基于網絡爬蟲的網絡平臺用戶數據獲取與分析
2020-04-20 11:48:27李世杰高雅蓉
計算機與網絡 2020年1期
李世杰 高雅蓉
摘要:社交網絡平臺擁有海量的用戶數據,為了更好地實現這些數據的價值,設計了一個基于Java的網絡爬蟲系統,用來獲取和分析某大型社交網絡平臺上的用戶數據。該系統通過特定用戶的URL來獲取基本信息,不斷裂變獲取相關用戶的數據信息。同時將該用戶信息以記錄的形式存儲在用戶明細表中,利用系統對記錄信息的分析,得出不同類別的圖表分析圖,并直觀地進行展示。該系統具有針對性強、數據采集速度快和分析結果直觀等優點,為社會關系和輿情分析等研究提供了新方法。
關鍵詞:網絡爬蟲;用戶數據;Java;裂變
中圖分類號:TP391文獻標志碼:A文章編號:1008-1739(2020)01-68-4

0引言
近年來,社交網絡平臺的發展極為迅速,目前已經出現多個用戶突破1億的平臺,擁有非常龐大的用戶數據,所以有效獲取和分析這些數據對于研究人類社會和經濟的潛在規律至關重要。傳統的數據收集是通過搜索引擎來進行的,但是對具體平臺進行特定數據抓取時,通過搜索引擎就無法有效完成,需要設計專門的網絡爬蟲系統來獲取特定數據。Python語言常被用于爬蟲程序編寫,但相比Java而言,Python的執行效率低,而且Java語言對多線程的支持更加完善[1]。針對某大型社交網絡平臺設計了基于Java語言的網絡爬蟲系統,爬取該平臺用戶的相關信息。同時為了更好地進行數據分析,系統可以從多角度對所獲得的用戶數據進行統計,并以直觀的圖表形式呈現。
1網絡爬蟲技術
網絡爬蟲技術是數據信息采集的常用手段,由于其自動化、拓展性強和開發相對簡單等優勢,被普遍應用于各行各業的數據模型分析[2]。通過網頁的鏈接地址,獲取其中傳遞的數據信息,自動檢索頁面數據模型,根據定義好的字段篩選數據獲得數據資源。網絡爬蟲將每一條鏈接存儲在隊列中,一個個調用,當鏈接被使用后自動廢棄,同時將每條鏈接上爬取的數據存儲在數據庫中,供用戶使用。
通過算法來優化數據爬取的方式,如廣度優先搜索策略,以最短的路徑爬取深層次的資源數據,減少數據搜集成本[3]。具體過程是首先確定少部分URL作為子結點,存儲在待抓取的URL隊列中,然后到對應的URL站點下載相應的頁面數據信息,當這些URL被抓取成功后,把它們放入已經抓取的URL隊列中,然后再抽出新的鏈接地址,進行頁面數據挖掘。流程如圖1所示。
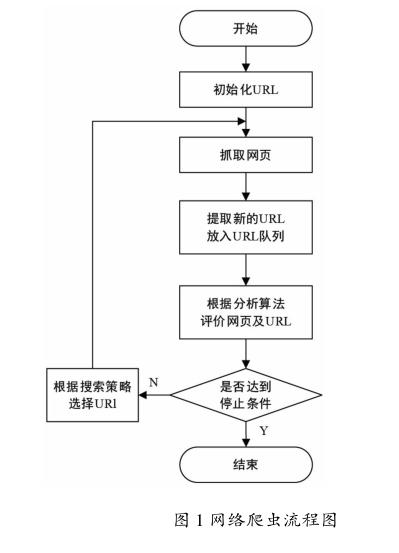
2 WebMagic
WebMagic是基于Java的一個爬蟲框架,核心部分主要是爬蟲的具體邏輯實現,除此以外還有一部分拓展功能,幫助用戶實現個性化需求[4]。WebMagicp爬蟲框架主要有四大組件,由Spider進行串聯,網絡爬蟲中的下載、處理和管理等功能都是由四大組件來負責,彼此之間交叉聯系,整體功能設計更趨向流程化的規范[5]。而Spider可以被認為是該框架的一個大容器,保存最核心的模塊。
3反反爬蟲機制
為了防止用戶數據被用于非法用途,許多網站都采取反爬機制,阻止別人批量獲取網站信息,并且反爬機制也在不斷完善。為了能夠成功獲取平臺上的用戶數據,提出以下幾種反反爬策略:
①動態更改user-agent,通過用戶代理讓服務器認為每次請求是來自不同的瀏覽器。
②通過獲取一定數量的代理IP地址,達到每次請求連接服務器都是來自不同的IP地址的目的,這樣可以迷惑服務器,讓服務器無法確定具體的訪問IP[6]。
③對系統的數據爬取頻率過快的話,容易造成賬戶被封禁,所以要對爬取速率進行控制[7]。
④建立并維護cookie池,所以更保險的方法是多獲取幾個cookie,每次請求隨機設定一個cookie[8]。
