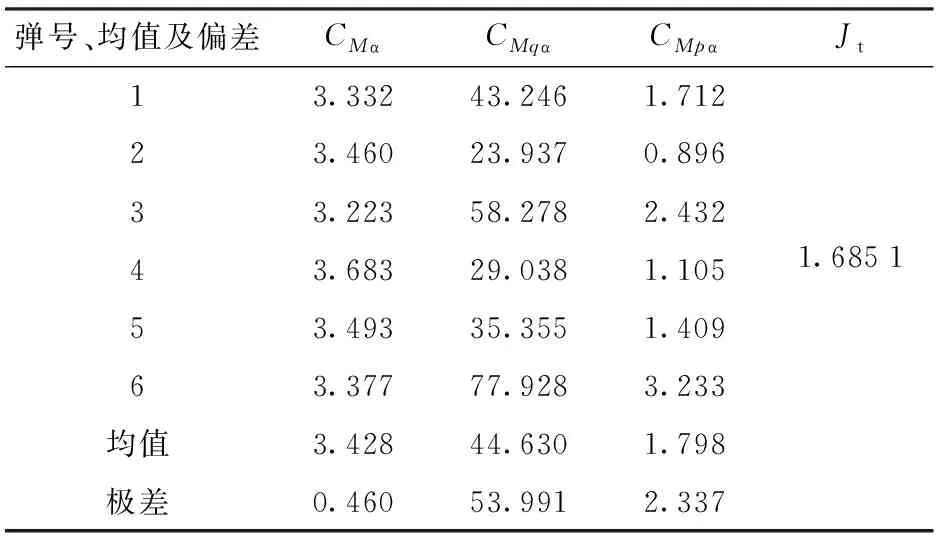
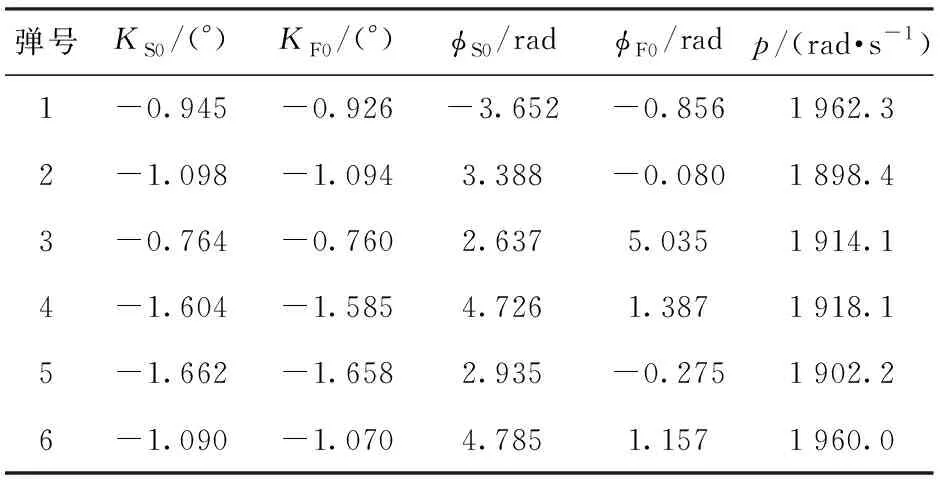
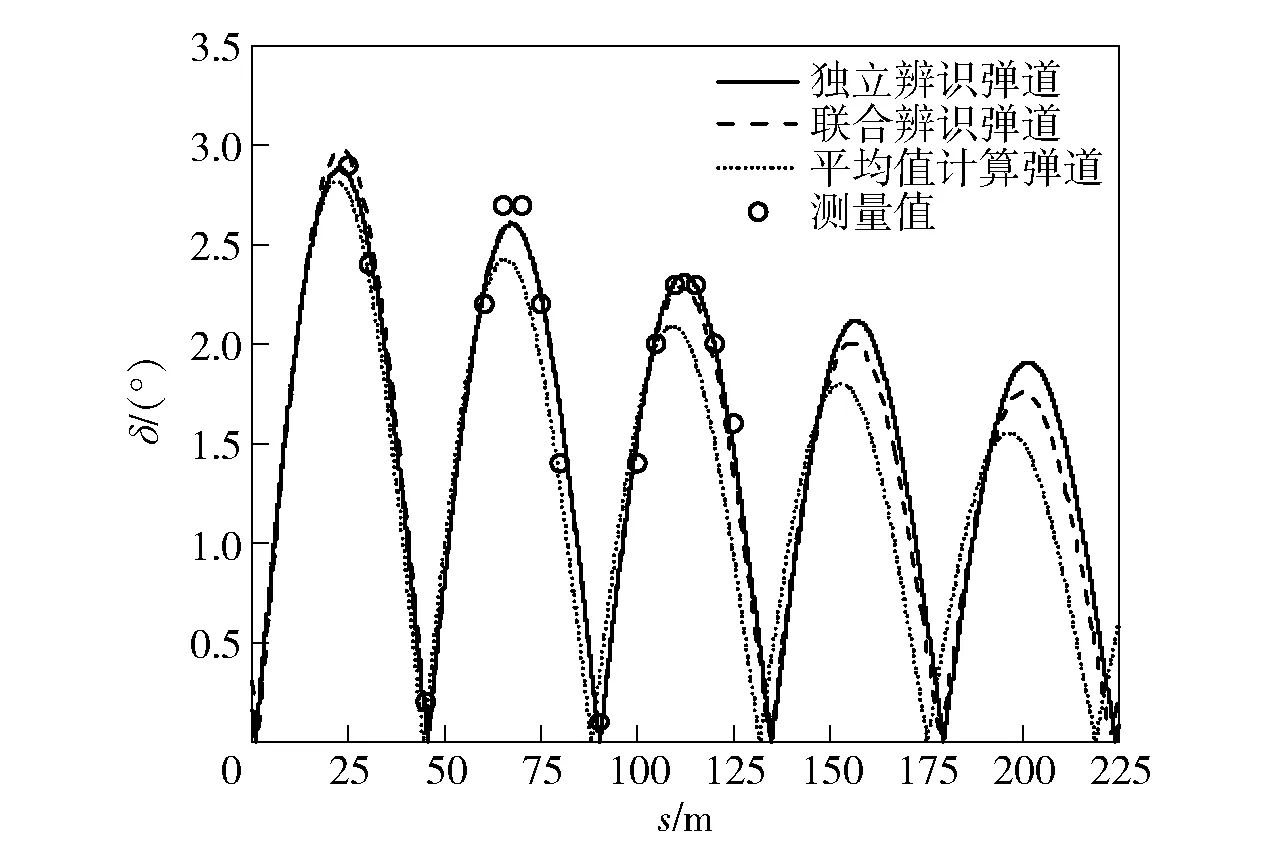
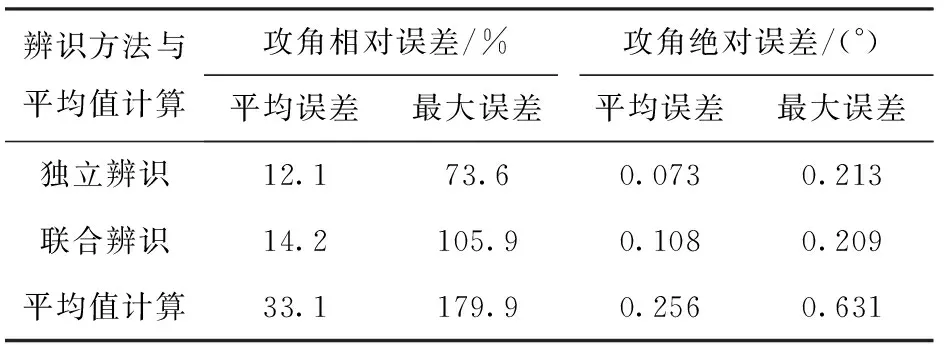
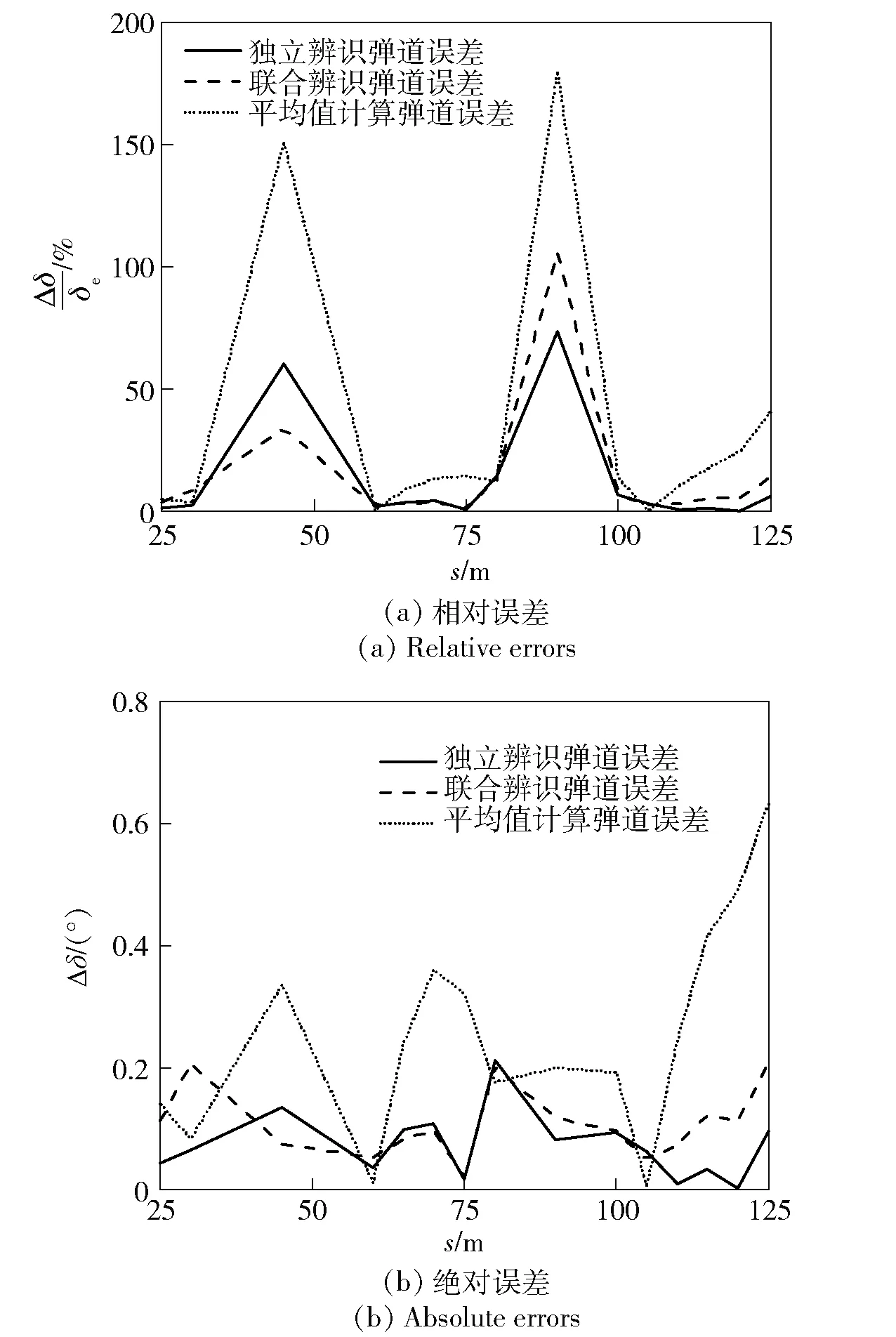
Jk (3) 式中:Jk為準則函數的k次迭代值;b1=10-3. 然而,實際中往往達不到這樣的條件,所以可采用以下條件中的任意一種: |Jk+1-Jk| (4) |θk+1-θk| (5) 式中:Jk+1為準則函數的k+1次迭代值;b2=10-5,b3=10-7. (4)式代表準則函數已經收斂,而(5)式代表待辨識參數已經收斂。在局部優化算法中,達到任意一種收斂條件都說明迭代已經收斂,即使該解可能為局部最優解。 對于差分進化算法,個體數量不止1個,所以無法使用(5)式,且由于可能存在局部最優解,使得相差較大的θ能計算出很接近的J值,所以(4)式也不能單獨使用。在聯合辨識中,考慮到整個種群應在所有維度上收斂,即有 (6) 式中:D()表示取方差;E()表示均值;i表示維度;b4=10-3.(6)式代表種群中所有個體在第i個維度達到收斂,當n×N1+N2個維度都滿足(6)式時,可認為種群在所有維度上收斂。當可能存在較多局部最優解時,可以考慮同時使用多個種群進行辨識。當辨識結果滿足(5)式而不滿足(6)式時,說明辨識結果可能是局部最優的;只有同時滿足(4)式和(6)式,才能說明辨識結果是全局最優的。 綜上分析,在獨立辨識中,可以同時使用(3)式、(4)式和(5)式,滿足任意1個條件即認為計算收斂;在聯合辨識的差分進化算法中,需要同時滿足(4)式和(6)式,才能認為收斂到全局最優解。b1、b2、b3和b4可視具體情況而定,基本原則是:當彈丸發數較少或測量點較少時,為保證充分收斂,b1、b2、b3和b4的取值應更小(如比上述所給數值再小1個數量級);當彈丸發數較多或測量點較多時,為優化計算時間,b1、b2、b3和b4的取值可適當放大,但一般不能大于上述所給數值。 為了驗證本文建立的多發彈測量數據聯合辨識策略,本節考慮一個典型的氣動力矩參數辨識問題[17],即利用紙靶試驗(測攻角)辨識彈丸靜力矩系數導數、俯仰阻尼力矩系數導數及馬格努斯力矩系數導數,將上述辨識流程應用于實測紙靶數據處理。 