基于Seq2Seq模型的港口進出口貨物量預(yù)測①
2020-03-18 07:55:00賈宇欣林友芳萬懷宇
計算機系統(tǒng)應(yīng)用 2020年3期
關(guān)鍵詞:模型
王 濤,張 偉,賈宇欣,林友芳,3,萬懷宇,3
1(北京交通大學(xué) 計算機與信息技術(shù)學(xué)院 交通數(shù)據(jù)分析與挖掘北京市重點實驗室,北京 100044)
2(天津市商務(wù)局 口岸平臺處,天津 300040)
3(北京交通大學(xué) 綜合交通運輸大數(shù)據(jù)應(yīng)用技術(shù)交通運輸行業(yè)重點實驗室,北京 100044)
1 引言
港口進出口貨物吞吐量是港口發(fā)展戰(zhàn)略研究的重要內(nèi)容,是港口物流規(guī)劃、物流資源合理配置過程中的重要環(huán)節(jié),同時它也為政府和港口管理部門制定科學(xué)發(fā)展規(guī)劃以及切實可行的市場開拓策略提供依據(jù).政府可以通過港口物流需求預(yù)測評估港口物流行業(yè)對當(dāng)?shù)亟?jīng)濟發(fā)展的總體貢獻,從而制定港口物流行業(yè)的發(fā)展政策,并引導(dǎo)物流市場資源的合理利用與優(yōu)化配置.因此,正確地預(yù)測港口進出口吞吐量對于合理布局港口、科學(xué)制定投資規(guī)模和營運策略,以及綜合運輸規(guī)劃都是十分重要的.與此同時,天津港作為世界上等級最高的人工深水港,也作為我國北方地區(qū)重要進出港口,國內(nèi)國外輻射廣,貨物種類多,運輸模式復(fù)雜,基于多年的港口運行特點形成了自己獨有的物流和報關(guān)模式,在進口和出口通關(guān)數(shù)據(jù)預(yù)測方面十分需要根據(jù)目前實際運行狀況做深入的梳理和研究,以進一步提高口岸管理信息化和通關(guān)作業(yè)裝備自動化水平,同時提高口岸工作效率[1-5].
根據(jù)實際需求,本文研究以天為粒度級同時預(yù)測八種不同類型的集裝箱吞吐量,具體包括:進口集裝箱數(shù)量(進口),出口集裝箱數(shù)量(出口),大集裝箱數(shù)量(大箱),小集裝箱數(shù)據(jù)(小箱),進口大集裝箱數(shù)量(進口大箱),進口小集裝箱數(shù)量(進口小箱),出口小集裝箱數(shù)量(出口小箱),出口大集裝箱數(shù)量(出口大箱).不同類別的集裝箱吞吐量不僅可以反映港口的承載量變化,也可以反映港口的不同類別的集裝箱的變化趨勢.
預(yù)測不同類型進出口貨物的吞吐量是一個非常有挑戰(zhàn)性的問題,因為進出口貨物的吞吐量受到許多復(fù)雜因素的影響.在時間維度上,未來一段時間的貨物吞吐量與距離當(dāng)前時間較近的一段時間以及歷史上具有相似特征時間節(jié)點上的吞吐量都有很大的關(guān)系.另外,由日常工作的規(guī)律可知,貨物吞吐量具有明顯的以日和周為單位的周期性規(guī)律,利用這些規(guī)律都可以幫助我們有效提高貨物吞吐量預(yù)測的準(zhǔn)確性.進出口貨物的吞吐量還會受到天氣、節(jié)假日、國家政策、外部事件等外部因素的影響.
