基于BiLSTM-CNN串行混合模型的文本情感分析
2020-03-06 12:55:58王偉杰
計(jì)算機(jī)應(yīng)用 2020年1期
趙 宏,王 樂(lè),王偉杰
(蘭州理工大學(xué) 計(jì)算機(jī)與通信學(xué)院,蘭州 730050)
0 引言
互聯(lián)網(wǎng)技術(shù)的持續(xù)進(jìn)步帶動(dòng)自媒體的快速發(fā)展,以微博、Facebook、Twitter等為代表的自媒體為用戶提供了表達(dá)觀點(diǎn)和抒發(fā)個(gè)人情感的平臺(tái),累積了海量帶有個(gè)人觀點(diǎn)和情感傾向的文本。對(duì)這些文本中個(gè)人觀點(diǎn)和情感傾向進(jìn)行挖掘,可以及時(shí)獲取網(wǎng)民對(duì)熱點(diǎn)事件的觀點(diǎn)、網(wǎng)民對(duì)購(gòu)物和社交活動(dòng)的情感傾向,有助于政府相關(guān)部門(mén)對(duì)網(wǎng)絡(luò)輿情的把控,商家對(duì)客戶需求的精準(zhǔn)理解[1]。
這些海量文本來(lái)源于互聯(lián)網(wǎng)的眾多用戶,形式多樣,無(wú)固定格式,很難用簡(jiǎn)單的自動(dòng)化手段進(jìn)行處理;如果依靠人工處理,則存在工作量過(guò)大和實(shí)時(shí)性較差等問(wèn)題[2]。自然語(yǔ)言處理領(lǐng)域的文本情感分析可以從表達(dá)形式自由的文本中提取作者的情感傾向,能夠應(yīng)用于海量文本的情感分析中。
為了實(shí)現(xiàn)海量文本的情感分析,學(xué)者們通過(guò)統(tǒng)計(jì)學(xué)、機(jī)器學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)等方法分析文本情感傾向[3]。
基于統(tǒng)計(jì)學(xué)的方法,首先對(duì)情感詞典中短語(yǔ)進(jìn)行極性和強(qiáng)度標(biāo)注;然后依據(jù)情感詞典,對(duì)待處理文本中提取的關(guān)鍵詞計(jì)算積極或消極的情感得分;最后經(jīng)過(guò)總和,得到文本情感傾向。常用的情感詞典主要有詞匯網(wǎng)絡(luò)詞典(WordNet)、臺(tái)灣大學(xué)情感詞典(National Taiwan University Sentiment Dictionary,NTUSD)和評(píng)價(jià)詞詞典(General Inquirer, GI)等[4]。Hu等[5]依托WordNet詞典計(jì)算待處理文本的情感得分,取得了較好的效果。Kim等[6]利用手工采集的種子情感詞匯對(duì)現(xiàn)有情感詞典進(jìn)行擴(kuò)充,提高了文本情感分析的準(zhǔn)確率。郗亞輝[7]利用情感詞間的交互信息和上下文約束關(guān)系擴(kuò)展了情感詞典的功能,從而提高了文本情感分析的準(zhǔn)確率,取得比較好的效果。Xu等[8]利用基本情感詞、字段情感詞和多義詞情感詞對(duì)情感詞典進(jìn)行擴(kuò)充,在評(píng)論文本上提高了文本情感分析的準(zhǔn)確率。Hu等[5]、Kim等[6]、郗亞輝[7]和Xu等[8]都是依托情感詞典統(tǒng)計(jì)待處理文本的積極和消極情感詞的數(shù)目,從而得到文本的情感傾向,取得較好的效果;但文本情感分析的準(zhǔn)確率和情感詞典規(guī)模的關(guān)聯(lián)度較大,從而使得模型的泛化能力較差,實(shí)時(shí)性不強(qiáng)。
基于機(jī)器學(xué)習(xí)方法,首先通過(guò)人工標(biāo)注的形式構(gòu)造結(jié)構(gòu)化的文本特征,然后使用樸素貝葉斯(Naive Bayes, NB)、最大熵 (Maximum Entropy, ME)和支持向量機(jī) (Support Vector Machine, SVM)等機(jī)器學(xué)習(xí)分類(lèi)器對(duì)待處理文本進(jìn)行情感分析。Pang等[9]根據(jù)傳統(tǒng)自然語(yǔ)言處理中的文本分類(lèi)技術(shù),綜合應(yīng)用樸素貝葉斯、最大熵和支持向量機(jī)等文本情感分析方法,在提取英文電影評(píng)論文本情感上取得了顯著的效果。