基于彈性網的深度去噪自編碼器異常檢測方法
2020-06-12 09:17:36譚敏生李行健
計算機工程與設計 2020年6期
譚敏生,呂 勛,丁 琳,李行健
(南華大學 計算機學院,湖南 衡陽 421001)
0 引 言
與傳統有線網絡相比,無線網絡更容易受到惡意攻擊。由于無線通信中的傳感節點缺乏監督,惡意攻擊很容易入侵系統并浪費大量資源。為此,學者們從各個角度對異常檢測方法[1,2]進行了研究,如多尺度主成分分析算法(MSPCA[3])、支持向量機(SVM)、K最近鄰算法(K-NN)等。深度學習作為一種很有前景的解決方案[4,5],在處理復雜大規模數據方面有著更出色的性能,一方面,深度學習算法[6]可以揭示輸入數據之間更深層的關系;另一方面,深度學習算法具有更強大的特征提取和表示能力,同時盡可能地保留有關信息。自編碼器[7]作為深度學習的一種新穎降維方法[8],通過使用神經網絡[9]可以找到最佳子空間,捕獲特征之間的非線性相關性。例如,V.L.Cao等[10]提出了結合自編碼器和密度估計的異常檢測方法;Zong等[11]提出了用于無監督異常檢測的深度自編碼高斯混合模型,能避免陷入局部最優;Zhou等[12]提出了一種魯棒深度自編碼器(RDA)來用于異常檢測,但是誤檢率較高;Hong等[13]提出了一種用于高維數據的混合半監督異常檢測模型,降低了計算復雜度;L.Bontemps等[14]提出了基于長短時記憶遞歸神經網絡(LSTM-RNN)的集體異常檢測方法,但存在過擬合現象。
現有研究成果在處理維度不高的數據時,效果不錯,但在處理多元和高維數據時,算法的誤報率較高,性能達不到預期效果。為此,本文提出一種基于彈性網的深度去噪自編碼器異常檢測方法,用正常數據對基于彈性網的深度去噪自編碼器進行訓練獲得數據的重構誤差閾值,來對數據進行異常檢測。
1 深度自編碼器
自編碼器(AE)是一種無監督[15]的三層神經網絡,將輸入壓縮成潛在的空間表征來重構輸出,利用反向傳播算法使輸出值盡可能等于輸入值。自編碼器由編碼器和解碼器構成,如圖1所示。
