基于語義元數據的醫養數據融合研究與實現
2020-05-16 06:33:14季文飛蔣同海唐新余
計算機應用與軟件 2020年5期
季文飛 蔣同海 王 蒙 唐新余 陳 光
1(中國科學院新疆理化技術研究所 新疆 烏魯木齊 830011)2(中國科學院大學 北京 100049)3(中國科學院新疆民族語音語言信息處理重點實驗室 新疆 烏魯木齊 830011)4(江蘇中科西北星信息科技有限公司 江蘇 無錫 214135)
0 引 言
醫養融合是國務院《關于加快發展養老服務的若干意見》中提出的創新養老服務模式,指將養老服務同醫療資源相結合,從而更好地服務老年人群[1]。醫養融合首先是數據融合,即打通醫療、養老信息系統的數據壁壘,統一相關系統業務和數據模型,共享相關系統數據。數據融合技術能夠對海量數據進行融合處理,提高“數據質量”[2],減少數據中的錯誤,為后續數據處理分析提供可靠的數據支持[3]。通過融合,一方面可以整合各自系統的就醫、用藥、養老等老年人生活數據[4],讓老年人享受更加便捷的老年生活服務,另一方面可以提高政府對老齡問題的洞察能力,提高決策科學水平[5]。我國現有的醫療、養老系統數據模型復雜,重復較高,無法共享相關的老人就醫和養老數據,存在嚴重的“信息孤島”問題[6]。傳統的醫養融合系統一般采用硬編碼技術實現,根據具體項目制定數據模型、清洗融合模型、可視化和訪問模型,在靈活性、可擴展性方面表現較差。
本文針對醫養數據融合中相關問題進行研究,提出使用語義元數據模型解決醫養數據融合中的統一建模問題、清洗和融合問題、可視化和訪問問題,并實現了相應的數據融合系統。該系統支持動態數據建模、支持融合規則建模和可視化模型建模,具有較好的靈活性和可擴展性,能滿足區域內養老、醫療數據融合處理響應時間的要求。
1 相關工作及面臨的問題
醫養融合需要匯聚來自各種醫療系統、養老系統的數據,需要支持物聯網設備、長護險結算系統及其他第三方數據產生端的系統接入,同時需對匯聚的數據進行清洗和融合,并提供數據可視化和訪問服務。
文獻[7]介紹了利用FHIR進行醫療信息集成,通過構建一個RESTFUL協議訪問的應用系統,利用基于XML的HL7協議對醫療信息進行建模,實現不同醫療系統之間的數據集成和共享。
