一種基于卷積神經網絡的自動問答系統
2020-06-06 06:30:28敬思遠
樂山師范學院學報 2020年4期
楊 駿,敬思遠,項 煒
(1.樂山師范學院 計算機科學學院,四川 樂山 614000;2.互聯網自然語言智能處理四川省高等學校重點實驗室(樂山師范學院),四川 樂山 614000)
0 引言
隨著互聯網技術的發展,人們需要從網絡上獲取越來越多的信息。但是,要從浩瀚的數據海洋獲取所需的準確信息,有相當大的難度。人們常常通過搜索引擎查找來獲取信息,但這種方式存在三個問題[1]:相關結果太多,用戶篩選困難;檢索技巧要求較高,用戶難以提供精準的檢索依據;搜索引擎的語義理解能力不足,導致檢索結果不夠理想。自1965年R.F.Simmons[2]首次提出“自動問答”的概念以來,許多研究人員在這方面做了大量探索,如美國、法國、德國、新加坡等國的研究者在開放領域[3]和各個受限領域[4-6]都進行過不斷嘗試。因為基于搜索引擎的檢索方式存在問題,學者們便開始了對基于知識工程的檢索方式的研究。知識工程通常包括知識創建、知識識別、知識存儲、知識共享、知識使用、知識學習和知識完善等環節[7]。隨著機器學習和深度學習的興起,卷積神經網絡被廣泛應用于各領域,如自然語言處理、圖形圖像處理、音頻視頻處理等,用于自動問答系統就是其在自然語言處理中的典型應用[8-9]。
本文結合搜索引擎和卷積神經網絡等技術,架構一個可以實現交互式和異步請求的自動問答系統,可以應用于開放領域或受限領域,以提高用戶信息檢索的準確性和檢索效率,改善用戶體驗。
1 相關技術
1.1 中文分詞
詞或詞語,是某種語言中有意義的、能單獨用來構造句子的最小單位。中文分詞,就是將一個中文句子按照中文語法結構,分解為單個獨立的詞語的過程。1993—2003年間,中文分詞的研究有了長足發展[10]。分詞方法主要包括詞典分詞、理解分詞、統計分詞和組合分詞等[11]。分詞的結果并不是穩定不變的,而是會受到訓練語料所屬領域和未登錄詞語的影響,所以,跨領域的分詞研究也有著重要的意義[12]。中文分詞的效果一般采用召回率(Recall),即精確率(Precious)和調和均值(F1-Meature)等指標[10]進行評價。“結巴”(jieba)分詞[13]是一個開源的中文分詞組件,支持三種分詞模式:精確模式、全模式和搜索引擎模式。對于未登錄詞語,采用了基于漢字成詞能力的HMM(Hidden Markov Model,隱馬爾科夫模型)和Viterbi算法進行分詞。該組件還提供了多語言(Java、C++、Python、Rust、PHP、Go等)和跨平臺(iOS、Android等)版本,可以方便地進行語言切換和平臺切換。
1.2 AIML
AIML(Artificial Intelligence Markup Language,人工智能標記語言)是聊天機器人ALICE (Artificial Linguistic Internet Computer Entity)采用的知識描述語言,這款機器人最早是在1995年由美國Richard S.Wallace博士開發的[14]。AIML語言完全兼容XML語言,核心知識單元由一個或多個分類(category)組成,每一個分類代表了一個人機交互的會話,包含用戶輸入、機器回答和上下文環境三部份。不過,由于AIML語言設計之初就是基于西方語種的,因此處理中文時會存在一些問題,文獻[14]提出了一種有效的解決辦法。
