基于分布式的算法封裝技術研究與應用
2020-04-26 07:41:42和志成
通信電源技術 2020年23期
李 輝,和志成
(1.云南電網有限責任公司信息中心,云南 昆明 650011;2.玉溪供電局,云南 玉溪 653100)
0 引 言
隨著大數據時代的到來,電力行業有關數據的存儲總量已達一定規模。這些數據蘊含豐富的知識,若能從中挖掘有關模式,將有利于電力行業的發展。為建設快速靈活、簡便易用、支持分布式以及可復用的企業算法中臺,需要充分考慮算法封裝方法及分布式架構的設計與實現,使其兼具實用性與易用性。本文提出了一種基于分布式的算法封裝框架,該框架不僅能夠支持分布式并行計算,而且融合了算法優化、參數擇優以及數據采樣等多種功能,能夠滿足電力行業數據分析方向的基本需要。
傳統的算法封裝框架有Weka、MADLib以及Mahout。Weka是一個用于數據挖掘的機器學習工具包,它的UI非常簡單,但需要專業人員來選擇合適的機器學習算法并調整有關參數,這降低了它的易用性。此外,Weka還是一個單節點式的,無法實現分布式計算,即無法滿足并行化數據分析的需要。在數據庫和分布式領域,Mahout的目標是建立一個可擴展的機器學習庫,它是Hadoop技術棧的一部分。MADLib則為關系型數據庫提供機器學習庫。這些框架的共同點是沒有自動的算法優化過程,然而這個過程對于非專業數據分析人員來說非常重要。
Google Predict是谷歌開發的Web服務,用于解決預測類問題,但它能支持最大訓練數據量僅為250 MB,遠遠無法滿足人們的需求。文獻[1]提出了數據庫應該原生支持預測模型的觀點,并基于此觀點展示了一個稱為Longview的模型。近期,在針對新型分析任務的分布式實時計算領域有很多重要的發現,如Hyracks和AMPLab’s Spark均支持基于內存的迭代式計算,能夠對機器學習算法起到很好的支撐作用。SystemML提供了一個類R語言的功能,并且提供了算法優化功能,最后將它編譯到MapReduce中,該思想值得借鑒。但是,SystemML嘗試支持機器學習專家來對分布式算法進行開發而忽略了對算法易用性的考慮。文獻[2]表明很多機器學習算法都能夠被簡化為一個凸優化問題,文獻[3]展示了一種在概率數據庫中對算法進行優化的技術。
1 框架結構