文獻[8]介紹了基于本體理論進行醫學數據建模及其應用,首先利用本體進行醫療建模,然后利用算法進行數據檢測和本體識別。文獻[9]則在本體建模形成的醫療數據模型基礎上進行了醫療知識抽取和可視化工作。
文獻[10]介紹了基于字符串模式匹配的數據交互集成方法,即利用人工干預進行多次迭代的方式生成全局統一的中介模式,并介紹了其在二手房數據集成上的應用。
文獻[11]介紹了使用新技術框架如Apache Hadoop、Apache Storm進行醫療、護理數據集成和計算,并建立了一個能夠支持實時進行醫療、護理數據計算的系統。
上述的研究一般以項目的形式,由編程人員在某一些醫療、養老系統之間,利用XML或者本體建模技術,進行少量的數據清洗和融合,限于較低的靈活性和擴展性,未能進行大范圍推廣和使用,其主要原因是當前醫養數據融合面臨以下問題:
(1) 統一數據建模問題[12]。醫、養相關的系統紛繁復雜,每個系統對醫療、養老業務的抽象能力參差不齊,導致所建的數據和業務模型不盡相同,需要對業務和數據進行標準化和統一化建模,抽取出全局標準模型;另外這些系統在建模時使用的工具各不相同,需要提供統一的數據建模描述工具并支持動態建模。
(2) 清洗和融合問題[13]。不同來源的醫療、養老數據產生和采集方式不同存在數據缺失、異常、冗余等問題,為后續的處理帶來很大困難,需要對數據進行數據清洗和融合處理。不同的數據一般采用不同的清洗和融合策略,且需要動態修改,因此需要對清洗和融合進行建模,并提供相應的過程描述工具。
(3) 可視化和數據訪問問題[14]。不同的醫療、養老業務場景對數據的訪問和可視化能力具有不同的要求,需要提供對數據不同粒度的查詢訪問和可視化訪問建模和描述工具。
2 基于語義元數據的醫養融合研究
語義元數據作為資源描述框架表現形式,具有結構緊湊、表達直觀、語義豐富等特點,在數據集成、知識抽取得到大量研究和應用[15]。語義元數據具有不同表示方法,例如元組、XML_DTD[16]、RDFa[17]、JSON-LD[18]等方法。由于元組具有較好的可讀性、緊湊性,是最直觀的方法之一,能夠靈活地對數據進行建模和表述,支持數據模型的擴展,因此本文使用五元組表示的語義元數據,對上述醫養數據融合的問題進行研究,并設計出靈活性好并可擴展的數據融合系統。