1.3 卷積神經網絡
卷積神經網絡(Convolutional Neural Networks, CNN)是一種特殊的前向神經網絡,包含輸入層、隱藏層和輸出層[15-16]。
1.3.1 輸入層
輸入層通常是一個多維張量,0維張量即標量,一維張量是向量,二維張量是矩陣等。最常見的輸入有一維的向量(如字符串或音頻數據)和多維張量(如圖像位圖數據通常是二維矩陣或三維數組)。輸入層代表了需要被處理的數據,一般會先進行歸一化處理,有利于提高運算效率。
1.3.2 隱藏層
隱藏層是卷積神經網絡的核心層,也稱為處理層或運算層。隱藏層包括一個或多個卷積層和池化層的序列,以及一個全連接層。卷積層通過內部的卷積核,提取輸入數據的特征值;卷積核的參數包括核大小、步長和數據填充,特征值提取后的數據尺寸大小由卷積核的步長決定。池化層將卷積層提取的特征值進行壓縮(下采樣),不僅可以降低數據的空間尺寸,減少模型參數,降低計算資源消耗,還可以避免過擬合;與卷積層相似,池化層的參數包括池化窗口大小、步長和數據填充。全連接層對池化層的結果進行非線性組合計算,與傳統前饋神經網絡中的隱藏層作用相同。
1.3.3 輸出層
輸出層通常使用邏輯函數或像softmax這樣的歸一化函數得到隱藏層的分類結果。
2 系統架構
文章采用相關技術,構建了一個自動問答系統,其系統架構如圖1所示。
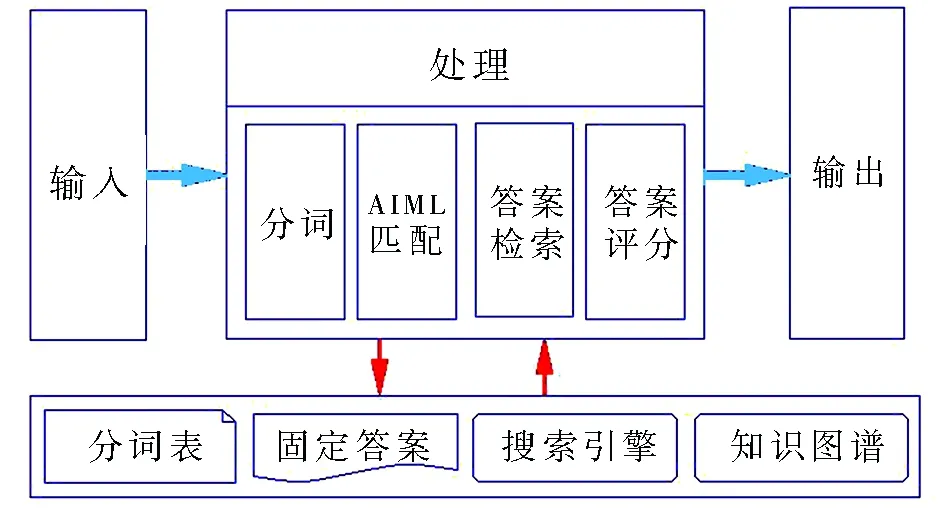
圖1 問答系統架構
系統流程分為輸入、處理和輸出。輸入表示用戶輸入的問題,處理部分通過對問題進行分詞、AIML匹配、搜索引擎檢索和答案評分等步驟獲得最終答案,并在輸出部分將其返回給用戶。系統所用資源包括分詞表、用于AIML匹配的固定答案,以及搜索引擎和公開的知識圖譜等。
3 系統實現
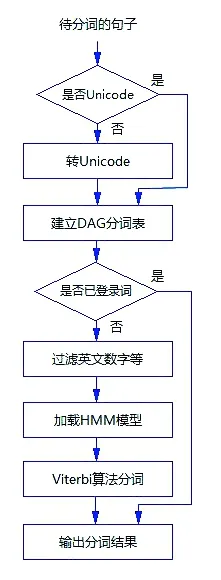
圖2 文本分詞流程
3.1 文本分詞
采用jieba進行分詞的工作流程如圖2所示。首先加載已登錄詞典,生成Trie樹(也稱字典樹或單詞查找樹)模型。待分詞句子先經過Unicode處理,然后建立DAG(Directed Acyclic Graph,有向無環圖)分詞表,計算全局概率,得到基于Trie樹的詞頻最大切分組合,找出句中的已登錄詞語。對未登錄詞語,采用基于漢字成詞能力的 HMM模型和Viterbi算法,通過動態規劃的方法獲得分詞和標注。
3.2 規則匹配
規則匹配采用AIML語言來實現常用的、不需要聯網搜索的問答。主要是AIML語料的構建,每個語料中包括一個或多個AIML分類(category)。一個典型的AIML分類示例如下所示:
該分類表示了一個有上下文的人機對話:
人:樂山怎么樣
機:你喜歡樂山美食嗎
人:喜歡(不喜歡)
機:很好,我給你推薦幾款最美味的(好吧,我猜你可能更喜歡樂山旅游)。
3.3 答案檢索
問題無法匹配規則時,需要聯網檢索答案。除了基于文本的答案外,還有百度知道、百度百科等之類的基于知識圖譜的結構化答案。結合這兩種方式,可以提供更接近用戶希望的答案,實現過程如圖3所示。
