基于GAN網絡的面部表情識別
2020-06-11 09:26:08陳霖段巍劉立志
電子技術與軟件工程 2020年1期
文/陳霖 段巍 劉立志
(1.中國電子科技集團公司第二十八研究所 江蘇省南京市 210000 2.武警天津市總隊參謀部 天津市 300000)
1 引言
面部表情識別是計算機視覺中最重要的任務之一,它在心理學、教育、數字娛樂、駕駛員監控等許多應用中起著至關重要的作用。面部表情識別旨在將給定的表情分析并分類成幾種特定的情緒類型,其過程主要有兩個階段,即特征提取和表情識別。在現有的方法中,大多數表情識別只基于正面面部圖像,對于任意姿態下的表情識別問題亟需解決。近年來,深度網絡已廣泛用于計算機視覺的各種任務,基于深度網絡的面部表情識別[1]問題也得到了發展,但使用深度模型需要足夠的標記數據來訓練,目前人臉表情識別中大部分數據庫中的數據量非常有限。因此,本文設計了一個基于生成對抗網絡(GAN)的模型生成更多的圖像擴充訓練集,同時并將分類器嵌入到GAN 網絡中實現面部表情識別。
2 基于GAN網絡的面部表情識別方法
2.1 面部表情識別
現有的表情識別過程分為特征提取和表情識別兩個階段。傳統的用于特征提取的方法主要包括SIFT[2]、LBP、Gabor 以及Geometry 等。本文采用卷積神經網絡(CNN)方法提取特征。特征提取后,將其輸入到表情的分類模型中參與訓練,進行表情識別。常用的表情分類模型主要有SVM、KNN 以及隨機森林等。得到相應的表情分類模型之后,即可針對一張給定的圖像進行表情分類任務。與現有的方法不同,為解決任意姿態下的面部表情識別問題,本文采用GAN 網絡的變體生成具有不同姿態和表情的面部圖像,并將分類器嵌入到GAN 網絡中訓練,實現一個端到端的深度學習模型。
2.2 生成對抗網絡(GAN)
GAN 網絡[3]是一種深度學習模型,包括一個生成模型與一個判別模型。生成模型用于接收一個隨機的噪聲,通過噪聲生成數據或圖片。判別模型包含兩類輸入,一類是生成的噪聲數據,另一類是從現實場景中采集到的真實數據。可以把判別模型看作一個二分類器,輸出的是一個概率值,用來判別輸入的樣本的真假,當輸出值大于0.5 說明樣本為真即來自現實場景中采集到的真實數據,反之樣本為假即來自生成器生成的噪聲數據。生成模型與判別模型是兩個獨立的模型,使用交替迭代的訓練方式。在訓練過程中,不斷優化生成模型,使得生成模型盡量生成服從真實數據分布的數據,不斷優化判別模型,直到對于生成的圖片判別模型不再能判別出其真假。生成模型與判別模型的目的正好是相反的,所以稱之為對抗。
2.3 GAN網絡與表情識別
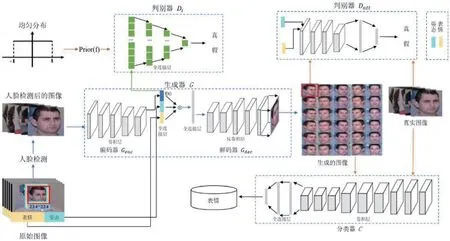
圖1:模型架構圖
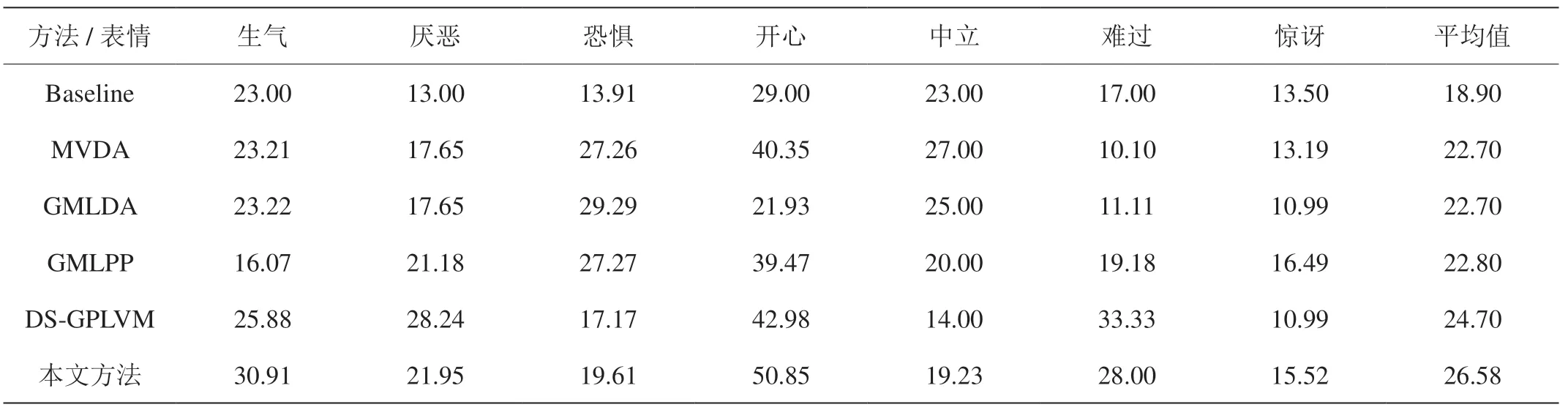
表1:本文的方法與現有的方法準確率對比