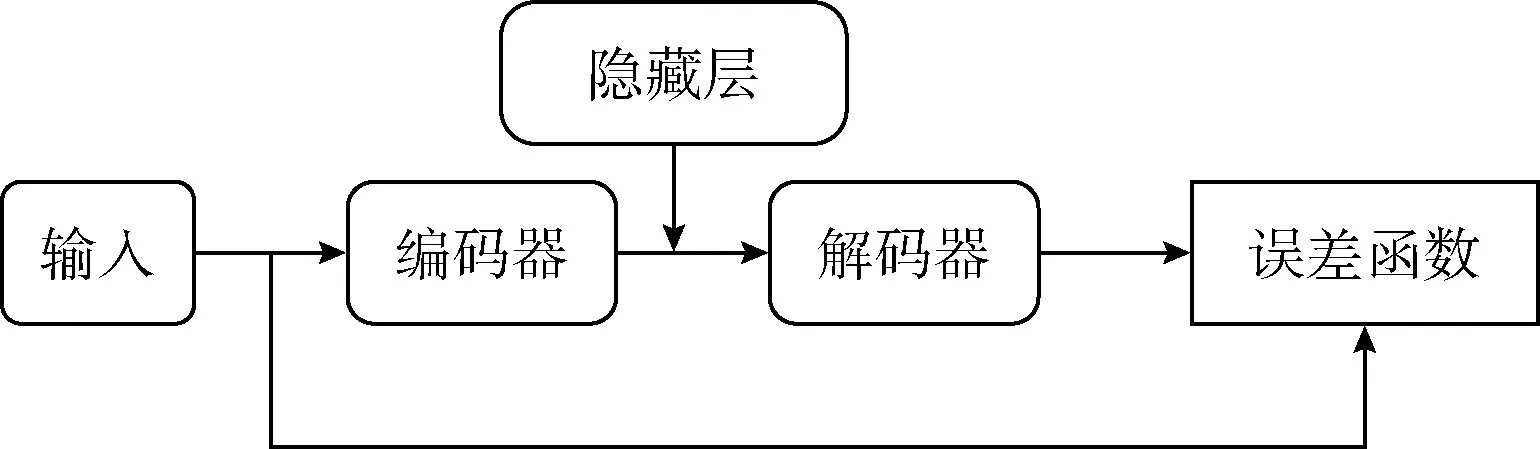
圖1 自編碼器模型
深度自編碼器(DAE)是由多個自編碼器端到端連接組成的神經網絡,前一層自編碼器的輸出作為下一個自編碼器層的輸入,以獲得輸入數據的更高級別特征表示,逐步將特定特征向量轉換為抽象特征向量,實現從高維數據空間到低維數據空間的非線性轉換。深度自編碼器結構如圖2所示。
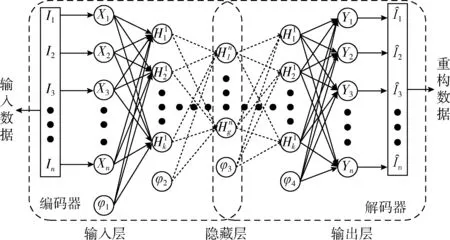
圖2 深度自編碼器結構
深度自編碼器的工作過程可分為兩個步驟:編碼和解碼,這兩個步驟可定義為:
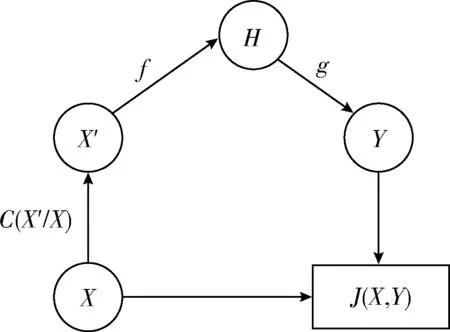
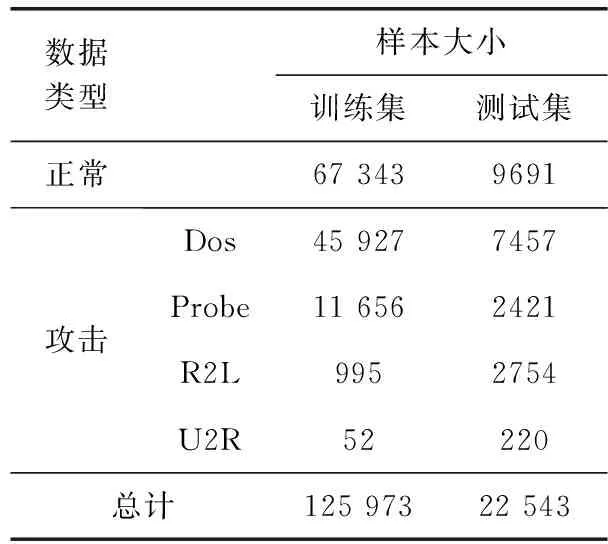
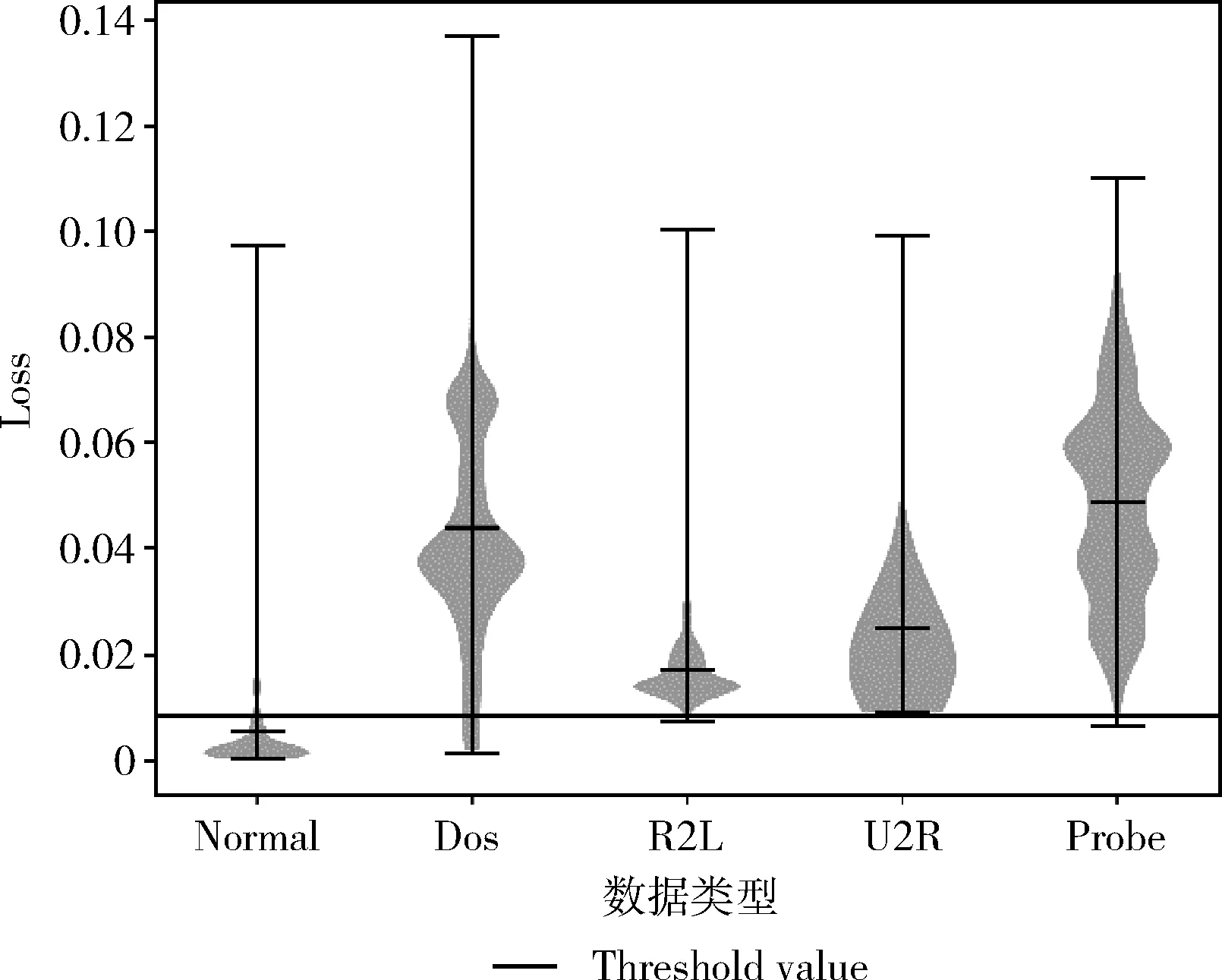
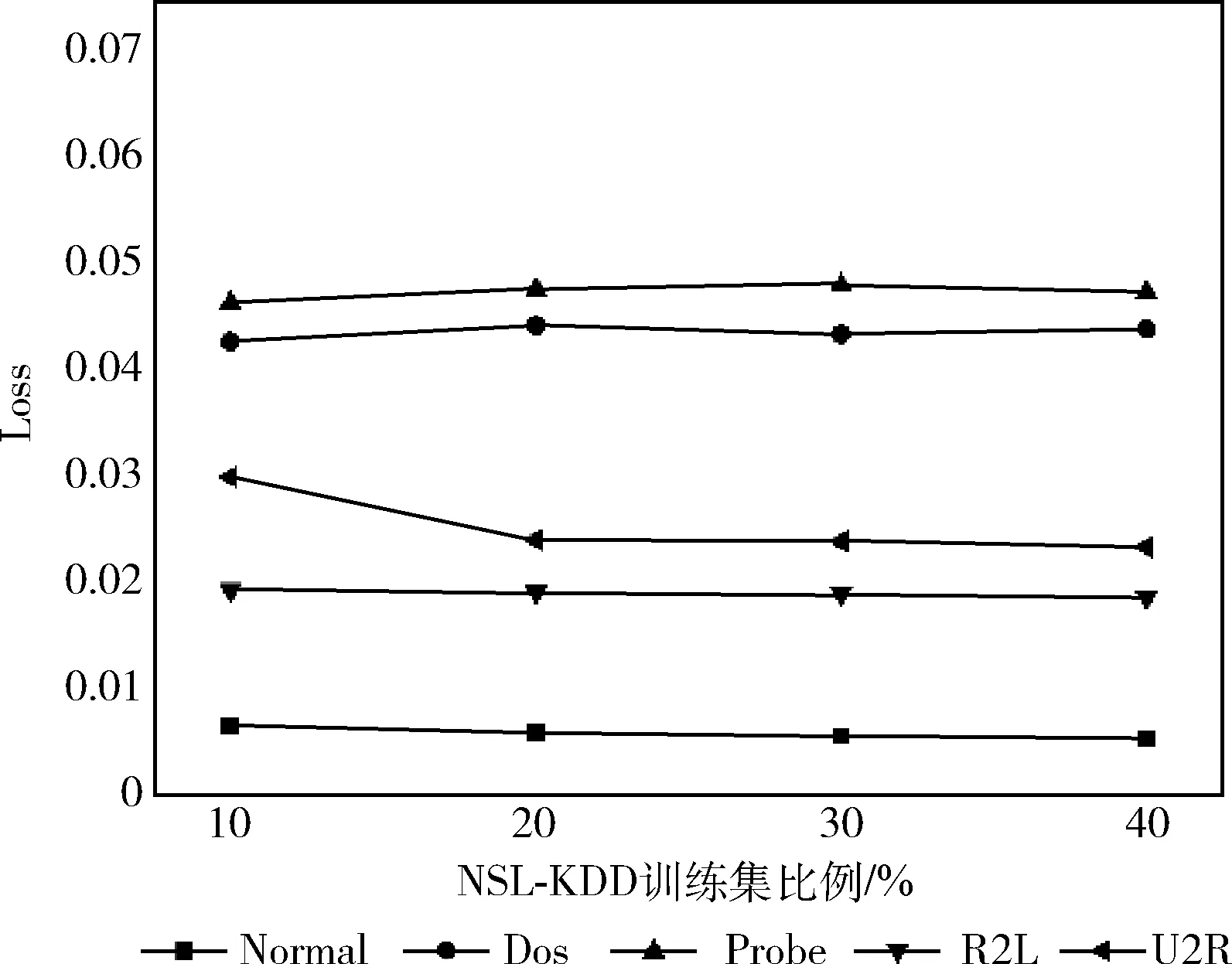
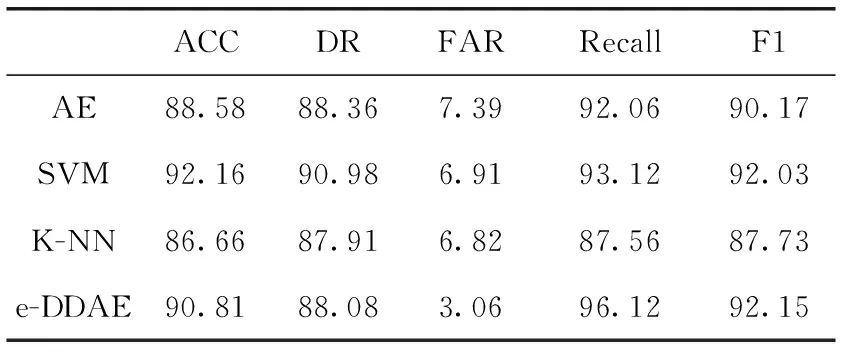
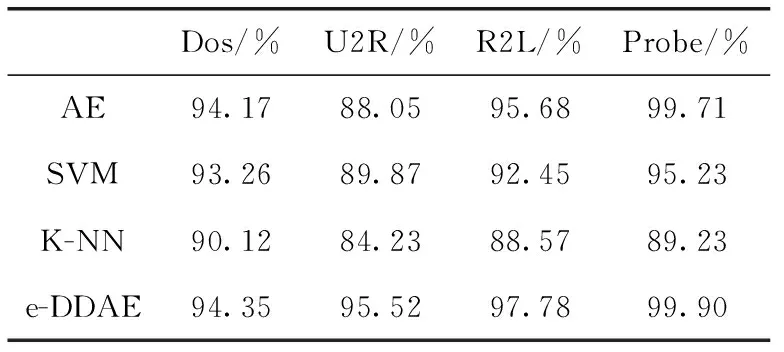
編碼:輸入向量(Xn∈Rd)被壓縮成構成隱藏層的mm (1) 其中,X為輸入向量,θ為參數Winput,φinput,W表示大小為m×d的編碼器權重矩陣,φ表示維數為m的偏置向量。 解碼:將得到的隱藏層輸出Hi解碼回原始輸入空間Rd,映射函數如下 (2) 其中,解碼器的參數θ′=Whidden,φhidden,Y是輸入數據后的重構向量,fθ(·)和gθ′(·)分別表示隱藏層神經元和輸出層神經元的激活函數,激活函數是非線性函數,用以揭示輸入特征之間的非線性相關性。本文采用relu函數和tanh函數作為激活函數,relu函數和tanh函數表達式如式(3)和式(4)所示 (3) relu(x)=max(0,x) (4) 通過訓練自編碼器來重構原始數據,調整編碼器和解碼器的參數,使輸出重構數據和輸入數據之間的誤差最小化,即誤差函數最小,把編碼器最后一層隱藏層的輸出數據作為輸入的最佳低維數據。