分布式監(jiān)測系統(tǒng)中的重復(fù)元素檢測機(jī)制
2020-06-08 09:00:18孫玉娥汪潤枝
計(jì)算機(jī)研究與發(fā)展 2020年5期
陸 樂 孫玉娥 黃 河,3 汪潤枝 曹 振
1(蘇州大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院 江蘇蘇州 215131)2(蘇州大學(xué)軌道交通學(xué)院 江蘇蘇州 215137)3(中國科學(xué)技術(shù)大學(xué)蘇州研究院 江蘇蘇州 215123)
近年來,隨著分布式服務(wù)架構(gòu)的流行,人們越來越關(guān)注分布式系統(tǒng)中各節(jié)點(diǎn)的數(shù)據(jù)整合問題.如何通過盡可能少的通信開銷整合各分布式節(jié)點(diǎn)存儲(chǔ)的數(shù)據(jù),并從中提取出有用的信息來幫助系統(tǒng)做出更好的決策,已經(jīng)成為人們研究的重點(diǎn)之一.給定一個(gè)閾值,當(dāng)一個(gè)元素被不少于該閾值個(gè)節(jié)點(diǎn)監(jiān)測到時(shí),我們就稱該元素為重復(fù)元素.本文將研究分布式系統(tǒng)中的重復(fù)元素檢測問題,即分布式系統(tǒng)中同時(shí)被不少于給定閾值個(gè)節(jié)點(diǎn)監(jiān)測到的重復(fù)元素集合,屬于節(jié)點(diǎn)數(shù)據(jù)整合問題的一種.對重復(fù)元素的有效檢測在實(shí)際生產(chǎn)中有很多重要的應(yīng)用,舉出一些應(yīng)用實(shí)例:
1) 在一個(gè)包含了大量可以獨(dú)立檢測惡意入侵行為節(jié)點(diǎn)的分布式入侵監(jiān)測系統(tǒng)[1-2]中,每個(gè)節(jié)點(diǎn)只檢測自己監(jiān)控的區(qū)域是否遭到了入侵并記錄入侵的相關(guān)信息,如入侵類型、地址等能區(qū)分不同入侵的數(shù)據(jù).通過網(wǎng)絡(luò),這些節(jié)點(diǎn)將入侵記錄上傳到中央節(jié)點(diǎn),由中央節(jié)點(diǎn)找出并重點(diǎn)處理其中威脅度較高的大規(guī)模惡意入侵記錄,即被大多數(shù)節(jié)點(diǎn)檢測到的入侵?jǐn)?shù)據(jù).
2) 如谷歌一類的在線搜索公司在世界各地都有自己的服務(wù)器,假設(shè)它們會(huì)記錄下各自地區(qū)近期內(nèi)搜索頻次較高的熱門關(guān)鍵詞并將其傳給中央服務(wù)器,那么中央服務(wù)器就能整合這些搜索數(shù)據(jù),找出其中大部分地區(qū)的人的共同興趣或者關(guān)注點(diǎn).比如在谷歌流感趨勢預(yù)測[3]中,谷歌通過收集和整合各個(gè)地區(qū)人們跟流感相關(guān)的搜索關(guān)鍵詞數(shù)據(jù),可以近乎實(shí)時(shí)地預(yù)測流感是否爆發(fā)以及流感爆發(fā)的區(qū)域.
目前的相關(guān)研究主要集中在分布式系統(tǒng)中對頻繁元素[4-8]和全局元素[9-14]的檢測上.其中頻繁元素即為在整個(gè)系統(tǒng)中出現(xiàn)頻率最高的s個(gè)元素,在這一類問題的模型中,同一元素可以被一個(gè)節(jié)點(diǎn)記錄多次.文獻(xiàn)[4]針對頻繁元素檢測問題提出了一個(gè)多層次檢測模型,將節(jié)點(diǎn)劃分為多個(gè)層次,通過中間節(jié)點(diǎn)的數(shù)據(jù)整合減小最終傳輸給中央?yún)f(xié)調(diào)器的數(shù)據(jù)量,但該方案并不能有效降低整個(gè)過程中消耗的通信代價(jià);文獻(xiàn)[5]先讓各節(jié)點(diǎn)找出本節(jié)點(diǎn)中出現(xiàn)頻次最高的s個(gè)元素,然后將其發(fā)送給協(xié)調(diào)器以計(jì)算出一個(gè)更低的頻次閾值并發(fā)回給各節(jié)點(diǎn),然后節(jié)點(diǎn)再將出現(xiàn)頻次超過該閾值的所有元素發(fā)給協(xié)調(diào)器,由其找出其中的頻繁元素.然而,上述研究并不適應(yīng)于重復(fù)元素檢測.這是因?yàn)橹貜?fù)元素檢測要計(jì)算每個(gè)元素被多少個(gè)不同節(jié)點(diǎn)監(jiān)測到,而與該元素在每個(gè)節(jié)點(diǎn)上出現(xiàn)的次數(shù)無關(guān).與本文研究問題類似的是全局元素檢測,即找到被所有節(jié)點(diǎn)監(jiān)測到的元素,是重復(fù)元素中的一個(gè)特例.文獻(xiàn)[9]中提出一種基于任意2個(gè)節(jié)點(diǎn)記錄的元素集合差異較小的假設(shè)的全局元素檢測算法,但這一假設(shè)與實(shí)際不符,在節(jié)點(diǎn)差異較大的情況下其通信開銷甚至超過了直接傳輸原數(shù)據(jù)的直觀算法;文獻(xiàn)[10]中提出的CFSP(combinable filter solution with progressive filtering)算法通過布隆過濾器[15]對節(jié)點(diǎn)數(shù)據(jù)進(jìn)行壓縮,并在協(xié)調(diào)器端將壓縮數(shù)據(jù)通過逐位相與的方式整合后發(fā)回各節(jié)點(diǎn)以篩去節(jié)點(diǎn)中的無關(guān)元素,最終經(jīng)過多輪篩選在給定的誤差范圍內(nèi)找出系統(tǒng)中的全局元素集合.CFSP算法可以有效降低檢測過程中的通信開銷,但其在參數(shù)設(shè)置過程中并沒有從全局最優(yōu)的角度進(jìn)行參數(shù)優(yōu)化,所以在理論上并沒有取得最佳效果.此外,全局元素本身也存在著很大的局限性.以分布式入侵監(jiān)測系統(tǒng)為例,入侵者如果有意識(shí)地漏過1~2個(gè)節(jié)點(diǎn)不去攻擊,就不會(huì)被全局元素檢測算法檢測到.因此本文在CFSP算法的基礎(chǔ)上,提出了一個(gè)更為普適的問題模型,并給出了一個(gè)檢測重復(fù)元素的有效解決方案。此外,本文還通過概率推導(dǎo)從全局最優(yōu)的角度對參數(shù)進(jìn)行了優(yōu)化,并且增設(shè)了對篩選停止條件的判斷,從而保證了每一輪篩選的收益最大化。
與本文最為相關(guān)的研究是文獻(xiàn)[16]中提出的利用Cuckoo Filter和Raptor Code來檢測重復(fù)元素的DISPERSE(probabilistic distributed persistent item identification algorithm)算法,但誤報(bào)和漏報(bào)情況的存在使其難以適用于某些嚴(yán)苛的應(yīng)用場景.
在重復(fù)元素的檢測過程中存在4個(gè)難點(diǎn):
1) 大規(guī)模的分布式系統(tǒng)會(huì)產(chǎn)生巨量的數(shù)據(jù),這些數(shù)據(jù)的傳輸會(huì)給協(xié)調(diào)器和整個(gè)系統(tǒng)造成極大的壓力,因此需要盡可能降低探測過程中的通信開銷,避免原始數(shù)據(jù)的直接傳輸.
