基于代碼克隆檢測的代碼來源分析方法
2020-03-11 12:50:52吳毅堅趙文耘
計算機應用與軟件 2020年2期
關鍵詞:檢測
李 鎖 吳毅堅 趙文耘
(復旦大學軟件學院 上海 201203) (上海市數據科學重點實驗室 上海 201203)
0 引 言
隨著互聯網的迅速發展以及開源代碼生態系統的日益繁榮,網絡上各種開源項目越來越多樣化并且獲取也更加便利。許多軟件企業內部也通過軟件資源庫、外部開源軟件、軟件產品線及開發框架等方式建立了多種多樣的軟件復用開發方法,同時開發人員自身也會通過多種方式大量復用已有的軟件資源。在這些軟件復用方法和資源的支持下,軟件系統和軟件產品大量引入了開源軟件、網絡資源、商業軟件等外部代碼成分。近年來,如何自動化查找分析軟件系統中的外部來源代碼,已成為當前非常重要的研究方向。
代碼成分隨著軟件項目之間的派生以及項目自身的持續演化而不斷發展變化,并與自有代碼成分不斷融合。由此造成的問題是,大量關鍵性軟件系統和產品中的代碼來源成分復雜,其中許多源自外部的代碼成分都存在安全漏洞、潛在缺陷或知識產權問題[1]。有些外部依賴還會導致軟件研制和開發方無法完全掌握軟件的持續演進方向[2]。外部引入的代碼也使項目代碼過于冗余,增加了系統的復雜度和軟件維護成本,降低了代碼的可理解性[3]。
本文提出一種基于代碼克隆檢測的代碼來源分析方法,將待分析代碼以方法為單位建模為Hash詞袋,之后利用并行化Hash詞袋模型算法找出目標系統代碼在代碼庫中不同項目間的來源關系,最后生成代碼來源報告。其目標在于,為軟件從業者和普通用戶提供一種代碼來源分析方法。而用戶所輸入的代碼數據可能是多種多樣的,存在著多種不同的情況。因此,代碼來源分析工具需要具備處理不同情況下用戶所輸入的代碼,并對不同情況的代碼提供統一的處理流程,同時提供統一的交互式圖形化操作工具,使得用戶無需關心工具的數據處理方式和流程,只需要進行目標系統代碼的輸入,執行簡單的操作步驟便能夠得到直觀的結果。
1 相關工作
代碼來源分析是指,針對特定目標軟件系統,分析該系統中各部分組件與其他項目之間的關系,其目的是找出該系統中組件的可能外部來源,這些系統組件包括源代碼文件、依賴庫、類、方法、代碼塊等。代碼來源分析旨在回答以下問題[4]:目標系統中某一特定組成部分可能來源于何處?
