基于HBase的QAR數據存儲設計與實現
2020-05-23 10:06:54霍緯綱程文莉李繼龍
計算機工程與設計 2020年5期
霍緯綱,程文莉,李繼龍
(中國民航大學 計算機科學與技術學院,天津 300300)
0 引 言
QAR(quick access recorder)意為快速存取記錄器,是指帶保護裝置的機載飛行數據記錄設備。QAR數據涵蓋了飛機飛行操縱品質監控的絕大部分參數,具有時序性、容量大、參數多等特點,是典型的多維時間序列數據。目前,中國民航每一架飛機上都已安裝快速存取記錄器,用以記錄飛機包含的所有傳感器每秒鐘所產生的數據。據統計,一個中等規模航空公司每年產生的QAR數據量可達到PB級,甚至TB級。通過對QAR數據的有效存儲和分析,航空公司可以掌握公司航班飛行的安全動態,從而有針對性地加強安全監管,減少事故隱患,提高飛行品質[1]。
傳統的關系型數據庫在存儲海量QAR數據時存在性能瓶頸、數據組織模式單一、延時較高等諸多問題[2]。HBase[3](Hadoop database)是一個高可靠、高性能、面向列、可伸縮的分布式數據庫,數據模式簡單、靈活、存儲速度快、擴展性高。文獻[4-7]將HBase數據庫分別應用于智能交通、船舶自動識別、云智能室內環境監測、生物DNA與蛋白質對等領域,都驗證了HBase作為海量數據存儲的可靠性。但根據QAR數據的特點和應用場景設計基于HBase的存儲模式和行鍵結構至關重要。根據HBase中的數據寫入及存儲特點,如果僅按照快速存取記錄器的采集時間作為行鍵,雖然從一定程度上能夠保證查詢效率,但在數據寫入時,集群會出現熱點問題,造成較大的寫入延遲。另外,QAR數據參數眾多(維數高),需設計合理的HBase表結構,以滿足航空公司對QAR數據分析的查詢需求。本文設計實現了一種基于HBase的QAR數據存儲模式。該存儲模式能夠較好滿足航空公司分析飛行超限事件的業務需求。將QAR數據劃分為七大主題,設計了基于主題優化策略的行鍵,并采用了預分區技術,避免了寫熱點問題,使QAR數據能均衡地分布在集群中。
1 相關工作
HBase作為時間序列數據的存儲介質在工業領域中有著廣泛的應用。文獻[8]從不同角度探討、設計了行鍵結構,并通過二級索引改善了HBase的查詢效率,但隨著RegionServer(HBase集群中的從節點)中的Region(HBase中數據存儲和管理的基本單元)發生split(分裂)操作,其索引結構需要不斷更新,帶來更新延遲;文獻[9]通過采用MySQL和HBase存儲地震業務需求的結構化數據和非結構化