算禮:探索計算系統的可分析抽象
2020-06-08 08:59:40徐志偉王一帆趙永威李春典
計算機研究與發展 2020年5期
徐志偉 王一帆 趙永威 李春典
(計算機體系結構國家重點實驗室(中國科學院計算技術研究所) 北京 100190)(中國科學院大學 北京 100049)
本文是一篇觀點文章,指出計算系統研究需要學習算法領域的經驗,探索能夠刻畫計算系統本質特征的可分析抽象,并提出了一個初步概念,稱為算禮,旨在拋磚引玉,促進計算系統抽象的研究.
長期以來,計算系統領域缺乏“算法”這樣簡潔的學術概念來刻畫系統的本質特征,使得系統研究往往依賴原型研制和基準程序測試.這種“原型測試”的計算系統設計方法非常耗時耗資源,研究結果往往難以被他人重現.另一方面,計算機系統結構研究正在進入多樣性時代,各種加速器帶來的異構硬件、領域特定體系結構(domain-specific architecture)、庫操作系統、眾多的應用框架、物聯網系統的昆蟲綱悖論,都是多樣性趨勢的表現.業界迫切需要超越“原型測試”的計算系統分析與設計方法,尤其需要能夠簡潔地刻畫計算系統的可分析抽象,即在原型測試之前,就能分析出系統重要性質的抽象描述.
計算系統出現多樣性趨勢主要可以歸納為3個原因:1)應用需求的多樣性,尤其是高能效(性能功耗比)的要求,難以被一種通用計算系統滿足[1-2];2)計算系統的范圍早已從單機拓展到并行計算機、分布式計算系統;3)計算系統的層次近年來已經從系統硬件層、系統軟件層拓展到包括Spark和TensorFlow等系統的應用框架層.
John Hennessy與David Patterson最近指出,計算系統的多樣性趨勢為計算機系統結構研究帶來了又一個黃金時代[2].系統抽象是計算機系統結構研究的一個重要方向.本文學習算法的經驗,指出計算系統研究需要能夠刻畫系統本質特征的可分析抽象,并提出了一個初步候選,稱為算禮(computation protocol),以拋磚引玉,促進學術社區對計算系統可分析抽象的研究.我們討論了算禮的黑箱模型和白箱模型,并用初步的實例指出,算禮思想有助于在計算系統領域提出系統猜想、分析新的并行計算模型、拓展現有架構、啟發新的系統評價方法.
1 計算系統研究需要向算法學習
計算機應用研究離不開計算機科學的一個本質抽象——算法.今天,算法已廣泛滲透到計算機科學技術整個領域,包括它的3個二級學科:計算機系統結構、軟件與理論、計算機應用.
算法的廣泛滲透性得益于它是一個可分析抽象.學習和研究一個算法,并不一定要將該算法實現成程序代碼在真實或原型計算機上運行,就可以分析出它的重要性質.事實上,國內外很多算法課程不涉及編程.但是,計算系統領域缺乏“算法”這樣的抽象來刻畫系統的本質特征,研究計算系統往往需要原型系統構建和基準程序測試.
算法這個抽象具備哪些特點呢?算法不同于程序,它是程序的簡潔描述,體現了程序的本質特征.Donald Knuth給出了算法的一般定義[3].
定義1.五特征算法定義[3].算法是一組有窮的規則,給出求解特定類型問題的運算序列,并具備下列5個特征:
1) 有窮性.一個算法在有限步驟之后必然要終止.
2) 確定性.一個算法的每個步驟都必須精確地(嚴格地和無歧義地)定義.
3) 輸入.一個算法有零個或多個輸入.
4) 輸出.一個算法有一個或多個輸出.
5) 能行性.一個算法的所有運算必須是充分基本的,原則上人們用筆和紙可以在有限時間內精確地完成它們.
定義1使得任何算法實例具備7個優點,我們可從算法概念本身和快速排序算法實例角度進一步說明.
1) 通用性.任何算法實例,不論是快速排序(quicksort)、高斯消元解方程、求最短路徑的Dijkstra算法,還是任何串行算法、并行算法、分布式算法,都滿足Donald Knuth的五特征算法定義.
2) 易描述.算法比實現該算法的程序往往簡潔得多,例如幾行偽代碼足以精確描述quicksort算法.
3) 易理解.簡潔描述特性也使得理解算法更容易,例如quicksort算法的基本邏輯與特色訣竅很容易被理解.
4) 可分析.quicksort算法的時間復雜度、空間復雜度可被嚴格地分析出來.