近年來,深度學(xué)習(xí)在很多應(yīng)用領(lǐng)域都取得了很大的成功.循環(huán)神經(jīng)網(wǎng)絡(luò)[6](RNN),在普通多層前饋神經(jīng)網(wǎng)絡(luò)基礎(chǔ)上,增加了隱藏層各單元間的橫向聯(lián)系,通過一個權(quán)重矩陣,可以將上一個時間序列的神經(jīng)單元的值傳遞至當(dāng)前的神經(jīng)單元,從而使神經(jīng)網(wǎng)絡(luò)具備了記憶功能,對于處理有上下文聯(lián)系的NLP、或者時間序列的機器學(xué)習(xí)問題,有很好的應(yīng)用性.長短期記憶模型(Long Short-Term Memory,LSTM)[7]作為一種改進的循環(huán)神經(jīng)網(wǎng)絡(luò),有效地緩解了傳統(tǒng)循環(huán)神經(jīng)網(wǎng)絡(luò)在處理長序列數(shù)據(jù)時存在的梯度消失問題,被廣泛應(yīng)用于時間序列學(xué)習(xí)任務(wù)上.在LSTM 中輸入序列和輸出序列必須等長,為了解決輸入輸出不定長的問題,改進了經(jīng)典的LSTM,并且加入了編碼器、解碼器模塊.Seq2Seq是一個Encoder-Deocder 結(jié)構(gòu)的模型,輸入是一個序列,輸出也是一個序列.Encoder 將一個可變長度的輸入序列變?yōu)楣潭ㄩL度的向量,Decoder 將這個固定長度的向量解碼成可變長度的輸出序列.受此啟發(fā),為了同時刻畫貨物吞吐量在時間維度上的依賴特性,本文提出了基于Seq2Seq 模型的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),用于解決進出口貨物吞吐量預(yù)測問題[8-11].
基于Seq2Seq 的預(yù)測模型首先利用長短期記憶模型刻畫貨物吞吐量隨著時間的推移變化規(guī)律.同時,編碼器-解碼器模塊可更好的學(xué)習(xí)歷史貨物吞吐量之間在高維隱藏空間的變換模式.該模型還可以對外部影響因素建模,進一步提高進出口貨物數(shù)量預(yù)測準(zhǔn)確性.
2 相關(guān)工作
近年來,進出口貨物量預(yù)測已經(jīng)成為海關(guān)進出口貿(mào)易的一個重要問題.進出口貨物量預(yù)測分為定性預(yù)測和定量預(yù)測兩類,在定性預(yù)測中研究人員主要關(guān)心的是貨物量的發(fā)展趨勢.定性研究方法主要有德爾菲法和專家會議法.而定量問題則更關(guān)心進出庫貨物量的具體大小以及一些細(xì)節(jié)的變化比如特殊節(jié)日,傳統(tǒng)的定量預(yù)測集中在以年為單位進行預(yù)測,更關(guān)注整年的情況.本文研究的問題屬于定量預(yù)測問題,而且預(yù)測的單位為天級別,可以做到更細(xì)粒度的預(yù)測,這個問題的難度更大,更具有研究與實際應(yīng)用價值.
進出口貨物預(yù)測的核心研究對象是時間序列數(shù)據(jù).早期的研究主要采用經(jīng)典的時間序列預(yù)測模型,如自回歸滑動平均模型(Autoregressive Moving Average,ARMA)[12],自回歸積分滑動平均模型(Autoregressive Integrated Moving Average,ARIMA)[13-15].基于ARIMA模型,一些擴展模型如SARIMA[16]、KARIMA[17]、VAR[18]以及STARIMA[19]等被提出來以適應(yīng)不同的預(yù)測問題.然而,此類時間序列預(yù)測模型具有很大的局限性,其預(yù)測結(jié)果通常很難滿足人們的要求.
隨著大數(shù)據(jù)技術(shù)越來越成熟,學(xué)者們在解決時間序列的預(yù)測問題時,開始關(guān)注并重點研究數(shù)據(jù)驅(qū)動的模型.其中應(yīng)用得最多的模型包括支持向量回歸模型(Support Vector Regression,SVR)[20]和多元線性回歸模型(Multivariable Linear Regression,MLR)[21]模型以及回歸決策樹模型(Regression Decision Tree,RDT)[22].其中,SVR 模型通過核函數(shù)將數(shù)據(jù)映射到高維空間以描述交通數(shù)據(jù)的非平穩(wěn)變化特征,但其預(yù)測結(jié)果的好壞很大程度上取決于核函數(shù)的選擇.MLR 和RDT 模型則比較關(guān)注于特征的選擇方式,很多學(xué)者針對不同的需求設(shè)計了不同的機器學(xué)習(xí)模型[23-25]用于特定場景下的進出口貨物數(shù)量問題.
