基于灰狼算法優化的支持向量機產能預測
2020-04-04 05:47:04宋宣毅劉月田王俊強孔祥明任興南
巖性油氣藏 2020年2期
宋宣毅,劉月田,馬 晶,王俊強,孔祥明,任興南
(中國石油大學(北京)油氣資源與探測國家重點實驗室,北京 102249)
0 引言
油井的初期產能預測是油田開發的重要環節,可為油藏的開發動態分析和調整提供依據,也常用于對新鉆井的經濟效益進行評估。關于產能預測模型,①根據油藏流體的滲流機理建立數學模型[1-5],其滲流微分方程組建立過程較為復雜,求解時需要多種假設條件,適用條件嚴格。②利用地質資料,建立地質模型,使用已有的開發資料進行歷史擬合,然后用油藏數值模擬的方法預測目標井位的產能[6],但是地質模型和數值模型的建立需要較高的時間成本和計算成本[7]。另外現場上也常采用經驗和類比的方法,其誤差較大。
在油田開發過程中,積累了大量關于油藏的地質數據、生產數據和工程數據等,這些數據對于深度認識油藏具有極其重要的作用,機器學習算法可以幫助人們從這些已有的數據中挖掘出需要的信息。潘有軍等[8]使用多元線性回歸方法建立了火山巖壓裂水平井的產能模型,但多因素對產能的影響規律,線性模型的表征仍不夠完善。田冷等[9]使用改進的BP 神經網絡建立了長慶氣田的產能預測模型,該模型只有較大的樣本容量才能建立一個高精度的神經網絡模型,而且容易產生過擬合現象。支持向量機(SVM)是以統計學習理論為基礎的新的機器學習算法,其建模過程簡單,耗時較少,能夠很好地解決小樣本、高維數的問題,而且可以表征多個特征與目標之間的非線性關系,預測結果也更加準確。王威[10]使用支持向量機方法對致密油藏的產能進行了研究,趙傳峰等[11]使用支持向量機方法,采用不同的核函數對調剖后的增油量進行了預測,發現其精度比BP 神經網絡預測精度高出很多。張志英等[12]在油藏數值模擬的基礎上,基于支持向量機形成了水平井的產能預測方法。
支持向量機的關鍵參數,懲罰因子、松弛因子等對模型的精確度、穩定性及泛化性能有較大的影響,這些參數的優化對能否形成一個高性能的模型型至關重要。目前用于支持向量回歸機參數選擇的方法主要有3 種:①利用經驗對參數進行選擇,這對使用者和樣本有較大的依賴性;②網格搜索尋優,它的不足之處在于步長的選擇,步長小,計算量大、時間長,步長大,容易錯失全局最優解;③利用優化算法對參數進行優選。灰狼算法具有良好的自組織學習性,而且參數簡單、全局搜索能力強、收斂速度快、易于實現。因此,采用灰狼算法對支持向量機進行優化[13],以特低滲油藏為例,建立油井的產能預測模型,以期提高產能預測的效率和精度。
1 特征因素選取
影響油藏初期產能的因素首先是地質因素,包括孔隙度、滲透率、含油飽和度、油層有效厚度和射孔段有效厚度等。其次是工程因素。對于特低滲透油藏來說,必須通過壓裂產生高滲條帶,形成基質孔隙與井筒的流動通道,從而建立產能,這里選用壓裂加砂量、加砂強度和泵效來分析工程因素對初產的影響。最后是開發因素,包括能量保持狀況以及井網井距等因素,能量的保持狀況用動液面的高度來表征,動液面越高,地層能量保持越好,動液面越低,地層能量保持程度越低;井網井距用油井的初始飽和度來表示,初始含水飽和度越高,表示注采井網的井距越小,初始含水飽和度越低,表示注采井網的井距越大。基于某特低滲油田34 口生產井,選取上面提到的10 個特征參數作為分析產能的影響因素,建立產能預測模型的基礎數據,如表1 所列。
首先利用皮爾遜相關性分析各個因素之間的相關關系。皮爾遜相關關系是用來量度2 個變量之間的線性相關性。相關系數從-1(負相關)到1(正相關)之間變化,相關系數為0 時意味著這2 個變量之間沒有相關關系。計算方法[15]為

