基于LSTM的藏語語音識別
2020-04-14 04:54:29郭龍銀扎西多吉尚慧杰旦增
電腦知識與技術 2020年4期
郭龍銀 扎西多吉 尚慧杰 旦增


摘要:針對藏語語音識別處理的步驟,首先將藏語語料的國際音標轉換,其次根據人耳對語音的處理方式,使用MFCC進行語音特征提取,再構建CNN_BiLSTM_CTC聲學模型,最后利用2-gram語言模型進行音標與文字的轉換。該文最終實現語音轉文本,并在音標識別上有較好的準確率。
關鍵詞:藏語;語音識別;MFCC;CNN_BiLSTM_CTC;2-gram .
中圖分類號:TP183
文獻標識碼:A
文章編號:1009-3044(2020)04-0154-02
藏語作為藏族的母語,同時也是中國重要的少數民族語言之一,其語音識別在信息化時代的如今,在解決語言溝通障礙,實時交流上的作用越來越受人重視。藏語主要分布于中國西藏自治區、青海、四川、甘肅、云南等省以及印度、尼泊爾、不丹錫金等國家地區,是國內外藏族同胞使用的主體語言[1]。目前實用型成果還未出現,本文是在深度學習方法上對其進行的研究。
1 MFCC特征提取
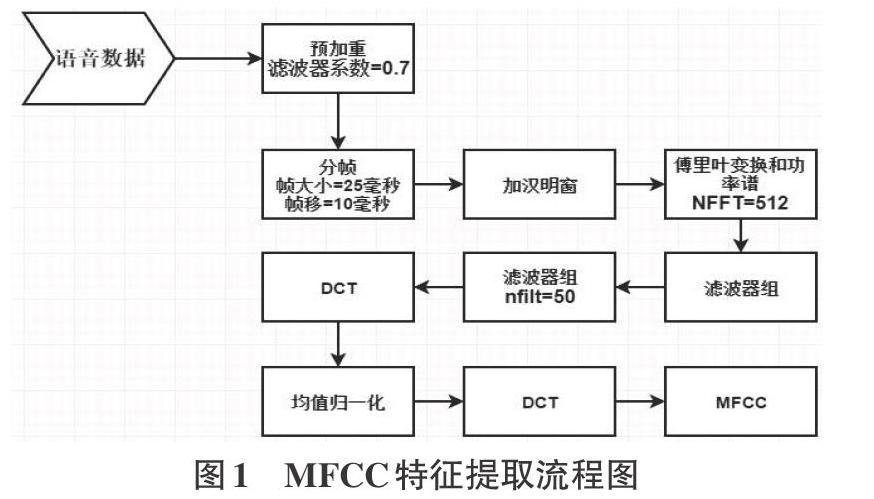
梅爾頻率倒譜系數MFCC)是基于人聽覺的屏蔽效應而來的,模擬人耳對于語音處理,其重點在于頻域內波于波之間的i距離關系顯得尤為清楚[2]。利用相關對數公式,在MEL頻域內,將語音頻率劃分為MEL濾波器組,每個濾波器的中心頻率由于屏蔽效應的非線性因素,使得其分布密度由頻率而定,但前一個和后一個濾波器與當前濾波器有重合部分,以表征屏蔽效應。我們利用MEL濾波器組得到MEL頻譜,在對MEL頻譜:進行傅里葉逆變換得到的倒譜系數就是MEL頻率倒譜系數(MFCC)。
本項目的語音數據的采樣率為16KHz,比特率256kbps,時長在6-10秒左右,大小在300kb左右,是句子級語音數據,文件質量高。對MFCC特征提取流程圖如圖1所示。
首先將語音數據轉換成數字矩陣,這是我們利用數字矩陣畫出的樣例聲音波形,如圖2所示。
其次我們經過對MFCC特征提取后,再將所得的部分MEL頻率倒譜系數畫出相應的熱力圖,如圖3所示。
2 聲學模型
LSTM模型是目前流行的用來處理語音識別的模型之一,它是在RNN模型的基礎上變形而成,用來解決當傳播時間比,較長而弓|起的網絡權重更新慢和梯度爆炸和消失問題[3]。這些問題會使RNN失去長期信息帶來的長距離依賴,這使得他能夠處理像語音處理這類與時間序列高度相關的問題。
LSTM相比RNN的多了輸入門、遺忘門、輸出門以及一個隱藏狀態,這種隱藏狀態包含將信息儲存較久且選擇性記憶網絡誤差回傳參數的存儲單元[3]。我們本文使用的前向傳播計算公式如下:
wij表示從神經元i到j的連接權重,輸入a用表示輸出用b、d表示,主要激活函數為sigmoid和tanh兩種,下標i、w、φ分別表示輸入門、輸出門、遺忘門,sct為細胞隱藏狀態,I為輸入層神經元的個數,H為隱層cell的個數,C為隱藏狀態的個數。
LSTM的反向傳播算法也是使用梯度下降法迭代更新所有參數,而計算方式則是基于損失函數的偏導數,在此便不予以展開。而本文使用的BiLSTM就是將LSTM的前向傳播和反向傳播算法相結合,類似BP算法包含前向和反向傳播。