李婷婷等[10]提出了一種基于SVM和條件隨機(jī)場(chǎng)(Conditional Random Field, CRF)相結(jié)合的文本情感分析方法,利用多種文本特征,如詞性、情感、程度等,構(gòu)造出不同的特征組合,提高了文本分類(lèi)的準(zhǔn)確率。朱遠(yuǎn)平等[11]構(gòu)建了一種優(yōu)化的SVM決策樹(shù)分類(lèi)器,依據(jù)類(lèi)間距離進(jìn)行分類(lèi),提高了SVM決策樹(shù)分類(lèi)器在文本分類(lèi)中的有效性。Cai等[12]先利用情感詞典對(duì)待處理文本構(gòu)造結(jié)構(gòu)化的文本特征;然后使用SVM和梯度提升樹(shù)(Gradient Boosting Decision Tree, GBDT)結(jié)合的混合模型進(jìn)行文本情感分析,并取得了比單一模型更好的分類(lèi)效果。Pang等[9]、李婷婷等[10]、朱遠(yuǎn)平等[11]和Cai等[12]都是通過(guò)人工構(gòu)造結(jié)構(gòu)化的文本特征如詞性、情感等,使用機(jī)器學(xué)習(xí)分類(lèi)器對(duì)待處理文本進(jìn)行情感傾向分析。雖都取得顯著的分類(lèi)效果,但過(guò)多地人工構(gòu)造結(jié)構(gòu)化的文本特征,實(shí)時(shí)性較差。
基于神經(jīng)網(wǎng)絡(luò)的方法,首先利用詞向量模型將離散的文本詞匯轉(zhuǎn)化為含有語(yǔ)義信息的高維實(shí)數(shù)向量,然后以有監(jiān)督的形式學(xué)習(xí)積極和消極的詞向量特征,從而得出文本的情感傾向。Bengio等[13]利用神經(jīng)網(wǎng)絡(luò)構(gòu)建語(yǔ)言模型,將詞向量映射到實(shí)數(shù)空間,通過(guò)計(jì)算詞之間的數(shù)值距離來(lái)判斷詞之間的相似性,簡(jiǎn)化了文本情感提取方法。Kim[14]使用不同卷積核的卷積神經(jīng)網(wǎng)絡(luò)對(duì)英文文本局部語(yǔ)義特征進(jìn)行提取,實(shí)現(xiàn)了句子級(jí)的分類(lèi)任務(wù)并取得很好的分類(lèi)效果。梁軍等[15]提出了基于極性轉(zhuǎn)移和LSTM神經(jīng)網(wǎng)絡(luò)的情感分析方法,在情感極性轉(zhuǎn)移模型中使用LSTM提取文本上文語(yǔ)義信息,提高了情感分析的準(zhǔn)確率。曾誰(shuí)飛等[16]將單詞詞典和詞性詞典的詞向量進(jìn)行融合,構(gòu)成Double word-embedding,送入BiLSTM進(jìn)行訓(xùn)練,進(jìn)一步提高了文本情感分析的準(zhǔn)確率。Ma等[17]提出了一種基于特征的合成存儲(chǔ)器網(wǎng)絡(luò)(Feature-based Compositing Memory Network,F(xiàn)CMN),利用FCMN提取待處理文本的三種特征豐富上下文的單詞表示。通過(guò)結(jié)合特征表示和詞嵌入,提高了注意力的性能,從而在文本情感分析中取得不錯(cuò)的分類(lèi)效果。Bengio等[13]、Kim[14]、梁軍等[15]、曾誰(shuí)飛等[16]和Ma等[17]都通過(guò)神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型進(jìn)行文本情感分析,并取得很好的分類(lèi)效果;但沒(méi)有綜合考慮文本的上下文信息和局部語(yǔ)義特征對(duì)文本情感分析的影響。
以上文本情感分析方法各有優(yōu)勢(shì),相比而言,基于統(tǒng)計(jì)學(xué)的方法使用情感詞典統(tǒng)計(jì)帶有情感標(biāo)注的短語(yǔ)計(jì)算情感得分,提高了文本情感分析的準(zhǔn)確率;但文本情感分析的準(zhǔn)確率和情感詞典規(guī)模的關(guān)聯(lián)度較大,實(shí)時(shí)性不強(qiáng)。基于機(jī)器學(xué)習(xí)的方法使用人工標(biāo)注的方式構(gòu)造結(jié)構(gòu)化的文本特征,可以有效提高文本情感分析的準(zhǔn)確率;但由于需要較多地人工構(gòu)造特征,實(shí)時(shí)性仍然不強(qiáng)。另外,人工標(biāo)注數(shù)據(jù)還需要一定的先驗(yàn)知識(shí),使得該方法應(yīng)用于大規(guī)模文本數(shù)據(jù)時(shí),效用下降。基于神經(jīng)網(wǎng)絡(luò)的方法可以從向量化的文本詞匯中自動(dòng)提取語(yǔ)義特征,不依賴(lài)人工構(gòu)造的特征;但是,使用單一的神經(jīng)網(wǎng)絡(luò)模型進(jìn)行特征提取,不能同時(shí)提取文本上下文信息和局部語(yǔ)義特征。