5) 可證明.可嚴格地證明quicksort算法的正確性、復雜度和適用范圍.
6) 抽象性.算法不依賴于具體實現技術(硬件及軟件),包括已有技術和未來的技術,英文稱這個特性為technology-proof和future-proof.
7) 可重復.有了上述6條優點,算法本身和算法的研究結果具備可重復性(reproducibility),即他人可復制、可復現和可重用,這是任何科學方法的本質特征.
上述7條優點中,最重要的是可分析抽象.計算系統研究需要能夠簡潔刻畫計算系統本質特征的可分析抽象,使其具備算法的上述7條優點,能夠超越原型系統構建和基準程序測試,提升系統研究的效率.
超越原型測試并不是不要原型測試.原型測試仍將是計算系統研究的重要方法.可分析抽象可用在多種系統設計選擇中、多次系統設計迭代中,在原型測試之前,篩掉不合適的候選系統,優選剩下的設計,再采用原型測試驗證優化.
2 相關工作的歷史經驗
計算系統可分析抽象的相關研究已有數十年歷史,本節討論了6類研究工作并總結了歷史經驗.
1) Jim Gray在1999年的圖靈獎獲獎演說中提出了未來計算機科學技術的12個挑戰難題[4],其中最后一個稱為“自動程序員”(automatic programmer)難題,即計算系統應該提供高效編程接口,使得設計應用程序容易1 000倍.如果系統缺乏可分析抽象,很難想象可以實現應用設計容易1 000倍的目標.
2) Leslie Lamport指出:這樣的可分析抽象,即刻畫系統本質特征的高級設計,是存在的[5].他引用了Tony Hoare的觀點:“Inside every large program, there is a small program trying to get out”,其中small program是刻畫該large program本質特征的算法,也稱為specification或high level design.Lamport開發了TLA+工具,可用于描述串行和并發系統,并對其性質做自動模型檢測[6].
3) John Hennessy與David Patterson因提出計算系統的量化設計方法獲圖靈獎.在回顧其量化設計方法時,Hennessy指出,處理器系統的CPI公式是量化設計方法的重要創新點[7].
事實上,這個公式既簡潔又實用.例如,僅用一個指標CPI(clocks per instruction)就能區分出不同的指令集體系結構.CPI>1(即執行一條指令需要多于一拍時鐘)對應著CISC體系結構;CPI=1對應著RISC體系結構;CPI<1對應著超標量(superscalar)體系結構.
4) 系統的性質不都是定量的,也有重要的定性性質,例如分布式系統的CAP定理:一個分布式系統能夠且僅能夠滿足一致性(consistency)、可用性(availability)、分區容錯性(partition tolerance)三條性質中的2條[8].CAP定理揭示了分布式系統的一種本質的不可能性.這個貌似負面的定性結果被廣泛應用于今天的云計算系統、大數據系統、互聯網服務系統的設計與實現中.
5) 針對并行計算系統,Leslie Valliant提出了Bulk-Synchronous Parellel(BSP)模型[9].借鑒串行計算機的馮·諾依曼模型經驗,BSP提供了一個并行計算機的簡潔抽象模型,應用算法研究者不用關心多種多樣的真實并行計算系統,而是針對簡潔唯一的BSP抽象模型研究并行算法.Valliant證明,不少典型并行算法,當從BSP過渡到真實并行計算機上時,映射開銷為O(1).這種在應用算法和真實計算系統之間提供一個簡潔抽象模型的思路稱為橋接模型(bridging model).今天,BSP已經成為很多真實的并行計算、云計算、大數據系統支持的典型計算系統模式.
6) 針對萬維網,Roy Fielding提出了表象狀態轉移(representational state transfer, REST)體系結構風格[10],支撐了近20年的PC互聯網與移動互聯網應用.REST給出了一類系統抽象,即“體系結構風格”(也稱為架構風格):architectural style—an abstraction across many specific application architectures[11].體系結構風格的核心是一組體系結構設計原則,又稱為體系結構約束(architectural constraints).例如REST提出了統一界面(uniform interface)、無狀態通信(stateless communication)等6條原則.不同的桌面瀏覽器系統、移動瀏覽器系統、安卓APP系統、各種WWW服務器系統都遵循這6條REST體系結構設計原則.
上述研究提供了計算系統抽象的6條成功經驗.它們表明,未來計算系統抽象應該考慮6個研究方向和目標:1)高效接口,使得應用設計容易1 000倍;2)刻畫系統本質特征的高級設計,揭示出大而復雜的系統中的小而簡潔的可分析抽象,即the small program trying to get out;3)刻畫系統本質特征的定量公式;4)刻畫系統本質特征的定性定理;5)真實應用算法與真實計算系統之間的橋接抽象模型;6)覆蓋多種真實系統結構的體系結構風格.
