基于神經(jīng)網(wǎng)絡(luò)方法的圖像描述研究綜述
2020-04-22 23:38:50劉浩
現(xiàn)代計算機(jī) 2020年8期
劉浩
(四川大學(xué)計算機(jī)學(xué)院,成都610065)
0 引言
視覺理解一直是計算機(jī)視覺領(lǐng)域的基礎(chǔ)任務(wù),這有助于計算機(jī)更好地理解這個多維世界,為將來人工智能全方位服務(wù)人類提供可能。其中Image Caption(圖像描述)是一個融合計算機(jī)視覺和自然語言處理的綜合問題,該任務(wù)對于人類來說非常容易,但是受限于不同領(lǐng)域的結(jié)合,要求機(jī)器去理解圖片的內(nèi)容并且還要用自然語言去表達(dá)它們之間的關(guān)系卻非常具有挑戰(zhàn)性。這不僅要求機(jī)器生成準(zhǔn)確的、通順的人類可讀的句子,而且還要求句子的內(nèi)容能充分表現(xiàn)圖像的內(nèi)容。受益于神經(jīng)網(wǎng)絡(luò)技術(shù)的發(fā)展和大數(shù)據(jù)的興起,近些年不斷有關(guān)于Image Caption 任務(wù)的創(chuàng)新方法被提出,其中不乏一些具有開創(chuàng)性意義的方法,為Image Caption 任務(wù)的研究與發(fā)展做出了巨大的貢獻(xiàn)。
1 相關(guān)工作
早期關(guān)于Image Caption 任務(wù)的做法例如由Kulkarni 等人[1]和Farhadi 等人[2]提出的方法都是利用圖像處理的一些算子提取出圖像的特征,經(jīng)過SVM(支持向量機(jī))分類等方法得到圖像中可能存在的目標(biāo)。然后根據(jù)提取出的目標(biāo)以及他們的屬性利用CRF(條件隨機(jī)場)或者是一些預(yù)先制定的規(guī)則來恢復(fù)成對圖像的描述。這種做法非常依賴于圖像特征的提取和生成句子時所需要的規(guī)則。自然而然這種效果并不理想。
在Vinyals 等人[3]提出的方法出現(xiàn)之前,利用RNN(循環(huán)神經(jīng)網(wǎng)絡(luò))做機(jī)器翻譯實際上已經(jīng)取得了非常不錯的成果。常用的做法是利用Encoder RNN(編碼器RNN)讀入源語言文字生成中間隱層變量,然后利用Decoder RNN(解碼器RNN)讀入中間隱層變量,逐步生成目標(biāo)語言文字。受到這種啟發(fā),以Vinyals 為代表的谷歌團(tuán)隊將機(jī)器翻譯中編碼源文字的RNN 替換成CNN(卷積神經(jīng)網(wǎng)絡(luò))來編碼圖像,希望通過這種方式來獲得圖像的描述。而且由于普通RNN 存在梯度下降的問題,RNN 只能記憶之前有限的時間單元內(nèi)容,所以谷歌團(tuán)隊在Decoder 階段使用了特殊的RNN 架構(gòu)——LSTM(長短期記憶),其具有長期記憶,解決了梯度消失的問題。這種Encoder-Decoder 框架取得了不錯的效果,為后人做Image Caption 任務(wù)提供了一條鮮明的道路。
2015 年微軟舉辦了一屆Image Caption 比賽,最終的結(jié)果是由兩篇論文并列第一,其中一篇就是上文提到的谷歌團(tuán)隊的論文,另一篇為微軟自家的作品,F(xiàn)ang等人[4]先通過目標(biāo)檢測和物體識別的方法把圖像中的實體詞都識別出來,然后再對語言進(jìn)行建模,進(jìn)行造句。實體詞相關(guān)之間的連接詞是構(gòu)造完整句子的核心,所以Fang 等人使用了弱監(jiān)督方法進(jìn)行造句。
受attention(注意力)機(jī)制在機(jī)器翻譯中發(fā)展的啟發(fā),Xu 等人[5]在傳統(tǒng)的Encoder-Decoder 框架引入了attention 機(jī)制,顯著的提高了Image Caption 任務(wù)的性能。具體做法為在圖像的卷積特征中結(jié)合空間attention 機(jī)制,將圖像上下文向量輸入到Encoder-Decoder框架中,該向量是當(dāng)前時刻圖像的顯著區(qū)域的特征表達(dá)。這樣就有了包含位置信息的特征,Decoder 在解碼時期就擁有了在位置特征中選擇的能力。
在Image Caption 任務(wù)的一般結(jié)果中,有些描述性詞匯可能并不直接和圖像相關(guān),而是可以從當(dāng)前已經(jīng)生成的描述語句中推測出來,換而言之,某些描述語句的關(guān)鍵部分的生成可能依賴于圖像特征,也可能依賴于語言模型,所以Lu 等人[6]提出了一種自適應(yīng)性的attention 機(jī)制,使得模型可以自己決定在生成單詞的時候是根據(jù)先驗知識還是根據(jù)圖像中的模板。
