單聲道語音降噪與去混響研究綜述
2020-06-08 08:59:48葉文政惠國強呂憶藍錢宇欣
計算機研究與發展 2020年5期
藍 天 彭 川 李 森 葉文政 李 萌 惠國強 呂憶藍 錢宇欣 劉 嶠
(電子科技大學信息與軟件工程學院 成都 610054)
語音增強是指利用音頻信號處理技術及各種算法提高失真語音信號的可懂度或整體感知質量,從而進一步在語音識別、語音通話、電話會議、場景錄音、軍事竊聽和聽力輔助等場景中改善應用效果.語音增強屬于語音分離的一項內容,而后者還包括說話人分離等.狹義的語音增強單指語音降噪,而廣義的語音增強還包括語音去混響[1],因為語音去混響也是提高語音質量的重要手段.根據接收端麥克風數目的不同,可以將語音增強分為單聲道(單個麥克風)與多聲道(多個麥克風)2類.單聲道語音增強算法只需單個麥克風,實現的成本較低,在實際生活中得到了廣泛的應用[1].由于單聲道增強算法獲取的音頻信息量較少,且無法利用聲音傳播的空間信息,它的實現更具挑戰[2-3].本文著重關注廣義的單聲道語音增強(為簡化敘述,后文如無特別說明則省略“單聲道”限定語),對語音降噪與語音去混響兩方面的研究工作都進行了調研分析.
早期的語音降噪或去混響主要通過數字信號分析方法,如譜減法、濾波法等,從時域、頻域或時頻結合的方式對語音信號進行分解,找到純凈語音或噪聲的特征,從而將二者分離,屬于無監督的方法.隨著機器學習技術的演進,有監督的方法不斷地被提出,學者們開始嘗試通過各種機器學習模型去自動發現帶噪(帶混響)語音與純凈語音信號之間的關系,近年來最有代表性的莫過于深度學習在本領域的應用,它極大提升了語音降噪、去混響的效果.
本文對單聲道語音增強的現有研究工作進行了梳理分類,簡要介紹了典型方法的研究思路,并對具備可比性的實驗結果進行了綜合比較,有助于本領域研究人員進一步分析這些方法之間的聯系與區別;對在實驗與評估過程中所涉及到的相關基本概念進行了整理與簡介,并提供出處來源,有利于初學者查閱所需預備知識;在全面分析相關研究工作現狀的基礎上,探討了目前單聲道語音增強仍然面臨的主要問題與挑戰,可供本領域研究人員參考歸納未來的研究方向.
1 傳統的語音降噪方法
語音降噪是語音處理領域的一個基本問題,旨在從受噪聲干擾的信號中有效地分離出目標信號.噪聲干擾對語音活動檢測和語音識別等任務的準確率具有很大的影響,因而研究解決噪聲對后續語音處理任務的影響一直受到學術界的廣泛關注[4].傳統的語音降噪方法主要是基于數字信號處理等算法,主要包括譜減法、維納濾波、基于統計模型以及子空間的方法等.
1.1 譜減法
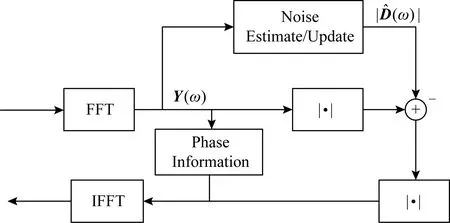
Fig. 1 Spectral subtraction based speech enhancement method圖1 基于譜減法的語音增強方法
譜減法是最早期提出的降噪算法之一,它基于一個簡單假設:噪聲是加性噪聲.通過從帶噪語音譜中減去對噪聲譜的估計來得到降噪后的語音譜,其基本做法如圖1所示,做出這一假設是基于噪聲的平穩性或者是一種慢變的過程[5].由于實際噪聲的非平穩特性,在使用過程中,這種方法很容易由于譜減過程中減去譜成分的過大或過小造成語音失真,即產生令人困擾的音樂噪聲.為減輕由譜減過程引入的語音失真,最常用的一種方式就是采用過減因子來控制失真程度,眾多學者提出了不同的準則來計算過減因子[6-8],例如對差分譜做半波整流(half-wave rectification, HWR)和基于心理聲學掩蔽閾值的方法.隨著小波技術的發展,Zhong等人[9]根據硬閾值和軟閾值改進了基于小波降噪的閾值函數算法,該方法有效地減少了降噪后信號中的毛刺現象.但是受到假設條件的限制,譜減法始終不能有效地解決音樂噪聲的問題.
1.2 濾波法
不同于基于簡單假設的譜減法,維納濾波器的提出是基于最小均方誤差意義的最優解,通過求解最優化均方誤差計算得到增強信號[10],基本流程如圖2所示,但是它的推導仍然是基于所分析信號具有平穩性這一假設,不能有效地處理非平穩信號的情況.在后續改進中,通過使用卡爾曼(Kalman)濾波器,濾波法成功地被推廣到處理非平穩信號和噪聲的場景下[11-12].Wang等人[13]提出了一種使用卡爾曼濾波器進行調制域語音增強的算法,利用高斯環統計模型將語音和噪聲頻譜幅度進行結合,通過高斯混合來模擬復數傅里葉域中語音和噪聲的先驗分布;Andersen等人[14]將多聲道技術,即基于語音失真加權的幀間維納濾波器(speech-distortion weighted inter-frame Wiener filter)應用于單聲道,進一步利用二次高分辨率濾波器組(secondary higher resolution filter bank)改進了對幀間相關性(inter-frame corr-elation, IFC)的估計,更好地在語音降噪和失真之間找到一個平衡參數,減輕了增強語音失真;Peng等人[15]在線性預測殘差域中結合人類聽覺系統的掩蔽特性,進一步抑制了殘留噪聲.

Fig. 2 Wiener filtering based speech enhancement method圖2 基于維納濾波法的語音增強方法
1.3 基于統計模型的方法
最小均方誤差(minimum mean-square error, MMSE)估計是一種常用的基于統計模型的語音降噪方法,與維納濾波的區別在于,基于MMSE的語音降噪方法可以得到對降噪語音譜的非線性估計[16-18].該方法對短時頻譜幅度(short time spectral amplitude, STSA)進行最優估計,即得到關于估計幅度與實際幅度均方誤差的最小優化估計器:
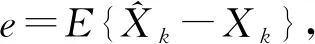
(1)
1.4 子空間方法
子空間方法是一種基于線性代數理論的語音降噪方法,這類算法假設純凈信號可以被視為帶噪信號在Euclidean空間中的一個子空間,通過將帶噪信號向量空間分解為純凈信號主導和噪聲信號主導的2個子空間,從而可以簡單地通過去除落在“噪聲空間”中的帶噪向量分量來估計純凈信號[22].帶噪信號分解為2個子空間常用的正交矩陣方法有奇異值分解(singular value decomposition, SVD)[23-24]和特征值分解(eigenvalue decomposition, EVD).Ephraim等人[25]提出了利用協方差矩陣的特征值分解,通過利用Karhunen-Loéve變換(Karhunen-Loéve transform, KLT)進行信號分解,在滿足殘余噪聲低于預設閾值約束的同時實現了語音失真最小化.
我們統計并比較了傳統的語音降噪方法在不同噪聲環境以及不同信噪比下的主觀語音質量評估(perceptual evaluation of speech quality, PESQ)和短時客觀可懂度(short-time objective intelligibility, STOI)指標,如表1和表2所示.其中PESQ取值范圍為-0.5~4.5,STOI取值范圍為0~1,兩者的數值越高表示降噪效果越好,詳見4.3節所述.
2 基于機器學習的語音降噪方法
語音降噪問題可以視為一個監督性學習問題,很多學者考慮使用機器學習的方法來解決語音降噪的問題.由于計算機硬件的限制,早期的有監督模型一般都是在淺層模型以及小數據集上實現的;在2006年Hinton等人[30]提出了一種基于受限玻爾茲曼機的逐層學習方案,并將其應用于深層神經網絡(deep neural network, DNN)的網絡訓練中,解決了DNN訓練中的局部最優問題,顯示出監督性學習的建模優勢.此后,得益于DNN的層次化非線性處理能力,深度學習的概念被廣泛應用于語音[31-32]、圖像[33]及自然語言處理[34]任務中,迅速發展成為機器學習領域的一個重要分支,越來越多的學者開始探索深度學習在語音降噪方面的應用.
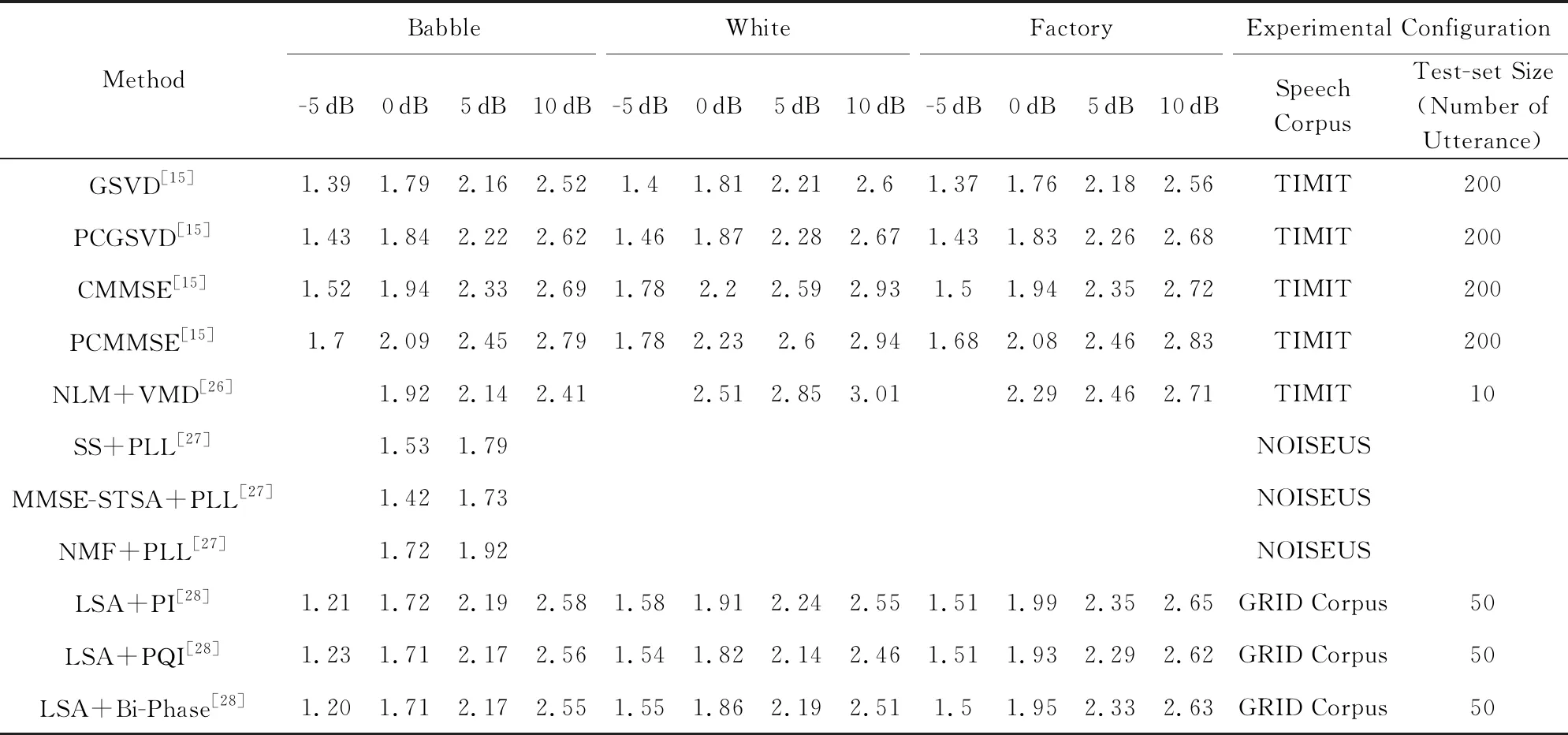
Table 1 Comparison of PESQ Scores in Traditional Speech Denoising Methods表1 傳統語音降噪方法的PESQ指標對比
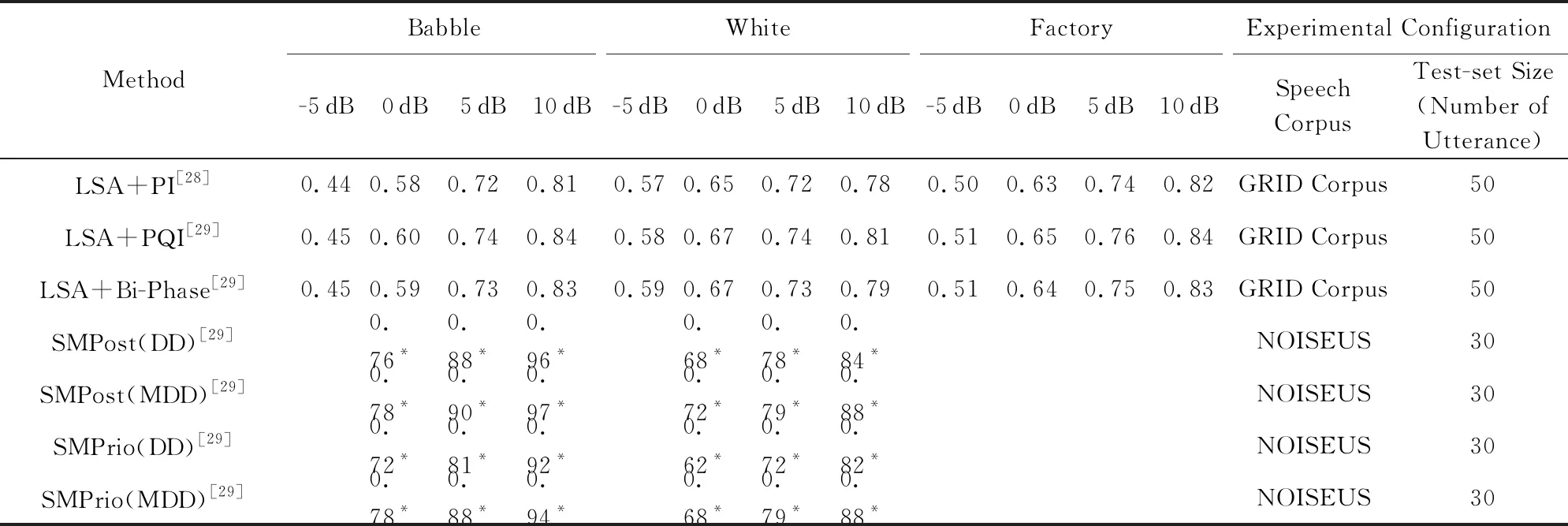
Table 2 Comparison of STOI Scores in Traditional Speech Denoising Methods表2 傳統語音降噪方法的STOI指標對比
Note: The symbol * comes from our estimation of the graph in the reference paper.