語義元數據用一個五元組
2.1 語義元數據與統一數據建模
當前的醫療、養老系統具有不同的數據模型定義,需要事先使用語義元數據進行統一的數據建模,原有系統的數據模型也使用語義元數據進行描述,并把原有的數據模型與統一的模型在語義層面進行關聯。例如針對老人基礎模型,f的一個函數可以是原系統老人基礎模型的“姓名”屬性映射轉換到統一模型的“name”屬性。
考慮到當前大部分醫療、養老系統基于關系型數據進行建模和存儲,需要找到原數據與模型之間的關系,如算法1所示。
算法1 數據模型適配算法
輸入:cur_rules:語義元數據規則集合
data:需要匹配的數據
輸出:adapt_rules:適合此數據的語義元數據規則集合
for rule in cur_rules
data_keys=data.keys()
needed_keys=rule.Q
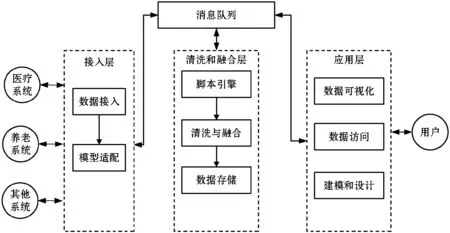
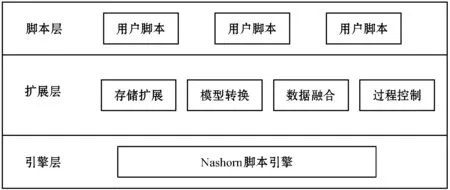
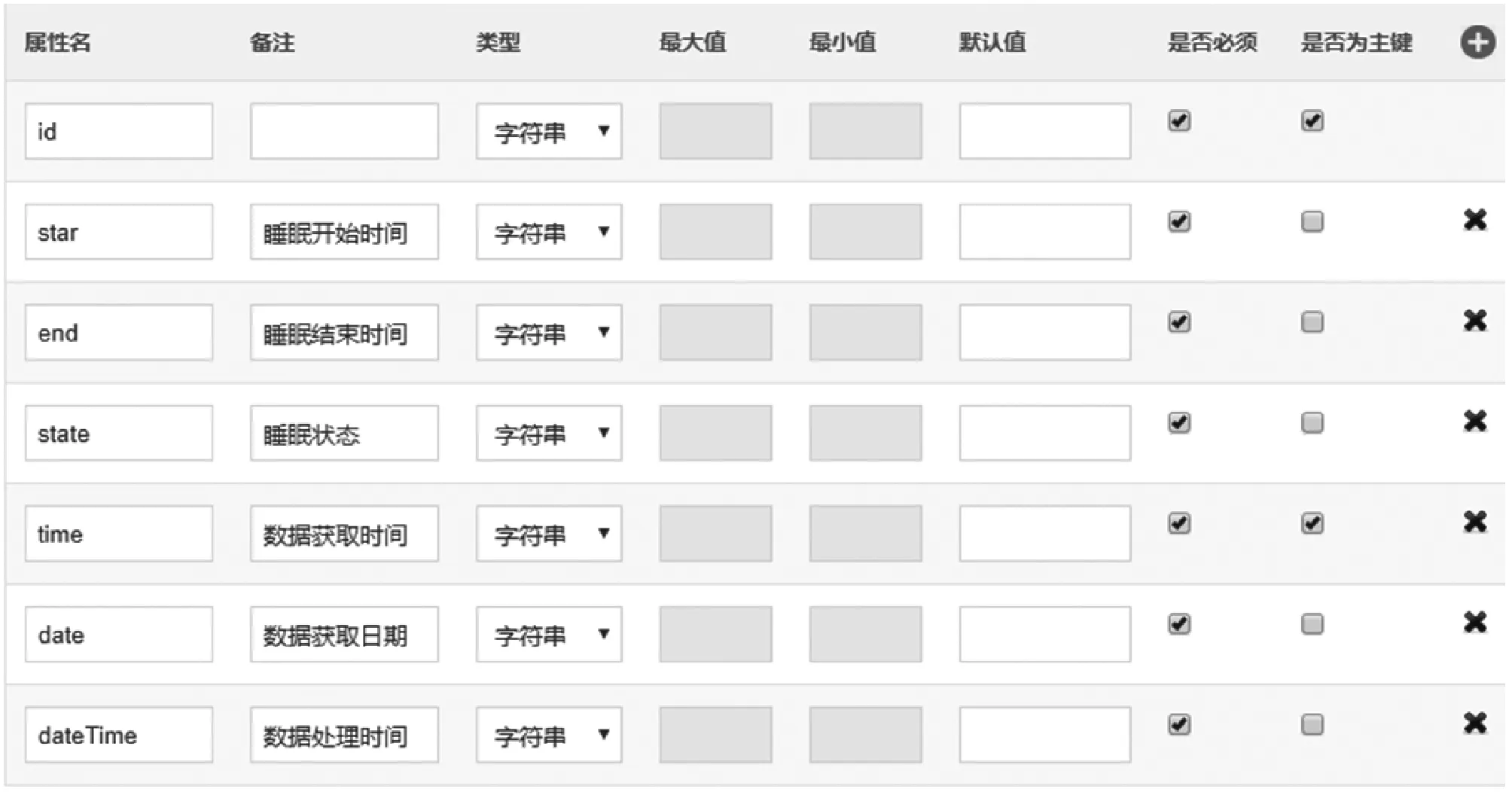
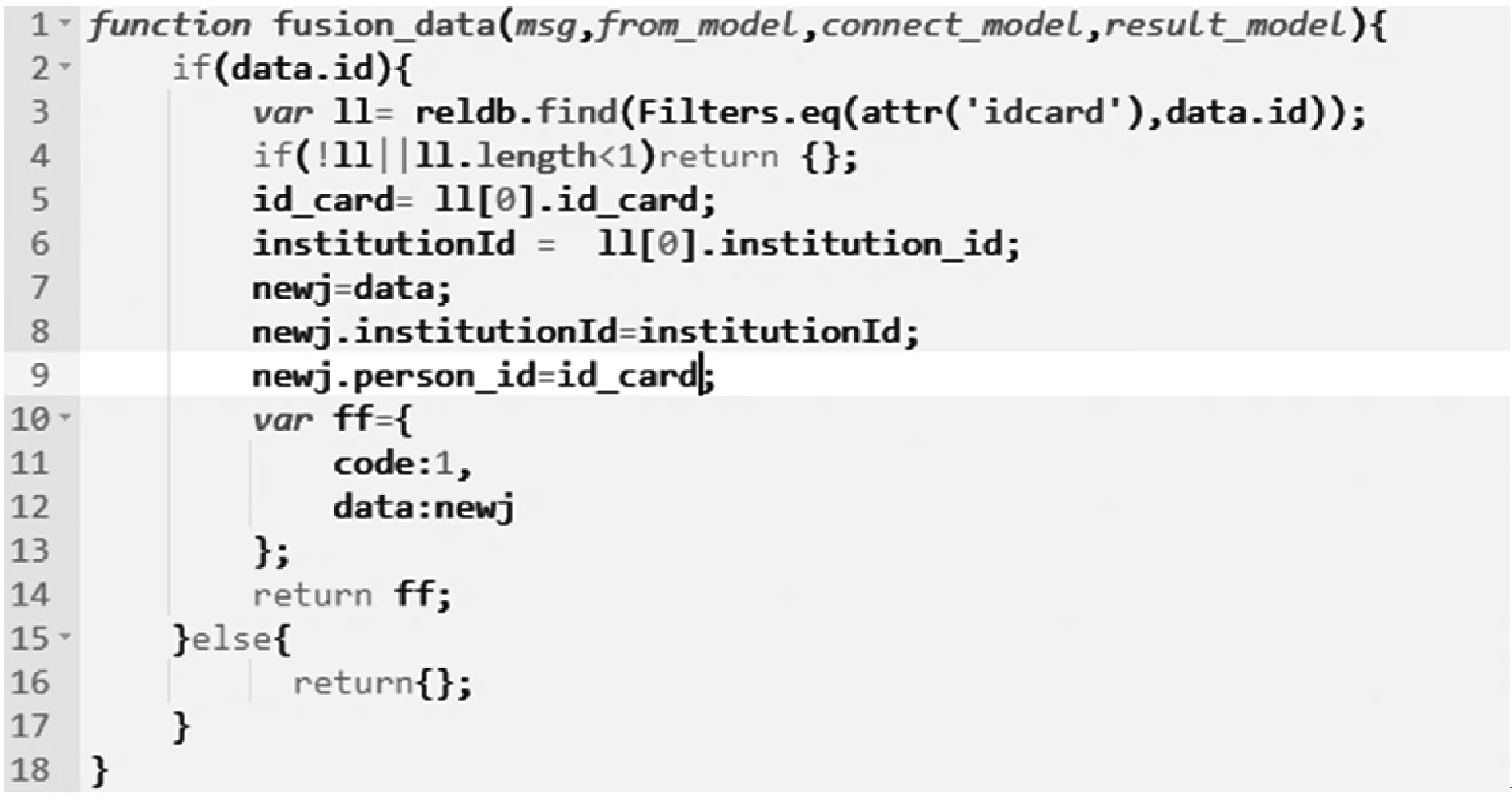
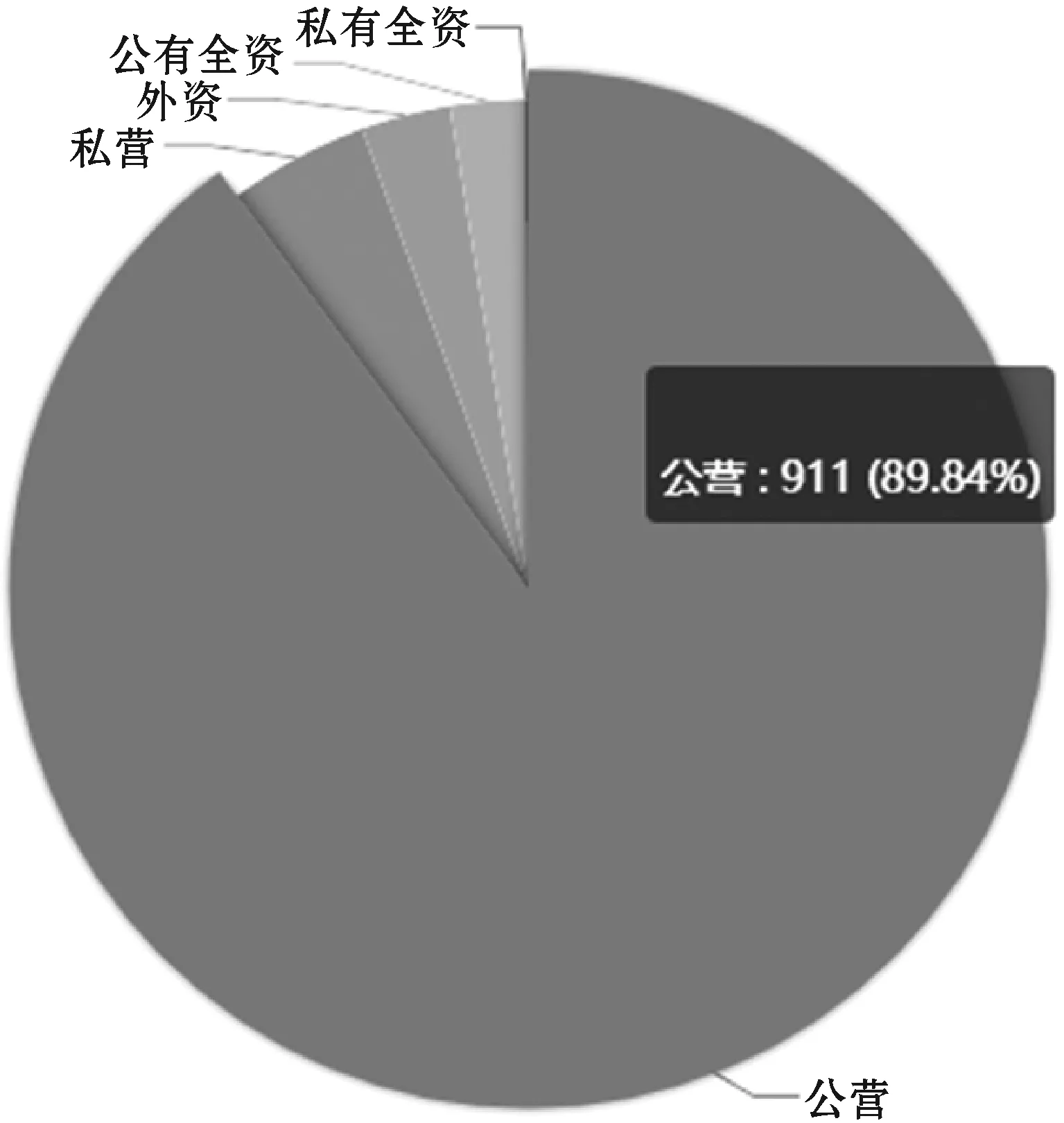
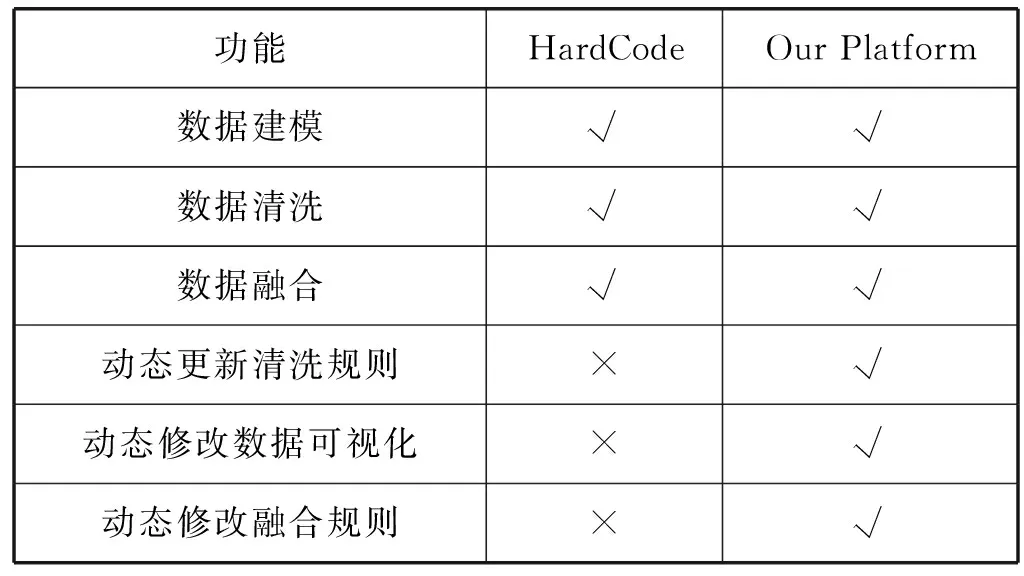
if data_keys.length Continue check_rule_flag=true for key in needed_keys if data_keys.index(key)<0 check_rule_flag=false break if check_rule_flag==true adaptive_rules.add(rule) 該算法不僅能夠給數據找到適合的模型,而且能夠把數據按照模型進行劃分,這在實際工程實踐中具有重要意義。