綜上,針對(duì)現(xiàn)有文本情感分析方法實(shí)時(shí)性不強(qiáng)、難以應(yīng)用到大規(guī)模文本、不能同時(shí)提取文本上下文信息和局部語(yǔ)義特征等問(wèn)題,提出一種基于雙向長(zhǎng)短時(shí)記憶神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)(Bi-directional Long Short Term Memory and Convolutional Neural Network, BiLSTM-CNN)串行混合的文本情感分析方法。首先,使用Word2Vec對(duì)文本詞匯進(jìn)行向量化,將評(píng)論文本詞匯轉(zhuǎn)化成高維實(shí)數(shù)向量;然后,通過(guò)BiLSTM-CNN串行混合模型提取文本上下文特征和局部語(yǔ)義特征;最后,使用Softmax分類(lèi)器對(duì)文本進(jìn)行情感傾向分類(lèi)。
本文的主要工作如下:
1)利用BiLSTM提取文本上下文特征,充分考慮了自然語(yǔ)言中一個(gè)詞的語(yǔ)義不僅與它之前的信息有關(guān),還與它之后的信息有關(guān);
2)先利用BiLSTM對(duì)待處理文本進(jìn)行上下文特征提取,再對(duì)已提取的上下文特征使用CNN進(jìn)行局部語(yǔ)義特征提取。既能同時(shí)利用BiLSTM和CNN提取特征的優(yōu)勢(shì),又能很好地理解待處理文本的語(yǔ)義,從而提高文本情感分析的準(zhǔn)確率。
1 BiLSTM-CNN串行混合模型的建立
基于BiLSTM-CNN串行混合模型如圖1所示,分為數(shù)據(jù)預(yù)處理、文本詞匯向量化、特征提取、情感分類(lèi)等四個(gè)步驟。

圖1 BiLSTM-CNN串行混合模型Fig. 1 Serial hybrid model based on BiLSTM-CNN
圖1中,數(shù)據(jù)預(yù)處理對(duì)文獻(xiàn)[18]中帶標(biāo)注的評(píng)論文本去除噪聲,只保留具有語(yǔ)義信息的文本,降低噪聲對(duì)文本情感分析準(zhǔn)確率的影響;文本詞匯的向量化利用Word2Vec工具將評(píng)論文本詞匯轉(zhuǎn)化成含有語(yǔ)義信息的實(shí)數(shù)向量;特征提取使用BiLSTM-CNN串行混合模塊,細(xì)分為BiLSTM提取文本的上下文信息和CNN提取局部語(yǔ)義特征;情感分類(lèi)使用Softmax。最后,使用十折交叉驗(yàn)證方法對(duì)基于BiLSTM-CNN串行混合模型進(jìn)行訓(xùn)練以及性能評(píng)估。
1.1 數(shù)據(jù)預(yù)處理
大量的評(píng)論文本由不同的用戶抒寫(xiě)而來(lái),形式自由,沒(méi)有固定的語(yǔ)法和模式,而評(píng)論文本不僅包含具有語(yǔ)義信息的文本,還存在大量的噪聲數(shù)據(jù)。為了減少噪聲數(shù)據(jù)對(duì)文本情感分析的影響,需要對(duì)評(píng)論文本進(jìn)行以下預(yù)處理:
1)過(guò)濾掉所有的標(biāo)點(diǎn)符號(hào)和特殊字符,只保留具有語(yǔ)義價(jià)值信息的中文文本。
2)使用jieba分詞工具進(jìn)行詞語(yǔ)分割。
3)使用哈工大停用詞表、百度停用詞表和四川大學(xué)機(jī)器智能實(shí)驗(yàn)室停用詞表[19]的交集,去除噪聲數(shù)據(jù)。
4)對(duì)標(biāo)簽進(jìn)行數(shù)字化,積極情感表示為1,消極情感表示為0。
1.2 文本詞匯向量化
數(shù)量巨大的評(píng)論由不同用戶自由書(shū)寫(xiě)而來(lái),沒(méi)有結(jié)構(gòu)化或規(guī)范化的語(yǔ)法和模式,具有高度非結(jié)構(gòu)化的特點(diǎn),因此,不能直接使用現(xiàn)成的數(shù)學(xué)模型或統(tǒng)計(jì)模型來(lái)處理和分析,需要將評(píng)論中的文本詞匯轉(zhuǎn)化成實(shí)數(shù)向量再進(jìn)行處理和分析。開(kāi)源詞向量工具Word2Vec[20-21]利用詞袋模型(Continueus Bag Of Words, CBOW)或跳字模型(Skip-gram),能夠?qū)⑽谋驹~匯轉(zhuǎn)化成含有一定語(yǔ)義信息的高維實(shí)數(shù)向量。
