基于三尺度嵌套殘差結構的交通標志快速檢測算法
2020-06-08 09:00:12李旭東張建明謝志鵬
計算機研究與發展 2020年5期
李旭東 張建明 謝志鵬 王 進
(長沙理工大學計算機與通信工程學院 長沙 410114)(綜合交通運輸大數據智能處理湖南省重點實驗室(長沙理工大學) 長沙 410114)
近年來,依靠計算機視覺與人工智能等相關技術的發展,自動駕駛呈現出接近實用化的趨勢.利用前端相機采集的圖像進行交通標志、車道線、信號燈的檢測與識別是自動駕駛的重要研究內容.交通標志檢測屬于特定目標的檢測,不僅具有通用目標檢測的難點,同時還會因特殊環境造成交通標志的遮擋、污損、模糊、褪色、變形等;同一類的交通標志在不同時間、天氣、角度、光照以及分辨率的情況下會呈現不同的檢測效果.實時的交通標志檢測作為自動駕駛的重要組成部分,是難度較大的實景目標檢測,同時對于準確性和穩定性也有很高要求.
目前按照不同的檢測手段,將交通標志檢測主要分為傳統方法和基于深度學習的方法.傳統方法中,以顏色、形狀等特征以及多種特征相結合的檢測為主;基于深度學習的方法分為2階段檢測方法R-CNN(region-convolutional neural networks)系列檢測算法和1階段檢測方法YOLO(you only look once)系列檢測算法,SSD(single shot multibox detector)系列檢測算法.現有的針對真實場景下交通標志的檢測算法大多只注重于準確率的提升,而忽略了應用場景中算法所需要具備的高實時性.實時性越高,檢測速度越快,能為駕駛者及自動駕駛系統提供更好的預警.YOLO系列檢測算法以速度為首要標準,其中YOLOv3檢測算法中利用多個尺度預測大幅提高小目標的檢測能力,而YOLOv3-tiny檢測算法則是以其更快的檢測速度著稱.因此,我們以YOLOv3-tiny檢測算法為基礎網絡,在不影響檢測速度的條件下,設計嵌套殘差結構和多尺度預測機制,構建了一個改進的YOLOv3-tiny檢測算法,從而訓練出一個高實時性和高魯棒性的交通標志檢測模型.
本文的主要貢獻有4個方面:
1) 在YOLOv3-tiny檢測算法的基礎網絡Darknet-19中,將中間層特征采用逐像素相加方式進行跨層連接,不會增加特征圖通道數,形成1個較小的殘差結構;
2) 將淺層特征跨層連接至深層特征進行逐像素相加,構成1個較大的殘差結構,并設計增加1層輸出預測層,使得該層能包含更豐富的空間細節信息,提高模型對小目標的檢測能力;
3) 將小殘差和大殘差結構進行嵌套,形成三尺度嵌套殘差結構,使得Tiny檢測算法的部分主網絡位于這2個殘差結構中,其作用是在訓練過程中能對其進行3次調參,進一步提高了模型的泛化能力;
4) 在2個不同國家的交通標志檢測數據集德國交通標志檢測數據集(German traffic sign detection benchmark, GTSDB)和長沙理工大學中國交通標志檢測數據集(CSUST Chinese traffic sign detection benchmark, CCTSDB)上,我們對提出算法的每個創新點進行驗證,并與當前主流的交通標志檢測算法進行了全面的對比.實驗效果表明:提出的方法不僅具有較高的檢測魯棒性,更具有高效的計算能力,單張圖像的檢測時間僅為5 ms.
1 相關工作
傳統的交通標志檢測算法:交通標志具有鮮明的顏色特征,通常在諸如RGB,HIS,HSV等不同顏色空間中獲取交通標志信息.Le等人[1]對RGB設置閾值,篩選出交通標志的紅色和藍色區域,對2×2的像素塊采用SVM進行分類,得到1個較為準確的快速交通標志檢測系統.Zhang等人[2]通過歸一化RGB到RGBY顏色空間,并針對不同顏色提出了一種新的顏色閾值約束方案,提高了檢測效果.同時交通標志也具有顯著的形狀特征,谷明琴等人[3]根據直線間頂點處的曲率關系,利用轉向角對頂點進行分類,并提出無參數形狀檢測子,使用該算子來檢測圖像中的警告、禁令和指示標志.但是,單一的顏色或形狀特征無法滿足真實場景中的高精度檢測,將兩者相結合的方法精度相比于單一特征會有較大提升.Xu等人[4]結合自適應顏色閾值分割和形狀對稱性假設檢驗可以有效提取交通標志候選框.張靜等人[5]使用HSI空間特征與形狀特征結合,很大程度上解決了其他顏色分量對檢測目標的影響,提高了檢測精度.
基于深度學習的2階段檢測方法:2014年,Girshick等人[6]提出了R-CNN目標檢測算法,使用從選擇性搜索和邊緣框中生成的建議區域來訓練卷積網絡,生成了基于區域的特征,并采用SVM(support vector machine)進行分類.隨后,SPPNet[7]引入空間金字塔池化層,在不考慮輸入圖像分辨率大小的情況下,允許分類模塊重用卷積特征.Fast R-CNN[8]檢測算法結合SPPNet并利用分類和位置回歸損失值進行端到端的訓練.Faster R-CNN[9]檢測算法則是用區域建議網絡(region proposal network, RPN)替代選擇性搜索,RPN用于生成候選邊界框并過濾背景區域,此外還利用了另一個小網絡進行分類和位置的回歸.Yang等人[10]基于Faster R-CNN檢測算法進行改進,使用注意力網絡代替RPN網絡用于交通標志建議區域的生成,其模型在TT100K[11]數據集以及BTSD[12]數據集上分別取得96.05%和98.31%的準確率.
基于深度學習的1階段的檢測方法:為了克服2階段檢測方法實時性差的問題,YOLO[13]檢測算法將輸入圖像劃分為若干網格,并對每個網絡進行定位和分類,大幅提升了目標檢測的速度,但精度卻不夠理想.YOLOv2[14]檢測算法是基于YOLO檢測算法的增強版本,通過移除全連接層來改進YOLO檢測算法.我們針對中國交通標志的特征,改進了YOLOv2檢測算法,并且公布了中國交通標志數據集CCTSDB,該改進方法在CCTSDB和GTSDB[15]兩個數據集上分別獲得很高的準確率[16].YOLOv3[17]檢測算法對YOLOv2檢測算法進行改進,增加了網絡層數,在Darknet-53基礎網絡上引入多尺度預測實現了更好的分類和檢測效果.YOLOv3檢測算法在Titan XP上的處理速度能達到20f/s,在COCO測試集上分類精度達到57.9%.YOLOv3檢測算法的模型較于原先的模型提高了復雜度,可以通過改變模型結構的大小權衡速度與精度.
SSD[18]檢測算法是另一種典型的1階段目標檢測方法.SSD檢測算法通過2個卷積層來分別預測邊界框的類別置信度和位置偏移量.為了檢測不同尺度的目標,SSD檢測算法增加了一系列逐漸變小的卷積層生成金字塔特征圖,根據各層的感受野大小設置相應的錨點,并利用非極大值抑制對最終檢測結果進行處理.為了提高精度,DSSD[19]檢測算法提出了將反卷積層來增強淺層的大尺度背景,其模型較為復雜,檢測速度較慢.Tian等人[20]基于DSSD檢測算法加入了注意力網絡,將相鄰層的相關上下文細節結合到檢測體系結構中,其提出的檢測模型在GTSDB檢測數據集上取得了很高的精度.RSSD[21]檢測算法通過引入彩虹連接,充分利用了特征金字塔中的各層之間的關系,盡管提升了精度,但損失了部分的計算時間.
2 算法基礎
YOLOv3[17]檢測算法是當前速度和精度比較均衡的目標檢測算法之一.YOLO系列檢測算法算法每個版本都有對應的Tiny版本.Tiny版本以原始算法為主框架,通過精簡得到快速檢測網絡,速度是原始算法的3倍以上,但由于過于精簡卷積操作,其精度并不理想.真實場景的交通標志檢測中更加注重實時性能,因此我們以YOLOv3-tiny檢測算法為基礎網絡,在不影響檢測速度的條件下,結合殘差結構與多尺度預測的思想,構建一個改進的YOLOv3-tiny檢測算法,從而訓練出一個高實時性和高魯棒性的交通標志檢測模型.
2.1 YOLOv3系列檢測算法
YOLOv3檢測算法采用全新的網絡來實現特征提取,通過殘差塊來加深網絡,達到106層,在多個尺度的特征圖上進行檢測,能顯著提升小目標的檢測效果.