Wu 等人[7]在2016 年提出了新的Image Caption 方法,他們摒棄了以前使用全局圖像信息作為圖像特征的方法,繼而使用圖像多標(biāo)簽分類的方法來提取圖像中可能存在的屬性。該方法相當(dāng)于保留了圖像的高層語義信息,不僅在Image Caption 上取得了不錯的結(jié)果,在VQA(視覺圖像的自然語言回答)問題上,也取得很好的成績。
2017 年Chen 等人[8]從CNN 入手對模型進(jìn)行改進(jìn)。Chen 等人分析了CNN 的特性,包括其空間性、多通道和多層級,最終提出在網(wǎng)絡(luò)的multi-layer 上用通道attention 和空間attention 結(jié)合的方式來做Image Caption。通道attention 機(jī)制的本質(zhì)是訓(xùn)練一個權(quán)重,然后這個權(quán)重可以用來對通道做選擇或者疊加在feature map(特征地圖)的每個像素點上,使得每次網(wǎng)絡(luò)的關(guān)注點可能只是圖像中的一個小部分,這也符合人類視覺系統(tǒng)的動態(tài)特征提取機(jī)制。這種方法使得Encoder-Decoder 模型的性能進(jìn)一步得到了提高。
2018 年attention 機(jī)制在Image Caption 的應(yīng)用繼續(xù)得到了擴(kuò)展,Anderson 等人[9]提出了一個新的LSTM組合模型,包括了Attention LSTM 和語言LSTM 兩個組件。其中Attention LSTM 機(jī)制是top-down(自上而下)和bottom-up(自下而上)組合起來得到的聯(lián)合attention機(jī)制,bottom-up 機(jī)制基于Faster R-CNN(一種被廣泛應(yīng)用于目標(biāo)檢測的技術(shù))來提取圖像區(qū)域,確定每個區(qū)域的特征向量。而top-down 機(jī)制確定特征權(quán)重。此方法沒有提及在目前研究中最為廣泛使用的Encoder-Decoder 框架,而是使用了自己創(chuàng)新的attention 模型,bottom-up 模型的任務(wù)是獲取圖像興趣區(qū)域和提取圖像特征,類似于對圖像進(jìn)行特征編碼,而top-down 模型用于學(xué)習(xí)調(diào)整特征權(quán)重,實現(xiàn)了圖像內(nèi)容的“時刻關(guān)注”,逐詞生成描述,相當(dāng)于解碼階段。從實驗結(jié)果看,Anderson 等人所提的方法的確獲得良好結(jié)果。
在Image Caption 任務(wù)中,常規(guī)的Encoder-Decoder框架都是利用檢測網(wǎng)絡(luò),如CNN 提取特征,然后送到Decoder 端進(jìn)行解碼生成句子。Yang 等人[10]在2019 年的文章中引入了場景圖模型。利用GCN(圖卷積網(wǎng)絡(luò))將圖中檢測得到的目標(biāo)和其自身的屬性,以及其他目標(biāo)之間的關(guān)系融合在一起作為網(wǎng)絡(luò)的輸入。另外,Yang 受到利用working memory(工作記憶)能夠保存動態(tài)知識庫的啟發(fā),提出了一個共享字典的結(jié)構(gòu),先在文本語料庫上進(jìn)行預(yù)訓(xùn)練,最后為圖像生成描述時,利用在語料庫中學(xué)到的先驗知識使生成的語句信息更加豐富。
2 數(shù)據(jù)集
到目前為止,神經(jīng)網(wǎng)絡(luò)依舊是一種需要大量數(shù)據(jù)來進(jìn)行驅(qū)動的方法,小樣本學(xué)習(xí)尚未有突破性的進(jìn)展,所以數(shù)據(jù)對于基于神經(jīng)網(wǎng)絡(luò)的算法依舊非常重要。在Image Caption 問題研究的過程中,研究者們對于數(shù)據(jù)集的選擇偏好也在發(fā)生變化,一些數(shù)據(jù)集運用的越來越廣泛,而一些數(shù)據(jù)集則越來越少地被使用。目前Image Caption 任務(wù)應(yīng)用比較廣泛的數(shù)據(jù)集主要是Flickr8K、Flickr30K 和Microsoft COCO,它們的數(shù)據(jù)量的大概分布見表1。
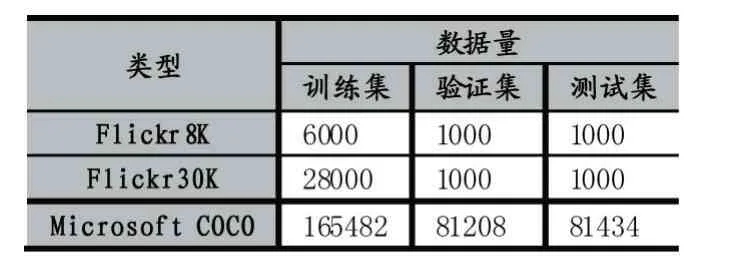