重構誤差函數JE(W,φ)用式(5)所示均方差函數表示 (5) 深度自編碼器是由多個自編碼器端到端連接而形成的神經網絡,相比簡單的自編碼器,深度自編碼器能更好的逐層學習原始數據的多種表達,刻畫更復雜的特征。θ,θ′用均方誤差函數來優化深度自編碼器的參數 (6) 其中,n表示樣本數量,JE表示均方差函數。將訓練集中一部分標簽為“正常”的數據去訓練基于彈性網的深度去噪自編碼器,對重構誤差進行閾值處理,利用正常數據與異常數據的重構誤差值,來對不同數據特征進行分類。 為了提高網絡的泛化能力和抗擾動能力,使結構風險最小化,在深度自編碼器的隱藏層輸出值加入某種約束,降低不重要特征的權重。一般在自編碼器中加入正則化,可用L1范數來正則化,L1范數符合拉普拉斯變換,是指權值向量W中各個元素的絕對值之和,可以產生稀疏權重矩陣即產生一個稀疏模型,用于特征選擇,這樣式(6)更新為如下表達式 (7) 也可以利用L2范數來正則化,L2范數符合高斯分布,是完全可微的,指權值向量W中各個元素的平方和然后再求平方根,也就是歐幾里得距離之和,這樣式(6)更新成如下表達式 (8) 而彈性網的正則化是L1和L2懲罰函數的線性混合,所以基于彈性網的深度自編碼器的重構誤差函數如式(9)所示 (9) 利用參數λ2可以控制稀疏性,利用參數λ1可以防止網絡過擬合,最小化重構誤差,提高網絡的泛化能力。 自編碼器是高度非線性的,通過在輸入層添加噪聲,可以提高自編碼器的重構能力。如圖3所示,引入一個損壞過程C(X′/X)將輸入X進行處理后產生一個損壞樣本X′,然后再對數據X′進行重構。本文使用加性高斯噪聲作為對輸入數據進行處理,通過引入噪聲使學習到的特征更具魯棒性,從而給深度自編碼器帶來更好的性能。 圖3 去噪自編碼器訓練過程 考慮到網絡中存在約束,對不同參數使用不同的學習速率,例如降低不頻繁特征的更新頻率。