YOLOv3-tiny檢測算法是一個在YOLOv3檢測算法基礎上精簡而來的輕量級網絡模型,具有23層網絡,只包含卷積層和最大池化層,相比于YOLOv3檢測算法大大減少了網絡層數,這使得它的檢測速度是YOLOv3檢測算法的3倍之多.在YOLOv3-tiny檢測算法主干網特征提取部分,一共有16層,其中卷積層有10個,最大池化層6個.在YOLOv3-tiny檢測算法主干網檢測部分,只使用了2個尺度的特征圖進行檢測框回歸和分類,分別是13×13的特征圖,以及它經過上采樣后與26×26的特征圖通過通道串接形成的特征圖.相比YOLOv3檢測算法少了一個尺度預測,其每一個網格的預測框數量也從9個變成6個.YOLOv3-tiny檢測算法中的檢測框回歸和分類任務與YOLOv3檢測算法保持一致,且損失值計算的原理相同.
2.2 殘差塊思想
深度神經網絡中隨著網絡深度的增加,訓練會變得愈加困難.這主要是由于在使用隨機梯度下降的網絡訓練過程中,誤差信號的多層反向傳播極易引發梯度消失或梯度爆炸.針對這個問題,He等人[22]在網絡中構建了恒等映射,可以在增加網絡層數的同時不增加訓練誤差.
如圖1(a)所示,假設網絡輸入為X,輸出為H(X):
H(X)=F(X)+X,
(1)
殘差是實際觀察值減去擬合的預測值.網絡只需要在訓練的時候不斷調整F(X)的參數來學習殘差F(X),這會比直接學習H(X)更簡單.
F(X)=H(X)-X,
(2)
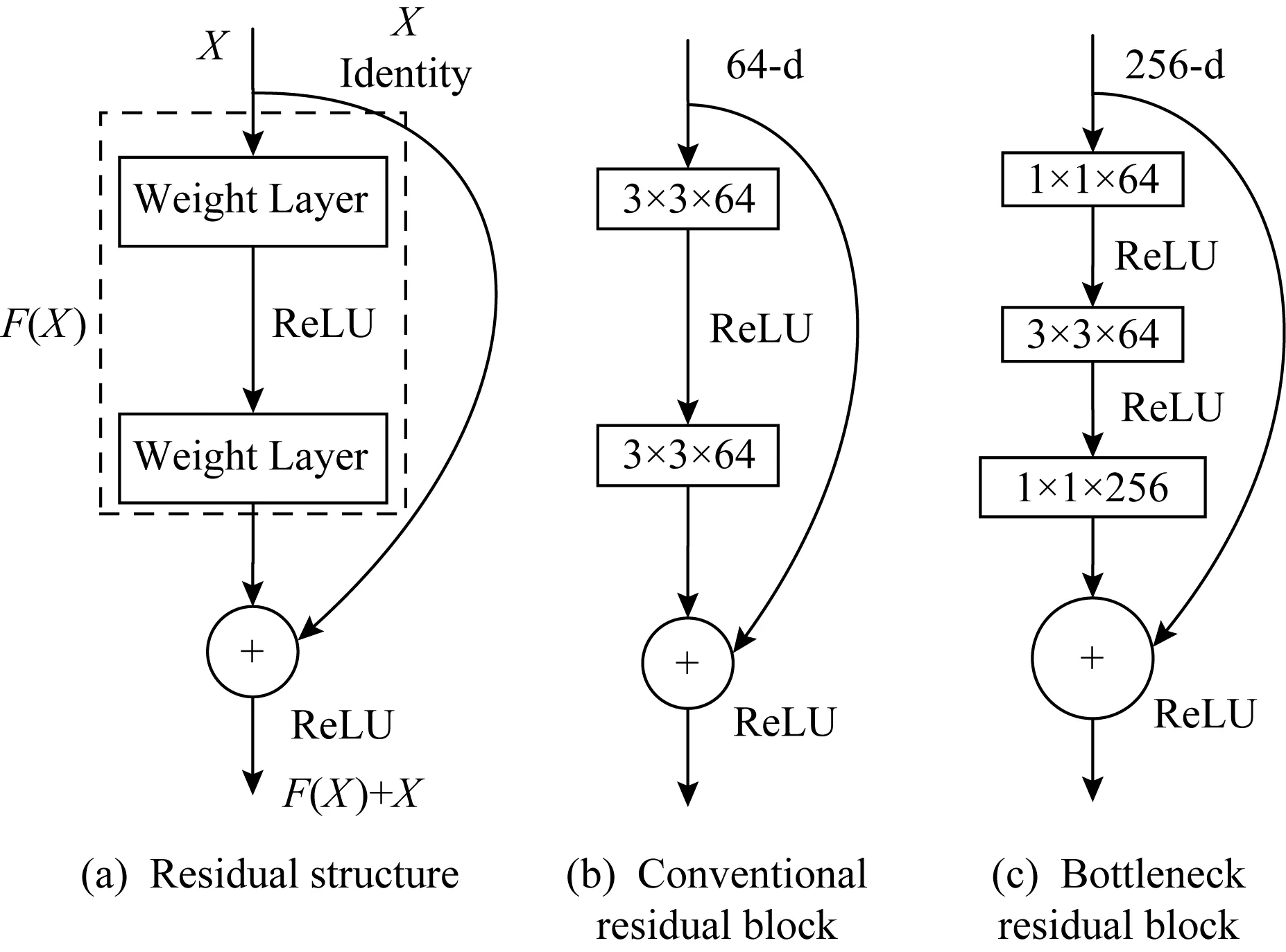
Fig. 1 Residual module圖1 殘差模塊
例如當期望輸出H(X)就是輸入X時:對于沒有跨層連接的結構,需要將其優化成H(X)=X;對于殘差結構,只需將F(X)=H(X)-X優化為0即可.
這里是使用特征圖逐像素相加的方式來得到的H(X).在ResNet結構中會用到2種殘差模塊,圖1(b)所示的是常規殘差模塊,由2個3×3卷積堆疊而成.圖1(c)的結構稱為“瓶頸殘差模塊”,依次由1×1,3×3,1×1這3個卷積層構成,其中每層之間均有線性整流函數(rectified linear unit, ReLU)進行激活連接.
3 基于三尺度嵌套殘差結構的快速檢測算法
3.1 改進思想
YOLOv3-tiny檢測算法的網絡結構與YOLOv2-tiny檢測算法類似,增加了1層多尺度預測輸出,而其和YOLOv3檢測算法的結構又有差別,沒有采用YOLOv3檢測算法中的殘差塊來加深網絡.Tiny版本更加注重檢測時間,增加網絡層的數量會提高檢測精度,但過多的增加層數又會導致更多的時間損耗,因此不能僅僅依靠增加網絡深度來提高Tiny版本的檢測精度.首先,我們結合殘差網絡中特征圖逐像素相加的跨層連接思想,在Tiny網絡中構建1個小殘差結構,即二尺度殘差結構;在此基礎上,將淺層特征跨層連接至深層特征進行逐像素相加,構成1個較大的殘差結構,并設計增加1層輸出預測層;最后,將以上2個殘差結構進行嵌套,形成了三尺度嵌套殘差結構.
本文中所涉及的定義和操作說明有5項:
1) 第m層.文中描述所涉及的“第m層”為表1算法檢測流程中操作的序號,并非圖2中所對應的層數,圖2中的層數只用作結構展示.
2)Route1(m).Darknet框架中用函數Route進行跳轉操作.Route1(m)表示從當前層跳轉至第m層.
3)Route2(m,n).Darknet框架中用函數Route還可以進行通道串接操作.Route2(m,n)表示將第m層和第n層特征圖進行通道串接,輸出1個與輸入特征圖寬高相同、通道維度更高的新特征圖,此操作要求第m層與第n層特征圖的對應寬、高必須相等,而通道數可以不相等.
4)Shortcut(m).函數Shortcut在Darknet框架中是進行逐像素相加操作.其表示當前操作層的輸入(即上一層輸出特征圖)與第m層的特征圖進行逐像素相加,輸出1個與輸入特征圖空間尺度完全一致的全新特征圖.此操作要求當前層的輸入與第m層特征圖對應的寬、高以及通道數必須相等.
