基于層次化深度學習的醫療數據庫離群數據檢測算法①
2020-03-18 07:55:16李曉峰王妍瑋
計算機系統應用 2020年3期
李曉峰,王妍瑋,李 東
1(黑龍江外國語學院 信息工程系,哈爾濱 150025)
2(普渡大學 機械工程系,西拉法葉市 IN47906)
3(哈爾濱工業大學 計算機科學與技術學院,哈爾濱 150001)
1 引言
數據庫管理系統和信息技術在近年來得以快速發展,人們收集和產生數據的能力不斷提高,醫療數據庫中存在的數據量呈直線增長.過去對數據的檢測分析主要通過分析員完成,在專家意見的基礎上通過數據分析在醫療數據庫中獲取和查詢數據,由分析員決定數據分析的結果.但由于數據庫中的數據急劇膨脹,數據的復雜性和時效性也不斷增強,傳統方法已經不能滿足人們的要求.為了從醫療數據庫中獲取有用的信息,需要改進現有的數據檢測技術.
在醫療數據庫中存在一些與其他數據行為不同,或是與其他數據差異較大的數據,被稱為離群數據.離群數據中通常存在有用的信息,因此需要對醫療數據庫中存在的離群數據進行檢測,眾多學者進行了相關研究,并取得了一定的成果.
Hauskrecht M 等[1]通過對數據離群點檢測實現異常患者管理,該方法通過使用EMR 存儲庫來學習將患者狀態與病人管理操作相關聯的統計模型,使用電子病歷保存患者信息,通過與以往病歷的異常分析,獲取異常患者行為,但該方法的計算代價較大;Yu YW 等[2]提出了一種新的基于鄰域軌跡離群點的分類方法,對研究對象真實數據集進行理論分析和實證研究,驗證了本文方法在捕獲不同類型數據的有效性,但該方法的離群點檢測率不高,且誤差率較高;Jobe JM 等[3]提出一種基于計算機的數據集群方法,將Rousseuw 的最小協方差行列式方法的重加權版本與最初基于多步聚類的算法結合起來,找出離群點,實驗結果表明,該方法穩健性較好,但是離群點檢測率較低,計算代價大;鄒云峰等[4]提出基于局部密度的數據庫離散數據檢測算法,該算法將弱k近鄰點和強k近鄰點概念引入離散數據檢測中,對鄰近數據點在數據庫中的離群相關性進行分析,根據分析結果區別對待數據點,通過數據點離群性預判方法完成醫療數據庫離群數據的檢測,該算法檢測離散數據的執行時間較長,存在檢測效率低的問題.李少波等[5]提出基于密度的數據庫離群數據檢測算法,該算法在離群數據檢測過程中引入滑動時間窗口,通過滑動時間窗口劃分數據,計算數據的信息熵,根據計算結果對數據進行篩選和剪枝,通過離群因子對篩選后的數據進行判斷,完成數據庫離散數據的檢測,該算法計算得到的離群因子存在誤差,不能準確的對醫療數據庫中的數據進行判斷,存在離散點誤差率高的問題.魏暢等[6]提出基于約簡策略的數據庫離散數據檢測算法,該算法在馬氏距離標準的基礎上對數據集進行簡約處理,通過數據流時間相關性和數據分布密度準則構建決策模型,通過決策模型對數據庫中存在的離散數據進行檢測,該算法構建的決策模型精準度較低,導致離散點檢測率低.尹娜等[7]提出了一種基于混合式聚類算法的離群點挖掘在異常檢測中的應用方法,該方法通過k-中心點算法找出簇中心,在此基礎上去除其中較隱秘的數據樣本,再結合基于密度的聚類算法計算出離群數據的異常度,從而判斷出離群點.但是該算法在挖掘隱秘樣本時出錯率較高,致使最終的檢測結果存在較大誤差.
針對目前現有方法中存在的離群數據檢測過程執行時間較長、檢測效率低、離群點檢測率低的問題,提出基于層次化深度學習的醫療數據庫離群數據檢測算法.在對空間中的稀疏區域和稠密區域進行劃分再合并,實現數據過濾,通過層次化深度學習過程融合專家知識增強對離群數據的多層感知,實現對離群數據的檢測,達到降低算法計算代價、降低耗時、提高檢測率和準確率的目的.
2 動態網格劃分與合并
醫療數據庫中存在海量的數據,在對其中的離群點檢測之前,本文基于層次化深度學習的醫療數據庫離群數據檢測算法首先使用動態網格劃分方法對醫療數據庫中的數據進行篩選,構建候選離群數據集,以此來達到縮小檢測規模、減少檢測執行時間的目的.
動態網格劃分方法是根據醫療數據庫中數據流的密度特點對數據做網格分裂及合并處理,按照密度大小對數據庫空間中的數據進行分類,劃分為稀疏區域和稠密區域,對稠密區域中存在的大量主體數據進行分析,存儲有較大概率成為離群點的數據并構建候選離群點集合[8,9].
將較小的權重賦予給歷史數據,降低歷史數據對網格劃分的影響,使當前數據在數據庫中的分布情況能夠更好的通過網格進行反應[10].
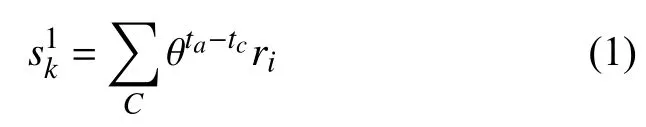
式中,ri代 表的是數據點.網格統計信息元素的計算公式如下:
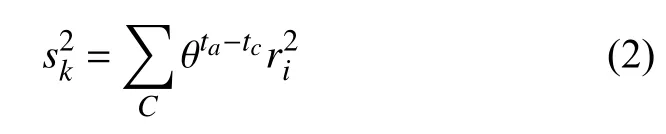