2) 系統(tǒng)中不同節(jié)點(diǎn)記錄的數(shù)據(jù)量可能大致相仿,也可能差異巨大,機(jī)制針對不同的元素分布狀況,都要能達(dá)到預(yù)期的效果.
3) 為了便于統(tǒng)籌全局,做出決策,協(xié)調(diào)器需要掌握所有重復(fù)元素的信息,而這些數(shù)據(jù)都是分散存儲(chǔ)在各個(gè)節(jié)點(diǎn)中的.
4) 在某些應(yīng)用場景下,重復(fù)元素的誤報(bào)或漏報(bào)可能造成巨大的損失,為了適用于類似場景,機(jī)制要完整、無誤報(bào)地檢測出所有重復(fù)元素.
針對以上4個(gè)難點(diǎn),本文以降低通信開銷為目標(biāo),設(shè)計(jì)了一個(gè)適用于大規(guī)模分布式監(jiān)測系統(tǒng)的重復(fù)元素檢測機(jī)制,保證協(xié)調(diào)器可以完整、高效、無誤報(bào)地完成重復(fù)元素的檢測.
1 系統(tǒng)建模
本節(jié)給出了分布式監(jiān)測系統(tǒng)的模型,并對所要解決的問題進(jìn)行了具體闡述.
1.1 系統(tǒng)模型
如圖1所示,所研究的分布式監(jiān)測系統(tǒng)部署在網(wǎng)絡(luò)中,主要由1個(gè)中央?yún)f(xié)調(diào)器和n個(gè)監(jiān)測器組成.每個(gè)監(jiān)測器獨(dú)立地監(jiān)測網(wǎng)絡(luò)數(shù)據(jù)流中的元素,這里的元素可以根據(jù)實(shí)際的應(yīng)用需求定義.例如,在掃描攻擊檢測應(yīng)用中,每臺(tái)監(jiān)測器是一個(gè)服務(wù)器,而一個(gè)元素則是一個(gè)訪問該服務(wù)器的源地址.由于本文只研究如何檢測網(wǎng)絡(luò)中的重復(fù)元素,并不需要考慮每個(gè)元素在同一監(jiān)測器中出現(xiàn)的次數(shù),所以假設(shè)同一監(jiān)測器所保存的元素集合并不存在相同元素(即已經(jīng)完成去重操作).
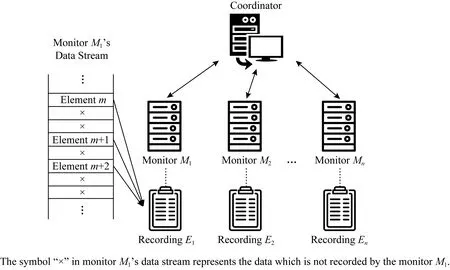
Fig. 1 The distributed monitoring system model圖1 分布式監(jiān)測系統(tǒng)的系統(tǒng)模型
當(dāng)需要進(jìn)行重復(fù)元素檢測時(shí),每個(gè)監(jiān)測器Mi首先開辟一塊大小為li的內(nèi)存空間,用于存儲(chǔ)所監(jiān)測到的元素集合Ei.由于元素的數(shù)量可能非常龐大,直接發(fā)送原始數(shù)據(jù)會(huì)帶來巨大的通信負(fù)擔(dān).為了節(jié)省傳輸帶寬,本研究采用布隆過濾器存儲(chǔ)元素,而每個(gè)監(jiān)測器上布隆過濾器的大小li由所監(jiān)測到的元素?cái)?shù)量決定.然后,監(jiān)測器將編碼后的布隆過濾器發(fā)送給協(xié)調(diào)器.協(xié)調(diào)器在收到所有監(jiān)測器發(fā)來的數(shù)據(jù)后會(huì)對其進(jìn)行整合,然后通過與監(jiān)測器之間的多輪通信、協(xié)作計(jì)算完成重復(fù)元素監(jiān)測工作.
1.2 問題描述及設(shè)計(jì)目標(biāo)
實(shí)際應(yīng)用中,根據(jù)應(yīng)用場景的不同,元素的定義可以非常寬泛.它可以是1個(gè)搜索頻率極高的熱門關(guān)鍵字、1條被蜜罐捕獲的入侵記錄或是1個(gè)被檢測系統(tǒng)判定為攻擊源的IP地址.在本文中,任意2條元素,只要內(nèi)容相同,就會(huì)被認(rèn)定是同一條元素.因此,1條元素可以出現(xiàn)在多個(gè)不同監(jiān)測器的記錄列表中.下面我們給出t-重復(fù)元素的定義,這也是本文研究的主題.
定義1.t-重復(fù)元素.在一個(gè)檢測周期中,如果某條元素被n個(gè)監(jiān)測器中的至少t個(gè)記錄下來,那么稱該條元素為t-重復(fù)元素.
本文研究的目標(biāo)是通過監(jiān)測器與協(xié)調(diào)器間的1輪或多輪通信,篩去各監(jiān)測器列表上的非t-重復(fù)元素,使協(xié)調(diào)器能用盡可能少的通信資源,找到一個(gè)包含了本周期內(nèi)系統(tǒng)中出現(xiàn)的所有t-重復(fù)元素的集合,此處記為Pt.參數(shù)t作為界定t-重復(fù)元素的閾值,其數(shù)值的改變會(huì)很大程度上影響Pt的內(nèi)容.在t取不同數(shù)值的情況下,Pt可能包含大量甚至全部的元素,也可能僅僅是某個(gè)集合Ei的一個(gè)子集.
在尋找Pt的過程中,本文提出的機(jī)制需滿足3點(diǎn)設(shè)計(jì)目標(biāo).
1) 完整性.在一些嚴(yán)格的應(yīng)用場景下,系統(tǒng)必須保證協(xié)調(diào)器找出的解是沒有遺漏的,即集合Pt要包含所有t-重復(fù)元素.
2) 無誤報(bào).最終解不能存在任何誤報(bào)的情況,任何一個(gè)非t-重復(fù)元素都不應(yīng)屬于Pt.
3) 篩選的必要性.機(jī)制中進(jìn)行的每一輪篩選操作都應(yīng)該是必要的,即相對直接發(fā)送剩余元素原始數(shù)據(jù)的方案而言,本輪的篩選能夠確實(shí)有效地降低整體的通信開銷.
基于以上考慮,本文以最小化中央?yún)f(xié)調(diào)器與監(jiān)測器之間的數(shù)據(jù)傳輸總量為優(yōu)化目標(biāo),提出了一個(gè)高效的t-重復(fù)元素檢測機(jī)制,在保證監(jiān)測準(zhǔn)確率的基礎(chǔ)上,盡可能地降低對傳輸帶寬的占用.
2 t-重復(fù)元素檢測機(jī)制
本節(jié)給出了t-重復(fù)元素檢測機(jī)制的設(shè)計(jì)細(xì)節(jié),主要包括檢測流程以及前2輪和后續(xù)輪次篩選過程中的參數(shù)優(yōu)化,并對機(jī)制的性能進(jìn)行了分析.