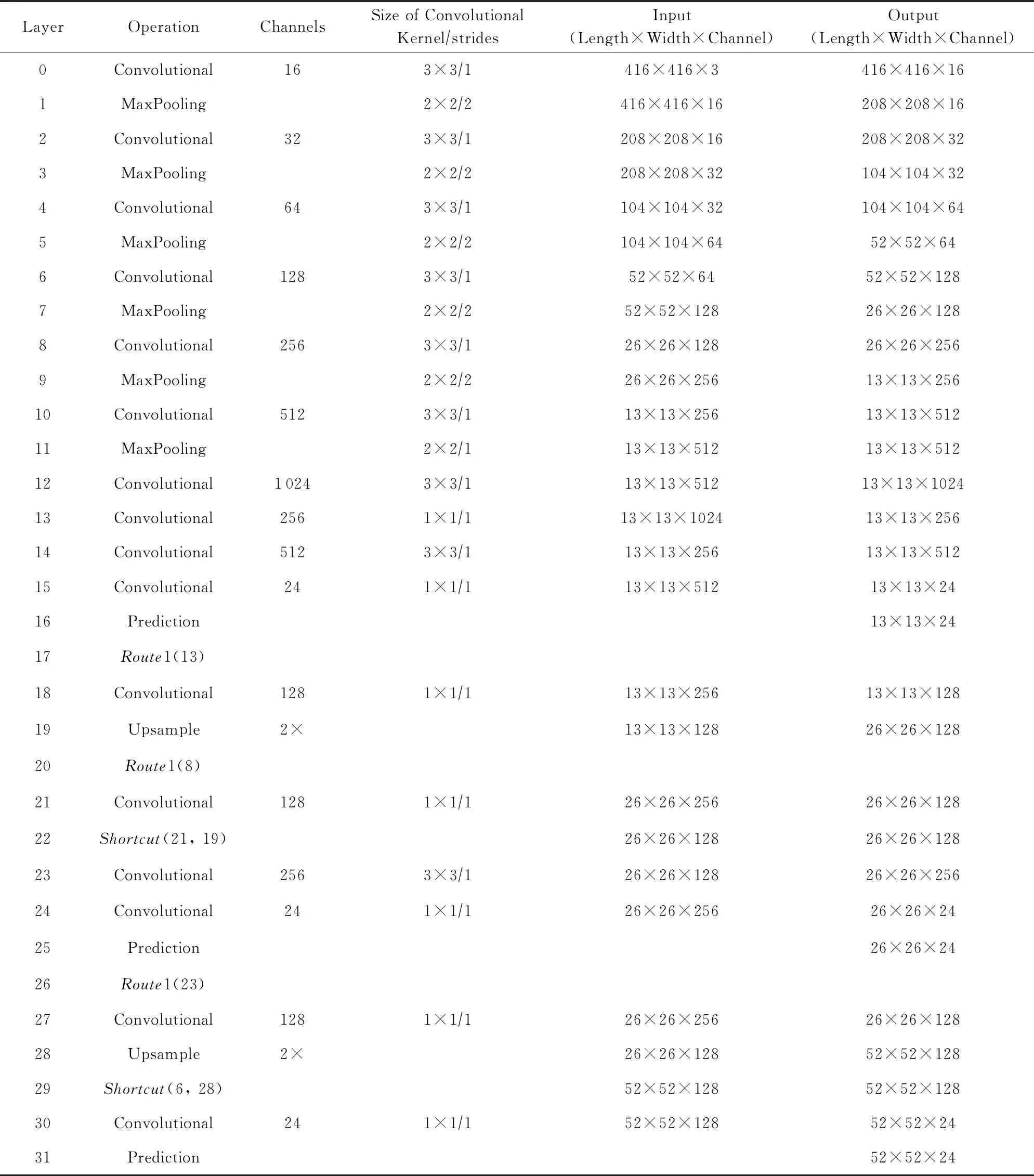
Table 1 The Process of Our Rroposed Algorithm表1 我們的算法流程
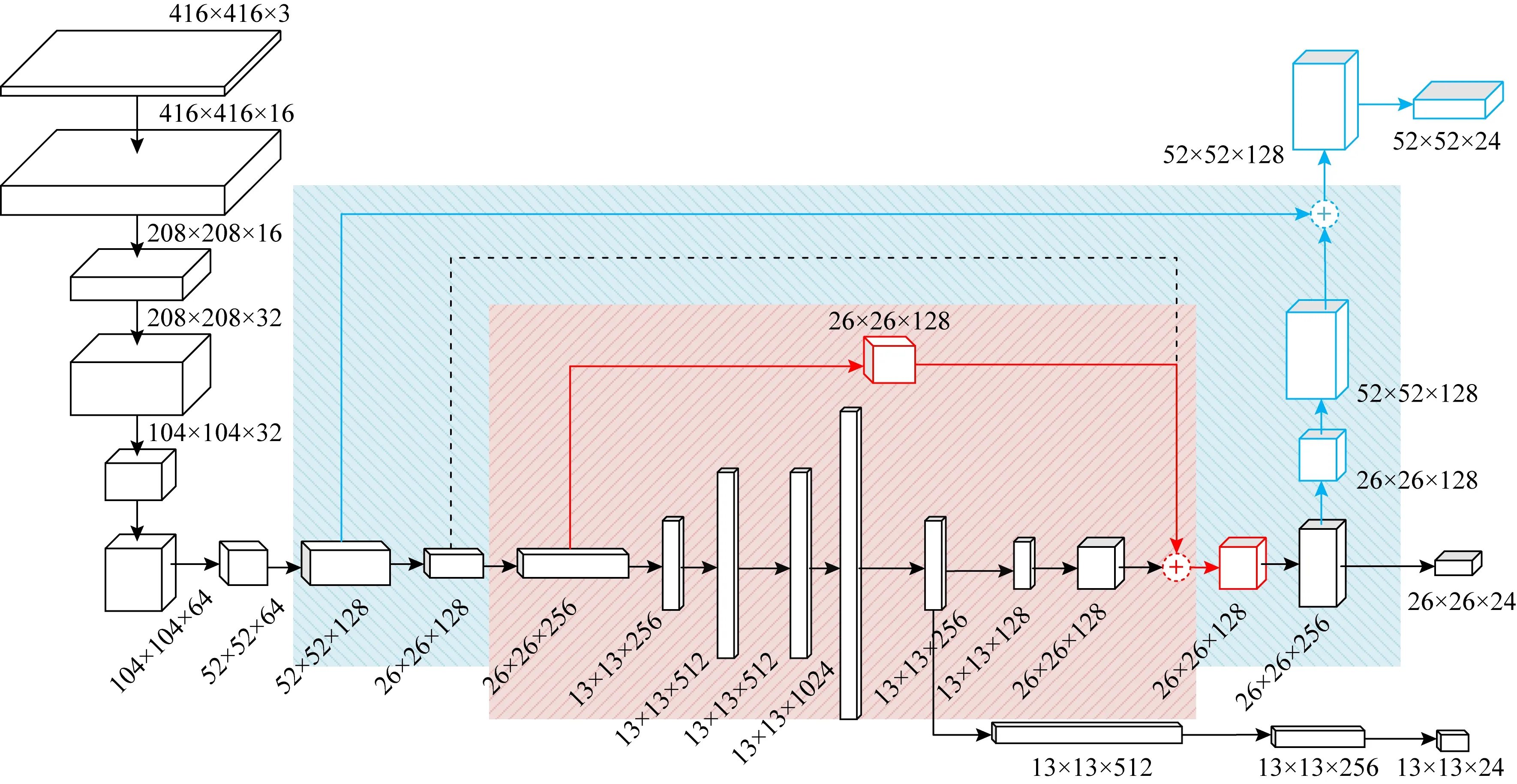
Fig. 2 Framework of our proposed algorithm圖2 本文算法的結構圖
5) 嵌套.與普通殘差網絡中殘差塊相互串聯或并聯不同,嵌套殘差由小殘差結構與大殘差結構共同組成,小殘差結構嵌套于大殘差結構中,且小殘差結構是大殘差結構的一部分,大殘差結構是主網絡的一部分.
3.1.1 二尺度殘差結構
如圖2所示,黑色實線和虛線部分為YOLOv3-tiny檢測算法的結構圖,黑色虛線部分為Tiny原有的通道串接操作.與YOLOv3系列檢測算法中的跨層連接操作不同,殘差塊結構中采用的是對應像素相加的方式來實現F(X)+X.
我們將YOLOv3-tiny檢測算法中的跨層連接操作進行改進,采用逐像素相加操作代替通道串接操作.如圖2所示,紅色實線部分為改進的跨層連接方式.將跨層連接的輸入向后移1層,雖然使用原黑色虛線部分的操作可以減少1次卷積從而直接進行逐像素相加,但在后期增加三尺度模塊時發現,藍色逐像素相加操作與黑色虛線相隔太近,兩層之間僅進行了最大池化操作,這導致2個特征圖之間的差異性不夠大.因此我們使用后一層經過卷積的特征圖,這與之前的特征圖在尺寸以及通道數上不同,使輸出更加豐富.但由于逐像素相加操作要求輸入空間尺度完全一致的特征圖,因此還需要先進行1次降維操作.此時,相加后輸出的特征圖大小為26×26×128,相比于改進前的輸出特征圖(26×26×256)在通道維度上減少了128維,將這128維的信息通過對應像素相加的方式融合到了新的輸出特征圖中.由于通道維度的降低,使得下一個卷積層中卷積操作的時間消耗減少了一半.同時,圖2中粉紅色區域塊形成了小殘差結構.當采用逐像素相加進行連接后,按照殘差網絡的基本原理,我們將把Tiny主網絡中被跨層區域作為殘差網絡中的F(X)部分,紅色實線則是引入了淺層更具有細節信息的特征圖,最后將深層與淺層的特征圖進行融合,達到提高檢測精度的效果.在網絡訓練時,整個網絡會按照YOLO系列檢測算法進行訓練調參,同時也會按照殘差網絡的方法不斷調整F(X)區域中各個卷積層的參數,實現2次優化調參.在圖2中黑色實線與紅色實線部分組成了二尺度殘差結構.