CBOW模型通過(guò)上下文詞匯預(yù)測(cè)中心詞,Skip-gram模型通過(guò)中心詞預(yù)測(cè)其上下文詞匯。CBOW在訓(xùn)練的過(guò)程中,預(yù)測(cè)次數(shù)為x,其中x是評(píng)論文本的詞匯數(shù)量;Skip-gram預(yù)測(cè)次數(shù)則是k*x,其中k表示上下文的詞匯數(shù)量。兩種模型對(duì)比,CBOW相比Skip-gram訓(xùn)練時(shí)間較短,但是對(duì)于一些低頻詞,CBOW模型的預(yù)測(cè)效果較差,模型泛化能力較弱。考慮到模型的泛化能力,本文選用Word2Vec的Skip-gram模型對(duì)文本詞匯進(jìn)行向量化處理。
假設(shè)評(píng)論文本W(wǎng)={w(1),w(2),…,w(n)},以第t個(gè)詞為中心詞進(jìn)行文本詞匯向量化操作,記為(V(w(t)),Context(w(t))),其中V(w(t))為評(píng)論文本W(wǎng)中心詞w(t)的詞向量,Context(w(t))為w(t)的上下文詞向量。使用Skip-gram模型的輸入、投影和輸出三層結(jié)構(gòu)進(jìn)行文本詞匯向量化轉(zhuǎn)變,如圖2所示。

圖2 Skip-gram模型Fig. 2 Skip-gram model
圖2中,評(píng)論文本W(wǎng)的第t個(gè)詞w(t)為中心詞,輸入層為中心詞w(t)的one-hot詞向量V(w(t));從輸入層到投影層是恒等投影,即將V(w(t))投影到V(w(t));投影層到輸出層根據(jù)評(píng)論文本詞匯的詞頻構(gòu)建Huffman樹(shù),并按照式(1)計(jì)算w(t)的上下文詞匯向量:
P(V(w(i))|V(w(t)))
(1)
其中:V(w(i))∈Context(w),t為中心詞序號(hào),i為中心詞上下文詞匯與中心詞的距離。
從根節(jié)點(diǎn)開(kāi)始,投影層的值沿著Huffman樹(shù)進(jìn)行二元邏輯回歸(Logistic)分類(lèi),輸出w(t)周?chē)?n個(gè)上下文文本詞匯的詞向量。例如,如果n取2,則中心詞w(t)的前兩個(gè)詞為w(t-2),w(t-1),后兩個(gè)詞為w(t+1),w(t+2),它們對(duì)應(yīng)的詞向量為V(w(t-2)),V(w(t-1)),V(w(t+1)),V(w(t+2)),即Context(w)={V(w(t-2)),V(w(t-1)),V(w(t+1)),V(w(t+2))}。
1.3 上下文信息提取
不同的用戶通過(guò)自媒體平臺(tái)發(fā)表的評(píng)論是自然語(yǔ)言的一種表現(xiàn)形式,形式雖然自由但結(jié)構(gòu)上仍然存在上下文依賴(lài)關(guān)系。依據(jù)文本的上文信息和下文信息,能夠更準(zhǔn)確地理解文本語(yǔ)義。經(jīng)典的循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network, RNN)能夠挖掘文本的時(shí)序信息和上下文語(yǔ)義信息,但RNN在學(xué)習(xí)任意長(zhǎng)度的時(shí)間序列時(shí),隨著輸入的增多,對(duì)很久以前信息的感知能力下降,產(chǎn)生長(zhǎng)期依賴(lài)和梯度消失問(wèn)題[22],而從RNN改進(jìn)而來(lái)的長(zhǎng)短時(shí)記憶(Long Short Term Memory, LSTM)網(wǎng)絡(luò)[23]能夠解決RNN的長(zhǎng)期依賴(lài)和梯度消失問(wèn)題。圖3所示是具有三個(gè)門(mén)控結(jié)構(gòu)的LSTM網(wǎng)絡(luò)模型。
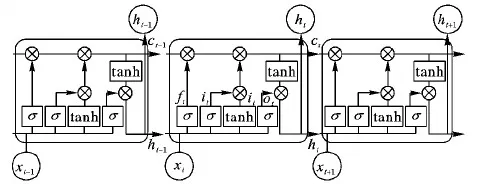
圖3 LSTM網(wǎng)絡(luò)模型Fig. 3 Network model of LSTM
LSTM模型中各個(gè)門(mén)計(jì)算如式(2)~(7)所示:
ft=σ(Wf·[ht-1,xt]+bf)
(2)
it=σ(Wi·[ht-1,xt]+bi)
(3)
ot=σ(Wo·[ht-1,xt]+bo)
(4)
ht=ot°tanhct
(5)
(6)
(7)
其中:Wf表示遺忘門(mén)連接的權(quán)重矩陣,bf表示遺忘門(mén)的偏移值,Wi表示輸入門(mén)連接的權(quán)重矩陣,bi表示輸入門(mén)的偏移值,Wo表示輸出門(mén)連接的權(quán)重矩陣,bo表示輸出門(mén)的偏移值,“°”表示兩個(gè)矩陣元素的相乘。
雖然LSTM解決了梯度消失和長(zhǎng)期依賴(lài)問(wèn)題,但LSTM只能學(xué)習(xí)文本的上文信息,而不能利用文本的下文信息。由于一個(gè)詞的語(yǔ)義不僅與文本的上文信息有關(guān),還與文本的下文信息密切相關(guān),因此,利用BiLSTM(Bi-directional Long Short Term Memory)[24]代替LSTM,引入下文信息。BiLSTM模型是由兩個(gè)LSTM網(wǎng)絡(luò)通過(guò)上下疊加構(gòu)成,如圖4所示。

圖4 BiLSTM網(wǎng)絡(luò)模型Fig. 4 Network model of BiLSTM
BiLSTM模型中每一個(gè)時(shí)刻狀態(tài)計(jì)算如式(8)、(9)所示。輸出則由這兩個(gè)方向的LSTM的狀態(tài)共同決定,如式(10)所示:
(8)
(9)
(10)
其中:wt表示正向輸出的權(quán)重矩陣,vt表示反向輸出的權(quán)重矩陣,bt表示t時(shí)刻的偏置。
基于BiLSTM的語(yǔ)言模型結(jié)構(gòu)如圖5所示,其中,V(w(i))表示第i個(gè)評(píng)論文本詞匯的詞向量,1≤i≤n。
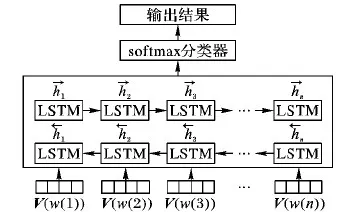
圖5 BiLSTM語(yǔ)言模型結(jié)構(gòu)Fig. 5 Language model structure of BiLSTM
假設(shè)評(píng)論文本W(wǎng)={w(1),w(2),…,w(n)},首先將評(píng)論文本W(wǎng)中的詞w(i)利用Word2Vec轉(zhuǎn)化為對(duì)應(yīng)的詞向量V(w(i)),并將詞w(i)組成的句子映射為句子矩陣Sij,其中Sij={V(w(1)),V(w(2)),…,V(w(i))},1≤i≤n。然后利用BiLSTM對(duì)句子矩陣Sij進(jìn)行上下文特征提取,計(jì)算方法如式(10)所示,即利用正向的LSTM提取評(píng)論文本的上文信息特征,計(jì)算方法如式(8)所示,反向LSTM提取評(píng)論文本的下文信息特征,計(jì)算方法如式(9)所示。
1.4 局部語(yǔ)義特征提取
評(píng)論文本由不同的用戶書(shū)寫(xiě),用戶通過(guò)形容詞、副詞等情感詞匯表達(dá)其情感傾向。情感詞匯或句子間存在一定的層次結(jié)構(gòu)和語(yǔ)義關(guān)系,卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)[25]可以通過(guò)卷積層提取情感詞匯所表達(dá)的局部語(yǔ)義特征,因此,選用CNN進(jìn)行文本局部語(yǔ)義特征提取。
用于文本語(yǔ)義提取并進(jìn)行分類(lèi)的卷積神經(jīng)網(wǎng)絡(luò)模型如圖6所示。
假設(shè)評(píng)論文本W(wǎng)={w(1),w(2),…,w(n)},首先將評(píng)論文本W(wǎng)中的詞w(i)利用Word2Vec轉(zhuǎn)化為對(duì)應(yīng)的詞向量V(w(i)),并將詞w(i)組成的句子映射為句子矩陣Sij,其中Sij={V(w(1)),V(w(2)),…,V(w(i))},1≤i≤n。CNN將Sij作為卷積層的輸入,該卷積層用大小為r*k的濾波器對(duì)句子矩陣Sij進(jìn)行卷積操作,提取Sij的局部語(yǔ)義特征,計(jì)算方法如式(11)所示:
cij=f(F·V(w(i:i+r-1))+b)
(11)
其中:F代表r*k的濾波器,f代表ReLU的非線性轉(zhuǎn)換,V(w(i:i+r-1))代表Sij中從i到i+r-1共r行詞向量,b代表偏置量,cij代表CNN提取的由i個(gè)詞組成的第j個(gè)句子的局部語(yǔ)義特征。