數據,非結構化數據采用基于列簇級別的大對象對文件形式的數據進行管理,對小文件數據的存儲有較好的效果;劉博偉等[10]對于金融的時序數據的存儲:該系統采用了異步機制的時間驅動的Netty中間件,對高并發事務有較好的處理性能,設計了基于HBase的行鍵優化策略和基于時序數據的表設計策略,在一定程度上解決了HBase存儲熱點問題以及數據存儲的分散問題;陸婷等[11]利用多源緩沖結構對不同類型的流數據進行隊列劃分,結合一致性哈希、多線程技術、行鍵優化設計策略將數據存入HBase,實現了多源數據的存儲性能的提升,具有良好的擴展性能;王遠等[12]針對海量智能電網數據的存儲,提出以策略驅動的基于HBase的時序數據存儲方法,在OpenTSDB中實現了數據分散存儲同一時間產生的數據,提高了數據加載時的I/O能力和查詢分析能力,但只適用于數值型數據,存在一定的局限性;Ochiai H[13]等設計了基于HBase的樓宇設備信息管理系統,收集某棟大樓內的光照、暖通等設備傳感器的數據進行存儲。基于非關系型模型的QAR數據存儲研究工作相對較少,馮興杰等[14]設計了基于Hive的數據倉庫的構建:通過對Hive特點及QAR數據結構分析,設計了基于Hive的QAR數據倉庫的存儲結構,該設計更適用于分析型應用,無法滿足具有低延遲要求的QAR操作型應用需求。本文在上述工作基礎上,根據QAR數據特點,設計實現了基于HBase的QAR數據存儲模式,實驗結果表明該存儲模式具有良好的存取性能。
2 數據存儲模式設計
2.1 參數主題劃分
經過與領域專家討論,將航空公司所關注的問題按主題對QAR數據進行劃分,歸納為以下主題:安全分析主題、航跡描繪主題、節省燃油主題、發動機狀況主題、預測主題、飛行員操作分析主題和其它主題。主題與QAR參數的對應關系見表1。

表1 參數主題劃分
2.2 QAR數據存儲設計
2.2.1 HBase表結構設計
經譯碼后的每個QAR文件包含飛機的航班信息、參數信息、參數值3部分,所以文中將每個QAR文件中的數據劃分為航班元信息、參數元信息和參數值3類。根據QAR文件中的數據類別和超限事件分析需求設計了4張表,分別是航班元信息表Flight_info,參數元信息表Para_info,航班參數索引表Index和數據值表Value。
Flight_info表的行鍵為航班號與日期的組合。該表包含一個列簇Flight_CF,列簇中的列分別為航空公司、機尾號、起飛時間、落地時間、起飛機場、落地機場、航班序列號,其中航班序列號對應每個QAR數據文件唯一編號,記為fid。Flight_info表的表結構見表2。