3.1.2 三尺度嵌套殘差結構
為了進一步提高對小尺寸目標的檢測精度,我們設計并輸出了多層特征圖,這些特征圖在空間細節和語義上具有互補性,算法可以在不同尺度大小的特征圖上進行預測.由于已經通過減少1層卷積層操作數量降低了時間消耗,我們對Tiny版本增加1層尺度的預測輸出,檢測時間變化不大.如圖2所示,藍色實線部分為增加的預測層,增加的預測層輸出大小為52×52×24,這一層較其他2個預測層的空間分辨率更高,特征圖中包含的空間細節信息越多,就有助于算法對小目標的檢測.同時,將增加的這一預測層也采用逐像素相加的跨層連接,融合淺層中的豐富細節信息.與之前的小殘差結構類似,圖2中粉藍色區域塊組成了大殘差結構.將小殘差和大殘差結構進行嵌套,形成三尺度嵌套殘差結構,此時小殘差結構位于大殘差結構中的F(X)部分,在訓練過程中,處于主干網絡的小殘差結構F(X)部分將會進行第3次優化調參.在圖2中除黑色虛線部分,其他結構所構成的就是三尺度嵌套殘差的YOLOv3-tiny檢測算法.
3.2 算法流程
基于三尺度嵌套殘差結構的YOLOv3-tiny檢測算法流程如表1所示.網絡可以接受任意尺寸的RGB彩色圖像輸入,然后將大小重置為416×416進行操作.整個網絡共16個卷積層、6個最大池化層、2次上采樣和3個預測輸出層.網絡層0~11為卷積層與最大池化層組合,是為了進行快速的下采樣降低特征圖尺寸;網絡層12~15為卷積層,是為了增加網絡擬合能力,同時最后一個卷積層可以降低特征圖維度;網絡層8~22構成了圖2中粉紅色區域的小殘差結構,網絡層6~29構成了粉藍色區域的大殘差結構;層16,26,31為預測輸出層,其輸出尺度大小分別為13×13×24,26×26×24,52×52×24.
3.3 損失函數
基于三尺度嵌套殘差結構的YOLOv3-tiny檢測算法中的檢測框回歸和分類任務與YOLOv3-tiny檢測算法保持一致,且損失值計算的原理相同.不同的是,在YOLOv3-tiny檢測算法中只有2個分支預測,而提出的算法中有3個分支預測,因此后者需要分別計算3個尺度分支相應的定位損失值、IOU損失值以及分類損失值.提出的算法中對每個預測的包圍框(bounding box)通過邏輯回歸計算一個目標的得分,若該預測的包圍框與真實的包圍框大部分重疊且比其他所有預測要好,則該值將會被保存,若重疊比例沒有達到IOU閾值,則該預測包圍框將會被忽略.YOLOv3系列檢測算法只為每個目標選取一個IOU值最高的預測包圍框,結合真實(ground truth)的包圍框,計算該預測包圍框的損失.總損失函數計算:
LN=Lcoord+LIOU+Lclasses,
(3)
其中,N表示YOLO預測分支所在的主網絡輸出的層數位置,LN代表不同尺度的預測輸出的損失值.在原版YOLOv3中N∈{82,94,106};在原版YOLOv3-tiny中N∈{16,23};我們提出的改進算法中N∈{16,25,31}.
Lcoord為定位損失值,計算的是預測包圍框的坐標誤差,即左上角點坐標與寬高的誤差值:
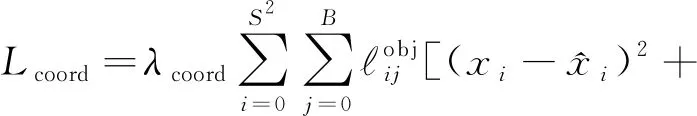
(4)
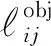
LIOU為IOU損失值,計算的是IOU值最大的預測包圍框與真實包圍框的誤差:
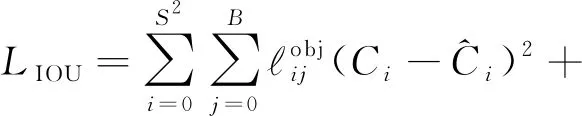
(5)
式(5)等號右邊第1項表示包含目標的預測包圍框的置信度預測值,第2項表示不包含目標的預測包圍框的置信度預測值.其中Ci為目標類別,λnoobj是未含目標的預測包圍框的約束系數.
Lclasses為分類損失,計算的是預測類別與真實類別間的誤差:
(6)
4 實驗與分析
4.1 實驗設置
本實驗的訓練環境與測試環境硬件不同.訓練需要耗費大量的GPU資源與磁盤空間,因此訓練使用的是性能更佳的CPU為Intel Xeon E5-2670 v3,GPU為TITAN X,顯存為12 GB的服務器.測試選取的環境是CPU為Intel Core i7-6700K,GPU為GTX980Ti,顯存6 GB的普通主機.所有的訓練以及測試模型使用的均在Linux環境下.
我們在GTSDB和CCTSDB兩大數據集上進行了多組對照實驗.GTSDB是德國交通標志圖像檢測數據集,也是交通標志檢測中最廣泛應用的數據集之一.CCTSDB[16]是我們提出的中國交通標志數據集,包含圖片近15 000張、交通標志近60 000個.目前的標注數據有三大類:指示標志、禁令標志、警告標志.CCTSDB的測試數據集使用的是重新標注過的CTSD[23]的400張測試圖像.
我們設置了模型1與模型2為對照實驗中的實驗組,其中模型1是二尺度殘差的Tiny檢測算法,共25層,主網絡結構與YOLOv3-tinys檢測算法相同,跨層連接中采用特征圖對應像素相加代替YOLOv3-tiny檢測算法的特征圖通道串接,一共有2個預測層,分別在第16,25層輸出大小為26×26,52×52的預測特征圖;模型2是三尺度嵌套殘差結構的Tiny檢測算法,共31層,網絡結構與模型1相似,在模型1的基礎上增加了1個YOLO預測輸出層,一共3個預測層,分別在第16,25,31層輸出大小為13×13,26×26,52×52的預測特征圖.對比實驗將選取對照實驗中性能最佳的模型與現有的主流交通標志檢測算法進行對比.
我們使用了多個標準來評價不同算法的性能,包括精確率(precision,P)、召回率(recall,R)、F1值、平均絕對誤差DMAD等.精確率是被預測成正的樣本中預測正確的比例;召回率是正樣本中被正確預測的比例;F1值是精確率和召回率的調和均值.為了衡量模型在不同IOU閾值下的穩定程度,我們引入了平均絕對誤差,平均絕對誤差是所有單個觀測值與算術平均值偏差的絕對值的平均值,它可以避免誤差相互抵消的問題,因而可以準確反映實際預測誤差的大小,通常該值越小表示模型越穩定.
我們對以上變量進行定義:將正樣本預測正確,記該類樣本數為TP;將正樣本預測錯誤,記該類樣本數為FN;將負樣本預測為正樣本,記該類樣本數為FP;n表示在不同IOU閾值下P或R的數量;xk表示第k個P或R的值;m(x)表示該組P或R的平均值,計算這些度量標準:
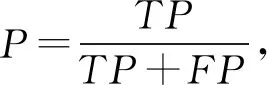
(7)
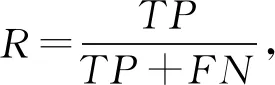
(8)
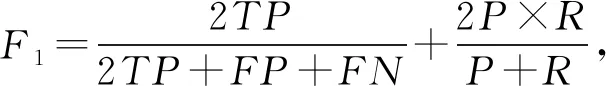
(9)
(10)
4.2 參數設置
各模型實驗中具有較多的預設參數,這些參數在訓練時會極大程度影響實驗效果.為了保證變量的單一性,我們固定其他參數,只改變網絡層相關參數,來證明每個創新點加入網絡中的效果.所有對照實驗中輸入網絡的圖像大小為416×416、學習率為0.001、每批次樣本數為64、每次送入訓練器的樣本數為8、迭代次數為200 000、每1 000次迭代輸出一個網絡模型.選定初始IOU閾值θ=0.5時,使用均值平均精度mAP來篩選出200個結果中最佳的模型作為此網絡結構的訓練結果.