圖6 CNN提取情感特征模型Fig. 6 Emotional features model extracted by CNN
1.5 局部語(yǔ)義特征提取
文本情感特征提取流程如圖7所示。
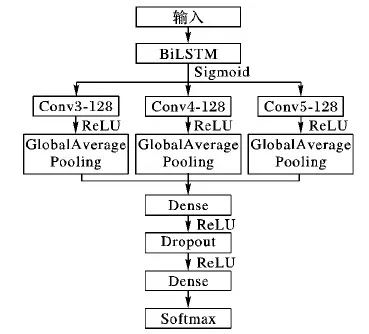
圖7 文本情感提取流程Fig. 7 Flowchart of text sentiment extraction
圖7所示流程解釋如下。
1)輸入層。使用文獻(xiàn)[18]中的數(shù)據(jù)集,對(duì)其包含的6個(gè)領(lǐng)域的評(píng)論文本進(jìn)行預(yù)處理,并將處理后的評(píng)論文本進(jìn)行詞匯向量化轉(zhuǎn)化,步驟如下:
a)對(duì)評(píng)論文本進(jìn)行預(yù)處理操作,具體操作見(jiàn)1.1節(jié)。
b)使用Word2Vec對(duì)預(yù)處理后的評(píng)論文本進(jìn)行文本詞匯向量化轉(zhuǎn)化。建立詞向量字典,使每一個(gè)文本詞匯唯一對(duì)應(yīng)一個(gè)已訓(xùn)練詞向量,其中,詞向量維度設(shè)置為100。將字典中沒(méi)有出現(xiàn)的文本詞匯的詞向量設(shè)置為0。
2)嵌入層。將文本詞匯中的詞向量進(jìn)行拼接,生成句子級(jí)詞向量矩陣,生成式如(12)所示:
Sij=V(w(1))⊕V(w(2))⊕…⊕V(w(i))
(12)
其中:w(1),w(2),…,w(i)表示文本詞匯;V(w(1)),V(w(2)),…,V(w(i))表示文本詞匯對(duì)應(yīng)的詞向量;Sij表示由i個(gè)詞向量拼接成的第j個(gè)句子詞向量矩陣;⊕表示詞向量的拼接操作。
3)BiLSTM。以Embedding層的句子矩陣Sij為BiLSTM層的輸入,設(shè)置隱層大小為128,激活函數(shù)為Sigmoid。將輸入序列分別從模型的兩個(gè)方向輸入,通過(guò)隱藏層提取文本的上文信息特征和文本的下文信息特征,最后,通過(guò)式(13)將兩個(gè)方向的隱層輸出進(jìn)行拼接:
hijt=BiLSTM(sijt)
(13)
其中:Sijt表示在t時(shí)刻輸入的第j個(gè)句子的i個(gè)詞向量組成的句子矩陣;hijt表示在t時(shí)刻BiLSTM的輸出。
4)Conv。使用濾波器為3×100,4×100,5×100各128個(gè)CNN提取局部語(yǔ)義特征[11],并通過(guò)式(14)進(jìn)行計(jì)算:
oijt=CNN(hijt)
(14)
其中:hijt表示在t時(shí)刻BiLSTM的輸出,oijt表示t時(shí)刻CNN的輸出。
CNN中激活函數(shù)使用ReLU,步長(zhǎng)stride設(shè)置為1。利用全局平均池化對(duì)卷積層的輸出矩陣進(jìn)行降維,使用Keras中的concatenate()方法對(duì)CNN中不同卷積核提取的局部語(yǔ)義特征進(jìn)行融合,最后使用全連接層進(jìn)行連接。
5)輸出。通過(guò)Softmax函數(shù)進(jìn)行文本情感分類(lèi),分類(lèi)函數(shù)如式(15)所示:
yi=softmax(widijt+bi)
(15)
其中:wi表示Dense層到輸出層的權(quán)重系數(shù)矩陣,bi表示相應(yīng)的偏置,dijt表示在t時(shí)刻Dense層的輸出向量。
2 實(shí)驗(yàn)與結(jié)果分析
2.1 實(shí)驗(yàn)環(huán)境
構(gòu)建操作系統(tǒng)為64位Windows 7,英特爾core i7- 5500u 2.40 GHz雙核CPU,8 GB內(nèi)存,開(kāi)發(fā)環(huán)境為Keras,開(kāi)發(fā)工具為JetBrains PyCharm,開(kāi)發(fā)語(yǔ)言為Python的實(shí)驗(yàn)環(huán)境。
2.2 實(shí)驗(yàn)數(shù)據(jù)集
實(shí)驗(yàn)選用文獻(xiàn)[15]中的數(shù)據(jù)集,該數(shù)據(jù)集包含兩萬(wàn)多條中文標(biāo)注語(yǔ)料,覆蓋書(shū)店、酒店和電腦商城等6個(gè)領(lǐng)域的評(píng)論,共21 105條,取6個(gè)領(lǐng)域的部分樣例如表1所示。

表1 數(shù)據(jù)集部分樣例 Tab. 1 Some examples in the dataset