由于紙靶試驗往往采取平射,單發彈丸飛行時間較短,可認為全彈道馬赫數基本不變、轉速無衰減;同組試驗的多發彈之間初速相差很小,認為具有相同馬赫數。可采用復攻角運動方程作為氣動力矩參數辨識用數學模型。 彈丸復攻角運動方程的齊次形式[18]如下: (7) 式中:Δ為復攻角;s為彈道弧長;i為虛數單位;H為角運動阻尼作用項;P為轉速作用項;M為靜力矩作用項;T為升力和馬格努斯力矩耦合作用項;α為縱向攻角;β為橫向攻角;Clα為彈丸升力系數導數;CD為阻力系數;ρ為大氣密度;d為彈徑;m為彈丸質量;l為特征長度;Iy為赤道轉動慣量;Ix為極轉動慣量;p為彈丸轉速;v為彈丸運動速度;CMα為靜力矩系數導數;CMqα為俯仰阻尼力矩系數導數;CMpα為馬格努斯力矩系數導數。 該方程的解析解[18]為 (8) 式中:KS0和KF0分別為慢圓運動和快圓運動的初始幅值;φS0和φF0分別為慢圓運動和快圓運動的初始相位;λS和λF分別為慢圓運動和快圓運動的阻尼指數;φ′S和φ′F分別為慢圓運動和快圓運動的角頻率。 旋轉穩定彈的陀螺穩定因子Sg為 (9) 工程上一般取Sg>1.3為陀螺穩定性條件,只有滿足該條件,才能保證彈丸形成周期運動[18]。因此,陀螺穩定性條件即可作為氣動辨識的約束條件: P2-5.2M>0, (10) 在整個辨識過程中,P和M的取值需始終滿足約束條件(10)式。 因此,計算對應s處的α和β時,先利用(7)式計算出H、P、T和M,并檢驗其是否滿足約束條件(10)式:若滿足約束,則將其代入(8)式中進行計算,若不滿足約束,則對CMα、CMqα和CMpα重新取值,直到其滿足約束條件。 在某大口徑榴彈的紙靶試驗中,共射擊1組6發彈丸。試驗前,對每發彈進行了靜態參數測量,且每發彈的紙靶布置方式相同:第1張紙靶布置在距離炮口25 m處,測量段s為25~125 m,每間隔5 m布置1張紙靶,彈丸平均飛行時間t≈0.11 s,平均馬赫數Ma=2.679 2,彈丸初速的最大值與最小值之差為3.1 m/s,符合3.1節中描述的假設。試驗完成后讀取紙靶數據并對其進行曲線平滑和野值剔除,處理后每發彈有15~17個測量點。每發彈的m、Ix、Iy、和v均采用實測值;由于沒有直接測量轉速p,故將p作為待辨識參數。彈道測量數據為α、β和s,辨識中p和v作為常數處理。 表1中給出了獨立辨識中的48個待辨識參數。 