基于重引力搜索鏈接預測和評分傳播的大數據推薦系統
2020-03-11 12:50:54耿海軍
計算機應用與軟件 2020年2期
李 貞 吳 勇 耿海軍
1(晉中職業技術學院電子信息學院 山西 晉中 030600)2(山西大學軟件學院 山西 太原 030013)
0 引 言
隨著移動互聯網和電子商務領域的蓬勃發展,目前已經進入信息嚴重過剩的網絡時代,為提高用戶瀏覽網絡信息的效率,自動推薦系統應運而生[1]。龐大的信息量和高復雜度的社交網絡為自動推薦系統帶來了巨大的挑戰,當前的推薦系統對于大規模數據和復雜網絡難以實現快速、準確的推薦服務[2]。
稀疏性問題和冷啟動問題是推薦系統的一個重要問題,直接影響推薦系統的推薦準確性、多樣性等性能[3]。深入挖掘并利用用戶的社交關系信息以及語義信息是目前解決這些問題的重要手段,文獻[4]提出的近鄰矩陣分解算法,將用戶近鄰與項目近鄰評分信息融合為一個近鄰評分矩陣,挖掘目標用戶對目標項目的評分信息。該算法降低了原始評分矩陣的稀疏性問題,并且有效地提高了推薦的準確性,但其未利用社交關系的社區信息,不支持分布式計算的擴展方法,對于大規模復雜網絡的搜索時間較長。文獻[5]運用SVD降維技術得到項目的隱式特征空間,引入項目信任因子,建立信任模型并融入到相似度空間中。該算法充分應用了用戶的社交關系,并且通過降維技術加快了系統的處理時間,但其采用余弦相似度計算項目間的相似度,存在較高的冗余度[6]。文獻[7]將Tri-training框架加以擴展,提出基于用戶活躍度生成無標記教學集合的算法和對矩陣分解模型擴充的形式,該算法對于復雜網絡的計算效率較低,難以提供高效的推薦列表。結合大量的研究和分析,現有的推薦系統大多存在以下的不足之處:① 未利用社交關系的社區信息;② 對于大規模復雜網絡的搜索時間較長;③ 不支持并行計算的擴展方法;④ 學習語義信息的過程中需要大量的時間。
皮爾森相似度、余弦相似性[8-9]是協同過濾推薦系統中廣泛采用的相似性度量方案,為充分考慮用戶環境的作用[10],采用相對相似性指數(Relative Similarity Index,RSI)度量用戶的相似性,應用Meta Path概念[11]構建網絡結構。為支持并行計算的可擴展性,將大規模復雜網絡劃分社區結構,再對小規模的子圖做并行處理。為解決稀疏性問題和冷啟動問題,設計了基于重引力搜索[11]的鏈接預測機制和評分信息傳播機制(Gravitational Search based Link Prediction & Rating Propagation,GSLPRP),以較短的學習時間獲得充足的隱藏評分信息。
1 推薦系統的主要結構