近年來,因為深度神經(jīng)網(wǎng)絡(luò)強大的表示能力,基于深度學(xué)習(xí)的模型在時間序列預(yù)測問題當(dāng)中應(yīng)用越來越廣泛,此類模型中的兩個重要分支分別是基于BP 神經(jīng)網(wǎng)絡(luò)的模型和基于循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Networks,RNNs)的模型[26-28].BP 神經(jīng)網(wǎng)絡(luò),即反向傳播網(wǎng)絡(luò),它是利用非線性可微分函數(shù)進行權(quán)值訓(xùn)練的多層網(wǎng)絡(luò),具有極強的容錯性、自組織和自學(xué)習(xí)性,有著較好的函數(shù)逼近和泛化能力.作為第二類重要分支的循環(huán)神經(jīng)網(wǎng)絡(luò)常被用于序列數(shù)據(jù)學(xué)習(xí)任務(wù)[9,29,30].其中,長短期記憶模型[31]在文本分析[32]、語音識別[33]以及機器翻譯[34]等序列數(shù)據(jù)學(xué)習(xí)任務(wù)中都取得了巨大的成功.基于長短時記憶模型的Seq2Seq 模型則克服了其輸入輸出定長的缺陷,可以更靈活的進行預(yù)測.在進出口貨物數(shù)量預(yù)測問題中,我們希望預(yù)測模型能夠自動學(xué)習(xí)過去一段時間數(shù)據(jù)之間的依賴關(guān)系,而不需要人為發(fā)現(xiàn)其中的聯(lián)系.因此,本文提出一種基于Seq2Seq的深度學(xué)習(xí)網(wǎng)絡(luò)結(jié)構(gòu)來解決這一問題.
3 問題描述
本節(jié)對貨物進出口數(shù)量預(yù)測問題進行形式化描述,首先對歷史進出口貨物數(shù)量的整體數(shù)據(jù)特征進行描述,然后在此基礎(chǔ)上對問題進行形式化定義.
圖1 是其幾種不同類型的集裝箱吞吐量的歷史變化趨勢圖.類別分別為大箱進口,小箱進口,大箱出口,小箱出口.如圖1 所示,不同類別的集裝箱以天為單位在時間軸上連續(xù)分布,形成連續(xù)的時間序列,因此港口進出口貨物問題是一個典型的時間序列預(yù)測問題.

圖1 不同種類別集裝箱數(shù)據(jù)趨勢變化
本文的研究問題是依據(jù)不同類別的集裝箱吞吐量歷史數(shù)據(jù)來以周(7 天)為級別預(yù)測未來的集裝箱數(shù)量.
問題定義.給定不同類別進出口貨物歷史統(tǒng)計值{Xt|t=1,2,…,n},預(yù)測Xt+△t.其中Δt∈{1,2,…,7}表示待預(yù)測的時間區(qū)間與當(dāng)前時間區(qū)間t 之間的跨度,即預(yù)測未來一周的數(shù)量.
4 基于Seq2Seq 模型進出口貨物量預(yù)測方法
本節(jié)將詳細(xì)介紹基于Seq2Seq 神經(jīng)網(wǎng)絡(luò)模型的進出口貨物量預(yù)測方法.Seq2Seq 是RNN(循環(huán)神經(jīng)網(wǎng)絡(luò))的一個變種,它是一個Encoder-Decoder 結(jié)構(gòu)的網(wǎng)絡(luò),它的輸入是一個序列,輸出也是一個序列,Encoder中將一個可變長度的信號序列變?yōu)楣潭ㄩL度的向量表達,Decoder 將這個固定長度的向量變成可變長度的目標(biāo)信號序列.這個結(jié)構(gòu)最重要的地方在于輸入序列和輸出序列的長度是可變的.將Seq2Seq 網(wǎng)絡(luò)應(yīng)用于時間序列預(yù)測問題,可以根據(jù)歷史一段時間的信息,去預(yù)測未來一段時間的數(shù)據(jù)情況,通過神經(jīng)網(wǎng)絡(luò)的記憶性、容錯性、自學(xué)習(xí)性來擬合預(yù)測函數(shù),從而進行時間序列問題的預(yù)測.