設tc代表的是當前時間.根據上述性質,增量更新數據在網格C中對應的統計信息如下:

在初始化處理時,對數據的網格進行分割,獲得初始網格,根據網格統計信息可以計算得到數據在網格中對應的平均值 μi和標準偏差σi:
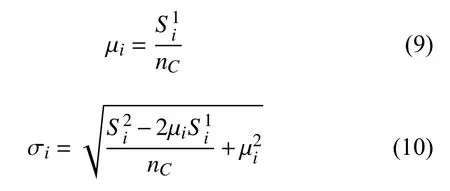
如果網格的密度達到設定的閾值時,分割網格.將數據聚集并劃分到對應的網格中是網格分裂合并的原則[11].所以保存每個維度上網格對應的方差和均值,選擇最大方差相應的維度,在均值處做劃分處理,可以在兩個新生成的網格中劃入數據.
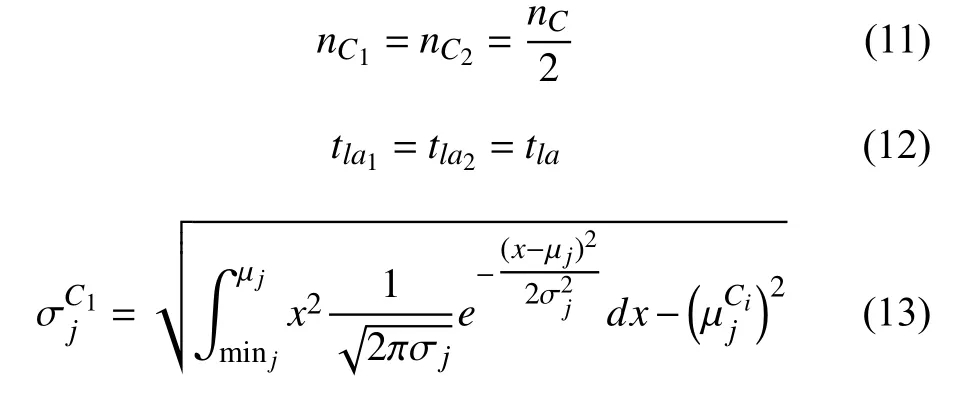
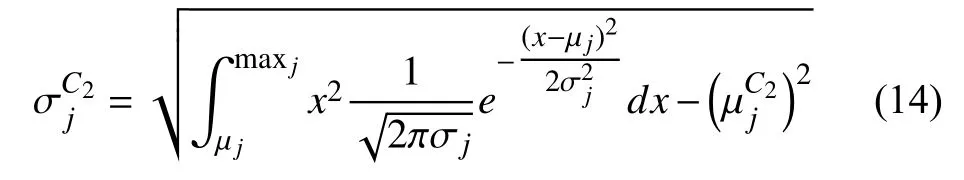
式中,m inj代 表的是第j維度上在網格中存在的最小值;maxj代表的是第j維度上在網格中存在的最大值.