4系統實現
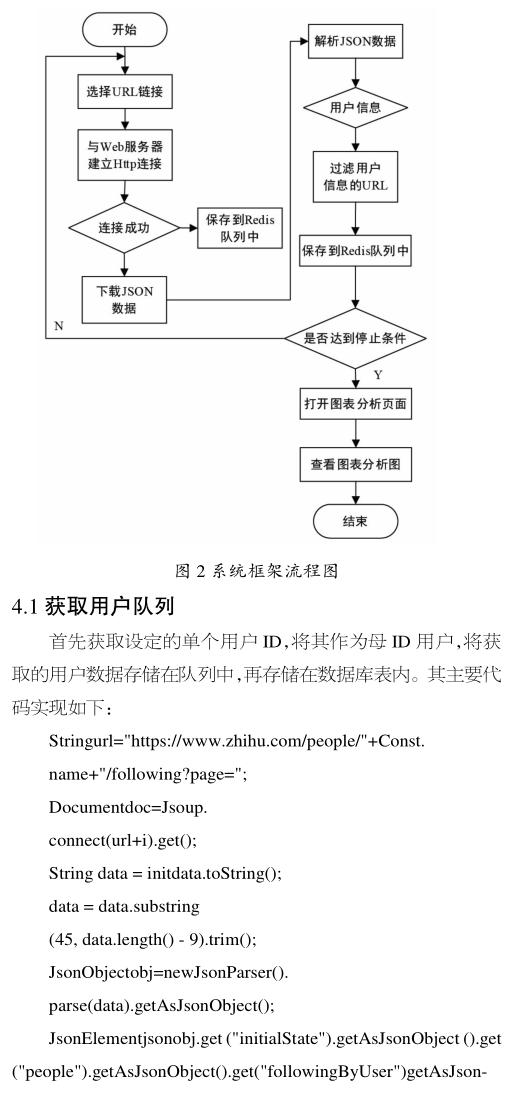
本文所設計的爬蟲系統是針對社交網絡平臺的用戶數據,目的是對用戶個人數據的獲取與分析。實現過程是以一個用戶為基準,然后不斷進行裂變,再對所爬取數據統計以直觀圖的形式呈現,進而得到有效合理的分析,系統框架流程圖如圖2所示。

從圖3可以看出,系統可以有效地爬取社交網絡平臺用戶的各項數據,包括性別、地域、從事行業以及畢業學校等信息,而且信息都清楚地進行分類展示,為下一步數據分析提供了極大的便利。
4.4對用戶數據進行統計分析
由于獲取到的數據龐大且復雜,為了更好地進行數據分析,系統可以從多角度對所獲得的用戶數據進行統計,比如男女比例、地域分布和從事的行業等,并以直觀的圖表形式呈現,以性別為例,如圖4所示。
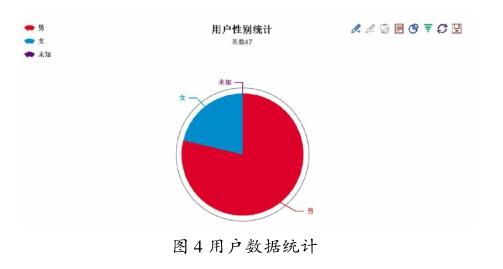
通過數據結果可以看出,目前該社交網絡平臺的大部分用戶在北上兩地,男性居多,行業都是目前主流的行當,例如互聯網、金融及計算機等,同時人群的普遍學歷較高。這些數據可以作為該社交網絡平臺發布廣告的一個側重點,發布符合年輕化、學歷高并且處于熱門的一些廣告內容,同時一些大數據分析公司可以借此獲取更多的數據,進而分析當前年輕人的喜好,為用戶提供更精準和優質的服務。
5結束語
本文研究網絡爬蟲的廣度優先搜索策略,通過一個用戶的關注信息來裂變,不斷進行新用戶的數據信息挖掘,并利用Java語言實現對社交網絡平臺用戶數據的獲取和分析。通過獲取到的該平臺用戶信息,包括男女比例、地域分布以及學歷程度等,不僅可以作為社交網絡平臺對其用戶精準定位,提供更優質服務,同時可以為一些大數據分析公司服務,為輿情分析和促進社會關系等研究提供便利。
參考文獻
[1]邵曉文.多線程并發網絡爬蟲的設計與實現[J].現代計算機(專業版),2019(1):97-100.
[2]蔡創.計算機軟件開發中JAVA編程語言的分析和思考[J].信息技術與信息化,2017(12):80-81.
[3] HERNANDEZI, RIVERO CR, RUIZD, et al. AnArchitecture for Efficient Web Crawling[J].Lecture Notes in Business Information Processing,2012: 228-234.
[4] RAFAEL P L,PEDRO B V,OTTO C M B.A Generalized Bloom Filter to Secure Distributed Network Applications[J]. Computer Networks,2011, 55(8):1804-1819.
[5] KAUSAR M A,DHAKA V S,SINGH S K.Web Crawler:A Review[J].International Journal of Computer Applications, 2013,63(2):31-36.
[6]羅咪.基于Python的新浪微博用戶數據獲取技術[J].電子世界,2018(5):138-139.
[7] FAN Y.Design and Implementation of Distributed Crawler System Based on Scrapy[J].Journal of Hubei University for Nationalities,2017:78-85.
[8]董博,翀李,劉學敏,等.基于爬蟲的數據監控系統[J].計算機系統應用,2017,26(10):53-60.