4.1 問題分析
在進出口貨物預(yù)測問題中存在4 種時間依賴特性,分別為:短時依賴(closeness)特性和周周期依賴(week influence),節(jié)假日影響(holiday influence)特性,特殊情況影響(special influence).例如,圖2 是港口進口集裝箱量在某段時間的以天為單位的變化情況,很明顯地展示了港口集裝箱吞吐量的3 類時間依賴特性.

圖2 進口集裝箱變化曲線
1)短時依賴特性:體現(xiàn)在某一天的集裝箱數(shù)量與其前面剛剛過去的幾天內(nèi)的集裝箱量對預(yù)測該天的影響,即相鄰天集裝箱數(shù)量之間存在很強的相關(guān)性.
2)周周期依賴特性:體現(xiàn)了集裝箱數(shù)量以星期為單位的周期性規(guī)律.歷史上相同的周次之間之間存在一定的聯(lián)系,以此類推即集裝箱吞吐量會受到當(dāng)前日期的星期數(shù)的影響.
3)節(jié)假日影響特性:體現(xiàn)了節(jié)假日(周六,周日,法定放假節(jié)日等)與非節(jié)假日的區(qū)別,節(jié)假日之間的聯(lián)系,還包括節(jié)前補班與節(jié)后上班之間的差異.圖2 中節(jié)假日顯示出明顯的差異.
4)特殊情況影響特性:體現(xiàn)在每個月的月末出現(xiàn)的集裝箱變化異常,以及特殊政策因素造成的影響.
根據(jù)以上分析結(jié)果,我們進行了相應(yīng)的特征構(gòu)造.根據(jù)反復(fù)的特征構(gòu)造實驗以及實驗結(jié)果,我們確定以星期(1-7),是否節(jié)假日,是否補班,月底(月末一周),放假前(前3 天)作為最優(yōu)特征組合,以上特征反映貨物進出口數(shù)量在時間維度上的所有特性.
4.2 模型結(jié)構(gòu)
圖3 是本文提出的基于Seq2Seq 的神經(jīng)網(wǎng)絡(luò)模型的完整網(wǎng)絡(luò)結(jié)構(gòu).該模型可以將短時依賴特性、周周期依賴特性、節(jié)假日影響、特殊情況影響全部都考慮進去,并進行規(guī)律的學(xué)習(xí).

圖3 基于Seq2Seq 的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
圖3 的底端表示模型的輸入.輸入以3 周作為一個窗口,前兩周的特征矩陣作為Encoder 層的輸入,后一周的集裝箱量的值作為Decoder 層的輸出,Decoder層的輸出與真實值作為損失函數(shù)計算的輸入.每一個窗口的輸入由21 天組成,用input= [day1,day2,day3,…,day14]表示每一個窗口里Encoder 層的輸入,dayi=[“Holidays”,“Work”,“Month_end”,“Before_holidays”,“Days1”,“Days2”,“Days3”,“Days4”,“Days5”,“Days6”,“Days7”] 其中dayi∈input.dayi表示特征向量,采用one-hot 方法表示.
output= [day15,day16,day17,…,day21],output向量表示當(dāng)天真實的貨物進出口數(shù)量.這樣每一個訓(xùn)練窗口window= [input,output],表示由Encoder 層的輸入和Decoder 層的輸出維度大小組成的向量,每一個window為 21×12.具體含義見表1.基于深度學(xué)習(xí)的Seq2Seq 模型中有很多需要學(xué)習(xí)的參數(shù),所以需要大量訓(xùn)練樣本.本文提出一種滑動窗口樣本構(gòu)造方法,在給定歷史時間(單位:天)的集裝箱數(shù)據(jù)上,可構(gòu)造出更多訓(xùn)練樣本.本方法尤其適用于歷史數(shù)據(jù)量不充分的情況.每一個訓(xùn)練的窗口window大小為連續(xù)21 天的數(shù)據(jù),然后以天為單位向后滑動窗口,類似于TCP 的滑動窗口選擇[35].假設(shè)總數(shù)據(jù)有N個點(N> 21),那么就可以構(gòu)造(N-21 + 1)個窗口,極大提高了獨立樣本的數(shù)量.滑動窗口可很好刻畫集裝箱量的短時依賴特性,保證數(shù)據(jù)在時間上的連續(xù)性,充分利用每一天的數(shù)據(jù),且可以實現(xiàn)數(shù)據(jù)在時間維度上的交叉驗證即數(shù)據(jù)在不同的窗口內(nèi)既可以充當(dāng)測試集也可以充當(dāng)驗證集,可以更好的優(yōu)化學(xué)習(xí)參數(shù).