表2 Flight_info表結構
Para_info表以參數名稱作為Para_info表的行鍵,該表包含一個列簇Para_CF,該列簇包含參數的簡稱、單位、所屬主題、序列號。根據2.1節中的參數主題劃分確定參數的主題,記為topic,由每個參數的采集順序生成一個唯一的參數序列號,記為pid,其結構見表3。
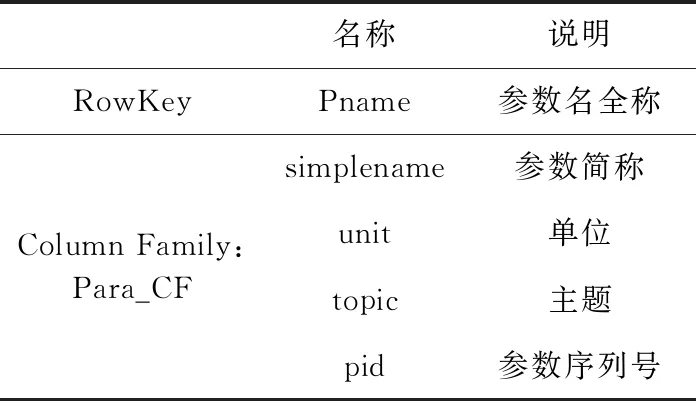
表3 Para_info表結構示意
Index表相當于下文Value表的索引,該表共包含兩個列簇:Index_CF1和Index_CF2。該表的行鍵為航班號、航班日期、參數名三者的組合。Index_CF1列簇包含一個列,該列將Flight_info表的fid與Para_info表的pid進行組合,記為paraid;Index_CF2列簇中包含一個列,該列存儲Index_CF1:paraid對應的航班號、日期及參數對應主題名三者組合的MD5值的前四字節,即Value表行鍵的前四字節,記為md5。Index表的結構見表4。
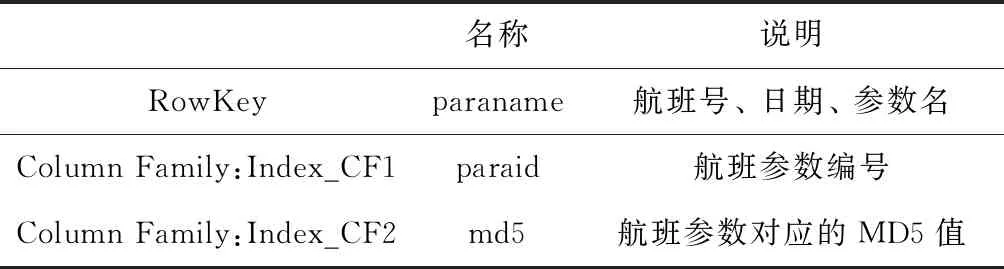
表4 Index表結構
Value表負責存儲QAR文件中參數的時序數據值,每行存儲一個航班文件中一個參數在一分鐘內的數據。該表的行鍵設計參見2.2.2節的詳細說明。除行鍵外,Value表包含一個列簇Value_CF,該列簇包含60列,分別存儲QAR參數一分鐘內每秒的數據值,列名即為秒數,其表結構見表5。
2.2.2 Value表行鍵設計
根據QAR參數的主題劃分及2.2.1節HBase表結構
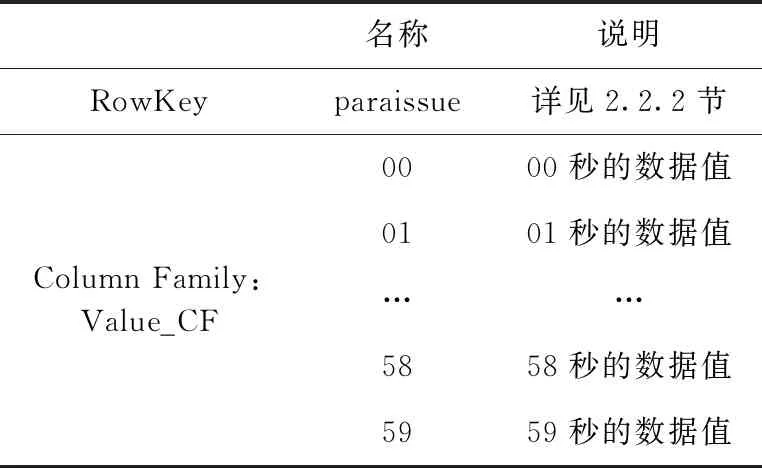
表5 Value表存儲結構
設計對Value表的行鍵結構進行了設計,其結構如圖1所示。Value表的行鍵設計中包含了以下信息:航班號、航班日期、參數及參數所屬主題、參數取值對應的時間。由于在設計行鍵時應保證行鍵的長度應盡量短,盡可能占用較少的存儲空間,本文設計行鍵長度為16個字節,行鍵的前4個字節內容計算方式為:航班號、航班日期及參數主題進行組合,采用MD5散列方法對該組合進行處理,取散列值的高四字節作為行鍵的高4字節內容。行鍵的中間八字節取Flight_info表的fid和Para_info表的pid序列號組合。低四字節取參數采集的時間中的小時、分鐘位。

圖1 Value表行鍵結構