式中:ρX,Y為參數X和參數Y之間的相關系數;cov為協方差;σ是標準差。
利用皮爾遜相關關系,計算了各參數之間,以及各參數與初產之間的相關系數,結果如圖1 所示。可以看出,在特低滲油藏中,滲透率和孔隙度有較強的線性相關關系,孔隙度越大,滲透率越大。油層有效厚度、射孔段厚度以及壓裂加砂量有一定相關性,油層厚度越大,射孔段厚度越大,相應的壓裂加砂量也越大。另外,根據各個因素與初產的相關系數可以看出,射孔段厚度、壓裂加砂量以及油層的有效厚度與初產的相關性較強。

表1 某特低滲油藏單井產能影響因素及對應初產[14]Table 1 Initial productivity and influencing factors of an ultra-low permeability reservoir

圖1 初期產能影響因素相關關系矩陣Fig.1 Correlation matrix of influencing factors of initial productivity
2 主控因素分析
皮爾遜相關系數只能簡單分析單因素對產能的線性影響關系,在油藏開發過程中,產能是在多個因素共同作用下的非線性結果。為了明確各個地質參數、工程參數和開發參數對初期產能的非線性影響程度,使用隨機森林方法確定初期產能的主控因素。隨機森林是一種集成機器學習方法,利用隨機采樣技術和節點隨機分裂技術構造多棵決策樹,通過投票得到最終結果,其用于特征排序時主要有2 種方法,一種是對每個特征按照Gini 不純度進行排序,另一種是測量每種特征對模型準確率的影響,這里使用后一種方法[16]。
隨機森林建模時隨機采樣未被抽到的數據稱為袋外數據集,這些數據沒有參與訓練集模型的擬合,可以用來檢驗模型的泛化能力。在對模型進行重要性排序時,使用相應的袋外數據計算它的袋外誤差r1,然后袋外數據中的某個特征的順序被隨機變換,再次計算袋外誤差r2,假設隨機森林有N棵樹,那么某個特征的重要性I為

根據上述原理,計算得到該特低滲油藏每個特征對初產的重要性如表2 所列。

表2 產能影響因素重要性排序Table 2 Importance order of influencing factors of productivity by Random Forest
利用隨機森林方法對產能影響因素重要性的排序結果表明,特低滲透油藏初期產能的5 個主控因素為壓裂加砂量、射孔段厚度、初始含水飽和度、油層有效厚度以及加砂強度,其重要性指標I均大于0.20。因此,在開發特低滲透油藏時,新井井位應選在油層有效厚度大的區域,完井時增大射孔段厚度,壓裂施工時增大加砂量,提高加砂強度,從而提高初期產能。另外,開發因素中油井初始含水飽和度對初產的影響因素較大,其表征的是井網井距的影響。因此,在特低滲透油藏開發中,合理的井網井距對產能的提高和保持也有著重要的作用。
3 模型的建立
3.1 支持向量機(SVM)原理
根據文獻[7]報道,支持向量機算法最初是Vladimie 等提出的,它是一種用來分析數據和模式識別的有監督學習方法,可以對數據進行分類和回歸分析。這里所用到的是支持向量回歸機,其原理如圖2 所示,旨在尋找一個最優的超平面,使得所有樣本離該最優超平面的距離最小。

圖2 支持向量機原理示意圖Fig.2 Schematic diagram of support vector machine
超平面可用式(3)表示,最優的回歸超平面為所對應的凸二次規劃問題,如(式4)所示[18]:

式中:c為懲罰參數,其取值反映了對式中2 個部分重要性的權衡;ξi和為松弛變量,以降低對超平面的要求;ε為不敏感參數,定義了不敏感帶的寬度;Φ(xi)為映射函數。
為了使式(4)容易求解,使用拉格朗日函數將目標函數轉化為其對偶形式:

式中:αi和為拉格朗日乘子向量;K(xi,xj)為核函數,可以將高維空間的內積運算轉換為低維空間的核函數運算。利用分塊算法、Osuna、序列最小優化算法、或者增量學習法求得αi后,最優超平面回歸函數可由式(6)確定
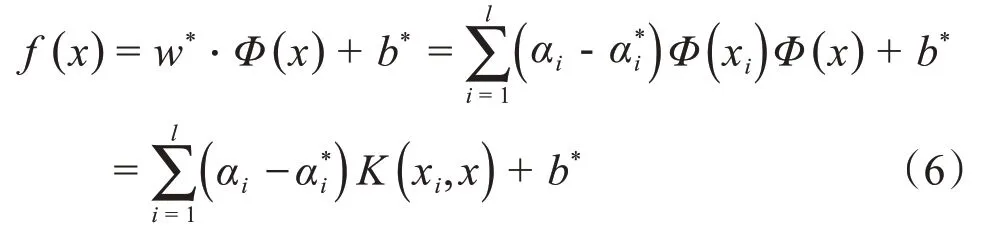
3.2 灰狼優化(GWO)算法原理
3.2.1 算法概述
灰狼優化算法是通過模擬狼群的等級制度和捕食策略,以迭代的方式不斷尋找最優值的一種群優化算法[19]。狼的生活習性以群居為主,每個群體中有7~12 只狼,具有較為嚴格的等級制度,如圖3 所示。
α是狼群中管理能力最強的,被奉為頭狼,因此所有狼都聽從它的指揮,其主要負責決策狼群的捕獵、駐地和休息時間等。β是α的顧問,幫助α制定決策及安排其他活動,也是狼群中秩序的維持者。當α去世或者年齡增大,β也是最好的α候選人。排在第3 層的是δ狼,聽從α和β的指示,并指揮ω,它們主要負責偵查、放哨、捕獵、看護等事務。年老的α和β也都會降級為δ。ω等級最低,必須服從其他等級狼的指揮和調度,也負責照顧幼狼,其數量可以平衡種群的內部關系。捕食活動由α帶領,首先狼群以團隊形式對獵物進行跟蹤、追趕、靠近,然后從各個方向包圍并恐嚇獵物直到獵物停止運動,最后攻擊獵物。
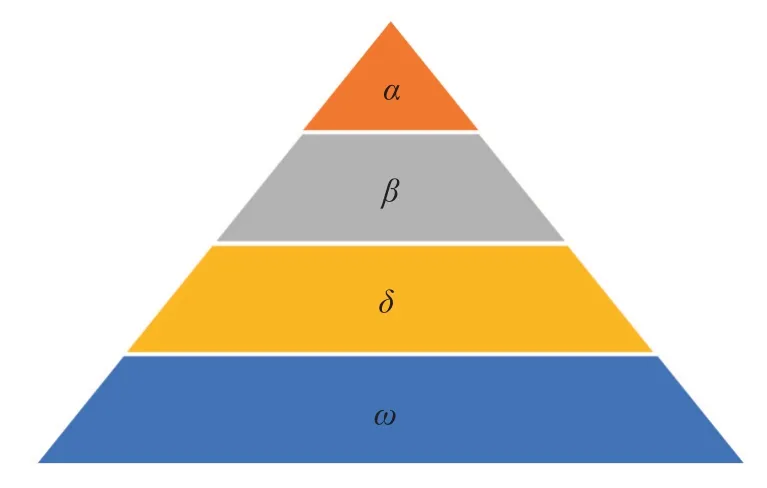
圖3 狼群等級層次機制Fig.3 Hierarchy mechanism of grey wolf
3.2.2 數學模型
捕食過程中,狼群與獵物的距離D可用式(7)表示,狼群根據獵物位置和與獵物的距離更新其位置,用式(8)表示[20]:

式中:X為狼的位置向量;Xp為獵物的位置向量;t為當前迭代步;A和C均為系數向量,通過調整這2個向量,狼可以到達獵物周圍的不同位置,其計算方法可用式(9)—(10)表示:

式中:a在迭代過程中,從2 到0 線性減小;r1和r2為[0,1]之間的隨機向量。
假定α,β和δ對獵物的潛在逃竄位置有較好的洞察能力,整個捕食過程由α,β和δ主導,而且α狼的位置是最優的,其次是β,最后是δ。首先根據式(11)確定α,β和δ到獵物的距離,再根據式(12)移動到下一步的位置,ω則根據這3 頭位置最好的狼來更新自己的位置。根據上述方法,不斷迭代,直到滿足終止條件,便可得到優化目標的最優解、次優解等。

初期產能預測模型建立流程如圖4 所示,首先將收集到的數據進行歸一化處理,將其中80%作為訓練集,20%作為測試集,然后使用訓練集建立基于支持向量機的產能預測模型。整個過程使用MATLAB2016 b 編程實現,支持向量機調用LIBSVM工具箱進行設計,選取徑向基函數作為核函數,決定支持向量機性能的2 個關鍵參數,懲罰參數c和核函數參數g使用上述灰狼算進行優化,直至滿足迭代終止條件。最后使用測試集對模型的準確性進行評估。

圖4 GWO-SVM 產能預測模型建模流程Fig.4 Workflow of GWO-SVM prediction model
4 實驗與分析
利用統計的某特低滲油藏34 口生產井的初期產量以及影響初期產量的10 種因素作為樣本庫,其中27 口井數據作為訓練集,7 口井作為測試集,使用網格搜索尋優的支持向量機(GRID-SVM)和灰狼算法優化的支持向量機(GWO-SVM)建立初期產能的預測模型,其中灰狼算法優化得到的支持向量機參數分別為c=52.40,g=0.01。
多元線性回歸模型[14],網格尋優的支持向量機模型(GRID-SVM)和灰狼算法優化的支持向量機模型(GWO-SVM)的預測結果如表3 所列,從表中可以看出,灰狼算法優化的支持向量機建立的產能預測模型比多元線性回歸預測結果和網格尋優的支持向量機預測結果誤差小得多,且均在12%以下。多元線性回歸和網格尋優的支持向量機對油井初期產能預測結果的誤差較大,對P43-841 井預測結果的相對誤差甚至超過了40%。3 種方法的產能預測結果對比如圖5 所示,可以清楚地看到,灰狼算法優化的支持向量機產能模型預測結果更準確。

表3 不同方法單井初期產能預測結果Table 3 Prediction results of different forecast models

圖5 不同方法單井初期產能預測結果Fig.5 Prediction results of initial productivity by different forecast model
另外,在編程計算過程中發現,GWO-SVM 比GRID-SVM 更加高效。當GRID-SVM 擴大網格搜索范圍或減小搜索步長時,計算所需要的時間會超過幾個小時。相反,GWO-SVM 往往在幾十秒之內便能得到結果,而且精度較高。
5 結論
(1)油藏初期產能的影響因素包括地質、工程、開發方面的10 種因素。皮爾遜相關性分析表明:射孔段厚度、壓裂加砂量和油層有效厚度均與初期產能有較強的線性相關性。
(2)用隨機森林方法表征特低滲油藏初期產能影響因素與初產之間的非線性關系,確定的初產主控因素為壓裂加砂量、射孔段厚度、初始含水飽和度、油層有效厚度和加砂強度。
(3)基于灰狼算法優化的支持向量機產能預測模型,對測試集7 口井的預測結果誤差均小于12%,平均預測結果誤差為5%,比多元線性回歸和網格搜索優化的支持向量機預測結果準確度提高10%以上。該模型也可以推廣到其他類型的油氣藏初期產能預測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