表1 獨立辨識的待辨識參數 而聯合辨識中的待辨識參數為 共有33個待辨識參數。 利用數值仿真MATLAB軟件編程并對多發彈測量數據進行辨識,為充分地利用計算資源,使用軟件中的Parallel Pool模塊進行多線程并行計算。在獨立辨識中,使用不同線程對多發彈并行計算;在聯合辨識中,使用不同線程對多個個體并行計算。 在獨立辨識中,使用文獻[19]中方法進行辨識,6發彈各自的準則函數收斂曲線如圖3所示。 圖3 獨立辨識收斂性Fig.3 Convergence of independent identification 由圖3可以看出,6發彈的準則函數都不滿足(3)式,而是滿足(4)式或(5)式。由于預先給定的初始相位、幅值和氣動參數與實際值(真值)相差較大,而迭代增量由導數確定,故圖3中各條曲線的截距不同,而斜率相同。 搜索空間維度D=33,根據2.2節中的辨識策略,選取個體數量N=2 000,并使用同一程序連續進行10次辨識。前5次辨識沒有進行邊界約束,其辨識結果均位于初始化搜索空間內且相對誤差小于0.01%,可認為該結果很可能為全局最優解,后5次辨識施加“出界反射”的邊界約束以提高計算效率。10次辨識結果的相對誤差小于0.01%,故認為該辨識結果即為全局最優解。 準則函數最大值Jmax、最小值Jmin、平均值Jmean和方差D(J)能夠反應整個種群在迭代過程中的收斂情況。Jmin所對應個體是潛在的最優解,而Jmax與Jmean則能代表種群的初始分布情況與收斂速度。圖4給出了最后1次辨識中J和D(J)隨迭代次數變化的曲線。 圖4 聯合辨識收斂性Fig.4 Convergence of combined identification 由圖4可以看出:Jmax在迭代之初的值很大,但是下降速度非常快,k=1 000時幾乎與Jmean和Jmin重合,且D(J)<10-3,準則函數基本收斂;k=2 000之后3條曲線就完全重合;k=3 000時,D(J)<10-5,整個種群的準則函數已經完全收斂。計算完成后,Jmin對應的氣動參數與狀態初值即為多發彈聯合辨識的全局最優解。 除了J需要收斂外,種群中的所有個體θ也需收斂。種群位置的關系與辨識的收斂性相關,種群位置越集中,收斂性越好。圖5給出了不同k時種群在氣動參數搜索空間中的位置,為方便觀察種群位置變化,在圖5(b)~圖5(f)中將其投影到CMα、CMpα和CMqα相互正交形成的3個面上。 