早期的經典DNN模型通常由一個輸入層,若干非線性隱含層以及一個輸出層組成,層與層之間相互堆疊,前一層的輸出傳遞到后一層,形成一個深層網絡.相比于淺層網絡,深層模型更擅長從原始數據中學習對目標有用的特征表示,比較典型的神經網絡有卷積神經網絡(convolutional neural network, CNN)[35-36]、循環神經網絡(recurrent neural network, RNN)[35]以及2014年提出的生成對抗網絡(generative adversarial network, GAN)[37]等.在基于深度學習的語音降噪任務中,根據神經網絡是否對語音時域波形直接處理可以分為非端到端和端到端的語音降噪;在非端到端的語音降噪任務中,根據網絡的學習目標的不同,可以把降噪方法分為:基于時頻掩蔽(time-frequency mask)的語音降噪算法、基于頻譜映射的語音降噪算法和基于信號近似的語音降噪算法;一些學者也提出了基于端到端的算法以及深度學習與傳統方法結合的算法.本節將介紹傳統機器學習、非端到端方法以及端到端的方法在語音降噪領域的應用.
圖3給出了非端到端的語音降噪算法結構圖,在訓練階段首先通過時頻分解、特征提取將原始的時域波形處理為時頻表示,隨后將時頻表示的特征送入到神經網絡中進行訓練,將估計出的目標作用于帶噪語音得到降噪后的語音;經過多輪迭代調整網絡參數,使其更好地學習帶噪語音與純凈語音之間的復雜映射關系.在測試階段,提取特征后的帶噪語音被輸入到訓練好的降噪模型中,降噪后的語音時頻表示與帶噪語音的相位結合便可得到時域的波形信號.與圖3類似,圖4給出了端到端的語音降噪模型,通過直接學習時域波形層級的映射關系,在保留更多原始波形信息的同時,簡化了處理流程.
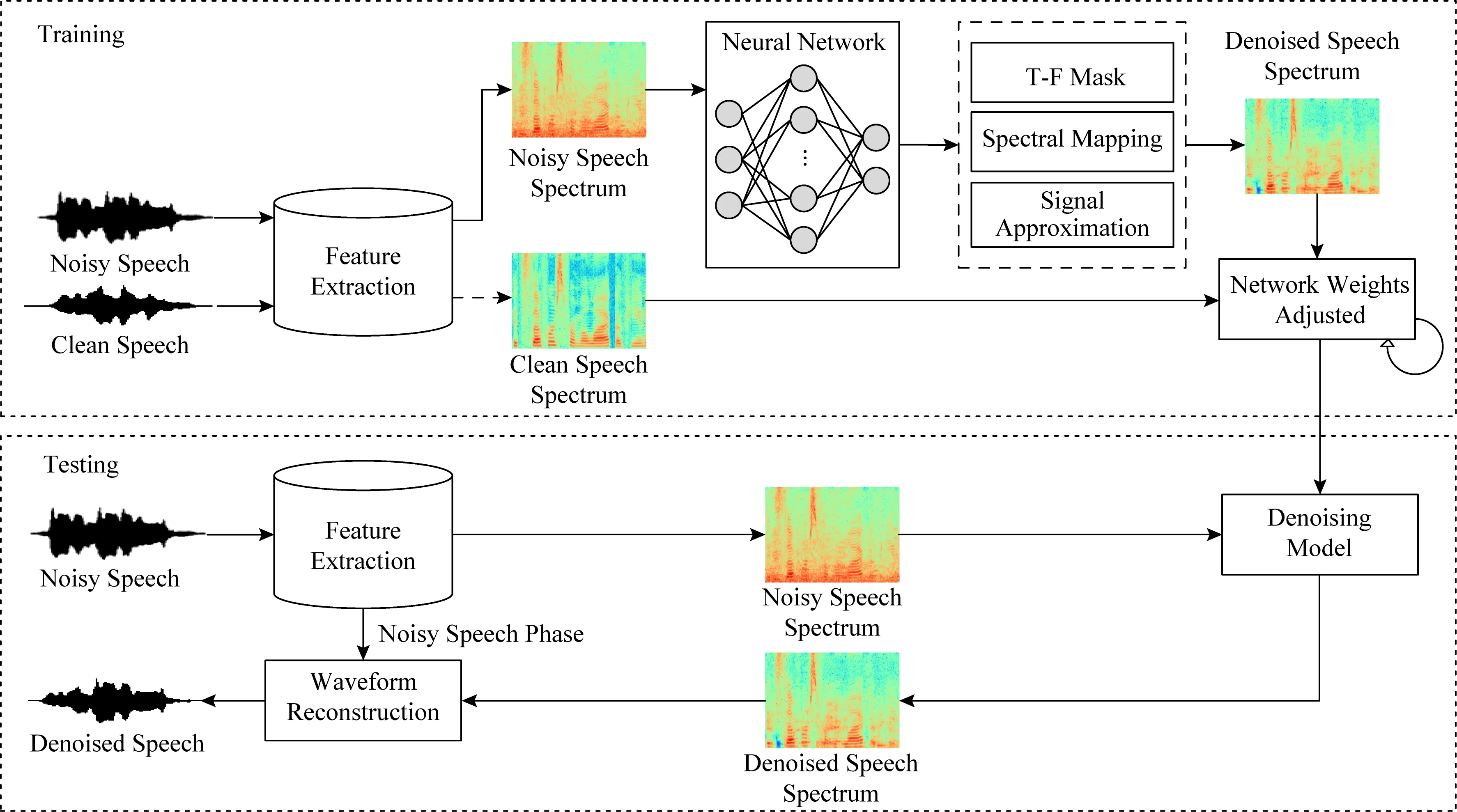
Fig. 3 A block diagram of non-end-to-end speech denoising system based on deep learning圖3 基于深度學習的非端到端語音降噪系統結構框圖
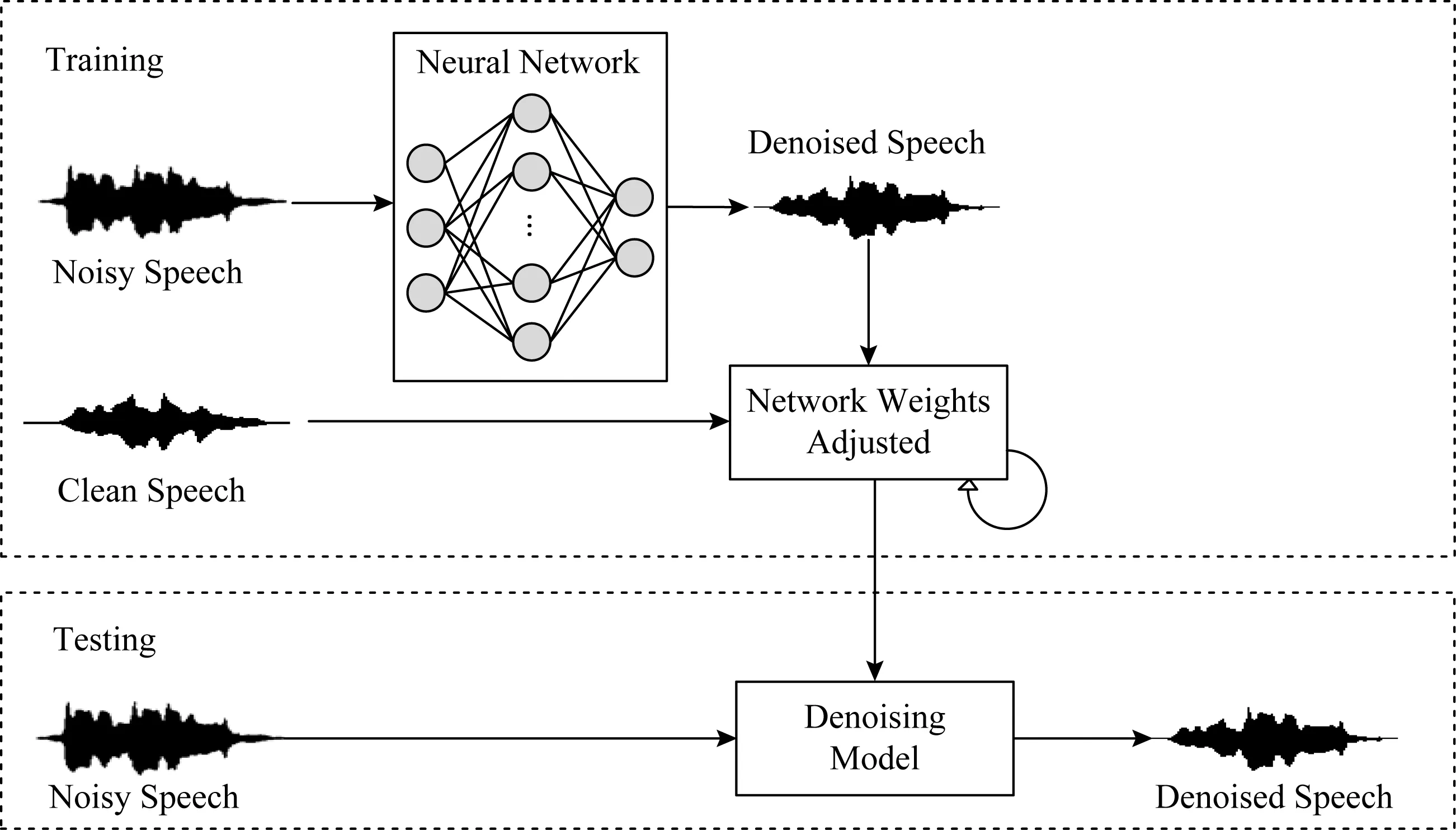
Fig. 4 A block diagram of end-to-end speech denoising system based on deep learning圖4 基于深度學習的端到端語音降噪系統結構框圖
2.1 基于傳統機器學習模型的方法
早期語音降噪系統模型主要是一些淺層模型,經典的方法包含高斯混合模型(Gaussian mixture model, GMM)、支持向量機(support vector machine, SVM)和非負矩陣分解(nonnegative matrix factori-zation, NMF).
