基于得分規整的說話人確認
2020-03-18 09:42:36梁春燕
智能計算機與應用 2020年10期
曹 偉, 梁春燕
(山東理工大學 計算機科學與技術學院, 山東 淄博 255049)
0 引 言
說話人識別,也稱為聲紋識別,是指利用語音波紋中所包含的信息自動識別說話人身份的技術[1]。由于語音獲取方便,采集設備簡單,并能通過網絡遠程識別,說話人識別正成為一種主要的生物特征識別手段[2]。
根據識別的目的不同,說話人識別可以分為說話人辨認(Speaker Identification)和說話人確認(Speaker Verification)兩種方式[3]。說話人辨認是從給定說話人集合中找到與測試語音匹配的說話人;說話人確認是判斷測試語音是否屬于某個預先聲明的說話人,即需要將測試識別對(由測試語音和其聲明的說話人身份構成)作出“True”或“False”的二類判決。根據是否依賴于語音的內容,說話人識別可以分為與文本有關和與文本無關兩種類型[4]。本文主要基于文本無關的說話人確認展開研究。
在說話人確認的測試階段,不同識別對的得分分布存在著很大的差異性[5],差異性主要來自以下方面:
(1)相同說話人的不一致性。由于受時間、健康狀況、心理狀態、錄音條件等因素的影響,同一說話人的不同測試語音在目標說話人模型上的得分并不是一個恒定值,而是呈現某種概率分布。
(2)不同說話人之間的不一致性。由于受說話習慣、嗓音、語言等因素的影響,不同說話人模型對應的識別對得分表現出不一致性。有的說話人模型對應的識別對得分普遍偏高,有的說話人模型對應的識別對得分則相對偏低。
(3)不同測試語音間的不一致性。在時長、環境噪聲、信道情況等影響下,不同測試語音對應的識別對得分也會表現出不一致性,比如有的測試語音對應的識別對得分普遍偏高,有的測試語音對應的識別對得分則偏低,而有的測試語音在目標說話人模型和非目標說話人模型上的得分比較接近,不容易區分。
綜合以上方面的原因,如果將所有識別對的得分匯集在一起,“True”和“False”兩類識別對的得分會出現嚴重的交叉和混疊;在這種情況下使用統一的門限對每一個識別對作“True”或“False”的判決,會嚴重影響說話人確認系統的性能[6]。因此,需要在識別對原始得分的基礎上進行得分規整[7]。
目前最常用也是最典型的得分規整方法有零規整(Zero normalization,Znorm)、測試規整(Test normalization,Tnorm)以及二者的結合算法ZTnorm等,通過估計“False”識別對的得分分布,對測試識別對的得分進行規整,將“False”識別對的得分規整為均值為0、方差為1的分布,從而消除不同說話人模型間的差異或不同測試語音之間的差異,有效減小兩類識別對得分匯集后的混疊部分,從而提高說話人確認的系統性能。一般來說,得分規整不受限于系統所使用的說話人模型建立方法,無論是簡單基礎的高斯混合模型-通用背景模型(Gaussian Mixture Model-Universal Background Model,GMM-UBM),還是目前比較主流的聯合因子分析(Joint Factor Analysis,JFA)、總變化因子分析(Total Variability Factor Analysis)技術等,原始測試得分均需要進行得分規整,而現有的得分規整方法也都適用于基于以上不同說話人模型的確認系統。