圖1所示是推薦系統的主要模塊。本算法主要由3個階段組成:第一階段:計算用戶之間的相似性,該階段結合RSI和Meta Path來增強用戶間的相似性計算。第二階段:應用鏈接預測算法發現隱藏的網絡鏈接,該階段設計了基于重引力搜索的鏈接預測算法,發現隱藏的用戶鏈接來緩解稀疏性問題。第三階段:應用評分傳播機制,該階段設計了基于傳染病模型的評分信息傳播機制,進一步豐富用戶的評分信息。
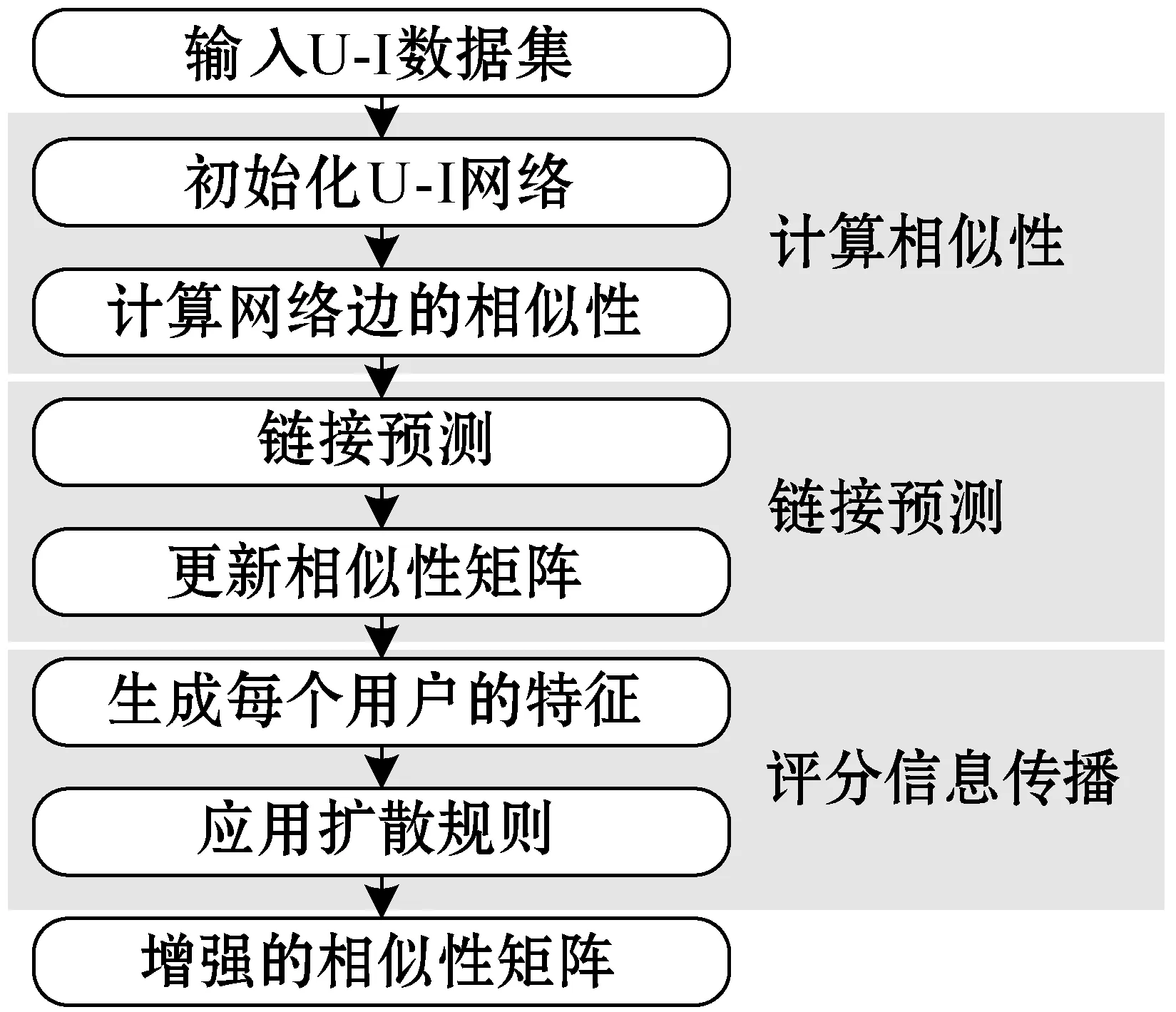
圖1 推薦系統的主要模塊
2 相似性計算
2.1 RSI相似性
文獻[12]提出了RSI,有效地提高了推薦系統的準確率和多樣性。兩個用戶ui和ui+1之間的RSI指數計算為:
(1)
式中:sim為兩個節點的余弦相似性,co_rate是與目標用戶共同評分的項目數量,max(co_rate)為網絡中每對用戶共同評分的項目數量。
2.2 構建基于meta-path的相似性圖
構建一個廣義的用戶-項目網絡(User-Item,U-I),網絡的節點為用戶和項目,邊為加權的鏈接,表示用戶對于各個項目的評分。圖2所示是一個網絡的實例,圖中U表示用戶,I表示項目,網絡由4個用戶和6個項目組成,鏈接為用戶對于項目的評分。
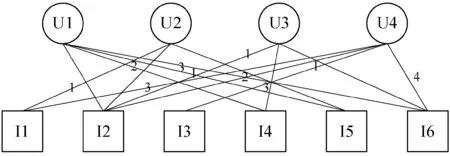
圖2 一個U-I網絡的實例
異構網絡中存在不同類型的節點和鏈接,采用廣義路徑Meta Path模型,定義為異構網絡中從一個節點到另一個節點之間包含的節點和鏈接,計算網絡中所有的Meta Path需要極大的計算負擔。Meta Path需要計算路徑內所有的用戶節點和項目節點,結合評分信息構建網絡,基于Meta Path計算用戶間的相似性。
采用“用戶-項目-用戶”的Meta-Path,簡稱為simUIU。simUIU計算加權Meta-Path的相似性,假設評分范圍為{1,2,3,4,5},將評分信息分為三個級別:低:{1,2},中:{3,4};高:{5}。圖3是評分分級的示意圖,將Meta-Path細分為三個加權的子Meta-Path{P1,P2,P3},圖中P1子Meta-Path對應評分值在R1區間的情況。
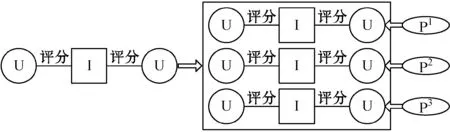
圖3 評分分級的示意圖
然后將U-I網絡分為3個子網,如圖4所示。將從細粒度轉化為粗粒度的目的是提高評分的可理解性,有助于觀察用戶的相似度。
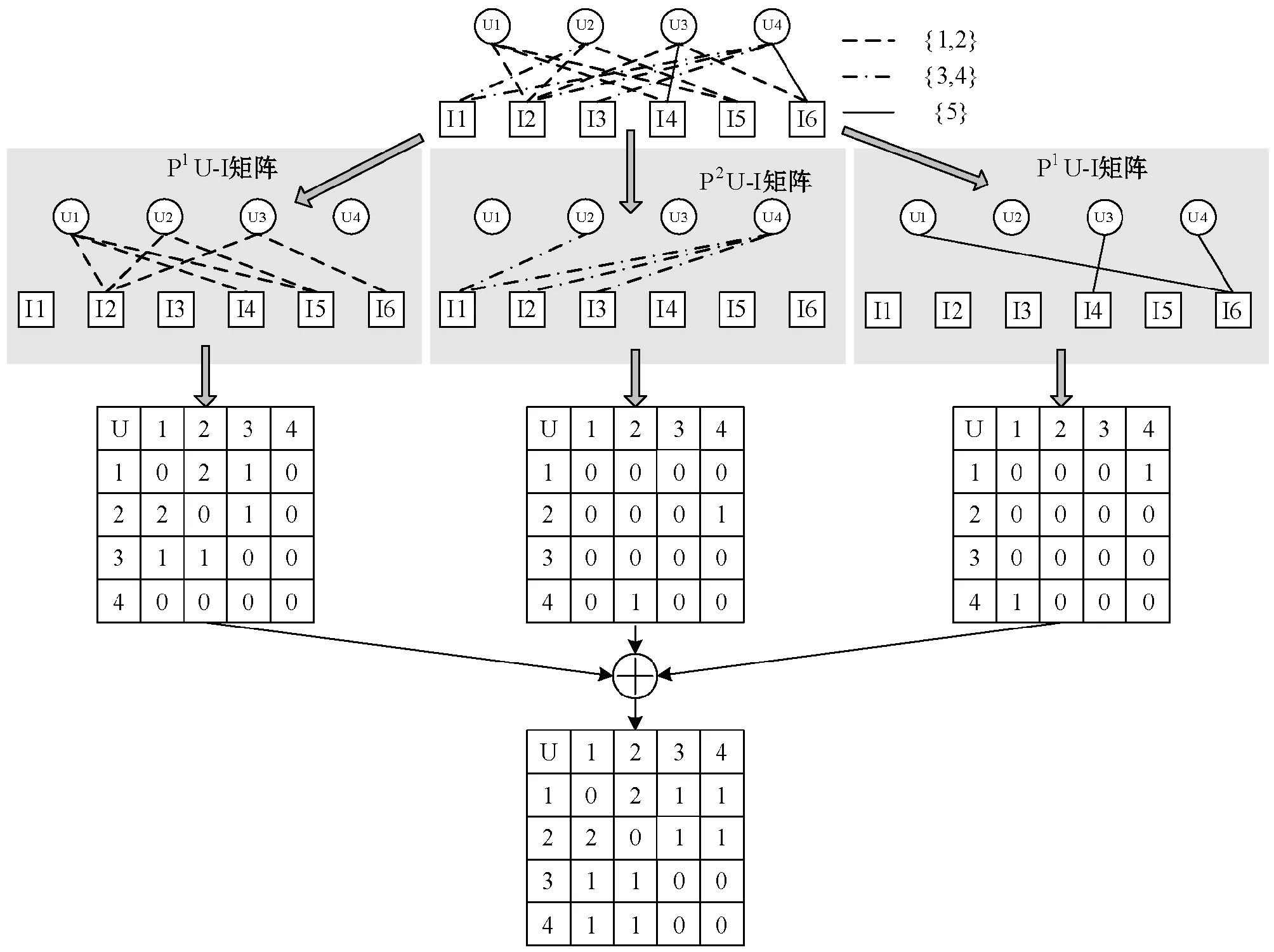
圖4 U-I網絡的子網劃分和Meta-Path圖
Meta-Path路徑的計算方法為:
(2)
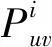
3 基于重引力搜索的鏈接預測
3.1 問題定義
連接預測的主要思想是通過引入社區信息來提高局部鏈接預測的準確率,從強社區提取優化的子圖來實現局部鏈接的預測,其中通過重引力搜索對子圖做優化處理,從而縮小搜索空間。

