機器學習輔助的高通量實驗加速硬質高熵合金CoxCryTizMouWv成分設計
2020-05-23 02:15:54王炯,肖斌,劉軼,
中國材料進展 2020年4期
王 炯,肖 斌,劉 軼,
(1. 上海大學 材料基因組工程研究院,上海 200444)(2. 上海大學物理系 量子與分子結構國際中心,上海 200444)
1 前 言
研發具有特定目標性能的新材料時,傳統的材料研究通常采用經驗試錯法,通過少量實驗離散地調整樣品成分與制備工藝來探索材料的最佳性能。然而,這種“炒菜式”研發手段耗時且成本高昂,同時由于實驗數據量較少,對材料結構-性能關系考察不夠全面深入。隨著材料基因組工程的興起[1],利用高通量實驗、計算模擬和機器學習加速新材料研發,受到了越來越多的關注。早在1970年,Hanak[2]提出了包含高通量材料研發(high-throughput materials development,HTMD)在內的所有環節流程,該研究被認為是材料領域內最早提出高通量概念的工作。1980年,Moulijn等[3]發表了使用多相催化平行反應器的高通量材料制備研究。1997年,Danielson等[4]采用電子束蒸發法在一個直徑為7.6 cm的襯底上合成了25 000種不同成分的材料。近年來,研究者們基于材料組合芯片思想,采用氣相沉積、磁控濺射等工藝制備了每個成分連續變化的多組元薄膜樣品或一批成分離散變化的塊體樣品[5-9]。總之,高通量材料制備方法具有多工位、自動化、并發式的特點,可以實現材料的快速、批量合成,比傳統的單一樣品生產模式在材料制備效率上有大幅度提升。隨著實驗數據的積累,材料數據庫在新材料研發設計過程中也起到越來越重要的作用。Bligaard等[10]利用包含晶格尺寸、體積模量等物理量的有序化金屬玻璃數據庫,篩選出了具有低壓縮性、高穩定性和低成本的備選材料。但通常情況下,針對某一類材料的單一或幾個性能進行設計時,高質量、大批量的數據還很缺乏,甚至某些全新體系可能不存在已有實驗數據,此時高通量實驗成為獲取大量優質、自洽實驗數據的有力手段。
