基于時空信息的高速公路出入口交通車流量預測
2020-04-18 08:30:59石文婷
西部交通科技 2020年11期
石文婷
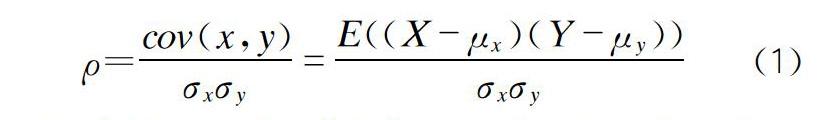
摘要:文章提出一種結合時間與空間信息,使用梯度提升決策樹的車流量預測方法,對廣西高速公路某特定出口的車流量進行數據分析,并將其與其他常用的預測方法進行了比較。結果表明,該方法可以更準確高效地預測高速公路出入口流量,具有更好的預測性能。
關鍵詞:車流量預測;時空信息;梯度提升決策樹
中圖分類號:U491.1+13 文獻標識碼:A DOI:10.13282/j.cnki.wccst.2020.11.048
文章編號:1673-4874(2020)11-0175-05
0引言
高速出入口作為交通路網的敏感點,經常在重要節假日承受著巨大的車流壓力。對高速公路出入口做車流量的預測有助于幫助出行民眾做出明智的決策,以決定出行時間與出行路線,分散出入口壓力,降低交通動脈的強度。準確的預測也為交管部門分擔部分壓力,為其高效地做好交管部署措施提供依據。
由歷史交通數據,對下一個時隙的交通量進行預測(比如使用前幾個月某節點的車流量數據預測未來一段時間此節點的車流量趨勢)是業界一直研究的比較經典的交通量預測問題。數十年來,許多研究調查了流量預測。博克思(Box)和詹金斯(Jenkins)于70年代初提出的著名時間序列預測方法自回歸積分移動平均(ARIMA)算法和卡爾曼濾波是比較早期被廣泛應用于交通預測問題中的研究方法,這些比較早期的研究方法只關注于個體交通節點交通信息的時間特征。近年來,空間特征也逐漸被考慮進入有關交通的相關研究。但是,多數方法仍基于傳統的時間序列模型或機器學習模型,無法很好地抓住非線性時空關系。
廣西境內有約360個高速出入口,高速公路每日的車流量(注:本文研究是基于經過出口收費站有收費數據的車輛數據,未將通過ETC通道的車輛算入本文所統計的車流量數據內)可達幾十萬輛。由此,對高速出入口做車流量預測是一項非常必要的研究方向。本文將會對廣西高速公路某特定出口的車流量進行數據分析,并基于時間與空間特征以及原始車流量數據,提出一種結合時間與空間特征的經過優化的梯度提升的決策預測方法,對此高速出口車流量進行預測與分析,以驗證本文方法的準確性。
1高速公路出入口車流量數據分析
1.1車流量數據分析
為更好地對高速公路車流量進行特征篩選,首先應對車流量數據進行數據分析以進行較為直觀的查閱,尤其是對于此類時序性數據,可視化的方法可以提供較為全面的參考和對比,為后續模型的搭建提供先決有利參考。
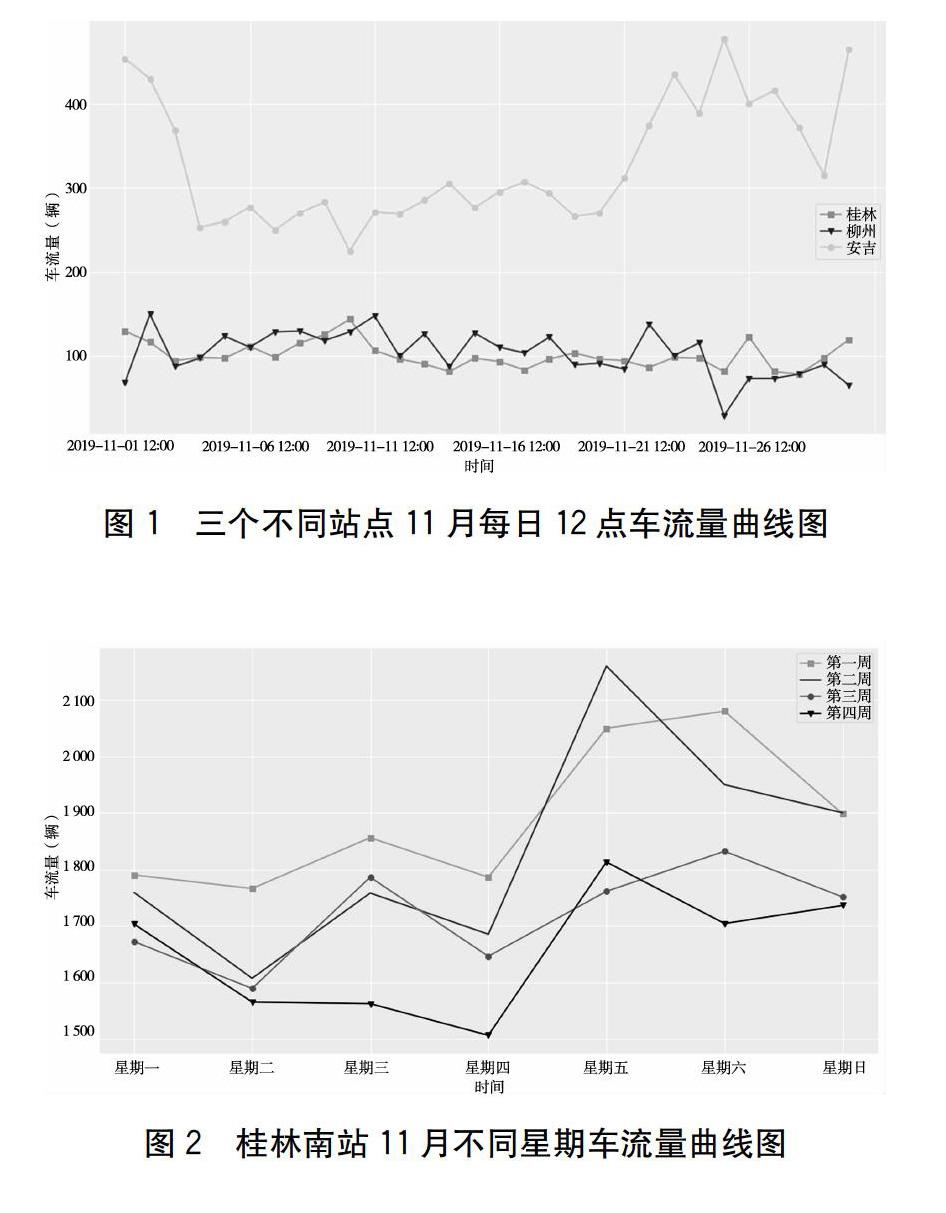
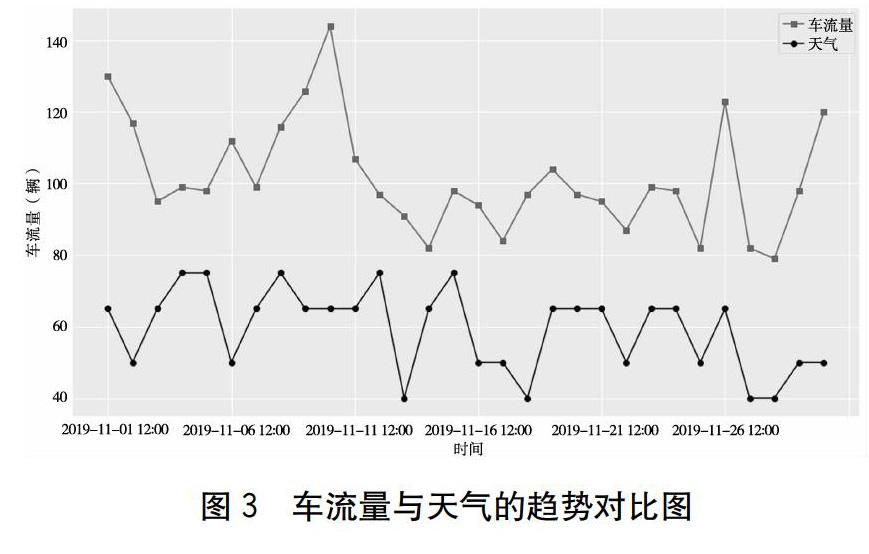
