一種支持稀疏卷積的深度神經(jīng)網(wǎng)絡(luò)加速器的設(shè)計
2020-06-10 07:40:46周國飛
電子技術(shù)與軟件工程 2020年4期
關(guān)鍵詞:設(shè)計
周國飛
(上海齊感電子信息科技有限公司 上海市 200120)
1 概述
自從2012年AlexNet算法發(fā)布以來,深度神經(jīng)網(wǎng)絡(luò)技術(shù)(Deep Neural Networking)在圖像識別、語音處理、自然語言處理(NLP)等非結(jié)構(gòu)化數(shù)據(jù)處理領(lǐng)域和廣告分類、搜索優(yōu)化等結(jié)構(gòu)化數(shù)據(jù)處理領(lǐng)域都得到了廣泛應(yīng)用。 深度神經(jīng)網(wǎng)絡(luò)算法對于硬件算力的需求也在近幾年以每月翻番的速度遞增,遠遠超過了芯片摩爾定律的增長速度[1]。本文針對深度神經(jīng)網(wǎng)絡(luò)的計算需求,定制設(shè)計一種新型的深度神經(jīng)網(wǎng)絡(luò)加速器(Deep Neural Networking Accelerator,簡稱DNNA),提高深度神經(jīng)網(wǎng)絡(luò)的計算效率,提高神經(jīng)網(wǎng)絡(luò)輸入數(shù)據(jù)的復(fù)用率,可集成在SoC芯片上實現(xiàn)低功耗邊緣推理。
深度神經(jīng)網(wǎng)絡(luò)的算法特征:
(1)包含多層卷積運算和矩陣數(shù)據(jù)的后處理計算;
(2)模型參數(shù)的數(shù)據(jù)量大,各層卷積有數(shù)十到數(shù)千個輸入通道(Input Channel)和輸出通道(即權(quán)重核數(shù));
(3)卷積計算是多重循環(huán)的乘法和加法運算,輸入數(shù)據(jù)按不同維度被重復(fù)參與計算;
(4)卷積計算具備稀疏性,即通過訓(xùn)練得到的模型權(quán)重可能包含很多的零值。
針對上述算法特征,本文DNNA的優(yōu)化設(shè)計一是對不同尺寸參數(shù)的卷積計算做動態(tài)適配,優(yōu)化計算的并行度;二是對稀疏卷積可以節(jié)省零值權(quán)重的計算時間,均衡非零權(quán)重的算力,提高計算單元的利用率。
2 DNNA的數(shù)據(jù)流設(shè)計
深度神經(jīng)網(wǎng)絡(luò)的核心計算負擔(dān)主要在于網(wǎng)絡(luò)中的多層卷積計算,每一層卷積是三維輸入特征(Input Feature Map,簡稱IFM)與四維卷積權(quán)重計算得到三維輸出特征向量(Output Feature Map,簡稱OFM)。