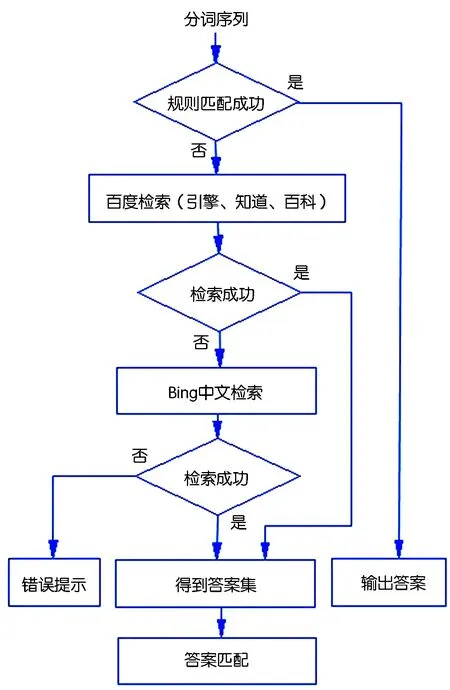
圖3 答案檢索流程
3.4 答案評分
對答案集進行評分和篩選,是最重要和最關鍵的步驟。對答案檢索階段得到的答案集,分別計算每個答案與問題的相關性,選取最好的答案。文獻[17-18]基于不同的應用,提出了不同的文本相似度和相關性的計算方法。本文采用A.Severyn[19]在2015年提出的一種基于卷積神經網絡的方法計算相關性,對答案進行評分,處理過程如圖4所示。
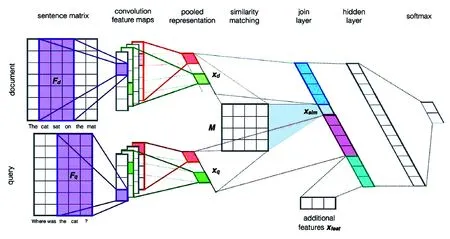
圖4 句子相似度卷積計算過程示意[19]
算法描述如下:
算法輸入:

算法輸出:
最佳答案和評分值(r,p),其中r∈D,0.0p1。處理過程:
a)假設所有模型參數均訓練完成(訓練過程的處理方法大致相同,這里主要描述評分操作,略過訓練過程),包括M,xfeat,分別表示訓練得到的相似矩陣參數和全連接層的附加特征參數,其他的如卷積核參數和池化窗口參數等略。
b)初始化變量,最佳答案r←null,最佳答案評分值p←0.0。
c)提取問句q的特征,卷積和池化操作計算得到問句的核心特征為xq。
d)FOR EACHd∈D
卷積和池化層:采用和c)相同的方法計算xd
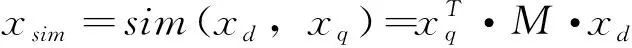
softmax層:px=softmax(xjoin)
IFp p←px r←d END IF NEXT FOR e)返回(r,p)。 圖5 系統運行效果 實驗硬件環境為Intel Core i7-3630QM處理器,8GB內存,軟件環境是Ubuntu16.04操作系統,Python 2.7。經測試,如果用戶提出的問題是基于AIML規則的,響應基本沒有延時;實驗了1 000次網絡請求,無論是基于百度搜索引擎、百度百科、百度知道還是Bing搜索引擎,響應延時基本在1~3 s。這個響應有明顯延遲,用戶體驗還不夠理想,不過,在要求不嚴格的環境下,基本也可以應用。系統運行效果如圖5所示。 隨著互聯網技術和人工智能技術的高速發展,計算機將為人們提供更多、更優質的服務,自動問答技術將在各個領域發揮明顯的作用,尤其是在傳統的人工客服領域。在旅游領域,自動問答系統可以為游客提供更及時、詳盡、專業和貼心的服務,這樣既能提升城市的服務水平,還能提升城市發展的科技含量。在以后的研究中,需要著重解決兩個問題:進一步改善問與答的相似度計算,以求得到更精準的答案;設法解決響應延時的問題,爭取提升到毫秒級別,進一步改善用戶體驗。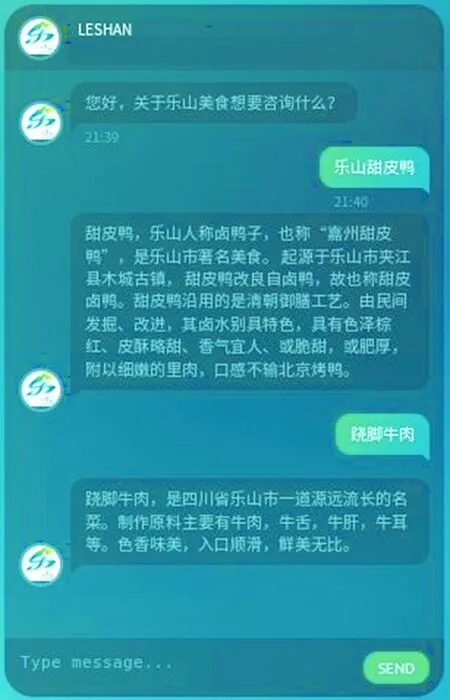
3.5 系統測評
4 小結
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
家庭影院技術(2017年9期)2017-09-26 03:41:45
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國衛生(2015年12期)2015-11-10 05:13:38
創業家(2015年5期)2015-02-27 07:53:25
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
