基于數據挖掘和互聯網評論探索貧困地區的景點特點
2020-05-23 15:32:06鄒冠如羅毓麟
科學導報·學術 2020年67期
鄒冠如 羅毓麟


【摘 要】為了促進貧困地區旅游業的發展,本文通過網絡爬蟲獲取到景點評論數據,通過文檔向量化方法Doc2Vec生成文本向量,應用改進后的基于歐幾里得距離的聚類算法K-mean將文本向量進行三個類簇的聚類,最后從三個類簇中獲取到評論的大文本,采用TextRank算法,對大文本中若干個句子進行打分排序,獲取到評分最高的句子,即評論大文本中最為核心的句子。
【關鍵詞】Doc2Vec;K-mean;TextRank算法
一、前言
隨著社會全面小康的時代的到來,作為人們休閑娛樂方式之一的旅游得到了飛速的發展,旅游越來越成為人們的一種時尚生活方式。而我國由于歷史和自然的原因,各地區之間和地區內部的經濟發展很不平衡,因此通過旅游產業帶動貧困地區的經濟發展是一項利于地區脫貧的一大措施。但是網上各種旅游平臺的信息量太大,不利于游客迅速抓到景點的亮點,對于貧困地區的景點來說更是如此。也正是如此,阻礙了貧苦地區的游客數量的增長。而事實上,大部分的貧困地區均具有優質的環境資源和廉價實惠的農產品。因此本文以河源五大為省級重點扶貧的特貧困縣之一的紫金縣的御臨門景區為案例,使用網絡爬蟲技術、數據挖掘技術和自然語言處理技術打造提煉景點特點模型,使得游客獲取到更多貧困地區的旅游景點信息,為自己打造更合適、性價比更高的旅游線路,并且帶動貧困地區經濟的發展,助其更快脫貧。
二、相關技術
1.網絡爬蟲
爬蟲技術是一種按照一定規則,自動抓取信息的程序或腳本[1]。我們可以在遵守網頁協議的前提上爬取到攜程網、美團網和大眾點評等的景點、酒店評論信息,為我們的綜合更全方面的評價提供了優秀的數據基礎。
2.數據挖掘
數據挖掘是使用現在的算法技術從數據獲取到數據的深層信息的探索過程。近年來,數據挖掘引起了各大行業的極大關注,其主要原因是存在大量去敏數據,可以廣泛使用,想要通過計算機和數學將這些數據轉換成有用的商業信息,產生數據的直接價值。
3.自然語言處理
自然語言處理是人工智能領域和計算機科學領域中的一個重要方向。它研究能實現計算機與人之間用自然語言進行有效通信的各種理論和方法[2]。通過特別的方法,讓計算機也能聽懂人類語言,這一技術在本文是至關重要的,計算依賴與計算機,而計算機則需要此項技術才能明白文本數據是在表達什么。
三、最具代表性的評論文本的自動提煉
1.基于Doc2Vec模型的句子向量化
Doc2Vec方法是一種無監督算法,能從文本(例如:句子、段落或文檔)中學習得到固定長度的特征向量表示。在Doc2Vec中,每一句話和每一個詞語都是唯一的向量,假設有兩個矩陣,第一個矩陣X的列表示的是文本中每個句子的向量,第二個矩陣Y的列表示的是每個句子的詞的向量。每次從一句話中滑動采樣固定長度的詞,取其中一個詞作預測詞,其他的作為輸入詞。將本句話的向量和本次采樣的詞向量相加求平均或者累加構成新的向量Z,Z便作為神經網絡輸入層的輸入神經元,進而使用向量Z預測此次窗口的預測詞[3]。
2.機器學習——K-mean算法
K-mean聚類算法具體過程如下:隨機選擇K個點作為初始聚類中心,將剩余的每個點按照距離分配給上述K個點,形成K個類簇。然后計算每個類簇的質心,并將其作為下一次迭代的聚類中心,直到滿足停止訓練的條件[4](例如函數收斂或達到最大迭代次數)。兩點之間的距離計算方式有歐幾里得距離、余弦距離、曼哈頓距離、切比雪夫距離、Jaccard相似系數等,本文采用歐幾里得距離計算方法計算文本與文本之間的相似度。
其中,和是表示文本,i和j表示文本的順序,n表示文本的向量維度。
傳統K-mean算法雖然具有簡單高效、可解釋性強的優點,但是K-mean聚類的效果和初始聚類中心(又稱重心)的選取密切相關,如果隨機選擇重心,容易使算法陷入局部最小值,無法收斂到全局最優。針對此項,本文做出了改進:通過多次數避免隨機選擇的隨機性,即是選用多次隨機初始化,計算每一次的成本函數,選取成本函數代價最小的初始點作為聚類結果。