根據道路運輸數據的特性,為了驗證同期車流量整體趨勢是否上升或下降的猜想,以及選取合適的粗細粒度來設計統計特征,本文先對時序數據進行數據探索,比如同月不同站點車流量情況、不同星期同日同站等時序數據進行對比,結果如圖1、圖2所示。不難發現,不同地點的車流量數據會與時間成一定關系,每周不同日期也對車流量有一定影響。
1.2天氣數據分析
天氣數據是時序數據,根據天氣數據與車流量關系,我們將天氣好易于出行的天氣賦予高權值,將不易于出行的天氣賦予低權值。如圖3為11月份每日桂林南出口車流量與天氣的趨勢對比圖。天氣曲線權值高的點代表天氣晴好利于出行,權值低的點代表天氣不利于出行(天氣曲線對應的數值無實際意義,只代表天氣狀態)。可以發現,天氣與交通量曲線變化趨勢大致相同,證明天氣的變化與交通量的變化有著相關聯系,天氣的時間序列變化可作為交通量預測的重要依據。
2基于時空信息的梯度提升的決策樹預測模型
2.1特征工程
根據前期工作已對高速出入口交通量與可能影響車流量的時間、空間等相關信息做的數據分析,不難發現,相關因素的時序差異會對車流量產生明顯的影響。如果可以將這些影響因素納入算法特征,則增加了算法的魯棒性,預測準確率也會相應提升。
2.1.1時間特征
經過對一定時間段內出入口的車流量進行相關分析,可計算得各出入口之間的相關系數,如圖4所示,并把其與出入口站點地理位置進行對比,易發現,皮爾遜相關系數可以滿足地理相關性特征的表述。
除了地理相關性特征,還有各地常住人口、景區數量、與其他高速出入口連通情況等特征可以表示該出入口地理環境的因素也可進行處理納入訓練特征。
2.1.3異常值處理
在交通流量的時間序列里,交通流量可能會隨著某些特殊日子的時間點產生較大的浮動。例如,交通流量在國慶假期前三天的數值遠高于其前后兩天的數值,此類數據可以當成異常值進行處理。如果不對數據中的突變值(異常值)進行處理,可能會影響最終模型回歸預測的結果。本文通過變換變量法以減少由異常值引起的回歸變化,將數值進行對數轉換,減少異常值帶來的模型敏感。
2.2基于優化的梯度提升的決策樹模型
本文選用LightGBM模型作為訓練模型。LightGBM是一個基于學習算法的決策樹的梯度提升框架。微軟團隊在2017年的NIPS中提出了LightGBME41,它也是一種基于優化的梯度提升決策樹(GBDT)進行提升的方法。對于此類型的決策樹模型,最耗時的部分是在執行特征選擇節點分割時,遍歷所有可能的分割點并計算信息增益以找到最佳分割點。LightGBM有兩種樹的生成方式,一種是Level—wise,另一種是leaf-wise。Level-wise策略逐級數據可以同時分割同一層葉子,是一種更有效的策略,每次從所有葉子中尋找具有最大分裂增益的葉子,然后分裂并循環。leaf-wise策略可以減少更多錯誤,并在分割數相同時獲得更高的精度,本文采用的是基于leaf-wise的LightGBM模型進行訓練。
2.3基于時空信息與其他相關影響因素的預測模型