然而,大多數傳統流行的梯度下降算法包括隨機梯度下降和小批量梯度下降,對網絡中所有需要更新的參數使用相同的學習速率,使得難以選擇合適的學習速率以及容易陷入局部最小。因此,為了訓練更好的深度網絡,本文使用自適應矩估計(Adam)梯度下降算法[16]來實現不同參數的動態自適應調整,Adam算法通過計算梯度一階矩估計mt和二階矩估計vt來實現不同參數的動態調整,調整方法如式(10)~式(15)所示 mt=β1mt-1+(1-β1)gt (10) (11) (12) 計算mt和vt的偏差矯正 (13) (14) (15) β1和β2分別表示一階和二階的矩估計指數衰減率,gt表示損失函數中時間步長t的參數梯度,γ表示更新的步長,ξ表示采用一個很小常數來防止分母為零。 本文把[122-110-90-10-90-110-122]作為深度網絡的結構。由于輸入數據是122維,所以把輸入層的神經元數設為122,在神經元數為10的隱含層中采用relu函數作為激活函數,其余層的激活函數采用tanh函數。 在訓練階段使用標簽為“正常”的數據進行訓練,則相應的測試集中正常數據的重構誤差會較小,而異常數據將具有相對較高的重構誤差。通過對重構誤差進行閾值處理,可以對惡意數據進行分類,如式(16)所示 (16) 基于彈性網的深度自編碼器網絡異常檢測算法(e-DDAE)主要步驟如下: 步驟1 數據預處理。使用獨熱(one-hot)編碼對NSL-KDD數據集進行符號特征數值化,然后對數據進行最小最大歸一化處理,將所有特征轉換為[0,1]的范圍。 步驟2 構建彈性網正則化的深度自編碼器。根據式(7)-式(9),在深度自編碼器的損失函數中加入彈性網正則化即L1和L2范數的線性混合,使得重構誤差函數最小化。 步驟3 對彈性網正則化的深度自編碼器的輸入數據加入高斯噪聲,提高深度自編碼器重構能力,根據式(10)-式(15),用Adam算法對網絡進行優化,對輸入數據進行降維重構,把輸入數據壓縮降維到10維,再重構為122維數據。 步驟4 自編碼器訓練。