現以2017年7月19日的某航班的名為GROUND SPEED的參數在4∶46分的數據為例說明Value表行鍵結構及數據存儲形式。該航班的fid為0018,參數的pid為0179,將時間4∶46以0446表示,將一分鐘內的數據存入Value表,其存儲形式如圖2所示。

圖2 行鍵計算
2.2.3 預分區設計
HBase在創建數據表時同時創建一個沒有起始和終止行鍵的Region,數據按照鍵值對的字典序升序向該Region中寫入,隨著寫入數據的增多,當HBase中的Region達到閾值,會頻繁觸發Split操作。這種原始的寫入機制會產生熱點問題,并且split操作也會消耗集群的I/O資源。本文在2.2.2節基于MD5散列行鍵設計的基礎上,采用預分區策略,以進一步提高集群讀寫性能。具體分區策略如下:
取散列值的前兩個字節作為預分區的splitKey。MD5散列值的前兩個字節的取值范圍是00~ff,假設擬劃分m(m為整數)個分區,將00~ff范圍內的候選splitKey從1開始進行編號,按照如下方式初步確定預分區的splitKey,第n個region的切分鍵的序號產生方式如式(1)所示

(1)
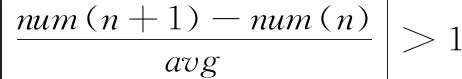

(2)
其中,x的取值如式(3)所示
(3)
最后,根據得到的預分區結果生成二維字節數組splitKeys,創建預分區的Value表。
2.3 存儲及查詢過程實現
2.3.1 QAR數據存儲實現
下面按2.2.1節設計的表結構說明QAR數據的存儲過程。其中Flight_info表與Para_info表、Index表的存儲原理類似,現以Flight_info表的存儲過程為例描述。文中將所有譯碼后的QAR數據文件的路徑記錄在文本文件file_path.txt中,通過讀取file_path.txt文件中的路徑打開QAR文件,然后解析具體QAR文件的表頭第一,二行內容,生成Flight_info表對應的航班元數據信息。其中航班號為航空公司二位代碼和航班序號組成,航班日期按格式yyyymmdd進行提取,機尾號為字母“B”加數位阿拉伯數字構成,起落地機場為機場四字碼,起落地時間為12小時制,以AM與PM區分日間或夜間。在讀取QAR文件的路徑時,記錄該路徑所在位置,生成4個字節的數字序列號,將序列號賦值于fid。將QAR文件表頭與Flight_info表相關的數據以Put(List

圖3 Flight_info等表數據存儲流程
首先,創建List
