多智能體深度強化學習研究綜述
2020-03-11 13:53:02陳希亮徐志雄
計算機工程與應用 2020年5期
孫 彧,曹 雷,陳希亮,徐志雄,賴 俊
1.陸軍工程大學 指揮控制工程學院,南京210007
2.中國人民解放軍31102部隊
1 引言
多智能體系統(Multi-Agent System,MAS)[1]是在同一個環境中由多個交互智能體組成的系統,該系統常用于解決獨立智能體以及單層系統難以解決的問題,其中的智能可以由方法、函數、過程,算法或強化學習來實現[2]。多智能體系統因其較強的實用性和擴展性,在機器人合作、分布式控制[3]、資源管理、協同決策支持系統、自主化作戰系統、數據挖掘等領域都得到了廣泛的應用。
強化學習(Reinforcement Learning,RL)[4]是機器學習的一個重要分支,其本質是描述和解決智能體在與環境的交互過程中學習策略以最大化回報或實現特定目標的問題。與監督學習不同,強化學習并不告訴智能體如何產生正確的動作,它只對動作的好壞做出評價并根據反饋信號修正動作選擇和策略,所以強化學習的回報函數所需的信息量更少,也更容易設計,適合解決較為復雜的決策問題。近來,隨著深度學習(Deep Learning,DL)[5]技術的興起及其在諸多領域取得輝煌的成就,融合深度神經網絡和RL 的深度強化學習(Deep Reinforcement Learning,DRL)[6]成為各方研究的熱點,并在計算機視覺、機器人控制、大型即時戰略游戲等領域取得了較大的突破。
DRL 的巨大成功促使研究人員將目光轉向多智能體領域,他們大膽地嘗試將DRL方法融入到MAS中,意圖完成多智能體環境中的眾多復雜任務,這就催生了多智能體深度強化學習(Multi-agent Deep Reinforcement Learning,MDRL)[7],經過數年的發展創新,MDRL 誕生了眾多算法、規則、框架,并已廣泛應用于各類現實領域。從單到多、從簡單到復雜、從低維到高維的發展脈絡表明,MDRL 正逐漸成為機器學習乃至人工智能領域最火熱的研究和應用方向,具有極高的研究價值和意義。
2 多智能體深度強化學習基本理論
2.1 單智能體強化學習
單智能體強化學習(Single Agent Reinforcement Learning,SARL)中智能體與環境的交互遵循馬爾可夫決策過程(Markov Decision Process,MDP)[8]。圖1 表示單智能體強化學習的基本框架。
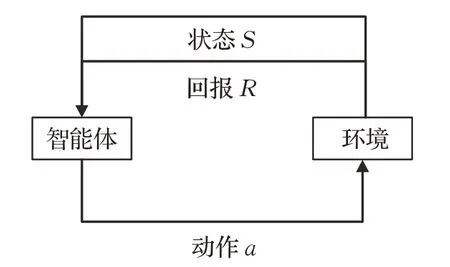
圖1 單智能體強化學習基本框架
MDP 一般由多元組 S,A,R,f,γ 表示,其中S 和A 分別代表智能體的狀態和動作空間,智能體的狀態轉移函數可表示為:

它決定了在給定動作a ∈A 的情況下,由狀態s ∈S轉移到下一個狀態s′∈S 的概率分布,回報函數為:

其定義了智能體通過動作a 從狀態s 轉移到狀態s′所得到的環境瞬時回報。從開始時刻t 到T 時刻交互結束時,環境的總回報可表示為:

其中γ ∈[0 ,1] 為折扣系數,它用于平衡智能體的瞬時回報和長期回報對總回報的影響。智能體的學習策略可表示為狀態到動作的映射π:S →A,MDP 的求解目標是找到期望回報值最大的最優策略π*,一般用最優狀態動作值函數(Q 函數)形式化表征期望回報:
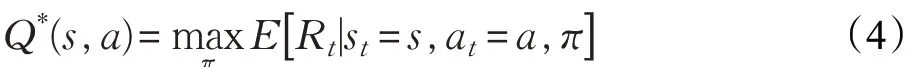
其遵循最優貝爾曼方程(Bellman Equation):
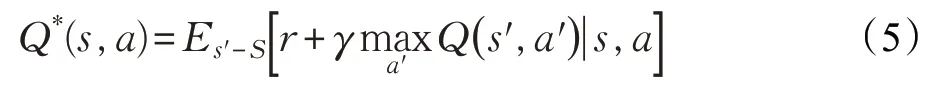
幾乎所有強化學習的方法都采用迭代貝爾曼方程[9]的形式求解Q 函數,隨著迭代次數不斷增加,Q 函數最終得以收斂,進而得到最優策略:

Q 學習(Q-Learning)[10]是最經典的RL算法,它使用表格存儲智能體的Q 值,其Q 表的更新方式如下所示:
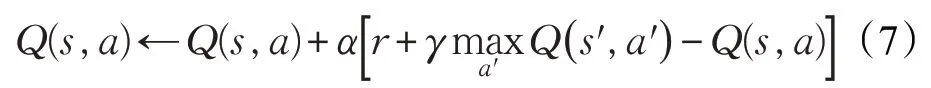
算法通過不斷迭代更新Q 函數的方式求得最優解。
與上述基于值函數(Value Based,VB)的RL方法不同,基于策略梯度(Policy Gradient,PG)[11]的方法用參數化的策略θ 代替Q 函數,并利用梯度下降的方法逼近求解最優策略,該類方法可以用來求解連續動作空間的問題,其代表性算法有REINFORCE[12]、PG[11]、DPG[13]等。
2.2 深度強化學習
傳統RL方法有較多局限性,如學習速率慢、泛化性差、需要手動對狀態特征進行建模、無法應對高維空間等。為了解決此類問題,研究人員利用深度神經網絡對Q 函數和策略進行近似,這就是深度強化學習方法,DRL不僅讓智能體能夠面對高維的狀態空間,而且解決了狀態特征難以建模的問題,下面簡要介紹DRL 及其典型算法。
2.2.1 基于值函數的方法
深度Q 網絡(Deep Q-Network,DQN)結合了深度神經網絡和傳統RL算法Q-Learning的優點,它使用神經網絡對值函數進行近似,與Q 學習等傳統RL算法不同,DQN放棄了以表格形式記錄智能體Q 值的方式,而采用經驗庫(Experience Replay Buffer)[14]將環境探索得到的數據以記憶單元 s,a,r,s′ 的形式儲存起來,然后利用隨機小樣本采樣的方法更新和訓練神經網絡參數。另外DQN還引入雙網絡結構(Fixed Q-targets),即同時使用Q 網絡和目標網絡訓練模型,其中Q 網絡參數θ 隨訓練過程實時更新,而目標網絡的參數θ-是每經過一定次數迭代后Q 網絡參數的復制值,DQN 在每輪迭代i 中的目標為最小化Q 網絡及其目標網絡之間的損失函數。