在訓練階段,抽取NSL-KDD訓練集中90%的標簽為“正常”數據樣本作為基于彈性網的深度去噪自編碼器的訓練集,剩下的10%的“正常”數據作為驗證集,并結合BP算法來訓練基于彈性網的深度去噪自編碼器,用驗證數據集進行測試,使其能夠捕獲正常數據的特征。通過訓練基于彈性網的深度去噪自編碼器,構建正常數據的重構誤差閾值。 步驟5 自編碼器檢測。將測試數據集輸入到自編碼器網絡中并根據式(16)進行分類,把訓練集的重構誤差作為異常閾值,重構誤差低于閾值的數據將被分類為正常,高于閾值的數據則被分類為異常。 使用NSL-KDD數據集來評價基于彈性網的深度去噪自編碼器異常檢測算法(e-DDAE),NSL-KDD數據集在KDD99數據集基礎上得到了改進,消除了KDD99數據集中的冗余數據。NSL-KDD數據集包含125 973個訓練樣本和22 543個測試樣本,包括拒絕服務攻擊(Dos)、探測攻擊(Probe)、遠程到本地攻擊(R2L)、用戶到根攻擊(U2R)這4種攻擊樣本類型,具體分布見表1。 表1 NSL-KDD數據集攻擊數目和分類 NSL-KDD數據集包含41個屬性特征,使用獨熱(one-hot)編碼來對數據集數字化。NSL-KDD數據集的符號特征包括“Protocol_type”,“Service”和“Flag”,其中“Protocol_type”包括TCP,UDP,ICMP這3種不同的協議類型,“Service”包括70種不同的符號特征值,“Flag”包括11種不同的符號特征值。因此,在完成數字化處理后,NSL-KDD數據集的41維特征數據擴展為122維。 為了將特征統一量綱,提高算法收斂速度和精度,使用式(17)歸一化方法來處理NSL-KDD數據集中的特征值,將特征線性映射到[0,1]區間上。xmax和xmin分別表示原始特征最大值和最小值,x表示原始特征值 (17) 本文使用基于混淆矩陣的方法來評估實驗結果,混淆矩陣的定義見表2,TP(true positive)表示預測為正常的正常數據,TN(true negative)表示預測為攻擊的攻擊數據,FP(false positive)表示被預測為正常的攻擊數據,FN(false negative)表示被預測為攻擊的正常數據。 