Value表存儲QAR文件的參數值部分。首先,每100行為一組讀取QAR文件的數據部分。對于每組中的數據按照參數維進行處理,取每行的參數采集時間切分為時分數據和秒鐘數據,按2.2.2節的行鍵設計方式組織行鍵,并創建對應的Put對象,以秒鐘數據作為Value表的列名,將每分鐘的數據列添加至Put對象中,將該Put對象添加至Put列表對象中,最后提交到數據表,完成該組參數的數據值存儲,再進行下一組數據的存儲。
Value表數據寫入
Input:file_path
Output:void
if(count% 100)then//每100行數據進行處理
batch←List
forjfrom0tothirdlenthen//從參數維進行循環處理
forkfrom0to100then//以讀取到的100行為循環對數據進行處理
mintim←time(k).subString()//將時間的子字符串的時分數據截取
sectime←time(k).subString()//獲取時間字符串的秒數數據
rowkey←md5+fid+pid(j)+mintime//組合為Value表的rowkey
qualifier←sectime//以秒鐘時間作為列名
value←value[k][j]//將數據部分的參數值作為value值
put←Put(rowkey)//以rowkey創建Put對象
put.addColumn(CF,qulifer,value)//將鍵值對添加至對應行的put對象
batch.add(put)//將Put對象添加到列表中
endfor
endfor
table.put(batch)//將Put列表提交到對應表
endif
2.3.2 數據查詢實現
定義f、p、t1、t2分別代表航班號、參數名稱、起始查詢時間、終止查詢時間,飛行品質監控分析中典型的查詢條件表示為q(f,p,t1,t2)。 例如2017年7月19日航班號為AB2834的航班,k時間在12:34到12:36的地速GROUND SPEED取值查詢表示為q("AB283420170719","GROUND SPEED", "1234","1236")。 現以該查詢為例說明文中的QAR數據查詢實現過程,具體如下:
首先,根據查詢參數f="AB283420170719"、p="GROUND SPEED"、t1="1234"、t2="1236",將查詢條件按照index表的行鍵結構進行組織,得到index表的rowkey="AB283420170719GROUND SPEED",通過行鍵過濾器獲取到index表對應的paraid列值:“00180179”和md5列值:“c9c6”;然后,將兩列值組合得到Value表行鍵的高十二字節。