3 算禮初探
3.1 算禮的直覺性質
研究算禮的目的是提煉出能夠簡潔刻畫計算系統本質特征的可分析抽象,使得計算系統研究具備算法研究的7條優點.那么,從直覺上看,算禮應該具備什么新性質,為什么不沿用“算法”或“計算模型”這些名稱,而是要使用一個新詞呢?
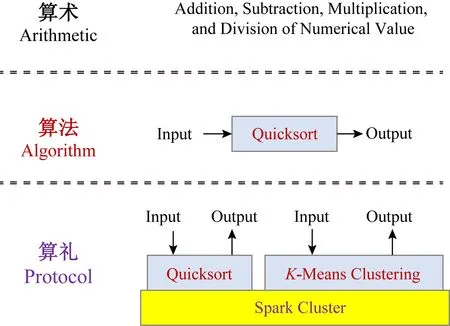
Fig. 1 Comparison among arithmetic, algorithm, and computation protocol圖1 算術、算法、算禮之比較
1) 算禮不是算法.圖1顯示了算禮與算術和算法的區別.算術關注特定數值的加減乘除四則運算.算法關注給定輸入數據,能夠求出期望的輸出數據的計算方法,尤其是時間復雜度/空間復雜度較低的有效方法.算禮關注計算系統的簡潔刻畫.一個算禮上可運行多個算法.例如圖1中的Spark機群可用一個算禮刻畫,它可以支持快速排序、k-means聚類等多種算法.給定一個算法,從給定輸入可求出期望的輸出結果.給定一個算禮,從給定算法和給定輸入,才可能求出期望的輸出結果.
2) 算禮不等于傳統的計算模型.在計算機科學界,計算模型(models of computation)已有特定的定義[12-13],主要關注各種圖靈機、PRAM、I/O自動機等串行、并行和分布式計算模型,這些模型難以刻畫Spark機群等計算系統的本質特征,也難以刻畫人機物三元計算系統的本質特征.我們可以稍微修改下Tony Hoare的觀點,得到:“Inside every large system, there is a small protocol trying to get out.”這個“small protocol”就是該“large system”的算禮.簡言之,算禮概念與計算模型有交叉,但不完全等同.
4) 算禮(computation protocol)之禮不是comm-unication protocol之protocol(協議),而是更像自然科學期刊《Nature Protocols》之scientific protocol,強調他人可復制的構造性科學方法、他人可復制可重現可重用的系統抽象.
3.2 算禮的一般表述
我們學習Donald Knuth的五特征算法定義,給出算禮的一般表述(稱為PEN刻畫).
定義2.算禮.算禮是一組有窮的規則,給出求解特定類型問題的計算系統,并具備下列4個特征.
1) 負載(payload, P):算禮支持的應用負載類型.
2) 執行模型(execution model, E):連接資源的體系結構,說明負載在資源上如何執行.
3) 賦名資源(named abstractions of resources, N):對負載和執行模型可消耗的資源的明確命名與抽象.
4) 可重復性(reproducibility):給定算禮的PEN刻畫,他人可重現系統與結果.
3.3 算禮的黑箱模型
算禮有白箱表示和黑箱表示.黑箱表示主要涉及P,白箱表示涉及PEN三者,如圖2所示.Payload除了算法和數據這些workload之外,還包含5個具體的P,即problem,principle,properties,programming model,policies,他們與workload一起共同刻畫了payload需求.算禮的黑箱表示主要關注problem,principle,properties,隱藏了PEN的其他內容.