雖然高通量實驗能夠有效提升研究效率,但面對多元合金巨大的成分參數空間(數千至數萬個成分組合)時,探索所有潛在合金成分在實驗上是幾乎不可能的,合金成分優化設計依然是一項艱巨的挑戰。因此,將機器學習法引入到材料成分設計領域成為了加速新材料研發進程的重要手段。傳統的機器學習法中,以神經元網絡(ANN)、支持向量機(SVM)、隨機森林(RF)、K近鄰(KNN)等方法最具代表性[11-22]。2016年,Raccuglia等[23]利用失敗實驗數據結合SVM算法成功建立了無機-有機雜化材料結晶過程反應模型,并預測了新化合物的形成條件,準確率達89%。此外,機器學習法也被作為加速研究方法廣泛應用于介電特性[24]、無機晶體帶隙[25]、熔點[26]、抗壓強度[27]、硬度[28]、相結構[29]等材料性質研究。
自Senkov等[30, 31]制備了具有優異高溫性能的W-Nb-Mo-Ta-V系列bcc相難熔高熵合金后,關于難熔高熵合金的研究受到了極大關注。研究者們廣泛研究了含W,Mo,Ti,Nb,Ta,Zr的高熵合金體系[32-37]。除純相高熵合金外,還廣泛研究了高熵合金中第二相對合金性能的影響[38-40]。本工作將高通量實驗與機器學習法相結合,應用于開發新型非等摩爾比的硬質高熵合金。在元素組成上,考慮到高熔點的W和Mo以及Co,Cr,Ti等在高溫結構材料中廣泛應用的金屬元素,以CoCrTiMoW體系為基礎設計了新型非等摩爾比的硬質高熵合金。
2 實 驗
2.1 高通量實驗
本工作首次提出了以制備離散成分塊體合金為特色的全流程高通量材料制備概念,涵蓋合金樣品配料、混合、壓塊、電弧熔煉、鑲嵌、切割、磨拋的合金熔煉和金相樣品制備環節。基于此思想,上海大學材料基因組工程研究院與合肥/沈陽科晶材料技術有限公司聯合設計研發了全流程高通量合金制備系統,具體包括36工位粉料分配器、16工位球磨混料機、16工位壓力機、32工位自動電弧熔煉爐、16工位冷鑲嵌機、8工位線切割機以及16工位自動磨拋機(圖1)。本實驗的合金熔煉和樣品制備均由高通量合金制備系統完成,對材料制備流程各環節實現了多工位、自動化加速,縮減了單個樣品的平均實驗準備和運行時間,例如省略了傳統電弧熔煉的多次抽真空過程,克服了材料制備過程中耗時的瓶頸。該高通量合金制備系統的整體效率比傳統單一或少樣品制備方法提升了至少10倍。
本工作以粒徑均約為50 μm的Co,Cr,Ti,Mo,W純金屬粉為原材料,其純度均大于99.5%(質量分數),共制備了138個合金樣品,其成分分布在CoxCryTizMouWv空間內。初始的合金成分設計采用以下兩種策略:① CoCrTiMouWv,重點調整難熔金屬W和Mo的含量;② CoxCryTizMouWv,首先將成分映射到與合金相穩定性有關的描述因子價電子濃度-原子半徑差(VEC-δ)空間[41],然后選取VEG-δ空間內均勻分布的點轉換回成分。