表2 混淆矩陣 本文使用的度量指標主要包括ACC(準確度)、FAR(誤報率)、DR(檢測率)、Recall(召回率)、F1值(F1 score),定義如下 (18) (19) (20) (21) (22) 實驗采用Adam優化算法,學習率取0.001,batch-size設置為128,網絡迭代次數設置為20,懲罰項系數λ1=0.0001,λ2=0.00001,β1=0.9,β2=0.999,ξ=10e-8。 e-DDAE算法構建一個深度去噪自編碼器,在損失函數中加入彈性網正則化,抽取訓練集中標簽為“正常”的數據來訓練網絡以獲得重構誤差閾值,利用閾值和自編碼器來對測試集數據進行分類。實驗通過正常數據和異常數據的重構數據值的分布來評估e-DDAE算法的有效性。 圖4的提琴圖顯示了測試集中所有數據樣本的重構損失值的分布,從圖中陰影部分也就是數據的分布密度可以明顯看出,異常數據(攻擊數據)的重構值基本要高于閾值,而正常樣本的數據要低于閾值。 圖4 不同數據重構誤差值分布 圖5是NSL-KDD數據集中不同訓練集比例下5種不同數據重構誤差值,可以明顯看出,隨著訓練集比例的增加,正常數據的重構誤差值明顯低于其它4種攻擊類數據,其中R2L攻擊和U2R攻擊數據的重構誤差值要比其它兩種攻擊的重構誤差值低,說明本文提出方法可以有效地對異常數據進行檢測。 圖5 不同訓練集比例下5種數據的重構誤差值 為了更好地分析本文e-DDAE算法的性能,從準確率、誤報率、精確率、召回率和F1值方面與AE算法(自編碼器算法)、SVM算法(支持向量機算法)、K-NN算法(K最近鄰算法)進行對比,實驗結果見表3。 表3 不同分類算法性能比較/% 從表3可以看出,e-DDAE的召回率比AE、SVM、K-NN分別提高了4.06%、3%、8.56%;e-DDAE的F1值比AE、SVM、K-NN分別提高了1.98%、0.12%、4.42%;e-DDAE誤報率比AE、SVM、K-NN分別降低了4.33%、3.85%、3.76%;e-DDAE分類準確率比AE提高了2.23%,比SVM略低了1.35%、比K-NN提高了4.15%;e-DDAE檢測率比AE略低了0.28%,比SVM略低了2.90%,比K-NN提高了0.17%。 