作者身份驗(yàn)證系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)
2020-04-08 09:30:50郭旭
電腦知識(shí)與技術(shù) 2020年3期

摘要:為了驗(yàn)證文本對(duì)是否由同一作者書寫,設(shè)計(jì)并實(shí)現(xiàn)了一個(gè)作者身份驗(yàn)證系統(tǒng)。該系統(tǒng)選擇了目前最先進(jìn)的作者身份驗(yàn)證方法之二,即基于深度神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型的方法和基于冒名者的方法。系統(tǒng)可根據(jù)不同的文本長(zhǎng)度,自適應(yīng)地選擇合適的算法,具有識(shí)別準(zhǔn)確率高、操作簡(jiǎn)便和運(yùn)行速度快等優(yōu)勢(shì)。最終,在一個(gè)公開的博客作者身份語(yǔ)料庫(kù)上進(jìn)行了實(shí)驗(yàn),獲得了83%的識(shí)別正確率。實(shí)驗(yàn)結(jié)果表明,該系統(tǒng)可以在一定程度上解決兩段文本的作者身份驗(yàn)證問(wèn)題。
關(guān)鍵詞:作者身份驗(yàn)證;冒名者;語(yǔ)言模型;神經(jīng)網(wǎng)絡(luò)
中圖分類號(hào):TP18 文獻(xiàn)標(biāo)識(shí)碼:A
文章編號(hào):1009-3044(2020)03-0031-03
1 背景
隨著我國(guó)網(wǎng)絡(luò)技術(shù)的不斷發(fā)展與社交媒體等新型媒體形式的不斷涌現(xiàn),網(wǎng)絡(luò)中出現(xiàn)了大量的匿名文本和作者用虛假身份書寫的文本,包括由“水軍”發(fā)表的虛假評(píng)論[1]、電信詐騙人員書寫的詐騙郵件和詐騙短信[2]、由“槍手”代寫的文章或冒名的文章[3]等。因此,對(duì)作者身份的有效驗(yàn)證具有巨大的實(shí)際應(yīng)用價(jià)值,成為當(dāng)前自然語(yǔ)言處理的熱點(diǎn)研究方向。
作者身份驗(yàn)證[4-5]主要研究:給定一個(gè)文本對(duì),判斷文本X和文本Y是否由同一作者書寫。本文設(shè)計(jì)的作者身份驗(yàn)證系統(tǒng)主要采用冒名者和深度神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型兩種算法,根據(jù)X和Y的文本長(zhǎng)度,自適應(yīng)地選擇算法驗(yàn)證文本對(duì),具有識(shí)別準(zhǔn)確率高、操作簡(jiǎn)便和運(yùn)行速度快等優(yōu)勢(shì),可以滿足目前作者身份驗(yàn)證方面的基本需求。
2 系統(tǒng)設(shè)計(jì)
2.1 系統(tǒng)組成
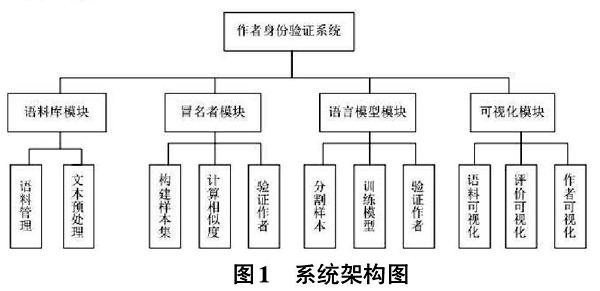
本文所設(shè)計(jì)的作者身份驗(yàn)證系統(tǒng)由語(yǔ)料庫(kù)模塊、冒名者模
2.1.1 語(yǔ)料庫(kù)模塊
主要完成語(yǔ)料的增、刪、改、查等語(yǔ)料庫(kù)管理功能,以及文本清洗、分詞和分句等文本預(yù)處理功能。
2.1.2 冒名者模塊
主要實(shí)現(xiàn)基于冒名者算法的作者身份驗(yàn)證方法,包括構(gòu)建冒名者樣本集、多種文本相似度算法的實(shí)現(xiàn)和驗(yàn)證作者等功能。
2.1.3 語(yǔ)言模型模塊
主要實(shí)現(xiàn)基于深度神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型的作者身份驗(yàn)證方法,包括分割文本為樣本集、構(gòu)建深度神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型、語(yǔ)言模型訓(xùn)練和識(shí)別等功能。
2.1.4 可視化模塊
主要完成語(yǔ)料可視化分析、算法評(píng)價(jià)指標(biāo)可視化和作者信息可視化等功能。
2.2 系統(tǒng)流程
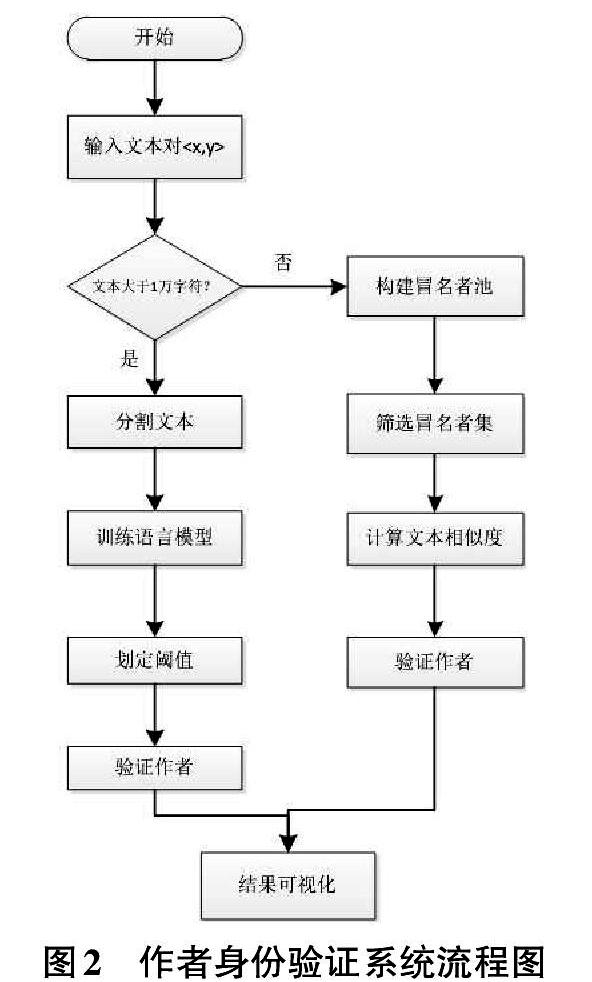
本文系統(tǒng)的運(yùn)行流程,如圖2所示。
步驟1:輸入文本對(duì)。
步驟2:判斷文本對(duì)中是否有文本的長(zhǎng)度大于10,000字符。如果否,跳轉(zhuǎn)步驟6。
步驟3:分割長(zhǎng)度大于10,000字符的文本為訓(xùn)練樣本集。
步驟4:訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型,并計(jì)算所有訓(xùn)練樣本在深度神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型中的概率,并根據(jù)概率劃定閾值。