高斯混合模型通過多個高斯分布函數的線性組合,來模擬復雜的分布.Kim等人[38]利用GMM對時頻單元進行建模,通過輸入給定的頻帶特征,輸出語音主導和噪聲主導的概率.利用估計的二值掩蔽和混合語音的Gammatone濾波輸出合成語音的時域波形.但由于該模型是單獨對每一個頻帶進行建模,忽略了頻帶間的相關性,不具有較強的實用性.
支持向量機通過在高維特征空間中尋找最優分類面對數據進行分割.Han等人[39]利用SVM對每個頻帶的時頻單元進行建模,學習被目標語音主導的時頻單元和被噪音主導的時頻單元最優區分面,通過計算到分類面的距離實現時頻單元的分類.相比于GMM,SVM具有更好的分類準確性和泛化性能.
非負矩陣分解是最常用的有監督語音降噪方法[40-41].NMF算法對純凈語音和噪聲單獨訓練,分別得到對語音和噪聲的信號基表示,從而在帶噪語音中分離出純凈語音.為了減少具有與語音信號類似的特征的殘余噪聲分量,Chung等人[42]提出了基于NMF的類條件基矢量的訓練和補償算法.但是當遇到在訓練階段沒有出現過的語音或者噪音時,算法性能會出現下降.
2.2 基于深度學習模型的方法
2.2.1 基于時頻掩蔽的方法
基于時頻掩蔽的語音降噪方法將描述純凈語音與噪聲之間相互關系的時頻掩蔽作為學習目標.研究表明,基于時頻掩蔽的方法可以有效地提高復雜環境下的語音可懂度[38,43],但該方法需要假設純凈語音與噪聲之間有一定的獨立性.理想二值掩蔽(ideal binary mask, IBM)[44]是最早用于語音降噪的時頻掩蔽之一,它實際上是一個定義在二維空間(時間和頻率)上的一個二值(0或1)矩陣,其中每個元素:
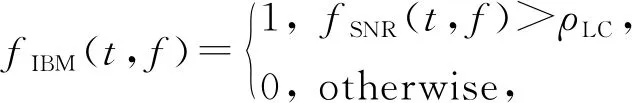
(2)
其中,t和f分別表示時刻和頻率,fSNR(t,f)表示在時刻t、頻率f處時頻單元的局部信噪比.當局部信噪比大于局部閾值(local criterion, LC)ρLC時,IBM在此處賦值為1,否則賦值為0,這代表IBM將每個時頻單元判定為以語音為主或以噪聲為主.除此之外,也有一些基于比值的掩蔽或復數域掩蔽相繼被提出,例如理想比值掩蔽(ideal ratio mask, IRM)[45]、最優比值掩蔽(optimal ratio time-frequency mask, ORM)[46]、頻譜幅度掩蔽(spectral magnitude mask, SMM)[47]、相位敏感掩蔽(phase-sensitive mask, PSM)[48]以及復數域理想比值掩蔽(complex ideal ratio mask, cIRM)[49]等.這些掩蔽根據語音及噪聲的幅度譜或功率譜計算得到,隨后通過將逆變換技術作用于估計的時頻掩蔽上,從而合成目標語音的時域波形.
Wang等人[50-51]將DNN引入語音分離與降噪領域,并對該工作進行擴展.他們將受限玻爾茲曼機(restricted Boltzmann machine, RBM)預訓練的前饋DNN作為二元分類器來估計IBM,并考慮了語音的時間動態特性,引入結構化感知機和條件隨機場來改進模型.實驗證明:相比于傳統方法,基于DNN的方法在匹配和不匹配的噪聲情況下均取得了很好的降噪效果.在擴展工作中,Wang等人[52]對通過Gammatone濾波器組的子帶信號使用DNN來學習輸入信號的特征,他們將訓練網絡中最后一個隱藏層的輸出與輸入特征串聯起來送入SVM中估計IBM,經過實驗評估作者取得了高的語音可懂度,但是語音質量損失較為嚴重;Healy等人[43]將該算法擴展為2階段訓練方式,利用數據的上下文信息,顯著提高了分類精度.作者在專業測驗中測試了該算法,結果表明,對于聽力正常和聽力受損的聽眾,語音可懂度均顯著提高.
Narayanan和汪德亮[53-54]將理想比率掩蔽IRM作為目標,在梅爾譜域估計IRM,并在一定程度上提高了語音識別的魯棒性;Madhu等人[55]也發現連續性學習目標相比于二值目標可以取得更好的性能;Nie和Zhang等人[56-57]提出了一種用于IBM估計的深度疊加網絡,并使用掩碼進行基音估計,提高了掩碼估計和基音估計的精度;Williamson等人[49]提出復數理想比例掩蔽cIRM并使用DNN同時估計cIRM的實部和虛部,極大提高了語音可懂度;Hui等人[58]使用卷積網絡,通過Maxout和Dropout方法分別解決了訓練的飽和問題以及泛化問題,并在客觀可懂度和語音質量方面均超過了基于DNN的方法;Wang等人[47]在語音分離任務中分析對比了一系列時頻掩蔽的訓練目標,從論文結果中可以看出,以IRM為訓練目標的方法可以得到更好的語音質量與可懂度.
2.2.2 基于特征映射的方法
基于特征映射的語音降噪方法利用帶噪語音特征與純凈語音特征之間的復雜關系,學習兩者間的映射.網絡的輸入與輸出通常是同種類型的聲學特征,并且在實現過程中,幾乎沒有對語音和噪聲信號做任何假設.常見的特征映射包括目標幅度譜(target magnitude spectrum, TMS)、Gammatone域目標功率譜(Gammatone frequency target power spectrum, GF-TPS)以及短時傅里葉變換幅度譜(short-time Fourier transform spectrum, SFTS)等.其中,TMS[59-62]從帶噪語音中估計純凈語音幅度譜、功率譜或梅爾譜等,然后將得到的幅度與帶噪語音相位結合,得到估計語音波形;GF-TPS[47]是基于Gammatone濾波器的聽覺譜(cochleagram),通過聽覺譜轉換,可以很容易地將GT-TPS的估計結果轉換為降噪的語音波形;SFTS是語音的時域信號經過分幀、加窗以及短時傅里葉變換得到的時頻表示.若不考慮相位不匹配的影響,則可直接估計目標語音的短時傅里葉變換(short-time Fourier trans-form, STFT)幅度譜,結合帶噪語音相位信息后,通過短時傅里葉逆變換(inverse short-time Fourier transform, ISTFT)可估計得到目標語音的時域波形.
自動編碼器是基于特征映射的語音降噪算法中的一類典型結構,Vincent等人[63]在2008年首次提出降噪自動編碼器(denoising autoencoder, DA),并將其用于提取魯棒性的特征;在此基礎上,Maas等人[64]提出了循環降噪自動編碼器(recurrent denoising autoencoder, RDA),并將該方法應用到語音識別的前端降噪任務上,降低了語音識別的錯誤率;Xia等人[65]利用降噪自動編碼器估計純凈語音的頻譜,然后用最小控制迭代平均的方法估計噪聲,進而計算出先驗信噪比,最后用維納濾波的方法得到純凈語音的頻譜估計;Lu等人[59]提出用堆疊式自動編碼進行語音降噪,將多個訓練好的自動編碼器(autoencoder, AE)疊加成一個深層自動編碼器(deep autoencoder, DAE),然后使用反向傳播算法對其進行監督微調.通過DAE學習一個梅爾域帶噪語音到純凈語音的功率譜映射,并在匹配噪聲的情況下取得了一定的降噪效果.
Xu等人[61,66]提出把深層神經網絡視為一個回歸模型,作者使用帶RBM預訓練的DNN將帶噪語音的對數功率譜映射到純凈語音的對數功率譜上,然后使用混合語音的相位,通過ISTFT得到目標語音的時域波形信號;作者使用了多種噪聲來構建訓練數據集,降噪后的PESQ比帶噪語音高0.4~0.5,明顯高于傳統語音降噪方法,并且具有較好的泛化性能.Han等人[62]使用DNN來學習帶混響和噪聲的語音到純凈語音的映射關系,提高了語音可懂度與信噪比;Tu等人[67]在DNN非連續層之間添加了跳連接,間接地迫使神經網絡學習IRM,另外,作者將網絡結構堆疊起來,取得了更好的評估結果;Wang等人[68]發現直接使用標準的前饋神經網絡把帶噪信號映射到純凈信號的效果不理想,所以他們將傅里葉逆變換融合到神經網絡中.Karjol等人[69]考慮到單個DNN可能無法更好地挖掘語音信號的時空結構信息,所以他們使用了添加門控網絡的多DNN策略來訓練數據,并取得了優于單個DNN的降噪效果.也有一些基于CNN的方法被用于頻譜映射,通常CNN模型由輸入層、卷積層、池化層、全連接層和輸出層組成,通過卷積層與池化層的級聯挖掘特征信息,另外CNN中的權重共享可以減少訓練參數的數量.Park等人[70]提出冗余卷積編碼解碼網絡(redundant convolutional encoder-decoder, R-CED),通過刪去池化層、加入跳躍連接的方式優化訓練過程.Fu等人[71]提出了一種SNR-Aware(signal to noise ratio aware)的CNN語音降噪模型,并在實際應用中驗證了該方法的泛化性.Gao等人[72]采用長短期記憶網絡[73](long short-term memory, LSTM)顯式學習特定信噪比的中間目標,引入密集連接的漸進學習,將輸入以及中間目標的估計拼接起來,再一起學習下一個目標.這種方式緩解了信息丟失的問題,語音可懂度在各種實驗噪聲下均有提高.
一些學者將GAN應用到了語音降噪領域,GAN中的對抗機制來源于二人博弈的思想,它同時訓練2部分模型:生成模型和判別模型,分別用MG和MD表示.MG的目標是生成更加“真實”的樣本以欺騙MD,MD的目標是更準確地分辨真實樣本與MG生成的樣本之間的差異;通過迭代訓練,在持續的競爭中共同推動2種模型提高性能,直到MD無法區分MG生成的樣本與真實樣本為止.Michelsanti等人[74]借鑒圖像領域的Pix2Pix[75]框架,通過MG對帶噪語音頻譜圖降噪,MD用來將MG生成的降噪頻譜與純凈語音頻譜區分開,作者取得了與DNN相當的降噪效果.Donahue等人[76]探索了GAN在語音魯棒性識別中的應用,在頻域上應用GAN,提出了FSEGAN(frequency-domain speech enhancement GAN)并在語音魯棒性識別中相比于傳統多風格訓練(multi-style training, MTR)有7%的性能提升.
2.2.3 基于信號近似的方法
基于信號近似(signal approximation, SA)的方法是利用神經網絡估計掩蔽,并將其作用于帶噪語音幅度譜上,得到估計語音的幅度譜。該掩蔽能最小化純凈語音幅度譜與估計語音幅度譜之間的差異:
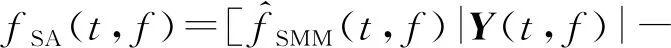
(3)
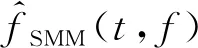
Huang等人使用DNN與DRNN(deep RNN)對說話語音進行降噪與分離[77-78],DRNN是多層RNN的堆疊,與RNN類似,是一類具有短期記憶能力的神經網絡,其神經元既可以接受其他神經元的信息,也可以接受自身的信息,形成具有環路的網絡結構,比較適合對語音信號這種序列化數據建模;通過DRNN估計出目標語音和干擾語音的掩蔽值,由區分性訓練的方式將掩蔽值引入到損失函數中,最小化混合語音重構誤差,實驗結果相比于NMF方法有很大提升.然而,在RNN中很容易出現梯度消失和梯度爆炸的問題[79],為緩解這一問題引入了LSTM,通過門控機制將上下文信息保持在記憶單元中,Weninger等人[80]使用LSTM模型實現信號近似來預測掩蔽值,在時頻域內估計誤差,在隨后的工作中加入了相位信息并應用到了魯棒性語音識別的任務中[81].
2.2.4 基于端到端的方法
大部分監督性語音降噪是在時頻域進行的,近年來,一些學者開始將注意力轉移到端到端的解決方式上,即對原始時域波形信號直接進行處理.由于不依賴于頻域表示,端到端的方法避免了相位信息丟失以及重構降噪語音時使用帶噪語音相位而可能引發的降噪效果不佳的問題;端到端的處理方式可以減少語音信號的處理工序,避免了信號在時頻域的來回切換,使得流程更加簡化.