因為傳統的應用系統一般以關系型的形式存儲相關數據,具有完善的模型之間關系,該算法能夠捕捉這種模型之間的關系并把數據任意組合到相關模型中,如針對老人的詳細信息,通過算法可以切分為老人基本信息、健康信息、生活信息,這非常便于存儲和檢索。 數據清洗和融合的主要步驟包含:模式對齊、實體識別、沖突消解及數據追蹤。利用語義元數據對清洗和融合規則進行定義,并通過執行該規則達到清洗和融合的目的。 針對清洗和融合規則,使用五元組定義,x=“cleanandfusion”,A=[id,name,description,condition,operation,from_model,to_model,connect_model,script,type],K=[id],Q=[id,name,condition,operation,type,script],f=[],其中:id是規則編號,具有唯一性;name是該處理規則的名稱;description是該規則的描述信息;condition是該規則的執行條件;operation是該規則對應的操作,如:模式對齊、實體識別、沖突消解和數據追蹤;from_model是指該規則對應來源數據的模型;to_model是處理完成后返回的數據的模型;connect_model是處理時所需要的額外的數據模型;script中定義了怎么進行處理相關操作的腳本;type是該腳本的類型,目前可支持JavaScript腳本。 往往一個數據完成清洗和融合操作,需要經過多次清洗和融合規則處理,需要保證不同規則之間處理順序,借助語義元數據可以實現不同規則之間的鏈式處理,即在五元組f中指定下一步清洗和融合的規則id。如果滿足規則中condition的條件則執行編號為id的規則,不斷重復上述步驟便可實現鏈式執行。例如,如圖1所示,從物聯網設備中采集的缺省身份證號碼的血壓數據,在script1中通過與connect_model指定的老人基本信息模型關聯操作,并把補充了身份證號信息的血壓數據輸出到to_model指定的統一血壓數據模型中;同理執行script2便可以把統一血壓模型的數據更新到老人最新健康數據模型中。 