在經驗庫機制和雙網絡結構的共同作用下,DQN有效解決了數據高相關性的問題,提升了神經網絡更新效率和算法收斂效果,在實際應用中,DQN能夠在多種策略游戲中戰勝高水平人類玩家。研究人員圍繞DQN在多個方面也進行了改進和拓展,如文獻[15]采用雙函數近似解決了過估計問題;文獻[16]利用優勢函數(Advantage Function)將Q 函數進行分解和整合,提升了動作輸出的確定性;文獻[17]使用循環神經網絡(Recurrent Neural Network,RNN)和長短時記憶單元(Long Short Temporal Memory,LSTM)代替傳統的神經網絡,強化了算法應對不同環境的魯棒性;文獻[18]則優化了DQN 的經驗庫機制,提高了算法訓練的效率和效果。
2.2.2 基于策略梯度的方法
與以DQN 為代表的VB 方法相比,PG 方法具有能夠勝任連續且高維的動作空間的優點。其代表算法為深度確定性策略梯度(Deep Deterministic Policy Gradient,DDPG)[19]。DDPG基于演員評論家(Actor-Critic,AC)框架[20];在輸入方面,其通過在Actor網絡引入隨機噪聲的方式產生探索策略;在動作輸出方面采用神經網絡來擬合策略函數,并直接輸出動作以應對連續動作空間;在參數更新方面,與DQN中直接參數復制的方法不同,該算法采用緩慢更新參數的方法提升穩定性;DDPG還引入了批正則化(Batch Normalization)方法保證其對多種任務的泛化能力。除了DDPG 外,AC 框架與PG方法相融合衍生出多種DRL算法,如使用多CPU線程進行分布式學習的異步優勢演員評論家(Asynchronous Advantage Actor-Critic,A3C)算法[21];增強策略梯度穩定性的信賴域策略優化(Trust Region Policy Optimization,TRPO)[22]和近端策略優化(Proximal Policy Optimization,PPO)算法[23]等。
DRL 的成功表明,RL 和神經網絡的融合在單智能體領域已較為普遍,并產生了大量成熟的算法,這為MDRL的突破指明了方向并提供了開闊的思路。
2.3 多智能體強化學習
與單智能體RL 不同,多智能體強化學習(Multi-Agent Reinforcement Learning,MARL)遵循隨機博弈(Stochastic Game,SG)[24]過程。圖2描述了多智能體強化學習的基本框架。
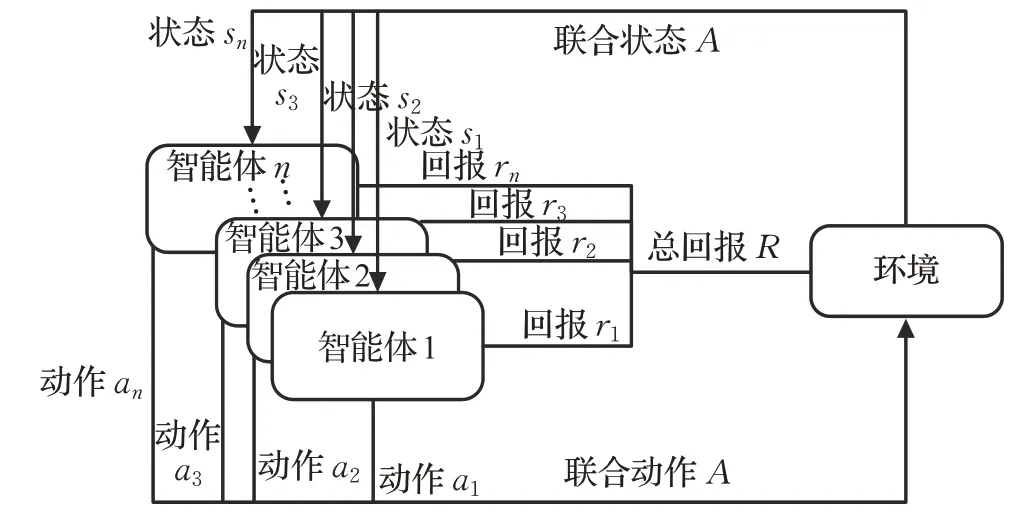
圖2 多智能體強化學習基本框架
SG 可由多元組 S,A1,A2,…,An,R1,R2,…,Rn,f,γ 表示,其中n 為環境中智能體的數量,S 為環境的狀態空間,Ai( )
i=1,2,…,n 為每個智能體的動作空間,A=A1×A2×…×An為所有智能體的聯合動作空間,聯合狀態轉移函數可表示為:

它決定了在執行聯合動作a ∈A 的情況下,由狀態s ∈S 轉移到下一個狀態s ∈S′的概率分布,每個智能體的回報函數可表示為:

在多智能體環境中,狀態轉移是所有智能體共同作用的結果:
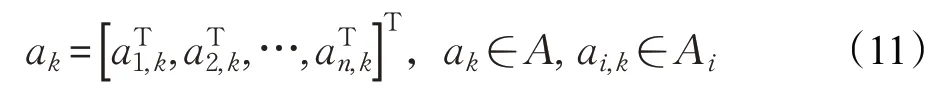
每個智能體的個體策略為:

它們共同構成聯合策略π 。由于智能體的回報ri,k+1取決于聯合動作,所以總回報取決于聯合策略:

每個智能體的Q 函數則取決于聯合動作Qπi:S×A →R,求解方式為:
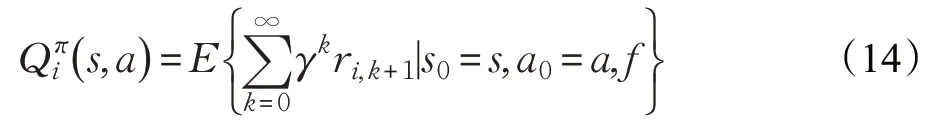
MARL 的算法根據其回報函數的不同可以分為完全合作型(Fully Cooperative)[25]、完全競爭型(Fully Competitive)[25]和混合型(Mixed)[25]三種任務類型,完全合作型算法中智能體的回報函數是相同的,即R1=R2=…=Rn,表示所有智能體都在為實現共同的目標而努力,其代表算法有團隊Q 學習(Team Q-learning)[26]、分布式Q 學習(Distributed Q-learning)[27]等;完全競爭型算法中智能體的回報函數是相反的,環境通常存在兩個完全敵對的智能體,它們遵循SG原則,即R1=-R2,智能體的目標是最大化自身的回報,同時盡可能最小化對方回報,其代表算法為Minimax-Q[28];混合型任務中智能體的回報函數并無確定性正負關系,該模型適合自利型(Self-interested)智能體,一般來說此類任務的求解大都與博弈論中均衡解的概念相關,即當環境中的一個狀態存在多個均衡時,智能體需要一致選擇同一個均衡。該類算法主要面向靜態任務,比較典型的有納什Q學習(Nash Q-learning)[29]、相關Q 學習(Correlated Qlearning)[30]、朋友或敵人Q 學習(Friend or Foe Qlearning)[31]等。表1對多智能體強化學習的算法進行了簡要匯總。

表1 多智能體強化學習算法匯總
總的來看,傳統MARL 方法有很多優點,如合作型智能體間可以互相配合完成高復雜度的任務;多個智能體可以通過并行計算提升算法的效率;競爭型智能體間也可以通過博弈互相學習對手的策略,這都是SARL所不具備的。當然MARL也有較多缺陷,如RL固有的探索利用矛盾(Explore and Exploit)和維度災難(Curse of Dimensionality);多智能體環境非平穩性(Nonestationary)問題;多智能體信度分配(Multiagent Credit Assignment)[32]問題;最優均衡解問題;學習目標選擇問題等。
3 多智能體深度強化學習及其經典方法
由于傳統MARL 方法存在諸多缺點和局限,其只適用于解決小型環境中的簡單確定性問題,研究如何將深度神經網絡和傳統MARL 相融合的MDRL 方法具有很大的現實意義和迫切性。本章將分類介紹主流的MDRL 方法并對每類方法的優缺點進行比較。按照智能體之間的通聯方式,大致將當前的MDRL 方法分為:無關聯型、通信規則型、互相協作型和建模學習型
4 大類。
3.1 無關聯型
此類方法并不從算法創新本身入手,而是將單智能體DRL 算法直接擴展到多智能體環境中,每個智能體獨立地與環境進行交互并自發地形成行為策略,互相之間不存在通信關聯,其最初多用于測試單智能體DRL方法在多智能體環境中的適應性。
Tampuu[33]、Leibo[34]、Peysakhovich[35]等人最早將DQN算法分別應用到Atari乒乓球游戲等多種簡單博弈場景中,他們在算法中引入了自博弈(Self-play)[36]機制和兩套不同的回報函數以保證算法收斂,實驗表明,DQN算法在這些簡單多智能體場景中能夠保證智能體之間的合作和競爭行為;Bansal等人[37]將PPO算法應用到競爭型多智能體模擬環境MuJoCo中,他們引入了探索回報(Exploration Rewards)[38]和對手采樣(Opponent Sampling)[39]兩種技術保證智能體形成自發性對抗策略,探索回報引導智能體在訓練的前期學習到非對抗性的策略,以增加學習策略的維度;對手采樣則引導智能體同時對新舊兩種對手智能體進行采樣,以增加學習策略的廣度;Raghu 