本工作使用自動粉料分配器根據給定合金成分進行配粉。將配置好的合金粉末經過自動球磨機充分混合均勻后,利用自動壓力機壓制成圓柱狀塊體(直徑約為2.05 cm,高度約為1.50 cm)。然后在Ar氣氛保護下的手套箱內利用自動電弧熔煉爐中的水冷銅模具自動連續熔煉制備鑄態金屬錠。每個工作流程最多可熔煉32個金屬錠,單個金屬錠的重量約為10 g,需反復熔煉5次以上以保證其組織均勻性。然后,經冷鑲嵌和磨拋后(依次用顆粒粒度為70,37,15,12,7和5 μm的砂紙打磨、拋光)制成金相樣品。最后,采用HBRV(D)-187.5A1型手動布洛維三用硬度計測試合金的宏觀維氏硬度(HV),測試條件為:壓力為30 kg,預加載時間為3 s,加載時間為10 s。對每個樣品進行多次宏觀硬度測量,至少獲得五次以上有效值并取其平均值。138個不同成分的合金的HV測量結果如圖2所示,其中36個合金的HV低于600 MPa,70個合金的HV在600~800 MPa之間,32個合金的HV高于800 MPa。
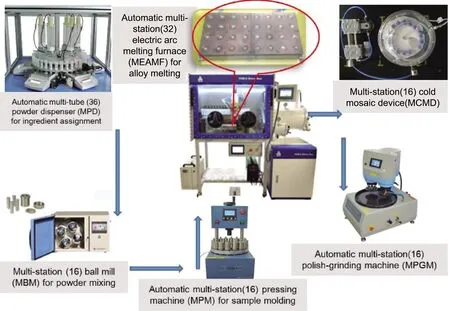
圖1 全流程高通量合金制備系統Fig.1 All-process high-throughput synthesis system of alloy
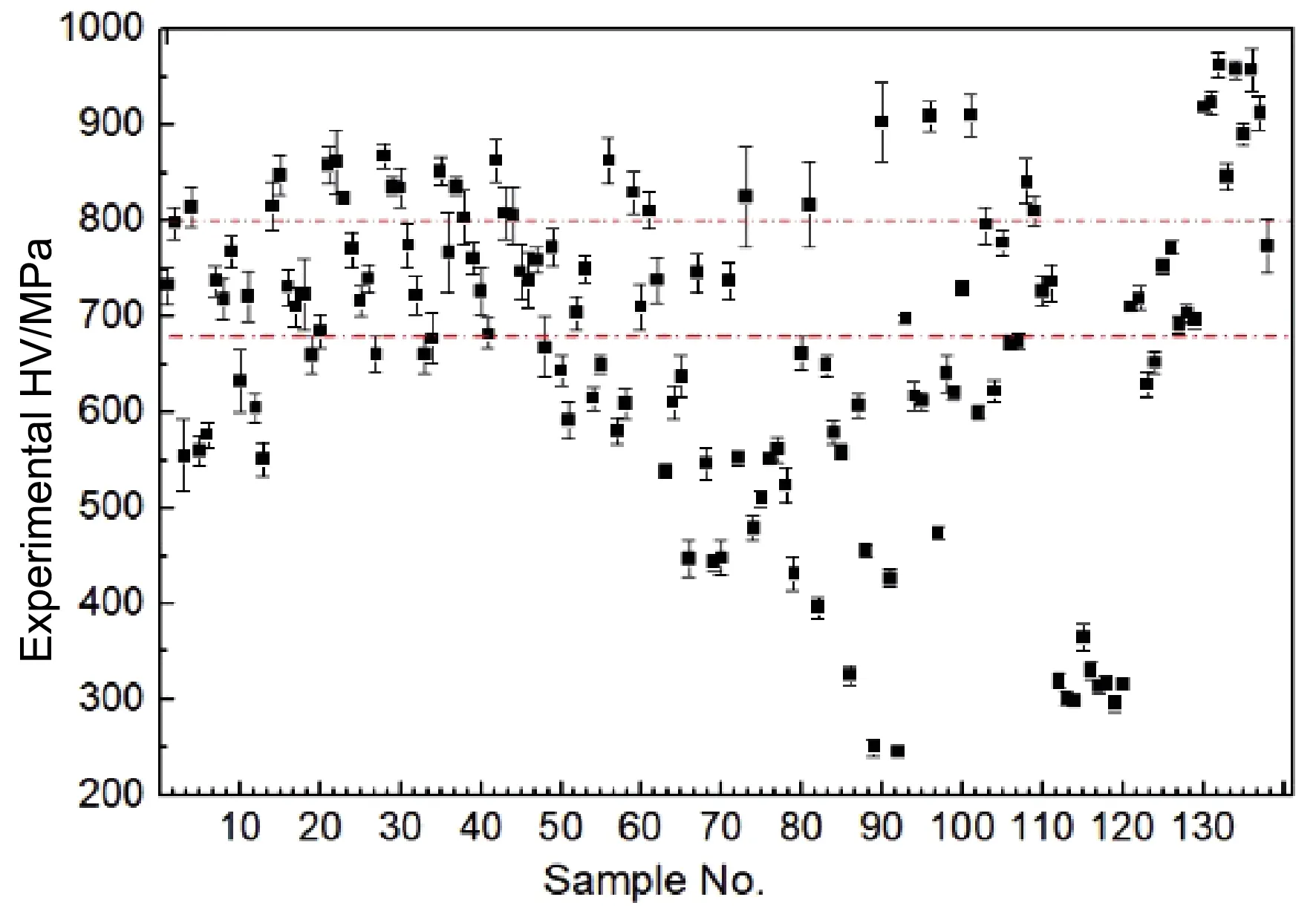
圖2 138個高熵合金CoxCryTizMouWv樣品的硬度實驗測量值Fig.2 Experimental HV values of 138 high-entropy alloy CoxCryTizMouWvsamples
2.2 機器學習
機器學習數據集為通過高通量實驗獲得的138個合金的硬度數據。由于全流程高通量合金制備系統盡可能提供了相同的實驗環境和過程,減少了因工藝參數不同造成的數據不確定性。對于不同的機器學習預測模型,本工作采用決定系數R2、平均絕對誤差MAE與均方根誤差RMSE來綜合評判模型優劣。考慮到小數據樣本和數據本身的誤差,在最終模型選用上,采用評判擬合效果的相關系數R2作為第一判據,并結合考慮MAE和RMSE。R2,MAE和RMSE由式(1)~式(3)計算得到:
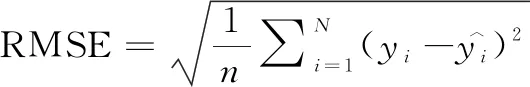

2.2.1 機器學習算法與特征
本工作測試了RF[42]和SVM[43]機器學習算法,其中SVM法選擇了高斯徑向基核函數(rbf)與線性核函數(linear),將上述算法分別記為RF、SVM_rbf和SVM_linear。所有機器學習算法由Python語言實現,主要使用Scikit-learn算法包[44]以及Pandas和Numpy計算擴展庫實現數據的讀入與處理。
本工作的機器學習共使用了29個基礎特征描述因子(表1)[45-48]和1個目標變量——HV。機器學習模型的輸入特征是基于合金體系中不同元素的基本屬性,以各組元成分的摩爾比為權重的算術平均值構建生成。因此,將29個基礎元素或單質體相材料的描述因子分為4組:
(1)AD:編號1~29的所有描述因子。
(2)EMF:只包含編號1~5表示元素摩爾比的描述因子。
(3)VDSHOT:VEC,△Hmix,△Smix,Tm,Ω,δ與高熵合金相結構關聯的特征[41, 49-52]。
(4)SD:選擇特征集合,由經RF算法評估后排名前9位的描述因子組成(δ,DC,NC,RC,△Smix,EI,W,EN,Cr)。
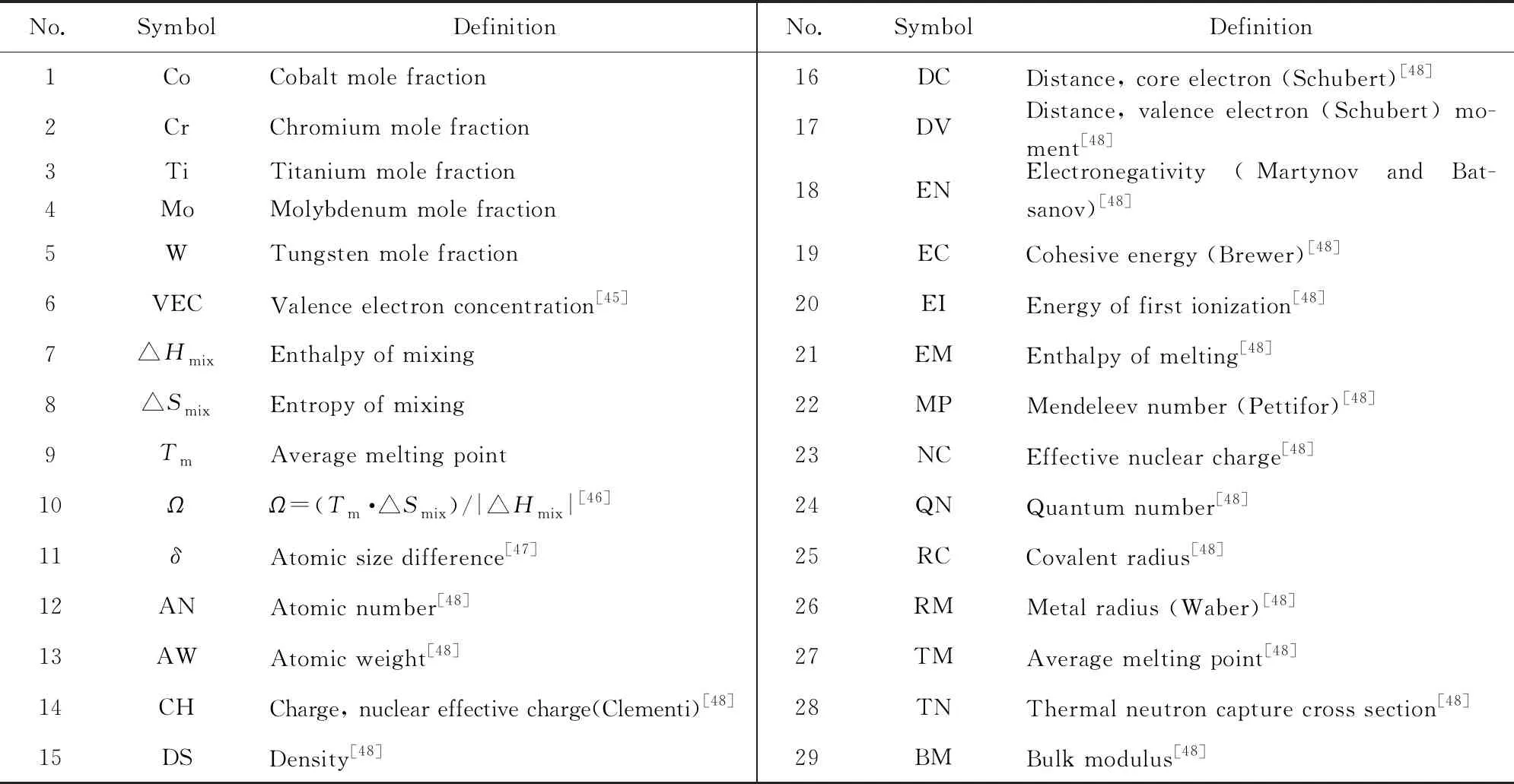
表1 機器學習模型的描述因子[45-48]
2.2.2 機器學習策略
將3種機器學習算法與4種描述因子集合進行組合,構建了12個機器學習方法,如表2所示。使用五折交叉驗證法分別對12個機器學習方法的超參數進行優化,即80%的數據用于建模,20%的數據用于評估算法的精度。對12個機器學習方法分別進行10次隨機數據集劃分(8∶2)建模,共獲得120個機器學習模型,記為ML(120)。

表2 由3種機器學習算法與4種描述因子集合組合而成的12個機器學習方法
2.2.3 模型選擇
