一種IT領(lǐng)域術(shù)語識別系統(tǒng)的設(shè)計與實現(xiàn)
2020-05-06 09:01:57木合亞提·尼亞孜別克古力沙吾利·塔里甫
中國科技術(shù)語 2020年2期
木合亞提·尼亞孜別克 古力沙吾利·塔里甫

摘 要:針對信息領(lǐng)域的術(shù)語識別平臺的設(shè)計和開發(fā)是對該領(lǐng)域術(shù)語資源進(jìn)行更有效利用的重要手段之一。文章闡述了信息領(lǐng)域的哈薩克語術(shù)語識別平臺的設(shè)計,該平臺采用條件隨機(jī)場和人工修改的方法,基于信息領(lǐng)域術(shù)語本身的特點分析了該領(lǐng)域術(shù)語的構(gòu)成規(guī)則及相關(guān)術(shù)語識別方法。
關(guān)鍵詞:信息領(lǐng)域;術(shù)語識別;系統(tǒng)設(shè)計
Abstract:The design and development of the terminology recognition platform in information technology field is one of the important means for more effective use of term resources. This paper describes the design of Kazakh language terminology recognition platform in the information technology field. Based on the characteristics of the information technology field terminology, the platform analyzes the rules of terminology formation and related terminology identification methods using a conditional random field (CRF) and manual modification method.
Keywords:information technology field; terminology recognition; system design
引 言
隨著中文各語言信息處理應(yīng)用領(lǐng)域的不斷擴(kuò)展,對于不同語言不同領(lǐng)域術(shù)語的檢索需求也越顯迫切。其中以計算機(jī)作為工具的哈薩克語信息技術(shù)領(lǐng)域術(shù)語識別平臺的構(gòu)建對哈薩克語自然語言信息處理、哈薩克語語言學(xué)研究、信息安全檢索、機(jī)器翻譯、語料庫建設(shè)、IT領(lǐng)域術(shù)語庫等民族語言信息化建設(shè)的作用日顯重要[1]。術(shù)語是代表特定學(xué)科領(lǐng)域基本概念的語言單元,是該領(lǐng)域核心知識的體現(xiàn),方便人們快速獲取專業(yè)知識,如何自動獲取術(shù)語自然也成為相關(guān)專業(yè)人員的研究熱點。