步驟5:計(jì)算待驗(yàn)證文本在深度神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型中的概率,如果大于閾值則認(rèn)定文本對(duì)由同一作者書寫,否則為不同作者書寫。
步驟6:構(gòu)建冒名者池,并從冒名者池中篩選出冒名者樣本集。
步驟7:計(jì)算文本對(duì)和文本X與冒名者樣本集中樣本的文本相似度,如果文本對(duì)取得較大的文本相似度,則認(rèn)定文本對(duì)由同一作者書寫,否則為不同作者書寫。
步驟8:可視化顯示驗(yàn)證結(jié)果。
3 系統(tǒng)實(shí)現(xiàn)
本文的作者身份驗(yàn)證系統(tǒng)將根據(jù)文本對(duì)中X和Y的文本長(zhǎng)度,選擇不同的作者身份驗(yàn)證方法。當(dāng)文本X或Y的長(zhǎng)度大于10,000字符時(shí),可將文本X或Y分割為多個(gè)樣本,此時(shí)選擇評(píng)價(jià)指標(biāo)較高的基于深度神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型的方法;否則,由于文本較短無(wú)法分割出足夠的訓(xùn)練樣本,選擇評(píng)價(jià)指標(biāo)略低的基于冒名者的方法。
3.1 冒名者算法
冒名者算法[6],是由Koppel等人提出的作者身份驗(yàn)證方法,是目前為止最成功的短文本作者身份驗(yàn)證方法之一,在多個(gè)作者身份驗(yàn)證的公開數(shù)據(jù)集上取得了較高的評(píng)價(jià)指標(biāo),在作者身份驗(yàn)證的國(guó)際評(píng)測(cè)PAN-2013和PAN-2014中,優(yōu)勝者就均采用了冒名者算法的變種。冒名者算法的基本思想是:通過(guò)引入一些其他作者書寫的外部語(yǔ)料,將作者身份驗(yàn)證這種單分類問(wèn)題轉(zhuǎn)換為二分類問(wèn)題處理,通過(guò)判斷文本X更接近文本Y或冒名者,來(lái)決定文本對(duì)是否由同一作者書寫。
冒名者算法的難點(diǎn)在于如何選擇合理的冒名者文本構(gòu)建冒名者樣本集。最簡(jiǎn)單的做法是在一個(gè)由多位冒名者構(gòu)成的冒名者池中,隨機(jī)選擇冒名者。本文采用由Potha等[7]人改進(jìn)的算法構(gòu)建冒名者文本集,該算法在冒名者池中選擇具有最高相似度的K個(gè)文本構(gòu)建冒名者樣本集,算法具體步驟如下:
步驟1:構(gòu)建冒名者池。
步驟3:選取冒名者池中相似度最大的K個(gè)冒名文本,構(gòu)建冒名者文本集。
3.2 基于深度神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型的方法
基于深度神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型的方法[8],是由郭旭等人提出的作者身份驗(yàn)證方法,適用于文本對(duì)的文本長(zhǎng)度不平衡的情況,即文本X的長(zhǎng)度較長(zhǎng)(10,000字符以上),文本Y的長(zhǎng)度較短(100字符左右)。該方法的基本思想是:使用同一作者的語(yǔ)料訓(xùn)練的語(yǔ)言模型,將分配給該作者書寫的文本更高的概率。本文選擇加入注意力機(jī)制的門控循環(huán)單元構(gòu)建深度神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型。具體步驟如下:
步驟1:分割長(zhǎng)度大于10,000字符的樣本為若干個(gè)文本塊,構(gòu)建訓(xùn)練語(yǔ)料。
步驟2:使用訓(xùn)練語(yǔ)料訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型。
步驟3:計(jì)算訓(xùn)練語(yǔ)料在神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型中的概率,劃定閾值0。
步驟4:計(jì)算短文本在神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型中的概率。若大于閾值0,判斷為正例;否則,為負(fù)例。
4 實(shí)驗(yàn)結(jié)果
本文選擇的實(shí)驗(yàn)語(yǔ)料來(lái)自一個(gè)公開的博客作者身份語(yǔ)料庫(kù),該語(yǔ)料庫(kù)包含19,320位作者共計(jì)681,288篇來(lái)自blogger.com的博客,平均每位作者有35篇博客和7,252字的博文。實(shí)驗(yàn)語(yǔ)料構(gòu)建過(guò)程如下:
步驟1:從博客作者身份語(yǔ)料庫(kù)中,篩選100位具有最多博客字?jǐn)?shù)的作者,并將每位作者書寫的所些博客首尾相連,形成一個(gè)博客文本。
步驟2:在博客文本的開始部分隨機(jī)取10,000到15,000字符和3,000到5,000千字符,在結(jié)束部分隨機(jī)取10,000到15,000字符和3,000到5,000千字符,共4個(gè)文本塊,首尾文本塊各2個(gè)。
步驟3:每位作者的首尾文本塊兩兩組合,構(gòu)成4個(gè)正例文本對(duì),共400個(gè)正例文本對(duì)。
步驟4:隨機(jī)在不同作者的文本塊中組合,構(gòu)成400個(gè)負(fù)例文本對(duì)。
步驟5:選取其中10個(gè)長(zhǎng)文本對(duì)和90個(gè)短文本對(duì)作為測(cè)試樣本集,其中正負(fù)例各占50%,其余文本對(duì)為訓(xùn)練樣本集。
本文系統(tǒng)在對(duì)測(cè)試樣本進(jìn)行驗(yàn)證時(shí),獲得了83%的識(shí)別正確率。
5 結(jié)束語(yǔ)
本文設(shè)計(jì)并實(shí)現(xiàn)了一個(gè)作者身份驗(yàn)證系統(tǒng),該系統(tǒng)采用Python語(yǔ)言編寫,借助tensorflow、keras和HanLP等開源工具包,完成了語(yǔ)料庫(kù)模塊、冒名者模塊、語(yǔ)言模型模塊和可視化模塊共四個(gè)功能模塊。實(shí)驗(yàn)結(jié)果表明,該系統(tǒng)可以有效地解決作者身份驗(yàn)證的問(wèn)題,在一定程度上滿足了當(dāng)前對(duì)文本作者驗(yàn)證的需要。但本文僅驗(yàn)證了系統(tǒng)在英文博客上的效果,對(duì)于在中文和其他體裁上的效果仍需要進(jìn)一步實(shí)驗(yàn)。
參考文獻(xiàn):
[1]張艷梅,黃瑩瑩,甘世杰,等.基于貝葉斯模型的微博網(wǎng)絡(luò)水軍識(shí)別算法研究[J].通信學(xué)報(bào),2017,38(1):44-53.
[2] Ren Y F,Ji D H.Neural networks for deceptive opinion Spamdetection: an empirical study[J]. Information Sciences. 2017.385/386: 213-224.
[3]關(guān)珠珠,李雅楠,郭錦秋,醫(yī)學(xué)期刊編輯初審過(guò)程中對(duì)“槍手”論文的識(shí)別[J].編輯學(xué)報(bào),2018, 30(1):61-63.
[4] Halvani 0,Winter C.Graner L On the usefulness of compres-sion models for authorship verification[C]//Proceedings of the12th International Conference on Availability. Reliability andSecurity - ARES '17, August 29-September l,2017. ReggioCalabria, Italy. New York. USA: ACM Press, 2017.
[5] Rocha A,Scheirer W J,F(xiàn)orstall C W. et al.Authorship attri-bution for social media forensics[J]. IEEE Transactions on In-formation Forensics and Security, 2017, 12(1):5-33.
[6] Koppel M, Winter Y.Determining if two documents are writ-ten by the same author[J]. Journal of the Association for Infor-mation Science and Technology, 2014, 65(1):178-187.
[7] Potha N,Stamatatos E.An improved impostors method for au-thorship verification[M]//Lecture Notes in Computer Science.Cham: Springer International Publishing, 2017: 138-144.
[8]郭旭,祁瑞華,基于神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型的作者身份驗(yàn)證[J/OL].情報(bào)理論與實(shí)踐[2019-11-12].http://kns. cnki.net/kcms/detail/ 11.1762.G3 .20191024.1127.002.html.