等人[40]則嘗試使用DQN、A3C、PPO 等多種單智能體DRL 算法解決了雙人零和博弈問題,實驗結果表明算法可以根據博弈問題的難易程度形成不同的行為策略;Gupta等人[41]將DQN、TRPO、DDPG等算法與循環神經網絡相結合,應用到多智能體環境中,為了提升算法在多智能體環境中的可擴展性,他們引入了參數共享和課程學習機制,算法在多種場景中都取得了不錯的效果。由于無關聯型方法屬于早期對多智能體學習環境的勇敢嘗試,國內研究團隊相對來說較為滯后,理論和實驗貢獻較為有限。表2總結分析了無關聯型方法。
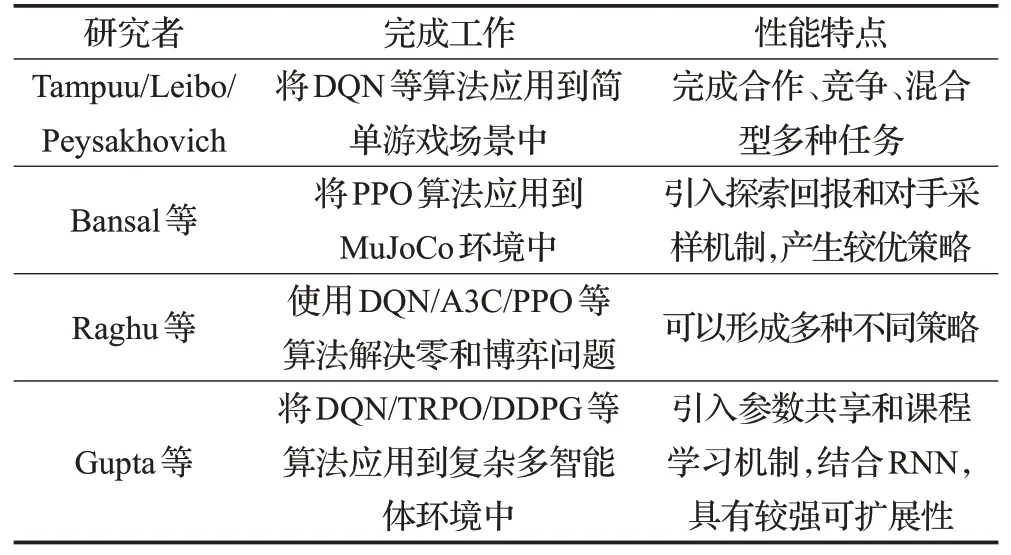
表2 無關聯型方法總結分析
無關聯型方法較易實現,算法無需在智能體之間構建通信規則,每個智能體獨立與環境交互并完成訓練過程,該類方法能夠有效地規避維度災難帶來的影響,且在可擴展性方面有先天性的優勢。但它的局限性也十分明顯,由于智能體之間互不通聯,每個智能體將其他智能體看作環境的一部分,從個體的角度上看,環境是處在不斷變化中的,這種環境非平穩性嚴重影響了學習策略的穩定和收斂,另外該類方法的學習效率和速率都十分低下。
3.2 通信規則型
此類方法在智能體間建立顯式的通信機制(如通信方式、通信時間、通信對象等),并在學習過程中逐漸確定和完善該通信機制,訓練結束后,每個智能體需要根據其他智能體所傳遞的信息進行行為決策,此類方法多應用于完全合作型任務和非完全觀測環境(詳見4.2節)。
強化互學習(Reinforced Inter-Agent Learning,RIAL)[42]和差分互學習(Differentiable Inter-Agent Learning,DIAL)[42]是比較有代表性的通信規則型算法,它們遵循集中訓練分散執行框架,都使用中心化的Q網絡在智能體之間進行信息傳遞,該網絡的輸出不僅包含Q 值,還包括在智能體之間交互的信息,其中RIAL使用雙網絡結構分別輸出動作和離散信息以降低動作空間的維度,而DIAL 則建立了專門的通信通道實現信息端到端的雙向傳遞,相比RIAL,DIAL 在通信效率上更具優勢。
RIAL和DIAL算法只能傳遞離散化的信息,這就限制了智能體之間通信的信息量和實時度。為了解決這一問題,Sukhbaatar 等人提出了通信網(CommNet)算法[43],該算法在智能體之間構建了一個具備傳輸連續信息能力的通信通道,它確保環境中任何一個智能體都可以實時傳遞信息,該通信機制具有兩個顯著特點:(1)每個時間步都允許所有的智能體自由通信;(2)采用廣播的方式進行信息傳遞,智能體可以根據需求選擇接受信息的范圍。這樣每個智能體都可以根據需要選擇和了解環境的全局信息。實驗表明,CommNet 在合作型非完全觀測(詳見4.2節)環境中的表現優于多種無通信算法和基線算法。
國內對于通信規則型的MDRL 研究也取得了不小的進展,其中最著名的有阿里巴巴團隊提出的多智能體雙向協同網絡(Bidirectionally-Coordinated Nets,BiCNet)[44],該方法旨在完成即時策略類游戲星際爭霸2中的微觀管理任務,即實現對低級別、短時間交戰環境中己方的單位控制。算法基于AC框架和雙向循環神經網絡(Bidirectional Recurrent Neural Network,Bi-RNN),前者使得每個智能體在獨立做出行動決策的同時又能與其他智能體共享信息,后者不僅可以保證智能體之間連續互相通信,還可以存儲本地信息。該方法的核心思路是將復雜的交戰過程簡化為雙人零和博弈問題,由以下元組表示:

其中,S 為所有智能體共享的全局狀態,M 、N 和A、B 分別為敵對雙方智能體的數量和動作空間,全局狀態轉移概率為:

第i 個智能體收到的環境回報為:

其中一方的全局回報函數為:

對于敵我雙方智能體來說,學習目標分別為最大化和最小化這一全局期望累計回報,二者遵循Minimax原則,最優Q 值可表示為:
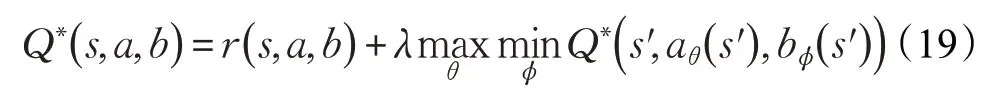
算法假設敵方策略不變,SG過程可被簡化為MDP過程進行求解:
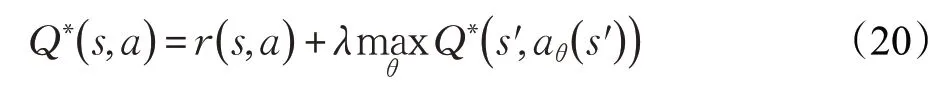
經過充分訓練,BiCNet 算法可以讓游戲中的單位成功實現如進攻、撤退、掩護、集火攻擊、異構單位配合等多種智能協作策略。
近來,通信規則型MDRL方法的研究成果主要側重于改進智能體之間的通信模型以提升通信效率,如北京大學多智能體團隊[45]提出了一個基于注意力機制(ATOC Architecture)的通信模型,讓智能體具備自主選擇通信對象的能力;Kim等人[46]將通信領域的介質訪問控制(Medium Access Control)方法引入到MDRL 中,提出了規劃通信(Schedule Communication)模型,優化了信息的傳輸模式,讓智能體具備全時段通信能力。表3總結了通信規則型方法。
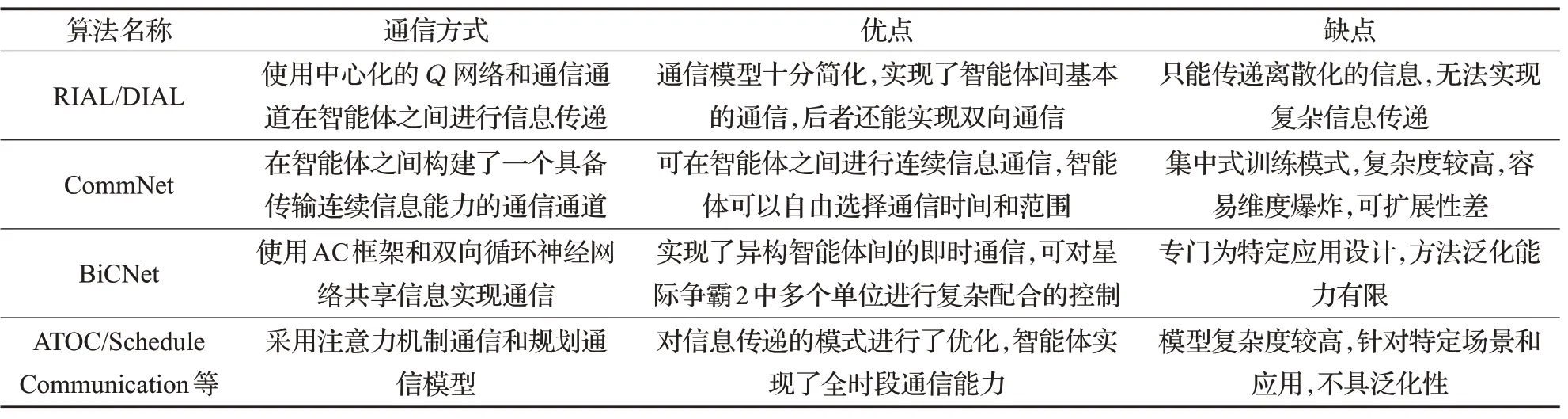
表3 通信規則型方法總結分析
總的來說,通信規則型方法優勢在于算法在智能體之間建立的顯式的信道可以使得智能體學習到更好的集體策略,但其缺點主要是由于信道的建立所需參數較多,算法的設計架構一般較為復雜。
3.3 互相協作型
此類方法并不直接在多智能體間建立顯式的通信規則,而是使用傳統MARL中的一些理論使智能體學習到合作型策略。
值函數分解網(Value Decomposition Networks,VDN)[47]及其改進型QMIX[48]和QTRAN[49]等將環境的全局回報按照每個智能體對環境做出的貢獻進行拆分,具體是根據每個智能體對環境的聯合回報的貢獻大小將全局Q 函數分解為與智能體一一對應的本地Q 函數,經過分解后每個Q 函數只和智能體自身的歷史狀態和動作有關,上述三種算法的區別在于Q 函數分解的方式不同,VDN 才采用簡單的線性方式進行分解,而QMIX和QTRAN則采用非線性的矩陣分解方式,另外,QTRAN 在具有更加復雜的Q 函數網絡結構。該值函數分解思想有效地提升了多智能體環境中的學習效果。
多智能體深度確定性策略梯度(Multi-Agent Deep Deterministic Policy Gradient,MADDPG)[50]是一種基于AC框架的算法,且遵循集中訓練分散執行原則。算法中每個智能體都存在一個中心化的Critic接收其他智能體的信息(如動作和觀測等),即(o1,a1,o2,a2,…,oN,aN),同時每個智能體的Actor 網絡只根據自己的部分觀測執行策略ai=μθi( )oi,每個智能體Critic 網絡的梯度遵循:
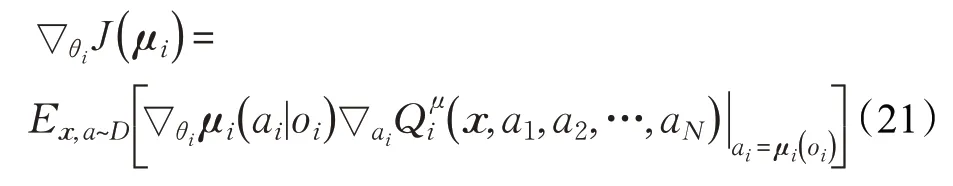
算法通過不斷優化損失函數得到最優策略:
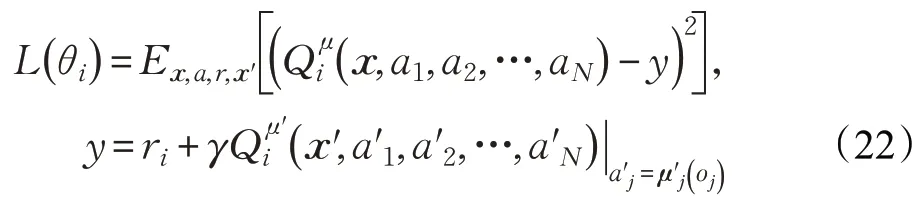
該算法無需建立顯示的通信規則,同時適用合作型、競爭型、混合型等多種環境,能夠很好地解決多智能體環境非平穩問題。
反事實多智能體策略梯度(Counterfactual Multi-Agent Policy Gradients,COMA)[51]是另一種基于AC 框架的合作型算法。該算法采用完全集中的學習方式,主要解決多智能體信度分配問題,也就是如何在只能得到全局回報的合作型環境中給每個智能體分配回報值,該算法的解決方式是假設一個反事實基線(Counterfactual Baseline),即在其他智能體的動作保持不變的情況下去掉其中一個智能體的動作,然后計算當前Q 值和反事實Q 值的差值得到優勢函數,并進一步得出每個智能體的回報,COMA 不受環境的非平穩性帶來的影響,但其可擴展性相對較差。
Pham等人將參數共享(Parameter Sharing,PS)[52]框架與多種DRL算法結合應用于多智能體環境。PS框架的核心思想是利用一個全局的神經網絡收集所有智能體的各類參數進行訓練。但在執行階段仍然保持各個智能體的獨立,相應的算法有PS-DQN、PS-DDPG、PS-TRPO等。
國內的多智能體協作型算法研究也有不小的進展,天津大學的郝建業等人提出了加權雙深度Q 網絡(Weighted Double Deep Q -Network,WDDQN)算法,該方法將雙Q 網絡結構和寬大回報(Lenient Reward)理論加入到經典算法DQN 中[53],前者主要解決深度強化學習算法固有的過估計問題,后者則側重于提升合作型多智能體環境隨機策略更新能力,此外作者還改變了DQN中的經驗庫抽取機制以提升樣本學習質量。實驗結果顯示該方法在平均回報和收斂速率上都超過了多種基線算法。表4總結了互相協作型方法。