圖5 聯合辨識氣動參數收斂性Fig.5 Convergence of aerodynamic parameters for combined identification 從圖5(a)~圖5(f)可以看出各氣動參數的迭代過程:當k=1時,種群的初始分布較為均勻,能充分地填充整個搜索空間;當k=179時,種群已向某一區域收斂;當k=1 000時,相比于初始搜索空間,整個種群幾乎收斂為一個點;隨著k的增大,種群的收斂性越來越高,但是在k=2 000之后,收斂方向發生改變。當搜索空間內僅有1個最優解時,在達到一定迭代次數后,種群的收斂方向應僅向內部收縮,而種群位置幾乎不會移動[16],如果種群位置發生移動,說明J的梯度方向發生改變,這種改變可能陷入局部最優解。 從圖5(b)和圖5(c)的投影可以看出,從k=179到k=1 000的收斂過程即為整個種群向內部收縮的過程;從圖5(d)~圖5(f)的投影可以看出,雖然從k=2 000到k=4 000同樣是整個種群向內部收縮,但種群整體的位置也發生了改變,說明該位置附近可能存在局部最優解。在多次辨識中均出現了這種情況,說明當多發彈同時辨識時,若使用局部優化算法或搜索能力不足的全局優化算法時,很容易陷入局部最優解[3]。 在聯合辨識中,由于無需雅克比矩陣,且搜索空間的選取較為合理,辨識過程中始終滿足(10)式的約束,未出現計算發散;而獨立辨識中卻出現了發散,人為減小步長后才能收斂。這表明全局優化算法的穩定性要優于局部優化算法。 為便于討論,以單發彈獨立辨識結果重構的彈道稱為獨立辨識彈道,以聯合辨識結果重構的彈道稱為聯合辨識彈道。理論上講,1種彈形對應唯一的氣動參數,實際中由于多發彈辨識出的氣動參數在數值上并不完全一致,在對辨識結果的處理中,往往取氣動參數的平均值或者加權平均值,作為該彈的氣動參數[12-13]。將獨立辨識結果中的氣動參數取平均值,利用該氣動參數與辨識結果中的狀態初值重構的彈道稱為平均值計算彈道,其準則函數計算方法與聯合辨識彈道相同。 由于單發彈的獨立辨識不具有全局性,故以平均值計算彈道和聯合辨識彈道為主要研究對象,獨立辨識彈道作為參考,Jt為單發彈辨識彈道準則函數,Jm為平均值計算彈道準則函數,Jc為聯合辨識彈道準則函數,獨立辨識結果與平均值計算結果如表2~表4所示。 