4.3 實驗結果與分析
4.3.1 GTSDB數據集上的評估
首先,我們將對照實驗的3個模型在GTSDB數據集上一起進行評估,德國交通標志檢測數據集是目前應用最廣泛的檢測標準之一,在此標準下我們會選取一個最優的檢測模型.
表2列出了3個模型在GTSDB數據集上使用不同IOU閾值的三大類交通標志P,R值,其中我們設定IOU閾值的范圍是0.1~0.9,閾值間隔為0.1.從表2中可知,對于每一個模型來說,當IOU閾值增加時,模型的精確率會增加,而召回率會隨之降低.這是由于增大的IOU閾值會使得模型篩選出來的預測框更加少,從而極大程度上保留了正確的預測框,但同時也會剔除一些正確的預測框.從表2可以看出,對于每一類標志來說,模型1的指示標志與禁令標志的精確率可以達到91.43%和100.00%,模型2上禁令標志精確率及三大類mAP達到了98.68%和90.94%;模型2的指示標志、警告標志以及Tiny檢測算法的禁令標志的召回率分別可以達到87.76%,93.65%,96.89%.
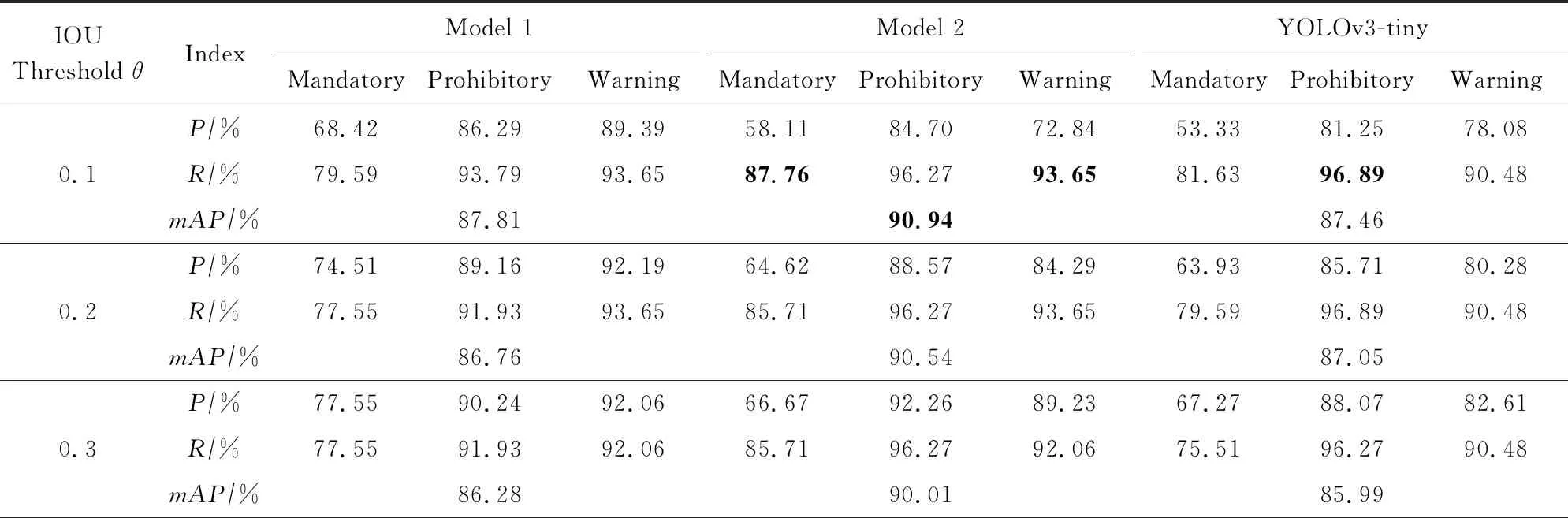
Table 2 P,R Values of Three Models Using Different IOU Thresholds in Three Kind of Traffic Signs on GTSDB表2 3個模型在GTSDB數據集上使用不同IOU閾值的三大類交通標志P,R值
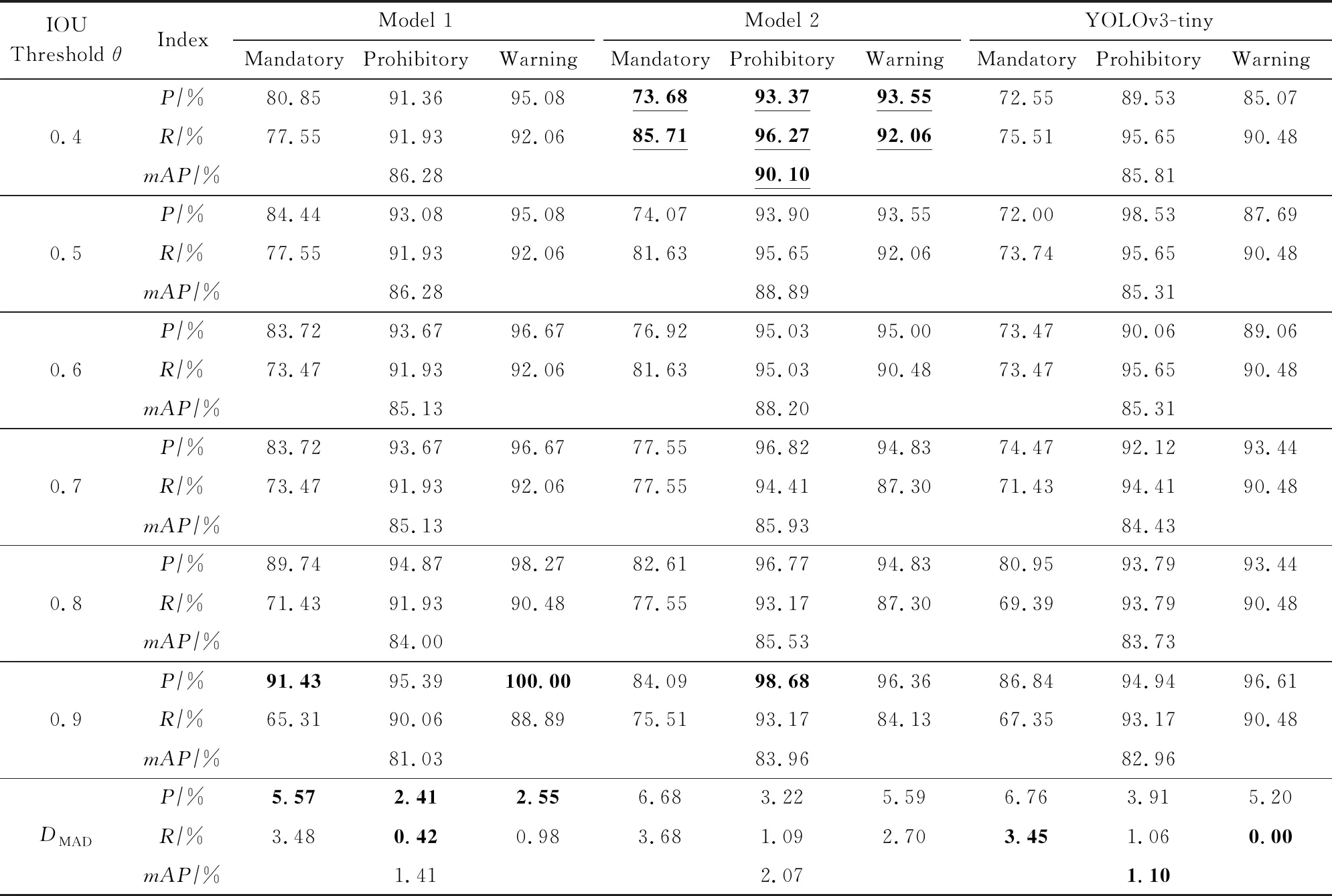
Continued(Table 2)
Note: Boldface indicates the best performance of the corresponding classification; Underscores indicate that the optimal performance of the corresponding algorithm is initially selected by threshold.