當前的代碼來源分析主要基于代碼克隆的研究。例如,Steidl等[5]針對開源系統中高達38.9%的文件具有不完整的歷史,提出了一種基于提交(commit)的增量方法,以基于克隆信息和名稱相似性重建代碼歷史。代碼克隆,即相同或相似的代碼片段[6],是軟件開發中的常見現象。開發人員經常利用代碼克隆簡化程序的編寫,在提升程序開發速度的同時也帶來了一些維護隱患。多年來,已經有大量研究專注于如何高效檢測程序中的不同種類的代碼克隆,從而對克隆代碼有了更加清晰的認識。目前對克隆代碼最普遍的分類是Bellon等[7]提出的,他們把克隆分為了以下四類:第一類是完全相同的代碼片段;第二類是只有變量名、類型或其他名稱、類型、格式等不同的代碼片段;第三類是在第二類的基礎上,增加、刪除或修改過少量語句的代碼片段;第四類是邏輯功能完全相同而實現方式不同的代碼片段。
軟件代碼克隆檢測在軟件維護、軟件結構優化等方面具有重要價值和意義。代碼克隆有多種檢測的方法,基于的不同的對象、不同的語言都有不同檢測的方法。克隆代碼檢測使用的技術主要包括:文本檢測法(text-based)[8]、符號檢測法(token-based)[9]、抽象語法樹檢測法(AST-based)[10]、程序依賴圖檢測法(PDG-based)[11]、度量檢測法(metric-based)[12]和深度學習檢測法(Deep Learning-Based)[13]。
基于代碼來源分析結果, 研究人員又提出了許多應用,其中主要包括軟件譜系和演化分析。例如,張久杰等[14]基于軟件多版本演化,根據克隆代碼主題信息構建版本間克隆代碼的映射關系,為演化過程中的克隆代碼添加演化模式,分析演化特征并構建克隆譜系。Nguyen等[15]針對軟件復用庫中構件演化帶來的客戶代碼同步演化問題,提出了一種基于圖的API使用代碼適應性演化方法。另外一些研究工作進一步提出了對演化中的克隆代碼進行科學、有效的管理[16],以及缺陷檢測等[17]。
從現有技術基礎來看,相關的研究工作主要集中在克隆檢測和克隆代碼的管理上,即使開展了對軟件代碼來源和演化歷史的研究分析工作,其應用目標也主要是對項目內不同版本之間代碼的演化軌跡進行描述。然而,如何全面、充分地對海量軟件代碼資源和其他相關資源,如代碼項目信息、版本信息等,全方位地建立目標系統的代碼來源關系,是本文關注的核心問題。
2 代碼來源分析方法
代碼來源分析對于軟件開發人員和軟件維護人員具有重要意義。軟件產品上線與更新的速度加快,以及互聯網的網絡資源的高速發展,為軟件開發與維護人員提供了大量可利用資源。因此,現在軟件開發人員在開發軟件系統時往往會參考一些開源項目的代碼,而分析這些代碼的來源對理解和維護軟件系統的代碼具有重要意義。