本文提出的方法模型包括一個生成器,兩個判別器和一個分類器,如圖1。將原始圖像輸入到生成器之前,先使用人臉檢測算法[3]去除背景之類的冗余信息。經過預處理后,將面部圖像輸入到由一個編碼器(Genc)和一個解碼器(Gdec)構成的生成器中。經過編碼器處理后,得到一個關于人臉圖像特征的表示,記作f(x),然后把人臉圖像特征、姿態和表情的編碼輸入到解碼器中,生成一張新的人臉圖像。之后,通過判別器(Datt)與生成器之間的對抗可以解開人臉圖像特征、表情以及姿態之間的關系。將其關系解開后,加入新的姿態編碼以及新的表情編碼可以生成大量不同姿態以及不同表情下的人臉圖像,促進表情識別任務的完成。同時,為了提高生成圖像的質量,加入另外一個判別器(Di)。在這個判別器中,把從均勻采樣中得到的數據當作正樣本,把經過編碼器處理后的人臉圖像特征當作負樣本,通過兩者之間的對抗可以使得人臉圖像特征滿足均勻分布,從而提高生成圖像的質量。最后,用生成的人臉圖像與原始圖像共同訓練分類模型。
生成器G 與判別器Datt的對抗學習過程:
x 代表經過預處理后的面部圖像,條件y 代表表情和姿態的編碼信息,用one-hot 向量表示,G(x,y)是由生成器生成的數據。這里加入條件y 有助于生成器在生成具有不同表情和不同姿態的圖像的同時保持人臉圖像特征不變,擴充了數據集,解決訓練集數據量不足的問題,推動當下姿態不變的面部表情識別問題的發展。真實的圖像滿足pd(x)分布,判別器通過圖像的分布信息來判別圖像的真假。通過生成器G 與判別器Datt之間的對抗訓練可以得到一個用于任意姿態與任意表情下圖像生成的模型,該訓練過程滿足式(1):
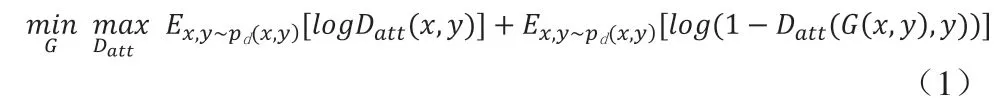
生成器G 與判別器Di的對抗學習過程:
假設prior(f)滿足某種先驗分布,則 f*~prior(f)表示從先驗分布中隨機采樣的過程。將從先驗分布中采樣的樣本當作正樣本,將經過生成器中的編碼器處理后的人臉圖像特征f(x)當作負樣本,通過生成器G與判別器Di之間的對抗訓練可以得一張滿足均勻分布、高質量的人臉圖像,該訓練過程滿足式(2):
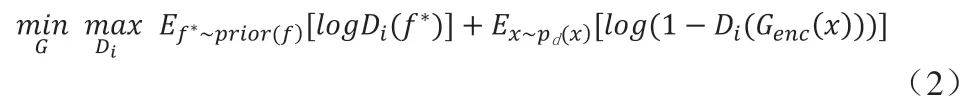
最后,將生成的圖像與原始圖像同時輸入到分類模型C 中訓練,兩項交叉熵作為損失函數,前一項交叉熵用生成的圖像來訓練,后一項用原始圖像進行訓練:
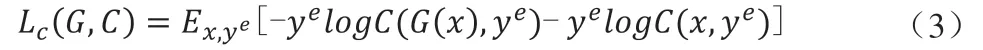
為了保障生成圖像與原始圖像之間的人物一致性,加入了一個l1范式進行約束:

3 實驗結果
本文提出的方法在SFEW[4]數據集上得到了驗證,如表1,對比現有的方法,該方法在七個基本表情上的平均識別準確率是所有方法中最高的,以此證明了該方法的有效性。
4 總結
本文提出了一個端到端的深度學習模型,在進行面部圖像合成的同時解決了姿態不變的面部表情識別問題。通過解開面部圖像中的人臉特征、姿態以及表情之間的關系,生成具有任意表情以及姿態的面部圖像擴充訓練集,以此提高模型的準確率,并在數據集SFEW 上得到了有效的驗證,與現有的面部表情識別方法相比,取得了最高的準確率,為面部表情識別方法的發展做出了相應的貢獻。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