圖3為按照描述因子集合劃分的120個機器學習模型評估結果。RF、SVM_rbf和SVM_linear 3種機器學習算法使用4種描述因子集合構建的模型的預測能力定性基本相似,其中以AD構建的模型的預測結果定量最優,后續針對該系列模型的預測結果進一步討論。不同機器學習算法的預測精度排序為RF>SVM_rbf>SVM_linear。雖然RF算法的模型預測能力最好,但SVM算法在隨數據集劃分變化時的波動性顯著小于RF算法,這說明SVM算法相較于RF算法對小樣本數據集合具有更強的魯棒性。考慮到機器學習建模過程中小樣本數據集劃分對模型的影響,在最終模型的選擇上除了以R2作為判據,也結合較低的MAE和RMSE進行綜合評判,因此挑選出的最佳模型為RF/AD_4。此外,還從魯棒性強的SVM_rbf算法生成的模型中依據R2選出一個最優模型SVM_rbf/AD-5,進而比較這兩種模型在合金硬度預測趨勢上的異同。
預測精度最好的RF/AD_4和SVM_rbf/AD-5模型的評估結果如表3所示,138個合金樣品硬度的實驗測量值(H138e)和機器學習模型預測值(H138m)如圖4所示。兩個模型的預測結果在趨勢上表現出一致性,但RF/AD_4模型在數據相關性和預測誤差方面明顯要優于SVM_rdf/AD-5模型。RF/AD_4模型在低(HV<600 MPa)、中(600
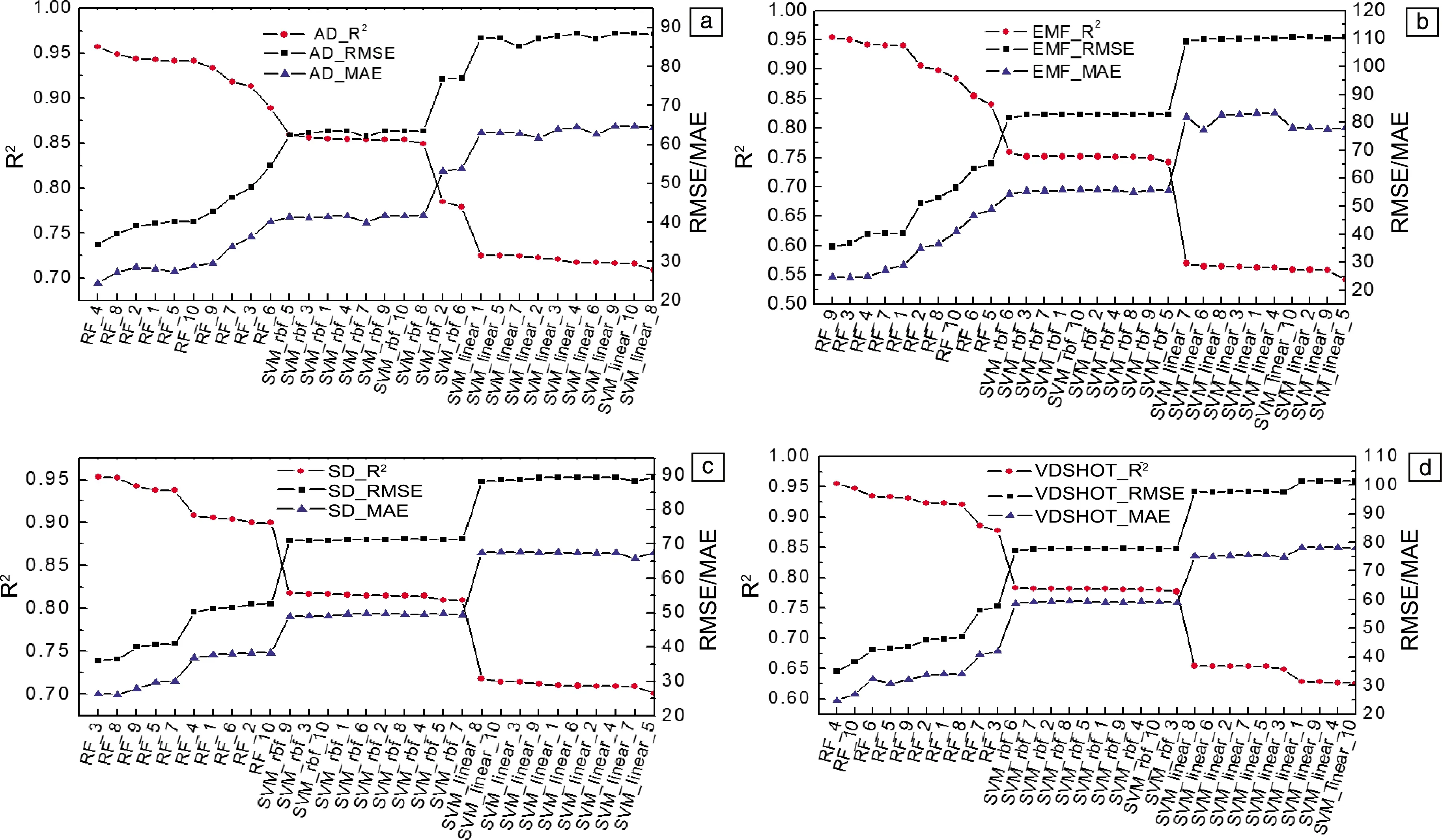
圖3 按照描述因子集合劃分的120個機器學習模型的評估結果:(a)AD,(b)EMF,(c)SD,(d)VDSHOTFig.3 The evaluation results of 120 machine learning models divided by different descriptor sets: (a) AD, (b) EMF, (c) SD, (d) VDSHOT

表3 RF/AD_4與SVM_rbf/AD-5模型的評估結果
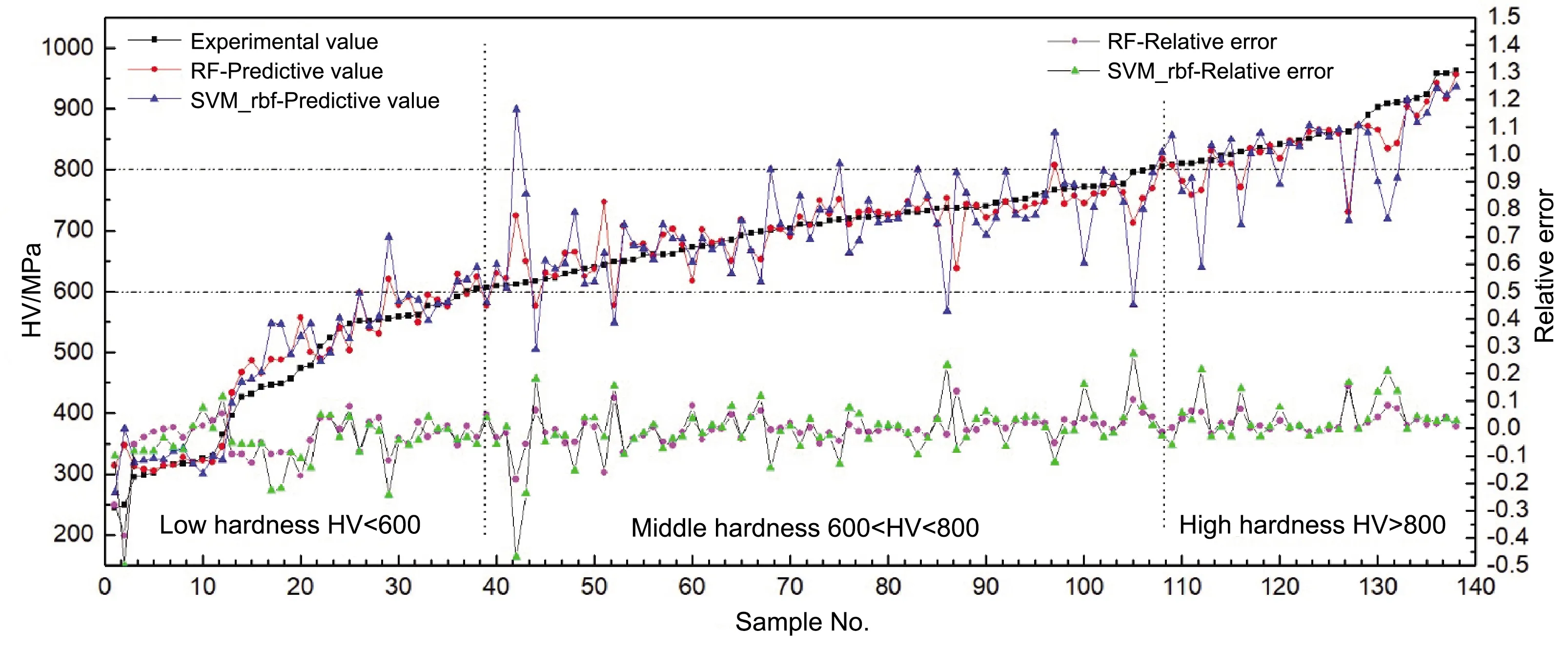
圖4 138個合金樣品硬度的實驗測量值、模型預測值以及預測值的相對誤差Fig.4 Experimental values,predictive values and relative errors of predictive values to the hardness of 138 alloy samples
3 結果分析
3.1 描述因子的選擇