圖1 缺省身份證號的血壓數據處理過程 數據可視化和數據訪問需要對數據進行查詢,并把結果以可視化或者接口的形式呈現出來。使用語義元數據,對數據可視化和數據訪問過程進行建模。 數據可視化定義為五元組 數據訪問定義為五元組 本文系統根據實際項目情況,選用SpringCloud作為基礎框架進行開發,使用kafka作為消息通信隊列,使用redis進行緩存,使用mongdb存儲語義元數據,使用mysql存儲用戶數據,使用vue2.0和echarts.js、d3.js作為前端框架。在部署和測試時采用10臺阿里ECS云服務器[19],其配置全部為4核CPU、16 GB內存、200 GB普通硬盤。 本文系統的架構如圖2所示,共分為三層:接入層,清洗融合層,應用層,各層之間通過消息隊列進行通信。接入層主要負責各系統的數據接入、數據與語義元數據模型之間的轉化。清洗和融合層主要用來根據用戶設定的語義元數據模型對數據進清洗、融合和數據存儲。清洗和融合模型中的script是在腳本引擎中進行執行。應用層主要提供數據可視化和數據訪問服務,以及提供界面供用戶設計基于語義元數據的數據模型、清洗融合策略、可視化和訪問方式。 圖2 醫養數據融合系統架構 在數據進行清洗和融合時,為提高系統的靈活性和擴展性,使用腳本引擎鏈式執行相關的腳本。Nashorn是Java語言中最新的腳本引擎,用于取代Rhino,相比于后者具有較好的執行效率[20]。本文使用Nashorn作為清洗融合腳本的執行器,同時又在此基礎上封裝了相關的數據清洗、融合、存儲等方面的API,用于簡化清洗融合的開發,其架構如圖3所示,主要包含三層:引擎層、擴展層和腳本層。引擎層主要包含能夠執行Javascript腳本的Nashorn引擎。擴展層主要是把存儲、模型轉化、清洗、融合和過程控制等功能封裝成相應的語義元數據模型,并提供腳本API,供上層的腳本層調用。腳本層主要是使用者編寫的腳本,用以進行數據清洗和融合以及過程的控制,其編寫的腳本對應清洗融合模型中的script。使用者編寫的腳本可以使用擴展層提供的API,進行數據關聯、數據模型之間的轉化、數據處理和過程控制操作。