其次,將查詢的參數的時間范圍添加至Value表行鍵的低四字節,得到查詢Value表的行鍵范圍:"AB283420170719GROUND SPEED1234"~"AB283420170719GROUND SPEED1236";設置二級過濾器,分別以GREATER、LESS對Value表進行過濾;最后,創建掃描器對象,將二級過濾器添加至掃描器對象,返回查詢結果。其它飛行品質監控的查詢場景如單值查詢、基于參數主題的查詢等與上述查詢原理相似。
飛行品質分析典型查詢實現
Input:f,p,t1,t2
Output: result
table1←pool.getTable(“Index”)//通過連接池創建與Index表的連接
table2←pool.getTable(“Value”)
rowkey1←f+p//將查詢航班號、 參數名組合為index表的查詢行鍵
get←Get(rowkey1)//創建get對象
paraid←table1.get.addColumn(“paraid”)//從index表獲取paraid列
md5←table1.get.addColumn(“md5”)//從index表獲取md5列
startrowkey←md5+paraid+t1//將時間與md5、paraid組合為查詢起始行鍵
endrowkey←md5+paraid+t2//將時間與md5、paraid組合為查詢終止行鍵
setfilter1(GREATER,startrowkey)//對起始行鍵按GREATER指定過濾器1
setfilter2(LESS,endrowkey)//對終止行鍵按LESS指定過濾器2
filterlist←FilterList//創建過濾器列表,為多級過濾器指定通過方式
scan←Scan()//創建掃描器對象
scan.setFilter(filterList)//為掃描器對象設置過濾器列表
scanner←table.getScanner(scan)//在數據表上創建掃描器
result←scanner.next()//得到Result結果集,并輸出
3 實驗結果與分析
3.1 實驗環境設置
實驗數據為某航空公司2017年200個航段的QAR數據文件。實驗集群包含3個節點:一個主節點master和兩個虛擬從節點slave1、slave2。集群整體搭建在一臺內存為16 G、磁盤存儲空間為2 T的服務器上,服務器型號為Power-Edge T130。每個節點分配50 GB磁盤空間,1 GB內存,單核CPU。