使用RF算法對29個描述因子的重要性進行排序(圖5),其中RF算法的回歸樹采用最小均方差原則計算、評估描述因子的重要性,其重要性由高到低排名前9的分別為:δ,DC,NC,RC,△Smix,EI,W,EN和Cr。根據重要性排序,其中最重要的描述因子為δ,表明δ在29個描述因子中對合金硬度的影響最大,相關文獻也證明了δ對合金硬度有顯著影響[53, 54]。從合金組元角度分析,各元素按其對合金硬度影響的大小排序為:W>Cr>Mo>Ti>Co。因此,將排名前9的描述因子作為SD用于機器學習建模,由其構建的模型預測結果如圖3c所示。
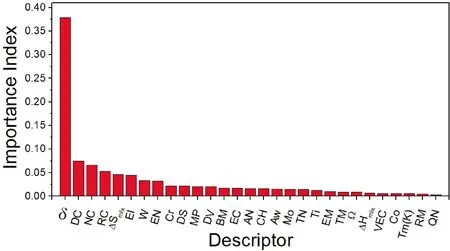
圖5 機器學習中29個描述因子的重要性排序Fig.5 Importance order of 29 descriptors in machine learning
3.2 “成分-硬度”圖譜
圖6分別為根據RF/AD_4與SVM_rbf/AD-5模型預測結果繪制的合金全成分空間的“成分-硬度”圖譜(composition-hardnessmap, CH map)。兩個模型在對CoxCryTizMouWv合金體系全成分空間的硬度預測結果上顯示出相似的趨勢。對于五組元成分體系,有4個獨立成分變量。兩個模型在CH圖譜上都具有4條與成分變量相對應的硬度包絡曲線,且各硬度峰值對應出現在相同的成分區間內。以合金元素的摩爾比作為變量,硬度隨成分改變呈現有規律的變化趨勢。
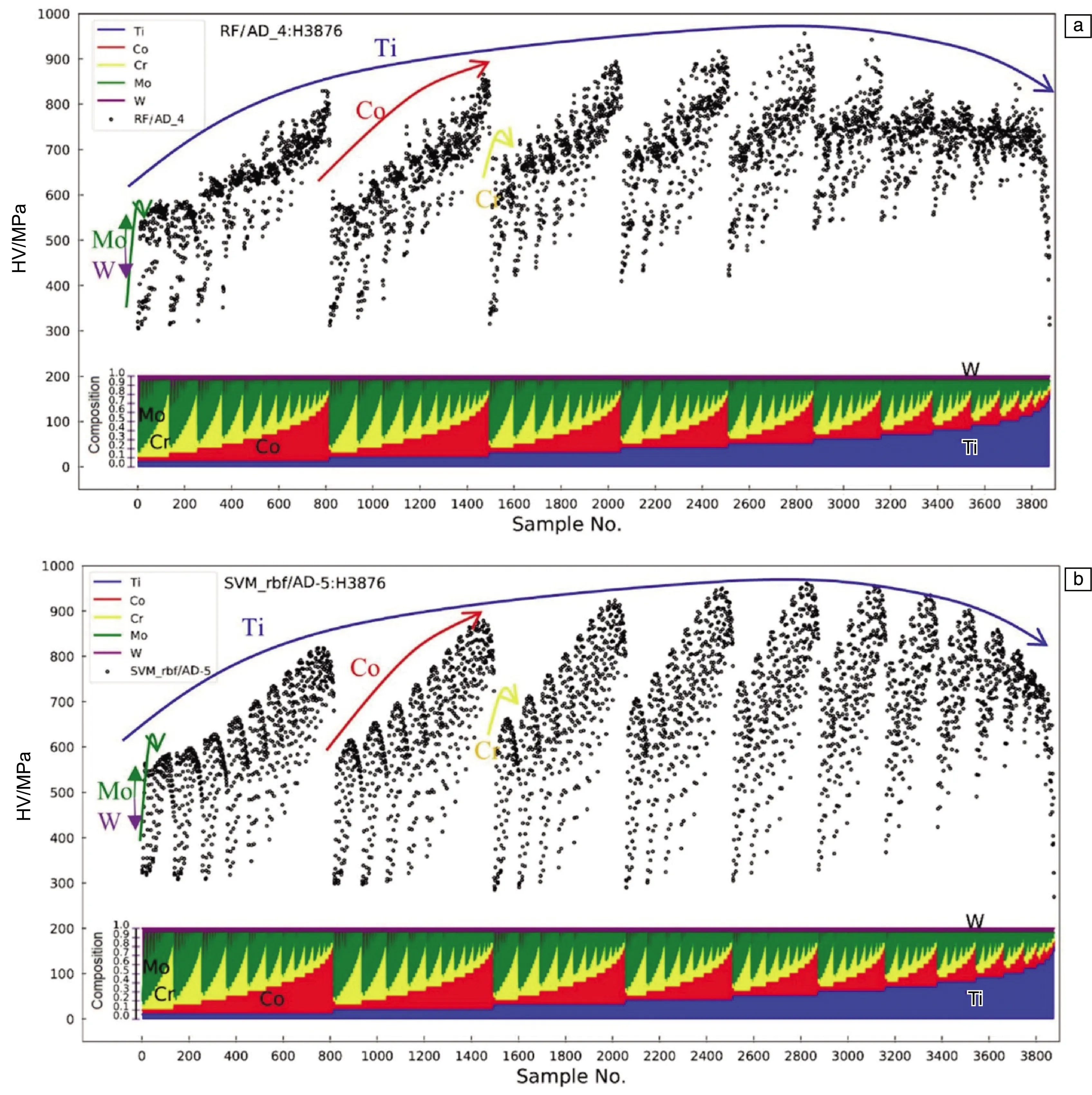
圖6 根據兩種機器學習模型預測結果繪制的高熵合金“成分-硬度”圖譜:(a)RF/AD_4,(b)SVM_rbf/AD-5Fig.6 “Composition-hardness” maps of high-entropy alloy constructed by the two kinds of machine learning models: (a) RF/AD_4, (b) SVM_rbf/AD-5
以Ti作為第一層變化元素,可以看到合金體系的硬度包絡曲線隨著Ti含量的升高先升高再下降,而且后半段曲線有加速下降的趨勢。結合一般二元固溶體合金的經驗,在一種元素的含量由0增加到1的過程中,合金一般會經歷“單相-固溶相-金屬間相-固溶相-單相”的轉變過程。在單相區間內,隨著元素含量的變化,晶格畸變也將發生顯著變化,從而影響位錯在晶粒內部的運動,產生位錯釘扎等效應,對合金的力學性能產生影響。