在本項目中代碼來源是指給定代碼塊,基于代碼克隆檢測,找出該代碼塊在代碼資源庫中的可能來源。當有多個克隆代碼實例時,代碼來源根據項目和時間進行串接,會形成“來源鏈”。來源鏈是指根據一定來源相似性閾值,代碼庫中與該代碼塊具有克隆關系的代碼實例。因為分析出來的代碼來源有不同的置信度(來自克隆代碼的相似度),因此來源報告中會給出多個可能的來源。
代碼來源分析過程如圖1所示,主要分為:(1) 解析源代碼文件,創建代碼塊詞袋;(2) 詞袋Hash化;(3) 創建代碼塊索引Hash表;(4)并行化克隆檢測,得到目標系統代碼來源對;(5)生成目標系統代碼來源鏈,得到來源報告。
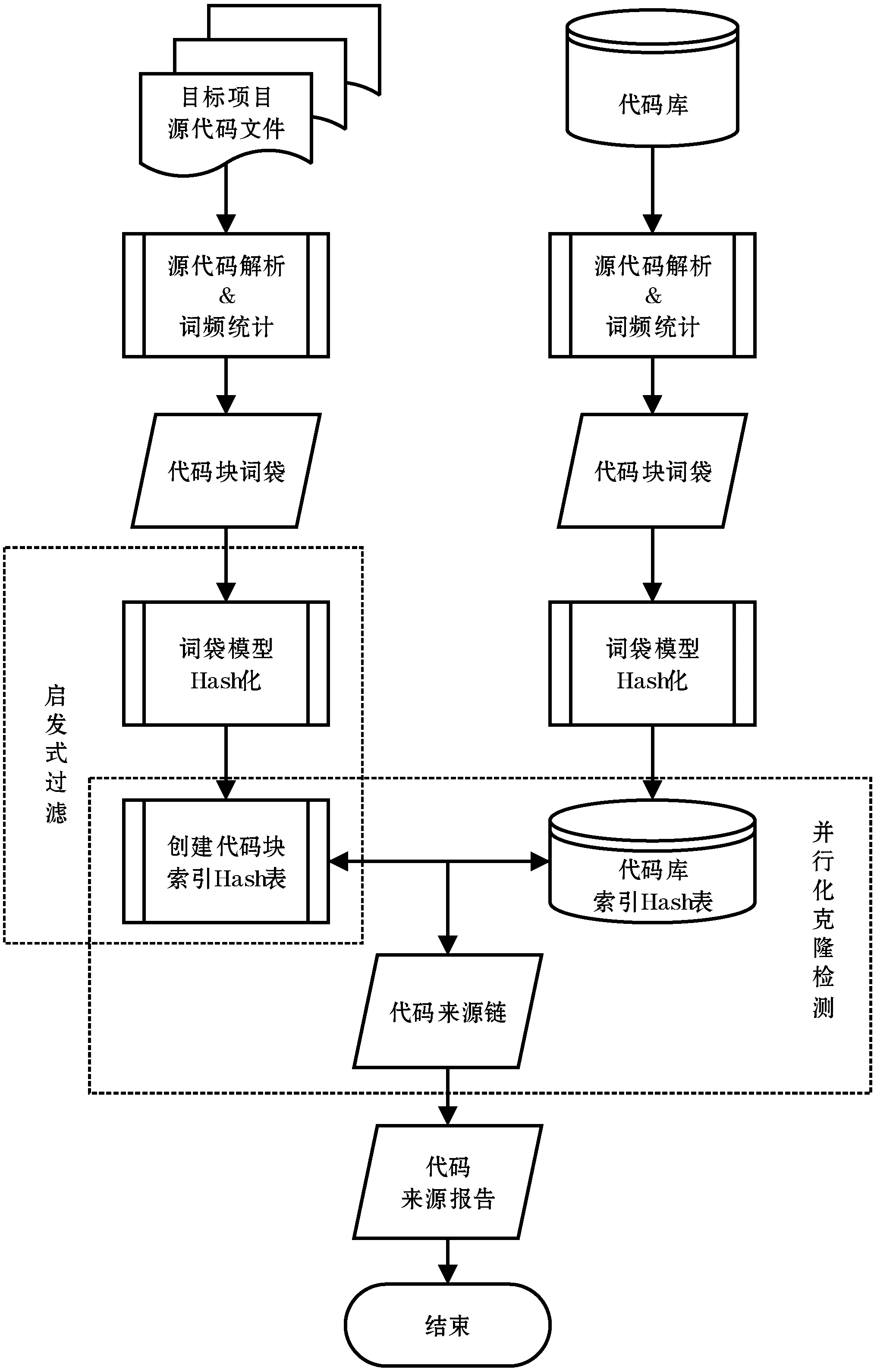
圖1 代碼來源分析過程
2.1 代碼塊的詞袋化方法
任意一個軟件項目P,可表示為一系列的代碼塊:{B1,B2,…,Bn}。代碼塊是任意一段具有特定起止邊界的代碼,有不同的粒度。常見的粒度包括文件、類、方法以及語言相關的多種亞方法粒度。一個代碼塊B由有限多個詞構成。根據自然語言處理的機制,這樣的一個代碼塊相當于一個文本片段,可進一步表示成詞袋(bag-of-words)。詞袋模型最早出現在自然語言處理(Natural Language Processing,NLP)和信息檢索(Information Retrieval,IR)領域。該模型忽略文本的語法和語序等要素,將其僅僅看作是若干個詞匯的集合,文檔中每個單詞的出現都是獨立的。詞袋模型使用一組無序的單詞(words)來表達一段文字或一個文檔。同時,由于代碼的特殊性,可將代碼中的關鍵詞、標識符、運算符等符號以詞為單位進行以對代碼進行Token化(Tokenization),表示為一串Token。因此,經過Token化后的代碼塊即表示為一個Token袋(bag-of-tokens):B{T1,T2,…,Tk},其中Ti是代碼塊B中的Token。由于Token可能出現重復,因此將Token與它在該代碼塊中的出現次數Frequency記作一個二元組(Token,Frequency),作為代碼塊的Token袋組成元素。這種(Token,Frequency)表示法大大縮減了代碼塊的表示長度,也有助于提高檢測相似代碼片段的效率。
為了定量推斷兩個代碼塊是否是克隆,使用相似性函數來度量代碼塊之間的相似度,并返回一個非負值。該值越高,表示代碼塊之間的相似性越大。最終,具有高于指定閾值的相似度值的代碼塊被識別為克隆。
給定兩個項目Px和Py,相似性函數f和一個閾值θ,目標是找到所有的代碼克隆對(或者克隆組)Px.B和Py.B,使:
f(Px.B,Py.B)≥「θ·max(|Px.B|,|Py.B|)?