如圖1所示,框架主要結構由驅動器、執行器以及集群管理器所構成。驅動器是框架的核心,它位于集群的某個節點上,主要負責以下內容。一是維護會話,以保存應用程序的相關信息,二是和用戶進行交互,管理輸入輸出,三是分析任務并將任務分發至執行器。執行器接收驅動器分配的任務并執行,然后將計算結果狀態返回給驅動器。集群管理器負責計算資源的統一調度,將計算資源統一按某種策略分配給應用程序[4]。
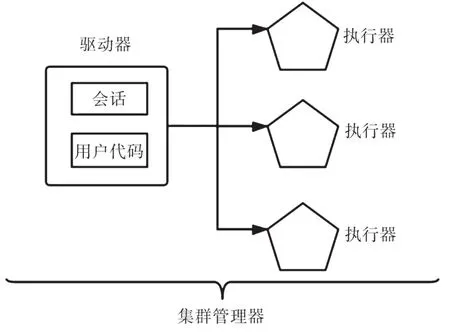
圖1 框架結構
2 框架原理
如圖2所示,當用戶將聲明式機器學習任務作為請求輸入后,框架將對其進行解析。解析后的請求會經歷兩個階段。第一個階段稱為計劃階段,該階段不對具體數據進行操作,而僅僅用于描述完成用戶請求的通用流水線。該流水線涉及算法選擇、特征工程、算法調參以及數據采樣等功能。此外,框架內部會自動搜索優化空間來對此階段進行優化。第二個階段稱為執行階段,它是由計劃階段轉化過來的。一個執行階段主要包含一系列的可執行操作,如過濾或特征值縮放,這些操作和MapReduce所實現的功能類似[5]。與計劃階段不同的是,執行階段使用具體參數對數據集進行測試。在測試過程中,主節點會將這些任務分配到從節點上執行。執行的過程有兩種,所產生的結果也會不同。一種是對數據特征進行處理,如數據降維等,所產生的結果是數據的某種表現形式,可用于后續預測或數據綜述;另一種是利用數據對模型進行訓練,所產生的結果即是已經訓練好的模型。同時,框架會總結模型的訓練過程,以便于用戶了解詳細情況[6]。
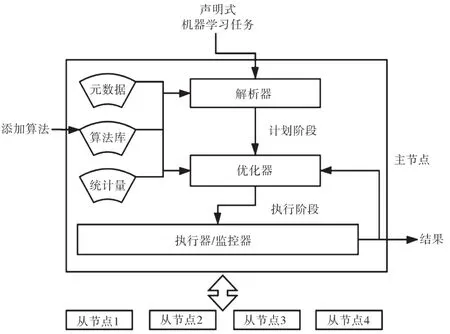
圖2 內部流程
當獲取到第一次計算結果時,計算任務仍未結束,而是會通過額外的探索來提高模型性能。在每一次計算過程中,框架會將中間步驟存儲起來,包括已訓練的模型、處理過的特征值以及和模型相應的核心統計指標。根據指標比對,可能會修改計劃以提高模型的最終效果[7]。
用戶提交當前請求后,在提交下一個請求之前,框架不會閑置,而是會持續在后臺搜索當前請求的更優解。若發現更優解,即質量更好的算法或參數,它會及時通知用戶。
框架優勢如下,一是通過讓用戶早期對初始模型進行評估試驗,使其具備交互性特點,二是使得用戶創建整個數據處理流水線變得更容易,三是降低了早停的風險,四是當用戶輸入新數據時,它能夠立即使用新數據更新模型并提升模型性能,即實現在線學習,五是框架具有良好的可擴展性,能夠容納新型機器學習算法[8]。一旦有需求,開發者就能通過指定的協議將新的機器學習算法源源不斷地添加到算法庫中。協議明確了算法的類別(如聚類算法)、參數以及時間復雜度等。