當合金內產生金屬間相,或單相結構產生較大的晶格畸變時,合金會表現出較高的硬度;而當合金成分接近單一組元(即固溶組元含量少)、晶格畸變較小時,合金一般表現出較低的硬度。由圖6中的4條硬度包絡曲線可以看出,在某一元素的含量達到最高值時,其對應的合金硬度出現跳變,由于x軸的成分變量按照Ti,Co,Cr,Mo,W的順序進行排序組合,因此Ti,Co,Cr對應的3條硬度包絡曲線變化更為顯著。這兩種模型的預測結果與傳統經驗有類似的變化規律,這也證明了模型預測結果的可靠性。
3.3 “描述因子-硬度”圖譜
除了建立CH圖譜,還根據RF/AD_4模型預測結果,將硬度投影到二維機器學習描述因子平面中構建“描述因子-硬度”圖譜(descriptor-hardness map,DH map),如圖7所示。由于部分描述因子具有特定的物理含義,這種表示材料性質的描述因子投影圖有助于理解合金成分之外的描述因子對合金硬度的影響規律。這種不含特定合金成分的圖譜可能具有更廣泛的適用性,不僅可應用于CoxCryTizMouWv特定合金體系,還可能擴展到其他多元合金體系的硬度預測。另外,將多組元成分空間投影到二維描述因子空間內,還將有效降低合金初始成分選擇的維度,實現快速簡便的合金成分反向設計。
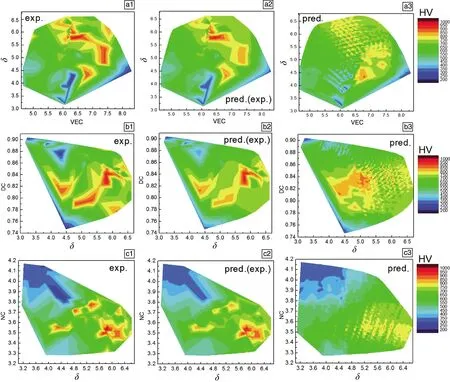
圖7 138個合金硬度的實驗測量值(H138e)(1)、機器學習模型預測(H138m)(2)和全局成分空間內3876個合金硬度的模型預測值(H3876m)(3)的“描述因子-硬度”圖譜(圖中的彩色標尺代表硬度,從藍到紅表示硬度增加):(a)VEG-δ,(b)δ-DC和(c)δ-NCFig.7 “Descriptor-Hardness” maps of H138e (1), H138m (2) and H3876m (3) (The color scales represent the hardness value increased from blue to red): (a) VEG-δ, (b) δ-DC and (c) δ-NC