e-DDAE算法的靈敏度高,總體性能良好,在保證較好的分類準確率和檢測率的情況下,召回率和F1值明顯提高,誤報率明顯降低。 e-DDAE等4種算法對數據集中4種攻擊類數據被分類為異常數據的準確率見表4,可以看出,在Dos攻擊類數據方面,e-DDAE比AE、SVM、K-NN分別提高了0.18%、1.09%、4.23%;在U2R攻擊類數據方面,e-DDAE比AE、SVM、K-NN分別提高了7.47%、5.65%、11.29%;在R2L攻擊類數據方面,e-DDAE比AE、SVM、K-NN分別提高了2.10%、5.33%、9.21%;在Probe攻擊類數據方面,e-DDAE比AE、SVM、K-NN分別提高了0.19%、4.67%、10.67%。e-DDAE算法對不同攻擊類數據被分類為異常數據的準確率明顯高于其它同類算法。 表4 不同算法對不同攻擊數據的分類準確率比較 本文提出了一種基于彈性網的深度去噪自編碼器網絡異常檢測方法,在構建深度去噪自編碼器中加入彈性網正則化,用經過預處理的訓練集中的一部分“正常”標簽數據去訓練網絡,獲得數據的重構誤差閾值,通過自編碼器和閾值來檢測網絡異常數據,避免了人為操縱閾值帶來的主觀影響。實驗結果表明,該方法的檢測性能優于其它的異常檢測方法,在保持了較高分類準確率和檢測率的同時,降低了誤報率,提高了召回率和F1值,對不同攻擊類數據被分類為異常數據的準確率也優于其它算法。2 基于彈性網的深度去噪自編碼器構建
3 基于彈性網的深度去噪自編碼器異常檢測方法
4 實驗與結果分析
4.1 實驗數據集
4.2 數據預處理
4.3 實驗評估指標與設置

4.4 實驗結果分析
5 結束語
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