2.1 檢測流程
對于t-重復(fù)元素檢測問題而言,一種簡單直觀的做法就是令各監(jiān)測器直接將元素列表全部發(fā)送給協(xié)調(diào)器,協(xié)調(diào)器經(jīng)過比對后就能準(zhǔn)確無誤地找出所有t-重復(fù)元素.這種方法思路簡單、易于操作,但會(huì)產(chǎn)生巨量的通信消耗,在大規(guī)模分布式監(jiān)測系統(tǒng)中尤其如此.而要讓協(xié)調(diào)器檢測到存儲(chǔ)在各個(gè)監(jiān)測器端的所有t-重復(fù)元素,這些t-重復(fù)元素的直接傳輸又是必要的.因此,為了降低整體的通信成本,本機(jī)制的基本思路是通過監(jiān)測器與協(xié)調(diào)器之間多輪的壓縮數(shù)據(jù)交互,篩去監(jiān)測器端元素列表中絕大部分的非t-重復(fù)元素,從而減小需要直接傳輸?shù)脑氐臄?shù)量.
當(dāng)一個(gè)監(jiān)測周期結(jié)束時(shí),系統(tǒng)即開始本周期的t-重復(fù)元素檢測.由于布隆過濾器具有結(jié)構(gòu)簡單、空間復(fù)雜度低以及無漏報(bào)等優(yōu)點(diǎn),本文將其作為監(jiān)測器壓縮元素列表的工具.在用布隆過濾器對元素列表進(jìn)行編碼之前,監(jiān)測器需要先用計(jì)算得到的布隆過濾器的參數(shù),即位數(shù)組的大小l和Hash函數(shù)數(shù)量k,對其進(jìn)行初始化.初始化完成后,各監(jiān)測器首先將列表中的所有元素在對應(yīng)的布隆過濾器上置位.
具體的置位流程為:對于每個(gè)元素,布隆過濾器通過給定的k個(gè)Hash函數(shù)將其隨機(jī)映射到長為l的位數(shù)組上的k個(gè)位置,并將這些位的值置為1.置位完成后,監(jiān)測器將各自的位數(shù)組發(fā)送給協(xié)調(diào)器,由協(xié)調(diào)器將接收到的所有位數(shù)組通過逐位累加的方法進(jìn)行整合,把累加后數(shù)值大于等于t的位置為1,其余位則置0,從而得到一個(gè)整合了所有元素?cái)?shù)據(jù)的結(jié)果位數(shù)組.此后這個(gè)結(jié)果位數(shù)組會(huì)被協(xié)調(diào)器發(fā)回給所有監(jiān)測器,每個(gè)監(jiān)測器對照著它用原來的k個(gè)Hash函數(shù)將自身列表中的元素一一映射到對應(yīng)的k位,若這k位全部為1,那么這條元素可能是t-重復(fù)元素,監(jiān)測器依舊將其保留.若這k位不全為1,基于布隆過濾器無漏報(bào)的特性,該元素一定是非t-重復(fù)元素,監(jiān)測器會(huì)將其從列表中移除.當(dāng)所有元素都在結(jié)果位數(shù)組上驗(yàn)證過一遍后,這輪篩選便到此結(jié)束.
系統(tǒng)重復(fù)上述步驟,進(jìn)行下一輪的篩選,直到監(jiān)測器接收到協(xié)調(diào)器的終止命令為止.篩選結(jié)束后,監(jiān)測器將列表中剩余的所有元素直接發(fā)送給協(xié)調(diào)器,協(xié)調(diào)器通過對比找出所有t-重復(fù)元素.
在篩選階段,使用布隆過濾器進(jìn)行數(shù)據(jù)的編碼壓縮在判別時(shí)總會(huì)有一定的誤報(bào)率存在,所以即使經(jīng)過多輪次的篩選,機(jī)制也無法保證所有的非t-重復(fù)元素都已經(jīng)被監(jiān)測器篩去.但無論監(jiān)測器最終傳輸?shù)脑刂惺欠癜莟-重復(fù)元素,機(jī)制都能確保協(xié)調(diào)器可以準(zhǔn)確地找到Pt.因此篩選階段允許誤報(bào)的存在,且本文不關(guān)心誤報(bào)率的大小,下一輪篩選對整體誤報(bào)率的影響并不能直接決定篩選是否繼續(xù)進(jìn)行.后續(xù)篩選的必要性只取決于其是否能給系統(tǒng)整體帶來收益,即通信開銷的降低,而這一點(diǎn)將交由協(xié)調(diào)器判斷.為了讓協(xié)調(diào)器能夠通過逐位累加的方法整合布隆過濾器,所有監(jiān)測器對應(yīng)的布隆過濾器理論上應(yīng)該保持一樣的大小l,并使用相同的k個(gè)Hash函數(shù)進(jìn)行置位.
記第q輪篩選中監(jiān)測器Mi對應(yīng)的布隆過濾器為Bi,q,其對應(yīng)的位數(shù)組長度為li,q,統(tǒng)一的Hash函數(shù)數(shù)量為kq.緊接著將介紹協(xié)調(diào)器怎樣判斷篩選何時(shí)停止以及如何給各布隆過濾器分配合適的參數(shù),因?yàn)椴煌A段元素集合的情況有所差異,本機(jī)制為前2輪篩選和后續(xù)篩選分別設(shè)計(jì)了不同的參數(shù)優(yōu)化方案.
2.2 首輪篩選機(jī)制
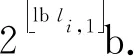
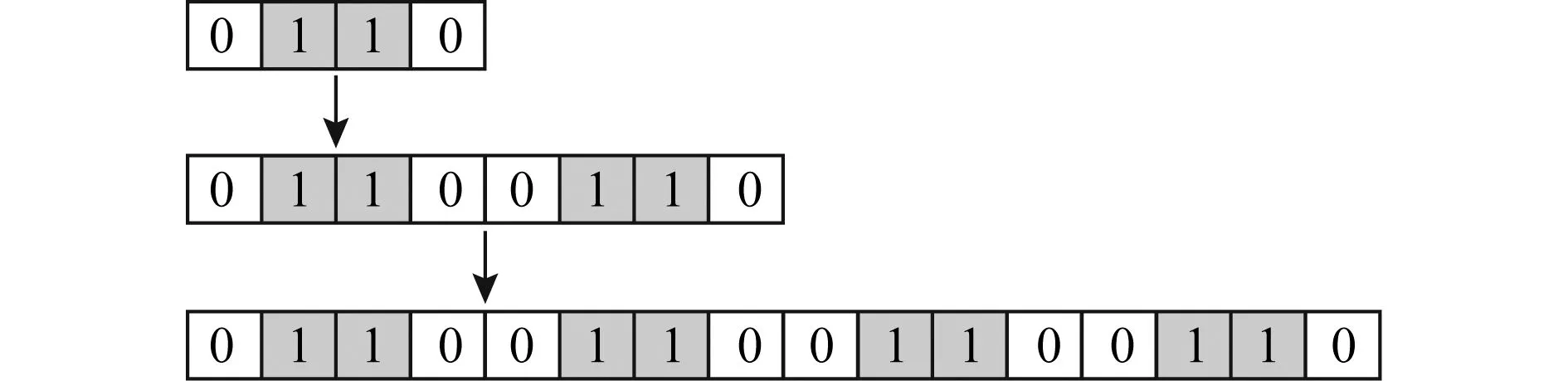
Fig. 2 Convert the bloom filter to the extended one by replicating itself twice圖2 通過2次自我復(fù)制擴(kuò)展布隆過濾器
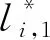
根據(jù)文獻(xiàn)[15]提供的單個(gè)布隆過濾器最優(yōu)參數(shù)的推導(dǎo),監(jiān)測器Mi可以計(jì)算得到對應(yīng)布隆過濾器的最優(yōu)參數(shù),首先是位數(shù)組的理論大小li,1:
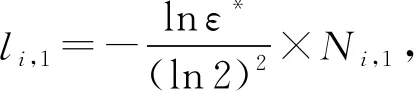
(1)
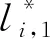
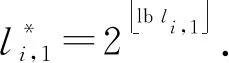
(2)
對于Hash函數(shù)個(gè)數(shù)k1,監(jiān)測器同樣依據(jù)文獻(xiàn)[15]給出推導(dǎo)計(jì)算它的實(shí)際最優(yōu)值:
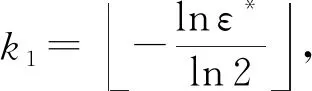
(3)
由于ε*采用統(tǒng)一的預(yù)設(shè)值,所有監(jiān)測器求得的k1也是一致的.