(1)
盡管相似性函數有很多選擇,為了簡單方便,計算使用重疊(Overlap)相似性函數,因為它直觀地捕獲了代碼塊之間重疊的概念。重疊相似性函數計算兩個代碼塊共有的Token數,包含計算每個Token的頻數。例如給定兩個代碼塊Bx和By,重疊相似性函數OS(Bx,By)計算代碼塊Bx和By中重復Token的數量,即:
OS(Bx,By)=|Bx∩By|
(2)
具體地,如果指定等于0.8,并且max(|Px.B|,|Py.B|)為t,當Bx和By共有至少「θ·|t|?個Token重復時認為Bx和By是克隆對。注意,如果Token a在Bx中出現兩次并在By三次出現,則由于Token a而導致的Bx和By之間的匹配為2。
本項目使用詞法分析程序(例如TXL[18])對源代碼文件進行掃描遍歷,構建代碼塊詞袋。通過詞法分析程序給定語言的標記和塊語義,識別并提取出源代碼文件中的代碼塊,并為每個代碼塊分配一個整數標識,從而在后續處理中能夠唯一標識每個代碼塊。
2.2 基于Hash詞袋模型的克隆檢測算法
2.2.1創建Hash詞袋
本節將創建Hash詞袋,也就是統計解析后的代碼塊(如方法)中每個詞出現的頻率,組成
在傳統的克隆檢測算法中,所有Token都會被一一比較。但是,基于詞袋模型的克隆檢測算法將相同的Token只創建一個
2.2.2創建代碼塊索引Hash表
上一小節將代碼塊中Token和頻率索引到Hash表中,接下來將以代碼塊為單位,將代碼塊索引到代碼塊Hash表中。源代碼解析文件中包含多個代碼塊特征序列,不同的特征序列有不同或相同的Token數量,在此,將相同Token總量的序列索引到同一Hash表中。這樣,在后面克隆檢測的時候,可以利用性質1過濾掉許多無關代碼塊,大大減少候選集。
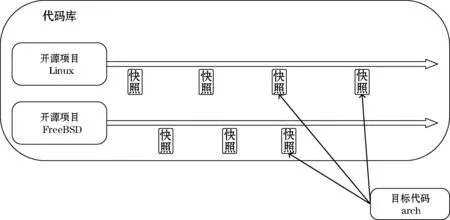
性質1:給定兩個代碼塊Bx和By分別包含Nx和Ny個Token,對于給定相似度閾值為sim(0 Nx·sim≤Ny≤Nx/sim (3) 創建代碼塊索引Hash表算法如算法1所示。該算法輸入是解析后的源代碼文件路徑,也就是Hash詞袋路徑,輸出是代碼塊索引Hash表。算法根據路徑讀取源代碼解析文件并初始化數據(2-3行),然后逐行讀取文件中的代碼塊詞袋序列,將代碼塊Token總量相同的詞袋序列索引到同一Hash單元中(4-7行)。如果Hash表中已經存在該總量的詞袋序列,則直接將詞袋序列附件到該單元中,否則新建以該詞袋序列為key的Hash單元,并將該詞袋序列添加到該單元中(8-16行)。 算法1創建代碼塊索引Hash表算法 1: function GetHashTable(parseFilePath){ 2: file = parseFilePath 3: while((line = file.readLine()) != null){ 4: blockID = getBlockID(line) 5: blockSize = getBlockSize(line) 6: tokenMap = getTokenMap(line) 7: node = Node(blockID, tokenMap) 8: if(sizeMap.containsKey(blockSize)){ 9: blockList = sizeMap.get(blockSize) 10: blockList.add(node) 11: }else{ 12: blockList = newLinkedList 13: blockList.add(node) 14: sizeMap.put(blockSize,blockList) 15: } 16: } 17: return sizeMap 18: } 2.2.3并行化代碼來源關系檢測 并行化來源關系檢測算法根據性質1,計算出目標代碼塊的Token總量的上限和下限,即upSize和lowSize,將上限和下限之外的其他代碼庫中的代碼塊直接排除,大大減少候選代碼塊的數量。