基于API服務器的爬蟲項目設計與實現
2020-06-13 07:22:14王予諾
電子技術與軟件工程 2020年2期
關鍵詞:頁面
文/王予諾
(西安科技大學 陜西省西安市 710600)
1 前言
在大數據時代,企業所掌握的數據數量決定了該企業的核心競爭力。人們所能接觸的數據數量決定了一個人的知識面和生活質量,如何能有效地選取對自己有利的信息逐漸成為人們所追求的能力。網絡爬蟲可以用來幫助我們獲取有效的數據資源,比如:作為學生的你,是否想知道歷年高考卷題以及答案來復習;作為找工作的你,是否想知道符合你理想條件的公司都有哪些,他們的標準都是什么;作為家庭婦女的你,是否想知道所有蔬菜水果的最佳搭配等。有了網絡爬蟲,我們可以輕松獲取到我們所需的數據,而API server基于C/S模式,模擬客戶端向服務器發送請求,可以輕松獲取到海量資源數據,也滿足你想擁有一個自己的API的愿望。
2 系統設計
該系統分為API和爬蟲兩個重要部分。從結構上可以分為客戶端和服務器端。客戶端包括curl和postman,用于向服務器發送HTTP請求。服務器端包括dbmovie爬蟲部分和API服務器部分。這個系統主要操作過程如下:postman/curl從客戶端發送一個HTTP請求API服務器已經部署成功,服務器通過調用crawler命令執行爬蟲的任務,通過管道將下載的代碼進行處理,生成目標文件,然后通過服務器返回結果,返回到客戶端和顯示一個爬蟲內容。系統總體架構如圖1所示。
在爬蟲框架搭建好的前提下,通過URL發送一個請求到服務器,使用xpath的方法提取的位置信息,在服務器運行正常的情況下,通過一個循環訪問數據,用戶可以接收請求的頁面響應和二進制格式的數據。然后解析器將解析頁面的內容。最后,管道會對二進制數據進行提取和處理,輸出需要的格式并將其保存,比如json格式,保存到本地。爬蟲的工作原理圖如圖2所示,系統功能架構圖如圖3所示。
演示操作過程及結果的視頻如下:
http://www.iqiyi.com/w_19sb2b9fgh.html
3 網絡爬蟲部分的設計實現
3.1 scrapy網絡爬蟲的搭建過程
3.1.1 安裝scrapy框架
Dos命令如下:(先安裝Twisted庫,否則會出錯)
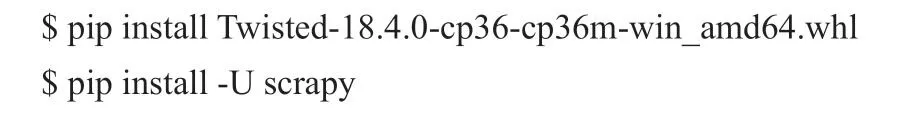
3.1.2 建立項目
命令如下:

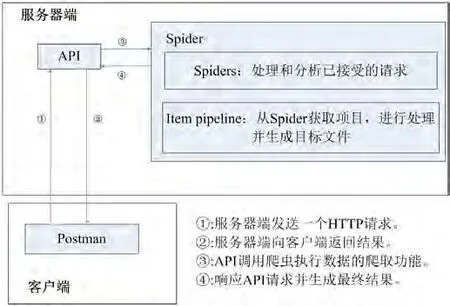
圖1:系統總體架構

圖2:爬蟲工作原理圖
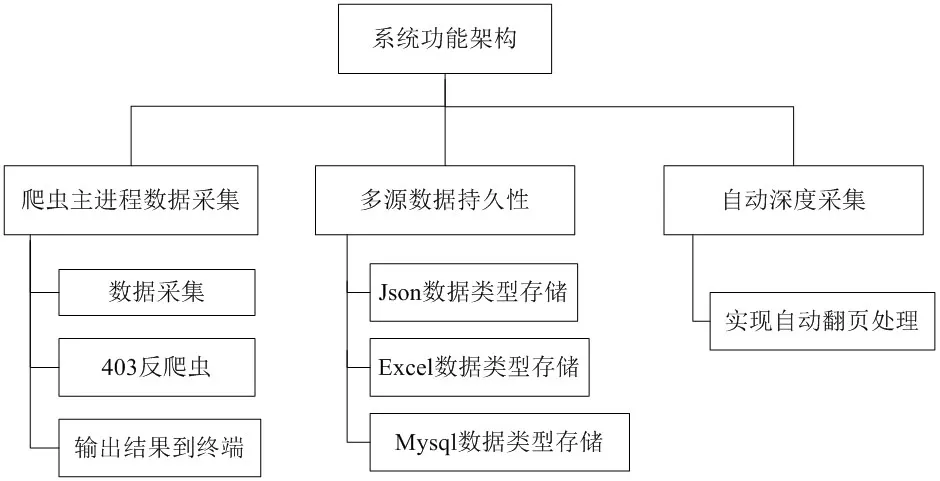
圖3:系統功能架構圖
可以使用以下命令查看項目文件夾結構
$ tree/f
項目文件夾結構說明
items.py:封裝實體類來收集數據
pipelines.py:處理采集到的數據
settings. py:框架核心配置文件
spiders:爬蟲主腳本文件
3.1.3 創建爬蟲腳本
$ scrapy genspider dbmovie https://movie.douban.com/top250
3.1.4 反爬蟲
測試網站連接,此時會有403錯誤,需要設置頁眉信息
$ scrapy shell https://movie.douban.com/top250
此時,我們需要創建一個名為“rotate_useragent”的新代理。在豆瓣電影中實現自動隨機選擇。
核心代碼如下:

并對“設置”進行更改,將rotate_useragent.py配置到框架中。

此時,可以使用shell視圖正常訪問瀏覽器(提示:200)
設置"items.py"來確定收集的數據對象。
核心代碼如下:
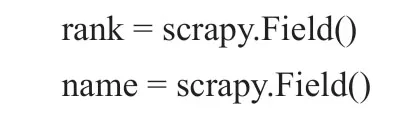
3.1.5 編寫"dbmovie.py"文件來分析HTML標記以獲取數據
核心代碼如下:

3.1.6 編譯"pipelines.py"來設置控制臺輸出。
核心代碼如下:

3.1.7 運行

3.2 爬蟲主進程數據采集的設計
數據收集主要通過提取Xpath中的字段來實現,使用路徑表達式來選擇web頁面中的節點,并通過節點的元素、屬性等來確定特定的信息內容。
“rank”屬性的Xpath提取方法:

“name”屬性的Xpath提取方法:
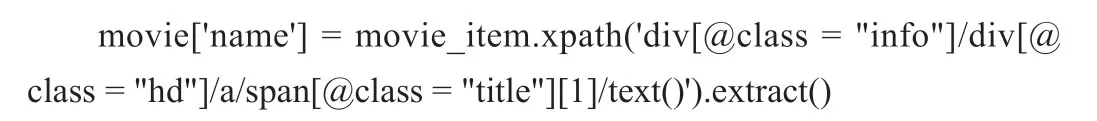
3.3 403反爬蟲的設計
很多網站都有反爬蟲機制,那么什么是反爬蟲機制呢?當我們的crawler剛開始制作的時候,它們通常是簡單的,快速的,但是偽裝度很低。如果我們抓取的網站沒有防爬蟲機制,那么我們可以簡單的抓取大量的數據,但是如果網站有反爬蟲機制,比如檢查報頭信息或者統計IP訪問頻率。一旦網站監視器識別爬蟲程序,例如相同的IP地址和用戶代理總是python,網站將限制對您的IP的訪問。此時,我們需要破解反爬蟲機制。反爬蟲機制可以模擬不同的瀏覽器行為,以一定的頻率改變代理服務器和網關,破解網站的反爬蟲檢測。
首先,我們可以通過“rotate_useragent”快速獲得用戶代理列表。實現自動隨機選擇,核心代碼如下:

然后擴展中間件,編寫user-agent列表,并將公共瀏覽器請求頭作為列表,部分核心代碼如下:

3.4 多元數據持久性的設計
通過對數據的處理,最終可以將數據存儲為:json格式、Excel格式、數據庫格式。當數據量不是很大時,Json存儲是一個很好的選擇。當數據從一個項目傳遞進來時,它被“json.dumps”轉換成json文件。注意,因為“json.dumps”為中文序列化默認的ASCII編碼,需要為最終輸出指定“ensure_ascii = False”,核心代碼如下:

CSV類型是最簡單的保存類型之一。它只需要改進CSV模塊到項目中,并調用“csv.writer”,核心代碼如下:

為了將數據保存在Mysql中,首先需要在Mysql數據庫中創建一個新的表“test”,然后需要將數據庫連接到python代碼中的爬蟲,主要是通過將數據庫的名稱與表的名稱匹配。使用SQL語句將抓取的結果直接存儲到數據庫中,核心代碼如下:


3.5 自動深度采集
自動深度采集模塊主要處理網站的翻頁功能。如果沒有添加自動翻頁,爬蟲將只會運行一次,并且只能抓取一個頁面的內容,這并不能保證它可以抓取排名在前250的所有信息。通過自動翻頁,可以通過xpath方法獲得下一頁的URL,然后判斷“下一頁”是否有效。如果是,將其URL拼接到前一頁,發送請求后完成所有頁面信息的抓取,核心代碼如下:

4 API server部分的設計實現
使用命令“pip install”將所需的Flask模塊導入到項目中,例如Flask、flask_restful、API等。該應用程序是Flask的一個實例,它可以使用包或模塊的名字作為參數,但是它通常會傳遞參數“__name__”,代碼如下:
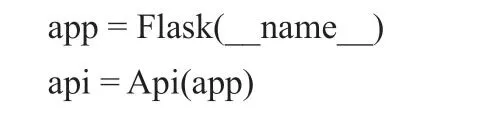
在類中,它繼承自flask_rest。資源類,并定義來自請求的方法,如get、post。我主要定義了一個由“get”提交的請求。在這個方法中,我調用了“Popen”方法來運行爬蟲項目的指令。在“Popen”中,可以使用“cwd”參數指定shell命令應該運行的位置,代碼如下:

如果想將爬網的內容輸出到終端,只需讀取存儲文件的絕對路徑并輸出即可,代碼如下:

最后,在主函數中使用app.run(debug=True,port=9191)啟動API,代碼如下:
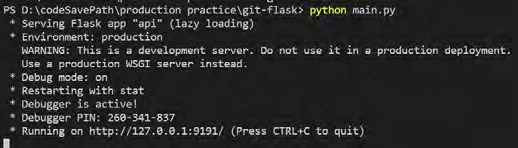
圖4:啟動API服務器
5 API測試
5.1 啟動API服務器
Api服務器搭建完成后,就可以啟動main.py來部署我自己的爬蟲請求,啟動API服務器,如圖4所示。
5.2 利用curl測試
curl是一個文件傳輸實用程序,它使用URL語法從命令行開始工作,測試命令如下:
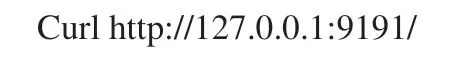
5.3 利用postman測試
postman:這是一個可視化的軟件,用來模擬HTTP請求,幫助人們在后臺的單元工具。它可以自定義請求URL、請求類型[GET、POST等]、添加頭信息和HTTP主體信息等,使我們可以簡單直觀地測試HTTP請求。只需選擇“GET”請求方式,在URL地址欄中輸入“http://127.0.0.1:9191/”,再按“send”按鈕發送請求,就可以在響應欄中得到輸出結果。
6 結語
此項目基于Python語言強大的動態特性和簡單的語法,再加上其用于科學和數值計算的標準庫,使之性能優于其他編程語言。通過網絡爬蟲爬取到的源數據,經過pipelines的處理,可以保存為json、csv、Mysql三種形式,此種網絡數據的采集提供了一種高效的數據采集方式,網絡爬蟲與API server的結合應用,更是為用戶提供了一種簡單、便捷的請求爬蟲的方式,其操作方式以及界面的可視化效果都要遠遠優于網絡爬蟲本身。
猜你喜歡
文萃報·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
電腦愛好者(2022年3期)2022-05-30 10:48:04
工業設計(2016年1期)2016-05-04 03:58:09
通信技術(2012年4期)2012-02-15 07:10:35
電腦愛好者(2011年11期)2011-06-22 08:20:18
網絡安全技術與應用(2011年3期)2011-03-14 06:44:46
赤峰學院學報·自然科學版(2010年11期)2010-09-21 11:30:50
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