3 算法優化過程
框架內部集成了算法優化的功能,主要體現在計劃階段。算法優化需要用到優化器,優化器通過參數調整和數據采樣多種策略組合優化已有的計劃階段,然后進行評估。為了滿足時間約束條件,優化器將基于統計模型,利用啟發式算法及最新的模型選擇工具來估計流水線的執行時間和算法綜合表現[9]。優化器能夠根據已有數據的表征形式來估計模型的運行時間。針對每一個模型,優化器會估計它的效果,選出一個最佳候選。
圖3顯示了一個具體的優化過程。在該過程中,優化器對數據進行特征標準化并采樣,接下來優化器采用10折交叉驗證進行檢驗。在每次實驗中,將其中一份數據用于驗證[10]。評價指標則采用通用標簽基線準則、誤分類率以及近鄰數。需要注意的是,最終的模型仍然是用全量數據集生成的。此外,優化器能夠建立多維索引結構并提前完成距離矩陣的計算工作,以便對算法進行加速。
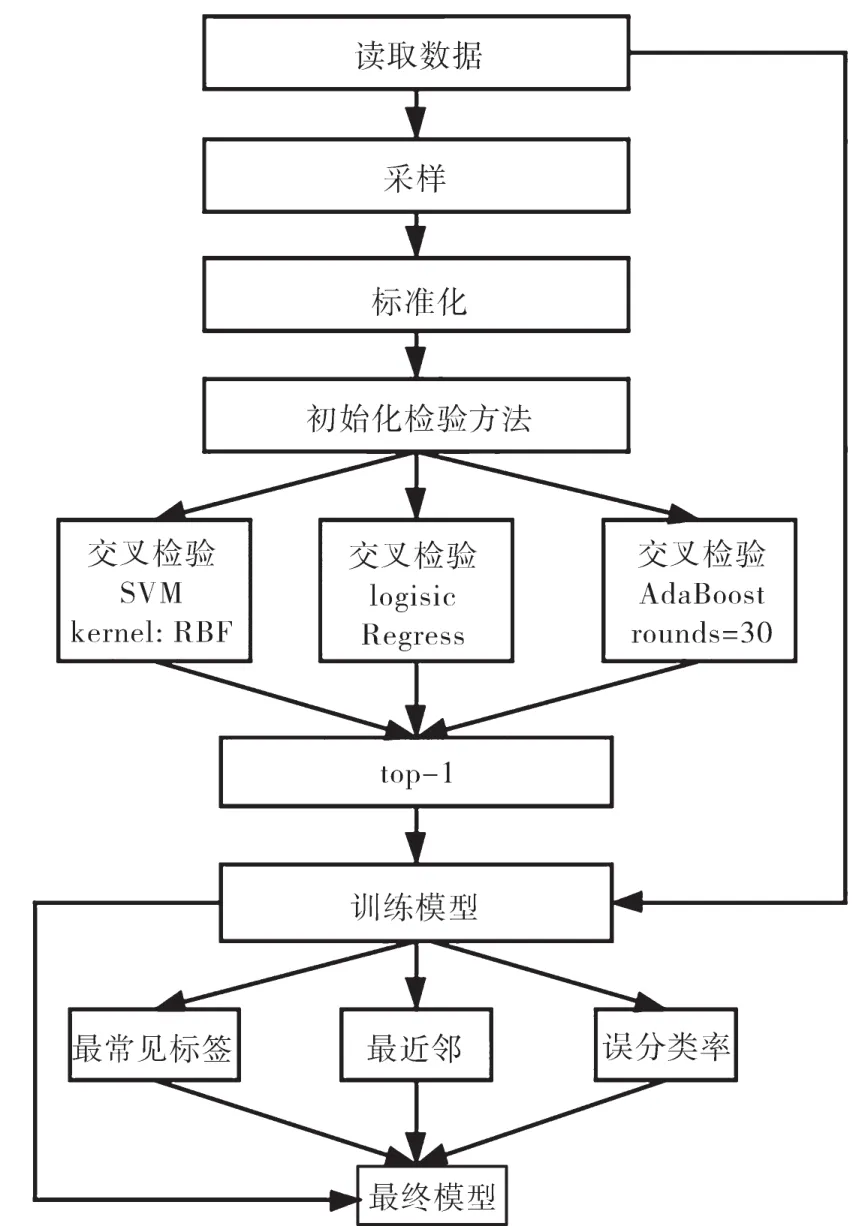
圖3 算法優化步驟
4 實例分析
驅動器運行在客戶端,因此不受主節點的管理和約束。執行器則不同,它運行在集群中的從節點上,因此會受到主節點的管理和約束。一個分布式應用程序在集群中的流程如下:(1)用戶向客戶端提交應用程序,本機啟動驅動器;(2)客戶端向集群提交應用程序、所需執行器的數目及相應資源;(3)主結點收到請求,根據合適的調度策略,尋找從結點并啟動執行器;(4)執行器與驅動器建立連接;(5)執行器分配并調度任務;(6)所有任務運行完畢,應用程序退出。
5 結 論
本文根據電力行業對于數據分析的需求及特點,提出了一種面向行業的分布式算法封裝框架。該框架具有輕便、智能、可擴容以及支持并行化等特點。本文所涉及的主要內容如下,一是基于主從模式和實時內存計算實現了分布式并行計算框架,為海量數據計算提供基礎支撐。二是通過設計優化器,將聲明式機器學習任務轉換成精密的學習計劃。在這個過程中,優化器在后臺嘗試快速給用戶返回一個優質的算法,讓用戶避開了煩瑣的算法選擇過程。此外,本文展示了在分布式架構基礎上優化器的強大潛力,為非專業開發人員進行數據分析提供了較好的幫助。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