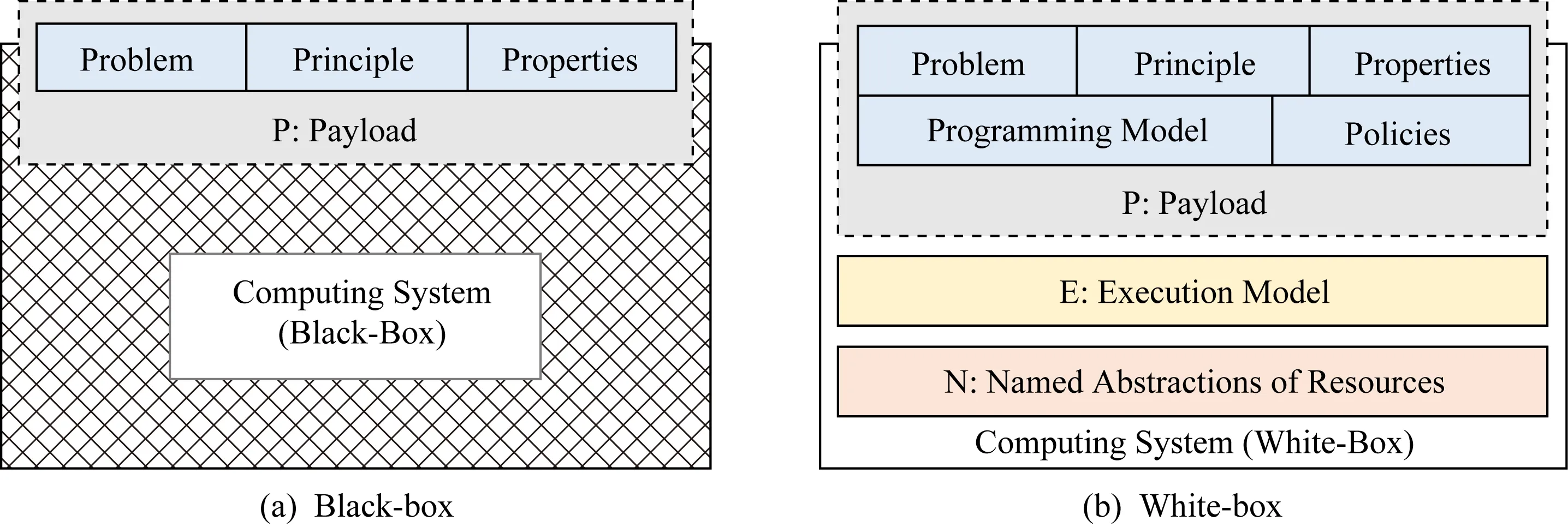
Fig. 2 The black-box representation and white-box representation of computation protocol圖2 算禮的黑箱表示與白箱表示
任何系統都是被設計用來有效支持一類負載的.它的算禮針對該負載的特有問題(problem),提出解決該問題的特有的原理(principle),凸顯期望的計算性質(properties).
隨著科學技術的快速發展,人們的生活方式、學習方式、娛樂方式等都發生了翻天覆地的變化,同時各國之間的利益關系也變得微妙起來,尤其是發展中國家的快速發展更是對國際力量產生了重要影響。與此同時,中國面臨的國際形勢越發嚴峻。另一方面,我國仍處于社會主義初級階段,這是我國最大的國情,距離實現中華民族偉大復興還有很長的一段路要走。在這樣的環境下,中國共產黨保持黨的先進性,領導中國人民走向共同富裕、民族復興成為重要內容,所以,重視黨的建設成為新時期中國共產黨的關鍵任務。[2]
例如大數據應用框架Spark的設計初衷是針對MapReduce等應用框架不能有效“重用多級計算的中間結果”(reuse intermediate results across multiple computations)的問題[14].MapReduce也可以重用多級計算間的中間結果,但比較低效,其原因有2個:1)中間結果需要存盤;2)為了容錯,數據需要復制.Spark解決這個低效問題的原理是“內存計算”(in-memory computing).Spark將數據和中間結果放在一種創新的內存數據抽象RDDs(resilient distributed datasets)中,并通過粗粒度的RDD transformation以及lineage機制實現容錯計算.
Spark算禮具備3個性質:1)大多數情況下,數據的存儲和計算發生在處理器和內存中,不涉及硬盤;2)特別地,多個RDD transformations的中間結果存放在內存中,不用存盤,從而通過內存計算支持了多級計算;3)容錯不是靠多副本,而采用lineage機制,出錯時重算,消除了復制開銷.
3.4 算禮的白箱模型
算禮的白箱模型暴露的PEN的全部,也稱為算禮的PEN模型.
定義3.算禮的PEN模型.一個算禮是三元組(負載,執行模型,賦名資源)=(P,E,N),說明如何利用賦名資源執行負載的系統組成和執行規則.三元組的含義說明為:
1) P是負載(payload),或者說是workloads,說明算禮適用的負載類型,包括支持的(和不支持的)負載.Payload還包括problem,principle,properties,programming model,policies五個更加具體的P.例如,MapReduce系統(MR算禮)主要支持批處理類負載,而不是交互式負載.MR算禮提供分布式系統的MapReduce函數式編程模型[15].
2) E是執行模型(execution model),即連接并組合賦名資源去實現負載的體系結構和任務執行方式.例如,MR算禮在機群上提供job,tasks的master-slave architecture,以及map-shuffle-reduce三階段執行方式.