第1輪篩選會(huì)篩去大量的非t-重復(fù)元素,使得后續(xù)輪次的篩選中各監(jiān)測器元素?cái)?shù)量不均衡的狀況得到大幅度的改善.所以在此后的第q輪篩選中,機(jī)制會(huì)以滿足剩余元素?cái)?shù)量最多的監(jiān)測器Mmax,q的需求為標(biāo)準(zhǔn),為各監(jiān)測器設(shè)置統(tǒng)一的布隆過濾器大小lmax,q和Hash函數(shù)數(shù)量kq.因此lmax,q和kq需由協(xié)調(diào)器在掌握了所有監(jiān)測器的具體情況后計(jì)算得到并分配給各個(gè)監(jiān)測器.
2.3 首輪篩選后的參數(shù)優(yōu)化
第2輪篩選開始前,各監(jiān)測器會(huì)先將各自列表中剩余元素的數(shù)量Ni,2發(fā)送給協(xié)調(diào)器.協(xié)調(diào)器收到所有監(jiān)測器信息后,會(huì)找出其中的最大值Nmax,2,然后以Nmax,2為基礎(chǔ)為各監(jiān)測器計(jì)算統(tǒng)一的lmax,2和k2.計(jì)算方式與第1輪篩選中類似:
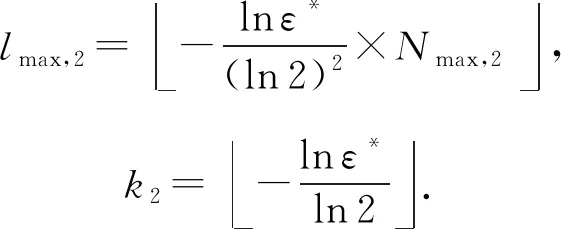
(4)
此后協(xié)調(diào)器會(huì)將lmax,2和k2發(fā)送給各監(jiān)測器,以供它們對布隆過濾器進(jìn)行初始化.
一般情況下,前2輪篩選都能夠大幅降低通信開銷,所以不考慮其必要與否.而在后續(xù)的數(shù)輪篩選中,協(xié)調(diào)器就需要在篩選前判斷該輪篩選的必要性以決定是否繼續(xù)進(jìn)行篩選了.
2.4 后續(xù)篩選的參數(shù)優(yōu)化
相比于前2輪篩選,后續(xù)幾輪的篩選從前次篩選中繼承了各監(jiān)測器對元素列表用布隆過濾器編碼后產(chǎn)生的大小一致的位數(shù)組.借助這些數(shù)據(jù),協(xié)調(diào)器可以在篩選開始前對元素的分布狀況進(jìn)行預(yù)估.記只出現(xiàn)在m個(gè)監(jiān)測器列表中的元素?cái)?shù)量為fm,在前次篩選整合出結(jié)果位數(shù)組前,協(xié)調(diào)器只要分別統(tǒng)計(jì)出逐位累加后各個(gè)位中數(shù)值等于0,1,…,n的位的數(shù)量,根據(jù)文獻(xiàn)[17]中提出的持續(xù)流量估計(jì)算法,就能夠以較高的準(zhǔn)確率估計(jì)出fm的值.由于原算法是基于1次Hash置位的Bitmap進(jìn)行的流量估計(jì),而在本文中,輸入是kq次Hash置位的位數(shù)組,所以在計(jì)算出數(shù)值后還要將其除以kq以得到對fm的估計(jì)值.
對于只出現(xiàn)在m個(gè)監(jiān)測器列表中的元素被記錄下的次數(shù),可以用m×fm進(jìn)行計(jì)算.根據(jù)t-重復(fù)元素的定義,協(xié)調(diào)器能夠估計(jì)出t-重復(fù)元素在所有監(jiān)測器列表中數(shù)量的總和:
(5)
根據(jù)布隆過濾器的相關(guān)理論,只要給定了待編碼集合的大小以及期望的誤報(bào)率閾值后,協(xié)調(diào)器就能依照公式計(jì)算出單個(gè)布隆過濾器的最優(yōu)參數(shù).但是單個(gè)布隆過濾器的最優(yōu)并不等同于多個(gè)布隆過濾器整合后的全局最優(yōu),在本機(jī)制的篩選過程中需要考慮的是全局的篩選成本和效果.因此在具備估計(jì)不同出現(xiàn)次數(shù)的元素分布狀況的條件后,本文給前2輪篩選外其他輪次的篩選設(shè)計(jì)了考慮全局最優(yōu)的參數(shù)優(yōu)化方案.
在第q輪篩選中,協(xié)調(diào)器在已知各監(jiān)測器擁有的剩余元素?cái)?shù)量的情況下,不僅要為所有布隆過濾器統(tǒng)一分配一個(gè)合理的lmax,q和kq,還要判斷該輪篩選是否有必要進(jìn)行.為此,本文為第q輪篩選構(gòu)造了一個(gè)收益函數(shù)pq:
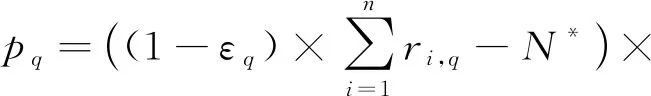
(6)
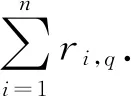
在定義了第q輪篩選的收益后,本輪的優(yōu)化目標(biāo)自然是將收益最大化.由于最大化pq隱含了用盡可能少的通信開銷篩去盡量多的非t-重復(fù)元素,因此在優(yōu)化過程中不必要對篩選的效果做額外的約束,可以將第q輪篩選的優(yōu)化方程規(guī)約為
maxpq
s.t. 1≤kq≤lmax,q,
(7)
其中,εq表示第q輪篩選的理論誤報(bào)率.文獻(xiàn)[17]中有類似的推導(dǎo)過程,只需要將由置位1次的Bitmap擴(kuò)展到置位k次的布隆過濾器即可,此處直接給出推導(dǎo)結(jié)果:
(8)
其中,Pi可令i從0取到n依次計(jì)算得到:
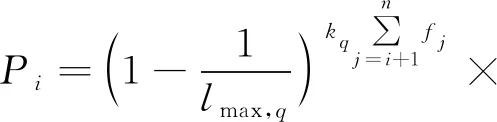
(9)
將式(6)(8)(9)代入式(7)中,求解優(yōu)化問題,協(xié)調(diào)器可以得到kq和lmax,q的值,同時(shí)也能夠解出本輪收益pq.在第q輪篩選的參數(shù)優(yōu)化中,文獻(xiàn)[17]提出的持續(xù)流量估計(jì)算法的時(shí)間復(fù)雜度與空間復(fù)雜度為O(N),N為第q輪篩選前系統(tǒng)中的元素總數(shù).求解優(yōu)化問題則需要遍歷每一對可能的(lmax,q,kq)組合并計(jì)算對應(yīng)的收益pq以找出最優(yōu)解,其時(shí)間復(fù)雜度為O(Lmax,q×Kmax,q),空間復(fù)雜度為O(1),其中Lmax,q和Kmax,q分別表示第q輪篩選中l(wèi)max,q和kq可能的最大值.綜上,第q輪篩選的參數(shù)優(yōu)化算法的時(shí)間復(fù)雜度為O(N+Lmax,q×Kmax,q),空間復(fù)雜度為O(N).