本文DNNA需要將參與計算的輸入數(shù)據(jù)通過DMA從片外DRAM載入到全局緩存、再緩存到IFM和權(quán)重的寄存器緩存、然后由乘法和加法器(MAC)陣列取到數(shù)據(jù)和完成計算。為了提高深度神經(jīng)網(wǎng)絡(luò)的計算能效,首先對卷積計算的并行方式,數(shù)據(jù)流動層次給出定量分析,該設(shè)計過程也被稱為DNNA的數(shù)據(jù)流設(shè)計。
卷積計算的各個變量定義如表1所示。
在神經(jīng)網(wǎng)絡(luò)加速器的一個時鐘周期內(nèi),通過組合邏輯電路的乘法和加法器(MAC)可以得到的相乘和累加的結(jié)果,這是卷積計算的一個原子操作。如果沒有并行計算,則一個原子操作只能完成一次乘法和一次加法運算。神經(jīng)網(wǎng)絡(luò)加速器的MAC陣列做并行計算,一個原子操作最多完成的乘法和累加次數(shù)等于NNA的MAC單元總數(shù)[3] [4]。本文DNNA根據(jù)卷積權(quán)重的尺寸特征,可以動態(tài)配置為二維并行卷積計算或者三維并行卷積計算。
二維并行卷積計算是在IFM輸入通道和權(quán)重核數(shù)的兩個維度上并行,兩個并行維度相互獨立,且并行計算沒有切割I(lǐng)FM表面(Hi*Wi),因此二維并行卷積并不受卷積步長(Stride)或者卷積核的空洞(Dilation)的影響。但二維并行卷積的MAC利用率依賴于IFM輸入通道。當(dāng)稀疏卷積的情況,每個IFM輸入通道的都可能有零值權(quán)重的存在,所以會影響MAC利用率。

表1:卷積參數(shù)說明
三維并行卷積計算是在IFM輸入通道C、OFM表面(Ho*Wo)和權(quán)重核數(shù)Kn三個維度上并行,且只采用Dual-MAC設(shè)計,并行計算兩個IFM輸入通道[2]。所以一是適合于對輸入通道較小的卷積計算場景,如DNN網(wǎng)絡(luò)的圖像輸入層;二是適用于稀疏卷積的情況。
本文DNNA計算的MAC陣列為8行16列Dual-MAC,即共計256個MAC單元。每個MAC單元完成8bit乘法和相應(yīng)的累加計算。一次卷積計算總的乘法計算個數(shù)需遍歷卷積權(quán)重的四個維度和OFM的兩個維度,一個單位周期內(nèi)有256個MAC并行計算。
綜上可得:二維并行卷積的乘法計算數(shù)如式(1)所示;三維并行卷積的計算時鐘周期數(shù)如式(2)所示。下式中均設(shè)OFM表面(Ho*Wo)足夠大。
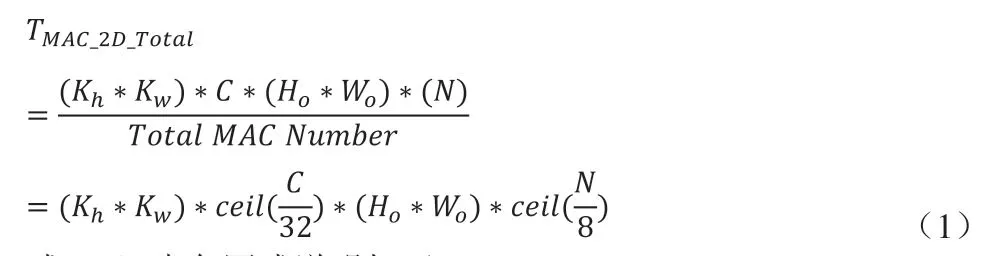
式(1)中各因式說明如下:
(1)(Kh*Kw)是遍歷輸入權(quán)重一個表面的循環(huán)。
(3)Ho*Wo是遍歷OFM一個表面的循環(huán)。
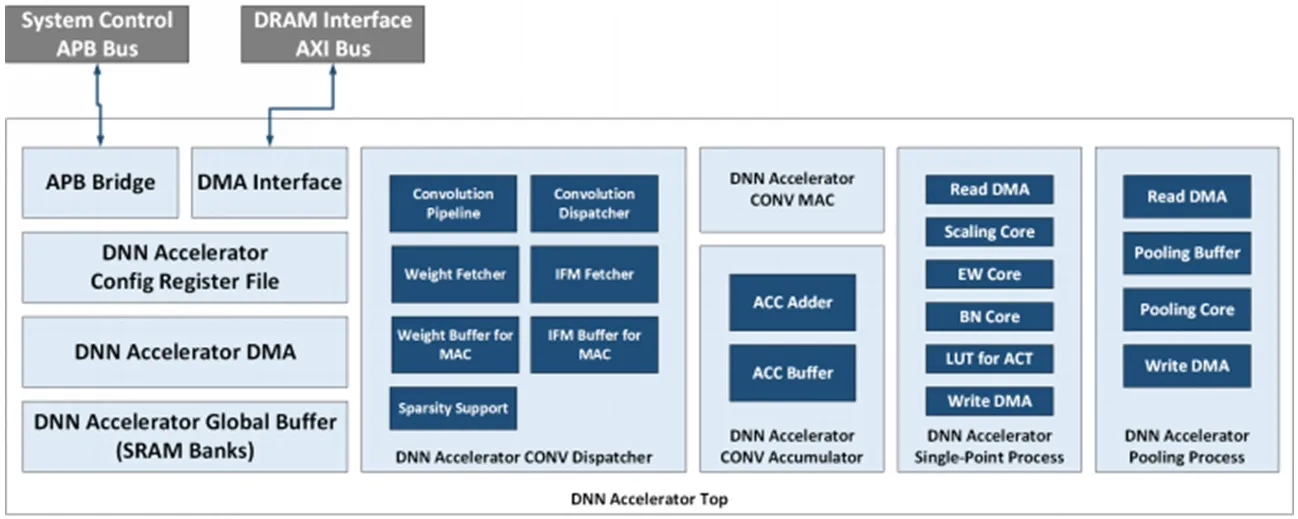
圖1:DNNA的頂層模塊框圖
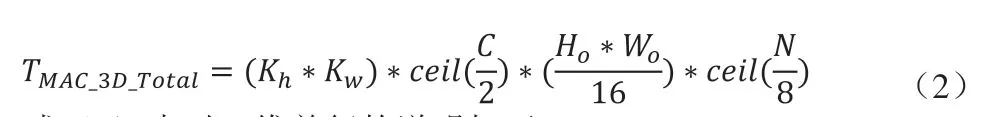
式(2)中對三維并行的說明如下:
3 DNNA的架構(gòu)設(shè)計
前述兩種并行數(shù)據(jù)流各有適用場景,本文DNNA通過寄存器配置,硬件模塊中以最合適的并行方式完成計算。本文DNNA硬件模塊的設(shè)計框圖如圖1所示,主要模塊描述如下:
(1)APB接口及配置寄存器文件作為軟硬件接口。
(2)專用DMA接口訪問外部DRAM存儲的卷積權(quán)重和IFM輸入數(shù)據(jù)。
(3)片上SRAM構(gòu)成全局緩存(Global Buffer),全局緩存可動態(tài)劃分存儲空間,存放IFM、權(quán)重、權(quán)重配置信息、寄存器配置信息等。
(4)CONV Dispatcher作為中控模塊,實現(xiàn)卷積計算的數(shù)據(jù)流控制和流水線控制。
(5)IFM Buffer和Weight Buffer是從全局緩存到MAC陣列的寄存器緩存,分別存儲IFM數(shù)據(jù)和權(quán)重數(shù)據(jù)。
(6)計算模塊:MAC陣列、累加器和緩存、單點數(shù)據(jù)的后處理模塊、池化處理模塊。
本文DNNA的層次化存儲設(shè)計為配置寄存器、DMA和全局緩存三部分,其中完成數(shù)據(jù)流動態(tài)配置和流水線控制的CONV Dispatcher設(shè)計如圖2所示。對計算數(shù)據(jù)流的動態(tài)配置說明如下:
(1)對深度神經(jīng)網(wǎng)絡(luò)的各層卷積,由寄存器配置各自對應(yīng)的并行數(shù)據(jù)流。
(2)將一層卷積層分解為多個獨立算子,如卷積、池化、激活函數(shù)、矩陣點的算術(shù)運算等,將一個獨立算子可再分解為DNNA操作和參數(shù)數(shù)據(jù)。該過程由DMA和寄存器配置協(xié)同完成。
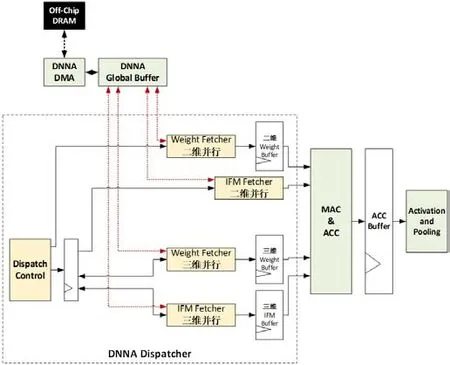
圖2:CONV Dispatcher設(shè)計框圖
(3)DMA可以自動從讀取IFM、權(quán)重和寄存器配置參數(shù)三種數(shù)據(jù)并放入全局緩存,寄存器配置參數(shù)決定計算過程。
(4)二維并行和三維并行的數(shù)據(jù)流分別有獨立的Fetcher模塊和寄存器緩存,根據(jù)數(shù)據(jù)特征自動讀入數(shù)據(jù),并且分配到各個MAC輸入端。
(5)全過程流水線控制,硬件自動完成。
4 優(yōu)化對稀疏卷積的實現(xiàn)
4.1 均衡稀疏卷積的MAC算力
對于包含了大量零值權(quán)重的稀疏卷積,一是不計算零值,節(jié)省計算時間;二是零值權(quán)重在權(quán)重核可能呈不均勻分布上分布不均勻,需要對權(quán)重核數(shù)據(jù)做預(yù)處理,并均衡算力,提高MAC陣列的利用率。本文DNNA采用軟硬件協(xié)同方式,實現(xiàn)如下:
(1)軟件工具鏈對訓(xùn)練后并量化的卷積權(quán)重進行壓縮,去掉零值。
(2)再將非零值權(quán)重按照如下順序緊密排序:
(a)連續(xù)2個輸入通道。

圖3:稀疏卷積的權(quán)重壓縮和排序
(b)連續(xù)8個權(quán)重核。