Qian等人[82]提出貝葉斯WaveNet[83]框架BaWN(Bayesian WaveNet)用于語音降噪,利用WaveNet對原始波形的強大建模能力,將輸出正則化到語音空間,顯示出貝葉斯框架中語音先驗分布的有效性,并取得了較好的泛化性能;隨后,Rethage等人[84]也在WaveNet的基礎上進行語音降噪,利用非因果擴張卷積來預測一系列目標,而不是單一目標.實驗結果表明,該方法優于基于幅度譜的Wiener濾波方法;Fu等人[85-86]提出了全卷積神經網絡(fully convolutional neural network, FCN)來對語音進行降噪,他們發現全連接層不易同時映射語音信號的高頻分量與低頻分量,所以刪除了卷積網絡的全連接層.作者將神經網絡應用于整句語音波形信號,并改進了損失函數,使得語音降噪效果得到改善.Venkataramani等人[87]提出了一種基于卷積自動編碼器的前端變換,用來替代STFT.該編碼器可以自動從數據的原始波形發現數據特定的頻域表示,該方法相比于基于STFT的方法,取得了更好的性能,可以用于端到端的語音降噪任務中.Pascual等人[88]提出了基于GAN的端到端語音降噪模型,其MG是一個全卷積網絡,用于對語音進行降噪處理,鑒別器MD與MG有著同樣的結構,它對MG生成的波形以及純凈原始信號波形進行判別,并將判別結果反饋給MG.通過作者的實驗,GAN可以在一定程度上對語音進行降噪,但是在評估指標PESQ上略低于Wiener濾波.
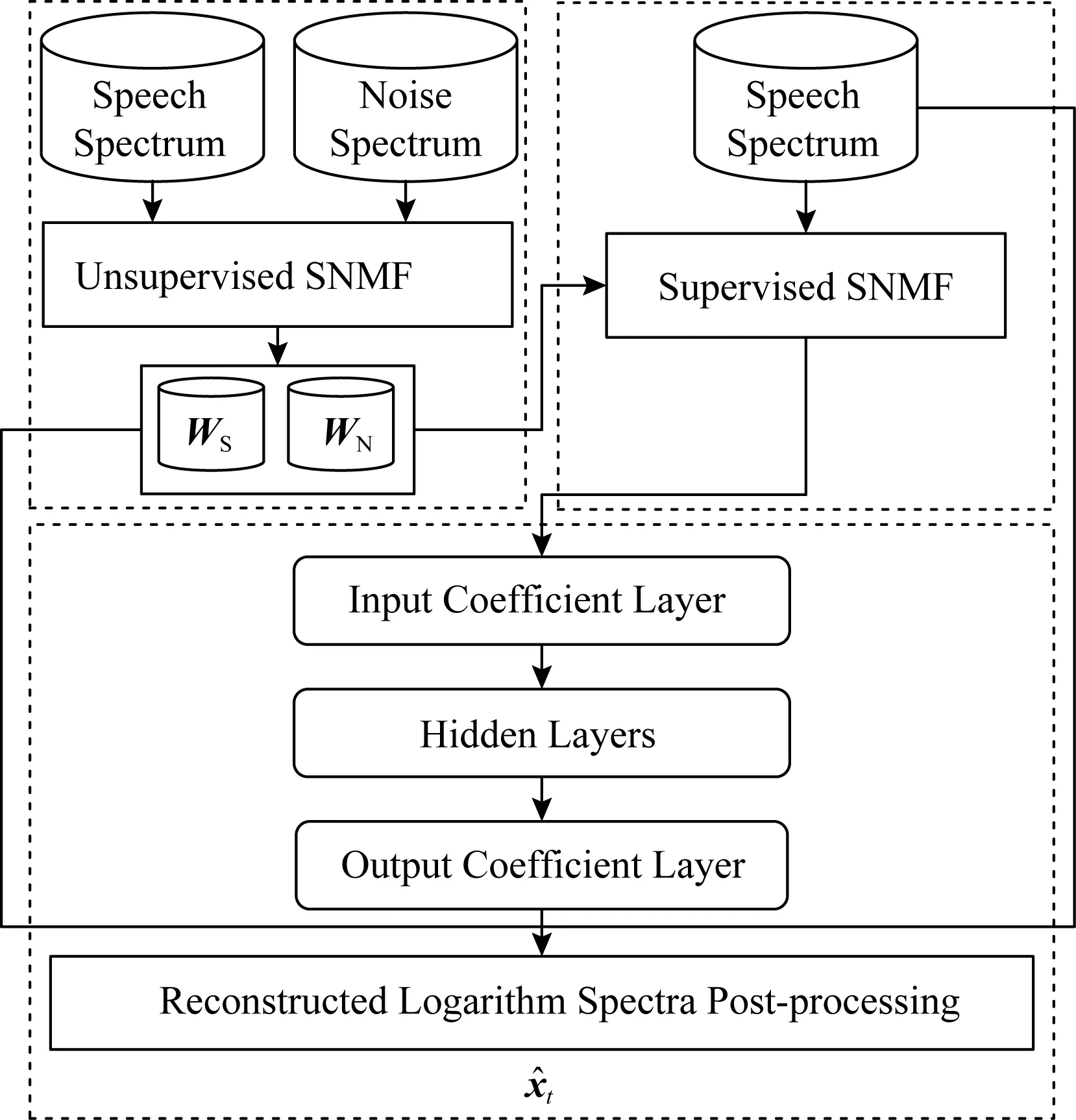
Fig. 5 Combination of DNN and NMF method圖5 DNN與NMF結合的方法[89]
2.3 結合傳統方法與深度學習的方法
并非所有的語音增強方法都是單純基于神經網絡的,一些學者將深度學習的方法與傳統方法相結合.Vu等人[89]將DNN與稀疏非負矩陣分解(sparse non-negative matrix factorization, SNMF)結合應用到噪聲環境下的自動語音識別(automatic speech recognition, ASR)任務中.如圖5所示,作者在已標記數據上對語音和噪聲基向量進行無監督SNMF學習,并進行有監督的SNMF特征提取,通過構建神經網絡來學習SNMF激活系數之間的非線性映射,使降噪信號的對數譜與目標語音的對數譜之間的均方誤差最小.Roux等人[90]將NMF擴展為深層結構,并在各種噪聲和混響條件下進行測試,取得了較大的性能提升.
Yang等人[91]提出了一種利用DNN估計自回歸模型(autoregressive model, AR)參數的新方法,訓練神經網絡學習純凈語音與噪聲AR模型的參數,利用學習到的AR模型參數構造AR-Wiener濾波器;采用語音存在概率對AR-Wiener濾波器進行了改進,消除了諧波間的殘余噪聲.Bando等人[92]最近提出了一種半監督語音降噪方法VAE-NMF(variational autoencoder NMF),該方法采用了基于變分自編碼器(variational autoencoder, VAE)的語音概率生成模型和基于NMF的噪聲概率生成模型,并在未知噪聲下取得了比傳統DNN監督學習更好的性能.我們對不同信噪比和不同噪聲條件下的深度學習算法進行了對比,并比較了他們的PESQ和STOI性能,如表3和表4所示:
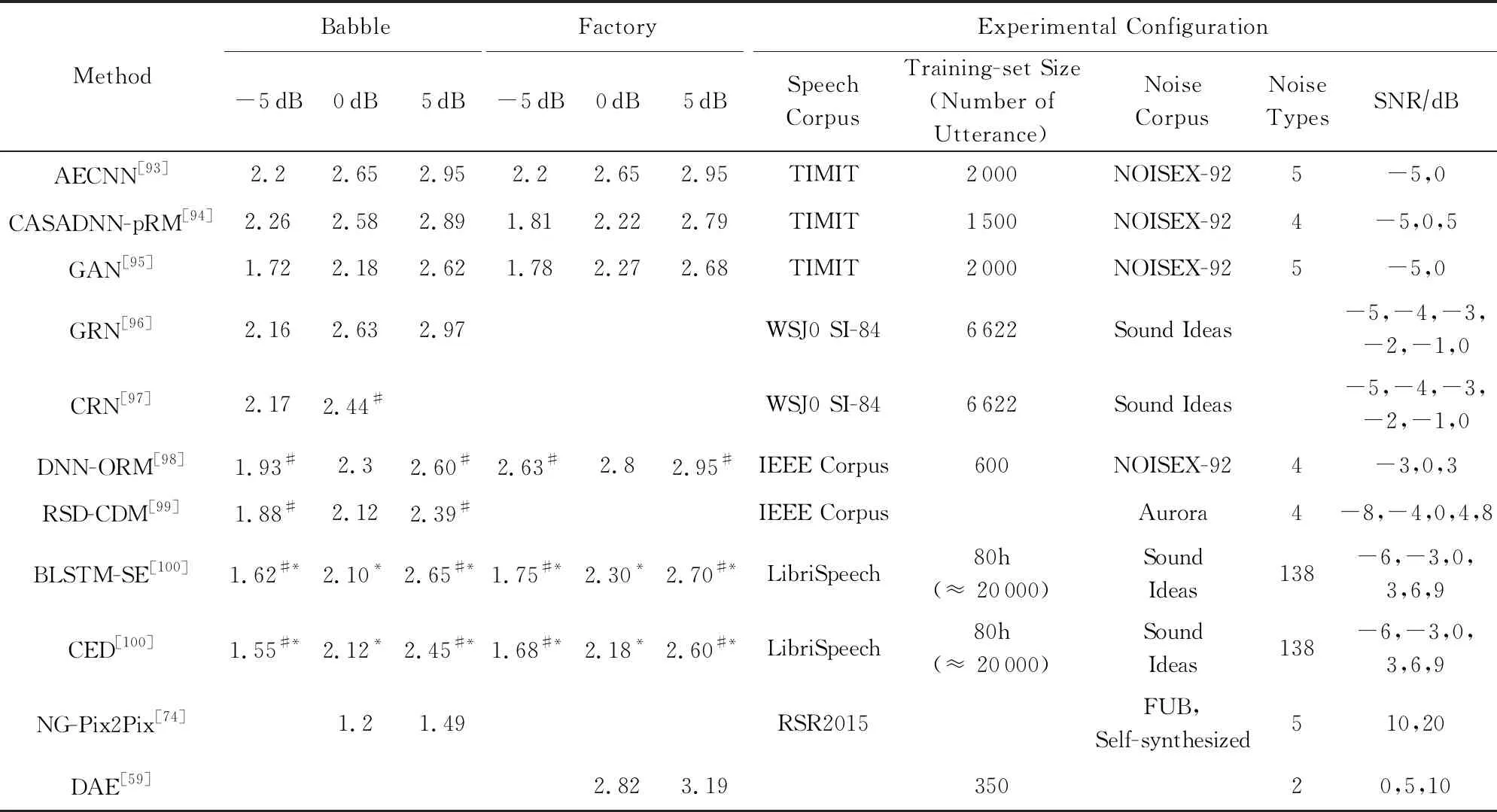
Table 3 Comparison of PESQ Scores in Deep Learning Based Speech Denoising Methods表3 深度學習語音降噪方法的PESQ指標對比
Note: The symbol * comes from our estimation of the graph in the reference paper, and the symbol # comes from the rounding of the data in the reference paper.