3) N是賦名資源(named abstractions of resources),為算禮提供模塊化的賦名資源和抽象接口.例如,MR算禮提供了機群節點資源抽象和HDFS分布式文件系統資源抽象.
4 算禮實例
4.1 實例1:啟發計算系統猜想
云計算系統中各類無序現象(稱為計算系統熵),使得用戶體驗和系統效率2個目標難以被同時滿足.我們提出下一代云計算系統的目標,稱為“低熵云計算系統”[16],要求多個應用負載在數據中心計算機上執行時,既能保證用戶體驗,又能提高系統利用率.
能否抽象出低熵云計算系統的主要性質?具備什么能力的系統才能同時滿足用戶體驗和系統效率2個目標?為此,我們定義了“實用可計算性”(pro-duction computability)來刻畫系統實現用戶體驗和提高系統效率的能力,并提出了實現“實用可計算性”的充分必要條件的猜想,稱為DIP(distinguishing, isolation, prioritizing)猜想.從算禮的黑箱表示看,低熵云計算系統需要考慮3個難題.
1) Problem:低熵云計算系統應該解決什么問題?
對于傳統的資源獨占式分區云和共享式的虛擬化云,前者能很好實現負載的用戶體驗,但是系統效率較低;后者理論上支持更高的系統效率,但是卻影響了特定負載的用戶體驗目標.
我們認為“難以同時滿足用戶體驗和系統效率”難題的本質是無序現象.特別地,針對負載干擾的無序現象,由于共享資源的競爭導致了系統的內耗,資源的共享呈現互相的抑制和搶占,既影響了負載的資源保證,也會降低系統的效率.
所以,低熵云計算的主要問題是“在共享式的云計算系統中,如何實現應用負載間的有序共享(減小干擾造成的無序影響),在保障特定負載的用戶體驗的基礎上,提高系統效率”.
2) Principle:解決這些問題主要原理是什么?
云計算系統需要克服無序性影響,保障負載的用戶體驗的基礎上,提高系統效率.顯然,這不只是特定負載有關的性質,而是云計算系統本身的能力:使得負載之間有序共享資源的能力.
我們不妨將云計算系統中的共享資源(時間資源、計算資源、存儲資源和通信資源)組成一個四維空間,稱為計算時空(cyberspacetime).那么,降低計算系統熵,或者實現負載的實用可計算性的主要原理是時空共享,即多個負載在總線周期粒度有序地共享計算時空,有利于同時保障用戶體驗和資源利用率.
3) Properties:低熵云計算系統具備什么新的性質才能實現計算時空的有序共享?
我們提出了實現實用可計算性的充分必要條件的猜想,稱為DIP猜想:如果應用負載A是實用可計算的,那么在給定用戶體驗閾值的前提下,云計算系統S實現A的實用可計算性,當且僅當S具備DIP能力.
這3點能力是:區分(distinguishing, D)、隔離(isolation, I)、優先化(prioritizing, P).也就是說,該云計算系統能夠在運行時動態地區分、隔離、優先化負載A在系統S的計算時空中執行的相空間.云計算系統具備的3點能力,亦可作為系統的3個性質,即可區分性、可隔離性、可優先化性.
這3個性質的本質是限制云計算系統中的無序影響.無序行為會一直存在,無法徹底消除.但通過系統創新限制住無序的影響范圍,從而使計算任務的尾延遲滿足用戶體驗閾值,還是有可能的.
4.2 實例2:啟發新并行計算模型
我們提出了分形馮·諾依曼體系結構[17],一種同構、串行編程、層次化且層次同性的新體系結構.實驗表明,具有分形馮·諾依曼體系結構的計算機Cambricon-F在機器學習領域能夠解決編程難題,同時性能不弱于目前最先進的GPU系統.但是Cambricon-F僅針對特定領域應用負載、采用了特定的體系結構.我們能否拓展分形馮·諾依曼體系結構的原理,使它能夠解決通用領域、廣泛的現有體系結構上的編程難題呢?我們通過提出一種新的并行計算模型“分形計算模型”來實現這一目標,而算禮思想要求我們首先回答黑箱表述的3個難題分別是什么.
1) Problem:需要解決的“編程難題”究竟是什么?
目前并行計算模型既有注重于算法分析的理論模型(例如BSP[9],Multi-BSP[18],LogP[19],PRAM[20]),又有注重于編程實現的實用模型(例如MPI[21],OpenMP[22]).然而,現有通用并行計算模型都是并行編程、并行執行(parallel code, parallel execution, PCPE)的.通常我們認為并行編程比串行編程更為困難,因為并行編程需要額外考慮多條執行流之間的同步、通信等問題.