根據(jù)pq的定義,當(dāng)pq≤0時(shí),本輪篩選無法給整個(gè)探測過程帶來任何收益,甚至?xí)岣呖傮w的通信開銷.此時(shí)將參數(shù)發(fā)送給監(jiān)測器,繼續(xù)第q輪的篩選顯然是不合適的,協(xié)調(diào)器將依據(jù)pq的值決定篩選是否繼續(xù).篩選過程會(huì)耗費(fèi)一定的時(shí)間成本,所以當(dāng)收益不大的時(shí)候,篩選帶來的通信開銷的降低可能不足以彌補(bǔ)其所消耗的時(shí)間.因此,可以根據(jù)具體應(yīng)用場景的要求和系統(tǒng)的規(guī)模為收益設(shè)置一個(gè)閾值λ,當(dāng)收益≤λ時(shí),則認(rèn)為沒有繼續(xù)下一輪篩選的必要.
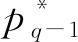
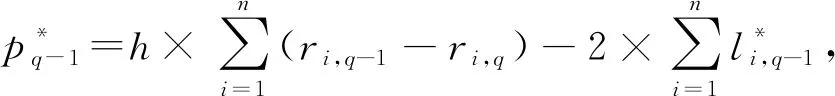
(10)
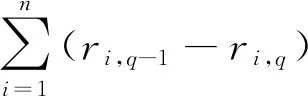
算法1.第q輪參數(shù)優(yōu)化算法(q≥3).
輸入:各監(jiān)測器持有元素?cái)?shù)目集合{Ni,q}i∈[1,n]、估計(jì)的t-重復(fù)元素?cái)?shù)目N*、收益閾值λ;
輸出:統(tǒng)一的布隆過濾器的大小lmax,q、Hash函數(shù)數(shù)量kq或終止篩選的信號(hào).
① 據(jù)文獻(xiàn)[17]的算法估計(jì){f1,f2,…,fn};
② 據(jù)式(5)估計(jì)N*并更新;
③ 據(jù)式(6)(8)確定pq,εq;
④ 據(jù)式(7)解出lmax,q,kq并計(jì)算pq;
⑦ returnlmax,q,kq;
⑧ else
⑨ return終止信號(hào);
⑩ end if
2.5 機(jī)制分析
本文提出的t-重復(fù)元素檢測機(jī)制最重要的目標(biāo)是用盡可能少的通信開銷完整、無誤報(bào)地找出單個(gè)監(jiān)測周期中系統(tǒng)內(nèi)所有的t-重復(fù)元素.基于這一目的,上文為t-重復(fù)元素檢測問題制定了3個(gè)設(shè)計(jì)需求,接下來將證明本機(jī)制是滿足這3點(diǎn)需求的.
定理1.所設(shè)計(jì)的t-重復(fù)元素檢測機(jī)制可以保證探測結(jié)果的完整性.
監(jiān)測器主要依靠布隆過濾器進(jìn)行數(shù)據(jù)壓縮.在任意的第q輪篩選中,根據(jù)布隆過濾器的運(yùn)作原理,任意一條t-重復(fù)元素在其被記錄的至少t個(gè)監(jiān)測器的布隆過濾器上都會(huì)被映射到相同的kq位,且這些位置都將被置1.因此數(shù)據(jù)整合后其對應(yīng)在結(jié)果位數(shù)組上的kq位也將全部被置為1,當(dāng)這些記錄了它的監(jiān)測器查驗(yàn)自身元素列表時(shí),該條元素會(huì)被保留.所以篩選過程中可以確保不會(huì)剔除任何一條t-重復(fù)元素.而最終協(xié)調(diào)器整合元素?cái)?shù)據(jù)的過程中,對于這些被至少t個(gè)監(jiān)測器傳輸來的元素,協(xié)調(diào)器不會(huì)有任何檢測缺漏的情況,即機(jī)制可以完整地檢測出所有t-重復(fù)元素.
定理2.所設(shè)計(jì)的t-重復(fù)元素檢測機(jī)制可以保證探測結(jié)果的無誤報(bào).
對于監(jiān)測器元素列表中存在的非t-重復(fù)元素,雖然多輪次的篩選無法保證將其全部篩去,但可以證明它們并不會(huì)影響探測結(jié)果的準(zhǔn)確性.在最后協(xié)調(diào)器的整合步驟中,各監(jiān)測器將包含了少量非t-重復(fù)元素和全部t-重復(fù)元素的元素集合傳輸給協(xié)調(diào)器.通過比對所有接收到的元素集合,協(xié)調(diào)器可以找到所有的t-重復(fù)元素.而對于非t-重復(fù)元素,以監(jiān)測器Mi中的某條非t-重復(fù)元素為例,當(dāng)且僅當(dāng)其本就在監(jiān)測器Mi的列表中且通過了多次篩選,它才會(huì)最終被發(fā)送給協(xié)調(diào)器.假設(shè)它被協(xié)調(diào)器誤報(bào)為t-重復(fù)元素,則它必須出現(xiàn)在至少t個(gè)監(jiān)測器的傳輸列表中,即它在本周期內(nèi)確實(shí)地被t個(gè)或更多的監(jiān)測器記錄了下來,那么按照定義,它應(yīng)當(dāng)是一條t-重復(fù)元素,因此假設(shè)并不成立,本文提出的機(jī)制可以滿足探測結(jié)果無誤報(bào)的要求.
定理3.所設(shè)計(jì)的t-重復(fù)元素檢測機(jī)制可以保證每一輪篩選的必要性,從而最大程度降低通信成本.
在滿足了結(jié)果準(zhǔn)確性需求的前提下,機(jī)制的性能也需要得到保證.本文給出的機(jī)制綜合了t的取值以及所有監(jiān)測器擁有元素的數(shù)目等因素從全局最優(yōu)的角度對各監(jiān)測器對應(yīng)的布隆過濾器進(jìn)行了參數(shù)優(yōu)化,因此無論元素在各監(jiān)測器列表中的分布狀況如何,機(jī)制都能保持良好的性能.而篩選終止條件的判斷則確保了每一輪篩選都是能夠取得收益的必要篩選,使得通信開銷永遠(yuǎn)隨著篩選輪次數(shù)的遞增而遞減,因此可以最大程度地降低通信成本.
3 實(shí)驗(yàn)分析
本節(jié)給出仿真實(shí)驗(yàn)的具體細(xì)節(jié),結(jié)合對比實(shí)驗(yàn)分析了機(jī)制在降低通信開銷上的效果,并驗(yàn)證了機(jī)制在不同元素分布狀況下的性能.