表2 狀態初值的獨立辨識結果 表3 氣動參數的獨立辨識結果 表4 氣動參數平均值計算結果 從表3和表4中可以看出:CMα的均值與極差分別為3.428與0.46,極差與均值之比為13.4%,CMqα的極差與均值之比為121%,CMpα的極差與均值之比為130%;平均值計算彈道的準則函數Jm=4.996 5,遠大于獨立辨識彈道的準則函數之和Jt=1.685 1,這說明獨立辨識彈道的準則函數雖然較小,但多發彈辨識結果相差較大,故平均值氣動參數計算彈道與測量值相差較大。 利用獨立辨識結果生成初始搜索空間進行多發彈聯合辨識,經反復調試,選取狀態初值和氣動參數的擴展比例均為±20%. 結果如表5和表6所示。 表5 狀態初值的聯合辨識結果 表6 氣動參數的聯合辨識結果 對比表3、表4和表6可以看出,盡管兩種方法辨識出的狀態初值和氣動參數相差不大,但聯合辨識彈道的準則函數值Jc=2.089 8卻遠小于平均值計算彈道的準則函數Jm. 需要說明的是,這6發彈獨立辨識的準則函數值并不相同,表3中給出的是6發彈的準則函數之和。為便于研究,這里選擇獨立辨識結果中準則函數最小的第4發彈作為研究對象,研究攻角變化規律與辨識誤差。 將第4發彈的獨立辨識彈道、聯合辨識彈道、平均值計算彈道與測量值進行對比,結果如圖6所示,圖6中δ為攻角。測量段s取25~125 m,為便于研究,2條辨識彈道和平均值計算彈道范圍取s為0~225 m,由于彈丸初速和轉速較高,該段彈道上的速度變化約為1%,轉速變化約為0.5%,工程上可作為常數處理。 圖6 辨識彈道與平均值計算彈道Fig.6 Identified and calculated trajectories 從圖6中可以看出:獨立辨識彈道和聯合辨識彈道與測量值較為接近,而平均值計算彈道與測量值相差較大;3條曲線在第1個攻角周期時相差不大,峰值位置和高度也很接近,隨著距離的增加,差異逐漸變大,這說明在待辨識參數中,KS0、KS0、φS0和φF0的誤差對彈道影響較小,而CMα、CMqα、CMpα和p的誤差對彈道影響很大。 由于測量值間隔較大,且在攻角峰值和零點處缺少測量值,而該發彈的獨立辨識彈道與測量值最接近,故以圖6中獨立辨識彈道為基準,研究第4發彈聯合辨識彈道與平均值計算彈道的運動規律。 在測量段內,聯合辨識彈道每個周期的運動距離與獨立辨識彈道相差0.9%,前3個周期攻角峰高度值分別相差0.118°、0.016°和0.064°,峰值位置分別相差0.35 m、0.06 m和0.49 m;平均值計算彈道每個周期的運動距離與獨立辨識彈道相差2.3%,并從第2個周期開始,攻角峰值高度、位置開始出現偏離,這種偏離隨著距離增加,前3個周期攻角峰值高度分別相差0.066°、0.174°和0.256°,峰值位置分別相差0.73 m、1.78 m和2.83 m. 