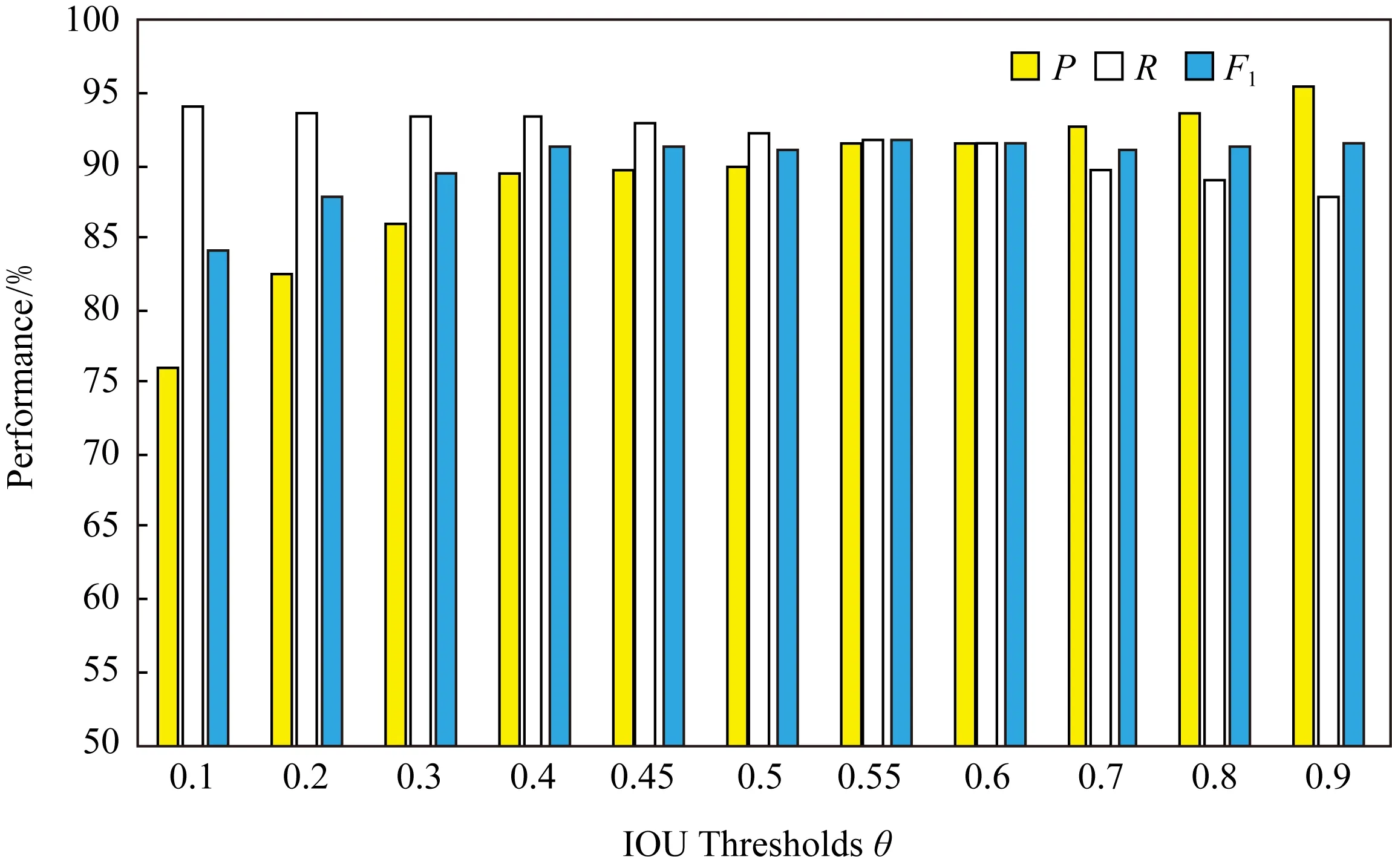
Fig. 3 Total P,R,and F1 values of model 2 using different IOU thresholds on GTSDB圖3 GTSDB數據集上模型2在不同IOU閾值下的總P,R,F1值
根據各模型的mAP值、細分類別中P,R值不小于70%以及各模型取得峰值數量最多等原則綜合考慮,模型2在IOU閾值θ=0.4時可以獲得單類別的精確率以及召回率總體相對較高的性能.但這僅僅是初步篩選閾值,接下來會進行細化區間篩選.
分析各模型在不同閾值下P,R值的波動情況,模型2的DMAD值并不是最小,甚至比Tiny原版的穩定性還要低,我們猜測這是由于GTSDB數據集樣本數量偏少造成的,當數據集數量偏少時模型1更加穩定,當數據集數量增加后,模型2更加穩定.我們將在4.3.2節中使用更大數量的訓練集驗證這個猜想.
圖3為模型2在GTSDB數據集上不同IOU閾值下的總P,R值和F1值.由表2可知,模型2在θ=0.4附近可取得單類別最佳性能,所以在測量總P,R值時,我們在0.4~0.6之間細化區域,以找到檢測性能最好的區域.從圖3我們可以看出,在θ=0.55時,F1取得了91.77%.這代表著此時的P,R值可以達到較高且相對平衡的狀態.
在GTSDB數據集上的對比實驗中,我們選取了10個算法進行對比.如表3所示,精確率、召回率和F1值最好的是ConvNet算法[24],雖然模型2以上指標不是最高的,但排名靠前,其精確度、召回率和F1值分別排在第3位、第2位和第2位.模型2比文獻[24]稍差主要是因為我們是以檢測速度為首要指標,在不影響檢測速度的情況下盡可能地提高算法的精確率和召回率.所以我們的網絡沒有構建得很深,這會使得檢測速度很快,也會給算法帶來檢測精確率上的瓶頸.模型2的F1值相較于文獻[24]下降了6.39%,但檢測速度卻提高了81.48%,模型2的檢測耗時只需要5 ms,在所有對比算法中是最快的.值得一提的是,對比算法的P,R值均參考的是原論文實驗中的結果,對比算法的F1值是根據其論文中P,R值計算得出的.
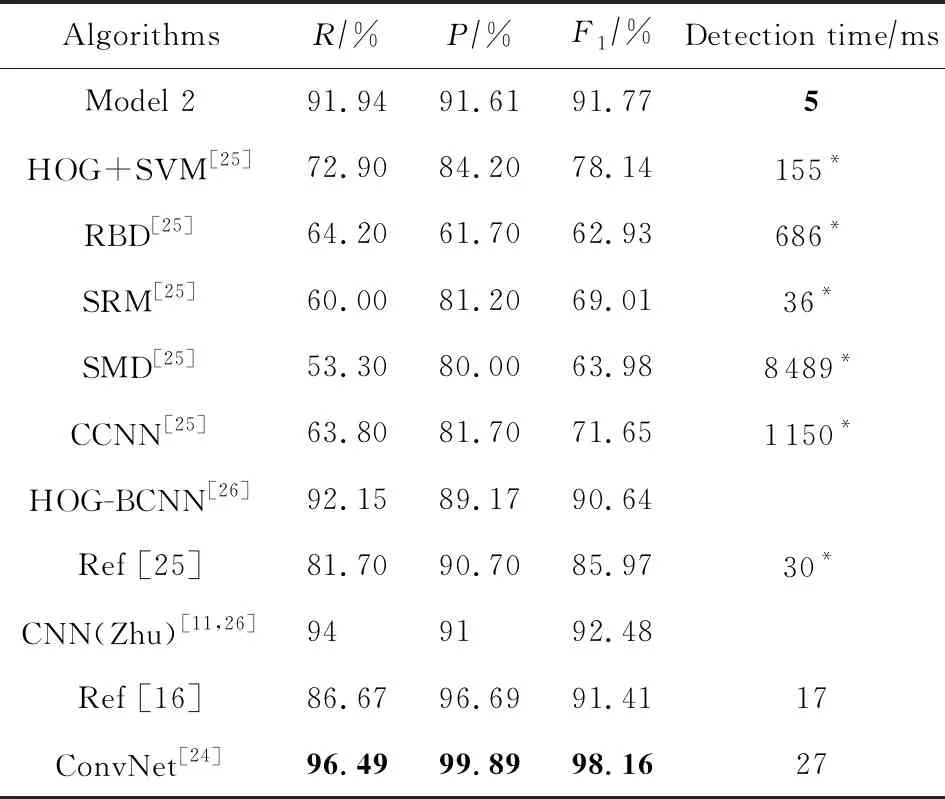
Table 3 Comparison of Experimental Results on GTSDB表3 GTSDB數據集上對比實驗結果
Note: Boldface indicates the best performance of the corres-ponding classification; * Indicates that the algorithm does not disclose code, and we do not have the same hardware environment, so the detection time comparison is only for reference. The hardware environment of the algorithm is GeForce GTX Titan XP with better performance, while we use NVIDIA GTX980ti.
圖4為模型2和原版Tiny模型在GTSDB數據集上的檢測效果圖,綠色框為模型2檢測結果,紅色框為YOLOv3-tiny檢測結果.從圖4(a)(b)中可以看出,模型2在圖像背光整體偏暗時還能夠檢測出較小、較偏的交通標志.圖4(c)中Tiny算法把穿著藍色雨衣騎自習車的人誤檢成交通標志.如圖4(d)所示,模型2能夠更加準確地定位交通標志的邊緣.

Fig. 4 The detection examples on GTSDB圖4 GTSDB數據集檢測效果圖
4.3.2 CCTSDB數據集上的評估
由于GTSDB數據集僅僅只有600張訓練圖片、300張測試圖片,且還存在少量負樣本數據,數據偏少,這對于深度神經網絡的訓練是非常不利的.因此我們還在CCTSDB這種大型數據集上進行了評估,同時驗證4.3.1節最后的猜想是否正確.