圖4 表示單層Seq2Seq 網(wǎng)絡(luò)結(jié)構(gòu),Source 表示網(wǎng)絡(luò)輸入,h(x)和H(x)分別表示LSTM 的cell,在每一層網(wǎng)絡(luò)里Encoder 將輸入Source 序列轉(zhuǎn)為上下文向量(context vector)C,Decoder 將C轉(zhuǎn)化為輸出序列.

表1 特征向量表示
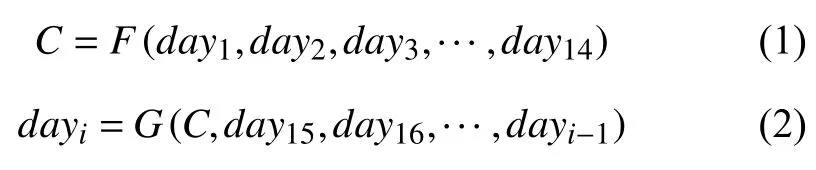
其中,i∈[15,21]且F和G分別表示編碼器和解碼器模塊.
模型的訓(xùn)練以最小化損失函數(shù)為目標(biāo).我們將損失函數(shù)定義為每個窗口里的集裝箱數(shù)量的真實值和預(yù)測值之間的平均絕對誤差,我們以表示模型輸出值,dayi表示真實大小,其中i∈[15,21].

其中,θ包括Seq2Seq 模型中所有需要訓(xùn)練的參數(shù).

圖4 單層Seq2Seq 網(wǎng)絡(luò)結(jié)構(gòu)
基于Seq2Seq 的預(yù)測模型相比于其他方法強調(diào)模型結(jié)構(gòu)的深度,突出特征學(xué)習(xí)的重要性,通過逐層特征變換,將樣本在原空間的特征表示變換到新特征空間,并將時間及外部特征進行編碼、解碼的高維度映射,使預(yù)測結(jié)果更準(zhǔn)確.
5 實驗與結(jié)果分析
5.1 數(shù)據(jù)集
實驗數(shù)據(jù)集為天津港歷史集裝箱吞吐量數(shù)量數(shù)據(jù)集(TJ_DataSet),數(shù)據(jù)集的統(tǒng)計信息如表2 所示.
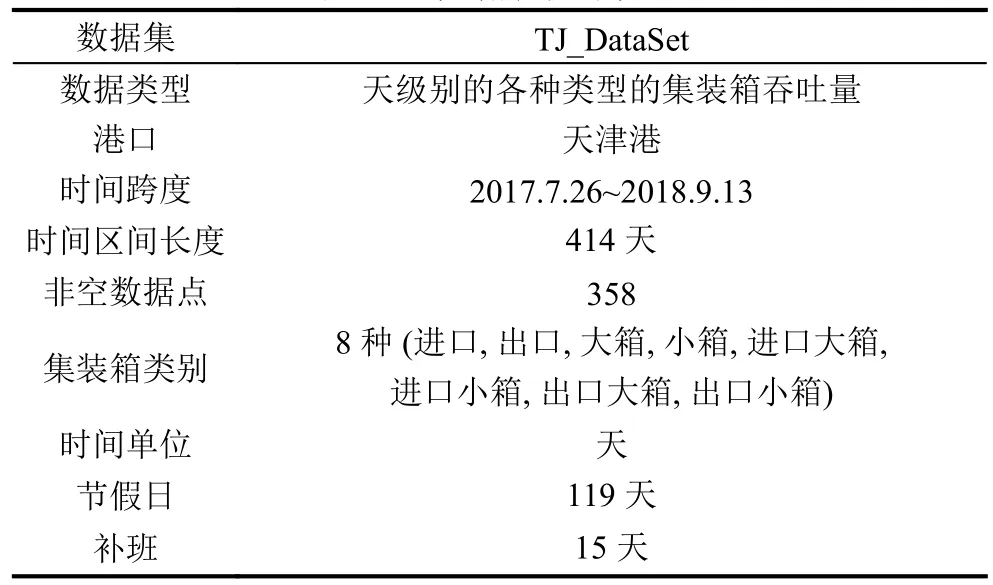
表2 數(shù)據(jù)集統(tǒng)計信息
5.2 數(shù)據(jù)預(yù)處理
(1)無效數(shù)據(jù)過濾
首先對分析數(shù)據(jù),剔除異常數(shù)據(jù),異常原因主要有關(guān)檢融合,系統(tǒng)未普及等,數(shù)據(jù)清洗后選定數(shù)據(jù)質(zhì)量良好的時間段,即2018-3-1~2018-8-25 為實驗數(shù)據(jù)集.