術(shù)語自動抽取是信息處理領(lǐng)域中一項重要的研究任務(wù),在詞典編纂、本體構(gòu)建、機(jī)器翻譯等領(lǐng)域都有重要應(yīng)用。術(shù)語抽取技術(shù)是大規(guī)模本體工程自動或半自動構(gòu)建、擴(kuò)充的關(guān)鍵技術(shù)之一。近年來,人們已經(jīng)認(rèn)識到了術(shù)語抽取方法的重要性并進(jìn)行了大量研究,而目前廣泛采用的術(shù)語提取思想主要分為基于統(tǒng)計學(xué)、基于機(jī)器學(xué)習(xí)、基于語言學(xué)和多種思想結(jié)合的混合方法。本文闡述的系統(tǒng)設(shè)計為結(jié)合語言學(xué)規(guī)則,并采用條件隨機(jī)場(conditional random fields,CRF)和人工修改的方法。望通過信息領(lǐng)域哈薩克語術(shù)語識別系統(tǒng)的設(shè)計實現(xiàn),對民族文化的挖掘、傳承、創(chuàng)新及民族科技教育工作和社會安全、穩(wěn)定與繁榮發(fā)展盡一份力。
一 系統(tǒng)設(shè)計
本系統(tǒng)是基于各類哈薩克文網(wǎng)站及中小學(xué)信息技術(shù)教材中獲取的各種文本的電子版語料,通過目前多語種信息技術(shù)實驗室使用的各種語言語料工具進(jìn)行原始語料的詞法分析后獲得的已經(jīng)完成單詞提取、詞綴提取和詞性標(biāo)注的熟語料。在輸入基于規(guī)則的哈薩克語信息技術(shù)領(lǐng)域術(shù)語抽取系統(tǒng)中的熟語料后,通過領(lǐng)域術(shù)語詞典和術(shù)語聚類規(guī)則庫進(jìn)一步過濾得到最終的術(shù)語生成候選術(shù)語和候選術(shù)語標(biāo)注語料[2-4]。再通過修改將候選術(shù)語標(biāo)注語料生成為訓(xùn)練語料。系統(tǒng)具體流程如圖1所示。
二 系統(tǒng)功能模塊
從系統(tǒng)功能角度出發(fā),以隨機(jī)場的方法為處理哈薩克信息技術(shù)術(shù)語抽取問題的提取條件,將哈薩克語信息技術(shù)領(lǐng)域術(shù)語識別看作一個序列詞性標(biāo)注問題,將哈薩克語信息技術(shù)領(lǐng)域術(shù)語分布的特征量化作為系統(tǒng)的訓(xùn)練的特征,利用條件隨機(jī)場(CRF)的工具包訓(xùn)練出哈薩克語信息技術(shù)領(lǐng)域術(shù)語特征模板。整個系統(tǒng)可分為術(shù)語標(biāo)注語料庫和CRF模式識別兩個子系統(tǒng),術(shù)語標(biāo)注語料庫子系統(tǒng)還包括預(yù)處理部分、生成訓(xùn)練語料部分、術(shù)語識別部分、術(shù)語抽取部分、定界規(guī)則部分等,另一個CRF模式子系統(tǒng)還包括模型參數(shù)部分、特征選擇部分、特征模板選取部分等。系統(tǒng)功能模塊如圖2所示。