Hadoop集群的版本分別為Hadoop 2.7.3,Zookeeper3.4.10,HBase1.2.6。文中設置分區個數m為27,按照2.2.3節預分區設計方法,經過預分區的測試實驗,確定預分區的Splitkey為{1, 1b, 2a, 2f, 2z, 3b, 42, 4e, 5c, 65, 6f, 72, 7b, 80, 8f, 93, 9e, a6, ac, b4, bf, ca, d, df, f, fc}。集群中HDFS的復制因子設置為2。
3.2 QAR數據存儲分布實驗
實驗在QAR文件數量逐步遞增的情況下,驗證集群中QAR數據存儲分布效果。共設置了5個測試,每個測試使用的QAR文件個數見表6。實驗結果如圖4所示。
圖4中橫坐標表示測試的次數,左側縱坐標表示集群數據節點的數據量,右側縱坐標表示實驗過程中所用數據總量,單位均為GB。DN1、DN2表示集群的數據節點DataNode1、DataNode2,數據量圖例表示每次測試實驗的數據量大小。從圖中不難看出,集群的數據節點DN1、DN2

表6 實驗一數據
的數據量在各測試實驗中始終保持相對均衡,隨著數據總量的線性增長,各數據節點的數據增長也呈現相同的趨勢,各數據節點中存儲的數據量大小相差少于2%。本設計中,Value表的行鍵高位采用了哈希處理,使Value表中的數據分布具有更好的離散性,避免了數據寫熱點問題的發生。在行鍵的哈希設計基礎上,Value表采用預分區技術,共劃分27個分區,各數據節點上的數據分區數量相對均衡,避免了數據傾斜。
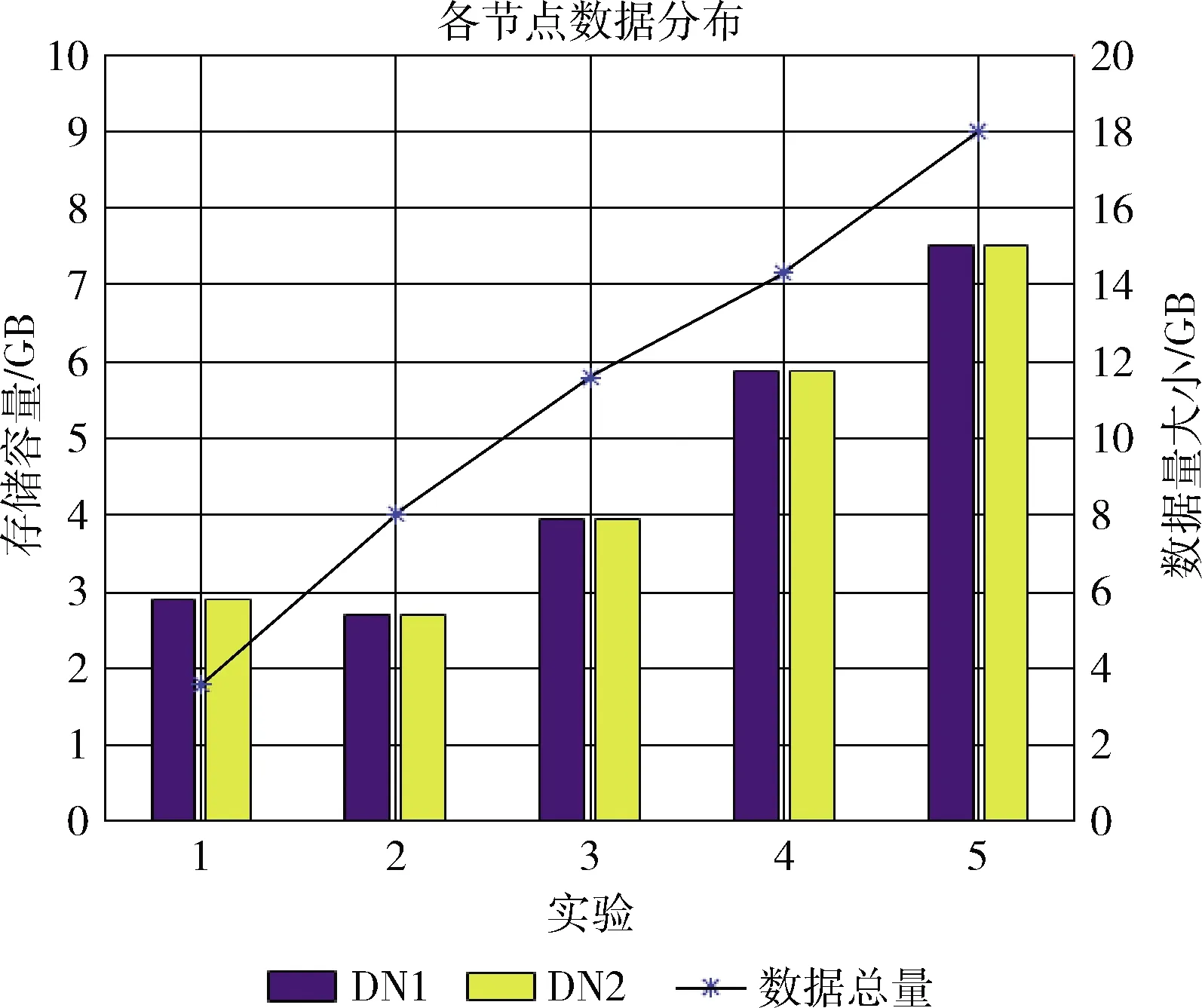
圖4 QAR數據存儲實驗結果
3.3 QAR數據查詢實驗
根據實際飛行品質分析需求,本節設置了3種不同的查詢場景。具體如下:
實驗1:查詢指定航班指定參數連續5分鐘內的300個參數數據。
實驗2:查詢指定航班指定主題下的5個不同參數,在1分鐘內的60個連續數據,共300個值。
實驗3:查詢指定航班5個不同主題下的指定參數在1分鐘內的60個連續數據,共300個值。
以上的每個實驗均進行20次測試,實驗結果如圖5~圖7所示。圖5~圖7中橫坐標表示實驗次數,縱坐標表示查詢耗時,單位為ms。圖5~圖7中的20次查詢的平均耗時分別為291.45 ms,1860.4 ms,1992 ms。由此可知,文中的存儲設計最適用于查詢指定QAR參數在一段時間內的連續取值序列。同一主題下的不同參數的取值序列查詢效率高于不同主題的參數取值查詢。這是因為在本文Value表的行鍵結構設計中,基于航班號和參數主題的哈希散列值能使同一個主題的不同參數連續存儲在region中,在行鍵的中間八字節采用航班編號及參數編號對參數進行精確定位,Value表行鍵的低四字節取參數的采集時間,使得同一參數的數據以時間的遞增順序存儲在連續空間中。