算法偽代碼如算法2所示。 算法2并行化代碼來源檢測算法 1: function ConcurrentDetection(sim, lines, sizeMap) 2: doubleCore 2*Runtime.availableProcessors() 3: exec = Executors.newFixedThreadPool(doubleCore) 4: for(int i=0; i 5: increment = lines.length / doubleCore + 1 6: start = increment ? i 7: end = increment ? (i + 1) 8: if(lines.length < end){ 9: end = lines.length 10: } 11: subPairs = Calculator(lines; start; end; sim; sizeMap) 13: tasks.add(subPairs) 14: if(!exec.isShutdown()){ 15: exec.submit(task) 16: } 17: } 18: return getResult() 19: } 20: 21: function Calculator(lines, start, end, sim, sizeMap){ 22: for(int iline=0; iline 23: for(int i=lowSize; i 24: cList = sizeMap.get(i) 25: if(cList != null){ 26: for(cNode in cList){ 27: cID = cNode.blockID 28: cMap = cNode.map 29: for(wBag in mBag){ 30: mWord = getWord(wBag) 31: mFreq = getFrequency(wBag) 32: if(cMap.containsKey(mWord)){ 33: canFreq = getFrequency(mWord) 34: wordC = min(mFreq, canFreq) 35: } 36: } 37: if(wordC / mSize >= sim){ 38: subPairs = subPairs + mID + cID 39: } 40: } 41: } 42: } 43: } 44: } 該算法輸入是來源相似性閾值、目標項目詞袋路徑、代碼庫索引Hash表,輸出是目標項目代碼來源關系對。算法首先根據主機CPU核心數創建相應數量的線程,接著根據不同線程拆分任務,使來源關系檢測并行化運行(1-19行)。Calculator函數根據線程參數,執行具體的克隆檢測(21-44行)。首先獲取待檢測代碼塊詞袋(參數lines),并逐行讀取詞袋并進行克隆檢測(22-44行);然后計算出目標代碼塊的Token數量的上限和下限(22-23行),從下限Token數量開始循環遍歷代碼塊索引Hash表(23-44行)。如果已經匹配的Token總數大于等于相似性閾值,則將目標代碼ID與候選代碼ID加入到克隆對中,表示這兩個代碼塊是克隆代碼,結束匹配(37-38)。 由于我們的系統的輸入對象是多項目多版本的,不管是演化圖譜的提取還是跨項目的檢測對比時都會面臨時間線不一致的情況,故采取對項目演化歷史時間進行對齊的方案:對于大量的項目,按照不同項目release的時間先后版本對齊,接著執行基于Hash詞袋模型的克隆檢測算法找到待檢測項目中的代碼塊在代碼庫中不同項目的來源關系,利用不同項目內release版本的時間先后順序,找到待檢測項目中代碼塊在代碼庫中不同項目的來源關系,時間最早的release代碼塊作為目標系統代碼的來源,其他的代碼塊根據不同置信度作為可能來源信息。 