三 系統(tǒng)主界面
整個系統(tǒng)由術(shù)語抽取、生成訓(xùn)練語料、術(shù)語識別、退出系統(tǒng)等四個部分組成。術(shù)語抽取部分可以進(jìn)行術(shù)語的打開、抽取、保存、退出等操作步驟,生成訓(xùn)練語料、術(shù)語識別部分進(jìn)入后也有各自不同的操作界面。系統(tǒng)主界面如圖3所示。
1. 術(shù)語抽取
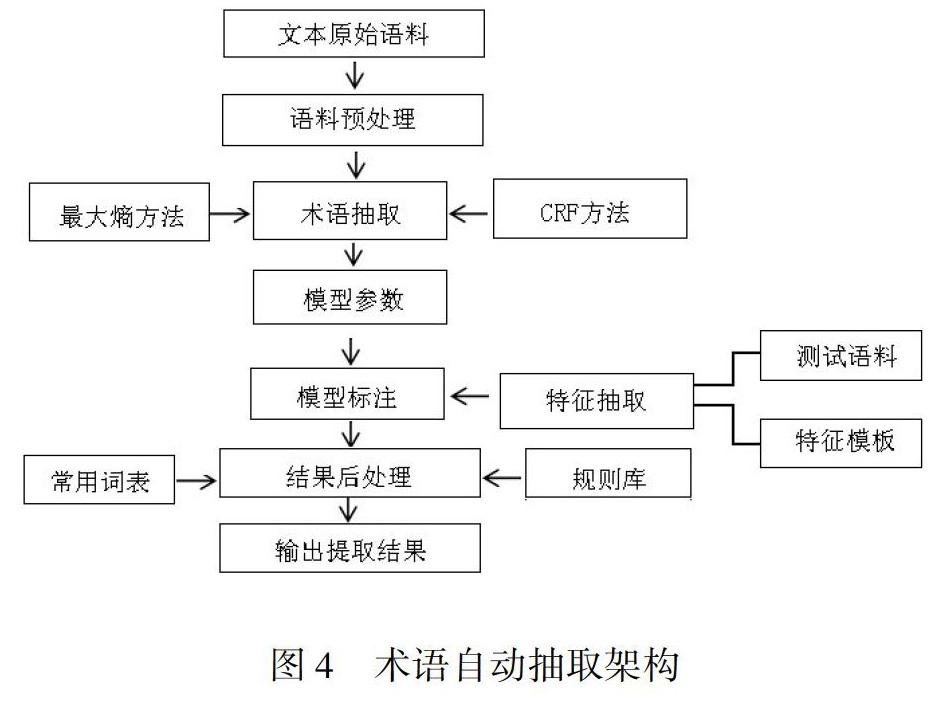
因存在單詞術(shù)語、多詞術(shù)語等區(qū)別,不同的語言中術(shù)語組成形式也不同,例如名詞+名詞、形容詞+名詞、名詞+動詞等,故術(shù)語抽取將根據(jù)語言特點及術(shù)語的組成結(jié)構(gòu)來界定抽取規(guī)則。該模塊主要為相關(guān)的資料中的術(shù)語抽取,進(jìn)入頁面后分左右兩個界面,左側(cè)可以進(jìn)行文件打開、抽取、保存、退出、術(shù)語統(tǒng)計等操作,右側(cè)顯示已抽取的術(shù)語及抽取個數(shù)等信息。系統(tǒng)的術(shù)語抽取架構(gòu)圖詳細(xì)操作界面如圖4所示。
2.生成訓(xùn)練語料
IT術(shù)語語料庫中存放的語言材料均在語言的實際使用中真實出現(xiàn)過,是以電子計算機(jī)為載體承載語言知識的基礎(chǔ)資源,真實語料需經(jīng)過加工才能成為有用資源。以系統(tǒng)中的熟語料作為輸入,依語言學(xué)規(guī)則自給定文檔中抽取術(shù)語,再經(jīng)過進(jìn)一步修改過程后生成訓(xùn)練語料。術(shù)語本身可以是詞也可以是詞組,哈薩克語IT領(lǐng)域術(shù)語結(jié)構(gòu)多種多樣,有些術(shù)語由一個詞或兩個詞連接組成,也有些術(shù)語由不同的附加成分或者嵌套組成,構(gòu)成形式有名詞+名詞、形容詞+名詞、名詞+動詞等。生成訓(xùn)練語料部分包括打開XML文件、打開術(shù)語文件、XML文件中標(biāo)注術(shù)語、保存標(biāo)注文件等模塊,可根據(jù)需要進(jìn)一步進(jìn)行相關(guān)操作,如打開術(shù)語庫文件進(jìn)行XML標(biāo)注等[5-8]。界面上也包括上一個、下一個或者上一段、下一段等選項,每個選項都有不同的階段性的操作步驟,生成訓(xùn)練語料模塊詳細(xì)操作界面如圖5所示。
3.術(shù)語識別
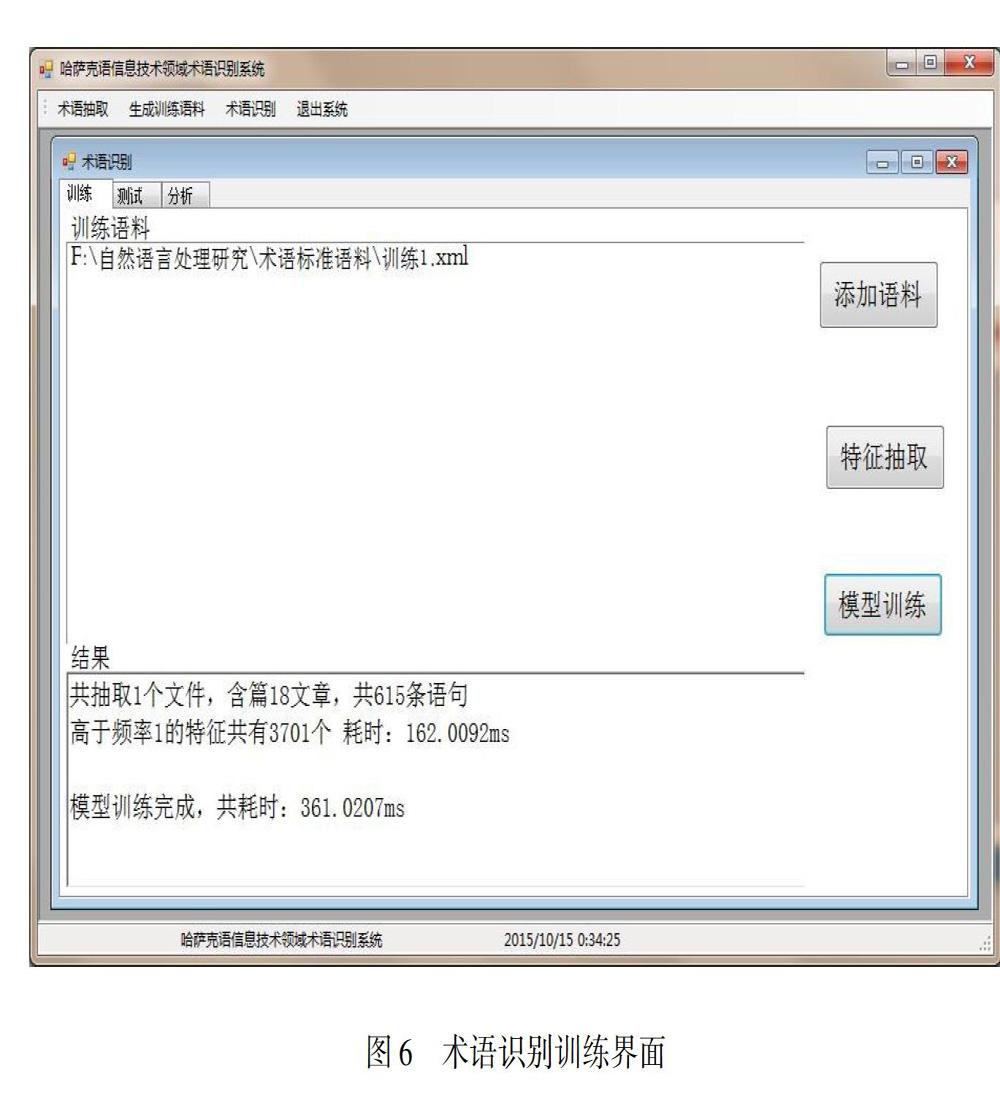