圖7a1~7c1為H138e分別在VEG-δ,δ-DC和δ-NC空間的DH圖譜;圖7a2~7c2為H138m分別在VEG-δ,δ-DC和δ-NC空間的DH圖譜;圖7a3~7c3為全成分空間內3876個合金硬度的模型預測值(H3876m)分別在VEG-δ,δ-DC和δ-NC空間的DH圖譜。與H3876m的DH圖譜相比,H138m與H138e的DH圖譜更吻合,這是因為后兩者是點對點對應,而前者在相同范圍內布點更密集,其高硬度與低硬度可能非常接近。盡管預測結果在絕對數值上可能存在差異,但在二維描述因子空間下,硬度分布呈現出定性相似模式。在DH圖譜中,VEG-δ映射中的高硬度區和低硬度區間的分離距離最大,表明VEG-δ空間在分離和預測硬度上具有優勢。實際硬度預測可以由多個DH映射同時確定,進一步增加預測的可靠性。
4 結 論
本文利用高通量實驗結合機器學習的方法加速非等摩爾比的硬質高熵合金CoxCryTizMouWv的成分優化設計,使綜合設計效率提高了200倍以上。利用本團隊自主研發的一系列新型全流程高通量合金制備實驗設備,多工位、大批量、自動化制備具有離散成分的塊體合金,較傳統單/少樣品制備過程至少加速10倍。該套高通量材料制備系統包括合金熔煉和金相樣品制備流程,具體涵蓋配料、混合、壓塊、電弧熔煉、鑲嵌、切割和磨拋。利用高通量實驗合成了138個不同成分的合金樣品,根據其硬度數據使用3種機器學習算法(隨機森林和兩種支持向量機法)和4種描述因子集合構建了120個機器學習模型。研究結果表明,隨機森林比支持向量機精度更高,其預測結果與實驗測量值接近。通過機器學習建模設計合金成分,與在全成分空間內排列組合式的窮盡搜索相比至少加速了20倍。利用機器學習模型構建全成分空間內的“成分-性質”和“描述因子-性質”關系,“從數據驅動設計再返回到知識驅動設計”,從而實現認知的螺旋式上升。本工作證明了材料基因組計劃提出的低成本加倍材料研發速度不僅可能,而且效率會比最初提議的兩倍更高。機器學習指導下的高通量實驗方法可成為加速多組元材料成分優化設計的有效通用策略。未來材料研究需要在“機器學習”的基礎上聚焦“向機器學習”,從而獲得新的專業領域知識。
致謝:感謝上海大學高水平大學建設項目對高通量實驗設備研制的支持;感謝中鋁材料應用研究院、鞍山鋼鐵公司、云南錫業集團、福建南平鋁業公司和上海紫燕合金公司對高通量材料研發的支持;同時感謝科晶(MTI)集團的江曉平博士在共同研發高通量合金制備系統方面的幫助。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