表4 互相協作型方法總結分析
互相協作型方法雖然不需要復雜的通信建模過程,但由于在訓練過程中融入了傳統多智能體算法的規則(如值函數分解、參數共享、納什均衡等),兼具易實現性和高效性,且此類方法應對不同學習場景的通用性也很強,其缺點是適用環境較為單一(無法應對完全對抗型環境)。
3.4 建模學習型
在此類方法中,智能體主要通過為其他智能體建模的方式分析并預測行為,深度循環對手網絡(Deep Recurrent Opponent Network,DRON)[17]是早期比較有代表性的建模學習型算法。它的核心思想是建立兩個獨立的神經網絡,一個用來評估Q 值,另一個用來學習對手智能體的策略,該算法還使用多個專家網絡分別表征對手智能體的所有策略以提升學習能力。與DRON 根據對手智能體特征進行建模的方式不同,深度策略推理Q 網絡(Deep Policy Inference Q-Network,DPIQN)[54]則完全依靠其他智能體的原始觀測進行建模,該算法通過一些附屬任務(Auxiliary Task)學習對方智能體的策略,附屬任務完成的情況直接影響算法的損失函數,這樣就將學習智能體的Q 函數和對方智能體的策略特征聯系起來,并降低了環境的非平穩性對智能體學習過程的影響,該算法還引入自適應訓練流程讓智能體在學習對手策略和最大化Q 值之間保持平衡,這表明DPIQN可同時適用于敵方和己方智能體。自預測建模(Self Other Modeling,SOM)[55]算法使用智能體自身的策略預測對方智能體的行為,它也有兩個網絡,只不過另一個網絡不學習其他智能體的策略而是對它們的目標進行預測,SOM適用于多目標場景。
此外,博弈論和MARL的結合也是該類方法的重要組成部分,如神經虛擬自學習(Neural Fictitious Self-Play,NFSP)[56],算法設置了兩個網絡模擬兩個智能體互相博弈的過程,智能體的目標是找到近似納什均衡,該算法適用于不完美信息博弈對抗,如德州撲克。Minimax原則也是博弈論中的重要理論,清華大學多智能體團隊將其與MADDPG 算法相結合并提出了M3DDPG 算法[57],其中Minimax原則用于估計環境中所有智能體的行為都完全敵對情況下的最壞結局,而智能體策略按照所估計的最壞結局不斷更新,這就提升了智能體學習策略的魯棒性,保證了學習的有效性。表5對建模學習型方法進行了總結分析。

表5 建模學習型方法總結分析
建模學習型方法旨在對手或隊友策略不可知的情況下以智能體建模的方式對行為進行預測,這類算法一般魯棒性較強,可以應對多種不同的場景,但計算和建模的復雜度較高,無法適應大型復雜的多智能體系統,所以實際應用較少。表6 對多智能體強化學習方法的分類進行了對比分析。

表6 多智能體強化學習方法分類對比分析
4 多智能體深度強化學習的關鍵問題
盡管MDRL 方法在理論、框架、應用等層面都有不小的進展,但該領域的探索還處在起步階段,與單智能體的諸多方法相同,MDRL方法在實驗及應用層面也面臨許多問題和挑戰,本章對MDRL方法所面臨的關鍵問題和現行解決方案及發展方向進行總結。
4.1 環境的非平穩性問題
與單智能體環境不同,在多智能體環境中,每個智能體不僅要考慮自己動作及回報,還要綜合考慮其他智能體的行為,這種錯綜復雜的交互和聯系過程使得環境不斷地動態變化。在非平穩的環境中,智能體間動作及策略的選擇是相互影響的,這使得回報函數的準確性降低,一個良好的策略會隨著學習過程的推進不斷變差。環境的非平穩性大大增加算法的收斂難度,降低算法的穩定性,并且打破智能體的探索和利用平衡。為解決環境非平穩問題,研究人員從不同角度對現有方法進行了改進,Castaneda[58]提出了兩種基于DQN的改進方法,它們分別通過改變值函數和回報函數的方式增加智能體之間的關聯性;Diallo 等人[59]則將并行運算機制引入到DQN中,加速多智能體在非平穩環境中的收斂;Foerster等人[42]則致力于通過改進經驗庫機制讓算法適用于不斷變化的非平穩環境,為此他提出了兩種方法:(1)為經驗庫中的數據設置重要性標記,丟棄先前產生而不適應當前環境的數據;(2)使用“指紋”為每個從經驗庫中取出的樣本單元做時間標定,以提升訓練數據的質量。目前針對環境非平穩性的解決方案較多,也是未來MDRL領域學術研究的熱門方向。
4.2 非完全觀測問題
在大部分多智能體系統中,智能體在交互過程中無法了解環境的完整信息,它們只能根據所能觀測到的部分信息做出相對最優決策,這就是部分可觀測馬爾可夫決策過程(Partially Observable Markov Decison Process,POMDP),POMDP 是MDP 在多智能體環境中的擴展,它可由多元組G= S,A,T,R,Q,O,γ,N 表示,其中S 和A 分別表示智能體的狀態和動作集合,T和R 則表示狀態轉移方程和回報函數,Q 和O 則為每個智能體Q 值和部分觀測值,每個智能體并不知道環境的全局狀態s ∈S,只能將自己的部分觀測值當作全局狀態,即:
并以此為根據做出決策:

得到一個關于狀態動作的回報值:

之后智能體轉移到了下一個狀態:
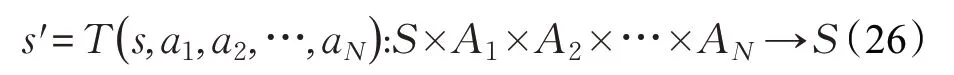
每個智能體的目標都是最大化自己的總回報:

4.3 多智能體環境訓練模式問題
早期的大部分MDRL 算法都采用集中式或分散式兩種訓練模式,前者使用一個單獨的訓練網絡總攬整個學習過程,算法很容易過擬合且計算負荷太大;后者采用多個訓練網絡,每個智能體之間完全獨立,算法由于不存在中心化的目標函數,往往難以收斂。所以兩種訓練模式只支持少量智能體的小型系統。集中訓練和分散執行(Centralized Learning and Decentralized Execution,CLDE)[50]融合了以上兩種模式的特點,智能體一方面在互相通信的基礎上獲取全局信息進行集中式訓練,然后根據各自的部分觀測值獨立分散執行策略,該模式最大的優點是允許在訓練時加入額外的信息(如環境的全局狀態、動作或者回報),在執行階段這些信息又可被忽略,這有利于實時掌控和引導智能體的學習過程。近來采用CLDE 訓練模式的MDRL 算法不斷增加。以上述三種基本模式為基礎,研究人員不斷探索出新的多智能體訓練模式,它們各有優長,可應用于不同的多智能體環境,限于篇幅原因本文就不做贅述。
4.4 多智能體信度分配問題
在合作型多智能體環境中,智能體的個體回報和全局回報都可以用來表征學習進程,但個體回報一般難以獲得,所以大部分實驗都使用全局回報計算回報函數。如何將全局回報分配給每個智能體,使其能夠精準地反映智能體對整體行為的貢獻,這就是信度分配問題。早起的方法如回報等分在實驗中的效果很差。差分回報(Difference Rewards)[60]是一個比較有效的方法,其核心是將每個智能體對整個系統的貢獻值進行量化,但這種方法的缺點是很難找到普適的量化標準,另外該方法容易加劇智能體間信度分配的不平衡性。COMA[51]中優勢函數(Advantage Function)思想也是基于智能體的貢獻大小進行信度分配,算法通常使用神經網絡擬合優勢函數,該方法無論是在分配效果還是效率上都好于一般方法。總之,信度分配是MDRL算法必須面臨的重要問題,如何精確高效地進行信度分配直接關系到多智能體系統的成敗,這也是近來多智能體領域研究的重點。
4.5 過擬合問題
過擬合最早出現在監督學習算法中,指的是算法只能在特定數據集中取得很好的效果,而泛化能力很弱。多智能體環境中同樣存在過擬合問題,比如在學習過程中其中一個智能體的策略陷入局部最優,學習策略只適用于其他智能體的當前策略和當前環境。目前有3種比較成熟的解決方法:(1)策略集成(Policy Emsemble)[50]機制,即讓智能體綜合應對多種策略以提升適應性;(2)極小極大(Minimax)[57]機制,即讓智能體學習最壞情況下的策略以增強算法的魯棒性;(3)消息失活(Message Dropout)[61]機制,即在訓練時隨機將神經網絡中特定節點進行失活處理以提升智能體策略的魯棒性和泛化能力。
5 多智能體深度強化學習的測試平臺
許多標準化的平臺如OpenAI Gym 已經支持在模擬環境中測試經典DRL 和MARL 算法,但由于MDRL起步較晚,目前來看還是一個較為新穎的領域,所以其配套測試平臺還有待進一步發展完善。當前已有一些研究機構或個人開發了一部分開源的模擬器和測試平臺用于MDRL 算法的分析和測試,它們各有特點,且面向不同類型的環境,本章將進行簡單介紹。
Bu?oniu等人開發出一種基于matlab的多智能體物體運輸(Coordinated Multi-agent Object Transportation,CMOT)環境[25],其本質上是一個2D 網格雙智能體環境,Palmer 等人在該環境原始版本的基礎上進行了擴展,使其支持隨機回報和噪聲觀測等復雜條件,該平臺面向傳統MARL 合作型算法的測試工作(http://www.dcsc.tudelft.nl/);炸彈人游戲(Pommerman)是由Facebook AI實驗室和Google AI聯合贊助的多智能體環境測試平臺,它同樣也是一個二維網格環境,最多可以容納四個智能體,支持合作型、競爭型、混合型等多種多智能體算法的測試,并且還支持非完全觀測環境和智能體的通信建模,測試人員依托該平臺不僅可以將自己的改進算法和基線算法進行對比,還可以與其他測試人員的算法實時對抗。另外該平臺還支持python、Java等多語言編寫(https://www.pommerman.com/);MuJoCo 最早是由華盛頓大學運動控制實驗室開發的物理仿真引擎,可應用于具有豐富接觸行為的復雜動態系統,平臺支持多種可視化的多智能體環境,研究人員目前已將多智能體足球游戲(Multi-agent Soccer Game)應用到該引擎中,讓環境模擬2對2比賽,該平臺的優點是可支持三維動作空間;谷歌DeepMind 和Blizzard 公司聯合開發了一個基于即時策略類游戲星際爭霸2 的DRL 平臺SC2LE,該平臺提供基于Python的開源接口來與游戲引擎進行通信,其中的多智能體測試主要針對小型場景的微觀管理,場景中的每個單位都由一個獨立的智能體控制,該智能體基于自己的部分觀測做出動作,該平臺已經成功應用多種MDRL 算法,如QMIX[48]、COMA[51]等;基于3D沙盒游戲《我的世界》的Malmo平臺可用于完成多場景合作型任務,并支持多種開源項目,具備實時調試的功能;以卡牌類游戲Hanabi為背景的學習平臺支持多玩家多任務競爭,該游戲的主要特點是玩家不僅分析自己手中的牌,同時也知曉其他玩家的部分信息,所以非常適合針對POMDP問題算法的測試;競技場(Arena)是一個基于Unity 引擎的多智能體搜索平臺,該平臺的支持多種經典多智能體場景(如社會難題、多智能體搬運等),并支持在智能體之間通信規則的搭建,目前該平臺已能夠實現如IDQN[41]、ITRPO[41]、IPPO[41]等幾種簡單的MDRL算法。
6 多智能體深度強化學習的實際應用及前景展望
6.1 多智能體深度強化學習的實際應用
MARL的實際應用領域十分廣泛,涉及領域包括自動駕駛、能源分配、編隊控制、航跡規劃、路由規劃、社會難題等,下文對此進行簡要的介紹。
Prasad和Dusparic[62]將MDRL模型應用到能源分配領域,模擬場景為一個由數幢樓房組成的社區,并假定該社區中的每幢樓房每年消耗的能源不高于產生的能源,在該場景中,樓房由智能體表示,它們通過學習適當的多智能體策略優化能源在建筑物間的分配方式,環境中的全局回報由社區中的能源總量來表示,即:
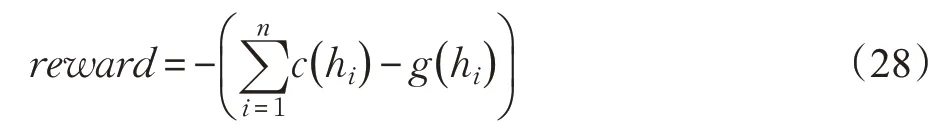
其中c( hi)和g( hi)分別表示第i 幢樓房的能源消耗和能源產出,另外環境中設置一個控制智能體主導智能體數量的增減和能源的實時分配,實驗表明該模型在保持樓房能源平衡的表現好于隨機策略模型。但該模型的缺點為訓練中不能實時觀察智能體的行為,另外該模型也不能適用于大型環境(樓房數量的上限為10),模型的架構也有待完善(未能考慮能源分類等更為復雜的情況)。
Leibo 等人[34]提出了解決貫序社會難題(Sequential Social Dilemmas,SSD)的模型,它用于解決POMDP 環境下多智能體環境中的合作問題。Hüttenrauch 等人[63]則嘗試控制大量的智能體完成復雜的任務,該應用也被稱為群體智能系統。系統使用的方法基于演員評論家框架,利用全局狀態信息學習每個智能體的Q 函數,研究人員還截取環境的實時圖像用于收集分析智能群體的狀態信息。該群體智能系統可以完成如搜索救援、分布式組裝等多種復雜合作型任務。Calvo 和Dusparic[64]則在群體智能系統中加入了多種對抗型MDRL 算法使系統中的不同智能體獨立并發的訓練,改進后的系統能夠勝任如城市交通信號控制等多種類型的任務。
通信規則型算法在實際問題中的應用較為廣泛。Nguyen 等[65]在智能體之間構建了一種特殊的通信通道以圖片形式傳輸人類知識,場景使用A3C算法,其優點是支持異構型智能體間的合作;Noureddine 等[66]基于合作型DRL算法構建了一套松耦合的分布式多智能體環境,環境中的智能體可以像人類團隊一樣互幫互助,適用于解決資源和任務的分配問題;CommNet 算法因其強大的通信能力也多被用于高復雜度的大型任務分配問題并取得了不錯的效果,但它也有計算復雜度高、通信開銷大等缺點。
互相合作型算法主要在編隊控制、交通規劃、數據分析[67]等方面有所應用。其中Lin等人[68]將多種合作型算法應用在大型編隊控制問題上,他們的方法聚焦于如何平衡分配交通資源以提升交通效率,減少擁堵,該方法使用參數共享機制保證多個車輛間的協同。Schmid等人[69]則將經濟學中的交易規則引入到多智能體系統中,在該系統中,智能體的動作、狀態、回報等參數都被看成可以互相交易的資源。該方法有效地抑制了每個獨立智能體的貪婪行為,從而利于達到系統回報的最大化,該系統在社會福利分配等經濟學問題中有可觀的應用。
6.2 多智能體深度強化學習的前景展望
MDRL雖然在眾多領域都有實際應用,但由于起步時間較晚,理論成熟度較低,其發展潛力十分巨大,前景相當可觀。
現有的MDRL算法大部分采用無模型的結構,雖然簡化了算法的復雜度,并且適用于復雜問題求解,但該類方法需要海量的樣本數據和較長的訓練時間為支撐,基于模型的方法則具有數據利用效率高、訓練時間短、泛化性強等優點,基于模型的強化學習算法在單智能體領域取得了較多進展,其必然是MDRL 未來的重點研究方向[70];模仿學習(Imitation Learning)[71]、逆向強化學習(Inverse Reinforcement Learning)[72]、元學習(Meta Learning)[73]等新興概念在單智能體領域已經有了不小的成果,解決了不少現實問題,其在多智能體領域的應用前景將相當可觀;在城市交通信號控制、電子游戲競技等實際應用中,同構型的智能體擁有如行為、目標和領域知識等較多的共性特點,可以通過集中訓練的方式提升學習的效率和速率,但當環境是由大量異構型智能體組成時,如何學習到有效的協同策略并得到最優解成為了一大難題,這其中需要解決如異構型智能體信度分配、過估計、可擴展性等多種實質問題,總之大型異構多智能體系統也是一個非常有前景的研究方向[74];人機交互這個詞正不斷地被大眾所接受,文獻[75-77]中人機智能交互是MDRL 未來的發展方向。因為在復雜環境中人類無法單獨處理海量數據,而機器則難以解決非形式化的隱性問題,所以人類智慧與機器智慧的結合至關重要。近來,研究人員已經在嘗試將人在回路(Human-On-The-Loop)[76]框架融合到MDRL算法中,即人類和智能體合作解決復雜問題,在傳統的“人在回路”設定中,智能體自動地完成其所分配的任務,然后等待人類指揮員做出決策并繼續自己的任務。未來將實現從“人在回路”到“人控回路”的飛躍,即從機器完成任務和人做決策的傳統時序框架到機器與人智能化協作共同完成任務的新體系,人作為終極掌控者將會在多智能體領域中扮演愈發重要的角色。
7 結語
本文對按照由淺入深的次序對多智能體深度強化學習進行了分析,介紹了包括MDRL 的相關概念、經典算法、主要挑戰、實際應用和發展方向等。本文首先在引言部分簡要介紹了MDRL的背景知識,隨后按照從單智能體到多智能體的發展順序簡述了傳統MARL 的基本框架,并按照回報函數的不同將MDRL 分為合作型、競爭型和混合型三類,接著對DRL 及其代表算法進行了簡要的概括,由此引入MDRL 的概念,之后根據多智能體間的關聯方式的不同將MDRL算法分為無關聯型、通信規則型、互相協作型和建模學習型四大類,并分別對各類別的主要算法進行介紹和對比分析,最后對MDRL 算法的測試平臺、主要挑戰、實際應用和未來展望進行簡要的闡述。通過本文可以得出結論:多智能體深度強化學習是個新興的、充滿創新點的、快速發展的領域,無論是學術研究還是工程運用方面都較多空間亟待拓展,相信隨著研究的不斷深入,將會誕生更多方法解決各類復雜的問題,實現人工智能更美好的未來。
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
中國生殖健康(2020年6期)2020-02-01 06:28:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
中國生殖健康(2019年11期)2019-01-07 01:28:02
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