為了提高模型轉換效率,對相關模型轉換的結果進行緩存,已經緩存的模型在執行時無需再次轉換。 圖3 清洗融合引擎架構 本系統能夠滿足醫養數據融合的需求,在全國多個區域進行了試用,已經接入各類系統二十余個,能夠靈活地對醫養數進行建模,涵蓋了老人、養老機構、醫療等多種類型的數據,為政府機構提供了實時的數據可視化和查詢服務。 圖4為對老人睡眠數據進行建模的界面,說明該系統能夠動態對數據模型進行擴展。圖中屬性名對應語義元數據中的A集合,Q集合元素對應在是否必須列打勾的,K集合元素對應是否為主鍵列打勾的,其余的備注、類型、最大最小值、默認值則設定到f中。 圖4 老人睡眠數據模型 圖5展示的是缺省老人身份證號的老人血壓模型的清洗和融合的腳本。圖中首先到connect_model中查找身份證號碼,然后形成帶有身份證號的血壓數據并返回。 圖5 補充身份證編號的融合腳本 圖6是統計某市養老機構性質占比圖,只需配置數據的來源。圖中對可視化模型的來源、類型、圖例等進行了配置,配置完成后即可查看到相關的可視化界面,如圖7所示。 圖6 機構性質占比可視化模型 圖7 機構性質占比 首先對比了本文設計的系統與傳統硬編碼系統(HardCode)在功能上的區別,傳統的硬編碼系統由研發人員根據項目需要,參照文獻[11],基于Hadoop和Storm進行編碼實現。如表1所示,本文系統支持融合規則的動態修改、數據清理規則的動態修改、動態修改數據可視化等功能,但傳統硬編碼系統不支持。 表1 功能對比 另外,為了滿足系統在數據接入、清洗和融合以及數據訪問在數據接入量較大時的實時性,需要保證系統在處理大數據量時具有較小的響應時間。因此對系統不同數據量下的響應時間進行了實驗,結果如圖8所示。 圖8 不同數據量響應處理時間統計 本次測試的數據來自江蘇某市2018年1月到2018年6月間的老人健康數據、生活數據、護理記錄數據共8.34 GB。數據采集方式有三種:第一種通過可穿戴設備直接采集錄入;第二種是第三方醫療、養老系統通過對接進行數據收集;第三種是護士、醫生、護工等手工錄入。 本次實驗使用了開源的Apache JMeter測試工具編寫測試腳本進行響應時間的測試。