表1 Image Caption 常用數(shù)據(jù)集數(shù)據(jù)量分布
Flickr8K 和Flickr30K 數(shù)據(jù)集來自于雅虎的相冊網(wǎng)站Flickr,數(shù)據(jù)集中的數(shù)量分別是8000 張和30000張(準(zhǔn)確地說是31783 張)。這兩個數(shù)據(jù)集中的圖像大多展示的是人類在參與到某項活動中的情景。每張圖像對應(yīng)人工標(biāo)注的五句話。
Microsoft COCO 數(shù)據(jù)集[11]是微軟團(tuán)隊推出的一個可以用來做圖像識別、分割和描述的數(shù)據(jù)集。這個數(shù)據(jù)集以場景理解為目標(biāo),主要從復(fù)雜的日常場景中截取,圖像中的目標(biāo)通過精確的分割進(jìn)行位置的標(biāo)定,并且使用亞馬遜公司的Mechanical Turk(土耳其機(jī)器人)服務(wù)人工地為每張圖像都生成了最少5 句標(biāo)注,標(biāo)注語句總共超過了150 萬句。實際上COCO Caption 數(shù)據(jù)集包含了兩個數(shù)據(jù)集,第一個數(shù)據(jù)集是MS COCO c5。它包含的訓(xùn)練集、驗證集合測試集圖像和原始的MS COCO 數(shù)據(jù)庫是一致的,只不過每個圖像都帶有5個人工生成的標(biāo)注語句。第二個數(shù)據(jù)集是MS COCO c40。它只包含5000 張圖片,而且這些圖像是從MS COCO 數(shù)據(jù)集的測試集中隨機(jī)選出的。和c5 不同的是,它的每張圖像都有用40 個人工生成的標(biāo)注語句。
Microsoft COCO 數(shù)據(jù)集還有一個巨大的貢獻(xiàn)就是搭建了一個評價服務(wù)器,實現(xiàn)了當(dāng)前最流行的評價標(biāo)準(zhǔn)(BLEU、METEOR、ROUGE 和CIDEr)。就目前發(fā)表的高水平論文來看,MS COCO Caption 數(shù)據(jù)集已經(jīng)越來越成為研究者的首選。
3 結(jié)語
總的來說,近些年的Image Caption 主要研究分為以下幾個方向:
(1)用單獨的CNN 來獲取圖像的特征,然后利用這些特征來生成句子;
(2)將CNN 獲取的特征和描述特征聯(lián)合嵌入到一個空間內(nèi),然后從中選擇最優(yōu)進(jìn)行描述;
(3)將CNN 和RNN 進(jìn)行結(jié)合,目的在于利用CNN的全局特征或者局部特征來指導(dǎo)描述的生成;
(4)利用一些全新的進(jìn)制對經(jīng)典模型進(jìn)行改進(jìn),比如加入注意力機(jī)制、加入視覺哨兵機(jī)制、利用強(qiáng)化學(xué)習(xí)來訓(xùn)練模型以及利用目標(biāo)檢測技術(shù)來改進(jìn)模型等。
研究Image Caption 的價值是顯而易見的,可以應(yīng)用到圖像檢索、兒童教育和視力受損人士的生活輔助等方面。相信隨著更多豐富數(shù)據(jù)集的出現(xiàn)和越來越高效的學(xué)術(shù)方法被提出,由機(jī)器進(jìn)行的Image Caption 任務(wù)也會越來越高效,越來越接近人類所能做到的水準(zhǔn),為人工智能全方位服務(wù)人類提供可能。
本文認(rèn)為,Image Caption 未來的研究方向要在關(guān)于圖像的內(nèi)容的描述語句滿足必要的準(zhǔn)確性和流暢性的基礎(chǔ)上,更追求圖像中細(xì)節(jié)元素的表現(xiàn),使Image Caption 任務(wù)的結(jié)果是更加豐富更加詳細(xì)的圖像內(nèi)容信息的表現(xiàn)。
猜你喜歡
中等數(shù)學(xué)(2022年2期)2022-06-05 07:10:50
小學(xué)生學(xué)習(xí)指導(dǎo)(低年級)(2020年6期)2020-07-25 02:31:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
文苑(2018年21期)2018-11-09 01:23:06
小學(xué)生學(xué)習(xí)指導(dǎo)(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國衛(wèi)生(2015年9期)2015-11-10 03:11:12
中國衛(wèi)生(2014年3期)2014-11-12 13:18:12