現有的得分規整方法中,大多數都是通過規整“False”識別對得分分布的方式,以減小兩類識別對得分匯集后的重疊部分,卻沒有有效擴大同一說話人模型或同一測試語音對應的兩類識別對得分之間的差距;在這些得分規整方法中,都需要預先收集和選取大量的非目標說話人語音數據來估計“False”識別對得分的均值和方差,而非目標說話人語音數據選取的好壞會影響最終得分規整的效果。
針對現有得分規整方法的不足,本文提出一種對數似然值歸一化得分規整算法(Log-likelihood Normalization,LLN),通過擴大同一測試語音在目標說話人模型與非目標說話人模型上的得分差距,使同一測試語音對應的兩類識別對得分混疊現象得到有效改善;與Znorm、Tnorm和ZTnorm等方法相結合,可同時從不同角度解決兩類識別對得分匯集后的混疊問題,從而進一步提高系統識別性能。
1 說話人確認系統
1.1 說話人確認系統的基本框架
說話人確認系統如圖1所示,主要分為三部分:提取特征、建立模型和打分判決[8]。
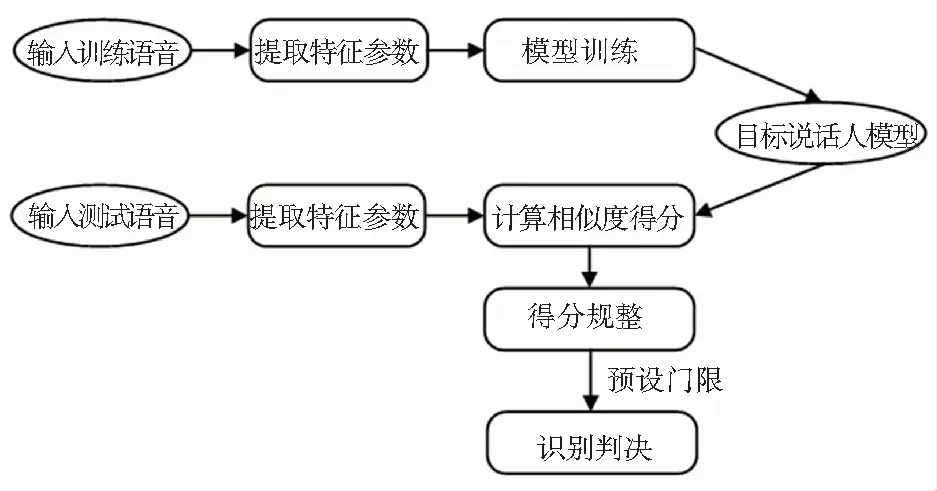
圖1 說話人確認系統
1.2 說話人確認系統的評價指標
在說話人確認系統中,每一次測試,就是將一組識別對進行“True”和“False”判決的過程。當本是“False”的識別對判決為“True”(非目標說話人被接受)時,稱之為“虛警”(False Alarm);當本是“True”的識別對判決為“False”(目標說話人被拒絕)時,稱之為“漏檢”(Miss),這兩種錯判出現的概率分別稱為虛警率和漏檢率。
(1)等錯率(Equal Error Rate,EER)。實際應用中,應同時降低虛警率和漏檢率,然而這二種錯誤概率相互約束,隨著判決門限設定的不同,二者呈相反趨勢變化,只有當虛警率和漏檢率大致相等的時候,系統的性能被認為達到了最大發揮,此時的錯誤率稱為等錯率(EER)。
(2)最小檢測代價(Minimum Value of Detection Cost Function,minDCF)。不同的應用場景對虛警率和漏檢率要求不同,系統門限的設定會按需調整,為了對不同情況下系統性能進行更加貼切地描述,引入了檢測代價函數(Detection Cost Function,DCF)的概念,其數學表達式(1)為:
(1)
其中,CM和CFA分別是漏檢率PM|T和虛警率PFA|NT對應的代價,PT是測試中應該判決為“True”的識別對出現的概率,(1-PT)是應該判決為“False”的識別對出現的概率。檢測代價函數是描述識別錯誤發生后損失大小的一個函數,可以很好地表示系統的性能。設定門限可以得到該門限對應的DCF值,遍歷判決門限,獲得最小檢測代價(minDCF),這是目前美國國家標準技術研究院說話人識別評測(NIST SRE)中最重要的指標。
1.3 零規整(Znorm)和測試規整(Tnorm)
Znorm方法是用大量非目標說話人語音對目標說話人模型打分,計算出對應于目標說話人模型λ的輔助參數均值μλ和方差σλ,用來規整得分分布的差異,其得分規整公式(2)如下:
(2)
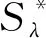
Tnorm是用測試語音對大量非目標說話人模型計算得分,得到對應于測試語音的輔助參數,同樣是均值和方差,用來減少測試語音環境不同對得分分布的影響,最終得分公式同(2)。