3.2 重引力搜索算法(GSA)
GSA的每個agent具有4個屬性:位置、慣性質量、主動引力質量和被動引力質量,agent的位置即為問題的解集。設兩個agent的質量分別為M1和M2,兩者的距離為R,那么其中一個agent受到的引力為F=G((M1M2)/R2),G為引力常量。GSA的搜索過程如下:
Step1初始化。根據下式隨機初始化N個agent的位置:
(3)
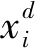
Step2評價適應度。在每次迭代中分別通過下式計算最優適應度和最差適應度:
fmax(t)=maxfitj(t)
(4)
fmin(t)=minfitj(t)
(5)
式中:fitj(t)為第j個agent在第t次迭代的適應度值。
Step3計算引力常量。第t次迭代G的計算方法為:
(6)
式中:G0與α均為初始化參數,T為迭代的總次數。
Step4計算agent的引力。第t次迭代agent慣性質量和引力的計算方法為:
Mαi=Mpi=Mii=Mi
(7)
(8)
(9)
式中:Mpi和Mαi分別為被動引力質量和主動引力質量,Mii為第i個agent的慣性質量,fiti為第i個agent的適應度函數。
Step5計算agent的加速度。第t次迭代agent加速度的計算方法為:
(10)
第i個agent總引力的計算方法為:
(11)
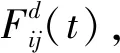
(12)
式中:Kbest為前K個agent的最優適應度值,最大質量隨著迭代線性降低,最終僅有一個agent對其他agent產生引力。G(t)為當前迭代的重引力常量,ε為常量,Rij(t)為agenti和j之間的RSI相似性。
Step6更新agent的速度和位置。搜索過程的速度和位置更新方法分別為:
(13)
(14)
Step7重復Step 2-Step 6。如果未達到結束條件,那么重復Step 2-Step 6。將最后一次迭代的最優適應度作全局適應度。
3.3 基于GSA預測網絡鏈接
基于重引力的鏈接預測參數、適應度函數和其他的參數建模為:
(1) 初始化網絡參數。隨機初始化agent的位置和網絡參數,N個agent的位置初始化為:
Xi=Init+(Xup-Init)×rand(0,1)+
(Xlo-Init)×rand(0,1)
(15)
式中:Init表示第i個agent的位置,Xup為最大的平均分簇系數,Xlo為最小的平均分簇系數(Average Clustering Coefficient,ACC)。
(2) 適應度函數。為將ACC參數最大化,通過以下的適應度函數評價質量:
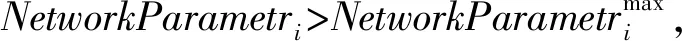
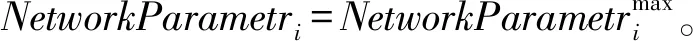
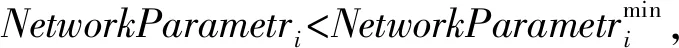
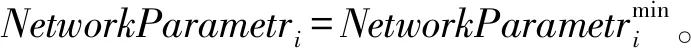
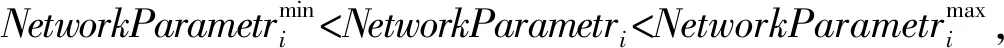
在求解最優解的問題中,在每次迭代t中通過式(4)和式(5)分別求解最優適應度和最差適應度,fitj(t)為第t次迭代、第j個agent的適應度值。
(3) 重引力搜索的常量值。重引力搜索的agent常量設為:G0=100,α=10,T=100。
(4) 重引力質量和慣性質量。GSA的每次迭代中通過式(7)-式(9)計算重引力的質量和慣性質量。
(5) 總體引力。Agent的引力和總引力計算方法分別如下:
(16)
(17)
式中:ε=0.1。
(6) 加速度和速度。網絡參數的加速度和速度分別如下:
(18)
(19)
3.4 GSA搜索速度
GSA傾向于開發搜索空間的中心位置,該性質嚴重影響了GSA的多樣性,而大多情況下,Xg附近的搜索空間才應該被局部地深入開發。為提高GSA的收斂速度和求解質量,對質量分配機制進行了改進。為每個agent的質量分配一個范圍[LM,UM],約束GSA的局部搜索空間。定義時間不變線性遞增函數如下,建立適應度和質量的映射:R→R,f(Xi)→g(f(Xi)),?Xj∈X。
Mi=g(f(Xi))=
(20)
式中:j∈{1,2,…,S}。
3.5 基于GSA的鏈接預測算法
采用特征相似性降低特征之間的冗余度,最大化簇內特征的相似性,最小化簇間特征的相似性。從每個社區中選擇一個特征組成降維的子集,然后采用GSA技術優化子集之間的冗余度。特征選擇由兩個步驟組成:(1) 原特征集分為若干的社區;(2) 從每個社區選擇一個代表性特征。
觀察發現,預測外部鏈接對于鏈接預測結果的準確性沒有明顯提高。圖5所示是鏈接預測算法的主要模塊,圖6所示是鏈接預測算法的流程框圖。
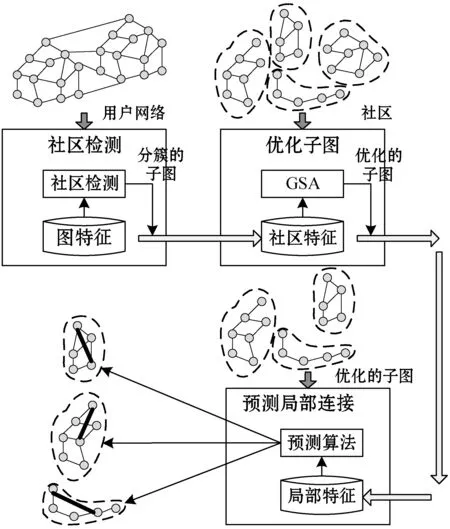
圖5 鏈接預測算法的主要模塊
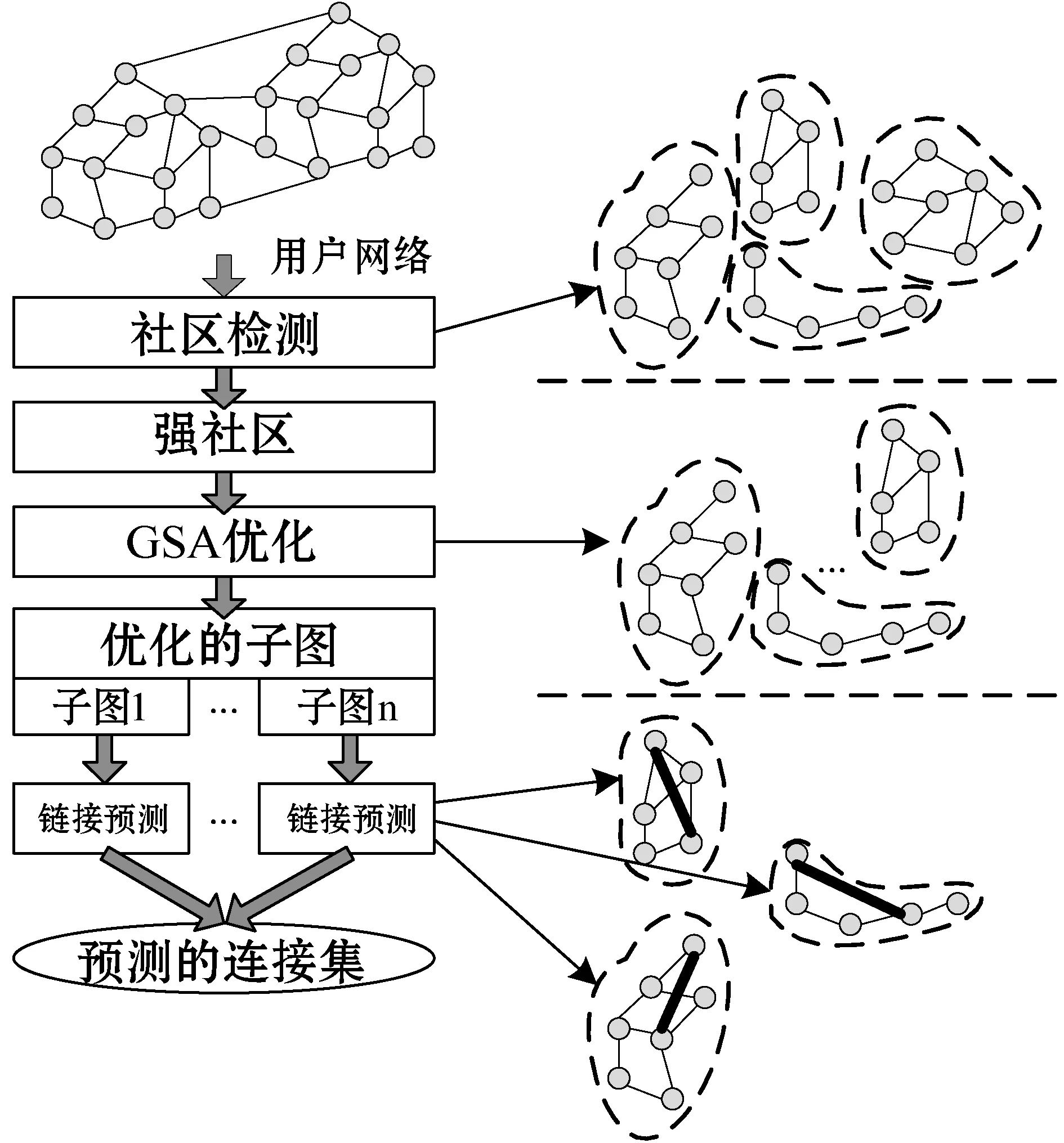
圖6 鏈接預測算法的流程框圖
算法1是本文基于GSA的鏈接預測算法。輸入變量為社交網絡的圖模型,輸出結果為預測的鏈接集。算法分為4個階段:(1) 社區檢測階段:將復雜網絡劃分社區,將網絡劃分為子圖能夠有效地提高算法的效率,算法的第1行通過社區檢測將社區分簇。(2) 子圖優化階段:算法的第5行通過GSA對每個社區Cis的子圖ci進行優化處理。(3) 鏈接預測階段:算法的第3行預測了社區的外部鏈接,第7行預測社區的內部鏈接。(4) 鏈接分類階段:將預測的所有鏈接分類,輸出最終的預測鏈接集。