為了簡化編程,我們需要實現串行編程、并行執行(sequential code, parallel execution, SCPE)——使用者只編寫串行執行的程序,卻可以并行、高效地執行在并行計算系統上.如果在分形計算模型上,編程與系統的規模無關,那么無論系統的規模如何,其編程都與在規模最小的系統(即僅具有單一計算節點的串行系統)上同樣簡單,即可實現SCPE.
并行編程的復雜性,本質來源于并行計算模型具有的編程-規模相關性(programming-scale variance):當系統規模發生變化時,程序需要重新調整才可保持最優地執行.因此,難題是如何設計分形計算模型,使其具有編程-規模無關性(programming-scale invariance).
2) Principle:解決問題的主要原理是什么?
分形計算模型解決問題的主要原理與分形馮·諾依曼體系結構相同,都是通過將系統刻畫為層次同性(isostratal)的層次結構,使系統在不同尺度上具有相同形式的硬件資源抽象、任務負載抽象和執行行為抽象,因此可以做到根據單一層次結構的刻畫對系統規模進行任意的擴展.
3) Properties:我們希望分形計算模型具備什么新的性質?
通用性.我們希望分形計算模型是一種具有通用性的并行計算模型,即能夠廣泛、高效地支持各種可以并行計算的算法.
效率-規模無關性.我們希望分形計算模型的效率不會因系統規模擴展而漸進降低,只有如此,任意擴展系統規模才具有實用意義.
編程-規模無關性.分形計算模型是一種串行編程、并行執行的計算模型,用戶無需編寫并行程序,即可由分形計算模型自動地展開至任意規模的系統上并行執行.
4.3 實例3:拓展現有體系結構
REST體系結構風格支撐了PC互聯網與移動互聯網應用.能夠進一步將REST拓展到智能萬物互聯網嗎?我們的回答是肯定的,并將拓展后的體系結構風格稱為T-REST(representational state transfer for things)[23],如圖3所示.從算禮的黑箱表示看,T-REST需要考慮3個難題.
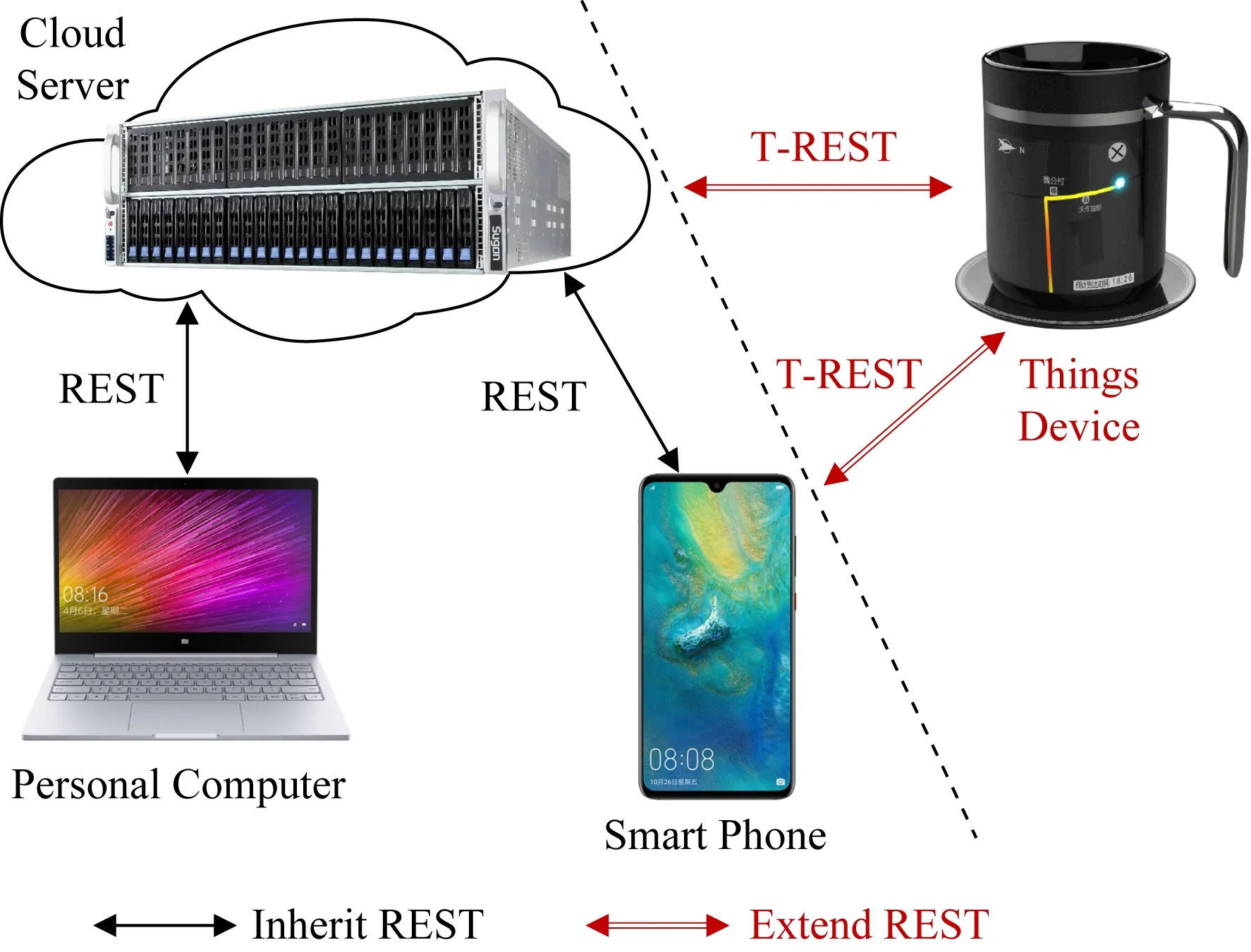
Fig. 3 Transition from PC Internet to mobile Internet only needs to inherit REST; Transition from mobile Internet to IoE needs to extend REST圖3 從PC互聯網過渡到移動互聯網只需繼承REST;再過渡到智能萬物互聯網需要拓展REST
1) Problem:T-REST架構風格應該解決什么問題?