該模塊包括訓(xùn)練、測試、分析三個部分,不同的操作界面自不同部分進(jìn)入。進(jìn)入訓(xùn)練語料部分后,可見添加語料、特征抽取、模型訓(xùn)練等選項,每個選項中可繼續(xù)進(jìn)行相應(yīng)操作。測試模塊包括測試語料、術(shù)語識別、保存結(jié)果及快速測試等部分,分析模塊中可顯示正確識別的術(shù)語個數(shù)、錯誤識別的術(shù)語個數(shù)、系統(tǒng)標(biāo)注為術(shù)語的個數(shù)、未判斷的術(shù)語個數(shù)、準(zhǔn)確率、召回率、F值等內(nèi)容。術(shù)語識別方法都已先預(yù)選,即首先候選出候選術(shù)語,哈薩克語雖屬于黏著語,但I(xiàn)T術(shù)語的詞性具有一定的規(guī)律性,通過分析、觀察,寫出IT術(shù)語的詞性規(guī)則表,再利用規(guī)則和已標(biāo)注好詞性的文本進(jìn)行匹配,抽取相應(yīng)的詞或者詞組作為候選術(shù)語。系統(tǒng)的術(shù)語識別訓(xùn)練語料操作界面如圖6所示。
四 結(jié) 語
術(shù)語識別平臺的建設(shè)是一個周期長、數(shù)據(jù)需求量大的大型工程。而針對信息領(lǐng)域的術(shù)語僅完成了原始數(shù)據(jù)的收集工作與基本信息的整理工作,術(shù)語識別系統(tǒng)的構(gòu)建還處于初始階段,任重而道遠(yuǎn)。相關(guān)專業(yè)人員還需不懈努力,提升加工處理和分析語料工具的技術(shù)方法,不斷完善該系統(tǒng)的建設(shè),才能進(jìn)一步滿足哈薩克語語言學(xué)信息研究的多種需要。
參考文獻(xiàn)
[1] 戴慶廈,趙小兵.中國少數(shù)民族語言文字信息處理研究與發(fā)展[M].北京:民族出版社,2010.
[2] 木合亞提·尼亞孜別克,古力沙吾利·塔里甫,達(dá)吾勒·阿布都哈依爾.采用CRF模型的哈薩克語信息技術(shù)術(shù)語自動抽取技術(shù)研究[J].西北師范大學(xué)學(xué)報:自然科學(xué)版,2016,52(1):53-56.
[3] 鄭家恒,張虎,譚紅葉,等.智能信息處理:漢語語料庫加工技術(shù)及應(yīng)用[M].北京:科學(xué)出版社,2010.
[4] 木合亞提·尼亞孜別克,古力沙吾利·塔里甫.哈薩克語IT領(lǐng)域術(shù)語識別研究與實現(xiàn)[J].中文信息學(xué)報,2016,30(3):68-73.
[5] 哈斯.蒙古語語料庫語言資源管理平臺的設(shè)計與實現(xiàn)[J].內(nèi)蒙古師范大學(xué)學(xué)報:自然科學(xué)漢文版,2008,37(6):743-745.
[6] 木合亞提·尼亞孜別克,古力沙吾利·塔里甫.哈薩克文信息處理現(xiàn)狀中的若干問題探討[J].智能計算機(jī)與應(yīng)用,2011,1(4):45-46.
[7] 劉劍,唐慧豐,劉伍穎.一種基于統(tǒng)計技術(shù)的中文術(shù)語抽取方法[J].中國科技術(shù)語,2014,16(5):10-14.
[8] 張榕.面向術(shù)語識別的術(shù)語界定研究[J].中國科技術(shù)語,2014,16(4):5-8.