在CCTSDB數據集上的實驗方法及流程與GTSDB數據集上相同,表4是3個模型在CCTSDB數據集上使用不同IOU閾值的三大類交通標志P,R值.由于算法相同,P,R值、mAP值與θ之間的變化規律和在GTSDB數據集上相同.加粗字體為各類別的較高值,下劃線代表初步篩選的閾值及較佳性能.
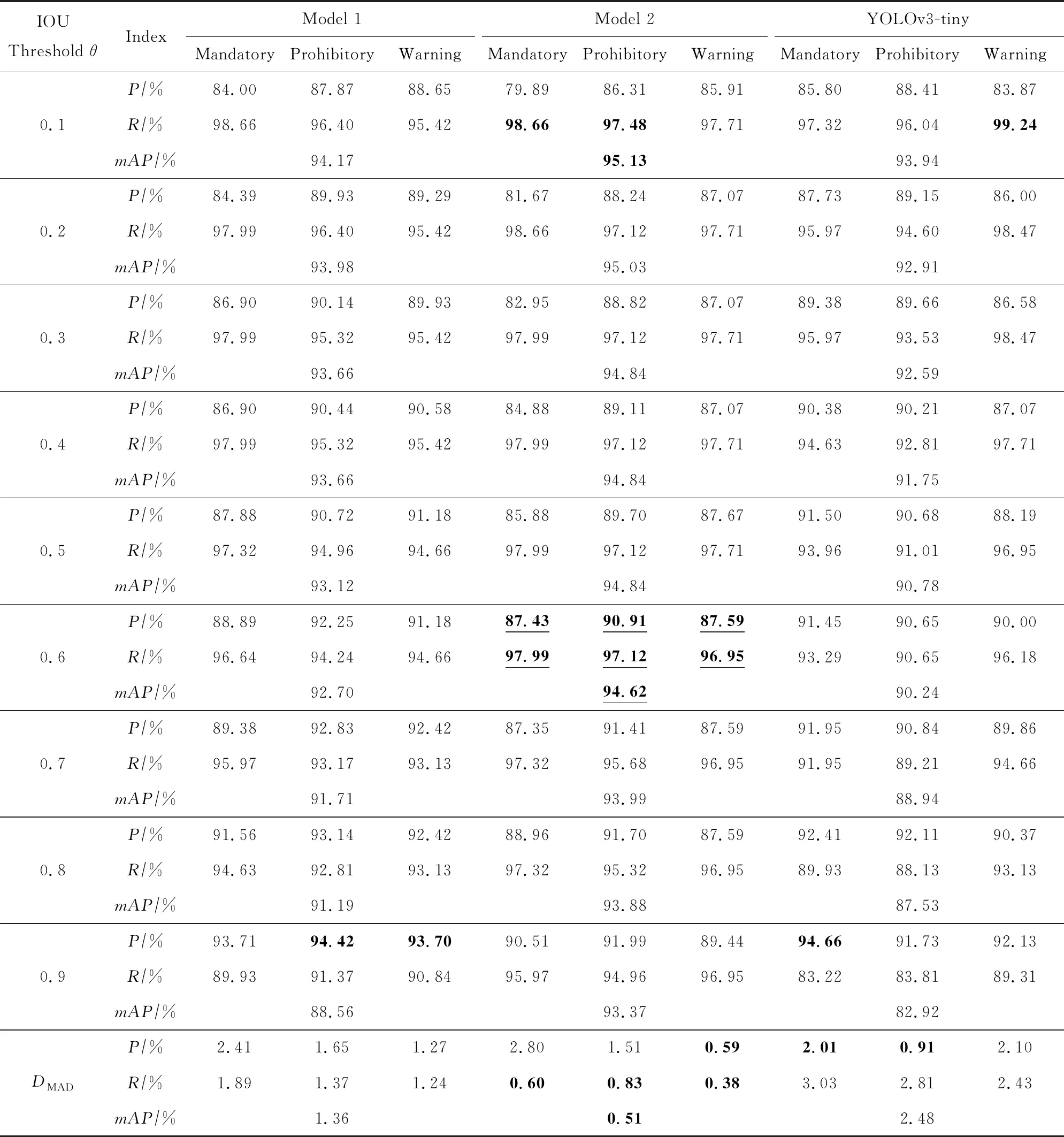
Table 4 P,R Values of Three Models Using Different IOU Thresholds in Three Kind of Traffic Signs on CCTSDB表4 3個模型在CCTSDB數據集上使用不同IOU閾值的三大類交通標志P,R值
Note: Boldface indicates the best performance of the corresponding classification; Underscores indicate that the optimal performance of the corresponding algorithm is initially selected by threshold.
值得一提的是,由于CCTSDB數據集中訓練數據數量高達15 000張,這使得模型2的穩定性得以突顯出來.模型2在各IOU閾值下的單類別最穩定數量最多,且總體模型DMAD值最小,這表明在具有大型數據集的情況下,模型2結合殘差思想與多尺度預測思想不僅具有較高的檢測精確率和召回率,同時在不同IOU閾值下的預測框相對一致,更加穩定,因此模型2具有更高的魯棒性.
圖5所展示的是模型2在CCTSDB數據集上使用不同IOU閾值的總P,R值與F1值.從圖5我們可以看出,模型2的精確率在各個閾值下都不是很高,但是召回率高達97%.這是因為我們在模型2上增加了一個預測輸出層,使得預測框更多,從而增加了召回率.經過細化區間實驗證明,在θ=0.6時,模型2在CCTSDB數據集上的精確率、召回率及F1值取得最高值.
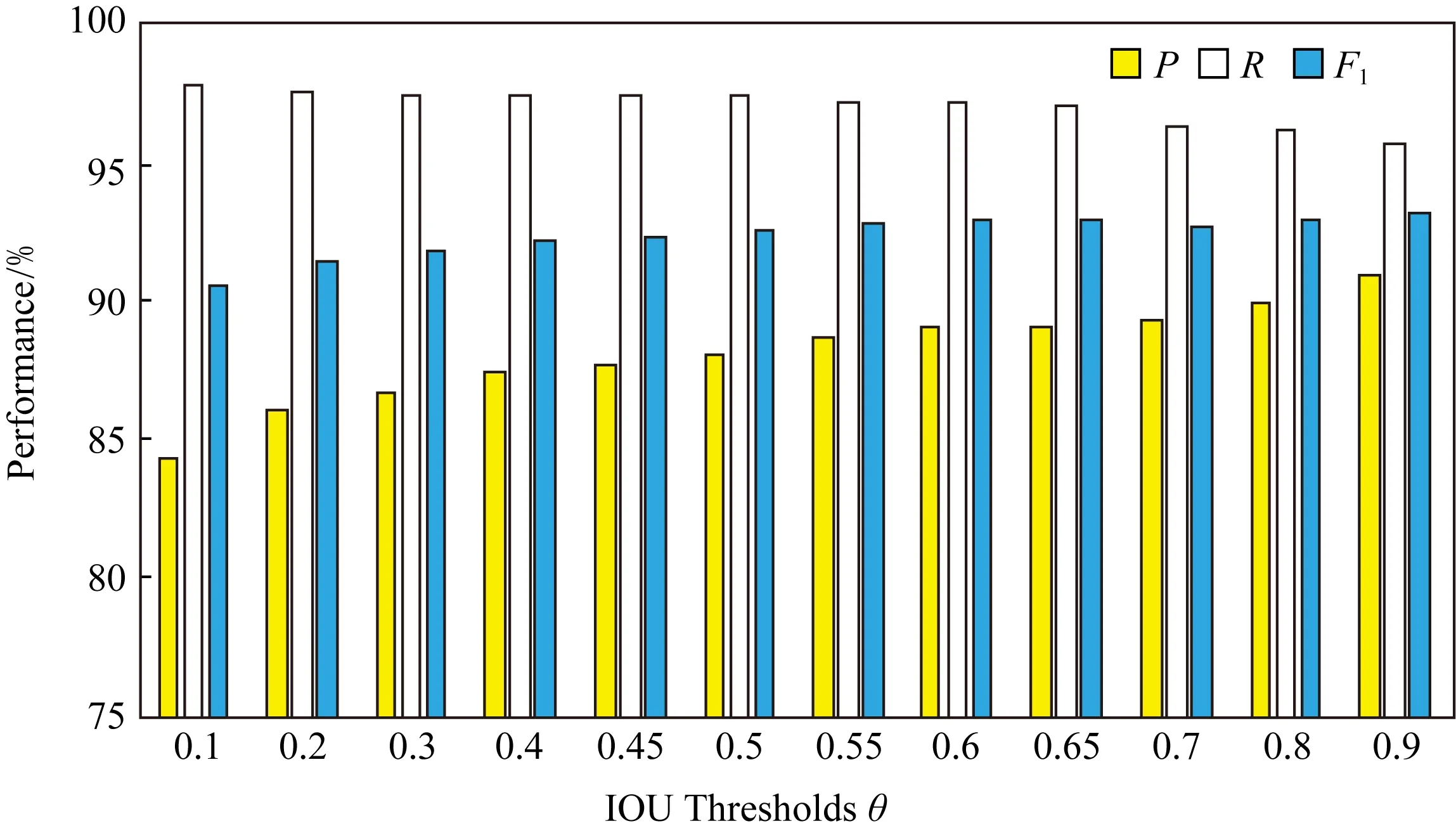
Fig. 5 Total P,R,and F1 values of model 2 using different IOU thresholds on CCTSDB圖5 CCTSDB數據集上模型2在不同IOU閾值下的總P,R,F1值
我們將在CCTSDB數據集上與文獻[16]中所提出的模型進行每一類別的詳細比較,結果如表5所示.表5中Model-A,Model-B,Model-C為文獻[16]中提出的各種改進模型,模型2為本文提出的最佳模型.由表5可知,對于準確率來說,YOLOv2的指示標志、Model-A的禁令與警告標志有最高值,這是因為文獻16的基礎網絡是YOLOv2,而我們使用的是精簡版的YOLOv3-tiny檢測算法,在YOLOv3系列中Tiny算法均是以減少卷積層、犧牲精確率來提高檢測速度;但是對于召回率來說,我們的模型2均取得最高值,相比文獻[16]中最佳模型Model-B的三大類召回率分別提高了18.56%,24.38%,2.21%,這是因為文獻[16]中的算法都是基于YOLOv2檢測算法實現的,該算法有且只有一個預測輸出層,而我們的模型2具有3個預測輸出層,這能提高算法的召回率.但是準確率與召回率往往相互對立,無法同時取得最高值.因此,為了綜合評估算法的水平,所以我們在P,R值的基礎上計算了F1值.