在測量段之后,由于誤差逐漸累積,在第5個運動周期時,平均值計算彈道對應的峰值位置將提前4.93 m,對于本次試驗,這意味著將提前1張紙靶出現攻角峰值。平均值計算彈道第4、第5個峰值高度與獨立辨識彈道的峰值高度之差達到15%和19%,而聯合辨識彈道僅有6%和8.8%. 以攻角計算值δ與對應彈道弧長處的攻角測量值δe之差作為絕對誤差Δδ,以絕對誤差與測量值之比Δδ/δe作為相對誤差,具體如表7所示。 表7 攻角誤差 從表7中可以看出,獨立辨識彈道的誤差最小,聯合辨識彈道誤差次之,平均值計算彈道誤差最大。相對誤差最大的點出現在δ=0°附近,因而該點的相對誤差較大,絕對誤差較小。獨立辨識彈道和聯合辨識彈道的最大絕對誤差分別為0.213°和0.209°,而平均值計算彈道的最大絕對誤差達到了0.631°,由于攻角最大測量值僅為2.9°,故該誤差不容忽視。攻角相對誤差和絕對誤差隨距離的變化如圖7所示。 圖7 攻角誤差Fig.7 Errors of angle of attack 從圖7中可以看出,獨立辨識彈道、聯合辨識彈道和平均值計算彈道相對誤差的2個峰值分別出現在s=45 m和s=90 m處,這兩處均在零點附近,除此之外,最大相對誤差分別為14.7%、14%和40.6%. 最大絕對誤差分別占攻角最大測量值的7.34%、7.21%和21.76%,結合表7中的誤差大小可知,平均值計算彈道的誤差約為其他2條彈道的2~3倍。 對于第4發彈丸,獨立辨識彈道和聯合辨識彈道與測量值的誤差較小,而平均值氣動參數計算的彈道誤差則相對較大。其他5發彈與第4發彈類似,只是誤差數值大小不同。對于全部彈丸,Jm比Jc大139.1%,因此,聯合辨識所得氣動參數更接近實際,全局性更好。 值得注意的是,在氣動辨識中,只有同時計算出CMα、CMqα、CMpα和轉速p,才能得到準確的彈丸角運動周期和阻尼指數。而KS0、KS0、φS0和φF0僅與試驗條件有關,每發彈丸都可能有所不同,故只有同時辨識出以上所有參數,才能得到全局最優解。因此可以認為,只有聯合辨識的結果為全局最優,平均值氣動參數不是全局最優。 