基于Mahout與協同過濾算法的中醫調理文章推薦引擎
2020-06-11 09:26:34劉艷方田劉嘉慧戴彩艷王珍
電子技術與軟件工程 2020年1期
關鍵詞:用戶
文/劉艷 方田 劉嘉慧 戴彩艷 王珍
(南京中醫藥大學人工智能與信息技術學院 江蘇省南京市 210023)
1 引言
隨著信息的快速增長,每天都有多種多樣的中醫養生調理方案產生,過多的數據導致被動獲取的信息過載,怎樣快速地獲取用戶感興趣且有用的信息呢?通過中醫調理文章的推薦信息管理系統,可以有效的解決這個問題。其主要的任務之一就是通過聯系更多的用戶與推薦平臺,解決推薦信息資源過載的問題,提升用戶推薦的質量,提高用戶的滿意度。
本文利用基于用戶的協同過濾推薦算法,分析智慧血壓監測與健康管理APP中用戶上傳的資料和用戶歷史數據,挖掘用戶相似度,引入屬性相似度概念,實現了一個基于Mahout 的中醫養生調理文章推薦系統,可以智能選取用戶感興趣的調理文章,每日推送相關的中醫調理方法。
2 Mahout研究
Mahout 是Apache 軟件基金會(全稱Apache Software Foundation,也簡稱ASF)旗下的一個經典算法開源項目,集成了各式各樣的聚類、推薦等算法,是一個很好用的經典算法工具集,可以更好地幫助我們去理解和學習這些算法,并在此基礎上對它們加以系統性的研究和創造性的改進。在目前被廣泛采用的機器智能學習數據分析技術中,Mahout 主要用于推薦引擎、聚類和分類。
Taste 是Mahout 基于Java 的一個推薦實現,Taste 不僅可以實現基本的基于用戶的和基于內容的協同過濾算法,還可以實現比較高效的SlopOne 算法和基于SVD 和線性插值的推薦算法,同時也為個性化推薦算法的實現提供了一個可擴展接口,使得用戶可以很方便的使用和設計完成自己的推薦算法,也較好的滿足了企業對個性化推薦引擎在性能、靈活性等諸多方面的更高要求[2]。Mahout協同過濾算法的具體包含如圖1 所示。
3 協同過濾算法研究

圖1:Mahout 協同過濾算法圖

圖2:用戶分析圖(左)和“物品—用戶”倒排表圖(右)
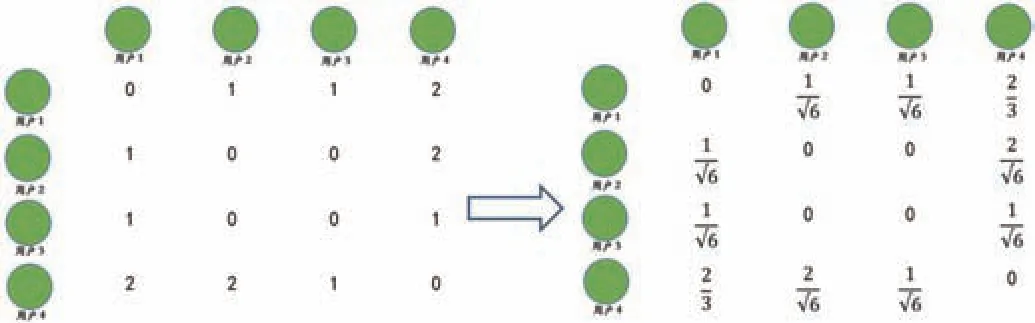
圖3:用戶矩陣圖(左)和用戶相似度矩陣計算圖(右)
3.1 協同過濾算法
協同過濾推薦算法是較為著名且誕生最早的推薦算法,其主要的功能是推薦和預測。算法主要是通過利用對用戶歷史瀏覽記錄和行為數據的統計與分析,進行挖掘發現每個用戶的喜好,基于各式各樣的喜好數據可以對每個用戶進行協同劃分,預測用戶的喜好,然后對用戶進行相應的喜好內容推薦。并且協同過濾最大的優點是對推薦的對象本身沒有特殊的結構化要求,能夠有效處理非結構化的復雜對象,如網絡小說,音樂等。
協同過濾推薦算法主要分為兩大類,一是基于用戶的協同過濾算法,二是基于物品的協同過濾算法。這兩種算法各有優勢,根據智慧血壓監測與健康管理APP 的實際情況,我們采用了基于用戶的協同過濾算法。
3.2 基于用戶的協同過濾算法
本算法是通過研究用戶的歷史行為數據,發現用戶對文章的喜歡,比如文章收藏,內容評論或分享等,然后對這些喜歡的文章進行打星或打分。算法主要的流程是:首先,找到和目標用戶喜好相似的用戶推薦集合;然后,找到這個推薦集合中目標用戶非常喜歡,且目標用戶沒有看過的文章推薦給目標用戶。
假設有4 個用戶購買了5 種不同圖書,如圖2 用戶分析圖所示。如何找到與目標用戶喜好相似的用戶呢?首先我們可以建立一張“物品—用戶”的倒排表,如圖2 的“物品—用戶”倒排表圖所示,可以清晰的看出每本書被哪些用戶購買。
然后利用“物品—用戶”的倒排表,構建用戶相似矩陣,其中的值,表示用戶和用戶之間共同喜歡的圖書的數量,如圖3 中的用戶矩陣圖所示。而后,可以通過余弦相似度公式(1)計算用戶與用戶之間的相似度,對用戶矩陣進行進一步的分析計算,如圖3 中的用戶相似度矩陣計算圖所示。
余弦相似度:

由上述步驟,可以很清楚的幫助目標用戶找到與其興趣相似的用戶集合。但是由于傳統的協同過濾算法僅僅是依靠用戶對項目的評分,用戶瀏覽記錄等信息,這樣容易導致用戶之間的相似度計算不準確。本文考慮將從用戶評分、用戶瀏覽等信息以外的用戶基本資料中挖掘到的用戶基本屬性相似度(稱屬性相似度)結合到協同過濾算法中,形成一種融合相似度,更好的幫助智慧血壓監測與健康管理APP 上的用戶進行個性化推薦。
4 中醫調理文章推薦算法設計
4.1 收集用戶數據
在智慧血壓監測與健康管理APP 上的用戶個人信息數據包括注冊用戶ID、性別、年齡、文章編號ID、文章分數、舒張壓、收縮壓、呼吸頻次、脈搏跳動次數、體溫等相關數據。本文將瀏覽文章分數作為文章的偏好程度的衡量依據,根據用戶ID,文章ID、文章分數這三種數據用于計算傳統的相似度,由皮爾遜相關系數計算,其他數據用于計算屬性相似度,增加相似度的準準確率。
4.2 計算相似度
4.2.1 皮爾遜(Pearson)相關系數
通過Pearson 相關系數計算傳統相似度,與余弦相似度相比,皮爾遜相關系數的特點是將數值“中心化”,首先將每個向量的所有分量都減去分量均值,再求余弦相似度。皮爾遜相關系數的絕對值越大,即相關系數越是接近于1 或-1,相關性越強,相關系數越是接近于0,相關性越弱[4]。
皮爾遜相似度:

4.2.2 屬性相似度
根據采集的用戶個人資料中的年齡、性別、舒張壓、收縮壓、呼吸頻次、脈搏跳動次數和體溫等的統計數據,當用戶與用戶之間屬性相同或屬性值相近時,則增加一個單位,得到的總數除以屬性總數,得到屬性相似度。
4.2.3 融合相似度
設置一個alpha 值(小于1),作為行為相似度(即由皮爾遜相關系數計算的相似度)占的比例,則屬性相似度占的比例則為1-alpha,計算公式為:
融合相似度=alpha×行為相似度+(1-alpha)×屬性相似度
4.3 建立評估推薦器,實現推薦系統
首先如何讓推薦器有一個好的結果,評估推薦器是一個很有必要的工具。評估推薦器的方法有多種,其中一種是評估它所可能產生的偏好指數與真實喜好程度的匹配程度,即預測準確度。

表1:部分推薦結果數據

圖4:基于用戶的協同過濾流程圖
評估推薦器可以利用平均絕對誤差(MAE)作為度量指標,來計算預測分數與真實分數之間的絕對變差的平均值。與平均誤差相比,平均絕對誤差不會出現正負相抵的情況,能更好的反應推薦性能的好壞[10]。平均絕對誤差越小,則說明推薦系統的性能越好,推薦越準確。u:測試集中的用戶,i:物品,rui:用戶對物品的實際評分,推薦算法給出的預測評分,MAE 平均絕對誤差具體公式如下:

而后,利用Mahout 里的Taste 組件來實現推薦系統,首先將數據加載到內存中,加載各個用戶瀏覽文章的信息,連接數據庫查詢用戶的屬性和體質信息,計算相似度(皮爾遜相似度和屬性相似度),而后計算固定大小的領域,構建基于用戶的協同過濾推薦器,生成推薦引擎,最后輸出推薦結果。基于用戶的協同過濾流程如圖4 所示。
4.4 推薦結果
本文所取的文章數據集是39 健康網中醫文章導讀搜集到的數據,系統運行后得到的推薦結果如表1 所示。
5 總結
在傳統的基于用戶的協同過濾算法上引入了屬性相似度,增加了相似度的可靠性和準確度,提高了推薦性能。利用評估推薦器計算平均絕對誤差評測,來衡量推薦器的好壞,使推薦器性能有一定的保障。在智慧血壓監測與健康管理APP 上構建基于Mahout 的推薦器,不僅對開發來說更方便,也給用戶推薦物品時帶來便捷,給智慧血壓監測與健康管理APP 帶來流量。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