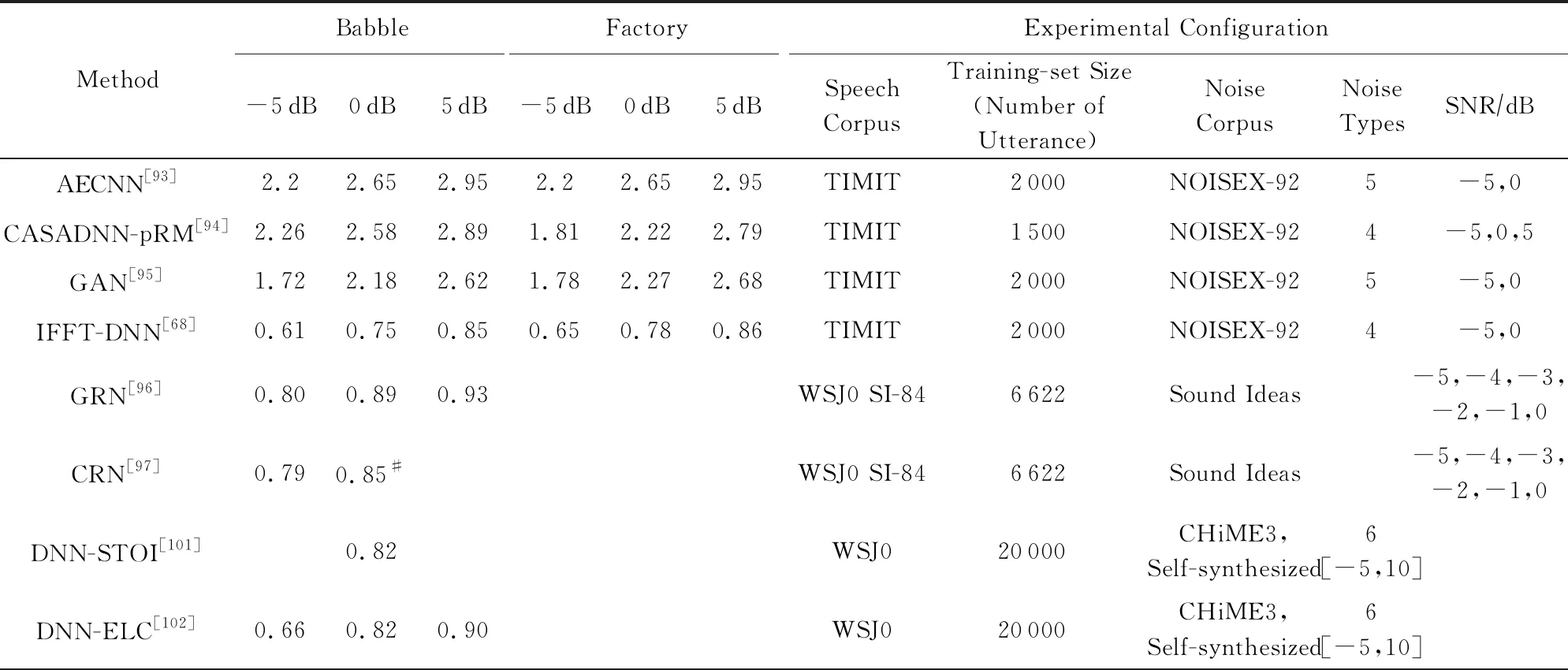
Table 4 Comparison of STOI Scores in Deep Learning Based Speech Denoising Methods表4 深度學習語音降噪方法的STOI指標對比
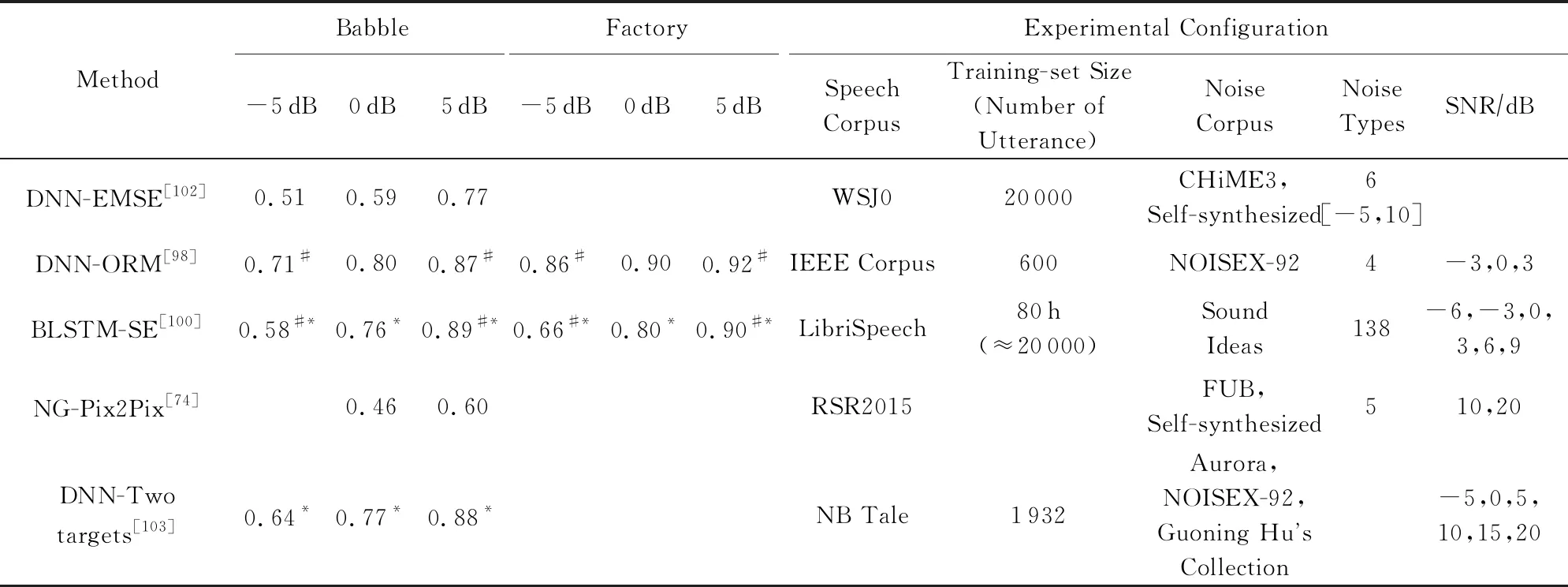
Continued (Table 4)
Note: The symbol * comes from our estimation of the graph in the reference paper, and the symbol # comes from the rounding of the data in the reference paper.
3 語音去混響
語音去混響的目標是將混響語音轉化為無混響語音,是一項具有挑戰的任務.混響是聲信號從聲源通過多條路徑傳播到人耳或麥克風(接收器)的過程.接收器接收到的信號中,包括未經過任何障礙物反射而直接到達的語音成分,以及隨后到達的混響成分.一般從直達語音到達后算起,50 ms內到達的混響,稱為早期混響,超過50 ms到達的稱為晚期混響[104-105].相比于晚期混響,早期混響反射次數較少,信號強度較高,與說話人和接收器的位置高度相關;晚期混響在經過多次反射后,強度大致呈指數衰減,與位置無關,并且會改變語音的時間包絡,對語音質量的影響較大[106-107].
語音去混響技術可概括為3類:1)假設帶混響語音由線性系統產生,首先估計聲學系統的參數,再得到無混響信號的估計,稱作混響消除方法;2)假設帶混響語音由加性過程產生,且混響與語音無關,稱作混響抑制方法;3)對混響聲學系統未知,直接從帶混響語音映射到無混響語音,這一類的典型代表是基于深度學習的語音去混響方法[104,106].
3.1 混響消除方法
混響消除方法利用卷積失真模型對信號建模,將純凈語音信號s(n)與線性系統沖激響應a(n)卷積,再加上噪聲u(n)形成帶混響和噪聲的語音x(n),在時域可表示為
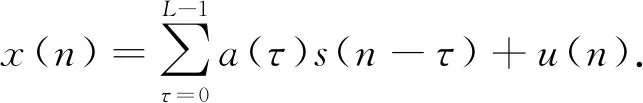
(4)
在不考慮噪聲干擾情況下,式(4)在經過傅里葉變換并取幅度值后,可表示成矩陣形式:
X=AS,
(5)
其中,S,X分別表示純凈語音與帶混響語音的時頻域幅值矩陣,矩陣A由沖激響應a轉換.
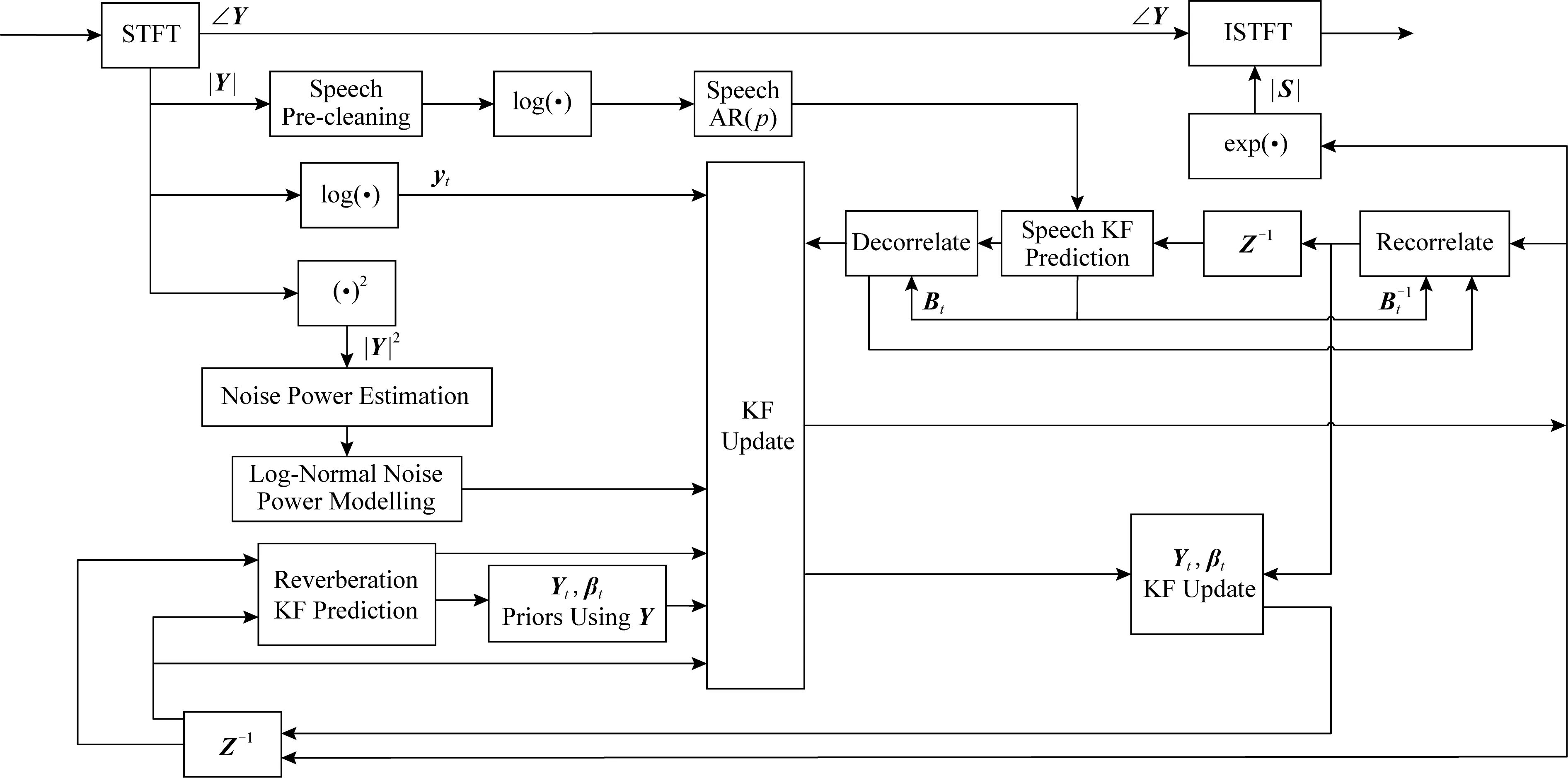
Fig. 7 A method for reverberation suppression圖7 一種混響抑制方法[118]
早期混響消除法的一個基本思路是對沖激響應求逆,通過混響的逆過程將語音還原.Neely等人[108]最先開展這方面研究,針對沖激響應恰好是最小相位的情況,設計了一個逆濾波器,在一定程度上消除了沖激響應對語音信號的影響,但在多數情況下沖激響應是非最小相位的,因此該方法有一定的局限性;Wu等人[109]利用逆濾波器解決早期混響的非平坦頻率響應使語音頻譜失真的問題,但發現不能去除晚期混響,于是采用譜減法進一步處理,實驗表明逆濾波器和譜減法都改善了語音質量;Dong等人[110]研究如何提升室內公共廣播系統的語音清晰度,提出將Taal等人[111]的感知失真測量語音增強方法(perceptual distortion measure based speech enhancement)方法與Kirkeby等人[112]的快速逆濾波法(fast inverse filtering, FIF)結合,新設計了一種基于Gammatone濾波器的FIF方法,比原FIF方法能進一步減少傳輸信道的失真,如圖6所示.有的工作根據式(3)構建NMF模型以消除混響.Liang等人[113]使用NMF對純凈無混響語音建模,并推導出一種有效的閉式變分期望最大化算法來估計混響和噪聲參數.Mohammadiha等人[114]提出的方法使用卷積傳遞函數的非負近似(non-negative appro-ximation of the convolutive transfer function, N-CTF)來同時估計語音信號和RIR(room impulse responses)的幅度譜.在N-CTF模型中,假設幅度譜中每個頻點的STFT系數大小是由純凈語音信號的幅度與RIR的卷積決定,其優勢在于無需對RIR相位建模.同時為了利用語音的頻譜結構,應用NMF對語音的頻譜建模;Zhang等人[115]考慮到在真實環境中,RIR可能較長而導致對其幅度譜的估計難以收斂,于是在結合N-CTF和NMF的基礎上,分2階段分別處理混響和噪聲,縮短了處理時間并提升了性能;Mohanan等人[116]提出構建非卷積的NMF模型,這樣將更容易在時域或頻域中引入新的約束,以及擴展到有加性噪聲的場景.