2.3 評(píng)價(jià)標(biāo)準(zhǔn)
為驗(yàn)證模型在文本情感分析的性能,使用準(zhǔn)確率(Precision)、召回率(Recall)和F-measure[26],計(jì)算式如式(16)~(18)所示:
(16)
(17)
(18)
其中:TP(True Positive)表示積極情感預(yù)測(cè)為積極情感的數(shù)量,F(xiàn)P(False Positive)表示消極情感預(yù)測(cè)為積極情感的數(shù)量,F(xiàn)N(False Negative)表示積極情感預(yù)測(cè)為消極情感的數(shù)量。
2.4 超參數(shù)選擇
由于實(shí)驗(yàn)參數(shù)的設(shè)定對(duì)實(shí)驗(yàn)結(jié)果的影響比較大,實(shí)驗(yàn)采用參數(shù)固定法,詞向量分別取100維、200維;CNN隱層節(jié)點(diǎn)數(shù)分別取32、64和128;BiLSTM隱層節(jié)點(diǎn)數(shù)分別取64、128和256,進(jìn)行多次實(shí)驗(yàn)。實(shí)驗(yàn)中選用Adam作為優(yōu)化函數(shù),選用交叉熵作為損失函數(shù)。通過(guò)對(duì)比多次實(shí)驗(yàn)的結(jié)果,發(fā)現(xiàn)當(dāng)取表2參數(shù)時(shí),BiLSTM-CNN串行混合模型的分類(lèi)效果最好。

表2 模型參數(shù)設(shè)置 Tab. 2 Model parameter setting
為增強(qiáng)模型泛化能力,在CNN和全連接層之間加入Dropout層,如圖8所示,Dropout不同的取值會(huì)影響模型輸出的準(zhǔn)確率,當(dāng)Dropout取值為50%時(shí),準(zhǔn)確率最高。
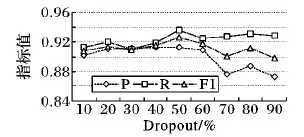
圖8 Dropout曲線Fig. 8 Dropout curve
Word2Vec向量化工具通過(guò)設(shè)置Window_size的大小來(lái)實(shí)現(xiàn)文本詞匯的語(yǔ)義理解,Window_size過(guò)大或過(guò)小都會(huì)引起文本情感分析效果不佳等問(wèn)題。通過(guò)設(shè)置Window_size的大小分別為1,2,…,10進(jìn)行對(duì)比實(shí)驗(yàn),結(jié)果如圖9所示,當(dāng)Window_size取值為7時(shí),綜合評(píng)價(jià)指標(biāo)F1達(dá)到全局最優(yōu)。
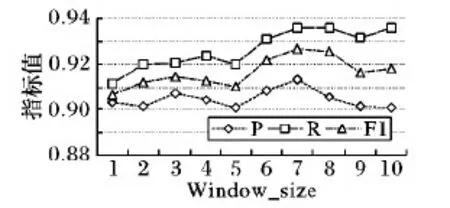
圖9 Window_size曲線Fig. 9 Window_size curve
2.5 模型性能比較
為驗(yàn)證本文文本情感分析方法的有效性,在相同的實(shí)驗(yàn)環(huán)境下使用包含6個(gè)領(lǐng)域的評(píng)論文本作為實(shí)驗(yàn)數(shù)據(jù)。首先,利用Word2Vec向量化工具將評(píng)論文本轉(zhuǎn)化成實(shí)數(shù)向量,其次,分別構(gòu)造單一的Word2Vec-CNN、Word2Vec-LSTM、Word2Vec-BiLSTM情感分析算法模型以及本文情感分析算法模型,最后,進(jìn)行實(shí)驗(yàn)對(duì)比,實(shí)驗(yàn)結(jié)果如表3所示。

表3 所提模型與單一模型的性能比較 Tab. 3 Comparison of the proposed model and single models in performance