對于說話人確認系統,Znorm參數計算在模型訓練階段完成,Tnorm參數計算在測試階段完成。ZTnorm是在得分域將訓練模型和測試語音的信息結合起來,即將Znorm和Tnorm相結合的得分規整方法。上述3種得分規整方法的不足之處是沒有有效擴大同一說話人模型或同一測試語音對應兩類識別對得分之間的差距;并且必須引入先驗知識,需要將訓練數據中的一小部分預留出來作為開發集,用來估計得分規整時需要的參數,而開發集選取的好壞會影響最終得分規整的效果。
2 對數似然值歸一化(Log-likelihood Normalization,LLN)
本文提出一種基于LLN的得分規整方法,該方法相對于Znorm、Tnorm和ZTnorm的優勢在于擴大了同一測試語音在目標說話人模型與非目標說話人模型上的得分差距,使同一測試語音對應的兩類識別對得分混疊現象得到有效改善;并且可以直接對測試得分進行規整,不需要引入先驗知識,因此不需要預留訓練數據。
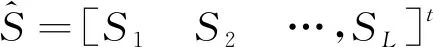
(3)
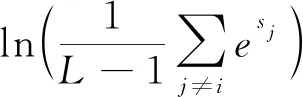
(1)如果i=t,則Si較大,規整量Ni因不包含St,故數值較小;
(2)如果i≠t,則Si較小,規整量Ni因包含St,故數值較大。
公式(3)中每個得分Si作為e的指數是考慮目標說話人模型得分的獨特性(較大且數目少),充分擴大其得分的影響,求和是利用非目標說話人模型得分的共同特點(較小且數目多),減少單個得分的影響,取對數可避免非目標說話人模型得分的規整量差距過大。經過(3)式規整,測試語音對目標說話人模型和非目標說話人模型得分差距會進一步拉大,即可以使識別對中“True”識別對和“False”識別對的得分具有更好的區分性,從而更容易設定門限區分“True”識別對和“False”識別對,提升了系統確認性能。
3 實 驗
3.1 實驗配置
本文實驗在NIST SRE 2008核心測試集 (short2-short3)的電話訓練、電話測試(tel-tel)情況下開展。實驗主要針對女聲測試集,該測試情況下共23 385個測試對,涉及1 674個測試語音和1 140個目標說話人模型,在LLN得分規整階段,每個識別對得分都是基于測試語音數據與全部1140個說話人模型的匹配得分經公式(3)得到。
本實驗中所使用的特征為36維的梅爾頻率倒譜系數(Mel Frequency Cepstral Coefficents,MFCC)特征,其每幀特征由18維的基本倒譜系數及其一次差分(delta)構成。首先用音素解碼器來對語音數據進行語音活動性檢測(Voice Activity Detection,VAD),以去除數據中的靜音部分;然后根據25ms的窗長和10 ms的窗移提取36維的MFCC特征。由于得分規整方法具有普適性,不受限于系統所使用的說話人建模方法,且目前主流的說話人建模技術大多基于GMM-UBM模型,因此本實驗的說話人建模方法選用簡單基礎的GMM-UBM。使用NIST SRE 2004 1side的目標說話人訓練數據訓練與性別相關的UBM,UBM高斯數為1023[9]。并利用本征信道(Eigenchannel)技術在模型域做了信道補償,訓練Eigenchannel信道空間的數據,選擇的是NIST SRE 2004、2005以及2006的電話語音數據,包含755個說話人的數據,共9 855個語音文件。另外,從NIST SRE2006的數據中挑選了340條數據,用于Tnorm得分規整和340條數據用于Znorm得分規整,基本上保證這兩個小數據集每個說話人只有一條語音數據。