為了檢測工具效率,我們從開源代碼庫中隨機選擇文件來構建不同大小代碼行數的輸入。使用Unix工具cloc[19]測量代碼行數,并且僅包含代碼,不包含注釋或空行。我們選擇的目標項目代碼行數為1.27 MLOC,代碼庫中選擇的代碼行數從6.75 MLOC到120 MLOC不等。環境和設置:所有實驗均在配備Intel i7-7820X CPU(8核,16線程)、SAMSUNG 970 EVO 1T SSD和SAMSUNG DDR4 2400 RECC 32GB RAM的單個服務器上運行。工具配置為檢測長于10行的代碼行數。相似性設定為0.6,相對較低的閾值可能產生更多的產出,因此執行時間應該接近上限。如果將相似度設置得更高以獲得更好的精度,則執行時間會更短。 執行時間結果如表1所示。實驗結果表明,當目標系統代碼為1.27 MLOC(百萬行),代碼庫中選取代碼行數為10 MLOC的來源關系檢測用時1小時14分鐘,相同的目標系統代碼,在代碼庫中選取代碼行數為100 MLOC的來源關系檢測用時16小時27分鐘。 表1 執行時間 由于到目前為止并沒有代碼來源的基準庫,我們參考了代碼克隆中用于評估召回率的The Mutation and Injection Framework[20]框架,這是一種綜合基準框架,用于評估工具在突變分析程序中對數千個細粒度人工代碼克隆的召回率。 以Java語言編寫的kubernetes-clint項目為例,這是一個開源的kubernetes客戶端軟件項目。我們在目標軟件項目中隨機選擇了10個不同的方法級代碼片段;然后將這10個代碼片段分別手動修改50%和70%,再將這些修改后的變異代碼片段隨機注入小規模代碼庫中;最后利用我們的工具檢測目標項目kubernetes-clint在注入變異代碼片段的代碼庫中進行來源檢測。檢測來源相似度閾值設置為70%,進行多次檢測取其平均值。其他編程語言也做類似的處理,最終檢測結果如表2所示。 表2 召回率 傳統的克隆代碼召回率主要評估某段或者某些代碼在整個數據集中的查全率問題。與傳統克隆代碼召回率相比,代碼來源的召回率主要評估目標系統中代碼片段在代碼庫中其他項目的來源關系。其中不僅包含了相似性代碼片段的檢測,還包含了該段代碼所在的代碼庫信息、項目信息、結構信息等。 通過手動驗證其輸出的隨機樣本來估計工具的準確率,這是典型的方法。我們從工具的結果中隨機選擇了實驗中檢測到的200個代碼來源關系對。每個克隆對由兩位評委獨立驗證,如果存在沖突,則在與第三位評委討論后做出最終決定。最終在函數粒度的檢測上,我們的工具準確率達到95%,誤報主要存在于非常短的函數片段中,因為函數片段越小,單個詞的相對權重就越大,對結果又比較大的影響。而在代碼塊粒度的檢測上,我們的工具準確率為85%,誤報的原因與函數片段類似。 針對單個項目不同的release版本中的代碼來源關系,我們以Linux內核中包含的arch模塊代碼為例,研究arch模塊中部分代碼在Linux和FreeBSD不同發布版本之間的來源關系。我們在arch模塊中選取了長度大小適中的void acct_process(void)函數,目的是研究該段代碼在不同Linux和FreeBSD發布版本中的來源關系,也就是要找出該段代碼在哪些Linux內核版本中出現過。void acct_process(void)函數只是static void do_acct_process(struct file *file)函數的包裝器,而static void do_acct_process(struct file *file)函數的主要功能是調用者保存對文件的引用。