由表3可知,本文文本情感分析算法模型在召回率和綜合評(píng)價(jià)指標(biāo)F1方面,優(yōu)于單一的CNN、LSTM和BiLSTM文本情感分析算法模型。在準(zhǔn)確率方面,本文的文本情感分析算法模型優(yōu)于單一的CNN和LSTM文本情感分析算法模型,與單一的BiLSTM文本情感分析算法模型準(zhǔn)確率相當(dāng),且在綜合評(píng)價(jià)指標(biāo)F1上,本文文本情感分析模型比單CNN、單LSTM和單BiLSTM文本情感分析模型分別提高了2.02個(gè)百分點(diǎn)、1.18個(gè)百分點(diǎn)和0.85個(gè)百分點(diǎn)。分析其原因,單CNN文本情感分析模型只考慮了局部語(yǔ)義特征對(duì)文本情感分析模型的影響,沒(méi)有考慮評(píng)論文本的上下文關(guān)系;單LSTM文本情感分析模型只考慮文本的下文信息,沒(méi)有考慮文本的上文信息以及局部語(yǔ)義特征對(duì)文本情感分析的影響;單BiLSTM文本情感分析模型充分考慮了上下文對(duì)文本情感分析的影響,但忽略了文本局部語(yǔ)義特征在文本情感分析的重要性。綜合考慮文本上下文和局部語(yǔ)義特征對(duì)文本情感分析的影響,本文所提的BiLSTM-CNN串行混合模型的文本情感分析算法明顯優(yōu)于其他三種單一的文本情感分析算法。
2.6 同類(lèi)相關(guān)工作對(duì)比
在相同的實(shí)驗(yàn)環(huán)境下,使用包含6個(gè)領(lǐng)域的評(píng)論文本作為實(shí)驗(yàn)數(shù)據(jù)。首先對(duì)數(shù)據(jù)預(yù)處理后的評(píng)論文本使用Word2Vec文本詞匯向量化工具將評(píng)論文本詞匯轉(zhuǎn)化成含有語(yǔ)義信息的實(shí)數(shù)向量;然后將詞向量矩陣分別作為L(zhǎng)STM-CNN模型、BiLSTM-CNN并行特征融合模型和本文模型的輸入;最后分別按照如下方式構(gòu)造LSTM-CNN[27]、BiLSTM-CNN并行特征融合模型[28]和本文模型。
1)LSTM-CNN模型[27]:首先采用LSTM提取前向文本特征,然后使用CNN提取局部語(yǔ)義特征,最后由Softmax層對(duì)文本進(jìn)行情感分析。
2)BiLSTM-CNN并行特征融合模型[28]:首先利用BiLSTM和CNN分別提取文本上下文特征和提取局部語(yǔ)義特征,然后將分別提取的上下文特征和局部語(yǔ)義特征進(jìn)行融合,最后由Softmax層對(duì)文本進(jìn)行情感分析。
3)本文模型:首先使用BiLSTM提取文本上下文特征,然后利用不同卷積核的CNN對(duì)已提取的上下文特征進(jìn)行局部語(yǔ)義特征提取,最后由Softmax對(duì)文本進(jìn)行情感分析。
由表4可知,本文模型在準(zhǔn)確率、召回率和綜合評(píng)價(jià)指標(biāo)F1方面,均優(yōu)于LSTM-CNN模型和BiLSTM-CNN并行特征融合模型,且本文文本情感分析模型相比LSTM-CNN模型和BiLSTM-CNN并行融合模型在綜合評(píng)價(jià)指標(biāo)F1上分別提高了1.86和0.76個(gè)百分點(diǎn)。分析其原因:LSTM-CNN[27]忽略了文本的上文信息,因此在文本情感分析綜合評(píng)價(jià)指標(biāo)上表現(xiàn)一般;BiLSTM-CNN并行特征融合模型[28]分別提取了上下文信息和局部語(yǔ)義特征并進(jìn)行融合,在提取局部語(yǔ)義特征時(shí)忽略了上下文信息;而本文模型是先提取評(píng)論文本的上下文特征再對(duì)已提取的上下文特征使用CNN提取局部語(yǔ)義特征,綜合考慮了上下文信息和局部語(yǔ)義特征對(duì)文本情感分析的影響,得到了較好的結(jié)果。

表4 所提模型與混合模型的性能比較 Tab. 4 Comparison of the proposed model and hybrid models in performance
3 結(jié)語(yǔ)
本文提出一種基于BiLSTM-CNN串行混合模型用于文本情感分析研究。該模型充分利用BiLSTM和CNN模型的優(yōu)勢(shì),先使用BiLSTM對(duì)文本上下文特征進(jìn)行提取,再利用不同卷積核的CNN對(duì)已提取的上下文信息進(jìn)行局部語(yǔ)義特征提取,從而能夠更好地準(zhǔn)確理解評(píng)論文本的語(yǔ)義信息。在包含6個(gè)領(lǐng)域的評(píng)論文本數(shù)據(jù)集上進(jìn)行模型的訓(xùn)練和測(cè)試,實(shí)驗(yàn)結(jié)果表明,所提出的基于BiLSTM-CNN串行混合模型能夠更加準(zhǔn)確地完成文本情感分析任務(wù)。
本文只是考慮了積極和消極二元文本情感分析,在接下來(lái)的工作中,將考慮多元文本情感分析,得出文本更為豐富的語(yǔ)義信息。
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