由于加工制造誤差及發射條件不完全相同,每發彈丸在實際飛行過程中的真實氣動特性不可能完全相同,且由于飛行環境差異、測量誤差等影響,每發彈丸的辨識結果僅是對該發彈實際條件下的最優估計,不一定是真值,而本文對于多發彈聯合辨識結果,實際上是對這一型或這一批次彈丸氣動特性的最優估計,對于未進行飛行試驗的同型彈丸來說,該辨識結果是對其氣動特性的最可靠預測。 本文提出了一種利用全局優化算法對多發彈測量數據進行聯合辨識的策略,設計了對應的辨識流程。利用某紙靶試驗中多發彈測量數據對該辨識策略進行了驗證,并與現有的氣動辨識方法進行對比,得出以下主要結論: 1)應用本文辨識策略不僅獲得了彈丸氣動參數與狀態初值的全局最優解,還通過利用局部優化算法構建初始搜索空間,進一步提高了計算效率和穩定性,有效地解決了多發彈測量數據聯合辨識氣動參數的局部最優問題,所得辨識結果是對該型彈丸氣動特性的最可靠預測。 2)與現有方法相比,應用本文辨識策略針對多發彈測量數據辨識,所得準則函數更小,重構的彈道與測量值更接近,能更為準確反映彈丸運動規律。 3)差分進化算法應用于多發彈測量數據聯合辨識氣動參數,具有較好的計算穩定性與收斂性,且算法本身無需求導和大矩陣求逆,進一步增強了計算穩定性,適于數據量較大的氣動辨識問題,具有較好的實用性和通用性,為多發彈聯合辨識氣動力參數提供了新的思路。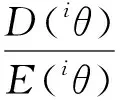
3 一個典型氣動力矩參數辨識問題
3.1 氣動辨識用數學模型
3.2 試驗條件及測量數據

3.3 辨識的收斂性檢驗
3.4 辨識結果與分析


4 結論
猜你喜歡
小學科學(學生版)(2021年5期)2021-07-22 02:40:06中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:02中學生數理化·八年級物理人教版(2019年3期)2019-04-25 06:20:54中學生數理化·八年級物理人教版(2018年3期)2018-05-31 08:52:45數學小靈通(1-2年級)(2017年10期)2017-11-08 08:39:45軍事文摘·科學少年(2017年4期)2017-06-20 23:25:16軍事文摘·科學少年(2017年2期)2017-04-26 21:58:43中學生數理化·八年級物理人教版(2016年3期)2016-04-07 04:49:32少兒科學周刊·兒童版(2016年1期)2016-03-14 03:52:21閱讀與作文(小學低年級版)(2015年4期)2015-04-29 00:00:00