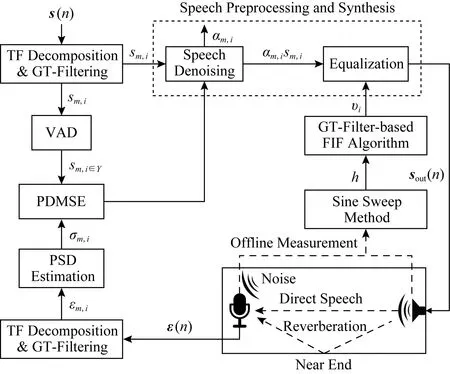
Fig. 6 A method for reverberation elimination圖6 一種混響消除方法[110]
3.2 混響抑制方法
混響抑制方法利用加性失真模型對信號建模,純凈語音信號s(n)、混響r(n)與噪聲u(n)相加形成帶混響和噪聲的語音x(n),在時域可表示為
s(n)=x(n)+r(n)+u(n).
(6)
在混響抑制方法中,早期混響因為混響時間極短且對語音質量有益,一般將它假設為純凈語音的一部分.而晚期混響因為失真且混響時間較長,假設其與純凈語音、早期混響無關,是需要被抑制的部分[104,117].
基于以上晚期混響與語音的加性假設和無關假設,語音降噪方法可以應用于去混響.例如Dionelis等人[118]提出將調制域的自適應卡爾曼濾波用于單聲道語音降噪和去混響,如圖7所示,該算法需要估計語音對數幅度譜的后驗分布,濾波器的更新步驟對語音、噪聲和混響之間的非線性關系進行建模,實驗證明了算法的有效性.Peng等人[15]對噪聲與混響同時加以抑制,使用廣義奇異值分解(generalized singular value decomposition, GSVD)的方法,提出了一種基于約束最小均方誤差(constrained minimum mean square error, CMMSE)的線性預測殘差估計(linear prediction residual estimator, LPRE)算法,稱作CMMSE-GSVD -LPRE.在含有混響和噪聲的實驗中,該算法優于譜減法,但仍有混響成分殘留,于是他們在線性預測殘差域利用了人的聽覺掩蔽特性,進一步提升性能.
帶有權重的預測線性誤差(weighted linear prediction error, WPE)方法早在2008年被提出[119],是目前應用廣泛的混響抑制方法,有不少研究是基于此方法[120-121].雖然其數學模型是基于多聲道的,但也能有效地應用到單聲道.WPE的基本思路是構造濾波器,使用從倒數第K+Δ幀開始的共K幀語音,估計出當前語音幀的混響,再用當前語音減去混響估計,得到對純凈語音的估計,WPE去混響可表示成:
(7)

3.3 基于深度學習的語音去混響方法
混響消除和抑制方法都對產生混響的信號模型做出假設,估計模型的參數,恢復出純凈語音.還有一類方法不估計信號模型的參數,直接將帶混響的語音轉換成純凈語音.近年來,這類方法的主要研究方向是用深度學習模型,通過大量數據訓練,建立混響語音到純凈語音的非線性映射.目前為止,涌現出的相關研究已經應用了多種神經網絡,并根據語音混響特點,結合其他機器學習方法做出創新.
基于深度學習的語音去混響方法在探索初期主要采用DNN.Han等人[122]提出了基于DNN的去混響算法,首先從混響語音中提取出頻譜,采用MLP估計純凈語音的耳蝸譜,最后重構語音信號,取得了比非深度網絡的方法更好的結果;隨后,Wu等人[123]提出混響時間感知模型,將混響時間作為一個控制參數,引入到特征抽取和模型訓練階段,以適當地選擇輸入的語音幀長和幀移;Zhao等人[124]針對噪聲和混響同時存在的場景,分2個階段建模,第1階段用DNN估計掩碼的方式去除噪聲,第2階段用另一個DNN直接估計頻譜的方式去除混響,第1階段的輸出經過特征提取輸入到第2階段的DNN,在訓練過程中,2個DNN是分別單獨訓練,然后再聯合訓練的;在重構語音階段,這項工作沒有直接使用帶噪帶混響語音的相位,而是使用Griffin等人[125]提出的時域信號重構技術;實驗結果表明,該方法明顯優于單階段方法.
除了DNN以外,也有研究工作使用CNN[126-127],RNN或LSTM[128-132]等深度學習模型.Guzewich等人[127]提出了一個基于CNN的去混響模型,參考了VGG模型[133]基本思路,用大量小卷積核提升神經網絡的能力,包含9個卷積層、4個池化層和最后2個全連接層;實驗表明該模型比參考的基線模型更好,并且優于Wu等人[123]提出的DNN模型,該模型在說話人識別任務中有效降低了錯誤率;考慮到早期混響對語音的可懂度有益,而晚期混響則會降低可懂度[134],Zhao等人[132]提出用LSTM神經網絡對混響語音中的長期依賴信息建模,估計出晚期混響成分并從混響語音中減去,而非直接估計出無混響語音;Yu等人[135]提出一個隱含層有CNN和LSTM結構的神經網絡模型,用于語音關鍵詞檢測的前端去噪和去混響;在Zhao等人[136]提出的神經網絡模型中,使用卷積層學習時頻域中的局部模式,再用雙向循環連接層對相鄰語音幀間的動態相關性建模,最后用全連接層估計純凈語音的頻譜;Santos等人[129]采用了相似的建模思路,使用了卷積層和循環連接層構建神經網絡,還在輸入層、隱含層及輸出層間加入了殘差連接.
值得注意的是,近年有工作開始使用GAN的對抗策略訓練去混響模型.Ernst[126]借鑒了全卷積網絡在圖像處理領域的成功經驗,用頻譜圖表示混響語音信號,使用U-Net[137]學習混響語音頻譜到無混響語音頻譜的映射.他們利用了CGAN(conditional GAN)[74]訓練U-Net,這是CGAN首次應用于去混響.Li等人[138]使用了對抗訓練策略,其中語音增強模型是一個包含卷積層、雙向LSTM層和全連接層的神經網絡,與之對抗的判別器模型同樣包含卷積層、雙向LSTM層和全連接層.
有的工作將深度學習與其他機器學習方法結合.Lee等人[139]提出的去混響模型包含多個DAE,根據集成學習的思想,每個DAE處理特定聲學環境中的語音,用融合函數將各DAE處理結果整合得到去混響語音;劉斌等人[128]提出用LSTM神經網絡去混響,發現LSTM估計的純凈語音過于平滑而降低了語音信號的感知質量,于是采用NMF對LSTM的輸出做后處理,有效抑制了過平滑問題;Chien等人[140]設計了一種由矩陣分解方法構建的神經網絡層,稱作STNF(spectro-temporal neural factorization)層,用于提取語音中的時頻域特征,STNF的前向計算和反向傳播都可視作矩陣分解過程,實驗表明STNF層相比于全連接層的去混響效果更好;Raikar等人[141]提出用最大后驗估計建模方法,將獨立的去混響和降噪過程結合到一起,其中降噪部分使用的是SEGAN模型[88],其輸入是去混響的結果,其去噪的結果又會提升混響卷積矩陣的估計準確率.表5中是不同去混響方法在不同的混響時間(T60)下的PESQ,STOI以及語音混響調制能量比(speech-to-reverberation modulation energy ratio, SRMR)指標統計.SRMR是一種非侵入式無需純凈語音進行計算的指標,用于評估語音質量與可懂度,它的值越高表示去混響的效果越好.
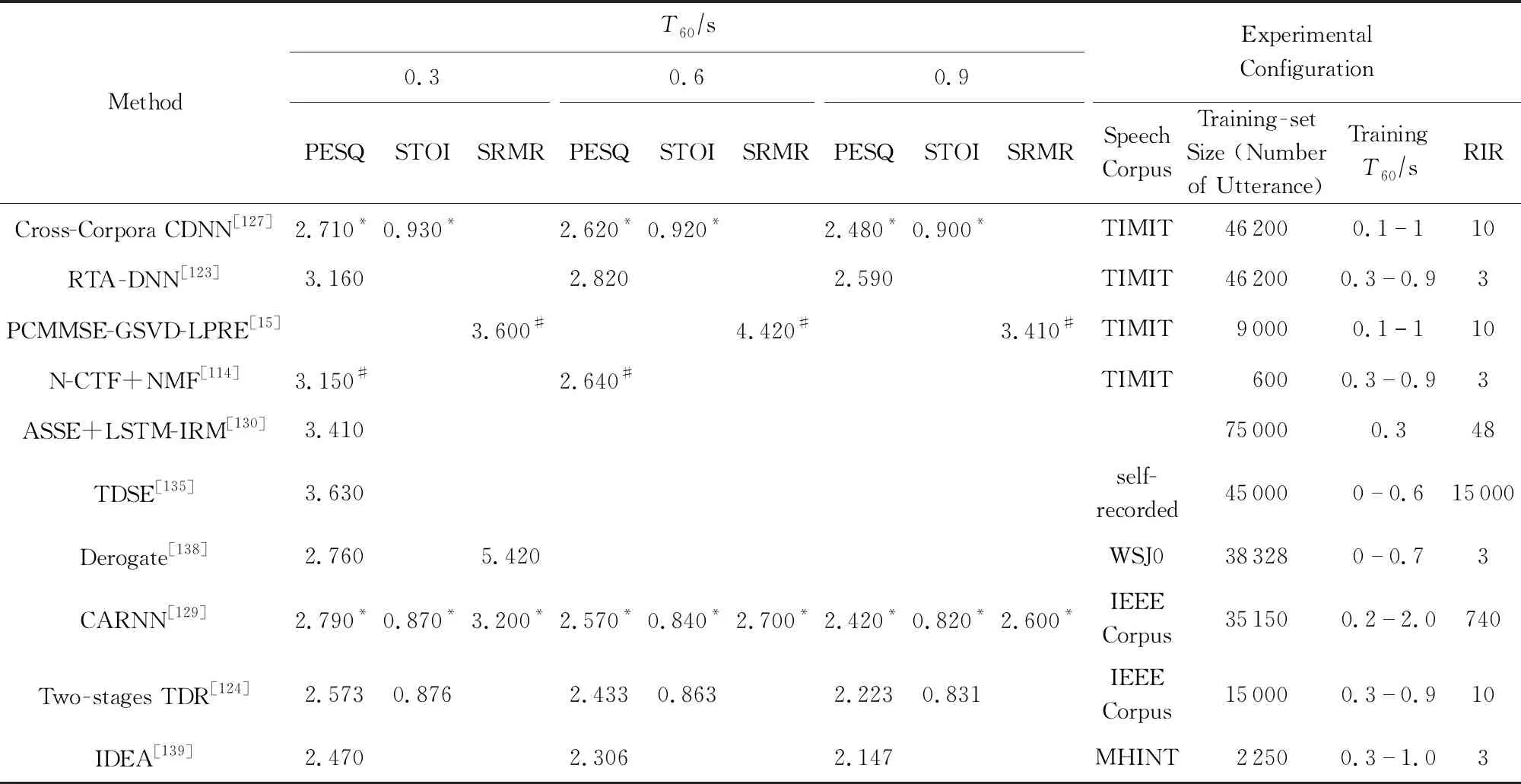
Table 5 Comparison of Scores in Speech Dereverberation Methods表5 語音去混響方法的指標對比
Note: The symbol * comes from our estimation of the graph in the reference paper and the symbol # comes from the rounding of the data in the reference paper.
4 實驗與評估
本節介紹了在語音增強實驗及評估中的一些必要內容,主要包括數據集、特征和評估指標.語音增強實驗都需要根據實驗目的準備特定的數據集,并使用數據集對算法的有效性及性能進行檢驗.對大多數學習算法而言,進行學習前需要先從數據中提取更易于學習的特征,因為直接學習原始數據往往是比較困難的.此外,對實驗結果進行評估也是必要的,一方面可以從評估分數判斷實驗結果的好壞,另一方面不同算法的實驗結果很難直接進行比較,在進行評估后就可以方便地對比每個算法的性能.
4.1 數據集
數據集是語音增強實驗的關鍵部分,作用于模型訓練、驗證、測試的整個過程.通常,數據集的大小和數據的多樣性對模型的性能及泛化能力有很大影響.在語音增強中,數據的多樣性包括語料的多樣性、噪聲的多樣性、信噪比的多樣性、說話人的多樣性.經實驗證明[61,142],在一定范圍內,隨著數據集數據量的增加和數據多樣性的提高,語音增強模型的噪聲、信噪比、說話人甚至是語言的泛化能力都有所提高.