3.1 實(shí)驗(yàn)設(shè)置
本文實(shí)驗(yàn)采用了公開數(shù)據(jù)集CAIDA中的真實(shí)網(wǎng)絡(luò)流量數(shù)據(jù)作為數(shù)據(jù)集,取其中12 min內(nèi)服務(wù)器記錄下的IP訪問信息,將其劃分為12個(gè)時(shí)間片.實(shí)驗(yàn)中,每個(gè)時(shí)間片(1 min)的數(shù)據(jù)都會(huì)被模擬為分布式監(jiān)測系統(tǒng)中一個(gè)監(jiān)測器節(jié)點(diǎn)所記錄的元素列表.在模擬的系統(tǒng)中一共有4 100 541條元素.其中每條元素包含1個(gè)源地址和1個(gè)目的地址,大部分IP地址都是IPv4地址,只有極少量的IPv6地址,所以直接發(fā)送1條元素的通信開銷h在本次實(shí)驗(yàn)中被設(shè)置為64 b.在系統(tǒng)包含的12個(gè)監(jiān)測器節(jié)點(diǎn)中,元素的分布大致均勻,平均每個(gè)監(jiān)測器約有34萬條元素記錄.為了適應(yīng)各種應(yīng)用場景,本文將t-重復(fù)元素的閾值t的數(shù)值設(shè)為4~12之間的任意數(shù)值,設(shè)收益閾值λ=0并分別進(jìn)行實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果均為多次實(shí)驗(yàn)后得到的平均結(jié)果.
本次實(shí)驗(yàn)的實(shí)驗(yàn)環(huán)境為Intel?CoreTMi7-7700 CPU 3.60 GHz,16 GB RAM.
3.2 性能分析
為了用作對比實(shí)驗(yàn),本文將文獻(xiàn)[10]中提出的CFSP算法加以修改,在整合壓縮數(shù)據(jù)時(shí)用逐位累加的方法取代逐位與,并在篩選結(jié)束后將剩余元素全部發(fā)送給協(xié)調(diào)器,以適應(yīng)所要解決的t-重復(fù)元素檢測問題.此外,雖然DISPERSE算法存在誤報(bào)與漏報(bào)情況,本文同樣將其與直觀算法一起納入對比.實(shí)驗(yàn)將從通信開銷、時(shí)間開銷、誤報(bào)漏報(bào)、算法的魯棒性等方面對機(jī)制進(jìn)行評(píng)價(jià).
4種算法的通信開銷如圖3所示,隨著閾值t的增大,改進(jìn)后的CFSP算法和本文提出的機(jī)制所耗費(fèi)的通信開銷不斷降低,DISPERSE算法的通信開銷基本趨于穩(wěn)定,直觀算法的通信開銷則始終保持在一個(gè)定值.這是因?yàn)椋瑃值的增大意味著t-重復(fù)元素的減少,所以在篩選過程中可以篩去更多的無關(guān)元素,進(jìn)一步降低了整體的通信開銷.而無論t取何值,DISPERSE算法都需對所有元素進(jìn)行編碼并且只依賴1次通信獲取結(jié)果,因此開銷趨于穩(wěn)定.直觀算法中監(jiān)測器總是將所有記錄下的元素直接發(fā)送給協(xié)調(diào)器,其通信開銷也是固定的,與t的取值無關(guān).可以看到,無論t取何值,所提出的機(jī)制總能在通信開銷的降低上取得較高的收益.當(dāng)t>8時(shí),機(jī)制的收益優(yōu)于其他3種算法.根據(jù)t的不同取值,本機(jī)制相比于直觀算法可以降低14%~79%的通信開銷,相比于改進(jìn)后的CFSP算法可以降低8%~26%的通信開銷,t>8時(shí)與DISPERSE算法比較可以節(jié)省11%~42%的通信開銷.機(jī)制會(huì)持續(xù)3~4輪的篩選,相較于改進(jìn)后的CFSP算法節(jié)省了3~4個(gè)輪次.
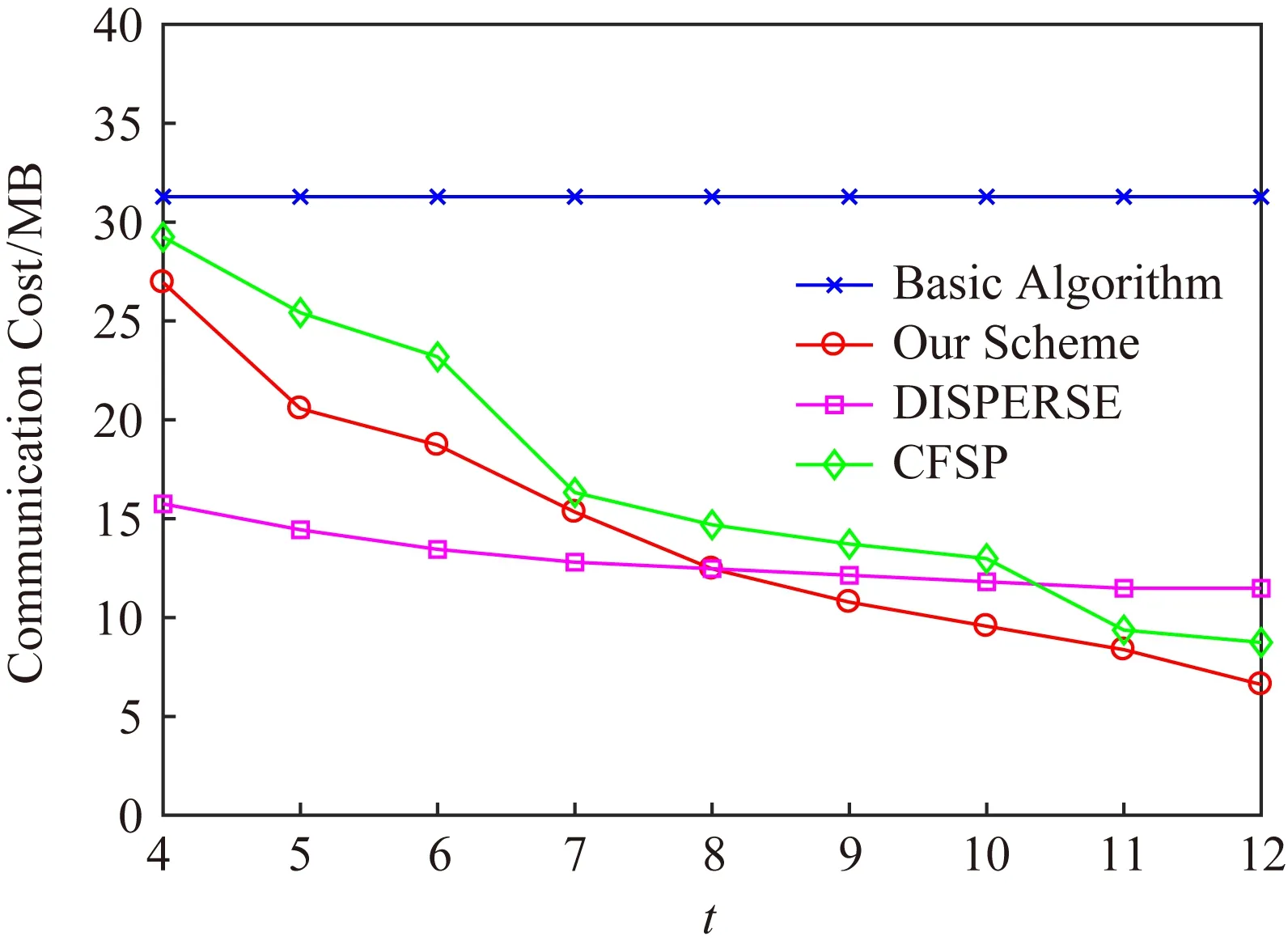
Fig. 3 Communication cost of our scheme andother three algorithms using the original data圖3 原始數(shù)據(jù)下機(jī)制與3種算法的通信開銷對比
因?yàn)镈ISPERSE算法的特殊性,表1單獨(dú)列出了其與本機(jī)制的性能數(shù)據(jù)以作對比,包含了全局的通信開銷、誤報(bào)率和漏報(bào)率.表1中的FPR(false positive rate)代表檢測結(jié)果中被誤判為t-重復(fù)元素的非t-重復(fù)元素在所有非t-重復(fù)元素中所占的比例,即誤報(bào)率.而FNR(false negative rate)代表未被檢測出的t-重復(fù)元素在所有t-重復(fù)元素中所占的比例,即漏報(bào)率.從表1可以看出,隨著t值的不斷增大,2種算法的通信開銷都呈下降趨勢.但相比之下,本機(jī)制的通信開銷下降速度更快,在t=8時(shí)基本與DISPERSE算法持平,此后的通信開銷更是優(yōu)于DISPERSE算法.此外,本機(jī)制在實(shí)驗(yàn)中始終沒有出現(xiàn)誤報(bào)漏報(bào)現(xiàn)象,而DISPERSE算法在保持著極低的誤報(bào)率的情況下,其漏報(bào)率卻不容忽視,且漏報(bào)率會(huì)隨著t值的增大而增大,從14%~38%不等.因此,相比于DISPERSE算法,本機(jī)制具有更為優(yōu)越的性能.