本文基于特征工程選擇及相關統計因素創建的54個基于時間和空間及相關影響因素的特征,通過使用具有深度限制的葉子生長策略并調整放入直方圖策略來優化LightGBM模型。將統計數據以離散值作為指標存儲在直方圖中。遍歷數據后,直方圖會累積所需的統計量,然后根據直方圖的離散值找到最佳分割點。
在Leaf-wise算法中,可以把該算法看成一個強模型由多個決策樹經過訓練,更新參數提升而成。本文模型訓練方法先初始化了64棵決策樹,訓練權重為1/64,在訓練各決策樹時更新改樹權值,直至誤差降到范圍之內則停止訓練,最終得到經過提升的強模型,見式3。
3仿真及結果
3.1數據集
本文的基礎車流量數據為廣西部分高速出口經過人工收費通道車流量數據,數據為每日每小時車流量總數。在實驗中的訓練數據(訓練集+驗證集)采用的是2019年10月、11月的相關出入口的車流量數據,以桂林南出入口的2019年12月的數據為預測對象(測試集)。訓練集用于模型的訓練以擬合數據樣本,使模型損失降低。驗證集主要作用為調整模型的超參數和用于對模型的能力進行初步評估,最終的測試集(算法的預測任務)用來評估最終模型的泛化能力。在本實驗中采用各數據集的配比為:訓練集:驗證集:測試集=4:2:3。天氣數據、地理位置等其他相關數據用于構造并優化特征。
在RMSE的表達式(4)中,yi為預測值,yi為真實值。均方根誤差RMSE用來衡量觀測值與真實值之間的偏差,常用作機器學習模型預測結果衡量的標準。本文采用RMSE作為算法誤差的評價指標,依次對比本文模型與其他常用預測模型的表現。
3.3結果與對比
經過運用本文基于時空信息的梯度提升決策樹模型,對目標站點2019年12月每天12:00的出口方向車流量進行的預測結果與車流量的真實值進行對比,如圖6所示,發現針對周末的預測值普遍高于實際值,且周末的實際車流量不太穩定,預測誤差較于工作日較大。經過對工作日以及周末的車流量數據分別進行統計特征提取并輸入訓練模型后,模型的預測能力均有所提升,優化后的預測結果如圖7、圖8所示。
將本文方法的預測誤差RMSE與其他常見用于預測的模型做本預測任務產生的RMSE作對比(如表1所示),不難發現本模型在做本次預測任務時所產生的RMSE低于其他模型,這表明本算法模型具有更優的預測交通車流量的能力。
綜上,本文方法對選定出入口的預測結果與實際車流量趨勢與數值吻合度較高,可以用于預測車流量的變化趨勢,為交管部門提供較為有利的決策依據。
4結語
本文提出了一種基于時空信息的使用梯度提升決策樹的車流量預測方法,主要將多種時序信息與空間信息映射成相應特征輸入訓練模型,使用一種經過調優的梯度提升的訓練方法進行訓練并完成相應的預測任務。實驗結果表明,本文方法的預測結果較為理想,在預測準確率與完成效率上均略高于其他常用預測方法,也高于只單一考慮時間信息的預測方法,所以本文方法可為車流量預測提供參考。