本文的總體模型是CNN_BiLSTM_CTC網絡模型,模型先由CNN卷積提取特征、池化層縮減模型大小一般該維度的值縮小一半,并提高特征魯棒性,而由于我們的模型層數較多且較為復雜,在每一次卷積層和池化層以及隨后的BiLSTM層都要有dropout操作,這可以忽略部分的特征檢測器,從而丟棄部分輸出以防止過擬合現象。在網絡最后生成的輸出序列中會產生與原先的輸入label序列不能一一對其,CTC(Connectionist Temporal Classification)則能有效解決此問題,它使得模型的輸出能夠消除由于音素特征訓練產生的重復結果,最終使得輸出序列與輸入序列一一對應,完整模型總體較為復雜,在此僅顯.示部分涉及BiLSTM的結構圖,如圖4所示。
3 語言模型
我們在訓練的語料庫分為(衛藏拉薩方言)語音數據、對應的藏語文本、對應的國際音標文本。在聲學模型中輸入輸出的是國際音標序列,通過2-gram語言模型,,使用隱馬爾科夫鏈尋找音標序列對應的文字概率序列。
2-gram語言模型,就是兩個字為一組,將所有語句從第一個字開始與第二個字為宜組,然后第二個字開始與第三個字為一組,再第三個……逐字進行化組,然后建立相關2-gram詞典,然后每次化組都會更新詞典生成新組或增加某一組頻率值。
對于藏語的國際音標我們采用龍從軍等人的藏語國際音標轉換方案。從藏文文本到國際音標的轉換總體上需要經過三個大的階段,首先是分詞,其次是音標轉換,最后是變音變調[6]。
4 實驗結果
本文語料數據一共40200個語音語料,以9:1切分語料為訓練語料和測試預料。訓練出的聲學模型的訓練PER值為28.34%,測試PER值為35.51%。而由于語言模型較差,在轉文字的正確率上只有訓練數據的單字能有70%以上。
5 結束語
本文最終實現了從語音到文本的識別,雖然語料能夠滿足,但由于存在國際音標轉換復雜性,實踐上有部分的錯誤,音標轉換不夠準確,且音素轉文本的語言模型很簡單,未能將語言模型進行深度學習的訓練,使得在轉文字上錯誤了大幅上升。
對于藏語語音識別而言,有一套快速而又成熟的國際音標轉換方案顯得迫在眉睫,這可以使得更多的人能夠參與藏語語音的識別且能讓研究者將精力從語料準備上抽離出來,更好的編寫聲學模型和語言模型。
參考文獻:
[1]姚徐,李永宏,單廣“榮,等.藏語孤立詞語音識別系統研究[J].西北民族大學學報:自然科學版,2009,30(1):29-36+50.
[2]BARUA P,AHMAD K,KHAN A A S,et al.Neural networkbased recognition of speech using MFCC features[C].International Conference on Informatics,Electronics & Vision.IEEE,2014:1-6.
[3]趙淑芳,董小雨.基于改進的LSTM深度神經網絡語音識別研究[J].鄭州大學學報:工學版,2018,39(05):63-67.
[4]余凱,賈磊,陳雨強,徐偉.深度學習的昨天、今天和明天[J].計算機研究發展,2013,50(9):1799-1804.
[5]史笑興,顧明亮,王太君,等.一種時間規整算法在神經網絡語音識別中的應用[J].東南大學學報,1999,29(5):47-51.
[6]龍從軍,劉匯丹,吳健.藏文國際音標(拉薩音)自動轉換研究[J].中文信息學報 2016,30(5):203-208+214.
[通聯編輯:代影]
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