我們的研究表明,主要問題是:“物端設備應該是WWW客戶端還是WWW服務器端”這個client vs. server問題.當PC互聯網過渡到移動互聯網時,智能手機繼承了REST Web,主要思路是將PC上的WWW瀏覽器適配到智能手機的WWW瀏覽器和APP.這是合理的選擇,因為PC機和智能手機都是人端設備,主要與人交互.但是,在智能萬物互聯網中,物端設備(不論是固定的還是移動的)主要與物理世界交互,包括傳感(sensing)與致動(actuating).物端設備是數據源和制動器,這是服務端的特征.物端設備主要是server,而不是像PC機或智能手機那樣的Web client.因此,難題是如何將原本在云端的WWW服務能力有效遷移到物端設備.
2) Principle:解決這些問題的主要原理是什么?
T-REST的核心原理是將超文本(hypertext)和超媒體(hypermedia)拓展為超任務(hypertask),提供服務端按需代碼(server-side code on demand)能力.
3) Properties:T-REST體系結構風格具備什么新的性質?
T-REST主要有2個性質,即2種新的體系結構原則,即計算超文本(computational HyperText, cHT)和可復用遠端求值(reusable remote evalua-tion, RREV),它們合起來提供服務側按需代碼(server-side code on demand)能力[23].
計算超文本原則.我們提出一種具體的新概念,稱為計算超文本,去實現超任務.超任務就像超文本(hypertext)和超媒體(hypermedia)一樣,也由URI超鏈接指向,通過傳統的REST協議調用.引入超任務不違反“hypermedia as the engine of application state”的REST基本原則,但將超媒體的內涵從數據內容拓展到了任務代碼.
可復用遠端求值原則.一旦一個超任務被成功部署到某個云端或邊緣端設備上,它就自動變成了一個Web資源和Web服務.該服務不是一次性的,而是具有持續復用的特點.例如執行HTTP方法“PUT http://edge.things.ac.cn/recognition_result recognize.cht”將超任務recognize.cht部署到邊緣服務器edge上,并自動生成一個全球可訪問的RESTful資源與服務,其URI為http://edge.things.ac.cn/recognition_result.
4.4 實例4:啟發新的系統評價方法
物端設備通常是資源受限的計算系統,在評價物端計算系統性能時,不能僅考慮基準程序的執行性能,還需要考慮每類負載對物端計算系統的資源利用效率.為此,我們提出了資源服務效率(resource serve efficiency, RSE)匹配模型和歸一化的匹配度量,用于評價物端計算系統性能.從算禮的黑箱表示看,RSE匹配模型需要考慮3個難題.
1) Problem:RSE匹配模型需要反映的性能指標具體是什么?