由于實(shí)驗(yàn)使用了連續(xù)時(shí)間片的網(wǎng)絡(luò)流量數(shù)據(jù)對監(jiān)測器的元素記錄進(jìn)行模擬,元素在系統(tǒng)中分布得較為均勻.為了檢測機(jī)制的魯棒性,我們進(jìn)一步地對數(shù)據(jù)進(jìn)行一定的處理,為每一個(gè)時(shí)間片隨機(jī)初始化一個(gè)概率并依據(jù)該概率在該時(shí)間片數(shù)據(jù)中隨機(jī)選取一些數(shù)據(jù)丟棄.經(jīng)過處理后,每個(gè)時(shí)間片包含的數(shù)據(jù)量從2~27萬條不等,由此模擬出的分布式監(jiān)測系統(tǒng)中,元素在各監(jiān)測器中的分布狀況極不均衡.在此基礎(chǔ)上,實(shí)驗(yàn)結(jié)果如圖4所示,可以看到,即使在元素分布不均勻的狀況下,本機(jī)制依舊可以保持良好的性能,甚至比在元素分布均勻的系統(tǒng)中表現(xiàn)得更為優(yōu)越.而當(dāng)t的取值較小時(shí),CFSP算法則表現(xiàn)得有些不穩(wěn)定,t=4時(shí)其消耗的通信成本甚至超過了直觀算法.機(jī)制相較直觀算法可以節(jié)省28%~96%的通信開銷,相較改進(jìn)后的CFSP算法可以節(jié)省21%~47%的通信開銷,t>4時(shí)與DISPERSE算法比較可以節(jié)省9%~91%的通信開銷.
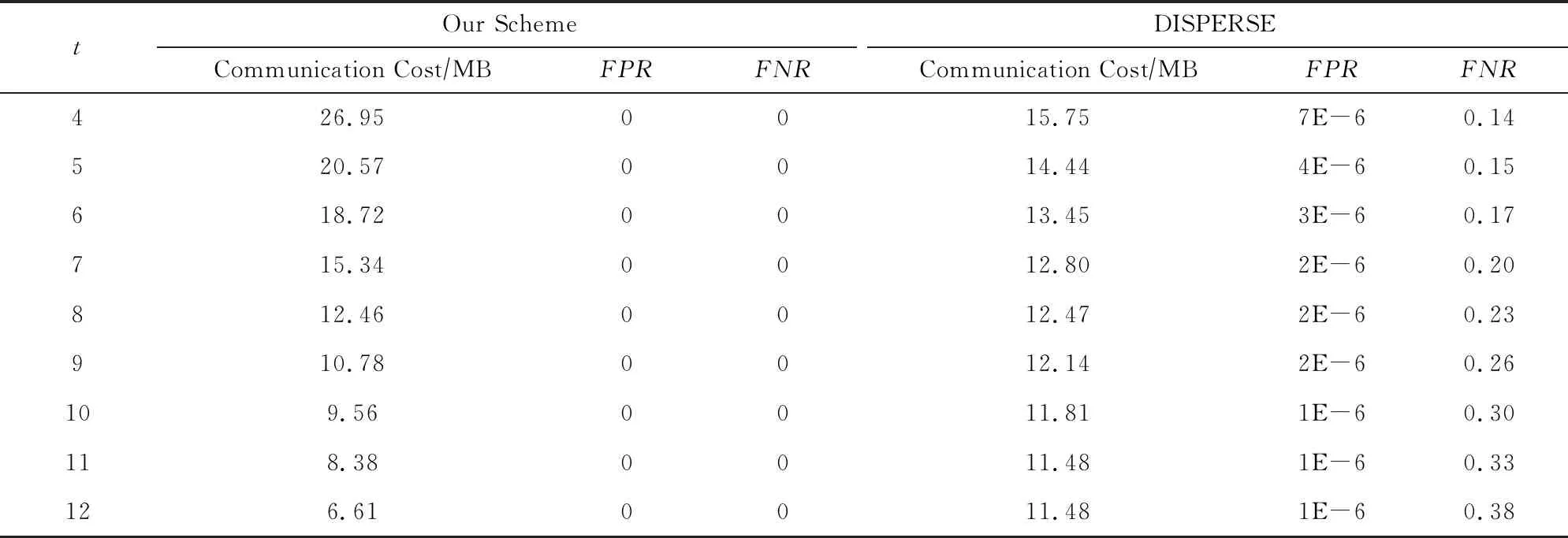
Table 1 The Performance Comparison of Our Scheme and DISPERSE Using the Original Data
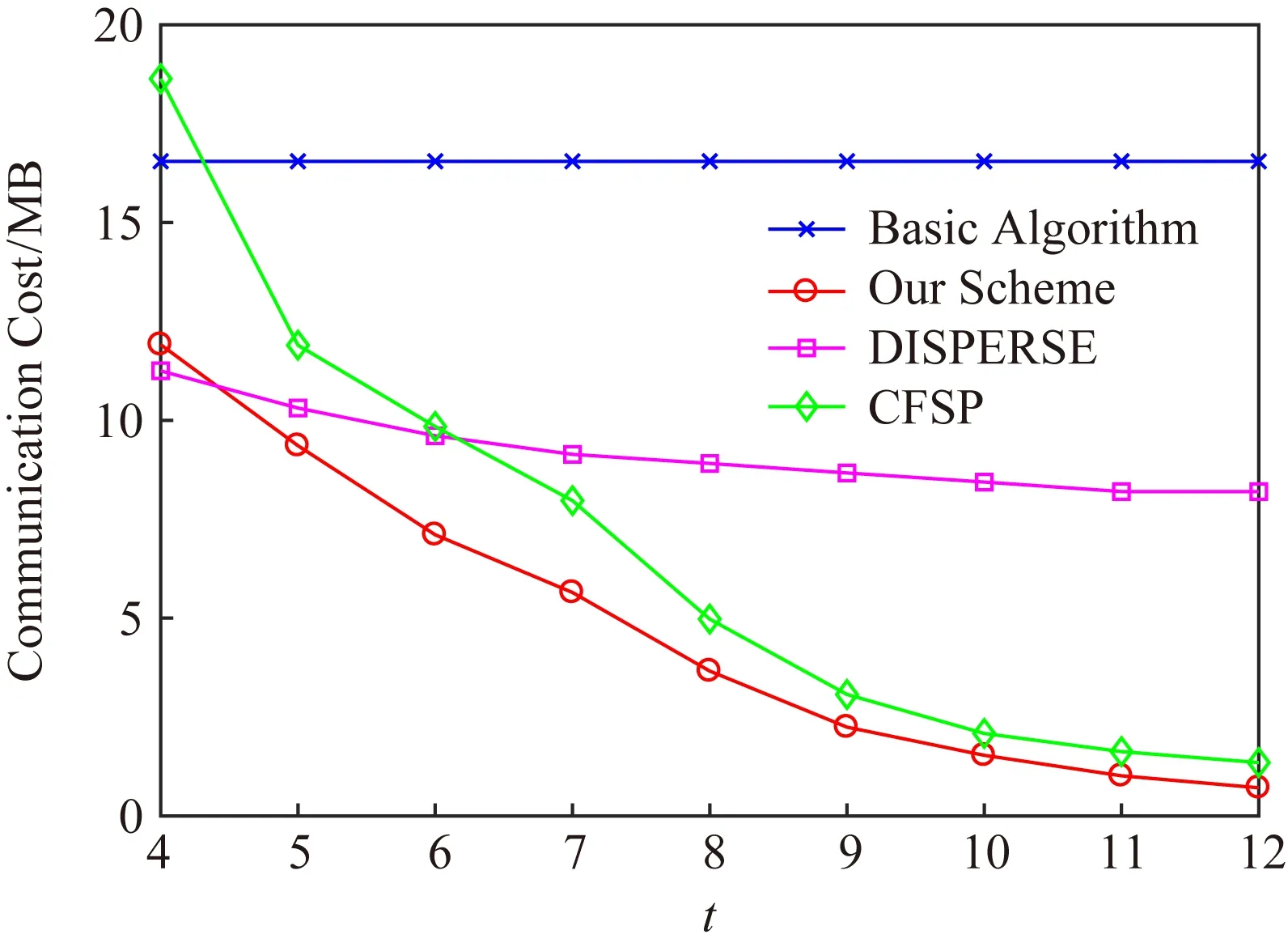
Fig. 4 Communication cost of our scheme and other three algorithms using the processed data圖4 處理后數(shù)據(jù)下機(jī)制與3種算法的通信開銷對比
在實(shí)驗(yàn)中,根據(jù)t的不同取值,篩選會(huì)持續(xù)3~4個(gè)輪次.其中當(dāng)t=8時(shí)各輪篩選的表現(xiàn)情況如表2所示,系統(tǒng)總共進(jìn)行了3輪篩選即達(dá)到終止條件,在此基礎(chǔ)上又額外進(jìn)行了第4輪篩選以作比較.
從表2可以看出,隨著篩選輪次的增加,篩選的收益在不斷減小.這是因?yàn)楹Y選降低的通信開銷和該輪篩選濾去的元素?cái)?shù)量呈正相關(guān),和每條元素的平均過濾代價(jià)呈負(fù)相關(guān).伴隨著篩選的進(jìn)行,非t-重復(fù)元素的數(shù)量大幅度減少,篩選中可以濾去的元素?cái)?shù)也隨之減小.而壓縮過程中用于給t-重復(fù)元素編碼的那部分?jǐn)?shù)據(jù)大小基本穩(wěn)定,且在篩選耗費(fèi)的總成本中的占比不斷增加,這使得篩選成本的降低幅度遠(yuǎn)遠(yuǎn)比不上篩去元素的減少幅度.因此隨著篩選次數(shù)的增加,篩選的收益,即其降低的整體通信開銷不斷減小.到了第4輪篩選,一共只篩去了48 635條元素,平均篩去1條元素需要108.5 b,而直接傳輸1條元素僅需64 b,所以該輪篩選反而讓整體收益有所降低.

Table 2 Performance of Each Round Using the Processed Data when t=8表2 當(dāng)t=8時(shí)處理后數(shù)據(jù)下各輪篩選的表現(xiàn)情況