在語音增強中音頻數據集一般可以分為純凈語音數據集、噪聲數據集以及帶噪語音數據集,實驗大多會使用公開數據集,但此外一些有特殊需求的研究者會自行構建數據集.當實驗需要用到帶噪語音時,可以使用已有的帶噪語音數據集,也可以使用語音噪聲混合工具,如濾波與噪聲添加工具(filtering and noise adding tool, FaNT)[143]將純凈語音和噪聲混合,通過調整參數得到特定信噪比的帶噪語音.在進行去混響實驗時,主要通過將語音信號與不同混響時間的房間脈沖響應RIR進行卷積得到混響語音信號.語音增強中常見的音頻數據集如表6所示:
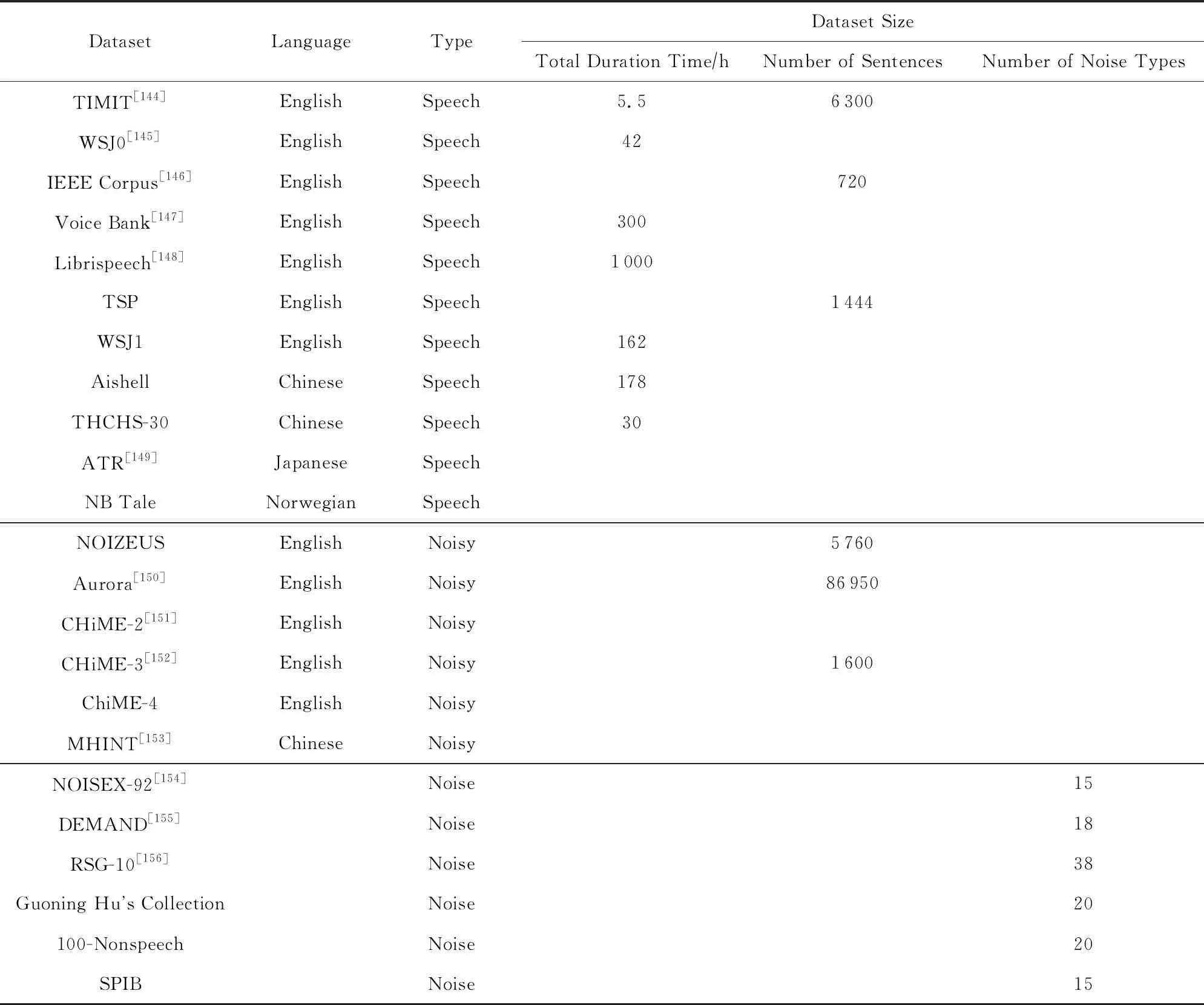
Table 6 Common Voice and Noise Datasets表6 常見語音和噪聲數據集
4.2 特 征
語音信號是一種非平穩、時變的隨機過程,很難直接對其學習,因此往往需要進行特征提取,而提取不同的特征會對增強性能有很大的影響.數十年來,為提高語音質量及可懂度,學者們提出了多種語音特征,這些特征都有各自的優勢和不足.在單聲道語音增強的早期研究中,主要使用基于基音的特征[157]和幅度調制譜(amplitude modulation spectrum, AMS)[158],這些特征提取過程相對簡單,但表示能力不足.接著逐步提出了更多單聲道特征,包括梅爾倒譜系數(mel-frequency cepstral coefficient, MFCC)[159]、感知線性預測(perceptual linear prediction, PLP)[160]、相對頻譜表示(representations relative spectra, RASTA-PLP)[161],這些特征雖然在一定程度上提高了語音增強性能,但單個特征還是難以取得很好的效果.針對這一問題,Wang等人[159]使用Group Lasso特征選擇器,得到了1組互補的特征組合,包括AMS,RASTA-PLP,MFCC,這個特征組合在多種條件下相對單個特征顯著地提高了增強性能,在很多研究中得到了應用.同時,短時傅里葉變換幅度譜和短時傅里葉變換對數幅度譜也常用于語音增強,且由于高頻部分幅度較小,故對數幅度相對幅度更能凸顯高頻成分.然而有研究[162]發現,短時傅里葉變換幅度譜的性能比短時傅里葉變換對數幅度譜略好.此外,學者們還在Gammatone濾波的基礎上提出了Gammatone特征(Gammatone feature, GF)、Gammatone倒譜系數(Gammatone frequency cepstral coefficient, GFCC)[163]、Gammatone調制頻譜(Gammatone frequency modulation spectral based cepstral, GFMC)[164].隨后,又有學者對已有的特征進行研究與改進,在MFCC的基礎上提出了Delta倒譜系數(delta spectral cepstral coefficients, DSCC)[165]、相對自相關序列MFCC(relative auto-correlation sequence MFCC, RAS-MFCC)[166]、自相關序列MFCC(auto-correlation sequence MFCC, AC-MFCC)[167]、相位自相關MFCC(phase auto-correlation MFCC, PAC-MFCC)[168].陳紀同等人[169]提出了多分辨率聽覺譜(multi-resolution cochleagram, MRCG)特征,它同時計算出4種不同分辨率的倒譜,從而可以同時提取到局部性信息和整體性信息,現已成為最常用的特征之一.
下面對一些常見的特征進行介紹:
1) MRCG
MRCG由4種不同分辨率的倒譜組成,高分辨率倒譜捕捉局部信息,3個低分辨率倒譜捕捉不同尺度的上下文信息.為得到MRCG,首先將信號進行64通道的Gammatone濾波得到一個聽覺譜,稱作CG1,并在每個時頻單元進行取對數操作;類似地,可用200 ms的幀長和10 ms的幀移計算得到第2個聽覺譜,稱作CG2;其次使用一個長為11幀和寬為11頻帶的方形窗對CG1進行平滑,得到第3個聽覺譜,稱作CG3;和CG3的計算相似,使用23×23的方形窗對CG1進行平滑,得到第4個聽覺譜,稱作CG4;串聯CG1,CG2,CG3,CG4得到一個64×4的向量,即為MRCG.
2) MFCC
MFCC即梅爾倒譜系數,首先對輸入信號作分幀操作,經驗上取10~30 ms幀長,5~15 ms幀移;其次對每一幀進行加窗處理,一般使用漢明(Hamming)窗;然后進行FFT計算得到對應的頻譜,再將頻譜通過Mel濾波器組轉換為梅爾域,最后在Mel頻譜上進行倒譜分析,得到MFCC.
3) GF
該特征由Gammatone聽覺濾波得到,首先用Gammatone濾波器組對信號進行處理,然后對每個濾波輸出以100Hz的頻率進行采樣,最后采樣結果通過立方根操作進行幅度壓縮得到GF.
4) GFCC
GF特征一般由64個頻率成分組成,但在實際系統中由于GF特征矢量的維度比較大,計算量也較大.此外,由于相鄰的濾波器通道有重疊的部分,導致GF特征矢量相互之間存在相關性.因此為減小GF特征矢量的維度及相關性,對每一個GF特征矢量進行離散余弦變換(discrete cosine transform, DCT)得到GFCC.實驗表明,前若干維及最后若干維的GFCCs系數對語音的區分性能較大,因此一般取前26維的GFCC系數作為特征.
5) PLP
PLP即感知線性預測系數,它能夠最大限度地消除說話人不同帶來的影響,同時可以留下關鍵的共振峰結構,由于該特征與語音內容比較相關,因此常用于語音識別.
4.3 評估指標
評估實驗結果需要設定評估指標,不同的指標從不同角度對實驗結果進行評分.語音增強任務有多種評估指標,這些指標按評估方法可以分為主觀方法和客觀方法.主觀方法的評估主體為人,以人耳感受為判別標準,帶有一定的主觀因素;客觀方法是指計算機直接以一定的計算方法來為語音評分,在實驗中多采用客觀方法.從評估目標級別的角度可分為信號級別和感知級別,信號級別的指標目的是量化信號增強或干擾降低的程度,如信噪比(signal to noise ratio, SNR);而感知級別的指標更關注語音增強對于語音的可懂度和感知質量的提高,如PESQ,STOI.表7~9中分別列舉了語音增強中的客觀指標、主觀指標以及語音去混響的指標:
Table 7 Speech Enhancement Objective Evaluation Index表7 語音增強客觀評估指標

Table 8 Speech Enhancement Subjective Evaluation Index表8 語音增強主觀評估指標

Table 9 Speech Dereverberation Evaluation Index表9 語音去混響評估指標
對4個常用的評估指標進行詳細介紹:
1) 平均主觀意見分(mean opinion score, MOS)
MOS[170]常用于衡量通信系統語音質量,由人對語音質量的真實反映得出,但其受測試條件的限制和測試人員主觀因素的影響,且不滿足實時性要求.由不同人分別對原始語料和經過系統處理后失真的語料進行主觀感覺對比,最后求平均得到MOS值,MOS值取值范圍為1~5分.
2) PESQ
PESQ指標[171]的設計目的是評估電話網絡和編解碼的語音質量,與MOS高度相關,側重于評估語音的清晰度.它是感知分析測量系統(perceptual analysis measurement system, PAMS)和感知語音質量增強版PSQM99(perceptual speech quality measure 99)集成的結果,應用范圍廣泛,包括模擬連接、編解碼器、報文丟失、可變延遲.同時它是國際電信聯盟電信標準化部門(ITU-T) P.862建議書提供的客觀MOS評估方法.PESQ值介于-0.5~4.5之間,但是對于正常的主觀測試材料,該值介于1.0(差)和4.5(無失真)之間.在極高的失真度下PESQ值可能會低于1.0,但這種情況非常少見.
3) STOI
STOI指標由Taal等人[172]于2011年提出,它是基于純凈語音與帶噪語音的時間包絡相關系數計算得到,在實驗中表現出與語音可懂度的高度相關性.計算STOI包括3個步驟:首先去除靜音幀(silent frames),即刪除能量少于50 dB的幀,因為靜音對語音可懂度沒有影響;其次,對信號進行基于DFT的1/3倍頻帶分解,漢明窗的長度為25 ms,256個頻率覆蓋,頻率范圍為0~5 kHz;最后通過相關過程計算輸出STOI.STOI取值范圍為[0,1],且與主觀語音可懂度正相關,即值越大表示語音可懂度越好.
4) 分段信噪比(segmental SNR,segSNR)
segSNR指標主要用于語音增強、語音編碼后的測試.由于語音信號是非平穩信號,有很多低能量和高能量區域,并且這些區域與語音的理解密切相關.segSNR不計算整段語音的信噪比,而是計算短期(15~20 ms)SNR的平均值,因此能夠反映語音的局部失真水平.與SNR相比,segSNR與MOS的相關度更高.