通過對網格進行劃分再合并,能夠去除數據集中的非離群數據,保證剩余的數據均為離群數據,從而實現數據過濾,有效降低算法計算代價和復雜度,節約耗時提高醫療數據庫離群數據檢測的效率.
3 醫療數據庫離群數據層次深度學習檢測
醫療數據庫中,針對數據類別的確定有多種方式,可依據不同設備采集到的數據進行分類,可依據不同種類疾病進行數據分類,還可依據不同身體部位進行數據分類等,只有依據同一分類方式獲取得到的醫療數據才具有實際意義.因此,本文提出了基于深度學習的醫療數據分類和檢測框架,在每一分類層次上都能夠實現數據檢測,即采用層次化深度學習方法對醫療數據庫中存在的離群數據進行檢測.
現有的離群數據檢測算法一般都是根據專家經驗設定對象鄰域半徑,結果隨機性和主觀性較大[13].本文所提的基于層次化深度學習的醫療數據庫離群數據檢測算法中,深度學習是基于模擬人腦進行學習的一種神經網絡,本文采用一種基于卷積神經網絡的深度網絡結構進行離群數據檢測;層次化是指包含了專家知識層次和數據屬性取值分布信息層次兩部分,依據這兩者構建深度網絡分類器,有效感知離群數據,提高離群數據檢測結果的準確率.基于層次化深度學習的離群數據檢測結構框架如圖1 所示.
根據圖1 可知,層次化深度學習檢測框架中,基于專家知識和數據屬性取值分布信息這兩個層次分類,構建了深度網絡分類器.接下來主要通過對數據差異度量來訓練分類器,從而實現離群數據檢測,具體過程如下:
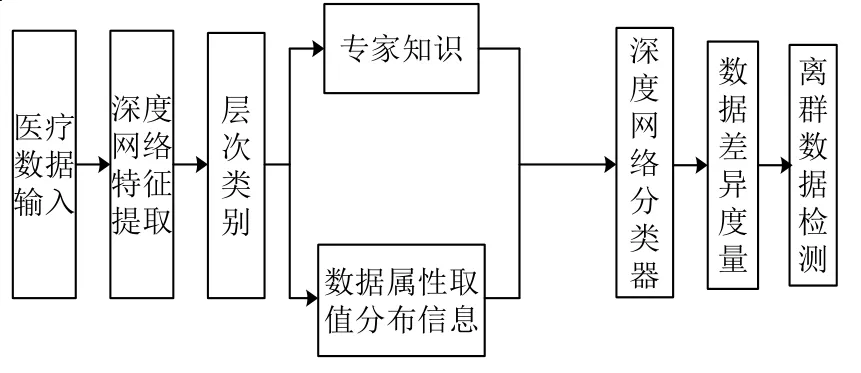
圖1 層次化深度學習檢測框架
醫療數據庫離群數據存在混合型屬性值和數據型屬性值,為了有效的對兩者之間存在的差異進行度量,主要通過度量鄰域距離實現[13,14].設HEOMB(x,y)代表的是重疊度量值,其計算公式如下:
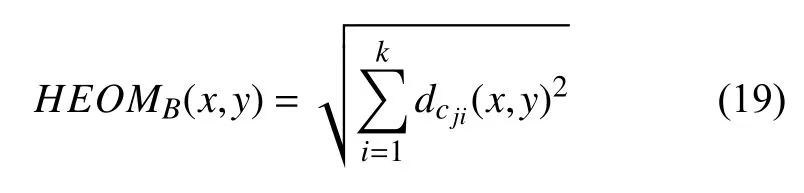
式中,參數dc ji(x,y)的計算公式如下:

通過式(22)確定鄰域半徑 εc j:

式中,std(cj)代 表的是屬性cj取值時對應的標準差,可以通過該標準差對屬性均值的分散程度進行衡量[15].如果標準差std(cj)的 值較大時,表明在屬性cj上大部分數據的均值和取值之間存在的差異較大;如果std(cj)的值較小時,表明在屬性cj上大部分數據的均值和取值之間存在的差異較小[16,17].
λ代表的是專家設定的參數,鄰域半徑的大小可以通過參數λ 進行調整[18].
設VDM(x,y)代表的是差異度量值,其計算公式為:

式中,x,y為對象集中存在的對象;P代表的是對象集對應的特征集;df(xf,yf)代 表的是xf、yf之間存在的距離.
為了確定數據在數據庫中的離群程度,離群度量數據型屬性的取值[19,20].用NVDM(xi,xj)代表某存在對象xi和yi之 間的鄰域值差異度量值,設NOF代表的是鄰域離群因子,其計算公式如下:

設 μ代表的是預設的離群點判定閾值,對比鄰域離群因子NOF與閾值μ 的大小.如果滿足如下條件,則該數據為離群數據,否則為離群數據.對所有的數據判斷完,即完成了對醫療數據庫中離群數據的檢測.

4 實驗分析與結果
為了驗證基于層次化深度學習的醫療數據庫離群數據檢測算法的整體有效性,需要對其進行測試.
實驗條件設置如表1 所示.

表1 實驗條件設置情況
實驗數據:本文使用UCI 機器學習庫中的Annealing和Wisconsin Breast Cancer 數據集(網址:http://archive.ics.uci.edu/ml/).為增強實驗說服力,將本文所提的基于層次化深度學習的醫療數據庫離群數據檢測算法(算法1)與文獻[2](算法2)、文獻[3](算法3)、文獻[4]中的基于局部密度的數據庫離散數據檢測算法(算法4)、文獻[5]中的基于密度的數據庫離群數據檢測算法(算法5)、文獻[6]中的基于約簡策略的數據庫離散數據檢測算法(算法6)、文獻[7]中的基于混合式聚類算法的離群點挖掘在異常檢測中的應用方法(算法7)進行對比測試.
實驗選取的評價指標及計算方式如下:
(1)計算代價:數據在實際應用中,由于過濾不佳或其他問題,易導致錯誤率增加,加大計算代價,本實驗以計算代價為指標進行分析,選取代價權值體現不同算法的計算代價情況,代價權值越高,計算代價越大.
(2)檢測時間:在迭代次數相同的條件下,測試本文算法和算法4、算法5、算法6、算法7 等5 種不同算法檢測離群數據的執行時間,執行時間越短證明檢測效率越高.
(3)離群點檢測率:為了進一步驗證本文所提的基于層次化深度學習的醫療數據庫離群數據檢測算法的整體有效性,將離群點檢測率作為對比指標進行實驗,計算方法如下:
設L代表的是離群點檢測率,其計算公式如下:

式中,Nl代 表的是檢測出正確的離群點總數;Nz代表的是數據集中存在的離群點總數.
(4)離群點誤差率:將離群點誤差率作為對比指標,對基于層次化深度學習的醫療數據庫離群數據檢測算法、算法2、算法5、算法6、算法7 進行測試.
設W代表的是離群點誤差率,其計算公式如下:

式中,M1代 表的是輸出的離群點總數;M2代表的是正確離群點總數;S代表的是數據集總數.
4.1 計算代價對比
對本文基于層次化深度學習的醫療數據庫離群數據檢測算法與算法2、算法3、算法4 進行對比,結果如圖2 所示.