傳統的計算系統性能評價方式是將每個基準程序的測試結果進行幾何平均得到系統性能的量化指標.而設計物端計算系統時,在保證特定負載的執行性能的同時,還會考慮盡量減少負載對資源的占用,則物端計算系統的評價方法也應該將資源利用效率考慮至性能評價模型中.因此,難題是如何使用一個量化指標同時反映負載執行性能和系統資源利用效率.
2) Principle:解決問題的主要原理是什么?
RSE匹配模型解決問題的主要原理是使用“木桶原理”對每個資源針對負載的服務效率進行加權平均,從而獲得系統-負載的匹配度量化指標.資源服務效率即為單個資源在不同利用率下負載執行性能曲線的積分;“木桶原理”的量化表達即為匹配度較低的資源代表系統的性能瓶頸,則其對系統-負載的匹配度應占有更高的計算權重,反之亦然.
3) Propertie:RSE匹配模型具備什么性質?
歸一化的性能度量.RES匹配模型提供的系統-負載的匹配度指標以及每個系統資源分量的匹配度指標均是歸一化的形式.歸一化的性能量化指標為物端計算系統提供橫向比較的基準,同時也為系統和負載性能優化給出了理論的性能優化上界.
反映系統性能瓶頸.負載和系統的匹配度指標可以對系統性能進行整體量化,而每個系統資源分量的匹配度指標則可以揭示出針對特定評測程序系統存在的性能瓶頸,為系統和負載性能優化提供方向.
我們在智能網聯車計算系統基準測試程序集CAVBench[24]中提出了RSE匹配模型一種具體的量化計算公式,使用該計算公式本文給出一個具體的優化實例:在物端計算系統Intel FRD[25]上使用深度學習框架TensorFlow1.12運行目標檢測算法SSD[26],得到系統的CPU利用率、內存帶寬、內存腳跡資源與負載的匹配度分別為0.08,0.14和0.23,計算可得該系統與SSD負載的匹配度為0.15,負載實際執行性能為2.5 FPS;RSE模型指出了CPU資源為該系統在執行SSD負載時的性能瓶頸,則使用TensorFlow的SIMD指令編譯優化,優化后CPU利用率、內存帶寬、內存腳跡資源匹配度分別為0.18,0.22和0.38,系統與SSD負載的匹配度則提高至0.25,SSD負載實際執行性能提高至4 FPS.
5 結 論
針對計算機系統結構領域的多樣性趨勢和挑戰,本文指出需要研究計算系統的可分析抽象,即在原型測試前就能分析出計算系統本質特征的學術抽象.針對計算系統可分析抽象,本文歸納3個初步結論.
1) 繼承算法的7條優點.本文回顧了Donald Knuth的五特征算法定義及其帶來的算法的7條優點,并倡導計算機系統結構領域應該學習算法領域的成功經驗,研究計算機科學的一個新概念:算禮.算禮是簡潔刻畫計算系統本質特征的可分析抽象,其目標是使得計算系統研究具備算法的7條優點,能夠超越原型系統構建和基準程序測試,提升計算系統研究的效率.
2) 學習系統研究的6條經驗.本文總結了6條歷史經驗,它們建議了計算系統抽象應該考慮的研究方向和目標:①高效接口,使得應用設計容易1 000倍;②刻畫系統本質特征的高級設計,尤其是對Tony Hoare觀點的修改:Inside every large com-puting system, there is a small computation protocol trying to get out;③刻畫系統本質特征的定量公式;④刻畫系統本質特征的定性定理;⑤真實應用與真實系統之間的橋接抽象模型;⑥覆蓋多種真實系統結構的體系結構風格.
3) 以PEN刻畫為特點的算禮思想有助于啟發計算系統研究.本文提出了算禮的一個初步定義,即(負載,執行模型,賦名資源)刻畫,簡稱為PEN模型.一個算禮可由它所支持的應用負載(payload)、執行模型(execution model)、賦名資源(named abstr-actions of resources)三元組刻畫,并有只考慮P的黑箱表示以及考慮PEN全體的白箱表示.我們討論了4個算禮研究實例,即低熵云計算系統的DIP猜想、分形并行計算模型、萬物互聯系統的T-REST架構風格、智能物端系統的性能匹配度模型.
這些實例和歷史經驗表明:與算法抽象相比,計算系統的可分析抽象研究還處于起步階段,有不少研究問題和機會;算禮思想有助于在計算系統領域啟發新的猜想、新的計算模型、新的架構風格、新的系統評價度量.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
數學物理學報(2020年2期)2020-06-02 11:29:24
中華詩詞(2019年7期)2019-11-25 01:42:50
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
中國音樂教育(2017年5期)2017-05-18 09:59:56