3. TextRank算法概述
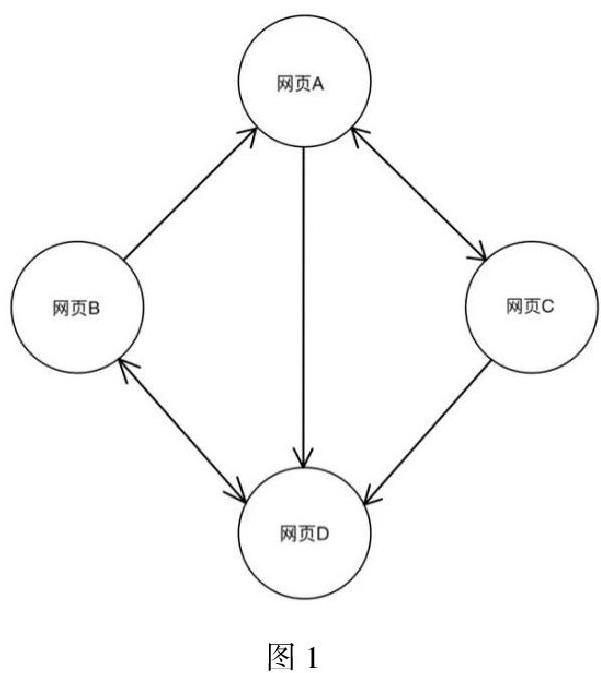
TextRank 算法是一種可以直接用來對文本進行排序的基于圖的排序算法,其基本思想來源于谷歌的PageRank算法。而PageRank算法的核心思想是網頁被更多的網頁指向連接,則證明此網頁更重要。如下圖,可以看到被網頁指向最多的是網頁D,所以在PageRank中,網頁D是比其他三個網頁更加重要的。
TextRank 采用的是投票打分機制,首先對文本進行預處理,按照詞項或者句子對基本單元進行分割,然后對預處理后的文本以項詞或者句子為節點構建圖模型,可以快速的實現對單個文本內容中的關鍵信息進行精確提取[5]。
TextRank 算法抽取摘要句的主要思想是通過對文本中句子進行打分排序,摘要抽取具體過程如下:
(1)預處理:將要構建的文本或文本集分割成句子=[,,...,],構建如圖2-2所示的圖,其中為句子集,為邊集,同時對句子進行分詞、去除停用詞等處理,得到=[,1,,2,...,,n],其中 是保留后的候選關鍵詞。
(2)句子相似度計算:構建圖中的邊集,邊的構建基于兩個節點的重疊信息,給定兩個句子和,根據以下公式進行相似度計算:
通過公式(1)計算得到兩個句子相似度,如果相似度大于提前設定的閾值,那么j句子i和句子j就含有相同的語義信息并且一條邊將兩個節點連接起來,邊的長度為兩個節點的相似度,相似度越大邊越長;
(3)句子權重計算:根據公式(a),迭代計算各句子的得分;
(4)抽取摘要句:將(b)得到的句子按照得分多少進行從高到低排序。
(5)形成摘要:按照一定的壓縮比(一定的長度或者字數)對排序后的句子抽取組成摘要[6]。
四、實驗過程
1.數據收集。本文爬取關于河源市景點的多個平臺的景點評論信息,如美團網、攜程網等,最大限度的整合同一景點的互聯網上的所有評論。
2.數據預處理。對爬取下來的數據進行格式上的清洗和整理。
3.向量化文本。使用Doc2Vec技術將每一個文本轉換為300維向量(參考谷歌網絡設置的維度)。
4.K-mean聚類。考慮到評價主要分為三個等級,分別是好、中和差,因此本文的目標是將向量化后的文本聚類成三個類簇,并且分別提出三個類簇的評論文本,做成三個拼接后不同族的大文本,為下面TextRank算法做好數據準備。
5.提取核心評價文本。利用第四步準備好的數據,使用TextRank排序技術對每一類簇的大文本進行打分排序,輸出每一個大文本的分數排名最高的評論作為三個該景點評論中最核心的三個評價。
五、實驗結果與分析
1.實驗結果
本文以貧困縣河源市紫金縣御臨門溫泉度假村為案例,爬取網上評論651條數據,使用python語言實現實驗,可以得到在改進后的K-mean聚類的三個類簇中,每個類簇最核心的評論分別為:
“我訂的是別墅、每個房間都有獨立的溫泉池,很方便,酒店環境很好,早餐我個人覺得很好,酒店位置有點偏,有大型停車場。”、“總的說來還是很好的,值得再去的溫泉,房間很衛生,周圍的環境也很好,這次唯一不好的就是安排的房間隔壁就是酒店工人的房間,還是有點吵,特別早上早早就聽到服務員在外面的聲音,還有早餐的種類不算多,還有待改進”、“酒店很不錯,溫泉的池子不少,房間設施也很好,前臺服務態度很熱情,早餐豐富,停車方便,就是往酒店的路比較爛”。
2.實驗結果分析
從上述三個核心評價來看,我們可以明顯的感受到紫金縣御臨門溫泉度假村整體還是不錯的,但是主要存在了兩個核心問題:第一是早餐的種類不夠多,不能滿足大部分人對這個價格的需求,第二是酒店對噪音的管制仍需繼續加強。
單從三個類簇中排名第一的評論觀察,對K-mean算法起到的重要性不夠明顯,所以我們分別從三個類簇中排名前三的評論再進行分析。
第0類族排名前三的分別是:
“我訂的是別墅、每個房間都有獨立的溫泉池,很方便,酒店環境很好,早餐我個人覺得很好,酒店位置有點偏,有大型停車場。”、“那天去到酒店已經晚上八點多了,很幸運的幫我們免費升級到別墅區,房間很大,因為是夏天,住店的人不是很多,當天晚上在房間里泡溫泉還不錯,第二天去公共溫泉區就實在太熱了,大太陽曬著水都太燙了,贊一下酒店的早餐送餐服務,按約定時間準時送到房間,而且都熱熱的,總體來說是很愉快的一次住店體驗。”、“酒店環境,服務,設施還可以,露天溫泉很干凈,下次還會再來。”。
第1類族排名前三的分別是:
“總的說來還是很好的,值得再去的溫泉,房間很衛生,周圍的環境也很好,這次唯一不好的就是安排的房間隔壁就是酒店工人的房間,還是有點吵,特別早上早早就聽到服務員在外面的聲音,還有早餐的種類不算多,還有待改進。”、“酒店雖然舊了些,但環境還是不錯,房價有點貴,早餐品種太少,是真溫泉。”、“訂的花園套房,感覺有點久,自費補差價住進了別墅房,環境很好,溫泉是真的溫泉,服務一般般,早餐品種不多,房間只有兩瓶水,叫送多一瓶礦泉水還要收費,2000一晚的房就顯得太小氣了,其他都還不錯。”。
第2類族排名前三的分別是:
“酒店很不錯,溫泉的池子不少,房間設施也很好,前臺服務態度很熱情,早餐豐富,停車方便,就是往酒店的路比較爛。”、“溫泉度假酒店算范圍大和位置好找地方,下了汕湛高速走十公里左右到了,環境舒適優美東南亞設計,有天然的溫泉溫眼,水質感好,房間設施齊全,早餐還算可以。”、“早餐沒有吃,睡床有點硬,前臺服務態度好,有問題都會幫忙解決,周邊餐廳很多,八刀湯棒棒,衛生還行,就是房間燈太暗,晚上房頂也沒有燈,看電視根本太暗了點,溫泉個別池還可以,有一些水都不太熱。”。
從上述評論中,可以明顯感受到每一個類簇表達的情感不一樣。
六、結束語
本文采用Dov2Vec將評論向量化,應用改進的機器學習算法K-mean進行三個類簇的聚類,最后使用TextRank算法對評論進行排序打分,得到每一個類簇最核心的評價文本,便于幫助游客從琳瑯滿目的互聯網旅游資源獲取到關鍵信息。通過應用數據挖掘和自然語言處理技術進行整合,更加有助于旅客根據自身需求和出行要求選擇更合適的景點和線路。同時有助于對擁有優質旅游資源的貧困地區通過旅游行業帶動自身經濟發展,走上脫貧大道,有助于商家根據核心評價,對自己的經營模式、服務質量和硬件措施等進行改進且一步提高,從而吸引更加多的游客前往游玩。
參考文獻
[1]孫建立,賈卓生. 基于Python網絡爬蟲的實現及內容分析研究[C]// 中國計算機用戶協會網絡應用分會2017年第二十一屆網絡新技術與應用年會論文集. 2017.
[2]王澤宇. 自然語言處理概述及應用[J]. 通訊世界,2019,26(04):309-310.
[3]徐馨韜,柴小麗,謝彬,等. 基于改進TextRank算法的中文文本摘要提取[J]. 計算機工程,2019,045(003):273-277.
[4]譚佩知. 基于K-MEAN算法的知識資源聚類研究[J]. 信息技術與信息化,2015,000(010):191-192.
[5]曹洋. 基于TextRank算法的單文檔自動文摘研究[D]. 南京大學,2016.
[6]張波飛. 基于LDA和TextRank相結合的中文多文檔自動摘要提取[D]. 內蒙古師范大學.
[7]于娟,劉強. 主題網絡爬蟲研究綜述[J]. 計算機工程與科學,2015,37(2):231-237
[8]JiaweiHan,MichelineKamber,JianPei,等. 數據挖掘概念與技術[M]. 機械工業出版社,2012.
[9]張奇,黃萱菁,吳立德. 一種新的句子相似度度量及其在文本自動摘要中的應用[C]// 第一屆全國信息檢索與內容安全學術會議. 2004.
作者簡介:
鄒冠如,2000年,男,本科在讀,專業:數據科學與大數據技術。
羅毓麟,2000年,男,本科在讀,專業:數據科學與大數據技術。
(作者單位:北京理工大學珠海學院)