圖2 計算代價對比
分析圖2 可以看出,本文基于層次化深度學習的醫療數據庫離群數據檢測算法的計算代價明顯較低,代價權值不超過1.5,而算法2、算法3、算法4 的代價權值集中在1.0~3.0 之間,算法2 最高,代價權值多在2.5 以上,由此可以看出,本文算法的計算代價小,具有一定的優勢.因為本文算法通過對網格進行劃分再合并,去除了數據集中的非離群數據,即進行了數據過濾,有效提高了數據質量,降低了計算代價.
4.2 檢測時間對比
在迭代次數相同的條件下,5 種不同算法檢測離群數據的執行時間測試結果如圖3 所示.
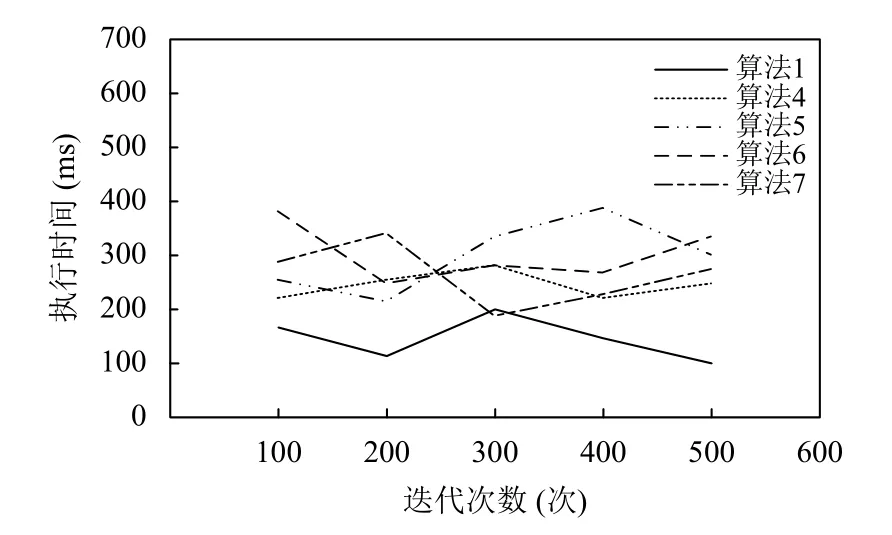
圖3 5 種不同算法的執行時間對比
分析圖3 可知,隨著迭代次數的不斷增加,不同算法的在檢測離群數據時的執行時間也在不斷發生變化.其中,本文所提的基于層次化深度學習的醫療數據庫離散數據檢測算法在多次迭代中的最多執行時間為200 s,其執行時間折線僅在迭代次數為300 次時與基于混合式聚類算法的離群點挖掘在異常檢測中的應用方法的執行時間折線相交,證明該算法的執行時間明顯少于基于局部密度的數據庫離散數據檢測算法、基于密度的數據庫離群數據檢測算法、基于約簡策略的數據庫離散數據檢測算法、基于混合式聚類算法的離群點挖掘在異常檢測中的應用方法的執行時間.這是主要因為基于層次化深度學習的醫療數據庫離群數據檢測算法采用動態網格劃分方法對數據進行篩選,有效縮小了數據檢測的范圍和規模,因此節省了檢測數據所用的時間,大大提高了檢測效率.
4.3 離群點檢測率對比
對基于層次化深度學習的醫療數據庫離群數據檢測算法、算法2、算法3、算法6、算法7 進行測試.
基于層次化深度學習的醫療數據庫離群數據檢測算法、算法2、算法3、算法6、算法7 的離群點檢測率計算結果如表2 所示.

表2 5 種不同算法的離群點檢測率測試結果(%)
為了更直觀、清晰地對比不同算法的離群點檢測率,將表2 中的數據用折線圖的形式表現,如圖4 所示.