算法1基于GSA的鏈接預測算法
輸出:L={l1,l2,…,lm}
/*社區檢測C=c1,…,ck*/
/*應用鏈接預測和ELP預測內部鏈接和外部鏈接*/
2.intlink=AAL(C);
3.extlink=ELP(ci,cj);
/*預測每個社區的外部鏈接*/
4.F=CalForce(ci,cj);
5.OptGraphList=GSA(C);
6. foreachjfrom 1 to l do
7.IntLinks=AAL(cj);
/*預測每個社區的內部鏈接*/
8. endfor
9. foreachcicjinOptGraphListdo
10.Fij=CalForce(ci,cj);
11.Flist←Fij;
12. endfor
13. foreachcicjinOptGraphListdo
14. ifFij>γ
15.PreLinks←ELP(ci,cj);
16.Mark(PreLinks,Fij);
/*為鏈接標記引力大小*/
17. endif
18. endfor
4 評分信息傳播方案
4.1 方案設計
評分信息是推薦系統的一個重要部分,采用基于傳染病模型的網絡傳播策略,根據已有的模式探索隱藏的模式。定義一個傳播閾值θd,如果N(u,i)≥θd,用戶u則接受項目i,N(u,i)為用戶u的鄰居數量。根據增強的相似性矩陣將評分信息在網絡中傳播,相似性矩陣建模為一個網絡,節點為用戶,評分信息為節點的特征。定義一個u的鄰居用戶集PN,PN中的用戶與u的相似性得分為正。
圖7所示為評分信息傳播的效果圖,圖中共有7個用戶,評分信息作為用戶的特征,黑色用戶u為目標用戶,u評分的項目為{0,7},灰色用戶為u的PN集,假設θd=0.1,u2、u3、u4的評分項目均包含了31和41,所以項目31和項目41的評分次數較多,因此用戶u接受PN對31和41兩個項目的評分。
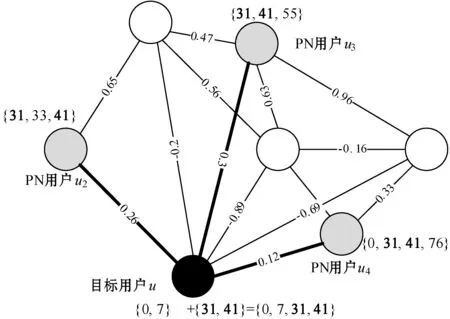
圖7 評分信息傳播的效果圖
θd決定了目標用戶是否接受PN集傳播的評分信息,定義為u接受PN評分的比例,將閾值設為θd=0.1。基于權重將評分信息融合,用戶u對于目標項i評分的融合方法為:
(21)
式中:sim(u,v)為用戶u和v的相似性,相似性越高,對于評分結果的貢獻度越大。ru,i為用戶u對于項i的評分。C(u,i)表示對項i評分的PN用戶集。
4.2 評分信息傳播算法
算法2為評分信息傳播算法。算法的輸入是用戶評分R,輸出是增強的評分信息Re與相似性矩陣Se。算法的第5、第6行計算用戶之間三個加權的Meta Path,第9行計算相似性矩陣,第14行計算新的評分信息Re。
算法2評分信息傳播算法