分別隨機選取真實的老人健康數據500條、1 000條、1 500條、2 000條測試信息處理響應時間(單位為s)。由圖8可知,隨著數據量的增加,數據處理響應時間緩慢增加,在處理2 000條數據的數據量時響應時間未超過2 s。本文設計的系統響應時間在處理較少數據量時響應時間高于硬編碼系統的響應時間,因為需要進行語義元數據模型轉換,而在數據量較多時,響應時間接近甚至少于硬編碼系統的響應時間,當數據量較多時,本文平臺可以發揮緩存模型的優勢。綜合來看,本文設計的系統能夠滿足平臺在區域內數據融合響應時要求。 本文通過對醫養數據融合中面臨的問題進行分析,基于語義元數據對數據建模、清洗和融合、數據訪問和可視化進行研究,形成靈活性好、可擴展的醫養數據融合系統,并通過相關實驗驗證了該系統能夠滿足醫養數據融合中對大數據量響應時間的要求。本文順應醫療、養老數據不斷融合的大趨勢,為醫療、養老機構更好地服務老人提供技術層面支撐,同時為涉老醫療監管,民政養老監管提供數據支持。隨著大數據分析技術的發展,同時考慮到監管機構對數據分析決策的需求,下一步將在清洗融合數據的基礎上,重點研究基于醫養融合的數據分析技術,并與本文系統進行結合,進一步提高支撐監管機構決策的智能化的水平。2.2 語義元數據與數據清洗和融合

2.3 語義元數據與數據可視化和訪問
3 系統實現和驗證
3.1 系統設計與實現
3.2 應用案例

3.3 綜合性能對比

4 結 語
猜你喜歡
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
開放教育研究(2020年2期)2020-03-31 01:54:14
傳媒評論(2019年4期)2019-07-13 05:49:14
基層中醫藥(2018年2期)2018-05-31 08:45:06
民生周刊(2017年19期)2017-10-25 15:47:39
華人時刊(2017年19期)2017-02-03 02:51:37
現代語文(2016年21期)2016-05-25 13:13:44
大社會(2016年5期)2016-05-04 03:41:44