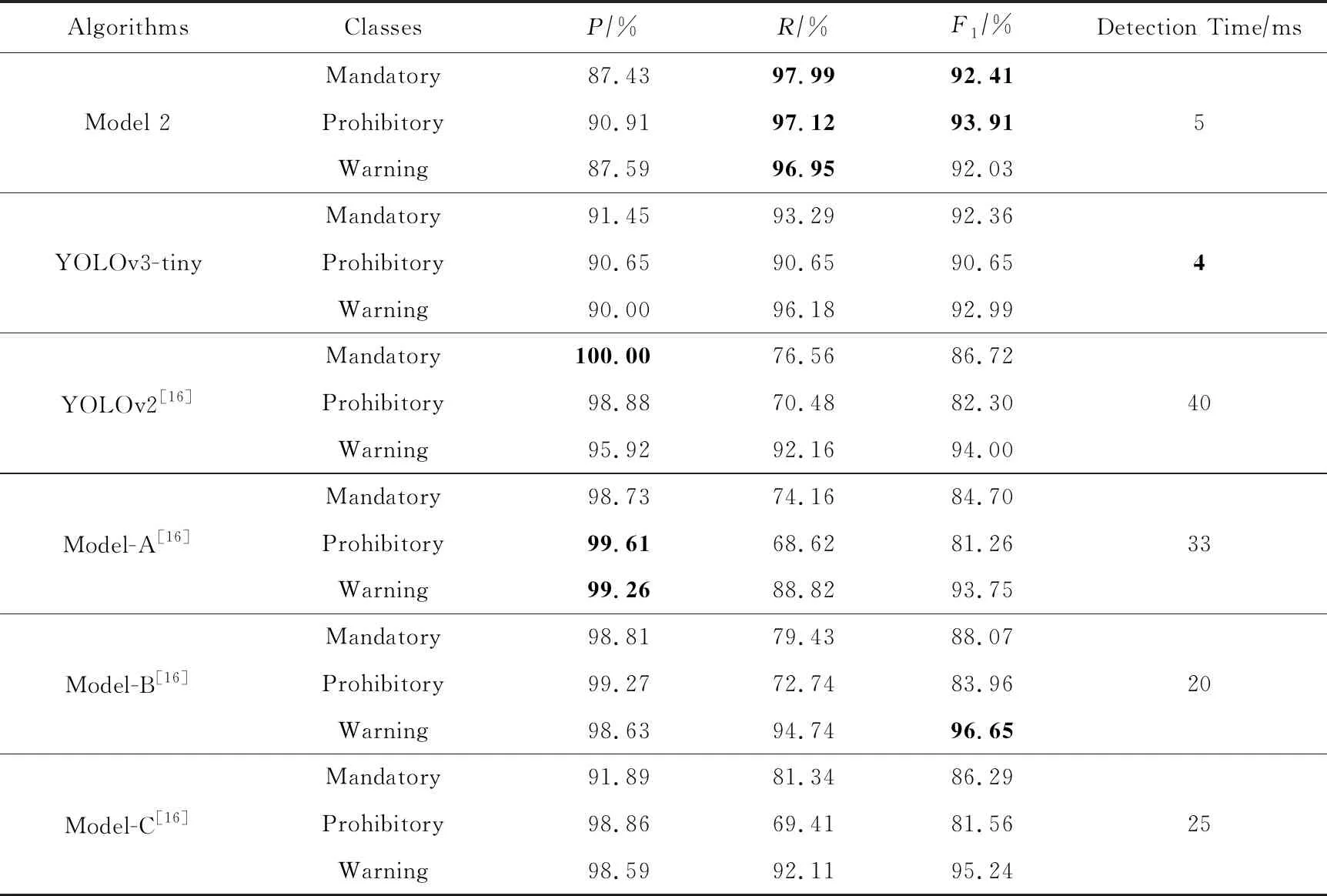
Table 5 Comparison of Experimental Results on CCTSDB表5 CCTSDB數據集上對比實驗結果
Note: Boldface indicates the best performance of the corresponding classification.
我們的模型2在指示標志與禁令標志的F1值分別取得了最高的92.41%和93.91%,同時檢測單張圖片速度是文獻[16]檢測算法的4~8倍.模型2的檢測時間略低于YOLOv3-tiny檢測算法,是因為我們在模型2上增加1個尺度預測以及嵌套殘差結構,這會使得檢測時間略有增加,不過僅僅是增加了1 ms,最終檢測時間與原版算法處于同一數量級,所以我們認為模型2算法是基本上不影響檢測時間的情況下提高了魯棒性.
圖6為模型2和原版Tiny模型在CCTSDB數據集上的檢測效果圖,綠色框為模型2檢測結果,紅色框為YOLOv3-tiny檢測算法結果.圖6(a)(b)為小目標檢測對比,Tiny檢測算法均未檢測出真實場景中距離較遠、尺寸較小的交通標志;圖6(c)(d)為預測框位置對比,模型2的檢測框可以很好地外切交通標志四周,在有相近顏色的背景干擾時也能夠準確地定位交通標志.

Fig. 6 The detection examples on CCTSDB圖6 CCTSDB檢測效果圖
5 總 結
現實場景中交通標志的實時檢測一直是研究者重點關注的話題.本文對此進行了研究,綜述了目前交通標志檢測的方法,并在YOLOv3-tiny檢測算法的網絡基礎上提出了一種基于三尺度嵌套殘差結構的交通標志快速檢測算法.
首先,我們在Tiny檢測算法上采用逐像素相加的跨層連接改進通道串接的跨層連接,使得連接操作輸出的特征圖大小相比之前在通道數上大大減少,同時由于采用改進的連接方式,使得網絡內部形成了1個小殘差結構,這可以讓主干網絡參數進行二次調參,這就是二尺度預測的殘差結構.然后,我們在此基礎上增加了1層更大尺度的預測輸出,更高空間分辨率的特征圖包含更多的空間細節信息,有利于小目標的檢測,同時我們在這一層預測輸出上也采用了與之前相同的跨層連接方式,形成了1個大殘差結構.最后,將2個殘差結構進行嵌套,使得最終網絡形成了1個三尺度嵌套殘差結構的交通標志快速檢測算法.相對于YOLOv3-tiny檢測算法來說,我們不但沒有增加過多檢測時間,而且還提高了算法的檢測精確率與召回率.
在GTSDB與CCTSDB數據集上的實驗也證明了我們的三尺度嵌套殘差結構的交通標志快速檢測算法可以在大部分對比算法中取得較高成績,同時檢測速度也是最快的.由于我們結合了殘差塊與多尺度預測的思想,在IOU閾值發生變化時,我們的模型也是最穩定的.事實上,許多場景中的目標檢測都能用到本文提出的檢測算法,特別是在計算能力受限且實時性要求極高的環境下,本算法可以確保實時、穩定、高效、魯棒的檢測效果.我們新版的CCTSDB數據集目前正在制作中,下一步將公開發布.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