3.2 實驗結果
表1比較了Znorm、Tnorm、ZTnorm和LLN不同得分規整方法的實驗結果。從表1可以看出,LLN在不需要開發集的條件下,具有良好的規整性能,相比無得分規整的情況,EER相對提升9.7%,minDCF相對提升4.57%,本身的規整性能可以和Znorm、Tnorm相當。
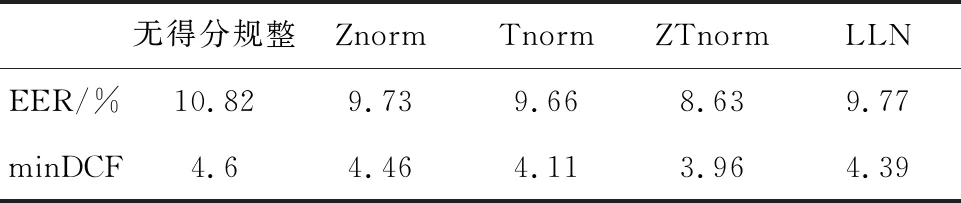
表1 NIST SRE 2008測試集上Znorm、Tnorm和LLN性能比較
表2是在Znorm、Tnorm和ZTnorm基礎上做LLN規整的實驗結果。結合表1和表2中的實驗結果可以看出,LLN可以大幅度提升原有說話人確認系統的性能。在Znorm基礎上做LLN和不做LLN相比,系統的EER和minDCF分別有20.45%和24.44%的性能提升;在Tnorm基礎上做LLN和不做LLN相比,系統的EER和minDCF分別有5.59%和9.98%的性能提升;在ZTnorm基礎上做LLN和不做LLN相比,系統的EER和minDCF分別有11.7%和18.69%的性能提升。

表2 NIST SRE 2008測試集上做LLN的性能
對比LLN規整前后某測試語音在15個說話人模型上的得分變化,如圖2所示。其中,spk13為該測試語音的目標說話人,其余為非目標說話人。從圖2可以看出經LLN規整后,測試語音對目標說話人模型和非目標說話人模型得分差距會進一步拉大。如果門限保持不變,相比LLN規整前,系統的虛警率會明顯降低。

圖2 某測試語音在不同說話人模型上得分
隨機選取500個“True”識別對和500個“False”識別對,比較LLN規整前后的得分分布,如圖3所示。從圖3可以看出經LLN規整后,“False”識別對的得分分布明顯向左偏移,而“True”識別對的得分分布變化不明顯,“True”識別對和“False”識別對的得分差距拉大,區分性增強,有效降低了虛警率。因此,用統一的門限進行判決時會更有優勢。LLN雖然不會改變同一測試語音在每個目標說話人上得分的排序,但可以有效降低EER和minDCF。
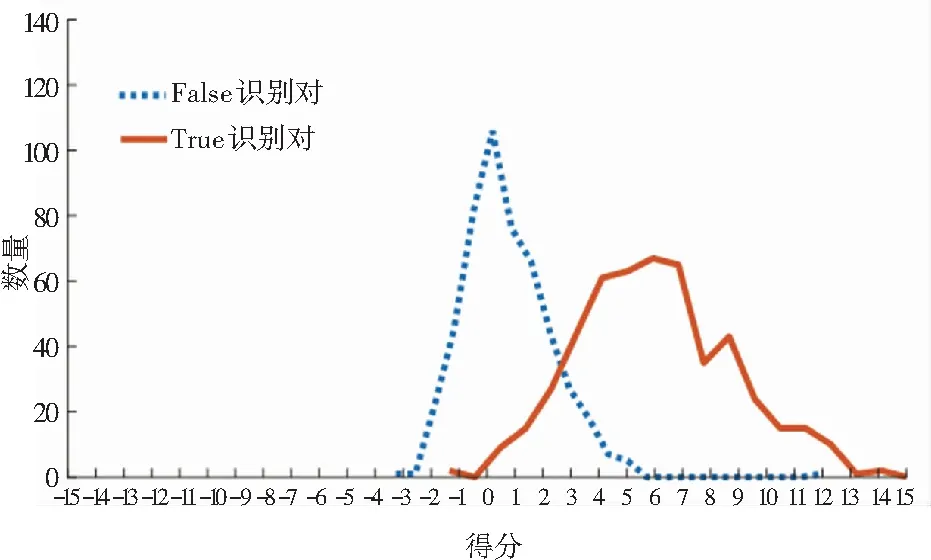
(a) LLN規整前識別對得分分布曲線

(b) LLN規整后識別對得分分布曲線
4 結束語
針對說話人確認系統中現有得分規整方法的不足,本文提出基于對數似然值歸一化(LLN)的得分規整方法。對每個測試對得分,充分利用其測試語音與集中所有說話人模型的得分做出規整,使同一測試語音對目標說話人模型和非目標說話人模型的得分差距拉大;該方法不需要預留額外開發集來估計規整參數,在后端得分域即可進行,因此也不受限于系統所使用的特征參數和模型;與已有的Znorm、Tnorm和ZTnorm得分規整方法能夠很好互補,使不同測試語音或不同說話人模型的得分分布一致的同時,擴大“True”和“False”兩類得分距離,在系統的統一門限下,獲得更好的確認準確率,使說話人確認系統的性能進一步提高。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