輸入:評分信息:R
輸出:增強的評分信息Re,相似性矩陣Se
1.NI←R中的項目數量;
2.NU←R中的用戶數量;
3. 將R分為子Meta-Path{P1,P2,P3};
4. 建立U-I矩陣;
5. 根據式(1)計算Sim;
/*根據式(1)計算相似性*/
6. 將Sim歸一化為[-1,1]區間;
7. foreachu,vfrom 1 toNUdo
8. ifSim(u,v)=0 &&u≠vdo
/*根據已有連接建立網絡*/
9. 根據式(2)計算Meta-Path路徑;
10. endif
11. endfor
12. 應用算法1預測隱藏的鏈接;
12.Se=Smain+Se;
13. foreachufrom 1 toNUdo
/*在網絡中傳播評分信息*/
14. 根據式(21)計算Re(u,Item(u));
15.Re=R+Re;
16. endfor
5 仿真實驗與結果分析
5.1 實驗環境與實驗方案
(1) 實驗環境。實驗環境為:Intel(R) Core(TM) i5-5200 CPU, 2.2 GHz主頻,8 GB內存容量,操作系統為Windows 10操作系統,編程環境為MATLAB R2016a。
(2) 實驗數據集。實驗采用三個經典的公開數據集,分別為FilmTrust、Epinion和Flixster[13]。FilmTrust數據集是電影評分的數據集,Epinions是產品評論數據集,Flixster是Flixster.com網站用戶對于電影評價和興趣的數據集。表1是3個實驗數據集的簡介。
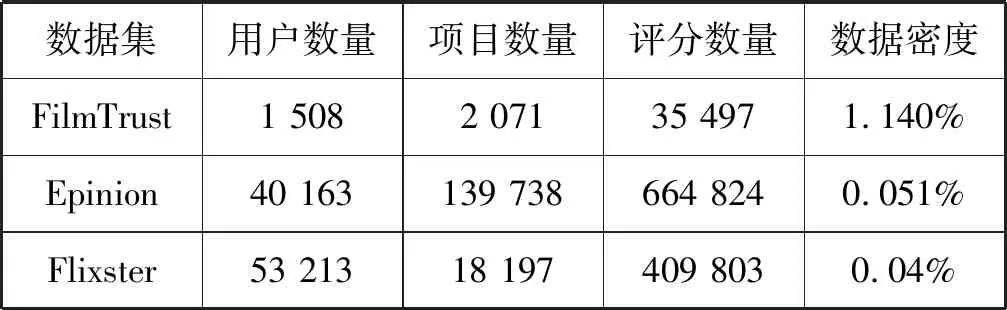
表1 數據集的主要屬性
(3) 性能評價指標。采用5折交叉驗證分別進行訓練和測試:每個數據集隨機分為5個子集,4個子集組成訓練集,另1個子集為測試集,輪流完成5次驗證,將測試數據集的結果統計為最終的平均性能。平均絕對誤差(Mean Absolute Error,MAE)和均方根誤差(Root Mean Square Error,RMSE)是評價推薦準確率的常用指標,MAE對異常點的敏感度較低,RMSE對異常點的敏感度則較高。MAE和RMSE的計算方法為:
(22)
(23)
式中:Ω為測試集,|Ω|為測試集的大小,用戶u對項目i的實際評分和預測評分分別記為ru,i和pu,i。
此外,評價了系統的評分覆蓋率RC(Rating Coverage),覆蓋率度量了系統對長尾項目的挖掘能力,定義為系統推薦的項目占總集合的比例。
