高職院校就業推薦系統的算法
2020-04-01 20:05:51劉西祥
計算機與網絡 2020年23期
劉西祥
摘要:分析了傳統的基于用戶的協同過濾推薦算法和改進的基于用戶的協同過濾推薦算法的算法思想和算法步驟,并對2種推薦算法在高職院校就業推薦系統中的應用結果進行了對比,證實了改進的基于用戶的協同過濾推薦算法更適用于高職院校就業推薦系統,提高了相似學生推薦的準確性,推薦的結果也更加符合實際。
關鍵詞:協同過濾推薦算法;就業推薦系統;聚類分析
中圖分類號:TP391文獻標志碼:A文章編號:1008-1739(2020)23-68-4

0引言
就業推薦系統的推薦算法是整個推薦系統中最核心、最關鍵的部分,目前關于就業推薦系統的算法研究主要有:吳迪的基于經驗公式的算法、魏麗芹的基于歷史信息的就業推薦算法、陳玉峰的ID3算法以及基于內容和Item-based協同過濾的組合推薦算法等,他們研究的對象一般比較廣泛,采用的算法也比較傳統,不適用高職院校就業推薦工作。本文采用基于用戶的協同過濾推薦算法(學生當作用戶,就業單位當作項目)來進行就業推薦。首先根據所有學生(含往屆畢業學生和應屆畢業學生)對就業單位簽約情況、感興趣程度,發現與應屆畢業學生對就業單位興趣度相似的往屆畢業學生最相鄰學生,然后根據該相鄰的往屆畢業學生的簽約情況,為該應屆畢業學生推薦就業單位,實現就業推薦功能。
1傳統的基于用戶的協同過濾推薦算法
1.1相似度計算
查找最近鄰居是基于用戶的協同過濾推薦算法的主要工作,通過應、往屆畢業學生對就業單位的評分矩陣,可以計算出他們之間的相似度,相似度越高,他們越接近。把應屆畢業學生與往屆畢業學生之間的相似度定義為( , ),每一個學生對就業單位的評分可以看作是一個維的向量,應屆畢業學生與往屆畢業學生之間的相似度就可以用不同的維向量間的相似度來進行度量。通過Cosine相似度(余弦相似度)來計算他們之間的相似度,設應屆畢業學生與往屆畢業學生在維對象空間上的評分表示為向量,,則( , )的相似度計算方法如公式(1)所示。

1.2推薦實現
通過計算相似度得到了應屆畢業學生的最近鄰居集(最相似的往屆畢業學生),然后就可以通過最近鄰居集進行預測評分,計算方法為:

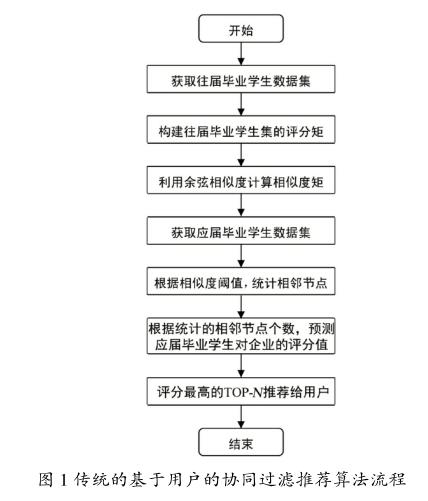
1.3推薦算法步驟及流程圖
(1)推薦算法步驟
①通過應、往屆畢業生對企業評分表分別構建應、往屆畢業生評分矩陣。
②構建應屆畢業生和往屆畢業生的相似度矩陣。
③根據相似度矩陣求出個與該應屆畢業生相鄰的往屆畢業生。
④根據統計的相鄰的節點個數,預測該應屆畢業生對企業的評分值。
⑤根據預測的評分值,按降序排列得出TOP-個企業推薦給應屆畢業生。
(2)推薦算法程序流程圖。
傳統的基于用戶的協同過濾推薦算法流程圖如圖1所示。
2改進的基于用戶的協同過濾推薦算法
傳統的基于用戶的協同過濾推薦算法只考慮了應屆畢業學生和往屆畢業學生對就業單位的興趣度,即評分矩陣的評分值只是針對簽約單位和感興趣的就業單位來進行的,而沒有考慮應屆畢業生和往屆畢業生本身的相似度,比如專業、性別、專業考證、是否學生干部、生源地、職業素養、專業課成績、外語成績、綜合評定、身高及畢業時間等特征屬性。實際就業推薦過程中,必須首先考慮學生的基本特征和綜合素質,因為基本特征和綜合素質相當的學生才能勝任類似的工作,而就業單位在招聘應屆畢業生的時候也會參考歷年招聘的往屆畢業生的基本特征和綜合素質,即招聘條件在近期內不會有太大的變化。當然,隨著時間的推移,往屆畢業學生數據庫的數據越來越多,所以在計算應屆畢業生和往屆畢業生相似度的時候還要考慮畢業時間的因素,加入時間權值。另外,高職院校畢業生就業專業比較對口,可以對就業推薦的對象先分類,再推薦。即進行相似度計算和推薦之前,先對應、往屆畢業生按專業進行聚類分析,然后按專業進行就業推薦。
2.1學生聚類分析
如果每次相似度計算都以全校所有畢業學生數據來進行,推薦復雜度和推薦效率勢必受到影響,不是理想的方法。所以在進行相似度計算和推薦之前首先對應屆畢業生和往屆畢業生按專業進行聚類分析,形成新的數據庫。
2.2興趣企業最近鄰
對應屆畢業生和往屆畢業生按專業進行了聚類分析,縮小了推薦范圍。而相同專業的應、往屆畢業生,由于有些專業人數特別多,故往屆畢業生對同一企業感興趣的情況也會經常出現,所以可以利用興趣企業最近鄰方法來進一步縮小計算范圍。把與應屆畢業生有共同感興趣的企業(共同給予評分)的相關往屆畢業生的所有評分進行求和,然后根據得分排名從高到低選擇個往屆畢業生與應屆畢業生進行相似度計算。找出與應屆畢業生有共同感興趣的企業(共同給予評分值較高)的相關往屆畢業生進行相似度計算,而那些與該應屆畢業生無共同感興趣企業(無共同給予評分或共同給予評分值較低)的往屆畢業生沒有推薦能力,不參與相似度計算,大大改善了推薦實時性,降低了數據稀疏性。