此外,實(shí)驗(yàn)還從時(shí)間開銷的角度對機(jī)制進(jìn)行了性能分析.本機(jī)制的時(shí)間開銷主要可分為通信和運(yùn)算2部分.其中通信時(shí)間與通信開銷成正比,比如在100 Mbps的網(wǎng)絡(luò)環(huán)境下,無論t取何值,機(jī)制都能在1~2 s內(nèi)完成所有的數(shù)據(jù)傳輸.即使在50 Mbps的網(wǎng)絡(luò)帶寬下,機(jī)制也能在3 s內(nèi)完成通信.接下來主要對運(yùn)算時(shí)間進(jìn)行分析,其結(jié)果如表2所示.依照機(jī)制的檢測流程,本文將一輪篩選的運(yùn)算時(shí)間劃分為監(jiān)測器端和協(xié)調(diào)器端2部分,協(xié)調(diào)器端的運(yùn)算時(shí)間主要用于參數(shù)優(yōu)化和整合位數(shù)組,監(jiān)測器端的運(yùn)算時(shí)間則包含了元素置位和篩去非t-重復(fù)元素所耗費(fèi)的時(shí)間.其中,前2輪篩選的參數(shù)優(yōu)化只進(jìn)行了簡單的計(jì)算,所以幾乎不占用時(shí)間資源.而監(jiān)測器進(jìn)行置位和篩選是所有監(jiān)測器同步進(jìn)行的,所以只取這些監(jiān)測器中運(yùn)算時(shí)間的最大值.可以看到,隨著篩選輪次的增加,元素列表的規(guī)模不斷減小,監(jiān)測器端所消耗的運(yùn)算時(shí)間也呈下降趨勢.在第3輪及后續(xù)輪次的篩選中,因?yàn)樾枰C合全局狀況求解最優(yōu)參數(shù),所以相比前2輪篩選依據(jù)公式計(jì)算參數(shù),協(xié)調(diào)器端需要更多的運(yùn)算時(shí)間.
上述實(shí)驗(yàn)過程中,協(xié)調(diào)器總是依據(jù)對下一輪收益pq的預(yù)測未達(dá)到預(yù)期而發(fā)出終止信號(hào),每一輪篩選都能有效降低整體的通信開銷.而協(xié)調(diào)器給出的檢測結(jié)果包含了所有t-重復(fù)元素,且沒有任何一條非t-重復(fù)元素被誤報(bào),這也驗(yàn)證了此前的理論分析.
4 總 結(jié)
針對分布式系統(tǒng)中t-重復(fù)元素檢測問題,以最大化降低通信開銷為優(yōu)化目標(biāo),提出了一種適用于分布式監(jiān)測系統(tǒng)的t-重復(fù)元素檢測機(jī)制.通過篩選過程中對監(jiān)測器信息的整合和動(dòng)態(tài)預(yù)測,確保了機(jī)制的強(qiáng)健性,保證了每一輪篩選通信代價(jià)的最小化.使用真實(shí)網(wǎng)絡(luò)流量數(shù)據(jù)進(jìn)行的模擬實(shí)驗(yàn)結(jié)果表明:無論系統(tǒng)中元素分布均勻與否,機(jī)制都能取得良好的效果.在相似的性能及實(shí)驗(yàn)環(huán)境下,機(jī)制的穩(wěn)定性和在降低通信開銷上的表現(xiàn)優(yōu)于直觀算法,改進(jìn)后的CFSP算法和DISPERSE算法.
猜你喜歡
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
文苑(2018年21期)2018-11-09 01:23:06
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
中國衛(wèi)生(2015年9期)2015-11-10 03:11:12