(4) 實驗方法。首先使用基本協同過濾推薦算法(Collaborative Filtering,CF)觀察本方法對于推薦系統的增強效果。然后選擇其他近期的協同過濾推薦算法進行對比實驗,進一步評價本算法的性能,分別為TrustSVD[14]、TrustMF[15]和BKCF[16]三個算法。TrustSVD是一種基于信任的矩陣分解方案,該方案為推薦模型引入了多種信息源,并且引用了社交關系的信息,與本算法具有相似之處。TrustMF[15]采用了信任傳播機制,利用矩陣分解方法將用戶映射至低維的特征空間,探索用戶觀點之間的影響,該方案是一種新穎且性能較好的推薦系統。BKCF設計了一種新的布爾核,并將布爾核嵌入協同過濾推薦系統中,該方案提高了推薦系統的語義感知能力,具有較好的推薦效果。
5.2 鏈接預測與評分傳播實驗
首先,測試了基于重引力搜索算法的鏈接預測效果。表2所示是通過鏈接預測增加的鏈接結果,表中顯示本算法有效地增加了數據量,對于數據密度較高的Filmtrust數據集,預測率達到了9.5%,對于密度較低的數據集,也實現了有效的補充。
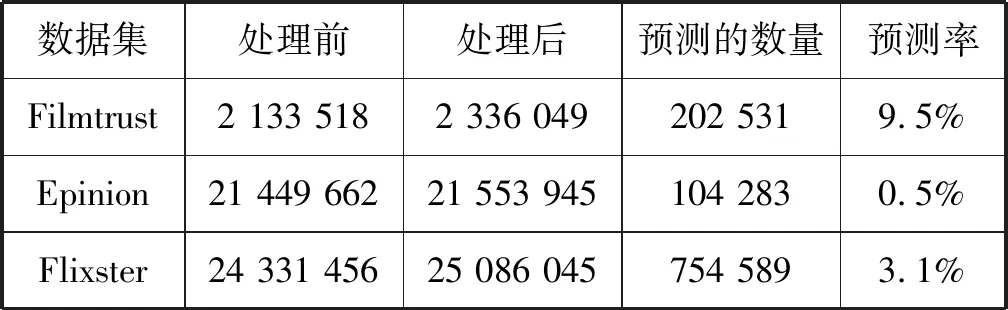
表2 鏈接預測處理的結果
鏈接預測的目標是緩解網絡的稀疏性,為后續的評分傳播處理提供支持,因此對評分傳播處理也進行了實驗和評價。對FilmTrust、Epinion和Flixster做預處理,刪除一些不完整的數據。然后測試評分傳播處理的效果,表3所示是評分傳播處理的結果,表中顯示評分傳播處理對于密度低的Flixster數據集增加了4%的信息。
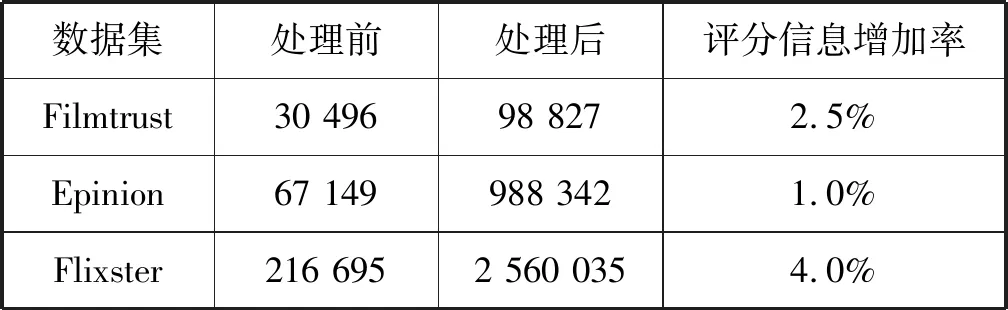
表3 評分傳播處理的結果
5.3 與基本CF推薦系統的比較
將本文算法與基本的協同過濾推薦算法集成,評估本文算法對推薦系統的改進效果。圖8所示為基本CF算法和集成CF算法對于三個數據集的RMSE結果,基本CF算法隨著領域閾值的增加緩慢提高,而集成CF算法的增長較快,具有明顯的優勢。
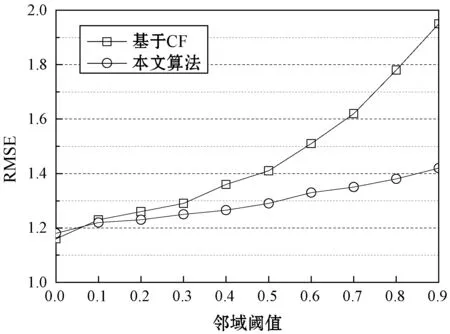
(a) Filmtrust數據集
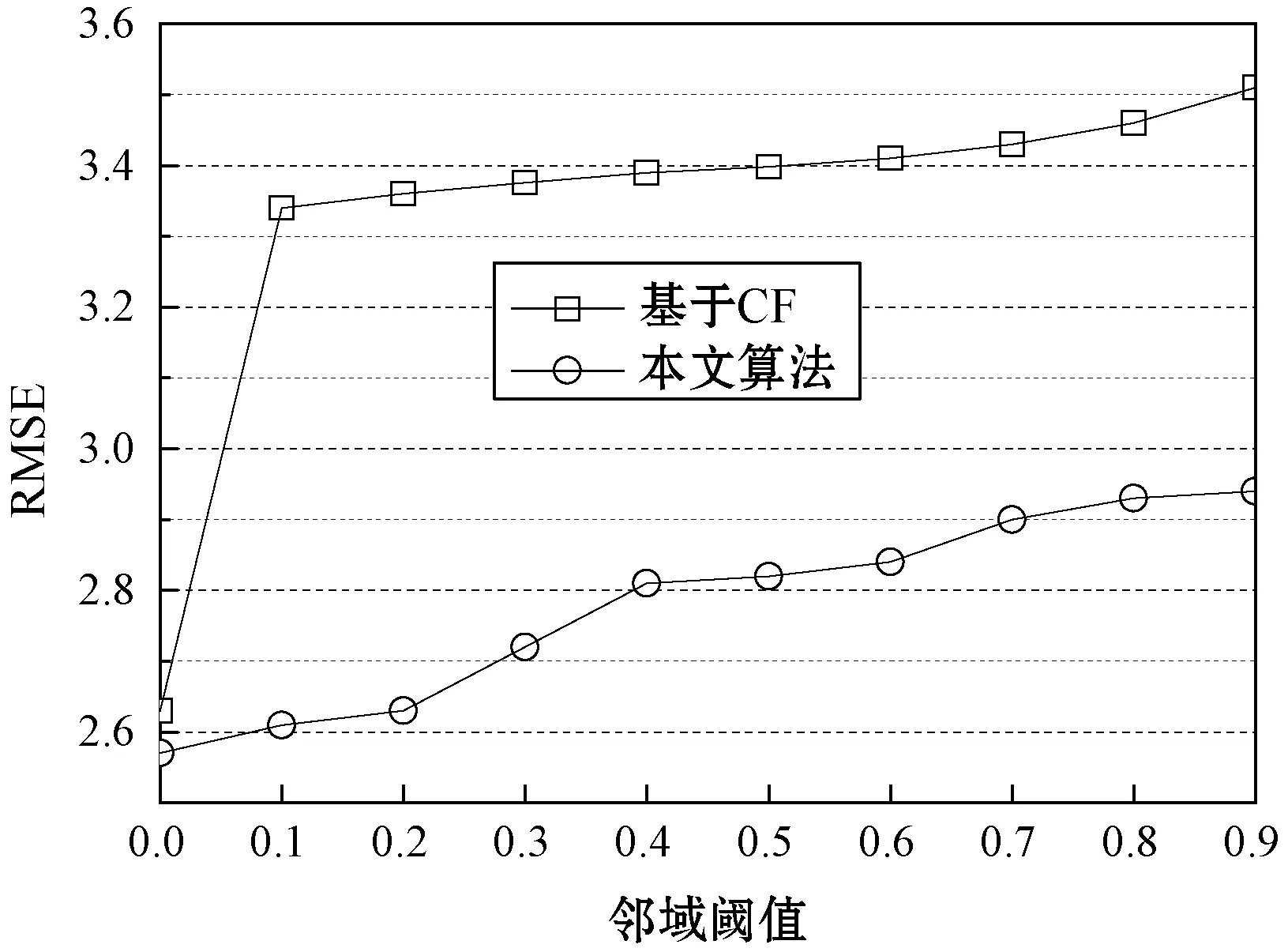
(b) Epinion數據集

(c) Flixster數據集圖8 RMSE的實驗結果
圖9所示為基本CF算法和集成CF算法對于三個數據集的MAE結果,基本CF算法隨著領域閾值的增加緩慢提高,而集成CF算法的增長較快,具有明顯的優勢。
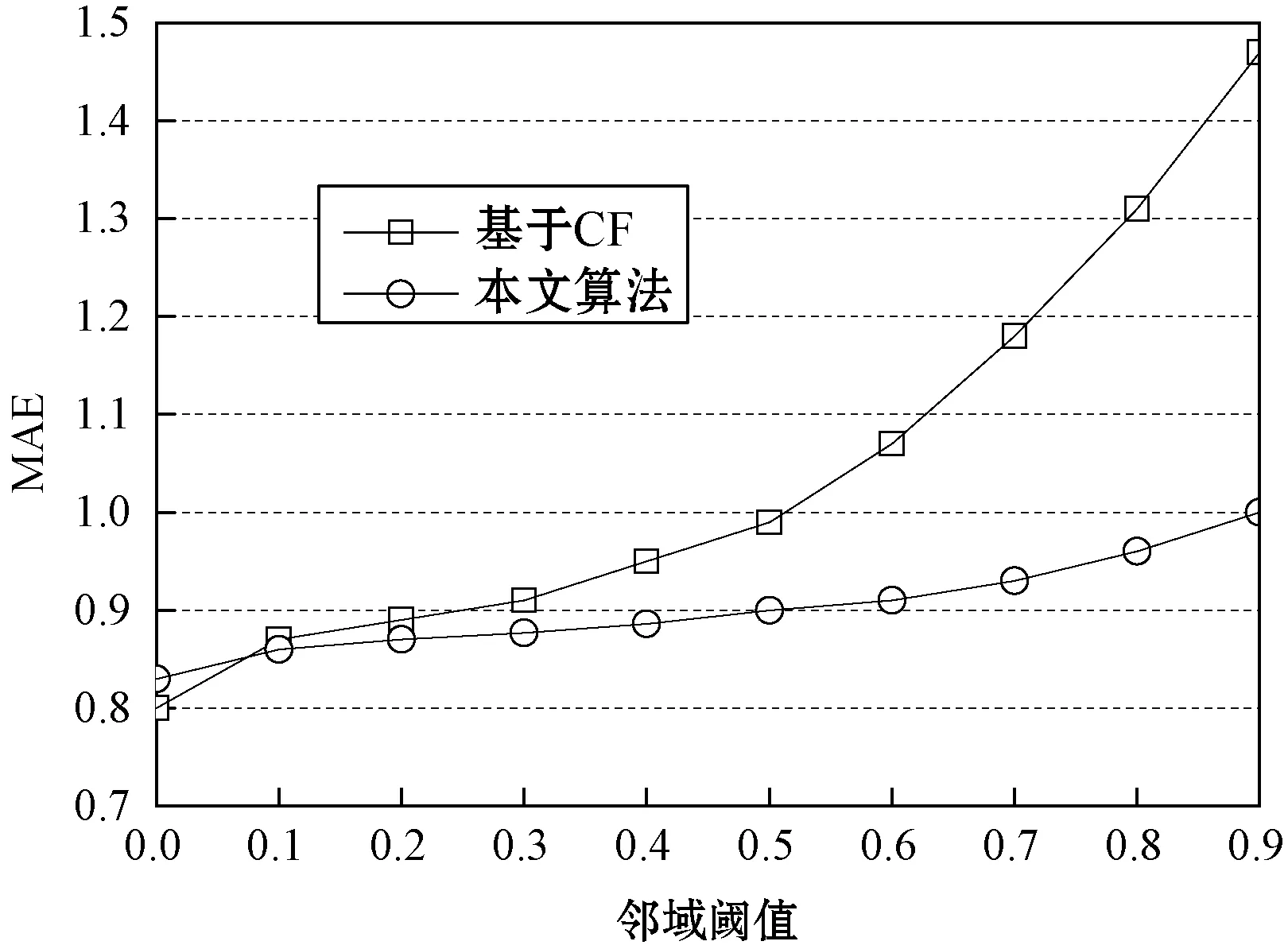
(a) Filmtrust數據集
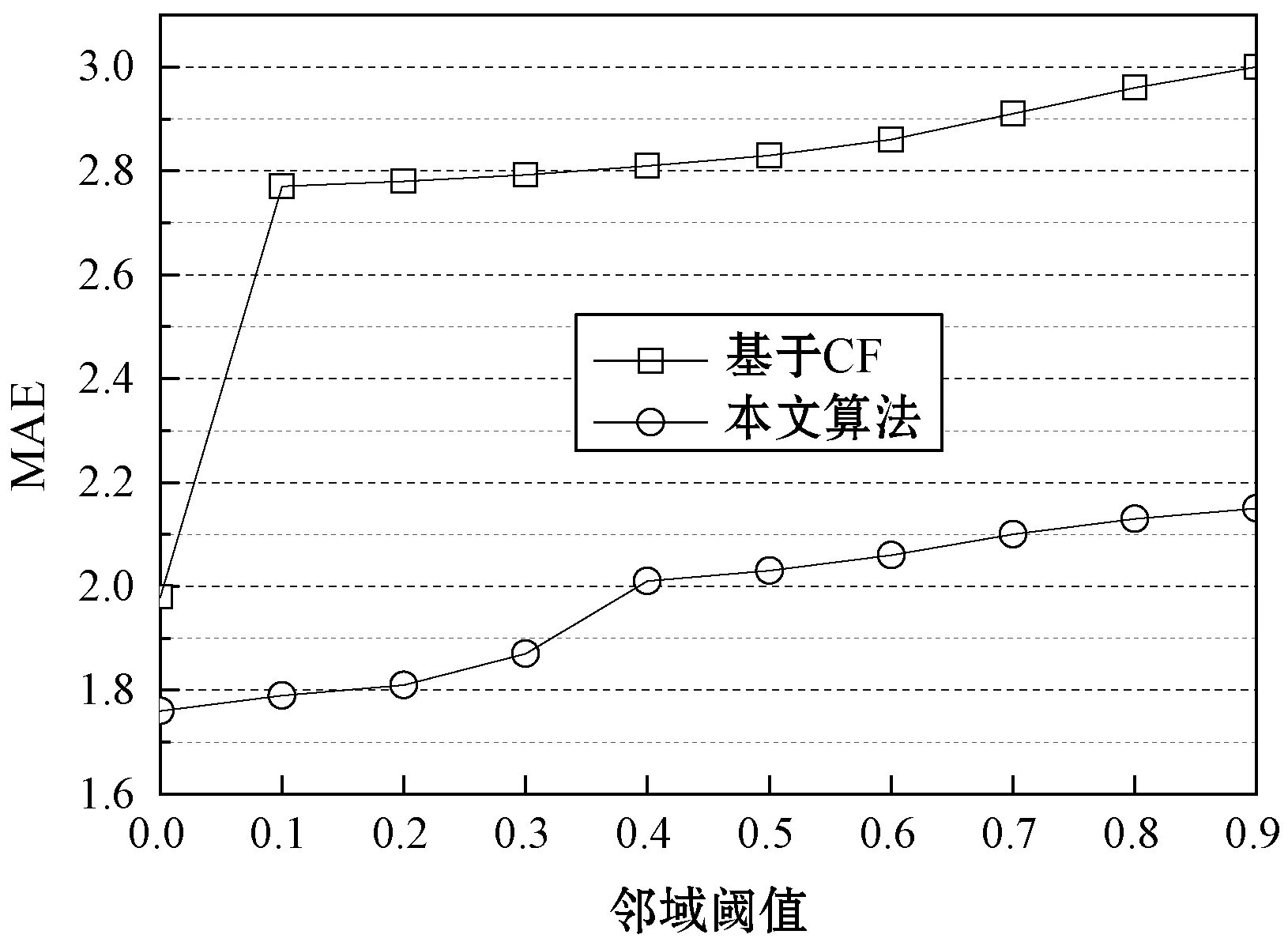
(b) Epinion數據集
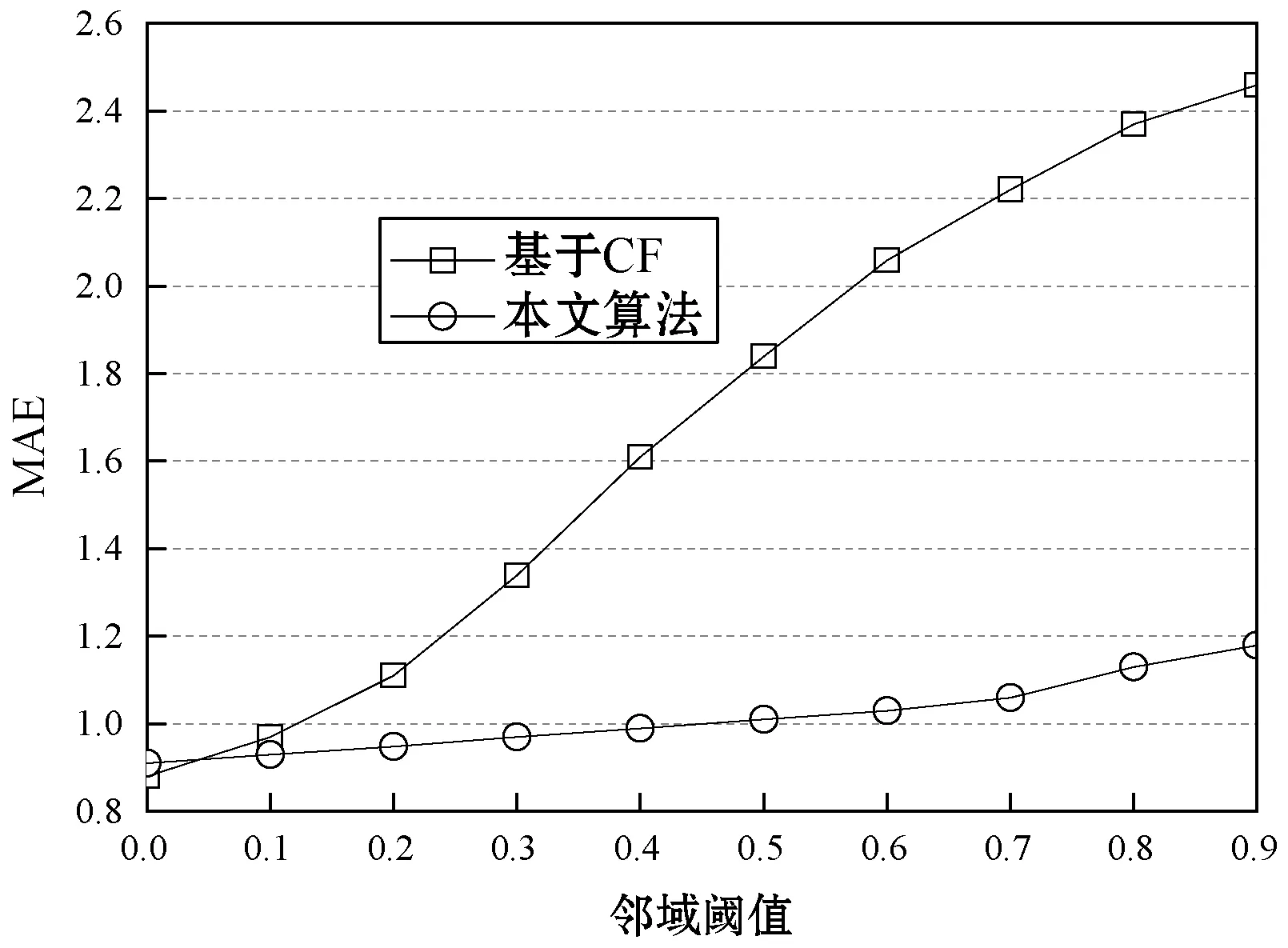
(c) Flixster數據集圖9 MAE的實驗結果