(c)權(quán)重行方向Kw。
(d)權(quán)重列方向Kh。
(3)然后均衡每2個輸入通道和8個權(quán)重核上的非零值權(quán)重。
(4)經(jīng)過上述壓縮和排序的預(yù)處理后的權(quán)重,輸入到本文DNNA硬件,Dispatcher模塊控制對非零值權(quán)重的算力均衡。
(5)本文DNNA對權(quán)重核數(shù)Kn的并行數(shù)為8,因此對應(yīng)于(Kh*Kw)*2*8的權(quán)重數(shù)據(jù)量的乘法計算,MAC陣列共享IFM輸入數(shù)據(jù)。
(6)MAC之間的均衡了算力的MAC中間結(jié)果(Partial Sum)有Accumulator Buffer進行緩存。
以一個尺寸為(Kh*Kw)*2*8=3*3*2*8的權(quán)重數(shù)據(jù)塊為例,壓縮和排序的預(yù)處理效果如圖3所示。圖中空白格表示零值。
4.2 優(yōu)化緩存的數(shù)據(jù)帶寬和數(shù)據(jù)復(fù)用
要使16*2*8的MAC陣列要達到100%的利用率,所需IFM和權(quán)重的數(shù)據(jù)帶寬需求(數(shù)據(jù)量/時鐘周期)如表2所示。
如表2所示,二維并行計算所需權(quán)重帶寬是IFM帶寬的8倍。本文DNNA采用流水線控制,在每次乘法操作前預(yù)取256 Bytes的權(quán)重數(shù)據(jù)。預(yù)取的權(quán)重數(shù)據(jù)復(fù)用至少8個時鐘周期。在當(dāng)前權(quán)重復(fù)用期間,流水線控制從全局緩存預(yù)取下一組256 Bytes的權(quán)重數(shù)據(jù)。所優(yōu)化的二維并行卷積數(shù)據(jù)流如式(3)所示,總的卷積計算周期數(shù)不變,且未額外增加讀取片上緩存時間,也未額外增加片上緩存的帶寬。

表2:MAC陣列的數(shù)據(jù)帶寬
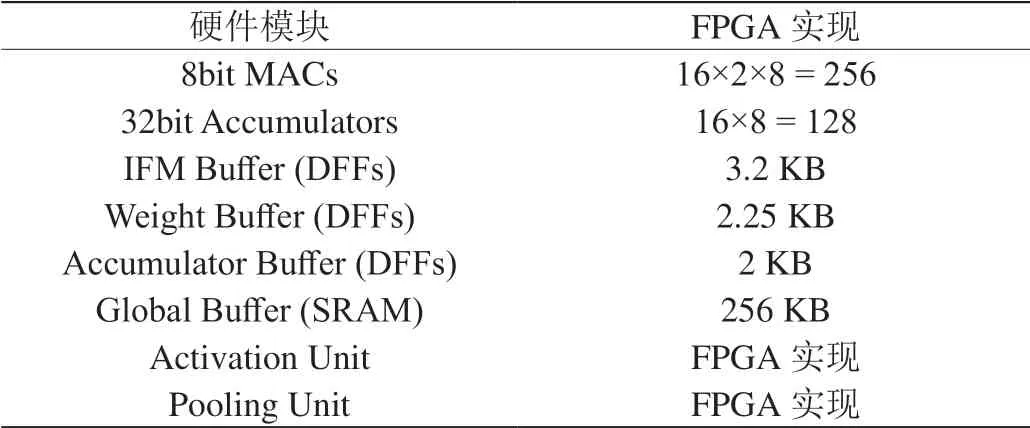
表3:FPGA硬件實現(xiàn)

表4:本文DNNA支持的神經(jīng)網(wǎng)絡(luò)算子
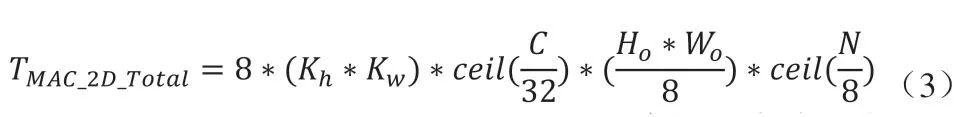
如表2所示,三維并行計算所需IFM數(shù)據(jù)帶寬大于權(quán)重,且因Stride或Dilation,需要從片上緩存的不同地址讀取IFM數(shù)據(jù)。本文DNNA每次計算需載入寄存器緩存的最小權(quán)重數(shù)據(jù)量為(Kh*Kw)*2*8。可以配置寄存器使本文DNNA預(yù)取兩個權(quán)重數(shù)據(jù)塊,同時預(yù)取對應(yīng)的IFM數(shù)據(jù),復(fù)用IFM數(shù)據(jù)完成16個權(quán)重核對應(yīng)的OFM部分和,所優(yōu)化的三維并行卷積數(shù)據(jù)流如式(4)所示。

5 FPGA實現(xiàn)