(2)滑動窗口
實驗采取滑動窗口的形式來組織訓(xùn)練集和測試集,將原始數(shù)據(jù)按類別(大箱/小箱/進口大箱/進口小箱/出口大箱/出口小箱/進口/出口)、時間順序排列,數(shù)據(jù)總量為2018-3-1 到2018-8-5,共185 個點,每個時間窗口的大小為21 天(2 周輸入,1 周輸出),并按天滑動.訓(xùn)練集與測試集的比例為7:3,總窗口數(shù)為164 個,其中訓(xùn)練集窗口個數(shù)為126 個,測試集窗口個數(shù)為28 個.
(3)數(shù)據(jù)標(biāo)準(zhǔn)化
對集裝箱量大小進行min-max 標(biāo)準(zhǔn)化,進行標(biāo)準(zhǔn)化可以加快模型的收斂速度以及提高模型的精度.
5.3 基準(zhǔn)方法與評價指標(biāo)
本文將Seq2Seq 模型和以下4 個基準(zhǔn)方法進行比較.
(1)RDT:回歸決策樹模型,是一種基于決策樹的回歸模型.
(2)SVR:支持向量回歸模型,SVR 是使用SVM(支持向量積)來擬合曲線,從而進行回歸分析,是一種應(yīng)用廣泛的時間序列預(yù)測方法.
(3)MLR:多元線性回歸模型,是在線性回歸的基礎(chǔ)上進行時間序列擬合.
(4)LSTM:長短期記憶模型,是一種循環(huán)神經(jīng)網(wǎng)絡(luò)模型,擅長處理序列類型的數(shù)據(jù).
本文使用均方根誤差(Mean Absolute Deviation,MAE)作為模型預(yù)測效果的評價指標(biāo):

其中,dayi表示集裝箱數(shù)據(jù)的真實值,表示集裝箱數(shù)據(jù)的預(yù)測值,n表示連續(xù)天數(shù)大小.
5.4 TJ_DataSet 數(shù)據(jù)集實驗
在TJ_DataSet 數(shù)據(jù)集上驗證了基于Seq2Seq 神經(jīng)網(wǎng)絡(luò)的預(yù)測效果.模型的超參設(shè)置見表3 所示,預(yù)測結(jié)果如表4.
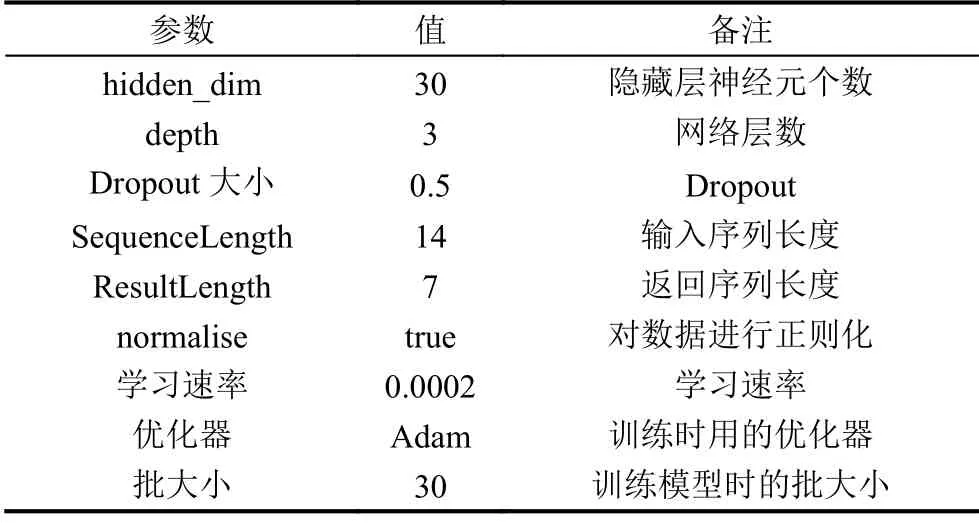
表3 Seq2Seq 中的超參設(shè)置

表4 各種方法預(yù)測結(jié)果
如表4 所示,基于Seq2Seq 的神經(jīng)網(wǎng)絡(luò)明顯比其他基準(zhǔn)方法要好,在大箱進口,大箱出口,小箱出口,進口,出口,大箱,小箱這7 種類別上,Seq2Seq 方法的MAE明顯比其他所有的方法要好,在小箱進口上基于RBF 核的SVR 