圖10所示為基本CF算法和集成CF算法對于三個數據集的覆蓋率結果,基本CF算法隨著領域閾值的增加迅速降低,而集成CF算法隨著領域閾值的提高表現得較為穩定,始終高于0.85。
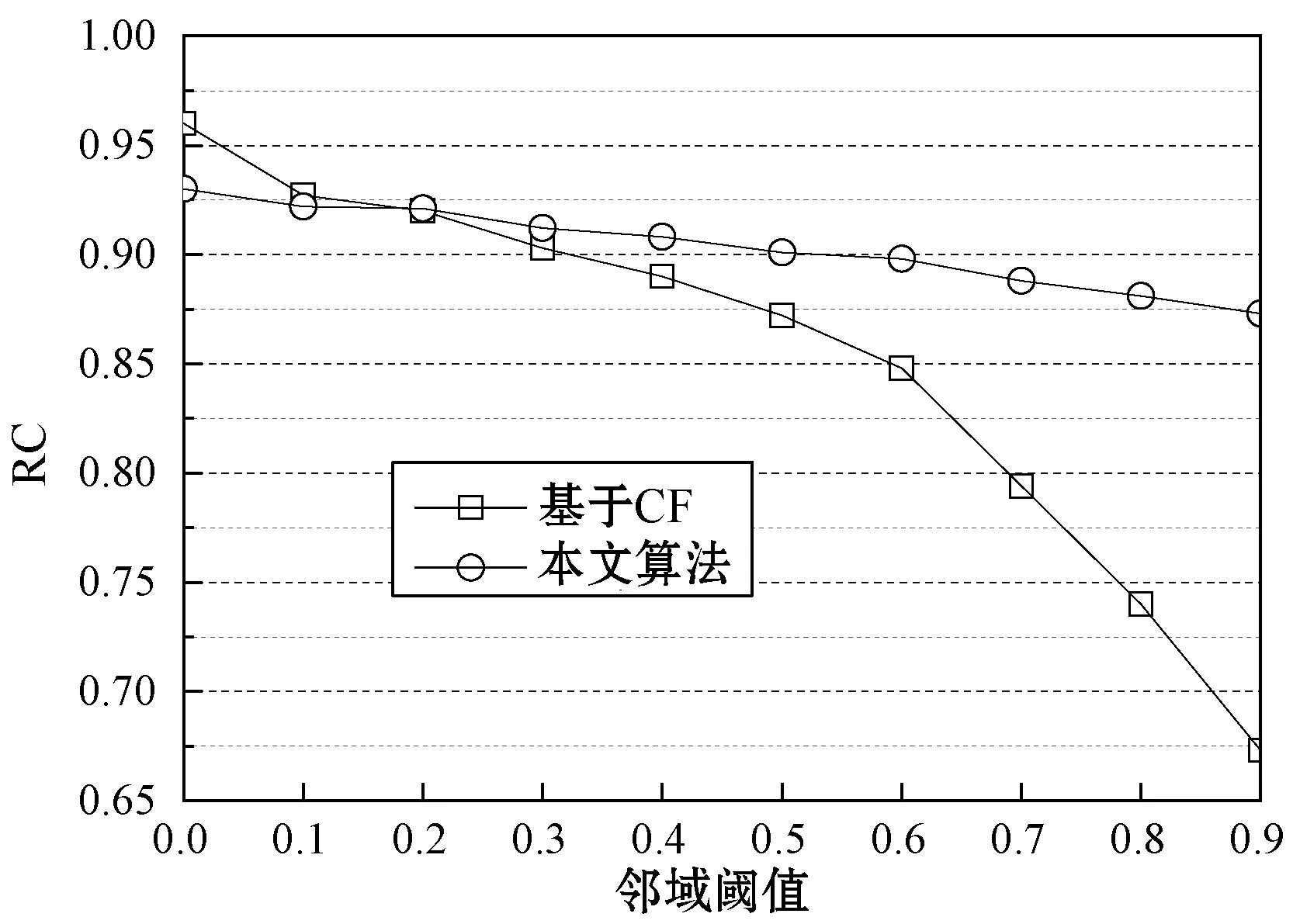
(a) Filmtrust數據集
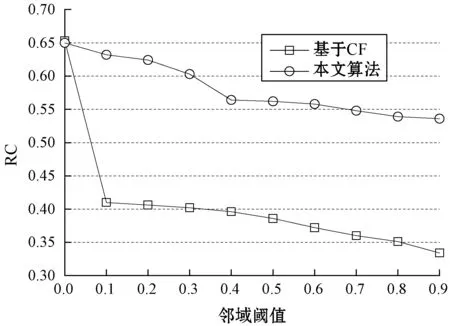
(b) Epinion數據集
5.4 與其他推薦系統的比較
將GSLPRP算法與多層協同過濾模型(Multifaceted Collaborative Filtering Model,MCFM)集成,組成GSLPRP_ MCFM算法。將GSLPRP_ MCFM與TrustSVD、TrustMF和BKCF三個推薦系統比較,結果如圖11所示。可以看出,GSLPRP_ MCFM算法的RMSE和MAE結果始終低于其他三個算法,并且具有明顯的優勢。與此同時,GSLPRP_ MCFM算法的覆蓋率也略高于其他三個算法。本文算法設計了基于重引力搜索的連接預測機制和評分信息傳播機制,有效地補充了數據集的信息,緩解了稀疏性問題。
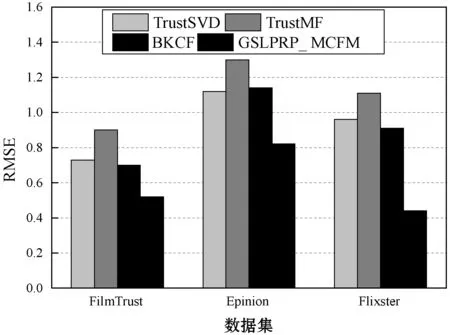
(a) RMSE結果
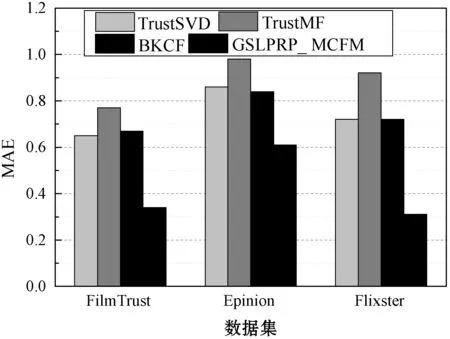
(b) MAE結果
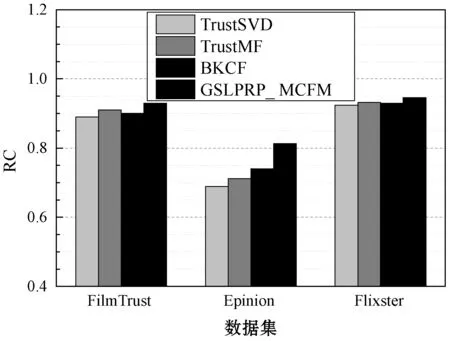
(c) RC結果圖11 4個推薦系統的性能比較
比較GSLPRP_ MCFM與TrustSVD、TrustMF和BKCF三個推薦系統的處理時間,結果如圖12所示。可以看出,GSLPRP_ MCFM算法的RMSE和MAE結果明顯低于其他三個算法,隨著數據量的增加,GSLPRP_ MCFM的處理時間依然保持較低。GSLPRP_ MCFM通過社區檢測算法將原網絡圖劃分成小規模的子圖,與MCFM的多層協同過濾模型集成,通過并行處理對每個子圖進行處理,因此隨著數據規模的增加,算法的總體時間并未呈現劇烈的增長趨勢。
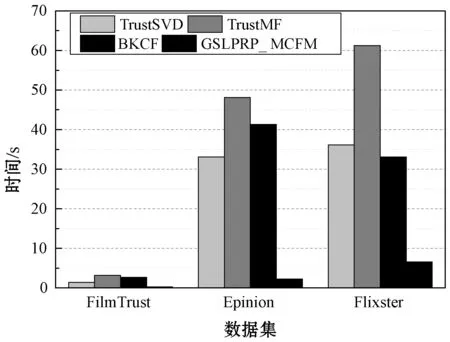
圖12 4個推薦系統的處理時間
6 結 語
為支持并行計算的可擴展性,將大規模復雜網絡劃分社區結構,再對小規模的子圖做并行處理。為解決稀疏性問題和冷啟動問題,設計了基于重引力搜索的鏈接預測機制和評分信息傳播機制,以較短的學習時間獲得充足的隱藏評分信息。實驗結果表明,本文算法對基本協同過濾推薦系統實現了明顯的增強效果,并且優于其他近期的推薦系統。
本文算法主要是一種推薦系統的增強策略,目前主要研究了與協同過濾推薦系統的集成效果,未來將關注與其他類型統計系統的集成方案和效果。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