本文DNNA基于Verilog HDL語言完成RTL設(shè)計,且均可綜合RTL代碼。RTL設(shè)計完成后,驗證設(shè)計的仿真方式為:隨機生成不同卷積尺寸的weight.bin,ifm.bin和配置寄存器的配置文件,并且同時生成用于比對的正確OFM數(shù)據(jù)golden.bin,通過VCS工具仿真和收集該DNNA的計算結(jié)果,與golden.hex比對一致。
仿真確認的RTL,在Xilinx Zynq-7000 FPGA上實現(xiàn)。FPGA實現(xiàn)的硬件模塊配置如表3所示。該FPGA實現(xiàn)需要27000 LUTs。
所實現(xiàn)的FPGA DNNA,可以完成如表4所示的神經(jīng)網(wǎng)絡(luò)計算。
用本文DNNA對3×3和5×5尺寸的稀疏權(quán)重核進行卷積計算,其中零值權(quán)重的分布完全隨機。優(yōu)化的稀疏卷積計算的提升效率如圖4所示。圖中稀疏率是零值權(quán)重占總權(quán)重數(shù)的百分比,節(jié)省的計算時間與未優(yōu)化的計算時間的百分比,按每種尺寸、每種稀疏率隨機迭代計算后,再求平均得到。根據(jù)圖中稀疏優(yōu)化節(jié)省的時間對比,可見對于(Kh*Kw)權(quán)重尺寸越大,稀疏優(yōu)化效果越明顯。且該優(yōu)化設(shè)計的效果正相關(guān)于稀疏率,與輸入通道和權(quán)重核數(shù)相對獨立。
6 結(jié)論
本文針對深度神經(jīng)網(wǎng)絡(luò)的卷積計算特征進行量化分析和DNNA的數(shù)據(jù)流設(shè)計,根據(jù)數(shù)據(jù)流進行DNNA架構(gòu)設(shè)計,并為了提高MAC陣列利用率和節(jié)省片上SRAM帶寬所進行專門優(yōu)化。進一步說明本文DNNA的硬件實現(xiàn),RTL仿真和FPGA實現(xiàn)工作,通過對稀疏卷積節(jié)省的計算時間驗證本文DNNA設(shè)計。下一步工作是將本文DNNA為作為神經(jīng)網(wǎng)絡(luò)專用處理器(DSA),集成到SoC異構(gòu)架構(gòu)中,配合各種外設(shè)接口和輸入設(shè)備,實現(xiàn)深度神經(jīng)網(wǎng)絡(luò)的多種應(yīng)用。
猜你喜歡
河北畫報(2020年8期)2020-10-27 02:54:06
現(xiàn)代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
電子制作(2019年19期)2019-11-23 08:41:36
電子制作(2019年15期)2019-08-27 01:11:50
電子制作(2019年7期)2019-04-25 13:18:16
藝術(shù)啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
商周刊(2017年26期)2017-04-25 08:13:04