圖5 實驗1結果
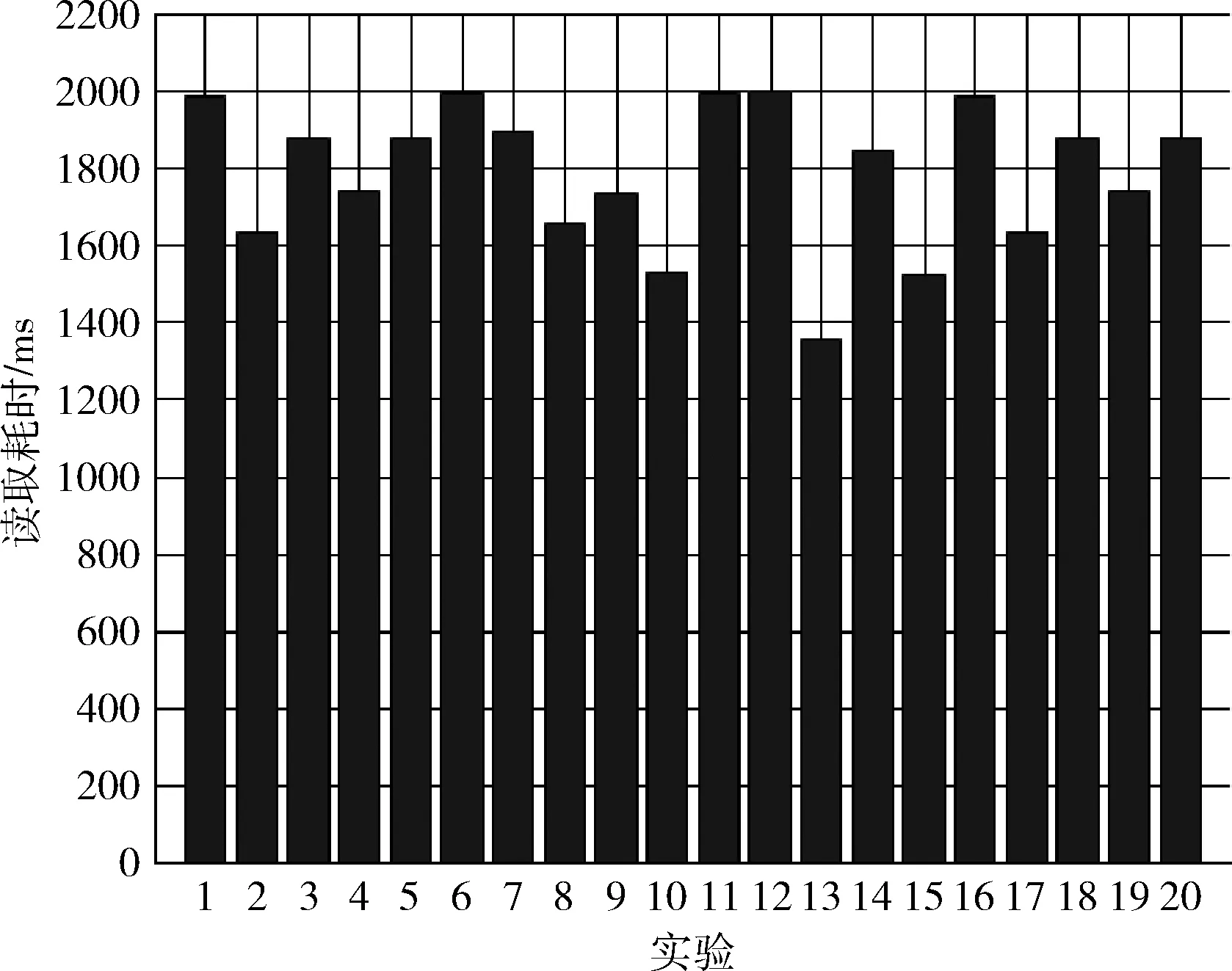
圖6 實驗2結果

圖7 實驗3結果
3.4 查詢對比實驗
為了驗證文中設計的存儲模式在典型QAR數據查詢分析上的有效性,與文獻[10]中存儲時序數據的行鍵設計策略進行了對比。根據文獻[10]的行鍵設計方法,實驗中將航班號、日期、參數名及參數采集時間作為行鍵,以指定航班指定參數在一段時間內的取值序列為查詢場景,查詢序列長度分別為300、3000、300 000,每個實驗均進行20次。實驗結果如圖8(a)~圖8(c)所示。圖8中每個圖的橫坐標為實驗次數,縱坐標為讀取耗時,單位為ms。由圖8(a)可知,在讀取參數取值序列較短的情況下,本文存儲設計模式的查詢耗時與采用文獻[10]的行鍵設計存儲模式下的查詢耗時相差較小。但是,從圖8(b),圖8(c)不難看出,隨著參數取值序列的增長,本文存儲模式下的查詢耗時明顯低于文獻[10]的行鍵設計策略的查詢耗時。這是因為按照文獻[10]的設計進行數據存儲時,隨著存儲數據量的不斷增大,HBase中的Region會進行多次分裂。在進行數據查詢時,HBase首先根據查詢條件生成的行鍵值確定Region,然后對該Region進行掃描得到查詢結果。而本文根據航班號與參數主題散列值的前兩個字節及預實驗,將Value表分為了27個Region。在查詢過程中,本文能根據航班號與參數名對應散列值的前兩個字節快速定位待查詢數據所在的Region,該過程的耗時少于文獻[10]定位Region的策略。而且本文生成每個Region內的數據量也少于文獻[10]中由HBase系統自動生成的Region,從而使本文在Region內部的數據查詢時間也較少。

圖8 與文獻[10]實驗對比結果
4 結束語
文中設計實現了基于HBase的QAR數據文件的分布式存儲模式。根據飛行品質監控業務需求,將QAR參數集合劃分為七大主題。設計了基于參數主題的行鍵組織結構和基于行鍵MD5散列值的預分區技術。真實QAR數據集上的實驗結果表明,文中的設計能使QAR數據文件均勻存儲在HBase集群中,在飛行品質分析中典型的QAR參數取值序列查詢場景下有較高的查詢效率。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