5 問題與挑戰
在研究者們的努力下,傳統方法或深度學習方法的語音增強算法性能都得到了一定提高.但語音增強領域仍存在著一些問題和挑戰,包括低信噪比環境下的語音增強問題、增強算法的泛化問題、相位失真問題、測度不匹配問題等.
5.1 低信噪比環境下的語音增強問題
在低信噪比環境中實現有效且穩定的語音增強仍然面臨著挑戰.在-5 dB環境下,語音功率不及噪聲功率的1/3,語音幅度常常只有噪聲幅度的一半.短時傅里葉變換后,幅度譜以噪聲為主導,使得一些基于掩蔽的模型失去了優勢,常用的IBM會把噪聲與語音混合的部分劃分為噪聲而全部過濾,這種情況下基于掩蔽的模型的效果往往不如基于映射的模型.
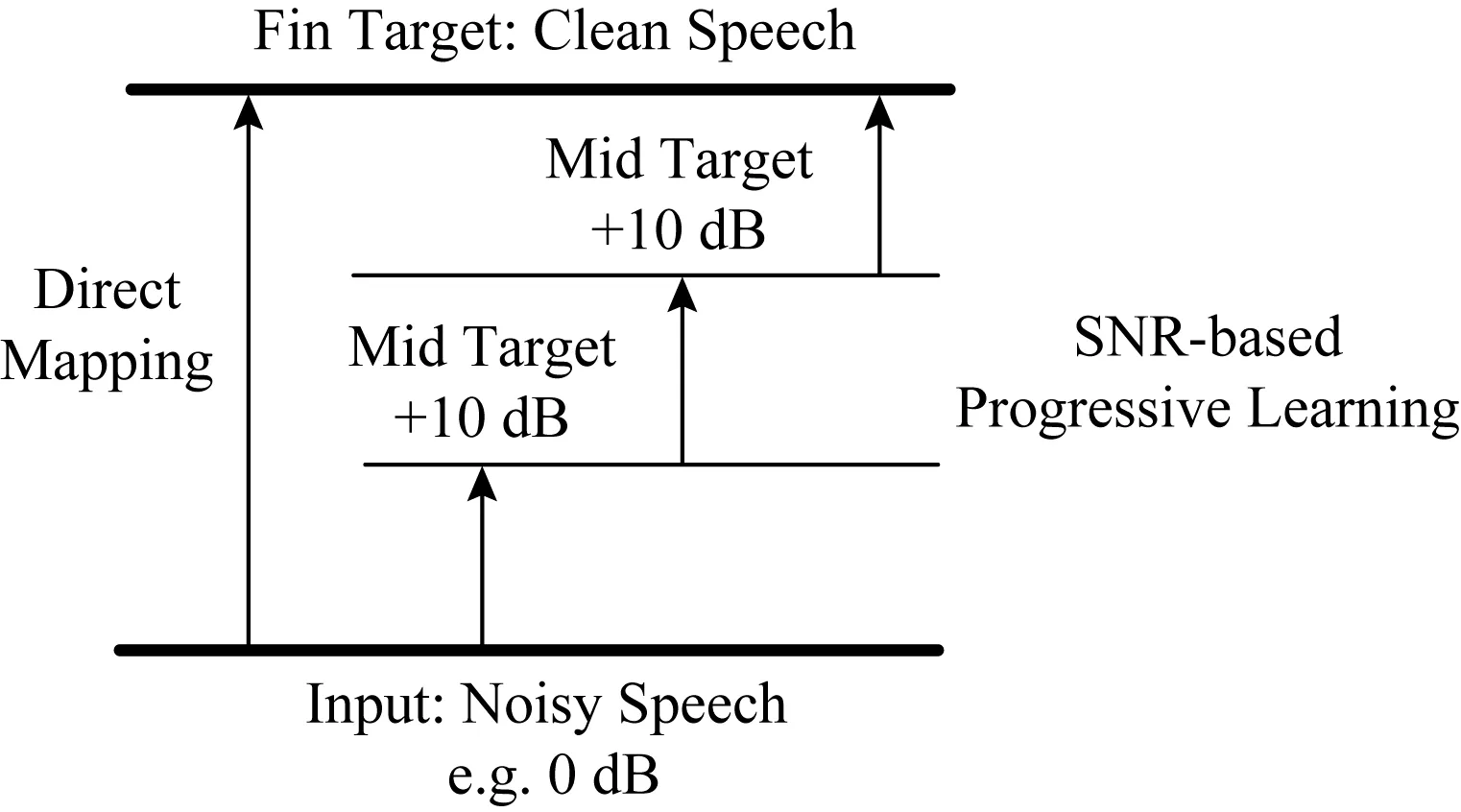
Fig. 8 The PL model for speech enhancement[174]圖8 語音增強的PL模型[174]
面對低信噪比條件下的復雜環境,PL(prog-ressive learning)模型及其與多任務學習和集成學習結合的方法進入了研究者的視野[72,173].PL模型與普通模型的差別是它把一個學習目標拆分為多個子目標,每個子目標相較前一個目標更加接近最終目標.如圖8所示,處理SNR為0 dB的信號的過程可以拆分為先達到10 dB、再到20 dB、最后獲得目標純凈信號3個階段.實驗證明,PL模型比一般模型更加適合訓練海量數據或復雜特征.一種解釋是一般模型訓練海量數據時,隨著訓練數據的增加,模型發生了災難性的遺忘,丟失了之前學到的部分信息.復雜的低信噪比環境下,一般模型也更容易受到影響.而PL模型的結構可以使之按階段保留過去學習到的信息,最后把每個階段的信息集成到對最終目標的訓練中去.因此,在低信噪比或多信噪比環境下,PL模型可以學習并保留更多特征,泛化性更強.然而,如何選擇中間階段的訓練目標是PL模型要解決的問題,簡單地把訓練目標指定為一個固定SNR的語音,可能無法發揮模型真正的效能.而在結合多任務學習的PL模型中,如何選擇訓練目標也是一個問題.研究者可以探索一種產生對信噪比環境自適應的階段目標算法,也可以選擇其他的評估指標.
在結合多任務的模型中,模型使用了不同濾波方法提取的聲音特征,MFCC和GFCC是2種提取聲音特征的方式[175],提取后的特征會存在相似或者不同的地方,研究者可能需要選擇具有互補特征的訓練目標.Fu等人[71]將SNR感知結構和語音增強模型相結合,提出了2個基于CNN的模型,它們在低信噪比條件下取得了更好的效果.前一個模型學習環境中的SNR級別,在目標函數中加入環境真實的SNR值,形成一個多任務學習模型.模型在降噪的同時還會判斷環境的SNR,以此適應不同的環境;后一個模型先評測環境的SNR.然后根據不同的SNR,選擇不同的降噪模型.實驗表明,這2個模型性能都優于簡單CNN模型,這說明對于不同的SNR環境,可以通過加入SNR評測的方法來提高模型能力.而且實驗中還發現后一個模型在12 dB和-12 dB的SNR環境下測得的一些指標優于前一個模型,這意味著對應不同SNR環境使用不同的語音增強模型可能得到更好的結果.
5.2 模型算法泛化問題
基于深度學習的語音增強模型在面對未知環境時,性能會明顯惡化.模型的泛化能力不良一直是個難題.語音增強算法的泛化能力可以分為3個方面:對未知種類噪聲的泛化能力、對未知信噪比環境的泛化能力和對未知說話人的泛化能力.一種簡單有效提高模型泛化能力的方法是在大量不同的噪聲數據集上訓練模型,而且使用RNN模型比DNN模型更加有優勢[96].近幾年,Park等人[176]提出了基于CNN編碼的語音增強模型,在未知噪聲和未知信噪比環境下表現較好.同時,利用編碼CNN或擴張CNN模型也能提高對未知說話人語音增強的能力[96-97].
ASAM[177]提供了另外一種提升增強模型對噪聲的泛化能力的思路.ASAM是一個利用注意力機制和長期記憶的語音分離模型,它利用雙向LSTM對混合語音和純凈語音的幅度譜作高維映射.再將純凈語音幅度譜的映射融合為一個向量,表示為純凈語音的特征,存入長期記憶中.然后利用該段記憶來關注混合語音中屬于同一說話人的映射的向量.長期記憶結構中存在一個存儲空間來臨時保存未知說話人語音的記憶.這是一個語音分離模型,但可以把要移除的語音替換作噪聲.在測試階段,把捕獲的不含語音的未知噪聲看作未知語音輸入模型,將其特征存入模型的長期記憶中.這類似一種實時獲取噪聲特征的方法.此后可以利用不同噪聲的特征結合語音特征來增強語音.
5.3 相位失真問題
目前常用的基于深度學習的語音增強過程是先對帶噪語音計算短時傅里葉變換得到幅度譜和相位譜,再對幅度譜進行處理,最后將產生的幅度譜與原始帶噪信號的相位信息合成純凈語音.但是近些年,研究者開始注意到相位信息在語音增強中的重要性.
除了利用相位信息的掩蔽層的模型[48],研究者探索更好的方法去使用帶噪信號的相位重構純凈語音信號的相位.在頻域的無監督語音增強的相位重構方法中,有2類方法:基于振幅的方法和基于模型的方法.基頻法是一種基于模型的方法,最近研究者提出利用基頻的方法[178-185].短時傅里葉變換相位改良法[182]是一種先進的相位重構方法,但該方法會引入額外的蜂鳴聲.而Wakabayashi等人[185]利用了相位失真特征,抑制了額外的聲音,在PESQ上表現超過短時傅里葉變換相位改良法[181],但在STOI指標上沒有有效地提高.
一些研究者直接在時域上利用CNN處理帶噪語音[84,93],這樣避免了原始帶噪信號的相位的使用,提升了一定的模型性能.但是這種做法只將時域上的信息輸入神經網絡,未利用神經網絡處理頻域信息,或忽略了信號在頻域上的信息,這樣可能丟失了一部分必要的純凈語音信息.將模型結合多任務學習的方法可能會有進一步提高.
5.4 語音增強算法測度不匹配問題
語音增強的一個目標是增加語音的可懂度,把錯字率(word error rate, WER)看作評估語音增強算法能力的指標可能更為直接.但這種做法要結合語音識別系統的測試或人工識別測試,評估難度較大.簡單地計算增強語音的SDR,SIR,SAR指標可以避免語音識別中繁雜的流程,但同時這些指標存在與語音可懂度的相關度不夠的問題.于是后來出現了一些匹配人類聽覺感知方法的指標,如STOI.
同時,不匹配的問題也存在于深度學習增強算法所常用的損失函數MSE(mean-square error).一個好的損失函數可以提高模型的性能.MSE簡單地計算預測語音和正確語音波形或幅度譜的歐氏距離,有時不能完全反映增強語音的質量.因此,出現了新的基于不同的語音評估指標的損失函數.STOI是目前評估增強語音可懂度的重要指標,它接近人類評估語音方式.但一般使用的損失函數MSE與這種方式不匹配,在優化模型時不一定能改善STOI[186].如何改良損失函數以匹配STOI的運算方式是最近的一個研究點.有研究者以提高語音有限的SNR為目標來訓練模型,卻取得了更好的效果,由此發現人類對語音質量的評估與損失函數MSE存在不匹配問題[103].Zhao等人[186]提出了以STOI指標為訓練目標的損失函數:
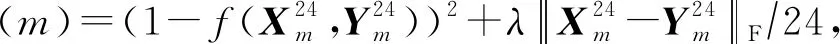
(8)

Table 10 Performance Comparison of Models Using STOI and MSE Loss Functions
Note: The bold indicates better performance under the same metric and SNR.
6 結束語
語音識別被認為是人工智能未來發展的重要方向之一,而語音增強是其中一項核心關鍵技術,此外它也能應用于語音通話、電話會議、場景錄音、軍事竊聽和聽力輔助等場景,因此具有重要的理論研究與實際應用價值.本文從方法、數據集、特征、評估指標等方面,對單聲道語音增強(包括降噪與去混響)研究工作的發展現狀進行了全面調研和深入分析,并對該工作面臨的重要挑戰和關鍵問題進行了總結.盡管國內外研究人員已經提出了多種單聲道語音增強方法,深度學習的引入也為該領域研究帶來了新的突破,但已有工作還存在泛化性差、相位失真、測度差異等問題,特別是在低信噪比環境下的應用效果還很不理想,所以這仍是一個充滿挑戰、值得研究的領域.
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