void acct_process(void)函數代碼片段如下: void acct_process(void){ struct file *file = NULL; //accelerate the common fastpath: if (!acct_globals.file) return; spin_lock(&acct_globals.lock); file = acct_globals.file; if (unlikely(!file)) { spin_unlock(&acct_globals.lock); return; } get_file(file); spin_unlock(&acct_globals.lock); do_acct_process(file); fput(file); } 由于Linux和FreeBSD中release版本眾多,我們選取了具有代表性的Linux-2.5.75、Linux-2.6.0、Linux-3.2.3、Linux-3.10.1版本和FreeBSD-7.3、FreeBSD-9.1、FreeBSD-11.0版本。結果顯示arch模塊中void acct_process(void)函數在Linux-2.6.0、Linux-3.2.3和FreeBSD-9.1中出現過,在Linux-3.10.1和FreeBSD-11.0其他版本中并未出現,結果如圖2所示。 圖2 arch模塊在Linux和FreeBSD中代碼來源 針對多個項目的代碼來源關系,我們分析了android-xbmcremote項目在不同來源項目中的來源關系。android-xbmcremote 是GitHub上Android開源項目,我們的代碼庫選取了50個開源項目。其中android-xbmcremote中public boolean equals(Object o)函數代碼在當前代碼資源庫中,來自5個項目,完全相同的代碼最早出現在Spring-Framework項目的3.2.18版本中,有70%相似的代碼最早出現在ElasticSearch項目,因此我們認為它可能來自Spring-Framework項目、ElasticSearc項目、Spring-boot項目。由于代碼資源庫中的項目和版本有限,因此所得到的結論僅能參考。但本文所提的方法是通用的,并且可以通過并行化方式在更大規模的代碼資源庫中使用。 內部有效性威脅:所提的方法目前僅是以代碼克隆為手段的,由于代碼可能會發生持續演化,因此對演化的分析可能是本方法的弱點,難以找到由于持續演化而不再是克隆的可能來源片段。但是由于本方法對克隆檢測是逐版本進行的,因此一定程度上緩解了版本演化的矛盾,可以在一定的置信度內找到演化的代碼來源關系。 外部有效性威脅:目前只對兩個待測系統進行了來源分析,并且代碼資源庫中的代碼量也只有千萬行級,因此本方法對于其他類型或語言的項目的來源檢測效果仍有待考量。但我們在選擇項目時考慮了不同時間、不同規模的項目,從而所選項目具有一定的代表性,這表明在符合特定條件的情況下,本方法具有通用性。 本文提出了一種基于Hash詞袋模型的跨項目的大規模代碼來源分析方法,設計并實現了一個大規模代碼庫的代碼來源追蹤系統。該系統首先提取代碼詞袋模型,然后利用詞袋模型設計并實現了一個并行化的代碼來源算法,找出目標項目在代碼庫中的來源關系。該系統能夠在多個項目之間找到不同克隆代碼的來源關系,輔助軟件維護人員作出相應的軟件維護決策。實驗結果表明,該系統能夠有效地找出目標項目在大規模代碼庫中的代碼來源信息。 本文下一步工作將考慮代碼演化,進一步細分置信度,使來源分析更精確;同時也將擴展數據規模,優化算法,提升效率。2.3 構建代碼來源鏈
3 實驗與案例分析
3.1 性 能
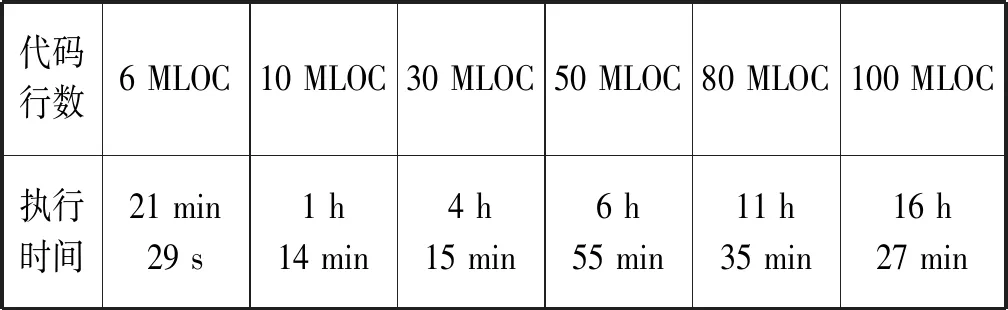
3.2 召回率與準確率

3.3 案例分析
3.4 有效性威脅
4 結 語
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