表現(xiàn)要略好一點,通過對小箱進口的數(shù)據(jù)進行分析發(fā)現(xiàn),測試集種小箱進口的數(shù)據(jù)短期依賴性比較差,而SVR 可以在長期記憶性上做的更好一些.Seq2Seq 模型相對于單獨的LSTM 模型具有較大優(yōu)勢,首先Seq2Seq 可以通過更長時間的數(shù)據(jù)來學(xué)習(xí)短期內(nèi)的一段數(shù)據(jù),而LSTM 只能通過定長的時間來學(xué)習(xí)并預(yù)測與之等長的時間序列,而且Seq2Seq 的編碼器-解碼器模塊具有更高維度上的擬合性.
各種類型的集裝箱數(shù)量預(yù)測圖如圖5 所示,這里截取測試集中2018-7-3~2018-7-31 這一時間段的進行展示.由圖5 可以看出來,模型在未來一段時間內(nèi)的預(yù)測效果相對較好.其中7-23 到7-27 這一周出現(xiàn)明顯的誤差,后經(jīng)過業(yè)務(wù)分析,這一周的確存在因為關(guān)檢融合造成的原數(shù)據(jù)不準(zhǔn)的情況,進一步說明了模型的穩(wěn)定性和正確性,并且具有一定的異常糾錯功能.
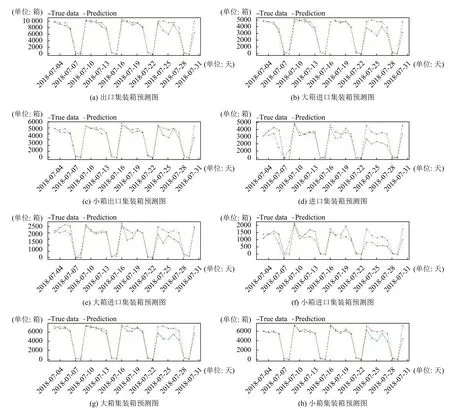
圖5 模型預(yù)測效果圖
6 結(jié)束語
本文提出一種基于Seq2Seq 的神經(jīng)網(wǎng)絡(luò)模型用于解決港口貨物量預(yù)測問題.基于Seq2Seq 的模型可以同時對影響港口貨物量變化的兩類因素,即時間依賴以及外部影響因素進行建模.基于Seq2Seq 的神經(jīng)網(wǎng)絡(luò)模型結(jié)合長短期記憶模型和編碼器、解碼器模塊能夠?qū)W習(xí)港口貨物量數(shù)據(jù)的時間特征,最終通過滑動窗口的學(xué)習(xí)方式,得到準(zhǔn)確的預(yù)測結(jié)果.我們將基于Seq2Seq的模型和經(jīng)典的時間序列預(yù)測模型、機器學(xué)習(xí)模型,基于深度學(xué)習(xí)的預(yù)測模型同時在相同的數(shù)據(jù)集上進行了對比實驗,實驗結(jié)果表明基于Seq2Seq 的網(wǎng)絡(luò)在不同數(shù)據(jù)集上取得了7 種類型下的最優(yōu)和一個類型下的次優(yōu)的預(yù)測效果.但該方法還有優(yōu)化的空間,比如其他外部特征比如政治因素,經(jīng)濟形式,天氣,股票等,也會對集裝箱的吞吐量大小產(chǎn)生一定的影響,但這部分因素難以進行合理量化,可作為后續(xù)模型調(diào)優(yōu)的方向.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