圖4 5 種不同算法的離群點檢測率對比
分析表2 和圖4 中的數據可知,在5 次不同迭代中,本文所提的基于層次化深度學習的醫療數據庫離群數據檢測算法的平均離群點檢測率為97.6%,算法4 的平均離群點檢測率為83.0%,算法5 的平均離群點檢測率為75.8%,算法6 的平均離群點檢測率為69.4%,算法7 的平均離群點檢測率為82.2%.對比5 種不同算法的離群點檢測率可知,基于層次化深度學習的醫療數據庫離群數據檢測算法的離群點檢測率始終高于另外4 種算法,進一步證明了本文所提算法的有效性.究其原因,是因為本文算法基于多層次深度學習進行離群數據檢測,融合了卷積神經網絡和層次分類兩者的優勢,有效提高了算法的離群點檢測率.
4.4 離群點誤差率對比
基于層次化深度學習的醫療數據庫離群數據檢測算法、算法2、算法5、算法6、算法7 的離群點誤差率計算結果如表3 所示.
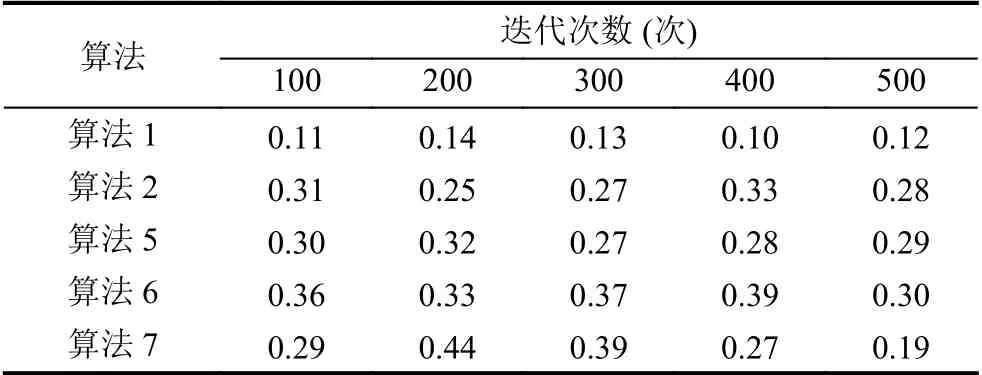
表3 5 種不同算法的離群點誤差率計算結果
為了更直觀地對比不同算法的離群點誤差率,將表3 中的數據用折線圖的形式表現,如圖5 所示.
分析表3 和圖5 可知,在五次不同迭代中,本文所提的基于層次化深度學習的醫療數據庫離群數據檢測算法的平均離群點誤差率為0.12%;算法2 的平均離群點誤差率為0.288%;算法5 的平均離群點誤差率為0.292%;算法6 的平均離群點誤差率為0.35%,算法7 平均離群點誤差率為0.316%.對比5 種不同算法的平均離群點誤差率可知,基于層次化深度學習的醫療數據庫離群數據檢測算法的離群點誤差率始終低于另外4 種算法,證明了本文所提算法的有效性.本文算法融合專家知識和數據的屬性取值分布信息,從多個層次感知離群數據信息,從而降低了離群數據檢測誤差.

圖5 5 種不同算法的離群點誤差率對比
綜上所述,本文所提的基于層次化深度學習的醫療數據庫離散數據檢測算法的離群點檢測率較高、離群點誤差率較低.這主要是因為基于層次化深度學習的醫療數據庫離群數據檢測算法在過濾離群數據時,采用動態網格劃分法降低數據檢測的計算代價,縮短了檢測執行時間,而在計算鄰域半徑時,融合專家知識和數據的屬性取值分布信息,降低了檢測誤差,大大提高了基于層次化深度學習的醫療數據庫離群數據檢測算法的有效性.
5 結語
醫療信息量的不斷增長以及信息技術的飛速進步,使醫療數據庫中積累了大量數據.如何在醫療數據庫中及時、高效、準確的獲取信息,是目前亟需解決的問題之一.針對當前醫療數據庫離群數據檢測算法存在檢測效率低、離群點檢測率低和離群點誤差率高的問題,本文提出基于層次化深度學習的醫療數據庫離群數據檢測算法,可以精準的在短時間內完成醫療數據庫中離群數據的檢測,解決了當前醫療數據庫離群數據檢測算法中存在的問題,具有計算代價小、檢測耗時短、離群點檢測率高、離群點誤差率低的優點,為數據檢測、挖掘技術的發展奠定了基礎.在未來的研究階段,將深入對不同屬性的離群數據進行精細檢測,進一步提高檢測效果.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
海峽科技與產業(2016年3期)2016-05-17 04:32:12
